EPO - Pytorch

Project description
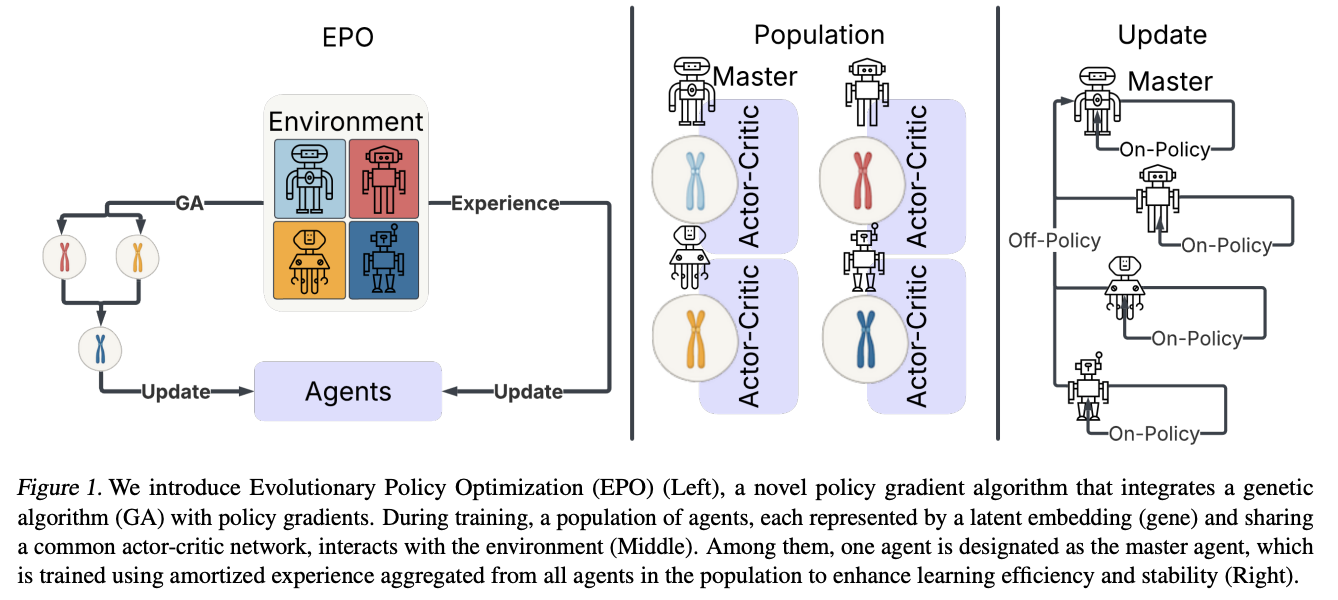
Evolutionary Policy Optimization
Pytorch implementation of Evolutionary Policy Optimization, from Wang et al. of the Robotics Institute at Carnegie Mellon University
This paper stands out, as I have witnessed the positive effects first hand in an exploratory project (mixing evolution with gradient based methods). Perhaps the Alexnet moment for genetic algorithms has not come to pass yet.
Besides their latent variable strategy, I'll also throw in some attempts with crossover in weight space
Install
$ pip install evolutionary-policy-optimization
Usage
import torch
from evolutionary_policy_optimization import (
LatentGenePool,
Actor,
Critic
)
latent_pool = LatentGenePool(
num_latents = 128,
dim_latent = 32,
)
state = torch.randn(1, 32)
actor = Actor(dim_state = 32, dim = 256, mlp_depth = 2, num_actions = 4, dim_latent = 32)
critic = Critic(dim_state = 32, dim = 256, mlp_depth = 3, dim_latent = 32)
latent = latent_pool(latent_id = 2)
actions = actor(state, latent)
value = critic(state, latent)
# interact with environment and receive rewards, termination etc
# derive a fitness score for each gene / latent
fitness = torch.randn(128)
latent_pool.genetic_algorithm_step(fitness) # update latent genes with genetic algorithm
End to end learning
import torch
from evolutionary_policy_optimization import (
create_agent,
EPO,
Env
)
agent = create_agent(
dim_state = 512,
num_latents = 16,
dim_latent = 32,
actor_num_actions = 5,
actor_dim = 256,
actor_mlp_depth = 2,
critic_dim = 256,
critic_mlp_depth = 3,
latent_gene_pool_kwargs = dict(
frac_natural_selected = 0.5
)
)
epo = EPO(
agent,
episodes_per_latent = 1,
max_episode_length = 10,
action_sample_temperature = 1.
)
env = Env((512,))
epo(agent, env, num_learning_cycles = 5)
# saving and loading
agent.save('./agent.pt', overwrite = True)
agent.load('./agent.pt')
Train Gym
An example training script for LunarLander-v3 is provided at train_gym.py
First install example dependencies
$ pip install '.[examples]' # or `uv pip install '.[examples]'`
Single process
$ python train_gym.py --cpu
Distributed with 8 processes (one latent per process)
$ torchrun --nproc_per_node=8 train_gym.py --cpu
With wandb logging
$ torchrun --nproc_per_node=8 train_gym.py --cpu --use_wandb
Contributing
At the project root, run
$ pip install '.[test]' # or `uv pip install '.[test]'`
Then add your tests to tests/test_epo.py and run
$ pytest tests/
That's it
Citations
@inproceedings{Wang2025EvolutionaryPO,
title = {Evolutionary Policy Optimization},
author = {Jianren Wang and Yifan Su and Abhinav Gupta and Deepak Pathak},
year = {2025},
url = {https://api.semanticscholar.org/CorpusID:277313729}
}
@article{Farebrother2024StopRT,
title = {Stop Regressing: Training Value Functions via Classification for Scalable Deep RL},
author = {Jesse Farebrother and Jordi Orbay and Quan Ho Vuong and Adrien Ali Taiga and Yevgen Chebotar and Ted Xiao and Alex Irpan and Sergey Levine and Pablo Samuel Castro and Aleksandra Faust and Aviral Kumar and Rishabh Agarwal},
journal = {ArXiv},
year = {2024},
volume = {abs/2403.03950},
url = {https://api.semanticscholar.org/CorpusID:268253088}
}
@inproceedings{Khadka2018EvolutionGuidedPG,
title = {Evolution-Guided Policy Gradient in Reinforcement Learning},
author = {Shauharda Khadka and Kagan Tumer},
booktitle = {Neural Information Processing Systems},
year = {2018},
url = {https://api.semanticscholar.org/CorpusID:53096951}
}
@article{Fortunato2017NoisyNF,
title = {Noisy Networks for Exploration},
author = {Meire Fortunato and Mohammad Gheshlaghi Azar and Bilal Piot and Jacob Menick and Ian Osband and Alex Graves and Vlad Mnih and R{\'e}mi Munos and Demis Hassabis and Olivier Pietquin and Charles Blundell and Shane Legg},
journal = {ArXiv},
year = {2017},
volume = {abs/1706.10295},
url = {https://api.semanticscholar.org/CorpusID:5176587}
}
@article{Banerjee2022BoostingEI,
title = {Boosting Exploration in Actor-Critic Algorithms by Incentivizing Plausible Novel States},
author = {Chayan Banerjee and Zhiyong Chen and Nasimul Noman},
journal = {2023 62nd IEEE Conference on Decision and Control (CDC)},
year = {2022},
pages = {7009-7014},
url = {https://api.semanticscholar.org/CorpusID:252682944}
}
@article{Doerr2017FastGA,
title = {Fast genetic algorithms},
author = {Benjamin Doerr and Huu Phuoc Le and R{\'e}gis Makhmara and Ta Duy Nguyen},
journal = {Proceedings of the Genetic and Evolutionary Computation Conference},
year = {2017},
url = {https://api.semanticscholar.org/CorpusID:16196841}
}
@article{Lee2024AnalysisClippedCritic
title = {On Analysis of Clipped Critic Loss in Proximal Policy Gradient},
author = {Yongjin Lee, Moonyoung Chung},
journal = {Authorea},
year = {2024}
}
@article{Ash2019OnTD,
title = {On the Difficulty of Warm-Starting Neural Network Training},
author = {Jordan T. Ash and Ryan P. Adams},
journal = {ArXiv},
year = {2019},
volume = {abs/1910.08475},
url = {https://api.semanticscholar.org/CorpusID:204788802}
}
@inproceedings{Gerasimov2025YouDN,
title = {You Do Not Fully Utilize Transformer's Representation Capacity},
author = {Gleb Gerasimov and Yaroslav Aksenov and Nikita Balagansky and Viacheslav Sinii and Daniil Gavrilov},
year = {2025},
url = {https://api.semanticscholar.org/CorpusID:276317819}
}
@article{Lee2024SimBaSB,
title = {SimBa: Simplicity Bias for Scaling Up Parameters in Deep Reinforcement Learning},
author = {Hojoon Lee and Dongyoon Hwang and Donghu Kim and Hyunseung Kim and Jun Jet Tai and Kaushik Subramanian and Peter R. Wurman and Jaegul Choo and Peter Stone and Takuma Seno},
journal = {ArXiv},
year = {2024},
volume = {abs/2410.09754},
url = {https://api.semanticscholar.org/CorpusID:273346233}
}
@article{Karras2019stylegan2,
title = {Analyzing and Improving the Image Quality of {StyleGAN}},
author = {Tero Karras and Samuli Laine and Miika Aittala and Janne Hellsten and Jaakko Lehtinen and Timo Aila},
journal = {CoRR},
volume = {abs/1912.04958},
year = {2019},
}
@article{Chebykin2023ShrinkPerturbIA,
title = {Shrink-Perturb Improves Architecture Mixing during Population Based Training for Neural Architecture Search},
author = {Alexander Chebykin and Arkadiy Dushatskiy and Tanja Alderliesten and Peter A. N. Bosman},
journal = {ArXiv},
year = {2023},
volume = {abs/2307.15621},
url = {https://api.semanticscholar.org/CorpusID:260316291}
}
@article{Jiang2022GeneralIR,
title = {General intelligence requires rethinking exploration},
author = {Minqi Jiang and Tim Rocktaschel and Edward Grefenstette},
journal = {Royal Society Open Science},
year = {2022},
volume = {10},
url = {https://api.semanticscholar.org/CorpusID:253523156}
}
@misc{xie2025simplepolicyoptimization,
title = {Simple Policy Optimization},
author = {Zhengpeng Xie and Qiang Zhang and Fan Yang and Marco Hutter and Renjing Xu},
year = {2025},
eprint = {2401.16025},
archivePrefix = {arXiv},
primaryClass = {cs.LG},
url = {https://arxiv.org/abs/2401.16025},
}
@inproceedings{Nisioti2025WhenDN,
title = {When Does Neuroevolution Outcompete Reinforcement Learning in Transfer Learning Tasks?},
author = {Eleni Nisioti and Joachim Winther Pedersen and Erwan Plantec and Milton L. Montero and Sebastian Risi},
booktitle = {Annual Conference on Genetic and Evolutionary Computation},
year = {2025},
url = {https://api.semanticscholar.org/CorpusID:278995766}
}
@article{Eysenbach2018DiversityIA,
title = {Diversity is All You Need: Learning Skills without a Reward Function},
author = {Benjamin Eysenbach and Abhishek Gupta and Julian Ibarz and Sergey Levine},
journal = {ArXiv},
year = {2018},
volume = {abs/1802.06070},
url = {https://arxiv.org/abs/1802.06070}
url = {https://arxiv.org/abs/2602.16863},
@article{Zhu2025Hybrid,
author = {Zhu, Zimo and Yu, Chuanqiang and Wang, Junti},
title = {A Hybrid Genetic Algorithm and Proximal Policy Optimization System for Efficient Multi-Agent Task Allocation},
journal = {Systems},
volume = {13},
year = {2025},
number = {6},
article-number = {453},
url = {https://www.mdpi.com/2079-8954/13/6/453},
issn = {2079-8954}
@misc{kedia2026simtoolrealobjectcentricpolicyzeroshot,
title = {SimToolReal: An Object-Centric Policy for Zero-Shot Dexterous Tool Manipulation},
author = {Kushal Kedia and Tyler Ga Wei Lum and Jeannette Bohg and C. Karen Liu},
year = {2026},
eprint = {2602.16863},
archivePrefix = {arXiv},
primaryClass = {cs.RO},
url = {https://arxiv.org/abs/2602.16863},
}
Evolution is cleverer than you are. - Leslie Orgel
Project details
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file evolutionary_policy_optimization-0.2.20.tar.gz.
File metadata
- Download URL: evolutionary_policy_optimization-0.2.20.tar.gz
- Upload date:
- Size: 24.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.8.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
52d534492d06676ee65235a00c13217470279fa39271746c4ad1908e0c53c30a
|
|
| MD5 |
f31a59ef93c255d9cdd05fb31b2a4bc4
|
|
| BLAKE2b-256 |
26a507f3633440809010f76b679b815af612ff40da962a7a5728510927a2f60c
|
File details
Details for the file evolutionary_policy_optimization-0.2.20-py3-none-any.whl.
File metadata
- Download URL: evolutionary_policy_optimization-0.2.20-py3-none-any.whl
- Upload date:
- Size: 26.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.8.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ce2fdc1859db765b59ebbe3a14355d335f5206ec343536ec3f73be39c8a490c8
|
|
| MD5 |
5a68a66d21da4745c9fa5c9410f50f61
|
|
| BLAKE2b-256 |
4b1cdd4b551059924414fb464d92c617895aa71544b7c450565329fa8f59820a
|







