A CLI tool for exporting data from Elasticsearch into a CSV file.

Project description
A CLI tool for exporting data from Elasticsearch into a CSV file
Command line utility, written in Python, for querying Elasticsearch in Lucene query syntax or Query DSL syntax and exporting result as documents into a CSV file. This tool can query bulk docs in multiple indices and get only selected fields, this reduces query execution time.
Quick Look Demo
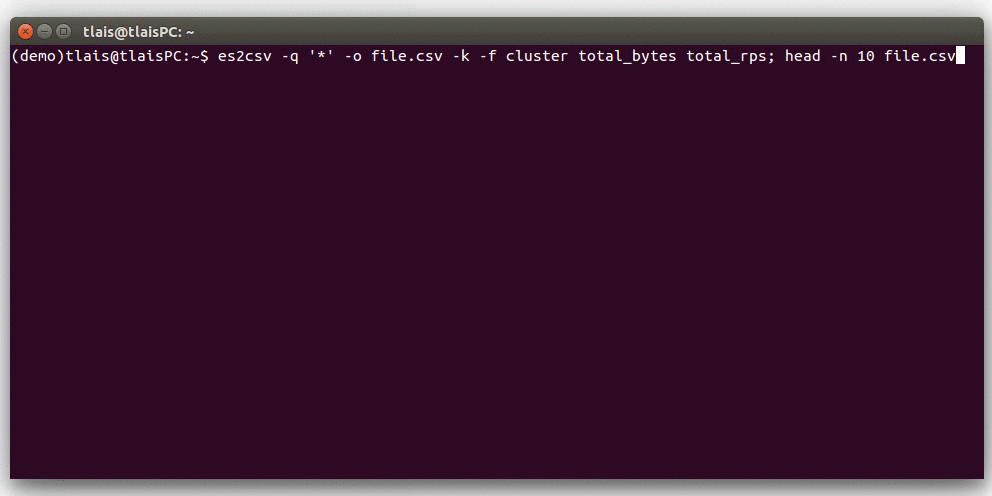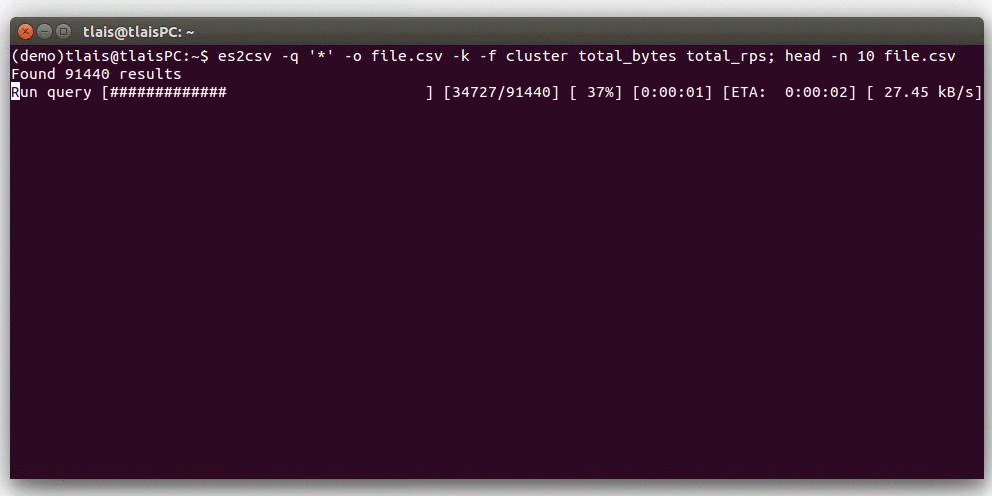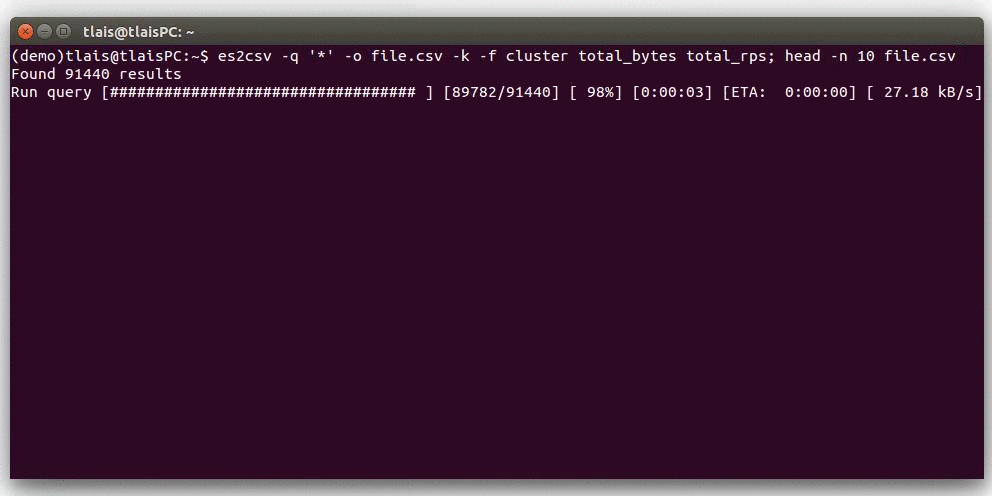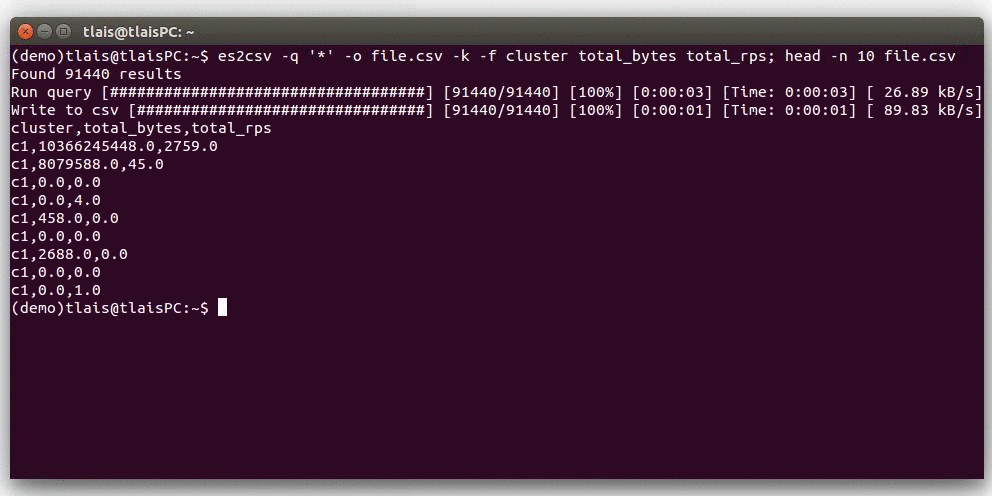
Requirements
Installation
>From source:
$ pip install git+https://github.com/taraslayshchuk/es2csv.git>From pip:
$ pip install es2csvUsage
$ es2csv [-h] -q QUERY [-u URL] [-a AUTH] [-i INDEX [INDEX ...]]
[-D DOC_TYPE [DOC_TYPE ...]] [-t TAGS [TAGS ...]] -o FILE
[-f FIELDS [FIELDS ...]] [-S FIELDS [FIELDS ...]] [-d DELIMITER]
[-m INTEGER] [-s INTEGER] [-k] [-r] [-e] [--verify-certs]
[--ca-certs CA_CERTS] [--client-cert CLIENT_CERT]
[--client-key CLIENT_KEY] [-v] [--debug]
Arguments:
-q, --query QUERY Query string in Lucene syntax. [required]
-o, --output-file FILE CSV file location. [required]
-u, --url URL Elasticsearch host URL. Default is http://localhost:9200.
-a, --auth Elasticsearch basic authentication in the form of username:password.
-i, --index-prefixes INDEX [INDEX ...] Index name prefix(es). Default is ['logstash-*'].
-D, --doc-types DOC_TYPE [DOC_TYPE ...] Document type(s).
-t, --tags TAGS [TAGS ...] Query tags.
-f, --fields FIELDS [FIELDS ...] List of selected fields in output. Default is ['_all'].
-S, --sort FIELDS [FIELDS ...] List of <field>:<direction> pairs to sort on. Default is [].
-d, --delimiter DELIMITER Delimiter to use in CSV file. Default is ",".
-m, --max INTEGER Maximum number of results to return. Default is 0.
-s, --scroll-size INTEGER Scroll size for each batch of results. Default is 100.
-k, --kibana-nested Format nested fields in Kibana style.
-r, --raw-query Switch query format in the Query DSL.
-e, --meta-fields Add meta-fields in output.
--verify-certs Verify SSL certificates. Default is False.
--ca-certs CA_CERTS Location of CA bundle.
--client-cert CLIENT_CERT Location of Client Auth cert.
--client-key CLIENT_KEY Location of Client Cert Key.
-v, --version Show version and exit.
--debug Debug mode on.
-h, --help show this help message and exit[ Usage Examples | Release Changelog ]
Release Changelog
5.5.2 (2018-03-21)
5.2.1 (2017-04-02)
5.2.0 (2017-02-16)
Updating version elasticsearch-py to 5.2.* and added support of Elasticsearch 5. (Issue #19)
2.4.3 (2017-02-15)
Update doc according to wildcard support in fields naming.
Added support of old version pip. (Issue #16)
2.4.2 (2017-02-14)
Added wildcard support in fields naming.
Removed column sorting. (Issue #21)
2.4.1 (2016-11-10)
2.4.0 (2016-10-26)
1.0.3 (2016-06-12)
1.0.2 (2016-04-12)
Added –raw_query(-r) argument for using the native Query DSL format.
1.0.1 (2016-01-22)
Fixed support elasticsearch-1.4.0.
Added –version argument.
Added history changelog.
1.0.0.dev1 (2016-01-04)
1.0.0.dev0 (2015-12-25)
Initial registration.
Added first dev-release on github.
Added first release on PyPI.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file es2csv-5.5.2.tar.gz.
File metadata
- Download URL: es2csv-5.5.2.tar.gz
- Upload date:
- Size: 10.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0ac4d64b5eaa1a4c24b008657ffeeeb5ad84a1b903f467b55d2e72eb1e963af1
|
|
| MD5 |
5f27ccd2a793391ce97b1be436ba6118
|
|
| BLAKE2b-256 |
7d4d331423adf788f1c82b0402604821011bf4d199230d75504a565f0f61be28
|
File details
Details for the file es2csv-5.5.2-py27-none-any.whl.
File metadata
- Download URL: es2csv-5.5.2-py27-none-any.whl
- Upload date:
- Size: 11.7 kB
- Tags: Python 2.7
- Uploaded using Trusted Publishing? No
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cf53dcbb29f6bc7c29014039049ac7d081be97ae7630726c56129e2aabae997a
|
|
| MD5 |
28a4714767793dc1517a2a08c606fbfa
|
|
| BLAKE2b-256 |
34379061c0bdb49153629fe61ce63701a5f9c9c85743c4564a68d841eb813fb9
|







