Query Utility for Elasticsearch

Project description
Query Helper for Elasticsearch or OpenSearch

This is a helper library for creating elasticsearch or opensearch query proxies using FastAPI.
from fastapi_elasticsearch import ElasticsearchAPIQueryBuilder
# Create a new query_builder for the endpoint.
query_builder = ElasticsearchAPIQueryBuilder()
# Decorate a function as a filter.
# The filter can declare parameters.
@query_builder.filter()
def filter_category(c: Optional[List[str]] = Query([],
description="Category name to filter results.")):
return {
"terms": {
"category": c
}
} if len(c) > 0 else None
# Then use the query_builder in your endpoint.
@app.get("/search")
async def search(
es: Elasticsearch = Depends(get_elasticsearch),
query_body: Dict = Depends(query_builder.build())) -> JSONResponse:
return es.search(
body=query_body,
index=index_name
)
The swagger API will result in:
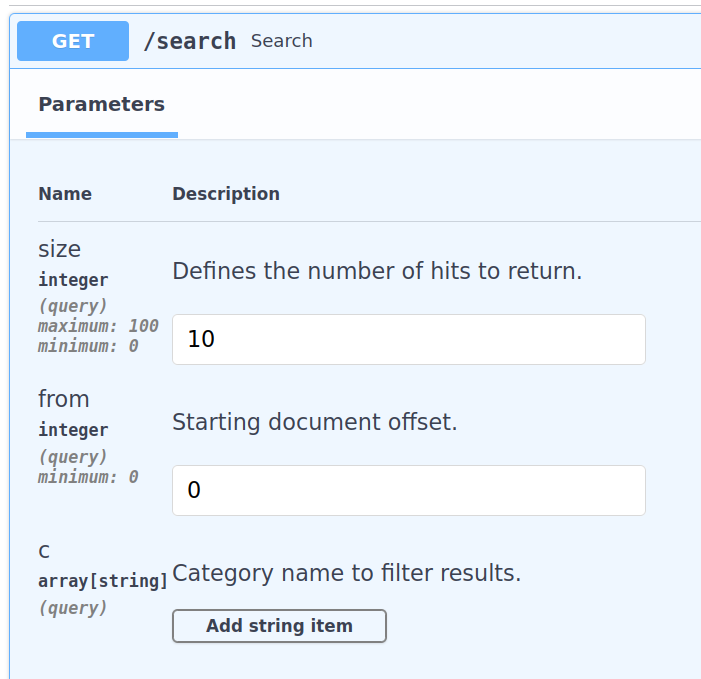
The resulting query will be like this:
{
"query": {
"bool": {
"filter": [
{
"terms": {
"category": [
"the-category"
]
}
}
]
}
},
"size": 10,
"from": 0
}
To use OpenSearch, simply change the client.
from fastapi_elasticsearch import ElasticsearchAPIQueryBuilder
from opensearchpy import OpenSearch
...
@app.get("/search")
async def search(
os: OpenSearch = Depends(get_opensearch),
query_body: Dict = Depends(query_builder.build())) -> JSONResponse:
return os.search(
body=query_body,
index=index_name
)
...
# Create a new query_builder for the endpoint.
query_builder = ElasticsearchAPIQueryBuilder()
To control the scoring use a matcher.
# Or decorate a function as a matcher
# (will contribute to the query scoring).
# Parameters can also be used.
@query_builder.matcher()
def match_fields(q: Optional[str] = Query(None)):
return {
"multi_match": {
"query": q,
"fuzziness": "AUTO",
"fields": [
"name^2",
"description"
]
}
} if q is not None else None
The swagger API will result in:
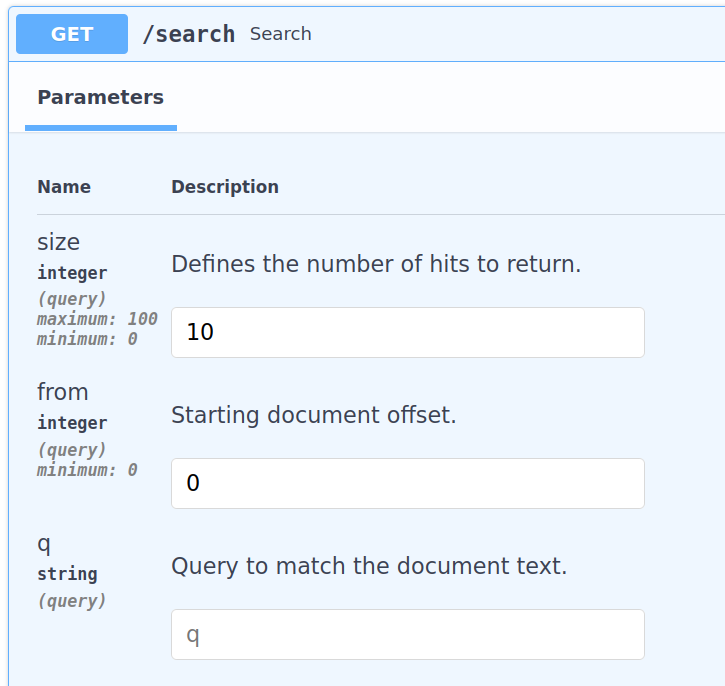
The resulting query will be like this:
{
"query": {
"bool": {
"should": [
{
"multi_match": {
"query": "bob",
"fuzziness": "AUTO",
"fields": [
"name^2",
"description"
]
}
}
],
"minimum_should_match": 1
}
},
"size": 10,
"from": 0
}
To control the ordering, it is possible to annotate a function as sorter.
class Direction(str, Enum):
asc = "asc"
desc = "desc"
# Decorate a function as a sorter.
# Parameters can be declared.
@query_builder.sorter()
def sort_by(direction: Optional[Direction] = Query(None)):
return {
"name": direction
} if direction is not None else None
The swagger API will result in:
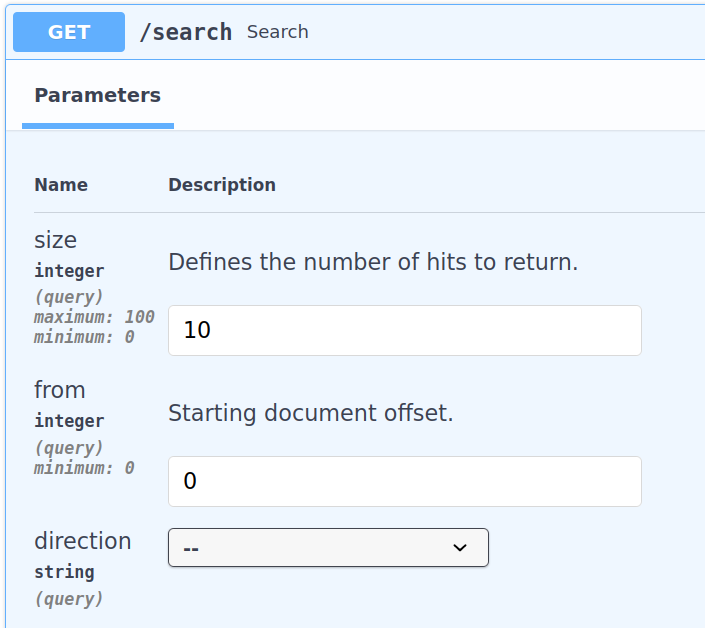
The resulting query will be like this:
{
"query": {
"match_all": {}
},
"size": 10,
"from": 0,
"sort": [
{
"name": "asc"
}
]
}
To add highlight functionality, it is possible to annotate a function as highlighter.
# Decorate a function as a highlighter.
# Parameters can also be declared.
@query_builder.highlighter()
def highlight(q: Optional[str] = Query(None,
description="Query to match the document text."),
h: bool = Query(False,
description="Highlight matched text and inner hits.")):
return {
"name": {
"fragment_size": 256,
"number_of_fragments": 1
}
} if q is not None and h else None
The swagger API will result in:
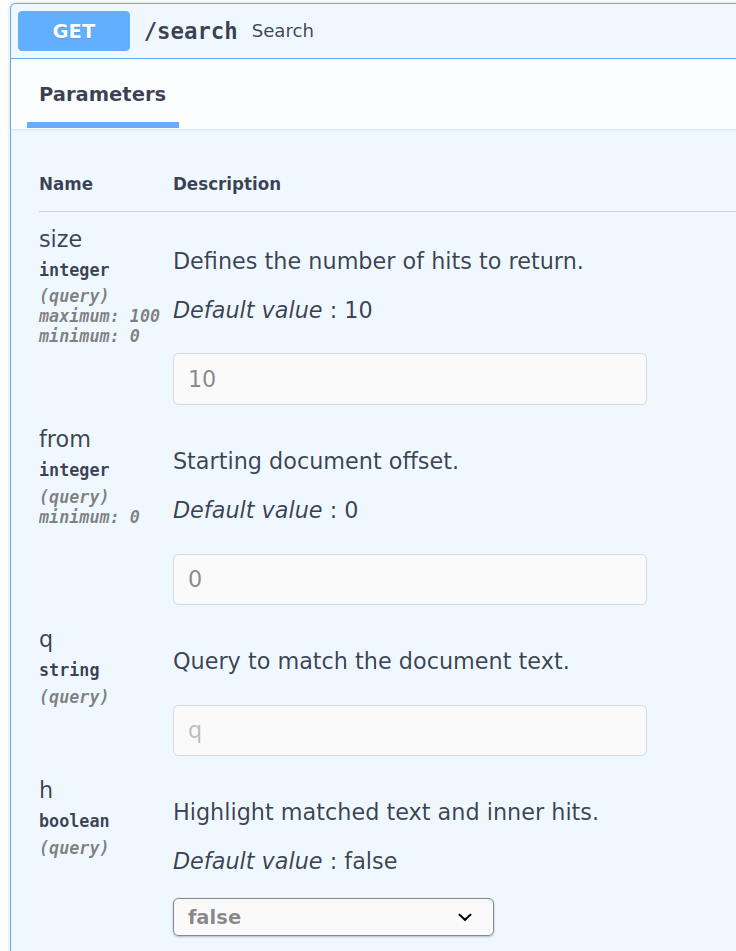
The resulting query will be like this:
{
"query": {
"bool": {
"should": [
{
"multi_match": {
"query": "bob",
"fuzziness": "AUTO",
"fields": [
"name^2"
]
}
}
],
"minimum_should_match": 1
}
},
"size": 10,
"from": 0,
"highlight": {
"fields": {
"name": {
"fragment_size": 256,
"number_of_fragments": 1
}
}
}
}
Now, a complete example:
app = FastAPI()
query_builder = ElasticsearchAPIQueryBuilder()
@query_builder.filter()
def filter_items():
return {
"term": {
"join_field": "item"
}
}
@query_builder.filter()
def filter_category(c: Optional[List[str]] = Query([],
description="Category name to filter results.")):
return {
"terms": {
"category": c
}
} if len(c) > 0 else None
@query_builder.matcher()
def match_fields(q: Optional[str] = Query(None,
description="Query to match the document text.")):
return {
"multi_match": {
"query": q,
"fuzziness": "AUTO",
"fields": [
"name^2",
]
}
} if q is not None else None
@query_builder.matcher()
def match_fragments(q: Optional[str] = Query(None,
description="Query to match the document text."),
h: bool = Query(False,
description="Highlight matched text and inner hits.")):
if q is not None:
matcher = {
"has_child": {
"type": "fragment",
"score_mode": "max",
"query": {
"bool": {
"minimum_should_match": 1,
"should": [
{
"match": {
"content": {
"query": q,
"fuzziness": "auto"
}
}
},
{
"match_phrase": {
"content": {
"query": q,
"slop": 3,
"boost": 50
}
}
},
]
}
}
}
}
if h:
matcher["has_child"]["inner_hits"] = {
"size": 1,
"_source": "false",
"highlight": {
"fields": {
"content": {
"fragment_size": 256,
"number_of_fragments": 1
}
}
}
}
return matcher
else:
return None
class Direction(str, Enum):
asc = "asc"
desc = "desc"
@query_builder.sorter()
def sort_by(direction: Optional[Direction] = Query(None)):
return {
"name": direction
} if direction is not None else None
@query_builder.highlighter()
def highlight(q: Optional[str] = Query(None,
description="Query to match the document text."),
h: bool = Query(False,
description="Highlight matched text and inner hits.")):
return {
"name": {
"fragment_size": 256,
"number_of_fragments": 1
}
} if q is not None and h else None
@app.get("/search")
async def search(query_body: Dict = Depends(query_builder.build())) -> JSONResponse:
return es.search(
body=query_body,
index=index_name
)
Also it is possible to customize the generated query body using the decorator search_builder.
from typing import List, Dict
@query_builder.search_builder()
def build_search_body(size: int = 10,
start_from: int = 0,
source: Union[List, Dict, str] = None,
minimum_should_match: int = 1,
filters: List[Dict] = [],
matchers: List[Dict] = [],
highlighters: List[Dict] = [],
sorters: List[Dict] = []) -> Dict:
return {
"query": {
...
},
...
}
Adopt this project: if you like and want to adopt it, talk to me.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file fastapi-elasticsearch-0.8.2.tar.gz.
File metadata
- Download URL: fastapi-elasticsearch-0.8.2.tar.gz
- Upload date:
- Size: 5.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.8.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f350dd16bb4640f9e804ab07ccba8dcf4b0cffff3ac6715e333c89752f15ebde
|
|
| MD5 |
b911538294e5c8af7f8ac530c7d04746
|
|
| BLAKE2b-256 |
a6b90eff38b0aaf5ba85f722ab9ca1272b6014f880341b4eba799f9086b41b80
|
File details
Details for the file fastapi_elasticsearch-0.8.2-py3-none-any.whl.
File metadata
- Download URL: fastapi_elasticsearch-0.8.2-py3-none-any.whl
- Upload date:
- Size: 5.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.8.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
fd6ab34159dfdaca9492457fe9aa2b1b4143c8e95883d7d73b7f67bfa8348e7f
|
|
| MD5 |
d26771e44a9b7af7e3acaf5a746e1336
|
|
| BLAKE2b-256 |
e0790be3dc251e89c0af193d90d7a34ab21c3d50611017f8120b5236a7161dfe
|







