Flash-ANSR: Fast Amortized Neural Symbolic Regression - Discover symbolic expressions from tabular data using SetTransformer and Transformer architectures
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
⚡Flash-ANSR:
Fast Amortized Neural Symbolic Regression






Flash-ANSR is a library for amortized neural symbolic regression: load a pretrained model, call fit(X, y), and recover a symbolic expression for your tabular data, or train your own model. It is built for fast, ready-to-use inference.
Publications
- Saegert & Köthe 2026, Breaking the Simplification Bottleneck in Amortized Neural Symbolic Regression (preprint, under review) https://arxiv.org/abs/2602.08885
Usage
pip install flash-ansr
import torch
import numpy as np
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Import flash_ansr
from flash_ansr import (
FlashANSR,
SoftmaxSamplingConfig,
install_model,
get_path,
)
# Select a model from Hugging Face
# https://huggingface.co/models?search=flash-ansr-v23.0
MODEL = "psaegert/flash-ansr-v23.0-120M"
# Download the latest snapshot of the model
# By default, the model is downloaded to the directory `./models/` in the package root
install_model(MODEL)
# Load the model (KV-cache, auto-batching and static decoding are on by default; see "Inference speed")
model = FlashANSR.load(
directory=get_path('models', MODEL),
generation_config=SoftmaxSamplingConfig(choices=1024), # or BeamSearchConfig / MCTSGenerationConfig
length_penalty=0.05, # prefer shorter expressions when scoring candidates (renamed from `parsimony` in v0.5)
).to(device)
# Define data: a small synthetic example, y = 2.5 * sin(x) + x^2 / 3
X = np.linspace(-5, 5, 100).reshape(-1, 1)
y = 2.5 * np.sin(X[:, 0]) + X[:, 0] ** 2 / 3
# Fit the model to the data
model.fit(X, y, verbose=True)
# Show the best expression
print(model.get_expression())
# Predict with the best expression
y_pred = model.predict(X)
Get all candidates at once (infer): instead of fit + read-back, call model.infer(X, y), which returns an InferenceResult carrying the best Candidate, the score-sorted refined candidates, and the full CandidateLedger (the generation pool joined with the refined survivors, each classified FIT_OK / FIT_FAILED / INVALID).
result = model.infer(X, y)
print(result.best.expression_infix, result.best.fvu) # best refined candidate
for c in result.candidates: # score-sorted survivors
print(c.score, c.expression_infix)
print(len(result.ledger)) # all candidates considered
Explore more in the Demo Notebook.
Train your own: see the training guide and browse the pretrained model collection on Hugging Face.
Inference speed
Flash-ANSR v0.5 ships several inference-speed improvements, enabled by default and designed to be quality-neutral, so the quickstart above already runs in the fast regime. The speed-relevant settings live on the generation config:
| Setting | Default | What it does |
|---|---|---|
use_cache |
True |
KV-cache decoding |
batch_size |
'auto' |
candidate-budget-adaptive batching (pass an int to override) |
static_decode |
None |
static decoding, auto-enabled for capable models (set True/False to force) |
from flash_ansr import SoftmaxSamplingConfig
config = SoftmaxSamplingConfig(
choices=1024, # number of candidate expressions to sample
use_cache=True, # KV cache (default)
batch_size='auto', # candidate-budget-adaptive chunking (default)
static_decode=None, # auto for capable models (default)
)
Constant refinement runs in parallel; control it via FlashANSR.load(..., refiner_workers=N, persistent_refine_pool=True).
To reproduce v0.4.x inference behavior, opt out of the new defaults:
SoftmaxSamplingConfig(choices=1024, use_cache=False, batch_size=128, static_decode=False)
Breaking change (v0.5): the candidate-selection penalty
parsimonywas renamed tolength_penalty. Replace anyparsimony=arguments withlength_penalty=.
Overview
SRSD/FastSRB Results
Results on the SRSD/FastSRB benchmark [Matsubara et al. 2022], [Martinek 2025] Left: Validation Numeric Recovery Rate (vNRR) as a function of inference time (log scale). FLASH-ANSR models (shades of blue) scale monotonically with compute, with the 120M model partially surpassing the PySR baseline (red). Baselines NeSymReS [Biggio et al. 2021] and E2E [Kamienny et al. 2022] fail to generalize to the benchmark. Right: Expression Length Ratio (predicted vs ground truth) versus compute. We observe a parsimony inversion: while PySR [Cranmer 2023] increases complexity to minimize error over time, FLASH-ANSR converges toward simpler, more canonical expressions as the sampling budget increases. Shaded regions denote 95% confidence intervals. |
Training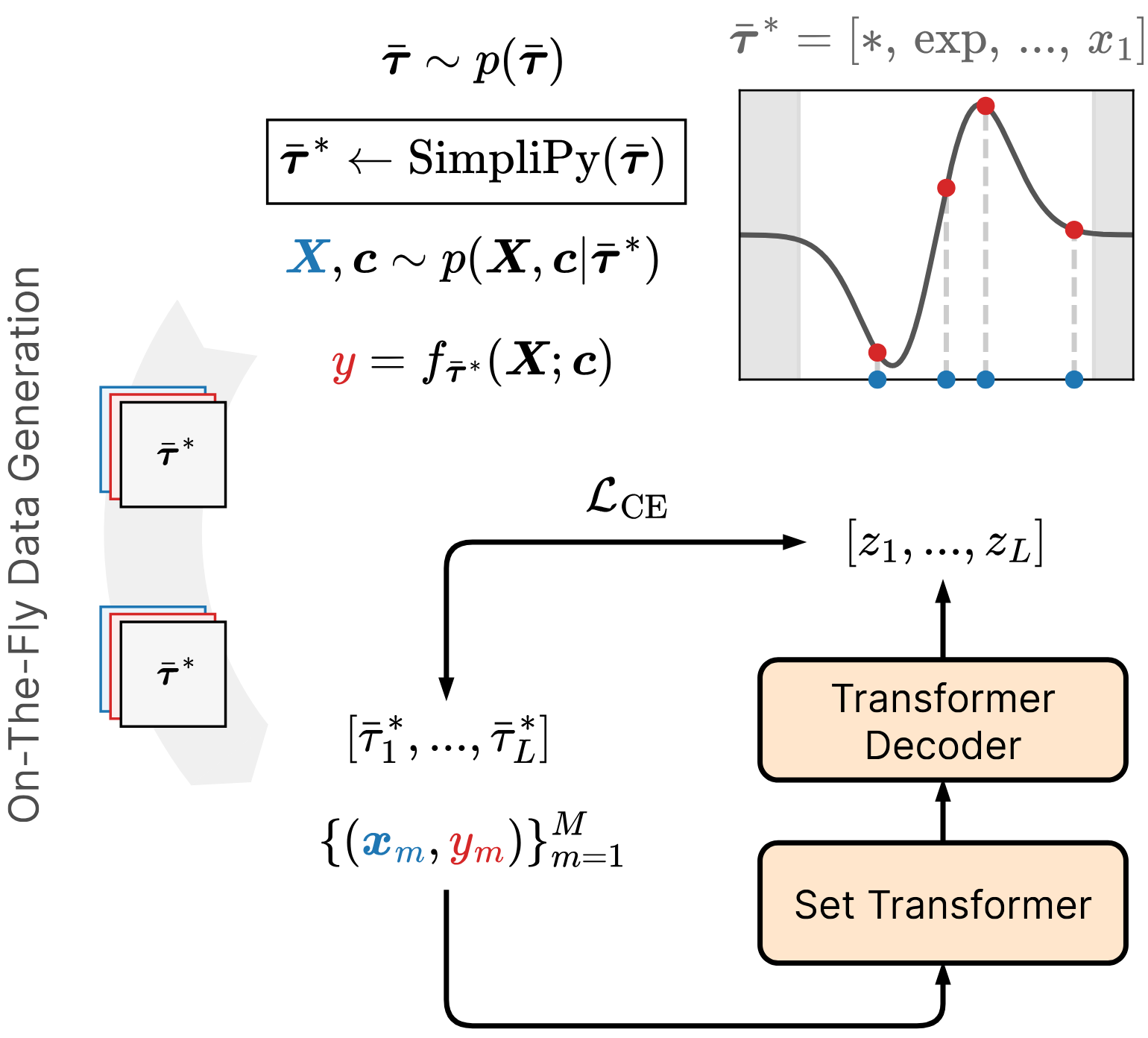
The Flash-ANSR training pipeline. Following the established standard encoder-decoder paradigm, our framework integrates SimpliPy (top center) into the loop for synchronous simplification of on-the-fly generated training expressions. |
Architecture
Flash-ANSR model architecture. The Set Transformer [Lee et al. 2019] encoder ingests a variable-sized set of input-output pairs and produces a fixed-size latent representation via Induced Set Attention Blocks (ISAB) and Set Attention Blocks (SAB). The Transformer decoder [Vaswani et al. 2017], [Xiong et al. 2020] autoregressively generates a symbolic expression token-by-token, attending to the encoded dataset at each step. |
Related projects
- SimpliPy: the expression simplification engine integrated into the Flash-ANSR training loop.
- srbf: the companion symbolic-regression evaluation and benchmarking framework (engine, model adapters, benchmarks, metrics), developed alongside Flash-ANSR.
Citation
@misc{saegert2026breakingsimplificationbottleneckamortized,
title = {Breaking the Simplification Bottleneck in Amortized Neural Symbolic Regression},
author = {Paul Saegert and Ullrich Köthe},
year = {2026},
eprint = {2602.08885},
archivePrefix = {arXiv},
primaryClass = {cs.LG},
url = {https://arxiv.org/abs/2602.08885},
}
% Optionally
@mastersthesis{flash-ansr2024-thesis,
author = {Paul Saegert},
title = {Flash Amortized Neural Symbolic Regression},
school = {Heidelberg University},
year = {2025},
url = {https://github.com/psaegert/flash-ansr-thesis}
}
@software{flash-ansr2024,
author = {Paul Saegert},
title = {Flash Amortized Neural Symbolic Regression},
year = {2024},
publisher = {GitHub},
version = {0.9.0},
url = {https://github.com/psaegert/flash-ansr}
}
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file flash_ansr-0.9.4.tar.gz.
File metadata
- Download URL: flash_ansr-0.9.4.tar.gz
- Upload date:
- Size: 166.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
07819095b2b49ca08c309e3f1f2e15bd5765cafbec8480bafe05d4491a18b4a2
|
|
| MD5 |
5f680a9cbcd0aca69f8f069a2f63c066
|
|
| BLAKE2b-256 |
e28ceafab89ced96736ac48a497468a665d403ebb416372ed1a5c8d6f76c2f9c
|
Provenance
The following attestation bundles were made for flash_ansr-0.9.4.tar.gz:
Publisher:
publish.yaml on psaegert/flash-ansr
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
flash_ansr-0.9.4.tar.gz -
Subject digest:
07819095b2b49ca08c309e3f1f2e15bd5765cafbec8480bafe05d4491a18b4a2 - Sigstore transparency entry: 2033721864
- Sigstore integration time:
-
Permalink:
psaegert/flash-ansr@cff81867f75afb0ddefc79df363ac2702c67e97c -
Branch / Tag:
refs/tags/v0.9.4 - Owner: https://github.com/psaegert
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yaml@cff81867f75afb0ddefc79df363ac2702c67e97c -
Trigger Event:
release
-
Statement type:
File details
Details for the file flash_ansr-0.9.4-py3-none-any.whl.
File metadata
- Download URL: flash_ansr-0.9.4-py3-none-any.whl
- Upload date:
- Size: 155.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
970dfdcf85b43101168ba46c8ea452c04bc7e8ab2bac7c9d68ef315d38d2853d
|
|
| MD5 |
0c6c852458a13e5c61b0373874d2ffb3
|
|
| BLAKE2b-256 |
07879031ff6593df9d940c389039be6b75fee1b652d8430903ee7259d4f9dbef
|
Provenance
The following attestation bundles were made for flash_ansr-0.9.4-py3-none-any.whl:
Publisher:
publish.yaml on psaegert/flash-ansr
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
flash_ansr-0.9.4-py3-none-any.whl -
Subject digest:
970dfdcf85b43101168ba46c8ea452c04bc7e8ab2bac7c9d68ef315d38d2853d - Sigstore transparency entry: 2033722125
- Sigstore integration time:
-
Permalink:
psaegert/flash-ansr@cff81867f75afb0ddefc79df363ac2702c67e97c -
Branch / Tag:
refs/tags/v0.9.4 - Owner: https://github.com/psaegert
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yaml@cff81867f75afb0ddefc79df363ac2702c67e97c -
Trigger Event:
release
-
Statement type:







