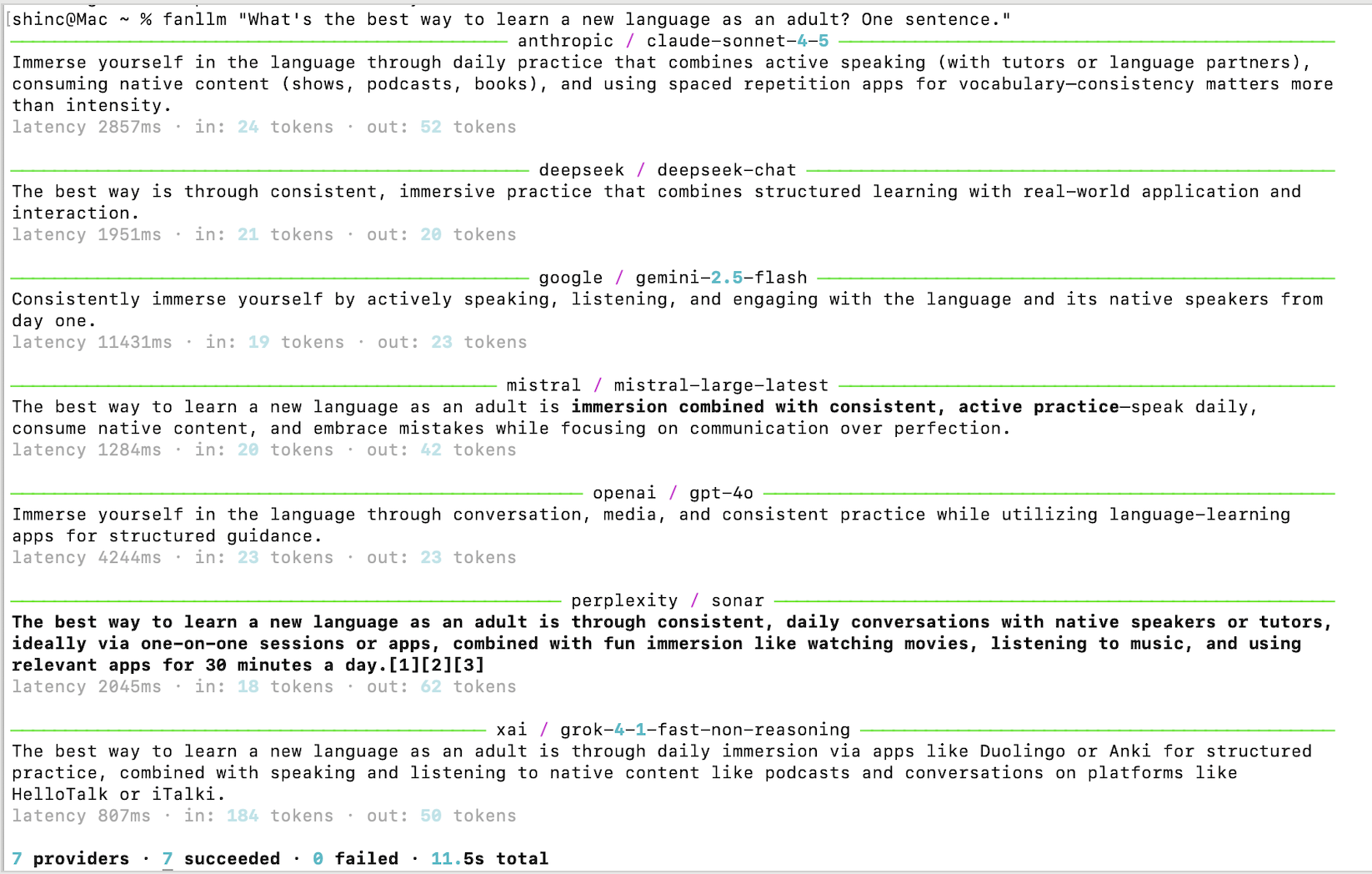
Fire one prompt at multiple LLMs in parallel, compare responses side by side.

Project description
fanllm


Fire one prompt at multiple LLMs in parallel. Compare responses side by side.
fanllm is a small Python library and CLI that sends the same prompt to seven hosted LLM providers concurrently and returns the results as structured objects. Use it when you want to see how different models actually respond to the same input. No router, no proxy, no framework — just the engine.
Why fanllm exists
LiteLLM and aisuite are unified wrappers: one call, one model, a consistent interface across providers. fanllm solves a different problem — it's a broadcaster. One call, many models, comparison built in. The codebase is roughly 600 lines across a handful of files, small enough to read in one sitting and fork rather than extend through a plugin system. If you want a unified client, use one of the tools above. If you want a systematic evaluation framework with assertions and batch runs, look at promptfoo. If you want to fan a prompt out to every major provider and see what comes back, this is that.
Supported providers
| Provider | Default Model | Environment Variable |
|---|---|---|
| OpenAI | gpt-4o | OPENAI_API_KEY |
| Anthropic | claude-sonnet-4-5 | ANTHROPIC_API_KEY |
| gemini-2.5-flash | GOOGLE_API_KEY | |
| Perplexity | sonar | PERPLEXITY_API_KEY |
| DeepSeek | deepseek-chat | DEEPSEEK_API_KEY |
| xAI | grok-4-1-fast-non-reasoning | XAI_API_KEY |
| Mistral | mistral-large-latest | MISTRAL_API_KEY |
Only providers whose API key is set will be called. Missing keys are skipped silently. A note on model defaults. The default model for each provider is chosen to be a sensible general-purpose option at a reasonable price point. Provider model IDs change over time — a model that's current today may be renamed or deprecated months from now. If you hit an error like HTTP 400 on a specific provider, check that provider's current model list and either open an issue or override the default via the models argument to run() (see the library quickstart below). fanllm deliberately does not maintain a catalogue of every model each provider offers; that's a scope choice to keep the tool small and readable.
Installation
bash pip install fanllm
Or, for development (clone and install in editable mode):
bash git clone https://github.com/yazararme/fanllm.git cd fanllm pip install -e .
Setup
Copy .env.example to .env and fill in the keys for the providers you want to use:
cp .env.example .env
OPENAI_API_KEY=sk-...
ANTHROPIC_API_KEY=sk-ant-...
GOOGLE_API_KEY=...
# Add keys for Perplexity, DeepSeek, xAI, or Mistral as needed
fanllm reads .env automatically on import via python-dotenv. You can also export the variables in your shell if you prefer.
Quickstart — CLI
fanllm "What's the most underrated programming language?"
Prints a formatted comparison with each provider's response, latency, and token usage, followed by a summary line showing total providers, successes, failures, and wall-clock time.
Common flags:
--models openai,anthropic— restrict to a subset of providers--system "You are..."— pass a system prompt--json— emit results as a JSON array instead of pretty-printing--timeout 60— per-provider timeout in seconds (default 90)
Quickstart — Library
import asyncio
import fanllm
async def main():
results = await fanllm.run("What's 2+2?")
for r in results:
print(f"{r.provider}: {r.response}")
asyncio.run(main())
Full signature of run():
async def run(
prompt: str,
*,
providers: list[str] | None = None, # subset of provider names; None = all with keys set
system_prompt: str | None = None, # optional system prompt
models: dict[str, str] | None = None, # override default model per provider, e.g. {"openai": "gpt-4o-mini"}
timeout: float = 90.0, # per-provider timeout in seconds
max_concurrency: int = 10, # cap on simultaneous in-flight requests
) -> list[LLMResult]
Each entry in the returned list is an LLMResult:
@dataclass
class LLMResult:
provider: str # provider name, e.g. "openai"
model: str # model actually used
response: str | None # the text response, or None on error
error: str | None # error string, or None on success
latency_ms: int # wall-clock latency for this call
input_tokens: int | None
output_tokens: int | None
Results are sorted by provider name. Failures do not raise — they come back as LLMResult entries with error set.
Non-goals
fanllm does not do the following:
- Streaming responses
- Tool / function calling
- Cost estimation — fanllm returns token counts; pricing math is out of scope because provider prices change and hardcoded tables go stale
- Response caching
- Retries beyond the built-in 3 attempts with exponential backoff
- Routing, fallback chains, or model selection logic — use OpenRouter or LiteLLM if you need these
- Local models (Ollama, llama.cpp) — fanllm targets hosted API providers only
- A catalogue of every model each provider offers — use the
modelsoverride for non-default models - A web UI — separate project
If you need these, fork fanllm — the codebase is small enough to modify easily — or use one of the unified-wrapper libraries linked above.
Design decisions
- Direct HTTP via httpx instead of provider SDKs. Keeps dependencies small and makes the wire behaviour transparent.
- One provider per file under
fanllm/providers/, each exposing the samecall()interface andDEFAULT_MODELconstant. - A single shared retry helper, not one per provider.
asyncio.gatherfor true parallelism; anasyncio.Semaphorecaps concurrency.LLMResultdataclass as the unified return shape. Errors are values, not exceptions.
Contributing
fanllm is a focused tool and its surface area is deliberately small. Bug reports and small fixes are welcome via GitHub issues and PRs. Feature requests that expand scope beyond the non-goals listed above will likely be declined — not because they're bad ideas, but because scope discipline is what keeps this tool readable. If you need those features, fork it.
License
MIT. See LICENSE.
Credits
Built by yazararme. Patterns inspired by adjacent tools including LiteLLM, aisuite, and promptfoo.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file fanllm-0.1.2.tar.gz.
File metadata
- Download URL: fanllm-0.1.2.tar.gz
- Upload date:
- Size: 669.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8c3e7bc9bf375903e3975bbb2aefd999f636637401a98bd62096871945e87d60
|
|
| MD5 |
a1ed1bb16c8d7c072ca1fbb8d7442f2d
|
|
| BLAKE2b-256 |
055d28a28d5b18b8bb843c0c5ed3033b6543b225d63dc552238d1a9cdcda2ce3
|
File details
Details for the file fanllm-0.1.2-py3-none-any.whl.
File metadata
- Download URL: fanllm-0.1.2-py3-none-any.whl
- Upload date:
- Size: 15.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bae403e3da1ccce89292b6b7892639d23edcba25dc94960590d4b86c3bcf1bc6
|
|
| MD5 |
d91b2e21c3e4afd8c9d0ea10112a858e
|
|
| BLAKE2b-256 |
3b5c9c5a70486d69b7943b30a9508be46a9cbbe497e985755965b17ddd2d2cde
|







