Fast Semantic Segmentation for PyTorch

Project description
Fast Semantic Segmentation

This respository aims to provide accurate real-time semantic segmentation code for mobile devices in PyTorch, with pretrained weights on Cityscapes. This can be used for efficient segmentation on a variety of real-world street images, including datasets like Mapillary Vistas, KITTI, and CamVid.
from fastseg import MobileV3Large
model = MobileV3Large.from_pretrained().cuda().eval()
model.predict(images)

The models are implementations of MobileNetV3 (both large and small variants) with a modified segmentation head based on LR-ASPP. The top model was able to achieve 72.3% mIoU accuracy on Cityscapes val, while running at up to 37.3 FPS on a GPU. Please see below for detailed benchmarks.
Currently, you can do the following:
- Load pretrained MobileNetV3 semantic segmentation models.
- Easily generate hard segmentation labels or soft probabilities for street image scenes.
- Evaluate MobileNetV3 models on Cityscapes, or your own dataset.
- Export models for production with ONNX.
If you have any feature requests or questions, feel free to leave them as GitHub issues!
Table of Contents
- What's New?
- Overview
- Requirements
- Pretrained Models and Metrics
- Usage
- Training from Scratch
- Contributions
What's New?
September 29th, 2020
- Released training code for semantic segmentation models
August 12th, 2020
- Added pretrained weights for
MobileV3Smallwith 256 filters
August 11th, 2020
- Initial release
- Implementations of
MobileV3LargeandMobileV3Smallwith LR-ASPP - Pretrained weights for
MobileV3Largewith 128/256 filters, andMobileV3Smallwith 64/128 filters - Inference, ONNX export, and optimization scripts
Overview
Here's an excerpt from the original paper introducing MobileNetV3:
This paper starts the exploration of how automated search algorithms and network design can work together to harness complementary approaches improving the overall state of the art. Through this process we create two new MobileNet models for release: MobileNetV3-Large and MobileNetV3-Small, which are targeted for high and low resource use cases. These models are then adapted and applied to the tasks of object detection and semantic segmentation.
For the task of semantic segmentation (or any dense pixel prediction), we propose a new efficient segmentation decoder Lite Reduced Atrous Spatial Pyramid Pooling (LR-ASPP). We achieve new state of the art results for mobile classification, detection and segmentation.
MobileNetV3-Large LRASPP is 34% faster than MobileNetV2 R-ASPP at similar accuracy for Cityscapes segmentation.
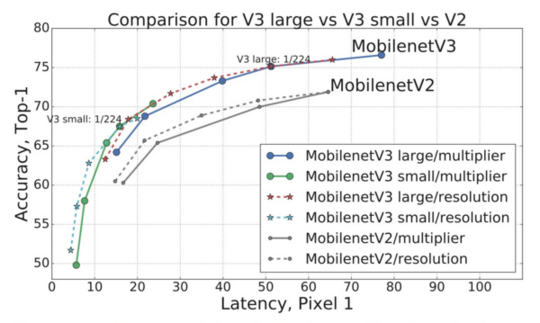
This project tries to faithfully implement MobileNetV3 for real-time semantic segmentation, with the aims of being efficient, easy to use, and extensible.
Requirements
This code requires Python 3.7 or later. It has been tested to work with PyTorch versions 1.5 and 1.6. To install the package, simply run pip install fastseg. Then you can get started with a pretrained model:
# Load a pretrained MobileNetV3 segmentation model in inference mode
from fastseg import MobileV3Large
model = MobileV3Large.from_pretrained().cuda()
model.eval()
# Open a local image as input
from PIL import Image
image = Image.open('street_image.png')
# Predict numeric labels [0-18] for each pixel of the image
labels = model.predict_one(image)

More detailed examples are given below. As an alternative, instead of installing fastseg from pip, you can clone this repository and install the geffnet package (along with other dependencies) by running pip install -r requirements.txt in the project root.
Pretrained Models and Metrics
I was able to train a few models close to or exceeding the accuracy described in the original Searching for MobileNetV3 paper. Each was trained only on the gtFine labels from Cityscapes for around 12 hours on an Nvidia DGX-1 node, with 8 V100 GPUs.
| Model | Segmentation Head | Parameters | mIoU | Inference | TensorRT | Weights? |
|---|---|---|---|---|---|---|
MobileV3Large |
LR-ASPP, F=256 | 3.6M | 72.3% | 21.1 FPS | 30.7 FPS | ✔ |
MobileV3Large |
LR-ASPP, F=128 | 3.2M | 72.3% | 25.7 FPS | 37.3 FPS | ✔ |
MobileV3Small |
LR-ASPP, F=256 | 1.4M | 67.8% | 30.3 FPS | 39.4 FPS | ✔ |
MobileV3Small |
LR-ASPP, F=128 | 1.1M | 67.4% | 38.2 FPS | 52.4 FPS | ✔ |
MobileV3Small |
LR-ASPP, F=64 | 1.0M | 66.9% | 46.5 FPS | 61.9 FPS | ✔ |
The accuracy is within 0.3% of the original paper, which reported 72.6% mIoU and 3.6M parameters on the Cityscapes val set. Inference was tested on a single V100 GPU with full-resolution 2MP images (1024 x 2048) as input. It runs roughly 4x faster on half-resolution (512 x 1024) images.
The "TensorRT" column shows benchmarks I ran after exporting optimized ONNX models to Nvidia TensorRT with fp16 precision. Performance is measured by taking average GPU latency over 100 iterations.
Usage
Running Inference
The easiest way to get started with inference is to clone this repository and use the infer.py script. For example, if you have street images named city_1.png and city_2.png, then you can generate segmentation labels for them with the following command.
$ python infer.py city_1.png city_2.png
Output:
==> Creating PyTorch MobileV3Large model
==> Loading images and running inference
Loading city_1.png
Generated colorized_city_1.png
Generated composited_city_1.png
Loading city_2.png
Generated colorized_city_2.png
Generated composited_city_2.png
| Original | Colorized | Composited |
|---|---|---|
 |
 |
 |
 |
 |
 |
To interact with the models programmatically, first install the fastseg package with pip, as described above. Then, you can import and construct models in your own Python code, which are instances of PyTorch nn.Module.
from fastseg import MobileV3Large, MobileV3Small
# Load a pretrained segmentation model
model = MobileV3Large.from_pretrained()
# Load a segmentation model from a local checkpoint
model = MobileV3Small.from_pretrained('path/to/weights.pt')
# Create a custom model with random initialization
model = MobileV3Large(num_classes=19, use_aspp=False, num_filters=256)
To run inference on an image or batch of images, you can use the methods model.predict_one() and model.predict(), respectively. These methods take care of the preprocessing and output interpretation for you; they take PIL Images or NumPy arrays as input and return a NumPy array.
(You can also run inference directly with model.forward(), which will return a tensor containing logits, but be sure to normalize the inputs to have mean 0 and variance 1.)
import torch
from PIL import Image
from fastseg import MobileV3Large, MobileV3Small
# Construct a new model with pretrained weights, in evaluation mode
model = MobileV3Large.from_pretrained().cuda()
model.eval()
# Run inference on an image
img = Image.open('city_1.png')
labels = model.predict_one(img) # returns a NumPy array containing integer labels
assert labels.shape == (1024, 2048)
# Run inference on a batch of images
img2 = Image.open('city_2.png')
batch_labels = model.predict([img, img2]) # returns a NumPy array containing integer labels
assert batch_labels.shape == (2, 1024, 2048)
# Run forward pass directly
dummy_input = torch.randn(1, 3, 1024, 2048, device='cuda')
with torch.no_grad():
dummy_output = model(dummy_input)
assert dummy_output.shape == (1, 19, 1024, 2048)
The output labels can be visualized with colorized and composited images.
from fastseg.image import colorize, blend
colorized = colorize(labels) # returns a PIL Image
colorized.show()
composited = blend(img, colorized) # returns a PIL Image
composited.show()
Exporting to ONNX
The onnx_export.py script can be used to convert a pretrained segmentation model to ONNX. You should specify the image input dimensions when exporting. See the usage instructions below:
$ python onnx_export.py --help
usage: onnx_export.py [-h] [--model MODEL] [--num_filters NUM_FILTERS]
[--size SIZE] [--checkpoint CHECKPOINT]
OUTPUT_FILENAME
Command line script to export a pretrained segmentation model to ONNX.
positional arguments:
OUTPUT_FILENAME filename of output model (e.g.,
mobilenetv3_large.onnx)
optional arguments:
-h, --help show this help message and exit
--model MODEL, -m MODEL
the model to export (default MobileV3Large)
--num_filters NUM_FILTERS, -F NUM_FILTERS
the number of filters in the segmentation head
(default 128)
--size SIZE, -s SIZE the image dimensions to set as input (default
1024,2048)
--checkpoint CHECKPOINT, -c CHECKPOINT
filename of the weights checkpoint .pth file (uses
pretrained by default)
The onnx_optimize.py script optimizes exported models. If you're looking to deploy a model to TensorRT or a mobile device, you might also want to run it through onnx-simplifier.
Training from Scratch
Please see the ekzhang/semantic-segmentation repository for the training code used in this project, as well as documentation about how to train your own custom models.
Contributions
Pull requests are always welcome! A big thanks to Andrew Tao and Karan Sapra from NVIDIA ADLR for helpful discussions and for lending me their training code, as well as Branislav Kisacanin, without whom this wouldn't be possible.
I'm grateful for advice from: Ching Hung, Eric Viscito, Franklyn Wang, Jagadeesh Sankaran, and Zoran Nikolic.
Licensed under the MIT License.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file fastseg-0.1.2.tar.gz.
File metadata
- Download URL: fastseg-0.1.2.tar.gz
- Upload date:
- Size: 16.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.24.0 setuptools/49.2.0 requests-toolbelt/0.9.1 tqdm/4.50.0 CPython/3.8.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3e934203ce652da404d8b8b673c63c95dfc14d2958beecfec04d4c9191f1fa8a
|
|
| MD5 |
66b9af1e100d03d59a334a12d7d1feeb
|
|
| BLAKE2b-256 |
7b71ac875dfa5fc09a0a955dc8b974acd957d9424a8c9b8d714ea722268a656a
|
File details
Details for the file fastseg-0.1.2-py3-none-any.whl.
File metadata
- Download URL: fastseg-0.1.2-py3-none-any.whl
- Upload date:
- Size: 14.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.2.0 pkginfo/1.5.0.1 requests/2.24.0 setuptools/49.2.0 requests-toolbelt/0.9.1 tqdm/4.50.0 CPython/3.8.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e269fe8b3ef2458e5405745b286a0acef43d45fd64a242ea2c91daf951079639
|
|
| MD5 |
042f89283f879055e14ad170a724ef01
|
|
| BLAKE2b-256 |
32773ade99309f2ee5d1ecba8174c4399ef0acc052b35af8d16060051c20c106
|







