A Sci-Kit Learn compatible Numba and CUDA-accelerated implementation of various feature selection algorithms.

Project description
Fast-Select: Accelerated Feature Selection for Modern Datasets







A high-performance Python library powered by Numba and CUDA, offering accelerated algorithms for feature selection. Initially built to optimize the complete Relief family of algorithms, fast-select aims to expand and accelerate a wide range of feature selection methods to empower machine learning on large-scale datasets.
Key Features
-
Blazing Fast Performance: Leverages Numba for JIT compilation, Joblib for multi-core parallelism, and Numba CUDA for GPU acceleration, providing unmatched performance while scaling with modern hardware.
-
ML Pipeline Integration: Fully compatible with Scikit-Learn, making it easy to fit into any machine learning pipeline with a familiar
.fit(),.transform(),.fit_transform()interface. -
Flexible Backends: Offers dual execution modes for both CPU (
Joblib) and GPU (CUDA). Automatically detects hardware with an easy-to-usebackendparameter. -
Feature-Rich Implementation: Provides lightning-fast implementations of ReliefF, SURF, SURF*, MultiSURF, MultiSURF*, and TuRF—with plans to support additional feature selection algorithms in future releases.
-
Lightweight & Simple: Avoids heavy dependencies like TensorFlow or PyTorch while delivering state-of-the-art acceleration for feature selection workflows.
Table of Contents
- Installation
- Quickstart
- Backend Selection
- Benchmarking Highlights
- Algorithm Implementations
- Future Directions
- Contributing
- License
- How to Cite
- Acknowledgments
Installation
Install fast-select directly from PyPI:
pip install fast-select
For development versions (with testing and documentation dependencies):
git clone https://github.com/GavinLynch04/FastSelect.git
cd fast-select
pip install -e .[dev]
Quickstart
Using fast-select is simple and seamless for anyone familiar with Scikit-Learn.
from fast_select.estimators import MultiSURF
from sklearn.datasets import make_classification
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression # Example classifier
# 1. Generate a synthetic dataset
X, y = make_classification(
n_samples=500,
n_features=1000,
n_informative=20,
n_redundant=100,
random_state=42
)
# 2. Use the MultiSURF estimator to select the top 15 features
selector = MultiSURF(n_features_to_select=15)
X_selected = selector.fit_transform(X, y)
print(f"Original feature count: {X.shape[1]}")
print(f"Selected feature count: {X_selected.shape[1]}")
print(f"Top 15 feature indices: {selector.top_features_}")
# 3. Integrate into a Scikit-Learn Pipeline
pipeline = Pipeline([
('scaler', StandardScaler()),
('feature_selector', MultiSURF(n_features_to_select=10, backend='cpu')),
('classifier', LogisticRegression())
])
# Fit the pipeline (now featuring fast feature selection!)
# pipeline.fit(X, y)
Backend Selection (CPU vs. GPU)
You can control the computational backend with the backend parameter during initialization:
-
backend='auto': Automatically detects if an NVIDIA GPU is available. Falls back to CPU if a GPU is not available. -
backend='gpu': Explicitly runs on GPU. Will raise aRuntimeErrorif no compatible GPU is found. -
backend='cpu': Forces CPU computations, even if a GPU is available.
Example usage:
# Force CPU usage
cpu_selector = MultiSURF(n_features_to_select=10, backend='cpu')
# Force GPU usage
gpu_selector = MultiSURF(n_features_to_select=10, backend='gpu')
Benchmarking Highlights
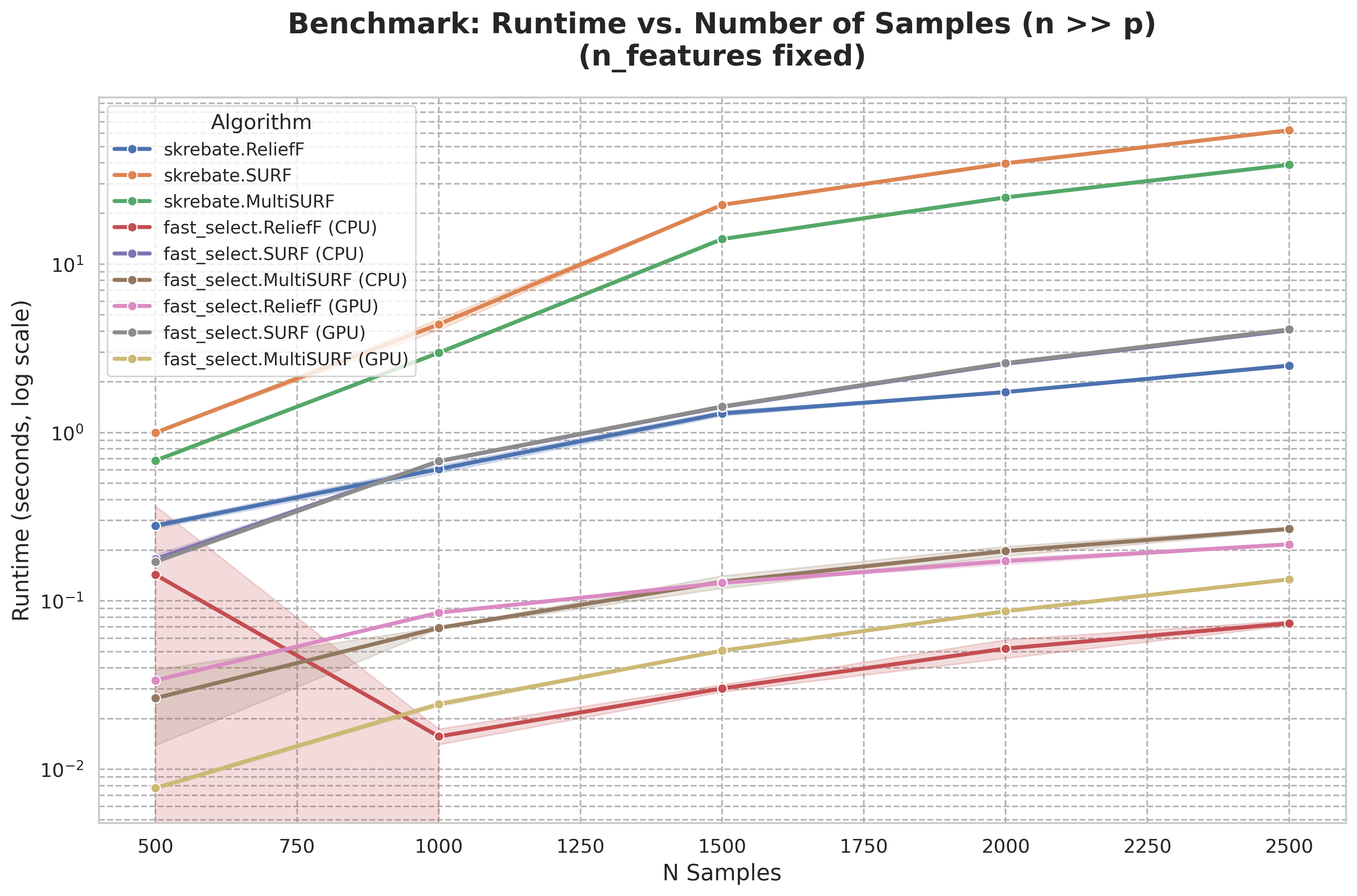
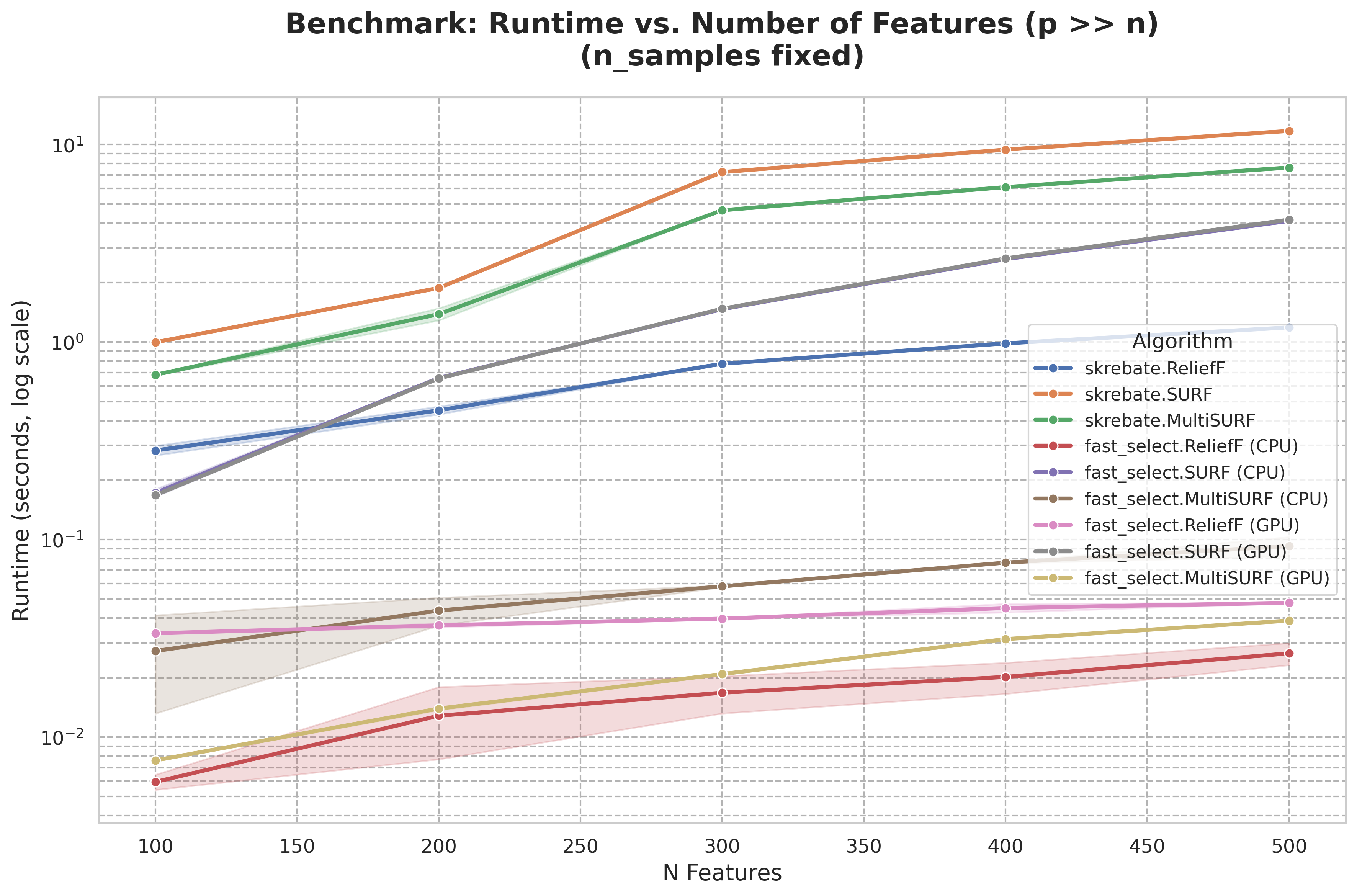
Fast-Select delivers groundbreaking improvements in runtime and memory efficiency. Benchmarks show 50-100x speed-ups compared to scikit-rebate and R's CORElearn library, particularly on large datasets exceeding 10,000 samples and features. Benchmarking scripts are available in the repository for further testing.
Runtime vs. Number of Samples (n >> p)
Runtime vs. Number of Features (p >> n)
Algorithm Implementations
Currently supported:
- Relief-Family Algorithms:
- ReliefF
- SURF
- SURF*
- MultiSURF
- MultiSURF*
- TuRF
Future plans include additional feature selection algorithms, such as wrappers, embedded methods, and more filter-based approaches.
Contributing
Contributions are highly encouraged. Whether you're fixing bugs, improving performance, or proposing new algorithms, your work is invaluable. Please ensure your submissions include relevant test cases and documentation updates.
License
This project is licensed under the MIT License. See the LICENSE file for full details.
Citing fast-select
If you use fast-select in your research or work, please cite it using the following DOI. This helps to track the impact of the work and ensures its continued development.
Gavin Lynch. (2025). GavinLynch04/FastSelect: v0.1.3 (0.1.3). Zenodo. https://doi.org/10.5281/zenodo.16285073
You can use the following BibTeX entry:
@software{gavin_lynch_2025,
author = {Gavin Lynch},
title = {{GavinLynch04/FastSelect: v0.1.3}},
month = jul,
year = 2025,
publisher = {Zenodo},
version = {0.1.3},
doi = {10.5281/zenodo.16285073},
url = {https://doi.org/10.5281/zenodo.16285073}
}
Acknowledgments
This library builds on the exceptional work of the following:
- The Numba team for enabling JIT compilation and GPU acceleration.
- The scikit-rebate authors for their inspiring Relief-based library.
- The original researchers behind the Relief algorithms for their foundational contributions to feature selection.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file fast_select-0.1.4.tar.gz.
File metadata
- Download URL: fast_select-0.1.4.tar.gz
- Upload date:
- Size: 22.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
20466cb4e92d6124f3514dfebc658b98b865a2b302d8a18616a302bac39ee4e4
|
|
| MD5 |
c243346a5c33b1af406360301ae6382f
|
|
| BLAKE2b-256 |
bc5a3a8bc6f6c77e6fb40e1c2271215423c30a0f0ad9e25e69d275f0b9a41c1f
|
File details
Details for the file fast_select-0.1.4-py3-none-any.whl.
File metadata
- Download URL: fast_select-0.1.4-py3-none-any.whl
- Upload date:
- Size: 20.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.10.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
45d097e2728783834af435f3d706a47b5fc7eb84833deea2ef455390d71208c2
|
|
| MD5 |
96fb05cf57bb77117c44993b8c18571d
|
|
| BLAKE2b-256 |
a1b8d5232cee5ea30091171f5b954740db0d11caec6e33034750adbbef177a81
|







