Evaluation Framework
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
Aleph Alpha Eval-Framework
Comprehensive LLM evaluation at scale - A production-ready framework for evaluating large language models across 90+ benchmarks.






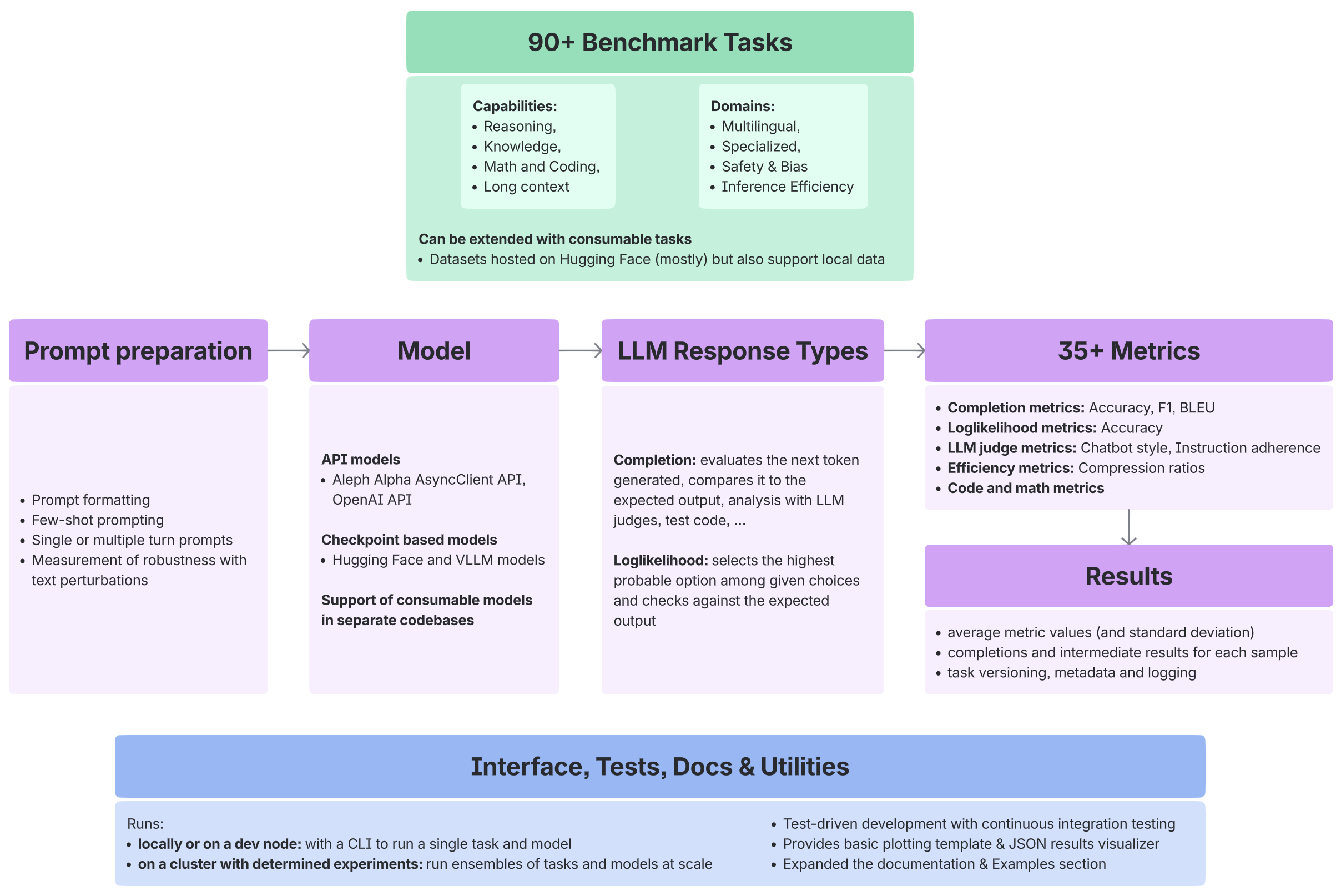
Why Choose This Framework?
- Scalability: Built for distributed evaluation. Currently providing an integration with Determined AI.
- Extensibility: Easily add custom models, benchmarks, and metrics with object-oriented base classes.
- Comprehensive: Comes pre-loaded with over 90 tasks covering a broad and diverse range, from reasoning and coding to safety and long-context. Also comes with a comprehensive set of metrics, including LLM-as-a-judge evaluations.
Other features
- Flexible Model Integration: Supports models loaded via HuggingFace Transformers or custom implementations using the BaseLLM class.
- Custom Benchmarks: Easily add new benchmarks with minimal code using the BaseTask class.
- Custom Metrics: Easily define new metrics using the BaseMetric class.
- Perturbation Testing: Robustness analysis with configurable perturbation types and probabilities.
- Rich Outputs: Generates JSON results, plots, and detailed analysis reports.
- Statistical Analysis: Includes confidence intervals and significance testing for reliable comparisons.
- Docker Support: Pre-configured Dockerfiles for local and distributed setups.
For full documentation, visit our Docs Page.
Quick Start
The codebase is tested and compatible with Python 3.12 and PyTorch 2.5. You will also need the appropriate CUDA dependencies and version installed on your system for GPU support. Detailed installation instructions can be found here.
The easiest way to get started is by installing the library via pip and use it as an external dependency.
pip install eval_framework
There are optional extras available to unlock specific features of the library:
apifor inference using the aleph-alpha client.determinedfor running jobs via determined.mistralfor inference on Mistral models.transformersfor inference using the transformers library.vllmfor inference via VLLM.
As a short hand, the all extra installs all of the above.
We use uv to better resolve dependencies when downloading the extras. You can install uv with:
curl -LsSf https://astral.sh/uv/install.sh | sh
or by follwing the uv installation docs.
Now, you can safely install the project with all optional extras:
uv sync --all-extras
or with pip
uv pip install eval_framework[all]
Tip: ensure python is properly installed with uv:
uv python install 3.12 --reinstall
We provide custom groups to control optional extras.
flash_attn: Installflash_attnwith correct handling of build isolation
Thus, the following will setup the project with flash_attn
uv sync --all-extras --group flash_attn
To evaluate a single benchmark locally, you can use the following command:
eval_framework \
--models src/eval_framework/llm/models.py \
--llm-name Smollm135MInstruct \
--task-name "MMLU" \
--task-subjects "abstract_algebra" \
--output-dir ./eval_results \
--num-fewshot 5 \
--num-samples 10
For more detailed CLI usage instructions, see the CLI Usage Guide.
Benchmark Coverage & Task Categories
Core Capabilities
Subset of core capabilities benchmarks coverd by eval-framework:
| Reasoning | Knowledge | Math | Coding | Structured outputs | Long Context |
|---|---|---|---|---|---|
| COPA, BalancedCOPA | ARC | AIME | BigCodeBench | IFEval | InfiniteBench |
| Hellaswag | MMLU | GSM8K | HumanEval | StructEval | QUALITY |
| Winogrande | Openbook QA | MATH-500 | MBPP | ZeroSCROLLS |
Languages & Domains
Subset of language-specific and domain-specific benchmarks coverd by eval-framework:
| Multilingual | Specialized | Safety & Bias | Efficiency Metrics |
|---|---|---|---|
| WMT Translation | MMLU | TruthfulQA | Compression ratios |
| FLORES-200 | Legal (CaseHold) | Winogender | Runtime |
| Multilingual MMLU | Scientific (SciQ) | ||
| German/Finnish tasks |
Completion
Tasks focused on logical reasoning, text distillation, instruction following, and output control. Examples include:
- AIME 2024: Logical Reasoning (Math)
- DUC Abstractive: Text Distillation (Extraction)
- Custom Data: Complaint Summarization: Text Distillation (Summarization)
Loglikelihoods
Tasks emphasizing classification, reasoning, and open QA. Examples include:
- Abstract Reasoning Challenge (ARC): Classification
- Casehold: Open QA
Long-Context
Tasks designed for long-context scenarios, including QA, summarization, and aggregation. Examples include:
- InfiniteBench_CodeDebug: Programming
- ZeroSCROLLS GovReport: QA (Government)
Metrics
Evaluation metrics include:
- Completion Metrics: Accuracy, Bleu, F1, Rouge
- Loglikelihood Metrics: Accuracy Loglikelihood, Probability Mass
- LLM Metrics: Chatbot Style Judge, Instruction Judge
- Efficiency Metrics: Bytes per Sequence Position
For the full list of tasks and metrics, see Detailed Task Table.
Getting Started
Understanding the Evaluation Framework
Eval-Framework provides a unified interface for evaluating language models across diverse benchmarks. The framework follows this interaction model:
- Define Your Model - Specify which model to evaluate (HuggingFace, API, or custom)
- Choose Your Task - Select from 150+ available benchmarks or create custom ones
- Configure Evaluation - Set parameters like few-shot examples, sample count, and output format
- Run Evaluation - Execute locally via CLI/script or distribute via Determined AI
- Analyze Results - Review detailed JSON outputs, metrics, and generated reports
Core Components
- Models: Defined via
BaseLLMinterface (HuggingFace, OpenAI, custom APIs) - Tasks: Inherit from
BaseTask(completion, loglikelihood, or LLM-judge based) - Metrics: Automatic scoring via
BaseMetricclasses - Formatters: Handle prompt construction and model-specific formatting
- Results: Structured outputs with sample-level details and aggregated statistics
Your First Evaluation
- Install the framework (see Quick Start above)
pip install eval_framework[transformers]
- Create and run your first evaluation using HuggingFace model:
from functools import partial
from pathlib import Path
from eval_framework.llm.huggingface import HFLLM
from eval_framework.main import main
from eval_framework.tasks.eval_config import EvalConfig
from template_formatting.formatter import HFFormatter
# Define your model
class MyHuggingFaceModel(HFLLM):
LLM_NAME = "microsoft/DialoGPT-medium"
DEFAULT_FORMATTER = partial(HFFormatter, "microsoft/DialoGPT-medium")
if __name__ == "__main__":
# Initialize your model
llm = MyHuggingFaceModel()
# Running evaluation on MMLU abstract algebra task using 5 few-shot examples and 10 samples
config = EvalConfig(
output_dir=Path("./eval_results"),
num_fewshot=5,
num_samples=10,
task_name="MMLU",
task_subjects=["abstract_algebra", "astronomy"],
llm_class=MyHuggingFaceModel,
)
# Run evaluation and get results
results = main(llm=llm, config=config)
- Review results - Check
./eval_results/for detailed outputs and use our results guide to interpret them
Next Steps
- Use CLI interface: See CLI usage guide for command-line evaluation options
- Evaluate HuggingFace models: Follow our HuggingFace evaluation guide
- Understand model arguments: Read out Model Arguments guide
- Create custom benchmarks: Follow our benchmark creation guide
- Scale your evaluations: Use Determined AI integration for distributed evaluation
- Understand your results: Read our results interpretation guide
- Log results in WandB: See how we integrate WandB for metric and lineage tracking
Documentation
Getting Started
- CLI Usage Guide - Detailed instructions for using the command-line interface
- Evaluating HuggingFace Models - Complete guide for evaluating HuggingFace models
- Understanding Results - How to read and interpret evaluation results
Advanced Usage
- Understanding Model Arguments - Thorough guide on each constructor argument for salient model classes
- Adding New Benchmarks - Complete guide with practical examples for adding new benchmarks
- Benchmarks and Metrics - Comprehensive overview of all available benchmarks and evaluation metrics
- Overview of Dataloading - Explanation of dataloading and task/sample/message structure
Scaling & Production
- Using Determined - Guide for distributed evaluation using Determined AI
- Controlling Upload Results - How to manage and control the upload of evaluation results
Contributing
- Contributing Guide - Guide for contributing to this project
- Testing - Guide for running tests comparable to the CI pipelines
Citation
If you use eval-framework in your research, please cite:
@software{eval_framework,
title={Aleph Alpha Eval Framework},
year={2025},
url={https://github.com/Aleph-Alpha-Research/eval-framework}
}
License
This project is licensed under the Apache License 2.0.
This project has received funding from the European Union’s Digital Europe Programme under grant agreement No. 101195233 (OpenEuroLLM).
The contents of this publication are the sole responsibility of the OpenEuroLLM consortium and do not necessarily reflect the opinion of the European Union.


Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file eval_framework-0.5.3.tar.gz.
File metadata
- Download URL: eval_framework-0.5.3.tar.gz
- Upload date:
- Size: 253.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f10edc75db128f0deb7b8e3c33725ffa275ad332ff1b3306eea4ca8c8587f9b6
|
|
| MD5 |
9f8ccc8290745e493cd5d1acd19a6864
|
|
| BLAKE2b-256 |
9ee3d3a3adde0e77be66579a02193ea9947f7d96cae906cb443ef7b1b591a268
|
Provenance
The following attestation bundles were made for eval_framework-0.5.3.tar.gz:
Publisher:
release.yml on Aleph-Alpha-Research/eval-framework
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
eval_framework-0.5.3.tar.gz -
Subject digest:
f10edc75db128f0deb7b8e3c33725ffa275ad332ff1b3306eea4ca8c8587f9b6 - Sigstore transparency entry: 2084406581
- Sigstore integration time:
-
Permalink:
Aleph-Alpha-Research/eval-framework@bca886fa8c29c259760a9f257e665bb4e11d2e33 -
Branch / Tag:
refs/tags/v0.5.3 - Owner: https://github.com/Aleph-Alpha-Research
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@bca886fa8c29c259760a9f257e665bb4e11d2e33 -
Trigger Event:
release
-
Statement type:
File details
Details for the file eval_framework-0.5.3-py3-none-any.whl.
File metadata
- Download URL: eval_framework-0.5.3-py3-none-any.whl
- Upload date:
- Size: 364.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
886ecbf69bb1a66490fe164ad240fed31c22fa7088c4181cfdb8a9e4f94ace4b
|
|
| MD5 |
9a34bc2dad116a9dee1293328a305542
|
|
| BLAKE2b-256 |
95ea6d79e73783c2f05bbde601a91ee0001d3268ef39bd277741d8bf833238f5
|
Provenance
The following attestation bundles were made for eval_framework-0.5.3-py3-none-any.whl:
Publisher:
release.yml on Aleph-Alpha-Research/eval-framework
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
eval_framework-0.5.3-py3-none-any.whl -
Subject digest:
886ecbf69bb1a66490fe164ad240fed31c22fa7088c4181cfdb8a9e4f94ace4b - Sigstore transparency entry: 2084406592
- Sigstore integration time:
-
Permalink:
Aleph-Alpha-Research/eval-framework@bca886fa8c29c259760a9f257e665bb4e11d2e33 -
Branch / Tag:
refs/tags/v0.5.3 - Owner: https://github.com/Aleph-Alpha-Research
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@bca886fa8c29c259760a9f257e665bb4e11d2e33 -
Trigger Event:
release
-
Statement type:







