This package learns fair decision tree classifiers which can then be bagged into fair random forests, following the scikit-learn API standards.

Project description
Fair tree classifier using strong demographic parity
Implementation of the algorithm proposed in:
Pereira Barata, A. et al. Fair tree classifier using strong demographic parity. Machine Learning (2023). [>>]
This package learns fair decision tree classifiers which can then be bagged into fair random forests, following the scikit-learn API standards.
When incorporating FairDecisionTreeClassifier or FairRandomForestClassifier objects into scikit-learn pipelines, use the fit_params={"z": z} parameter to pass the sensitive attribute(s) z
Installation
A)
pip install fair-trees
or
B)
git clone https://github.com/pereirabarataap/fair_tree_classifierpip install -r requirements.txt
Usage
from fair_trees import FairRandomForestClassifier as FRFC, load_datasets, sdp_score
datasets = load_datasets()
X = datasets["adult"]["X"]
y = datasets["adult"]["y"]
z = datasets["adult"]["z"]["gender"]
clf = FRFC(theta=0.5).fit(X,y,z)
y_prob = clf.predict_proba(X)[:,1]
print(sdp_score(z, y_prob))
Example
import numpy as np
import pandas as pd
import seaborn as sb
from tqdm.notebook import tqdm
from matplotlib import pyplot as plt
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import StratifiedKFold as SKF
from fair_trees import FairRandomForestClassifier as FRFC, sdp_score, load_datasets
datasets = load_datasets()
results_data = []
for dataset in tqdm(datasets):
X = datasets[dataset]["X"]
y = datasets[dataset]["y"]
z = datasets[dataset]["z"]
fold = 0
skf = SKF(n_splits=5, random_state=42, shuffle=True)
# ensuring stratified kfold w.r.t. y and z
splitter_y = pd.concat([y, z], axis=1).astype(str).apply(
lambda row:
row[y.name] + "".join([row[col] for col in z.columns]),
axis=1
).values
desc_i = f"dataset={dataset} | processing folds"
for train_idx, test_idx in tqdm(skf.split(X,splitter_y), desc=desc_i, leave=False):
X_train, X_test = X.loc[train_idx], X.loc[test_idx]
y_train, y_test = y.loc[train_idx], y.loc[test_idx]
z_train, z_test = z.loc[train_idx], z.loc[test_idx]
desc_j = f"fold={fold} | fitting thetas"
for theta in tqdm(np.linspace(0,1,11).round(1), desc=desc_j, leave=False):
clf = FRFC(
n_jobs=-1,
n_bins=256,
theta=theta,
max_depth=None,
bootstrap=True,
random_state=42,
n_estimators=500,
min_samples_leaf=1,
min_samples_split=2,
max_features="sqrt",
requires_data_processing=True
).fit(X_train, y_train, z_train)
y_prob = clf.predict_proba(X_test)[:,1]
auc = roc_auc_score(y_test, y_prob)
sdp_min = np.inf
for sens_att in z.columns:
if len(np.unique(z_test[sens_att]))==2:
sens_val = np.unique(z_test[sens_att])[0]
z_true = z_test[sens_att]==sens_val
sdp = sdp_score(z_true, y_prob)
if sdp < sdp_min:
sdp_min = sdp
else:
for sens_val in np.unique(z_test[sens_att]):
z_true = z_test[sens_att]==sens_val
sdp = sdp_score(z_true, y_prob)
if sdp < sdp_min:
sdp_min = sdp
data_row = [dataset, fold, theta, auc, sdp_min]
results_data.append(data_row)
fold += 1
results_df = pd.DataFrame(
data=results_data,
columns=["dataset", "fold", "theta", "performance", "fairness"]
)
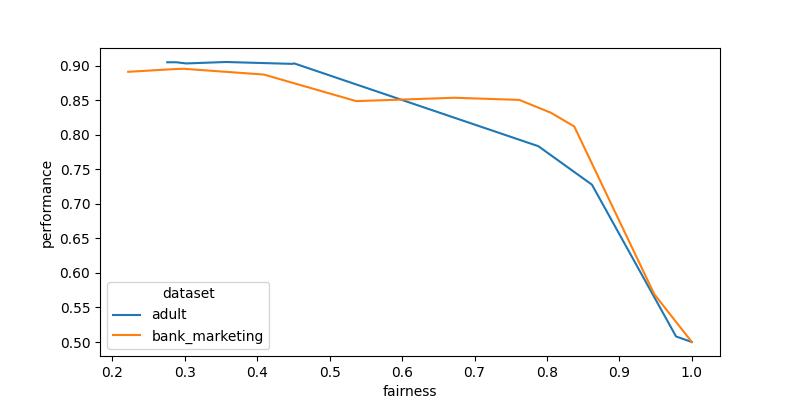
fig, ax = plt.subplots(1,1,dpi=100, figsize=(8,4))
sb.lineplot(
data=results_df.groupby(by=["dataset", "theta"]).mean(),
x="fairness",
y="performance",
hue="dataset",
ax=ax
)
plt.show()
3D Figures
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file fair_trees-2.6.6.tar.gz.
File metadata
- Download URL: fair_trees-2.6.6.tar.gz
- Upload date:
- Size: 1.4 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.12.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b6e4ee1332db2f6b6dd1c59c77ccd3ffc0a68b6c0751d0f4e18bf805df7665b3
|
|
| MD5 |
1ffbc0e87e1578a6b54806689ebf0e7d
|
|
| BLAKE2b-256 |
f442c622f03edb247a14f6bfe29cabff9768a0acfaaf11998568896cb27da8d5
|
File details
Details for the file fair_trees-2.6.6-py3-none-any.whl.
File metadata
- Download URL: fair_trees-2.6.6-py3-none-any.whl
- Upload date:
- Size: 1.4 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.12.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f805288121dff62c2ea805d656d89bf15482227b7426dc3ce4d58e3687fef0bf
|
|
| MD5 |
397472e247677c2cf692b13c66f032a1
|
|
| BLAKE2b-256 |
a76084aaf9e94ef956d4bc5fd200587b9956d685eb95fa0bf0e50341db33e38c
|







