FFPA: Yet another Faster Flash Prefill Attention for large headdim, 1.8x~3x faster than SDPA EA.

Project description
🤖FFPA: Yet another Faster Flash Prefill Attention
with O(1)⚡️GPU SRAM complexity for large headdim🐑
📚FFPA(Split-D) Blog | 📈L20 ~1.9x↑🎉 | 📈A30 ~1.8x↑🎉 | 📈3080 ~2.9x↑🎉 | 📈4090 ~2.1x↑🎉
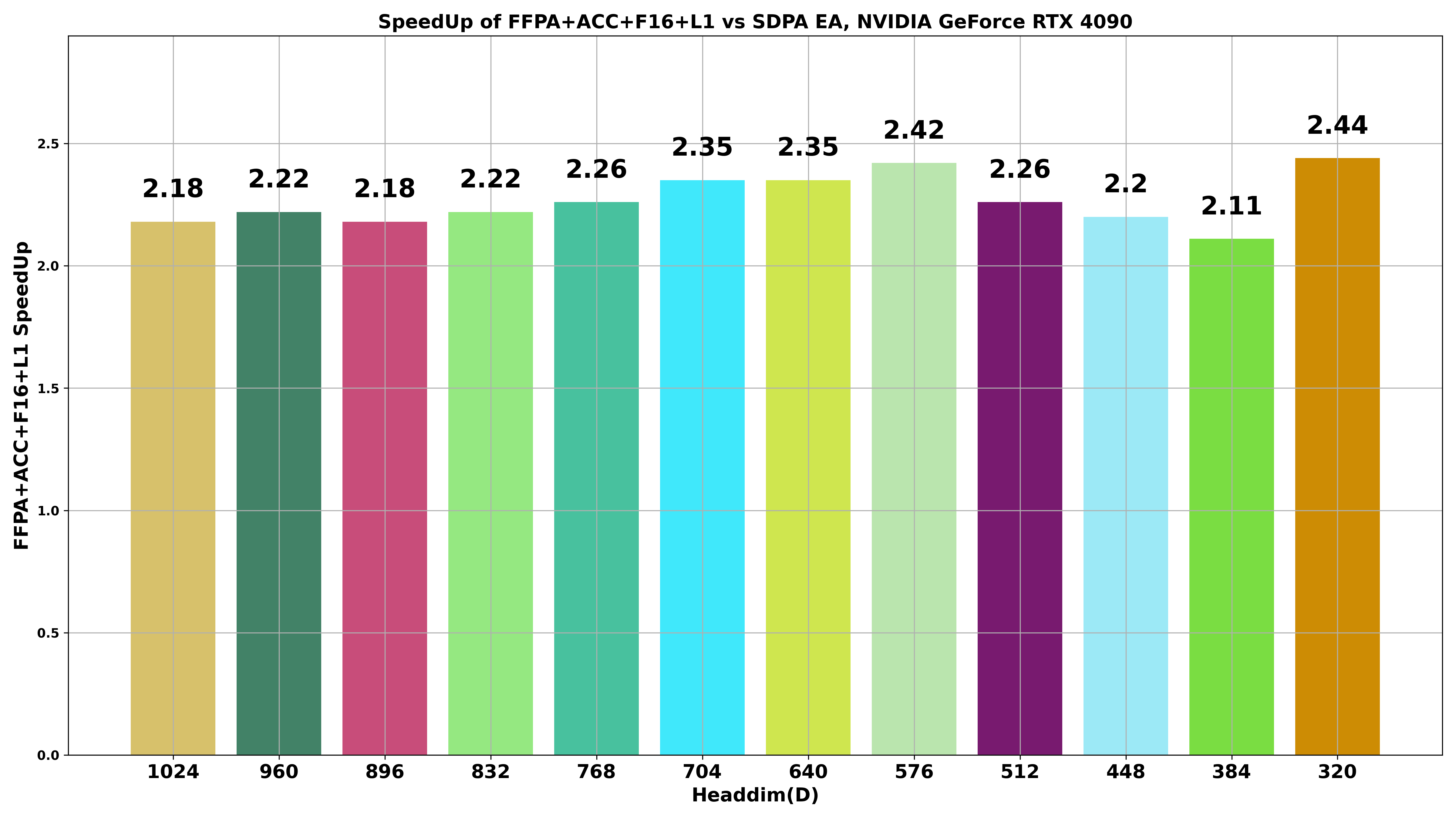
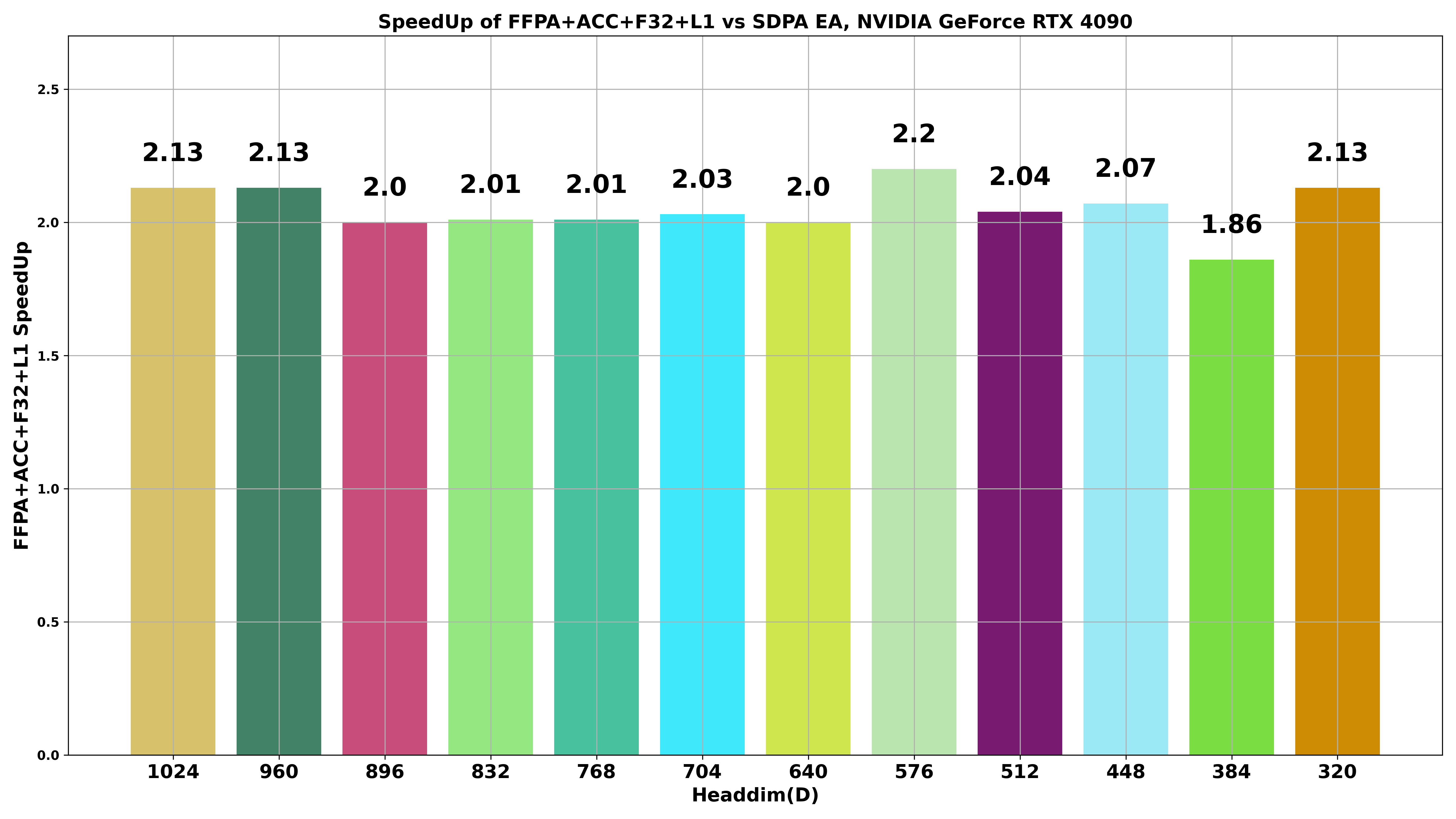
FFPA(Split-D): Yet another Faster Flash Prefill Attention with Split-D strategy, achieve O(1) SRAM complexity and O(d/4) register complexity for large headdim (> 256), 1.8x~3x 🎉 faster than SDPA. Currently, FFPA supports self-attention, cross-attention, grouped/multi-query attention, causal attention with large headdim (D=320~1024). While the standard FlashAttention-2 only support headdim <= 256.
| Self Attention | Cross/Decode Attention | GQA/MQA Attention | Causal Attention | Headdim |
|---|---|---|---|---|
✔️(Nq = Nkv) |
✔️(Nq != Nkv) |
✔️(Nh_q % Nh_kv == 0) |
✔️(causal mask) |
32~1024 |
[!NOTE] FFPA has been tested on
Ampere,Ada,Hopper, andBlackwellarchitectures (e.g., A30, L20, 4090, H200, 5090), achieves1.8×~3×↑🎉forward (CUDA) and1.5×~2.5×↑🎉backward (Triton w/ autotune) speedup over SDPA for headdim> 256.
📖 Quick Start
First, install the prebuilt whl from PyPI (required: PyTorch>=2.11.0, CUDA>=13.0, Ubuntu>=22.04):
pip3 install -U ffpa-attn # (support: sm_{80, 89, 90, 100, 120})
Or, you can build ffpa-attn from source (recommended: PyTorch>=2.11.0, CUDA>=13.0):
git clone https://github.com/xlite-dev/ffpa-attn.git
# Then, build the wheel package and install it with pip
cd ffpa-attn && MAX_JOBS=32 python3 setup.py bdist_wheel
# Optional: build ffpa-attn with ccache for faster rebuilds
apt install ccache && bash tools/build_fast.sh bdist_wheel
# Optional: for editable whl, use `pip install -e .` instead.
pip3 install dist/ffpa_attn-*.whl # pip uninstall ffpa-attn -y
[!NOTE] FFPA supports cross-attention where the query seqlen
Nqmay differ from the key/value seqlenNkv, GQA / MQA attention where Q hasNh_qheads and K/V haveNh_kvheads (requiresNh_q % Nh_kv == 0; group size =Nh_q / Nh_kv), and causal attention (passcausal=True; queries are aligned to the KV tail, i.e. Q rowrattends tok <= r + (Nkv - Nq), which requiresNkv >= Nq). K/V must share the sameNh_kvandNkv.
Minimal usage example — Self-Attention (B=1, H=32, N=8192, D=512):
import torch
import torch.nn.functional as F
from ffpa_attn import ffpa_attn_func
# D: 32, 64, ..., 320, ..., 1024 (FA-2 <= 256, FFPA supports up to 1024).
B, H, N, D = 1, 32, 8192, 512 # batch_size, num_heads, seq_len, head_dim
q = torch.randn(B, H, N, D, dtype=torch.bfloat16, device="cuda")
k = torch.randn(B, H, N, D, dtype=torch.bfloat16, device="cuda")
v = torch.randn(B, H, N, D, dtype=torch.bfloat16, device="cuda")
# FFPA self attention; layout follows SDPA: (B, H, N, D).
out = ffpa_attn_func(q, k, v) # -> torch.Tensor of shape (B, H, N, D)
print(out.shape, out.dtype)
ref = F.scaled_dot_product_attention(q, k, v)
print(f"vs SDPA max_abs_err={(out - ref).abs().max().item():.4e}")
Cross-Attention or Decoding-Attention example (short query, long KV cache; Nq != Nkv):
import torch
import torch.nn.functional as F
from ffpa_attn import ffpa_attn_func
# Short-query / long-KV, e.g. incremental decoding or cross-attention:
# Q: [B, H, Nq, D], K/V: [B, H, Nkv, D]; Nq can differ from Nkv but Nk==Nv required.
B, H, D = 1, 8, 512
Nq, Nkv = 128, 8192
q = torch.randn(B, H, Nq, D, dtype=torch.bfloat16, device="cuda")
k = torch.randn(B, H, Nkv, D, dtype=torch.bfloat16, device="cuda")
v = torch.randn(B, H, Nkv, D, dtype=torch.bfloat16, device="cuda")
out = ffpa_attn_func(q, k, v) # -> (B, H, Nq, D) = (1, 8, 128, 512)
print(out.shape, out.dtype)
ref = F.scaled_dot_product_attention(q, k, v)
print(f"vs SDPA max_abs_err={(out - ref).abs().max().item():.4e}")
Grouped-Query / Multi-Query Attention example (Q has more heads than K/V):
import torch
import torch.nn.functional as F
from ffpa_attn import ffpa_attn_func
# GQA: Q has Nh_q heads, K/V share Nh_kv heads; group_size = Nh_q / Nh_kv.
# Typical Llama-3-style 32/8 ratio; MQA is the Nh_kv==1 special case.
# FFPA targets large headdim so we use D=512 here (FA-2 tops out at D=256).
B, D, Nq, Nkv = 1, 512, 1024, 4096
Nh_q, Nh_kv = 32, 8 # group_size = 4
q = torch.randn(B, Nh_q, Nq, D, dtype=torch.bfloat16, device="cuda")
k = torch.randn(B, Nh_kv, Nkv, D, dtype=torch.bfloat16, device="cuda")
v = torch.randn(B, Nh_kv, Nkv, D, dtype=torch.bfloat16, device="cuda")
out = ffpa_attn_func(q, k, v) # -> (B, Nh_q, Nq, D) = (1, 32, 1024, 512)
print(out.shape, out.dtype)
# Reference: replicate K/V along head dim to match Q's head count.
group_size = Nh_q // Nh_kv
k_ref = k.repeat_interleave(group_size, dim=1)
v_ref = v.repeat_interleave(group_size, dim=1)
ref = F.scaled_dot_product_attention(q, k_ref, v_ref)
print(f"vs SDPA max_abs_err={(out - ref).abs().max().item():.4e}")
Causal Attention example (self-attention causal; also supports chunked / decoding prefill with Nkv > Nq):
import torch
import torch.nn.functional as F
from ffpa_attn import ffpa_attn_func
# Causal self-attention: Q row r attends to k <= r (standard triangular mask).
# FFPA is tuned for large headdim, so we keep D=512 as in the self-attn example.
B, H, N, D = 1, 8, 4096, 512
q = torch.randn(B, H, N, D, dtype=torch.bfloat16, device="cuda")
k = torch.randn(B, H, N, D, dtype=torch.bfloat16, device="cuda")
v = torch.randn(B, H, N, D, dtype=torch.bfloat16, device="cuda")
out = ffpa_attn_func(q, k, v, causal=True)
print(out.shape, out.dtype)
ref = F.scaled_dot_product_attention(q, k, v, is_causal=True)
print(f"vs SDPA max_abs_err={(out - ref).abs().max().item():.4e}")
# Chunked / decoding prefill: Nq < Nkv, queries aligned to the KV tail
# so Q row r attends to k <= r + (Nkv - Nq). Requires Nkv >= Nq.
Nq, Nkv = 128, 8192
q = torch.randn(B, H, Nq, D, dtype=torch.bfloat16, device="cuda")
k = torch.randn(B, H, Nkv, D, dtype=torch.bfloat16, device="cuda")
v = torch.randn(B, H, Nkv, D, dtype=torch.bfloat16, device="cuda")
out = ffpa_attn_func(q, k, v, causal=True)
print(out.shape, out.dtype) # (1, 8, 128, 512)
Backward Pass example (compare dQ / dK / dV against SDPA):
import math
import torch
import torch.nn.functional as F
from ffpa_attn import ffpa_attn_func
# Focus on a large-headdim case where FFPA is typically used.
B, H, N, D = 1, 32, 8192, 512
scale = 1.0 / math.sqrt(D)
q = torch.randn(B, H, N, D, dtype=torch.bfloat16, device="cuda", requires_grad=True)
k = torch.randn(B, H, N, D, dtype=torch.bfloat16, device="cuda", requires_grad=True)
v = torch.randn(B, H, N, D, dtype=torch.bfloat16, device="cuda", requires_grad=True)
out = ffpa_attn_func(
q,
k,
v,
softmax_scale=scale,
)
out.sum().backward()
dq = q.grad.detach().clone()
dk = k.grad.detach().clone()
dv = v.grad.detach().clone()
q_ref = q.detach().clone().requires_grad_(True)
k_ref = k.detach().clone().requires_grad_(True)
v_ref = v.detach().clone().requires_grad_(True)
out_ref = F.scaled_dot_product_attention(q_ref, k_ref, v_ref, scale=scale)
out_ref.sum().backward()
print(f"dQ vs SDPA dQ max_abs_err={(dq - q_ref.grad).abs().max().item():.4e}")
print(f"dK vs SDPA dK max_abs_err={(dk - k_ref.grad).abs().max().item():.4e}")
print(f"dV vs SDPA dV max_abs_err={(dv - v_ref.grad).abs().max().item():.4e}")
Runnable examples are provided under examples. The performance (forward and backward) snapshot for the NVIDIA L20 with Headdim=512 is listed below:
| Case | dtype | Nq/Nkv | allclose | FFPA / SDPA | speedup |
|---|---|---|---|---|---|
| self-attn | fp16 | 8192/8192 | ✅ | 46.7 / 74.7 ms | 1.60x |
| cross-attn | fp16 | 1024/8192 | ✅ | 6.32 / 9.94 ms | 1.57x |
| gqa | fp16 | 8192/8192 | ✅ | 46.4 / 74.8 ms | 1.61x |
| causal | fp16 | 8192/8192 | ✅ | 24.3 / 37.4 ms | 1.54x |
| non-aligned | fp16 | 8191/8191 | ✅ | 12.3 / 19.0 ms | 1.55x |
| self-attn | bf16 | 8192/8192 | ✅ | 46.5 / 74.7 ms | 1.61x |
| cross-attn | bf16 | 1024/8192 | ✅ | 6.29 / 9.95 ms | 1.58x |
| gqa | bf16 | 8192/8192 | ✅ | 46.2 / 74.7 ms | 1.62x |
| causal | bf16 | 8192/8192 | ✅ | 24.2 / 37.5 ms | 1.55x |
| non-aligned | bf16 | 8191/8191 | ✅ | 12.3 / 19.0 ms | 1.55x |
📖 Split-D
We have extended FlashAttention for large headdim (D > 256) by implementing Fine-grained Tiling at the MMA level (GEMM style) for the Q@K^T and P@V matmul (namely, Split-D). This approach results in a constant SRAM usage of Br * 16 or Bc * 16 (Br = Bc) for Q, K, and V, leading to an overall SRAM complexity of O(Br * 16) ≈ O(1) and a register complexity of O(d/4). Consequently, this method allows us to extend headdim > 256 and achieve faster performance compared to SDPA with or without MMA Accumulation F32 (1.8x~3x 🎉 faster than SDPA EA).
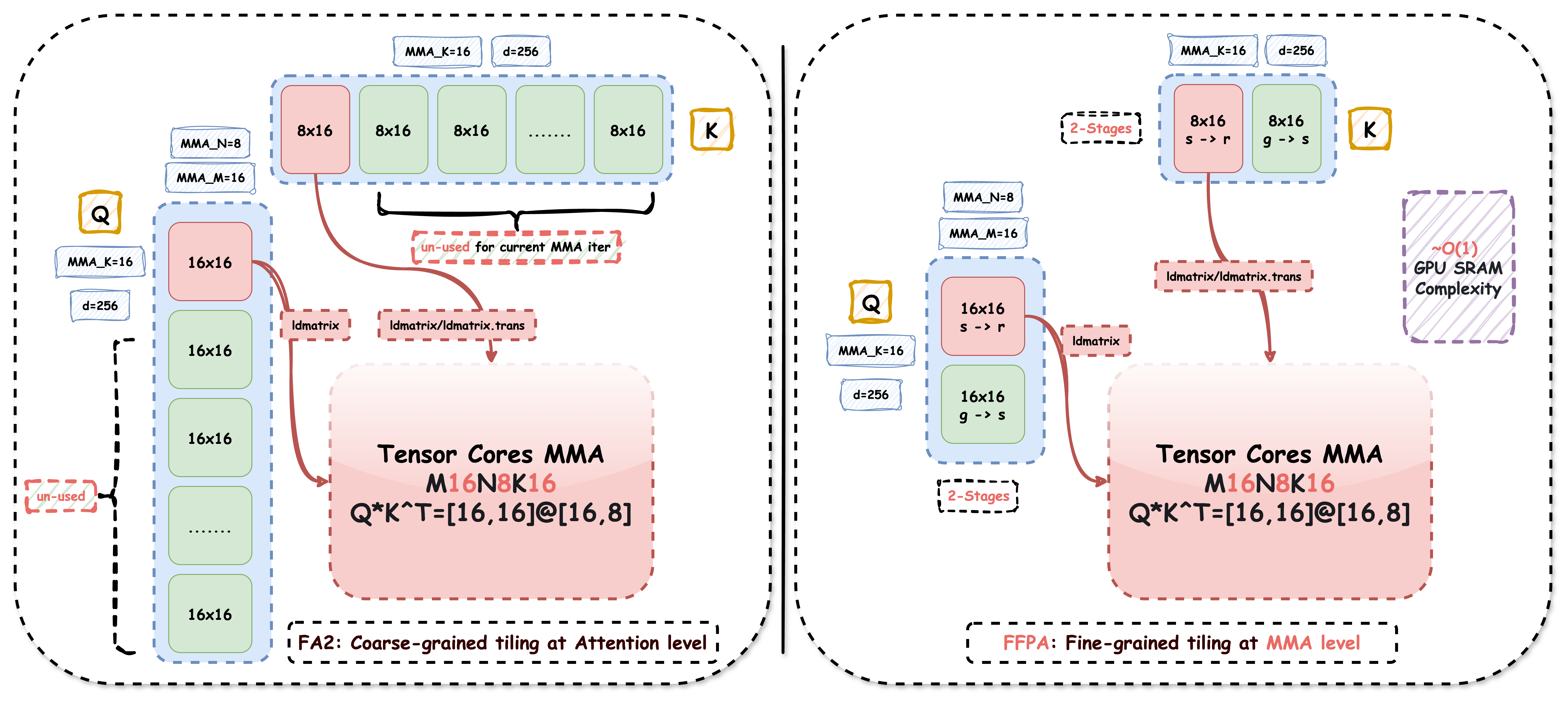
We have named this new attention tiling technique FFPA: Faster Flash Prefill Attention. FFPA does not introduce any additional VRAM requirement, so the HBM memory complexity remains the same as FlashAttention.
By leveraging this approach, we can achieve better performance than SDPA EA for very large headdim (D > 256, FA-2 not supported). Approximate SRAM and register complexity analysis for FFPA is as follows: (d=headdim, C,Br,Bc=Constant, Br=Bc, let O(C)≈O(1)) 👇
| 📚Complexity Analysis | 📚FFPA Attention (Split-D) | 📚FlashAttention-2 |
|---|---|---|
| SRAM | O(2xBrx16)≈O(1) | ≈O(3xBrxd), d↑ |
| Register | ≈O(d/4), d↑ | ≈O(d/2), d↑ |
| HBM | ≈FA2≈O(Nd), O | ≈O(Nd), O |
| Extra HBM | ≈FA2≈O(N), m,l | ≈O(N), m,l |
🤔 Why not TMA?
FFPA ships an experimental SM90 TMA path (tma=True) that replaces the K/V cp.async global-to-shared transfer with cp.async.bulk.tensor.2d. After tuning (K SWIZZLE_128B, 64-col TMA box) it reaches parity with the cp.async baseline, but does not beat it.
FFPA's Split-D dataflow is a TMA anti-pattern. TMA wins when single thread instruction can amortise its dispatch cost over a large box, but split-D gives it narrow Bc x kMmaAtomK slices. It would require a major redesign (super-tiled K/V on TMA + warp-specialized WGMMA), rather than a drop-in K/V replacement.
©️License
Apache License 2.0
🎉Contribute
How to contribute? Wecome to star⭐️ this repo to support me👆🏻 ~

©️Citations
@misc{ffpa-attn@2025,
title={FFPA: Yet another Faster Flash Prefill Attention for large headdim.},
url={https://github.com/xlite-dev/ffpa-attn.git},
note={Open-source software available at https://github.com/xlite-dev/ffpa-attn.git},
author={DefTruth},
year={2025}
}
📖 References
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file ffpa_attn-0.1.3-cp314-cp314-manylinux_2_34_x86_64.whl.
File metadata
- Download URL: ffpa_attn-0.1.3-cp314-cp314-manylinux_2_34_x86_64.whl
- Upload date:
- Size: 55.8 MB
- Tags: CPython 3.14, manylinux: glibc 2.34+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.12.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f8bfb3e0d3344014e1946c4016d4a3fda39146db264ba601c247456fe2da6409
|
|
| MD5 |
7e5ab03d2854f39a9e47ba315520f362
|
|
| BLAKE2b-256 |
2466dce5952d263542edc27b3a3a35ee93cf15266be98650aff4bd5e5544860e
|
File details
Details for the file ffpa_attn-0.1.3-cp313-cp313-manylinux_2_34_x86_64.whl.
File metadata
- Download URL: ffpa_attn-0.1.3-cp313-cp313-manylinux_2_34_x86_64.whl
- Upload date:
- Size: 55.8 MB
- Tags: CPython 3.13, manylinux: glibc 2.34+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.12.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
dff57ae067baad5c3434c6bfc7a30656fe096f1a209e8a1cd95d56aea1562524
|
|
| MD5 |
359107bc106205fc513b34769941ac74
|
|
| BLAKE2b-256 |
1cdc14aab48bf1eb05aa3f54e99dd27338ce2bf9615248a73f9bec3f97700eb2
|
File details
Details for the file ffpa_attn-0.1.3-cp312-cp312-manylinux_2_34_x86_64.whl.
File metadata
- Download URL: ffpa_attn-0.1.3-cp312-cp312-manylinux_2_34_x86_64.whl
- Upload date:
- Size: 55.8 MB
- Tags: CPython 3.12, manylinux: glibc 2.34+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.12.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
22c252d0d345a558d851c87272b466f97a39ea827cd124e4cc6595b422ed6eee
|
|
| MD5 |
c522670aaab6b97f9699dac8a475b618
|
|
| BLAKE2b-256 |
c5e1de5e03bbd0f68d09004ab744487bac40069be4e1f8f5eba6892695b6f19a
|
File details
Details for the file ffpa_attn-0.1.3-cp311-cp311-manylinux_2_34_x86_64.whl.
File metadata
- Download URL: ffpa_attn-0.1.3-cp311-cp311-manylinux_2_34_x86_64.whl
- Upload date:
- Size: 55.8 MB
- Tags: CPython 3.11, manylinux: glibc 2.34+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.12.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
672030340526dd629c5e01d220943ad953cb6349ad3da4b9e041ff6dc212478e
|
|
| MD5 |
e43143c1521315aab09156fd049534cc
|
|
| BLAKE2b-256 |
8279d6d8ac55bb7a8bafa032751875e77b3172841af3ba7cec2e14d12b708381
|
File details
Details for the file ffpa_attn-0.1.3-cp310-cp310-manylinux_2_34_x86_64.whl.
File metadata
- Download URL: ffpa_attn-0.1.3-cp310-cp310-manylinux_2_34_x86_64.whl
- Upload date:
- Size: 55.8 MB
- Tags: CPython 3.10, manylinux: glibc 2.34+ x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.12.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
062777557f8d06b2cf9a056371fcc16a14c25539ac6b25bc96082656dab7c7cf
|
|
| MD5 |
21bf4c008d96e70b9f5a52b012826eda
|
|
| BLAKE2b-256 |
f2156cfdd553729daebeb8fc12b8d9efdf31b61bf5a5664ea53153bcdd2bcdbb
|







