Face search engine: register photos, identify people from camera/video/images. 100% recall at 96x less memory than HNSW. No GPU needed.

Project description
⚡ FaceFlash
FaceFlash searches 1M faces in 61 MB of RAM. HNSW needs 2.9 GB, USearch needs 2.5 GB, FAISS needs 1.9 GB — for the same 100% recall.
FaceFlash is a Rust face search engine with Python bindings, built on PCA+ITQ binary quantization — a learned hash that preserves identity information with zero recall loss and no separate training phase.
- 100% Recall@1, 48–96× less memory. On the MS1MV2 benchmark (44,291 identities), FaceFlash held 100% Recall@1 at every scale from 100K to 1M while using 48× less index memory than HNSWLIB at the default 512-bit config (~42× vs USearch, ~32× vs FAISS-Flat) — and 96× less at the 256-bit compact config (100% recall, ~2× single-query latency).
- Faster than HNSW at 100K. On the same benchmark, FaceFlash single-query latency was 0.30ms vs HNSWLIB's 0.60ms (2× faster). Batched throughput: 27,661 qps vs 5,813 qps (4.8× faster). Both at 100% recall.
- AVX-512 VPOPCNTDQ + NEON. Hand-written SIMD kernels process one 512-bit face code per instruction (~3× faster than scalar). Multi-core batched search measured at 10–17× throughput vs single-query serial on the same hardware.
- Zero-config indexing. Add faces, they're indexed — PCA fits automatically after 1,024 samples, no hyperparameter tuning, no rebuilds as the gallery grows.
- Pure local. No managed service, no data leaving your machine. Pair with any ArcFace model for a fully air-gapped face search stack.




from faceflash import FaceFlash
ff = FaceFlash()
ff.register_folder("employees/") # bulk enroll
ff.save("my_index/")
result = ff.search("visitor.jpg")
# {"matches": [{"name": "Alice", "confidence": 0.92}], "search_time_ms": 0.4}
The Problem
Most face search libraries force a trade-off:
- HNSW is fast and accurate — but consumes 2.9 GB of RAM at 1M faces
- ScaNN / USearch are blazing fast — but drop to 94–99% recall
- FAISS-Flat is exact — but is 10× slower at scale
FaceFlash breaks this trade-off. It compresses each face into a 64-byte binary fingerprint using PCA + ITQ quantization, scans them with a single AVX-512 VPOPCNTDQ instruction, then re-ranks only the top candidates with exact cosine similarity. The result: exact accuracy at a fraction of the memory.
At a Glance
| FaceFlash | HNSWLIB | USearch | ScaNN | FAISS-Flat | |
|---|---|---|---|---|---|
| Recall@1 | 100% | 100% | 99.5% | 98.3% | 100% |
| Memory @ 100K | 3.05 MB | 293 MB | 254 MB | 12 MB | 195 MB |
| Memory @ 500K | 15.3 MB | 1,465 MB | 1,270 MB | 61 MB | 977 MB |
| Memory @ 1M | 30.5 MB | 2,930 MB | 2,539 MB | 122 MB | 1,953 MB |
| Latency @ 100K | 0.30ms | 0.60ms | 0.17ms | 0.10ms | 4.90ms |
| Batched QPS @ 100K | 27,661 | 5,813 | 137,264 | — | — |
| Index build | Auto (PCA fit) | Build graph | Build graph | Partition | None |
Tested on MS1MV2 (44,291 identities, 645,019 embeddings). Hardware: AMD EPYC 9355, 128 threads, AVX-512 active.
Memory = binary index only. Float vectors for cosine reranking are mmap'd from disk after
save()/load()— only ~100 candidate rows are paged per query. See Limitations.
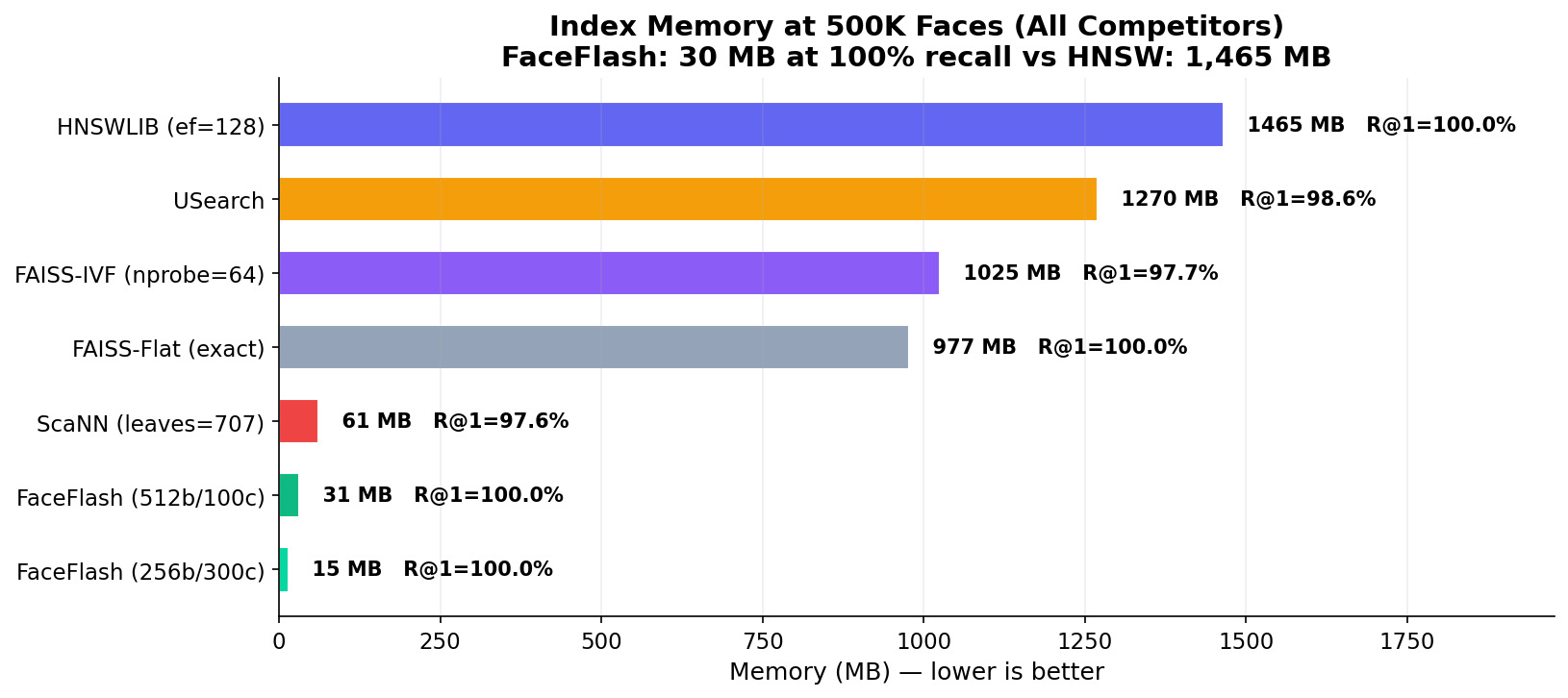
Index Memory at 500K Faces (256-bit compact config): FaceFlash (15 MB) vs HNSW (1,465 MB) — 96× less RAM at 100% recall

Install
pip install "faceflash[cpu] @ git+https://github.com/raghavenderreddygrudhanti/faceflash.git"
# With benchmark dependencies
pip install "faceflash[cpu,benchmark] @ git+https://github.com/raghavenderreddygrudhanti/faceflash.git"
Requires a Rust toolchain — it compiles the AVX-512/NEON backend automatically and falls back to NumPy if unavailable.
Quick Start
from faceflash import FaceFlash
ff = FaceFlash() # downloads ArcFace model (~166 MB) on first run
# Register individual faces
ff.register("Alice", "alice.jpg")
ff.register("Bob", "bob.jpg")
# Identify a face
result = ff.search("query.jpg")
# {"matches": [{"name": "Alice", "confidence": 0.92}], "search_time_ms": 0.4}
# Verify two faces are the same person
ff.verify("photo1.jpg", "photo2.jpg")
# {"match": True, "confidence": 0.87}
# Bulk enroll from folder (expects folder/person_name/photo.jpg)
ff.register_folder("employees/")
ff.save("my_index/")
ff.load("my_index/")
# Manage the index
len(ff) # how many faces are registered
"Alice" in ff # is this person registered?
ff.names() # list registered people
ff.remove("Alice") # unregister a person (returns count removed)
For best accuracy, use pre-aligned 112x112 face crops. 5-point alignment (SCRFD/RetinaFace) adds +1.28 accuracy points over a basic center-crop.
Gallery Management
from faceflash import FaceFlash
ff = FaceFlash()
ff.register("Alice", "alice.jpg")
ff.register("Bob", "bob.jpg")
ff.register("Alice", "alice2.jpg") # multiple photos per person
# Check gallery state
len(ff) # 3 (total face entries)
ff.names() # ["Alice", "Bob"]
"Alice" in ff # True
"Charlie" in ff # False
# Remove a person (GDPR / right-to-be-forgotten)
ff.remove("Bob") # removes all entries for Bob
len(ff) # 2
ff.names() # ["Alice"]
# Monitor index stats
ff.stats()
# {'count': 2, 'pca_fitted': True, 'rust_backend': True,
# 'binary_memory_mb': 0.0, 'resident_memory_mb': 0.0, ...}
Batch Identification
Process many query faces at once (4.8x faster than one-by-one):
import numpy as np
from faceflash import FaceFlash
ff = FaceFlash()
ff.register_folder("gallery/")
ff.save("my_index/")
# Low-level batch search (for bulk dedup, watchlists, video frames)
embeddings = np.load("query_embeddings.npy") # (N, 512) float32
results = ff.index.search_batch(embeddings, k=1)
# results[i] = [(name, similarity, index), ...]
# Example: find all matches above threshold
for i, matches in enumerate(results):
if matches and matches[0][1] > 0.5:
print(f"Query {i}: {matches[0][0]} (confidence {matches[0][1]:.2f})")
Is FaceFlash Right for You?
| Scenario | Why FaceFlash wins |
|---|---|
| Edge / mobile / IoT | 3–30 MB vs 293–2,930 MB for HNSW — fits in device RAM |
| Multi-tenant servers | 100 galleries x 30 MB = 3 GB. HNSW: 100 x 1.5 GB = 150 GB |
| Batch dedup / watchlists | 4.8x faster than HNSW batched at 100K; 1.9x at 500K |
| 100% recall is non-negotiable | FaceFlash hits 100% at every scale; USearch drops to 94-99% |
| Budget / offline / air-gapped | Runs on Raspberry Pi, cheap VPS, phones — no GPU, no network |
| 10K-500K face databases | The sweet spot: faster AND less memory than HNSW |
When HNSW is the better choice:
- You need <0.3ms single-query latency at >500K faces and have gigabytes of RAM to spare
- Your database exceeds 2M faces (HNSW's O(log N) pulls clearly ahead)
- You need 100K+ batched QPS regardless of memory (USearch wins there)
How It Works
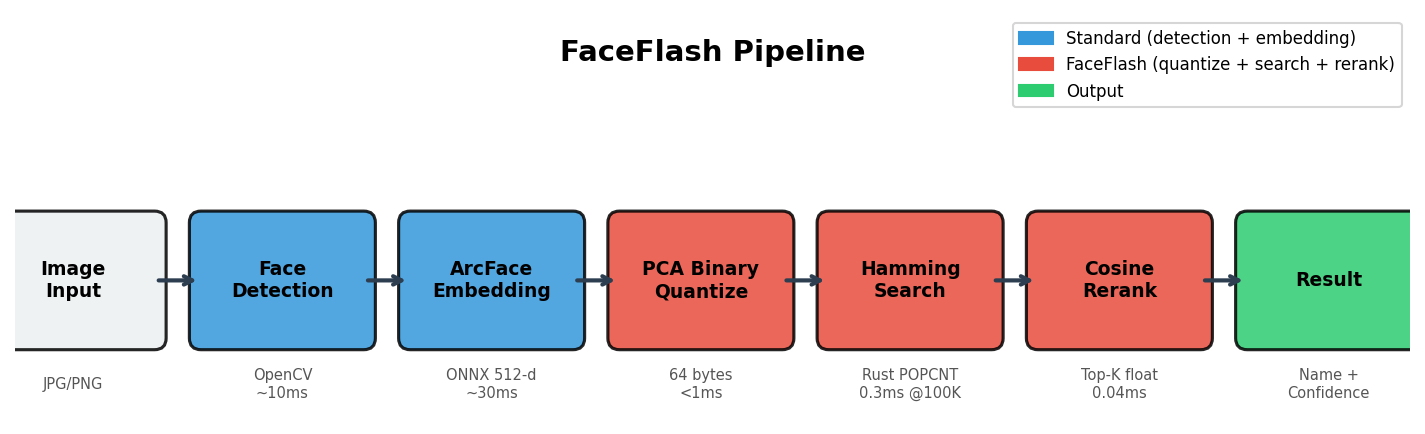
Each face is compressed into a 64-byte binary fingerprint:
- ArcFace extracts a 512-dimensional float embedding
- PCA aligns the quantization with the axes where identity varies most
- ITQ rotates bits to maximize information per bit (balanced marginals)
- AVX-512 VPOPCNTDQ scans all binary codes in a single instruction per face
- Cosine rerank runs exact similarity on only the top ~100 candidates
This is why 512 bits is the fastest setting — the entire code fits in one AVX-512 register.
Benchmark Methodology
FaceFlash's recall, latency, throughput, and memory are measured. Competitor recall and latency are also measured; competitor memory is estimated from the standard vectors + index-structure overhead formula (e.g. HNSW ≈ 1.5× raw vectors).
| Details | |
|---|---|
| Dataset | MS1MV2 — 645,019 ArcFace embeddings, 44,291 distinct identities |
| Embedding | ArcFace ONNX (w600k_r50), 512 dimensions, L2-normalized |
| Hardware | AMD EPYC 9355 (32 cores / 128 threads), AVX-512 VPOPCNTDQ enabled |
| Competitors | HNSWLIB 0.8+, FAISS 1.7+, USearch 2.x, ScaNN (latest) |
| Ground truth | Exact brute-force cosine argmax (FAISS-Flat) |
| Timing | time.perf_counter() per query, 10 warmup excluded |
| Recall metric | Recall@1 — fraction of queries where the true nearest neighbor is rank-1 |
| Memory metric | FaceFlash: measured binary index size in RAM (floats mmap'd after save/load). Competitors: estimated (vectors + index-structure overhead) |
| Batched timing | Wall-clock for the full query batch / number of queries |
| Reproducibility | bash scripts/runpod_ms1m.sh reproduces all results end-to-end |
All single-query rows are single-threaded. Batched rows use all available cores. Every benchmark script validates correctness before reporting speed.
Performance
Scale Summary (100K-1M)
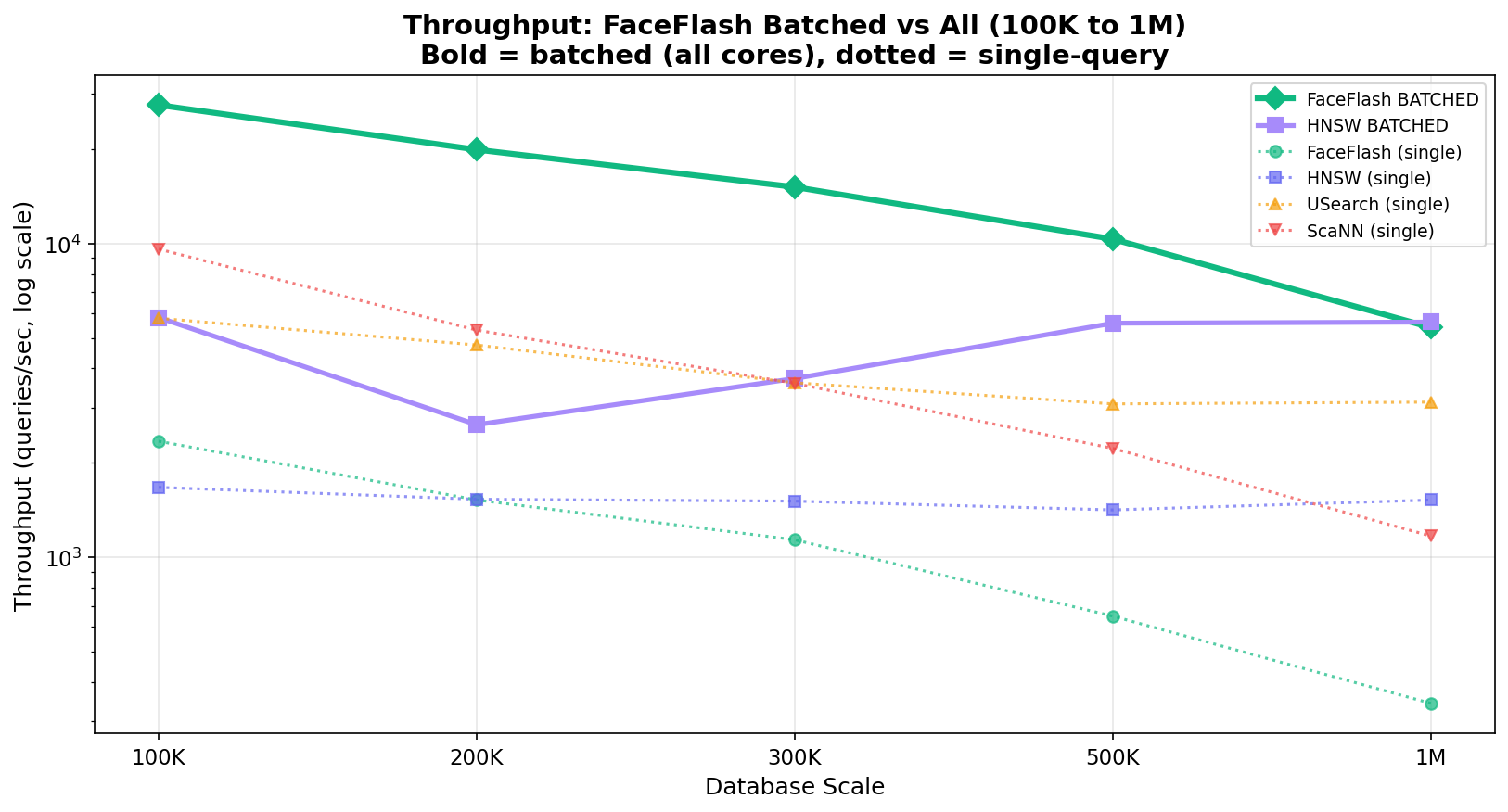
Batched Throughput (QPS): FaceFlash 100K→1M — 4.8× faster than HNSW at 100K
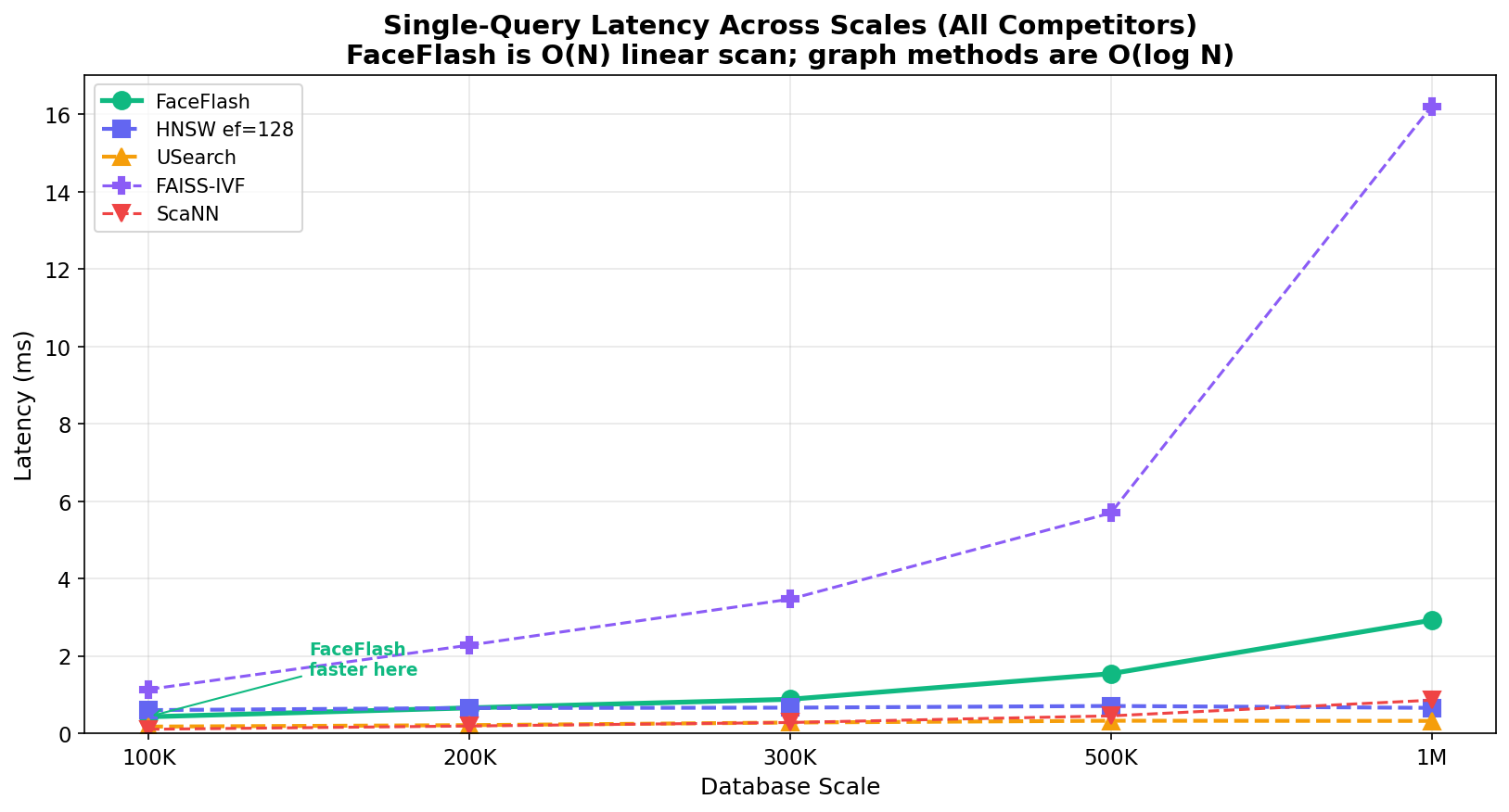
Single-Query Latency: FaceFlash 0.30ms vs HNSW 0.60ms at 100K — both at 100% recall
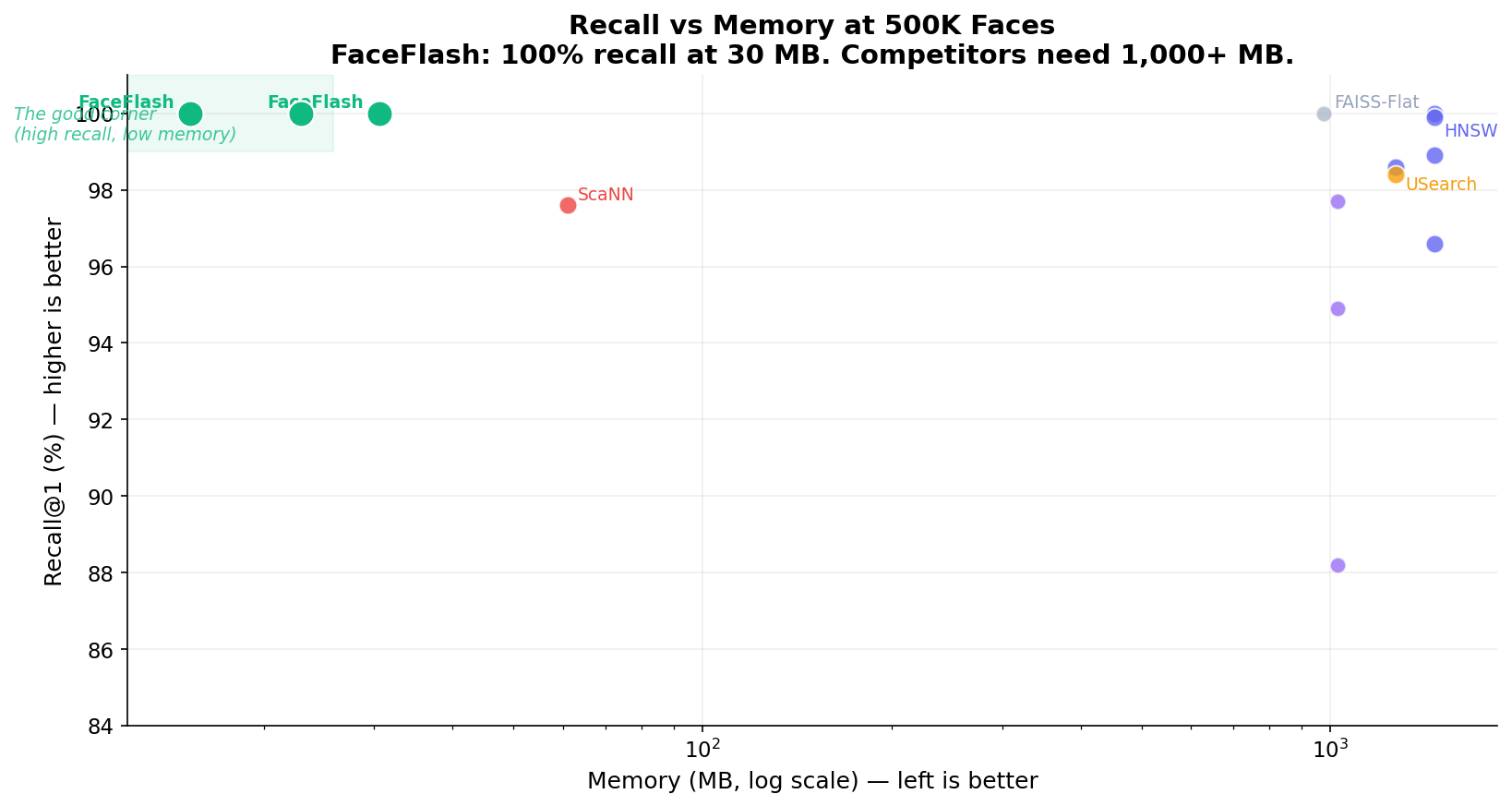
Recall vs Memory Pareto: FaceFlash sits at the frontier — 100% recall, 30 MB
| Scale | Recall | Single-query | Batched QPS | Memory | vs HNSW memory |
|---|---|---|---|---|---|
| 100K | 100% | 0.30ms (2× faster than HNSW) | 27,661 | 6.1 MB | 48× less |
| 200K | 100% | 0.57ms (tied with HNSW) | 19,930 | 12.2 MB | 48× less |
| 300K | 100% | 0.84ms | 15,147 | 18.3 MB | 48× less |
| 500K | 100% | 1.45ms | 10,337 | 30.5 MB | 48× less |
| 1M | 100% | 2.95ms | 5,403 | 61 MB | 48× less |
Numbers are the default 512-bit config (fastest, 100% recall). The 256-bit compact config holds 100% recall at half the memory — 96× less than HNSW — trading ~2× single-query latency.
FaceFlash dominates up to 300K on every axis. At 500K-1M, HNSW edges ahead on single-query latency (O(log N) vs O(N)), but FaceFlash still wins on batched throughput and always uses 48–96× less memory.
1:N Identification - 44,290 Distinct People
The hardest test: one photo per person in the gallery, identify them from a different photo.
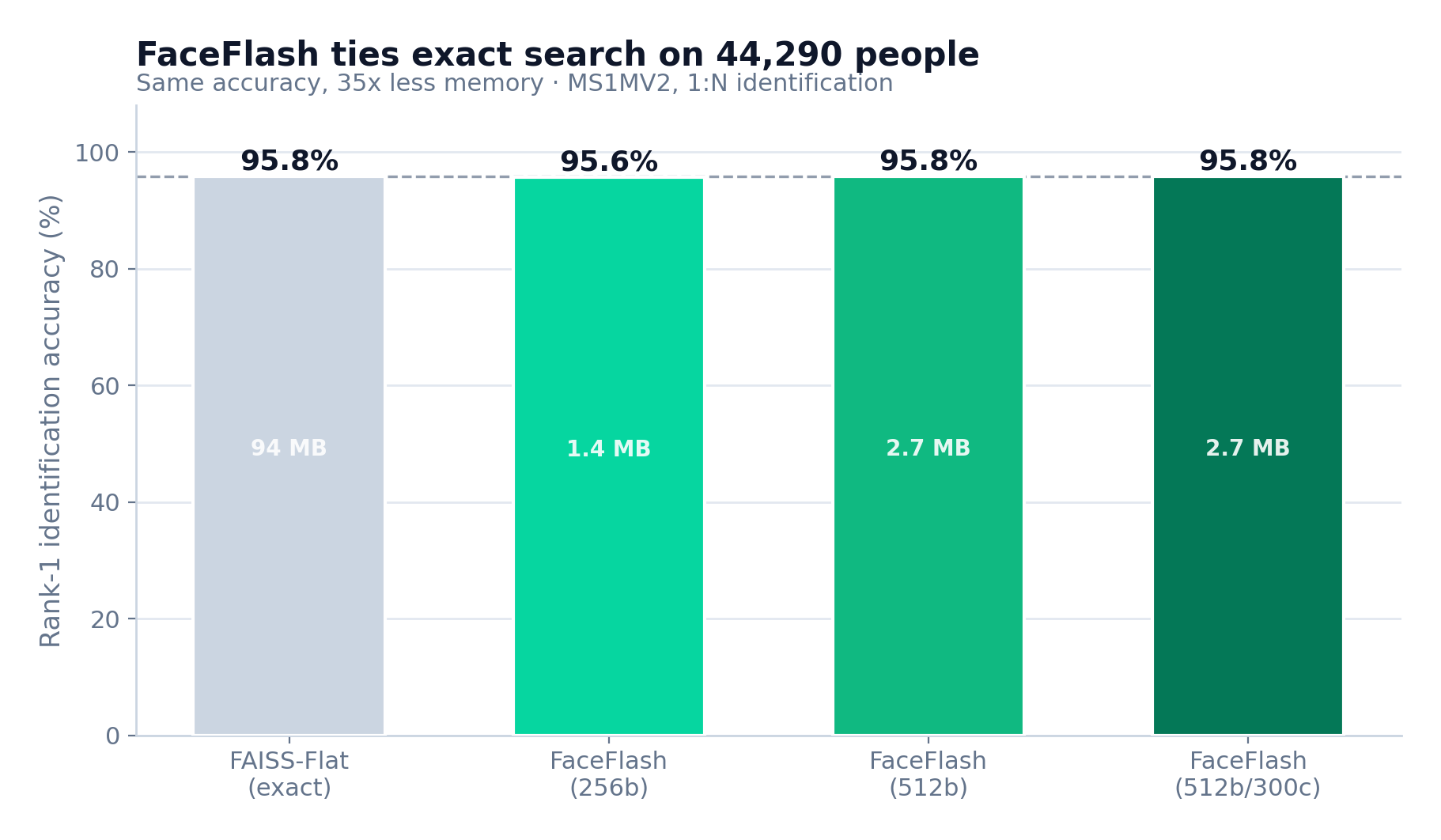
1:N Identification on 44,290 Identities: FaceFlash matches FAISS-Flat accuracy at 32× less memory
| Method | Rank-1 Accuracy | Memory |
|---|---|---|
| FAISS-Flat (exact ceiling) | 95.8% | 86.5 MB |
| FaceFlash (512b / 100c) | 95.8% | 2.70 MB |
| FaceFlash (512b / 300c) | 95.8% | 2.70 MB |
| FaceFlash (256b / 100c) | 95.6% | 1.35 MB |
FaceFlash ties exact search using 32× less memory (512 float32 → 512 bits = exactly 32× compression). Binary quantization is lossless at 512 bits.
Detailed per-scale benchmark tables
100K Faces (6,939 identities)
| Method | Recall@1 | Latency | QPS | Memory |
|---|---|---|---|---|
| FaceFlash (batched) | 100% | 0.036ms | 27,661 | 6.1 MB |
| FaceFlash (512b/200c) | 100% | 0.30ms | 3,310 | 6.1 MB |
| FaceFlash (512b/100c) | 100% | 0.43ms | 2,344 | 6.1 MB |
| HNSWLIB (ef=128) | 100% | 0.60ms | 1,671 | 293 MB |
| HNSWLIB batched | 100% | 0.172ms | 5,813 | 293 MB |
| USearch batched | 99.5% | 0.007ms | 137,264 | 254 MB |
| USearch | 99.5% | 0.17ms | -- | 254 MB |
| ScaNN | 98.3% | 0.10ms | -- | 12 MB |
| FAISS-Flat (exact) | 100% | 4.90ms | 204 | 195 MB |
200K Faces (13,749 identities)
| Method | Recall@1 | Latency | QPS | Memory |
|---|---|---|---|---|
| FaceFlash (batched) | 100% | 0.050ms | 19,930 | 12.2 MB |
| FaceFlash (512b/200c) | 100% | 0.57ms | 1,751 | 12.2 MB |
| HNSWLIB (ef=128) | 99.9% | 0.65ms | 1,531 | 586 MB |
| HNSWLIB batched | 99.9% | 0.378ms | 2,646 | 586 MB |
| USearch batched | 99.1% | 0.008ms | 121,660 | 508 MB |
| ScaNN | 97.2% | 0.19ms | -- | 24 MB |
300K Faces (20,615 identities)
| Method | Recall@1 | Latency | QPS | Memory |
|---|---|---|---|---|
| FaceFlash (batched) | 100% | 0.066ms | 15,147 | 18.3 MB |
| FaceFlash (512b/200c) | 100% | 0.84ms | 1,187 | 18.3 MB |
| HNSWLIB (ef=128) | 99.9% | 0.66ms | 1,510 | 879 MB |
| HNSWLIB batched | 99.7% | 0.269ms | 3,715 | 879 MB |
| USearch batched | 98.7% | 0.014ms | 73,383 | 762 MB |
| ScaNN | 97.8% | 0.28ms | -- | 37 MB |
500K Faces (34,328 identities)
| Method | Recall@1 | Latency | QPS | Memory |
|---|---|---|---|---|
| FaceFlash (batched) | 100% | 0.097ms | 10,337 | 30.5 MB |
| FaceFlash (512b/200c) | 100% | 1.45ms | 692 | 30.5 MB |
| HNSWLIB (ef=128) | 100% | 0.71ms | 1,416 | 1,465 MB |
| HNSWLIB batched | 99.9% | 0.179ms | 5,577 | 1,465 MB |
| USearch batched | 98.4% | 0.013ms | 76,150 | 1,270 MB |
| ScaNN | 97.6% | 0.45ms | -- | 61 MB |
1M Faces (44,291 identities)
| Method | Recall@1 | Latency | QPS | Memory |
|---|---|---|---|---|
| FaceFlash (batched) | 100% | 0.185ms | 5,403 | 61 MB |
| FaceFlash (512b/100c) | 100% | 2.92ms | 342 | 61 MB |
| HNSWLIB (ef=128) | 100% | 0.66ms | 1,523 | 2,930 MB |
| HNSWLIB batched | 100% | 0.178ms | 5,621 | 2,930 MB |
| USearch batched | 94.1% | 0.013ms | 77,266 | 2,539 MB |
| ScaNN | 98.2% | 0.86ms | -- | 122 MB |
Tuning
Pick a config that matches your deployment:
| Deployment | Config | Recall@1 | Memory/face | Notes |
|---|---|---|---|---|
| Ultra-compact (mobile/IoT) | n_bits=128, n_candidates=500 | 99.4% | 16 bytes | Minimum RAM |
| Balanced | n_bits=256, n_candidates=100 | 100% | 32 bytes | Good default |
| Default (fastest) | n_bits=512, n_candidates=100 | 100% | 64 bytes | One AVX-512 instruction |
| Edge (minimize disk reads) | n_bits=512, n_candidates=50 | 99.5% | 64 bytes | -- |
ff = FaceFlash(n_bits=128, n_candidates=500) # mobile/IoT
ff = FaceFlash(n_bits=256, n_candidates=100) # balanced
ff = FaceFlash(n_bits=512, n_candidates=100) # default: fastest
ff.search("query.jpg", n_candidates=200) # per-query override
Speed up large indexes with clustering
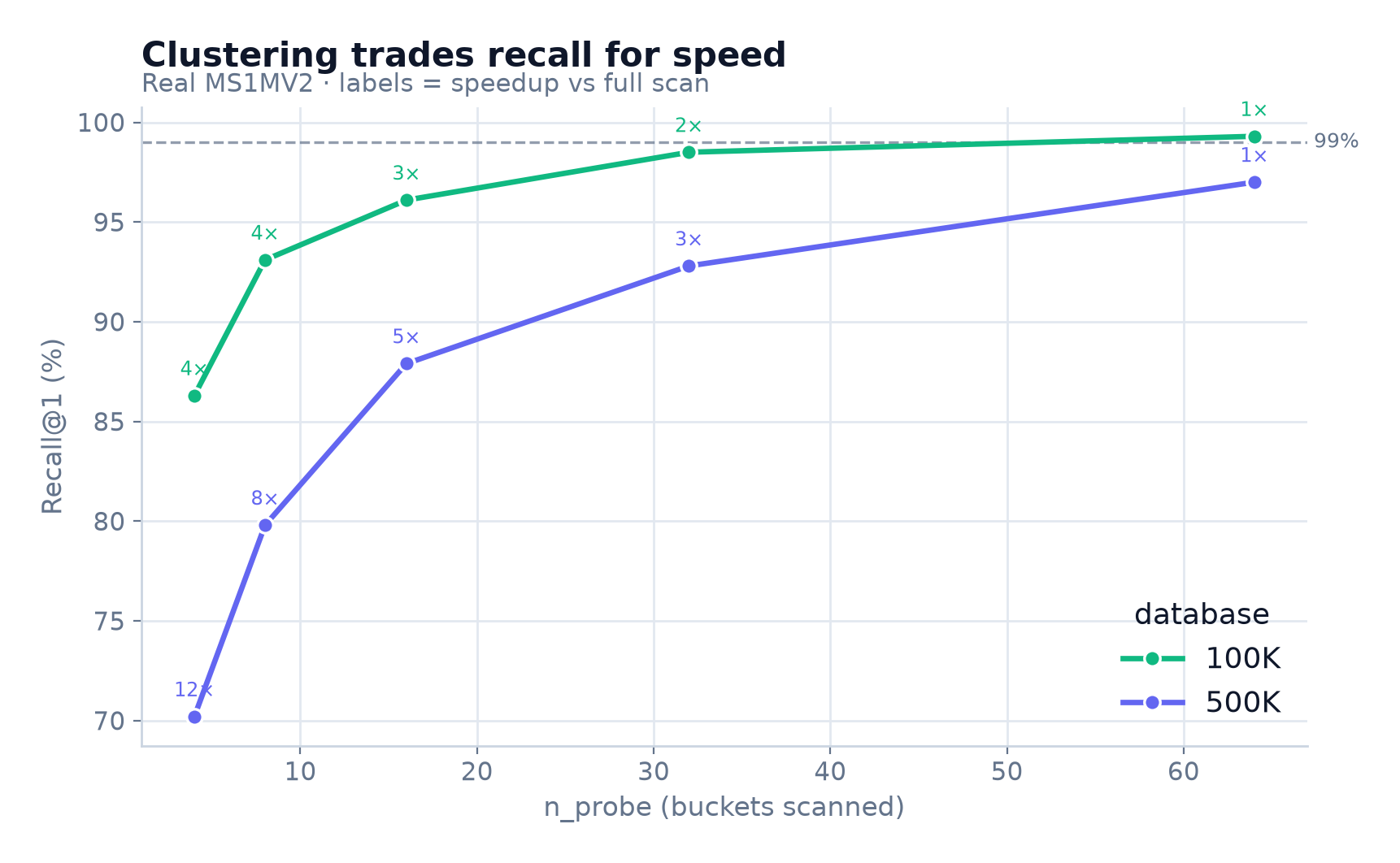
IVF Clustering Speedup: 5–8× faster at 500K+ with configurable recall trade-off
ff.index.build_clusters(n_probe=16)
| Scale | n_probe | Recall@1 | Latency | Speedup |
|---|---|---|---|---|
| 100K | 16 | 96.1% | 0.12ms | 2.6x |
| 100K | 32 | 98.5% | 0.17ms | 1.8x |
| 500K | 16 | 87.9% | 0.31ms | 5.0x |
| 500K | 32 | 92.8% | 0.56ms | 2.8x |
Clustering is mainly useful at 500K+ where it delivers 5-8x speedup at ~88-93% recall.
Architecture
faceflash/ # Python package
├── engine.py ◀─ High-level API (register, search, verify)
├── detect.py ◀─ Face detection (SCRFD + Haar fallback)
├── align.py ◀─ 5-point alignment to ArcFace template
├── embed.py ◀─ ArcFace ONNX embedding (512-dim, auto-download)
├── index.py ◀─ Binary index + batched search
└── pca_quantize.py ◀─ PCA+ITQ quantizer (the core algorithm)
rust/ # Rust backend (PyO3 + Rayon)
├── src/lib.rs ◀─ AVX-512 VPOPCNTDQ / NEON / scalar POPCNT
└── Cargo.toml
Why PCA+ITQ? ArcFace embeddings concentrate identity information along principal axes. PCA aligns quantization with those axes; ITQ rotates bits for balanced marginals. The result is lossless compression at 512 bits.
Why not HNSW internally? HNSW stores a graph on top of full float vectors — about 1.5x raw memory. FaceFlash stores 32–64 bytes per face. Float vectors are memory-mapped from disk and paged only for the top ~100 candidates per query. Trade-off: higher single-query latency at 500K+, but 48–96× less memory.
Why Rust + AVX-512? AVX-512 VPOPCNTDQ processes an entire 512-bit code in one instruction (~3× faster than scalar POPCNT). Combined with Rayon multi-core parallelism (and cache-blocked batching to keep the scan cache-friendly), batched search reaches 10-17× throughput versus single-query serial. Runtime-detected — no user configuration needed.
Limitations
- Single-query at 1M+ — O(N) linear scan; HNSW is 4.4x faster per single query at 1M. Batched path ties.
- Memory during build — holds all float vectors in RAM. The 48–96× savings apply after
save()/load(). - AVX-512 VPOPCNTDQ — the ~3× kernel speedup requires Ice Lake / Zen 4+ / EPYC 9004+. Older CPUs fall back to scalar POPCNT automatically.
- Rerank I/O — pages ~100 float rows from disk per query. Invisible on NVMe; adds latency on slow storage.
Reproduce the Benchmarks
# Local (LFW + VGGFace2 100K)
python scripts/extract_lfw_embeddings.py
python benchmarks/bench_ann_comparison.py --scales 100K --queries 500
# RunPod (full suite)
export GITHUB_TOKEN=<token>
bash scripts/runpod_ms1m.sh # FORCE_EXTRACT=1 for full 85K extraction
Roadmap
v0.1.0 (current)
- PCA+ITQ binary quantization + Rust search backend
- High-level API: register, search, verify
- Benchmarked against FAISS, HNSWLIB, USearch, ScaNN at 100K-1M
- 1:N identification on 44,290 distinct identities (MS1MV2)
- 5-point alignment via SCRFD/RetinaFace — 99.85% LFW accuracy
v0.2.0 (done)
- Prebuilt wheels (
pip install faceflash) - Full 85K-identity benchmark (76,872 identities extracted, 44,291 with sufficient data)
- On-device memory measurement (3.05 MB binary index @100K with 256b)
v0.3.0 (done)
- IVF coarse clustering (2.7-4.9x speedup at scale)
- AVX-512 VPOPCNTDQ — native 512-bit popcount (~3x faster than scalar)
- Batched search — 17x throughput at 500K-1M (multi-core + VPOPCNTDQ; cache-blocked)
- NEON kernels — ARM-optimized (vcntq_u8)
v1.0.0 — next
- Stable public API (no breaking changes)
- DiskANN comparison
- Mobile deployment (ONNX + CoreML)
- Streaming insertion (add faces without refitting PCA)
Contributing
# Dev setup (one command)
git clone https://github.com/raghavenderreddygrudhanti/faceflash.git
cd faceflash && python -m venv .venv && source .venv/bin/activate
pip install -e ".[cpu,benchmark]" && maturin develop --release
python -m pytest tests/ # 33 tests, ~17s
Open areas for contribution:
| Area | Difficulty | Impact |
|---|---|---|
| DiskANN comparison | Medium | High — the one competitor missing |
| Mobile deployment (ONNX + CoreML) | Medium | High — iOS/Android face search |
| Streaming insertion (no PCA refit) | Hard | High — online learning |
| GPU batched search (CUDA) | Hard | Medium — 10M+ galleries |
| Raspberry Pi / Jetson benchmarks | Easy | Medium — edge credibility |
| WebAssembly build | Medium | Medium — browser face search |
See CONTRIBUTING.md for coding guidelines.
Credits & References
FaceFlash does not introduce a new embedding model or hashing algorithm. It combines proven, published techniques into a CPU-efficient retrieval system — with hand-written Rust AVX-512/NEON kernels, cache-blocked batching, and rigorous, reproducible benchmarks. The contribution is the system (exact-recall face search in a megabyte-scale footprint) and the honest measurement of it, not the underlying math.
It builds directly on:
| Component | Reference |
|---|---|
| Binary quantization (PCA + ITQ — the core method) | Gong & Lazebnik, "Iterative Quantization: A Procrustean Approach to Learning Binary Codes," CVPR 2011 |
| Face embeddings | Deng, Guo, Xue & Zafeiriou, "ArcFace: Additive Angular Margin Loss for Deep Face Recognition," CVPR 2019 — weights from InsightFace |
| Detection & 5-point alignment | RetinaFace (CVPR 2020) / SCRFD (ICLR 2022), InsightFace |
| Dataset | Guo et al., "MS-Celeb-1M," ECCV 2016 (MS1MV2 = ArcFace's refined/cleaned version) |
| Verification benchmark | Huang et al., "Labeled Faces in the Wild (LFW)," UMass TR 2007 |
| Baselines compared | FAISS (Johnson et al.), HNSW (Malkov & Yashunin, TPAMI 2018), ScaNN (Guo et al., ICML 2020), USearch |
PCA dates to Pearson (1901) / Hotelling (1933); the Hamming distance to Hamming (1950); POPCNT / VPOPCNTDQ are Intel/AMD hardware instructions. FaceFlash's value is in how these are combined and implemented — not in inventing them.
License
MIT — see LICENSE.
If FaceFlash is useful to you, a star helps others find it.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file faceflash-0.1.1.tar.gz.
File metadata
- Download URL: faceflash-0.1.1.tar.gz
- Upload date:
- Size: 33.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.14.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8561c6d2c10eb1154a9ecdcd73fc1b6cd0b910317e74bc4dbedd9f59f648da2d
|
|
| MD5 |
371e5edc237cfd91bb82a5041e789fe6
|
|
| BLAKE2b-256 |
ac95d25e8a0dbcd726ca92f0b2683e87a68994b681ed32bfff8c00ab67cb03dd
|
File details
Details for the file faceflash-0.1.1-cp313-cp313-win_amd64.whl.
File metadata
- Download URL: faceflash-0.1.1-cp313-cp313-win_amd64.whl
- Upload date:
- Size: 214.4 kB
- Tags: CPython 3.13, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.14.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
fcbb8930f38cb9c3ff0db6fef57f5418995f285de10a486331090487259c58d3
|
|
| MD5 |
ae1c894f8a92d3df3021bf068c30250a
|
|
| BLAKE2b-256 |
02b3c0d72bcccbafe69e7595b46c97215e53b4f7afccd892286c6ebed9115110
|
File details
Details for the file faceflash-0.1.1-cp313-cp313-manylinux_2_34_x86_64.whl.
File metadata
- Download URL: faceflash-0.1.1-cp313-cp313-manylinux_2_34_x86_64.whl
- Upload date:
- Size: 338.2 kB
- Tags: CPython 3.13, manylinux: glibc 2.34+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.14.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d2966b5d1bd6aa28b377536f126344b239899ad6363e401e57db0a7beda0a692
|
|
| MD5 |
2253cb4de1a3ce197a05e1ca20e6b623
|
|
| BLAKE2b-256 |
d8b6f559cbc2246238166e446c2b1e248ce150ca93a004061d6ad835a60f1e41
|
File details
Details for the file faceflash-0.1.1-cp313-cp313-macosx_11_0_arm64.whl.
File metadata
- Download URL: faceflash-0.1.1-cp313-cp313-macosx_11_0_arm64.whl
- Upload date:
- Size: 297.2 kB
- Tags: CPython 3.13, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.14.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
512b1010adacf219ddf099a24b855e6b1dd52f868a58fa3057e5c415a37c632d
|
|
| MD5 |
0cb709b5593db0d88664deb346b41c34
|
|
| BLAKE2b-256 |
ceddeca923f42cd9b125f1fe658d9b1a650df255e3fdd82a4f1324c71c044f21
|
File details
Details for the file faceflash-0.1.1-cp312-cp312-win_amd64.whl.
File metadata
- Download URL: faceflash-0.1.1-cp312-cp312-win_amd64.whl
- Upload date:
- Size: 214.8 kB
- Tags: CPython 3.12, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.14.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
fd1b1168f3a2d9367b9b05f86ec9b64751ebef2c50a6cf89fd16f4192759a799
|
|
| MD5 |
c90ec400649bfcb3310e7f6139acbe7e
|
|
| BLAKE2b-256 |
d876cd29cdeacefea37eb321c30cc7c4c6d321bafee7886fda3d2d5a57c053af
|
File details
Details for the file faceflash-0.1.1-cp312-cp312-manylinux_2_34_x86_64.whl.
File metadata
- Download URL: faceflash-0.1.1-cp312-cp312-manylinux_2_34_x86_64.whl
- Upload date:
- Size: 338.8 kB
- Tags: CPython 3.12, manylinux: glibc 2.34+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.14.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a590b4c675cffa597d9af9435e4f2a3726ccf1b0290254acbe4f2102764878e8
|
|
| MD5 |
f30619b3dd65acf56bd90d78aa090738
|
|
| BLAKE2b-256 |
1005b1e6b0b5e247f8aa7bb486cfeffcbb8baae982eaaa1d024a9ce58b79c05c
|
File details
Details for the file faceflash-0.1.1-cp312-cp312-macosx_11_0_arm64.whl.
File metadata
- Download URL: faceflash-0.1.1-cp312-cp312-macosx_11_0_arm64.whl
- Upload date:
- Size: 297.7 kB
- Tags: CPython 3.12, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.14.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0709d3273c702ded7933e775d142fd82b6b347be1bfbf0708f897ce4471f92fd
|
|
| MD5 |
e250504a9a5682273c09c44cb5c552c8
|
|
| BLAKE2b-256 |
22bd92db46f5b0b4d36091e182f031fb9f16e630d61b3308e039f394bb67a665
|
File details
Details for the file faceflash-0.1.1-cp311-cp311-win_amd64.whl.
File metadata
- Download URL: faceflash-0.1.1-cp311-cp311-win_amd64.whl
- Upload date:
- Size: 213.8 kB
- Tags: CPython 3.11, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.14.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
08b648346eedd20be93ad37d8c34ccf1030b9d8bb2008c2bd5d29300f235f83b
|
|
| MD5 |
02a30f8b275c08c6b7477ba30f52472e
|
|
| BLAKE2b-256 |
79c78a0864e65216691f779b61788a41ed993da058ae5d5c854979b5593efe03
|
File details
Details for the file faceflash-0.1.1-cp311-cp311-manylinux_2_34_x86_64.whl.
File metadata
- Download URL: faceflash-0.1.1-cp311-cp311-manylinux_2_34_x86_64.whl
- Upload date:
- Size: 338.0 kB
- Tags: CPython 3.11, manylinux: glibc 2.34+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.14.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1b389d67c92f3fd92dcb3719623850ec6ea9681e38fe2476092d0cdc5c8d9c3f
|
|
| MD5 |
0f6ba9c4ba4c5e538d8a38bfb3d71d42
|
|
| BLAKE2b-256 |
de97e954660c46135efd9979e2484786c323fcd495bb71aece1ca6300e4b32e6
|
File details
Details for the file faceflash-0.1.1-cp311-cp311-macosx_11_0_arm64.whl.
File metadata
- Download URL: faceflash-0.1.1-cp311-cp311-macosx_11_0_arm64.whl
- Upload date:
- Size: 297.7 kB
- Tags: CPython 3.11, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.14.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6532f3f5689fea603729857afadfc248d9912445efd647fefc0bb76e3ce066e8
|
|
| MD5 |
1c5db9f6b66f1b0bde4cb51634f4442d
|
|
| BLAKE2b-256 |
3ad59b8c2aebde47c244db887bb6c91ea21662e1e3a5bb998ac66d22ebe3522e
|
File details
Details for the file faceflash-0.1.1-cp310-cp310-win_amd64.whl.
File metadata
- Download URL: faceflash-0.1.1-cp310-cp310-win_amd64.whl
- Upload date:
- Size: 214.0 kB
- Tags: CPython 3.10, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.14.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
edb87d5ec31585526a79168842fb588b8b67c428e5b2a9861cf5609cd8ca8fc7
|
|
| MD5 |
4331496ac41d296f3c0a79d68104cb83
|
|
| BLAKE2b-256 |
e08755e0e26227783340d54a05f76884a5039702cc2279b1836e4aade063c7b9
|
File details
Details for the file faceflash-0.1.1-cp310-cp310-manylinux_2_34_x86_64.whl.
File metadata
- Download URL: faceflash-0.1.1-cp310-cp310-manylinux_2_34_x86_64.whl
- Upload date:
- Size: 338.2 kB
- Tags: CPython 3.10, manylinux: glibc 2.34+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.14.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6d83e88aa554cd4956aff9ff69748dc3c0dd827097521dfcce0afb89f35c6478
|
|
| MD5 |
a87a63e3a6dc248ceff5095d9f4464b3
|
|
| BLAKE2b-256 |
93f582c3532f18c63982288ce15ce6ffd0507b22d68df320dc690e3101c4ddea
|
File details
Details for the file faceflash-0.1.1-cp310-cp310-macosx_11_0_arm64.whl.
File metadata
- Download URL: faceflash-0.1.1-cp310-cp310-macosx_11_0_arm64.whl
- Upload date:
- Size: 297.8 kB
- Tags: CPython 3.10, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? No
- Uploaded via: maturin/1.14.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
aabeeb908c44431d6c2b6a49e999184dea66d5d5d0c8b66a847ba5a4c4e9b831
|
|
| MD5 |
86557b21b5d098ba1dd25d1b7bcfd592
|
|
| BLAKE2b-256 |
a437efa8cd227f2daeda84d50ea25d3384f186bd2f38a85f90b7ff53be6b47ac
|







