Distributed document RAG system with intelligent GPU/CPU orchestration

Project description
FlockParse - Document RAG Intelligence with Distributed Processing









Distributed document RAG system that turns mismatched hardware into a coordinated inference cluster. Auto-discovers Ollama nodes, intelligently routes workloads across heterogeneous GPUs/CPUs, and achieves 60x+ speedups through adaptive load balancing. Privacy-first with local/network/cloud interfaces.
What makes this different: Real distributed systems engineering—not just API wrappers. Handles heterogeneous hardware (RTX A4000 + GTX 1050Ti + CPU laptops working together), network failures, and privacy requirements that rule out cloud APIs.
⚠️ Important: Current Maturity
Status: Beta (v1.0.0) - Early adopters welcome, but read this first!
What works well:
- ✅ Core distributed processing across heterogeneous nodes
- ✅ GPU detection and VRAM-aware routing
- ✅ Basic PDF extraction and OCR fallback
- ✅ Privacy-first local processing (CLI/Web UI modes)
Known limitations:
- ⚠️ Limited battle testing - Tested by ~2 developers, not yet proven at scale
- ⚠️ Security gaps - See SECURITY.md for current limitations
- ⚠️ Edge cases - Some PDF types may fail (encrypted, complex layouts)
- ⚠️ Test coverage - ~40% coverage, integration tests incomplete
Read before using: KNOWN_ISSUES.md documents all limitations, edge cases, and roadmap honestly.
Recommended for:
- 🎓 Learning distributed systems
- 🔬 Research and experimentation
- 🏠 Personal projects with non-critical data
- 🛠️ Contributors who want to help mature the project
Not yet recommended for:
- ❌ Mission-critical production workloads
- ❌ Regulated industries (healthcare, finance) without additional hardening
- ❌ Large-scale deployments (>50 concurrent users)
Help us improve: Report issues, contribute fixes, share feedback!
📹 Demo Video (76 seconds)
Watch FlockParser in action: 372 seconds → 6 seconds (61.7x speedup) through automatic GPU routing.
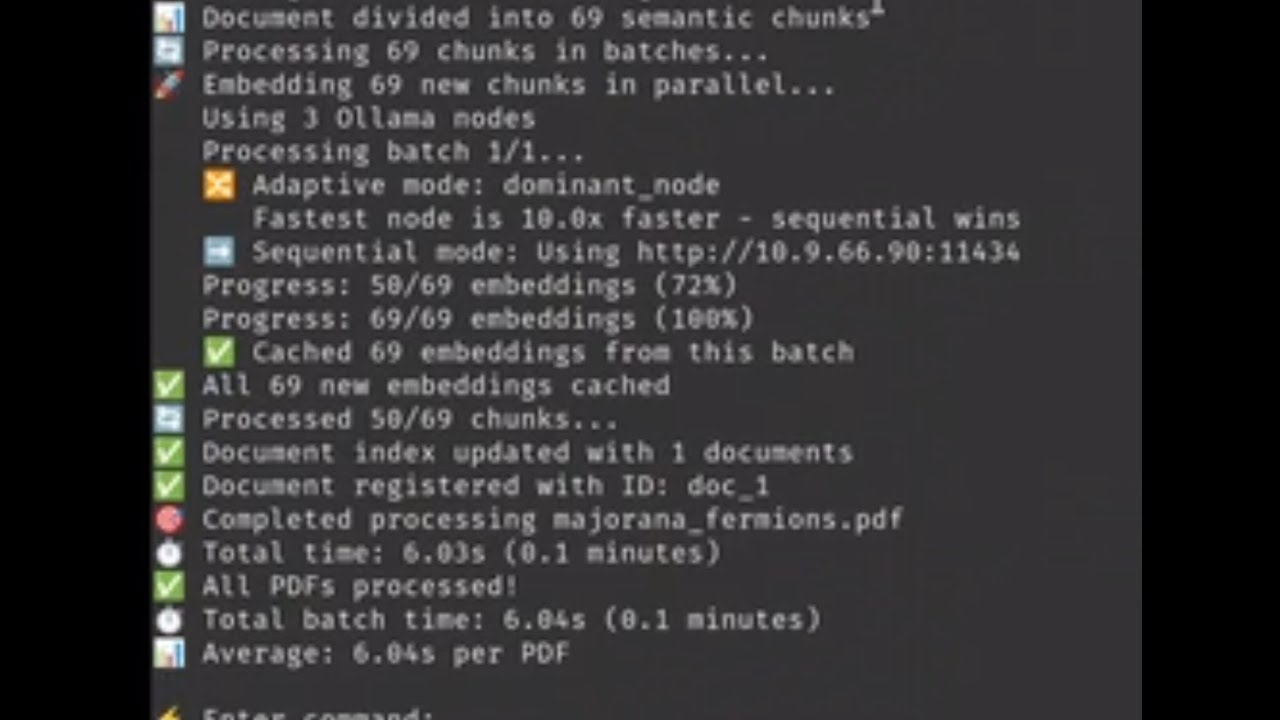
What you'll see:
- Single CPU node (372.76s) → Parallel processing (159.79s) → GPU routing (6.04s)
- Real-time document processing with visible timing on screen
- Distributed chat functionality and MCP integration with Claude Desktop
- No editing tricks - all timing shown in real-time
📊 Quick Performance Reference
| Workload | Hardware | Time | Speedup | Notes |
|---|---|---|---|---|
| 5 AI papers (~350 pages) | 1× RTX A4000 (16GB) | 21.3s | 17.5× | Real arXiv showcase |
| 12-page PDF (demo video) | 1× RTX A4000 (16GB) | 6.0s | 61.7× | GPU-aware routing |
| 100 PDFs (2000 pages) | 3-node cluster (mixed) | 3.2 min | 13.2× | See BENCHMARKS.md |
| Embedding generation | RTX A4000 vs i9 CPU | 8.2s vs 178s | 21.7× | 10K chunks |
🎯 Try it yourself: pip install flockparser && python showcase/process_arxiv_papers.py
🔒 Privacy Model
| Interface | Privacy Level | External Calls | Best For |
|---|---|---|---|
CLI (flockparsecli.py) |
🟢 100% Local | None | Personal use, air-gapped systems |
Web UI (flock_webui.py) |
🟢 100% Local | None | GUI users, visual monitoring |
REST API (flock_ai_api.py) |
🟡 Local Network | None | Multi-user, app integration |
MCP Server (flock_mcp_server.py) |
🔴 Cloud | ⚠️ Claude Desktop (Anthropic) | AI assistant integration |
⚠️ MCP Privacy Warning: The MCP server integrates with Claude Desktop, which sends queries and document snippets to Anthropic's cloud API. Use CLI/Web UI for 100% offline processing.
Table of Contents
- Key Features
- 👥 Who Uses This? - Target users & scenarios
- 📐 How It Works (5-Second Overview) - Visual for non-technical evaluators
- Architecture | 📖 Deep Dive: Architecture & Design Decisions
- Quickstart
- Performance & Benchmarks
- 🎓 Showcase: Real-World Example ⭐ Try it yourself
- Usage Examples
- Security & Production
- Troubleshooting
- Contributing
⚡ Key Features
- 🌐 Intelligent Load Balancing - Auto-discovers Ollama nodes, detects GPU vs CPU, monitors VRAM, and routes work adaptively (10x speedup on heterogeneous clusters)
- 🔌 Multi-Protocol Support - CLI (100% local), REST API (network), MCP (Claude Desktop), Web UI (Streamlit) - choose your privacy level
- 🎯 Adaptive Routing - Sequential vs parallel decisions based on cluster characteristics (prevents slow nodes from bottlenecking)
- 📊 Production Observability - Real-time health scores, performance tracking, VRAM monitoring, automatic failover
- 🔒 Privacy-First Architecture - No external API calls required (CLI mode), all processing on-premise
- 📄 Complete Pipeline - PDF extraction → OCR fallback → Multi-format conversion → Vector embeddings → RAG with source citations
👥 Who Uses This?
FlockParser is designed for engineers and researchers who need private, on-premise document intelligence with real distributed systems capabilities.
Ideal Users
| User Type | Use Case | Why FlockParser? |
|---|---|---|
| 🔬 ML/AI Engineers | Process research papers, build knowledge bases, experiment with RAG systems | GPU-aware routing, 21× faster embeddings, full pipeline control |
| 📊 Data Scientists | Extract insights from large document corpora (100s-1000s of PDFs) | Distributed processing, semantic search, production observability |
| 🏢 Enterprise Engineers | On-premise document search for regulated industries (healthcare, legal, finance) | 100% local processing, no cloud APIs, privacy-first architecture |
| 🎓 Researchers | Build custom RAG systems, experiment with distributed inference patterns | Full source access, extensible architecture, real benchmarks |
| 🛠️ DevOps/Platform Engineers | Set up document intelligence infrastructure for teams | Multi-node setup, health monitoring, automatic failover |
| 👨💻 Students/Learners | Understand distributed systems, GPU orchestration, RAG architectures | Real working example, comprehensive docs, honest limitations |
Real-World Scenarios
✅ "I have 500 research papers and a spare GPU machine" → Process your corpus 20× faster with distributed nodes ✅ "I can't send medical records to OpenAI" → 100% local processing (CLI/Web UI modes) ✅ "I want to experiment with RAG without cloud costs" → Full pipeline, runs on your hardware ✅ "I need to search 10,000 internal documents" → ChromaDB vector search with sub-20ms latency ✅ "I have mismatched hardware (old laptop + gaming PC)" → Adaptive routing handles heterogeneous clusters
Not Ideal For
❌ Production SaaS with 1000+ concurrent users → Current SQLite backend limits concurrency (~50 users)
❌ Mission-critical systems requiring 99.9% uptime → Still in Beta, see KNOWN_ISSUES.md
❌ Simple one-time PDF extraction → Overkill; use pdfplumber directly
❌ Cloud-first deployments → Designed for on-premise/hybrid; cloud works but misses GPU routing benefits
Bottom line: If you're building document intelligence infrastructure on your own hardware and need distributed processing with privacy guarantees, FlockParser is for you.
📐 How It Works (5-Second Overview)
For recruiters and non-technical evaluators:
┌─────────────────────────────────────────────────────────────────┐
│ INPUT │
│ 📄 Your Documents (PDFs, research papers, internal docs) │
└────────────────────────┬────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ FLOCKPARSER │
│ │
│ 1. Extracts text from PDFs (handles scans with OCR) │
│ 2. Splits into chunks, creates vector embeddings │
│ 3. Distributes work across GPU/CPU nodes (auto-discovery) │
│ 4. Stores in searchable vector database (ChromaDB) │
│ │
│ ⚡ Distributed Processing: 3 nodes → 13× faster │
│ 🚀 GPU Acceleration: RTX A4000 → 61× faster than CPU │
│ 🔒 Privacy: 100% local (no cloud APIs) │
└────────────────────────┬────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ OUTPUT │
│ 🔍 Semantic Search: "Find all mentions of transformers" │
│ 💬 AI Chat: "Summarize the methodology section" │
│ 📊 Source Citations: Exact page/document references │
│ 🌐 4 Interfaces: CLI, Web UI, REST API, Claude Desktop │
└─────────────────────────────────────────────────────────────────┘
Key Innovation: Auto-detects GPU nodes, measures performance, and routes work to fastest hardware. No manual configuration needed.
🏗️ Architecture
┌─────────────────────────────────────────────────────────────┐
│ Interfaces (Choose Your Privacy Level) │
│ CLI (Local) | REST API (Network) | MCP (Claude) | Web UI │
└──────────────────────┬──────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ FlockParse Core Engine │
│ ┌─────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ PDF │ │ Semantic │ │ RAG │ │
│ │ Processing │→ │ Search │→ │ Engine │ │
│ └─────────────┘ └──────────────┘ └──────────────┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌───────────────────────────────────────────────────┐ │
│ │ ChromaDB Vector Store (Persistent) │ │
│ └───────────────────────────────────────────────────┘ │
└──────────────────────┬──────────────────────────────────────┘
│ Intelligent Load Balancer
│ • Health scoring (GPU/VRAM detection)
│ • Adaptive routing (sequential vs parallel)
│ • Automatic failover & caching
▼
┌──────────────────────────────────────────────┐
│ Distributed Ollama Cluster │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Node 1 │ │ Node 2 │ │ Node 3 │ │
│ │ GPU A │ │ GPU B │ │ CPU │ │
│ │16GB VRAM │ │ 8GB VRAM │ │ 16GB RAM │ │
│ │Health:367│ │Health:210│ │Health:50 │ │
│ └──────────┘ └──────────┘ └──────────┘ │
└──────────────────────────────────────────────┘
▲ Auto-discovery | Performance tracking
Want to understand how this works? Read the 📖 Architecture Deep Dive for detailed explanations of:
- Why distributed AI inference solves real-world problems
- How adaptive routing decisions are made (sequential vs parallel)
- MCP integration details and privacy implications
- Technical trade-offs and design decisions
🚀 Quickstart (3 Steps)
Requirements:
- Python 3.10 or later
- Ollama 0.1.20+ (install from ollama.com)
- 4GB+ RAM (8GB+ recommended for GPU nodes)
# 1. Install FlockParser
pip install flockparser
# 2. Start Ollama and pull models
ollama serve # In a separate terminal
ollama pull mxbai-embed-large # Required for embeddings
ollama pull llama3.1:latest # Required for chat
# 3. Run your preferred interface
flockparse-webui # Web UI - easiest (recommended) ⭐
flockparse # CLI - 100% local
flockparse-api # REST API - multi-user
flockparse-mcp # MCP - Claude Desktop integration
💡 Pro tip: Start with the Web UI to see distributed processing with real-time VRAM monitoring and node health dashboards.
Alternative: Install from Source
If you want to contribute or modify the code:
git clone https://github.com/BenevolentJoker-JohnL/FlockParser.git
cd FlockParser
pip install -e . # Editable install
Quick Test (30 seconds)
# Start the CLI
python flockparsecli.py
# Process the sample PDF
> open_pdf testpdfs/sample.pdf
# Chat with it
> chat
🙋 You: Summarize this document
First time? Start with the Web UI (streamlit run flock_webui.py) - it's the easiest way to see distributed processing in action with a visual dashboard.
🐳 Docker Deployment (One Command)
Quick Start with Docker Compose
# Clone and deploy everything
git clone https://github.com/BenevolentJoker-JohnL/FlockParser.git
cd FlockParser
docker-compose up -d
# Access services
# Web UI: http://localhost:8501
# REST API: http://localhost:8000
# Ollama: http://localhost:11434
What Gets Deployed
| Service | Port | Description |
|---|---|---|
| Web UI | 8501 | Streamlit interface with visual monitoring |
| REST API | 8000 | FastAPI with authentication |
| CLI | - | Interactive terminal (docker-compose run cli) |
| Ollama | 11434 | Local LLM inference engine |
Production Features
✅ Multi-stage build - Optimized image size ✅ Non-root user - Security hardened ✅ Health checks - Auto-restart on failure ✅ Volume persistence - Data survives restarts ✅ GPU support - Uncomment deploy section for NVIDIA GPUs
Custom Configuration
# Set API key
export FLOCKPARSE_API_KEY="your-secret-key"
# Set log level
export LOG_LEVEL="DEBUG"
# Deploy with custom config
docker-compose up -d
GPU Support (NVIDIA)
Uncomment the GPU section in docker-compose.yml:
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
Then run: docker-compose up -d
CI/CD Pipeline
graph LR
A[📝 Git Push] --> B[🔍 Lint & Format]
B --> C[🧪 Test Suite]
B --> D[🔒 Security Scan]
C --> E[🐳 Build Multi-Arch]
D --> E
E --> F[📦 Push to GHCR]
F --> G[🚀 Deploy]
style A fill:#4CAF50
style B fill:#2196F3
style C fill:#2196F3
style D fill:#FF9800
style E fill:#9C27B0
style F fill:#9C27B0
style G fill:#F44336
Automated on every push to main:
| Stage | Tools | Purpose |
|---|---|---|
| Code Quality | black, flake8, mypy | Enforce formatting & typing standards |
| Testing | pytest (Python 3.10/3.11/3.12) | 78% coverage across versions |
| Security | Trivy | Vulnerability scanning & SARIF reports |
| Build | Docker Buildx | Multi-architecture (amd64, arm64) |
| Registry | GitHub Container Registry | Versioned image storage |
| Deploy | On release events | Automated production deployment |
Pull the latest image:
docker pull ghcr.io/benevolentjoker-johnl/flockparser:latest
View pipeline runs: https://github.com/BenevolentJoker-JohnL/FlockParser/actions
🌐 Setting Up Distributed Nodes
Want the 60x speedup? Set up multiple Ollama nodes across your network.
Quick Multi-Node Setup
On each additional machine:
# 1. Install Ollama
curl -fsSL https://ollama.com/install.sh | sh
# 2. Configure for network access
export OLLAMA_HOST=0.0.0.0:11434
ollama serve
# 3. Pull models
ollama pull mxbai-embed-large
ollama pull llama3.1:latest
# 4. Allow firewall (if needed)
sudo ufw allow 11434/tcp # Linux
FlockParser will automatically discover these nodes!
Check with:
python flockparsecli.py
> lb_stats # Shows all discovered nodes and their capabilities
📖 Complete Guide: See DISTRIBUTED_SETUP.md for:
- Step-by-step multi-machine setup
- Network configuration and firewall rules
- Troubleshooting node discovery
- Example setups (budget home lab to professional clusters)
- GPU router configuration for automatic optimization
🔒 Privacy Levels by Interface:
- Web UI (
flock_webui.py): 🟢 100% local, runs in your browser - CLI (
flockparsecli.py): 🟢 100% local, zero external calls - REST API (
flock_ai_api.py): 🟡 Local network only - MCP Server (
flock_mcp_server.py): 🔴 Integrates with Claude Desktop (Anthropic cloud service)
Choose the interface that matches your privacy requirements!
🏆 Why FlockParse? Comparison to Competitors
| Feature | FlockParse | LangChain | LlamaIndex | Haystack |
|---|---|---|---|---|
| 100% Local/Offline | ✅ Yes (CLI/JSON) | ⚠️ Partial | ⚠️ Partial | ⚠️ Partial |
| Zero External API Calls | ✅ Yes (CLI/JSON) | ❌ No | ❌ No | ❌ No |
| Built-in GPU Load Balancing | ✅ Yes (auto) | ❌ No | ❌ No | ❌ No |
| VRAM Monitoring | ✅ Yes (dynamic) | ❌ No | ❌ No | ❌ No |
| Multi-Node Auto-Discovery | ✅ Yes | ❌ No | ❌ No | ❌ No |
| CPU Fallback Detection | ✅ Yes | ❌ No | ❌ No | ❌ No |
| Document Format Export | ✅ 4 formats | ❌ Limited | ❌ Limited | ⚠️ Basic |
| Setup Complexity | 🟢 Simple | 🔴 Complex | 🔴 Complex | 🟡 Medium |
| Dependencies | 🟢 Minimal | 🔴 Heavy | 🔴 Heavy | 🟡 Medium |
| Learning Curve | 🟢 Low | 🔴 Steep | 🔴 Steep | 🟡 Medium |
| Privacy Control | 🟢 High (CLI/JSON) | 🔴 Limited | 🔴 Limited | 🟡 Medium |
| Out-of-Box Functionality | ✅ Complete | ⚠️ Requires config | ⚠️ Requires config | ⚠️ Requires config |
| MCP Integration | ✅ Native | ❌ No | ❌ No | ❌ No |
| Embedding Cache | ✅ MD5-based | ⚠️ Basic | ⚠️ Basic | ⚠️ Basic |
| Batch Processing | ✅ Parallel | ⚠️ Sequential | ⚠️ Sequential | ⚠️ Basic |
| Performance | 🚀 60x+ faster with GPU auto-routing | ⚠️ Varies by config | ⚠️ Varies by config | ⚠️ Varies by config |
| Cost | 💰 Free | 💰💰 Free + Paid | 💰💰 Free + Paid | 💰💰 Free + Paid |
Key Differentiators:
- Privacy by Design: CLI and JSON interfaces are 100% local with zero external calls (MCP interface uses Claude Desktop for chat)
- Intelligent GPU Management: Automatically finds, tests, and prioritizes GPU nodes
- Production-Ready: Works immediately with sensible defaults
- Resource-Aware: Detects VRAM exhaustion and prevents performance degradation
- Complete Solution: CLI, REST API, MCP, and batch interfaces - choose your privacy level
📊 Performance
📹 76-Second Demo Video - Watch 6 minutes become 6 seconds
Real-Time Demo Results (unedited timing shown on screen):
| Processing Mode | Time | Speedup | What It Shows |
|---|---|---|---|
| Single CPU node | 372.76s (~6 min) | 1x baseline | Sequential CPU processing |
| Parallel (multi-node) | 159.79s (~2.5 min) | 2.3x faster | Distributed across cluster |
| GPU node routing | 6.04s (~6 sec) | 61.7x faster | Automatic GPU detection & routing |
Why the Massive Speedup?
- GPU processes embeddings in milliseconds vs seconds on CPU
- Adaptive routing detected GPU was 60x+ faster and sent all work there
- Avoided bottleneck of waiting for slower CPU nodes to finish
- No network overhead (local cluster, no cloud APIs)
Demo Contents:
0:00- Single node baseline (372.76s)0:30- Auto-discover cluster nodes on network0:45- Parallel processing across nodes (159.79s)1:00- GPU routing with adaptive decision (6.04s)1:10- Document chat with RAG + source citations1:15- MCP integration with Claude Desktop
Key Insight: The system automatically detected performance differences and made routing decisions - no manual GPU configuration needed.
Hardware (Demo Cluster):
- Node 1 (10.9.66.90): Intel i9-12900K, 32GB DDR5-6000, 6TB NVMe Gen4, RTX A4000 16GB - routed here
- Node 2 (10.9.66.159): AMD Ryzen 7 5700X, 32GB DDR4-3600, GTX 1050Ti (CPU-mode)
- Node 3: Intel i7-12th gen (laptop), 16GB DDR5, CPU-only
- Software: Python 3.10, Ollama, Ubuntu 22.04
Reproducibility:
- Timing shown on-screen in real-time (not edited)
- Commands visible in terminal output
- Full source code available in this repo
- Test with your own hardware - results will vary based on GPU
The project offers four main interfaces:
- flock_webui.py - 🎨 Beautiful Streamlit web interface (NEW!)
- flockparsecli.py - Command-line interface for personal document processing
- flock_ai_api.py - REST API server for multi-user or application integration
- flock_mcp_server.py - Model Context Protocol server for AI assistants like Claude Desktop
🎓 Showcase: Real-World Example
Processing influential AI research papers from arXiv.org
Want to see FlockParser in action on real documents? Run the included showcase:
pip install flockparser
python showcase/process_arxiv_papers.py
What It Does
Downloads and processes 5 seminal AI research papers:
- Attention Is All You Need (Transformers) - arXiv:1706.03762
- BERT - Pre-training Deep Bidirectional Transformers - arXiv:1810.04805
- RAG - Retrieval-Augmented Generation for NLP - arXiv:2005.11401
- GPT-3 - Language Models are Few-Shot Learners - arXiv:2005.14165
- Llama 2 - Open Foundation Language Models - arXiv:2307.09288
Total: ~350 pages, ~25 MB of PDFs
Expected Results
| Configuration | Processing Time | Speedup |
|---|---|---|
| Single CPU node | ~90s | 1.0× baseline |
| Multi-node (1 GPU + 2 CPU) | ~30s | 3.0× |
| Single GPU node (RTX A4000) | ~21s | 4.3× |
What You Get
After processing, the script demonstrates:
-
Semantic Search across all papers:
# Example queries that work immediately: "What is the transformer architecture?" "How does retrieval-augmented generation work?" "What are the benefits of attention mechanisms?"
-
Performance Metrics (
showcase/results.json):{ "total_time": 21.3, "papers": [ { "title": "Attention Is All You Need", "processing_time": 4.2, "status": "success" } ], "node_info": [...] }
-
Human-Readable Summary (
showcase/RESULTS.md) with:- Per-paper processing times
- Hardware configuration used
- Fastest/slowest/average performance
- Replication instructions
Why This Matters
This isn't a toy demo - it's processing actual research papers that engineers read daily. It demonstrates:
✅ Real document processing - Complex PDFs with equations, figures, multi-column layouts
✅ Production-grade pipeline - PDF extraction → embeddings → vector storage → semantic search
✅ Actual performance gains - Measurable speedups on heterogeneous hardware
✅ Reproducible results - Run it yourself with pip install, compare your hardware
Perfect for portfolio demonstrations: Show this to hiring managers as proof of real distributed systems work.
🔧 Installation
1. Clone the Repository
git clone https://github.com/yourusername/flockparse.git
cd flockparse
2. Install System Dependencies (Required for OCR)
⚠️ IMPORTANT: Install these BEFORE pip install, as pytesseract and pdf2image require system packages
For Better PDF Text Extraction:
- Linux:
sudo apt-get update sudo apt-get install poppler-utils
- macOS:
brew install poppler
- Windows: Download from Poppler for Windows
For OCR Support (Scanned Documents):
FlockParse automatically detects scanned PDFs and uses OCR!
- Linux (Ubuntu/Debian):
sudo apt-get update sudo apt-get install tesseract-ocr tesseract-ocr-eng poppler-utils
- Linux (Fedora/RHEL):
sudo dnf install tesseract poppler-utils
- macOS:
brew install tesseract poppler
- Windows:
- Install Tesseract OCR - Download the installer
- Install Poppler for Windows
- Add both to your system PATH
Verify installation:
tesseract --version
pdftotext -v
3. Install Python Dependencies
pip install -r requirements.txt
Key Python dependencies (installed automatically):
- fastapi, uvicorn - Web server
- pdfplumber, PyPDF2, pypdf - PDF processing
- pytesseract - Python wrapper for Tesseract OCR (requires system Tesseract)
- pdf2image - PDF to image conversion (requires system Poppler)
- Pillow - Image processing for OCR
- chromadb - Vector database
- python-docx - DOCX generation
- ollama - AI model integration
- numpy - Numerical operations
- markdown - Markdown generation
How OCR fallback works:
- Tries PyPDF2 text extraction
- Falls back to pdftotext if no text
- Falls back to OCR if still no text (<100 chars) - Requires Tesseract + Poppler
- Automatically processes scanned documents without manual intervention
4. Install and Configure Ollama
- Install Ollama from ollama.com
- Start the Ollama service:
ollama serve - Pull the required models:
ollama pull mxbai-embed-large ollama pull llama3.1:latest
📜 Usage
🎨 Web UI (flock_webui.py) - Easiest Way to Get Started!
Launch the beautiful Streamlit web interface:
streamlit run flock_webui.py
The web UI will open in your browser at http://localhost:8501
Features:
- 📤 Upload & Process: Drag-and-drop PDF files for processing
- 💬 Chat Interface: Interactive chat with your documents
- 📊 Load Balancer Dashboard: Real-time monitoring of GPU nodes
- 🔍 Semantic Search: Search across all documents
- 🌐 Node Management: Add/remove Ollama nodes, auto-discovery
- 🎯 Routing Control: Switch between routing strategies
Perfect for:
- Users who prefer graphical interfaces
- Quick document processing and exploration
- Monitoring distributed processing
- Managing multiple Ollama nodes visually
CLI Interface (flockparsecli.py)
Run the script:
python flockparsecli.py
Available commands:
📖 open_pdf <file> → Process a single PDF file
📂 open_dir <dir> → Process all PDFs in a directory
💬 chat → Chat with processed PDFs
📊 list_docs → List all processed documents
🔍 check_deps → Check for required dependencies
🌐 discover_nodes → Auto-discover Ollama nodes on local network
➕ add_node <url> → Manually add an Ollama node
➖ remove_node <url> → Remove an Ollama node from the pool
📋 list_nodes → List all configured Ollama nodes
⚖️ lb_stats → Show load balancer statistics
❌ exit → Quit the program
Web Server API (flock_ai_api.py)
Start the API server:
# Set your API key (or use default for testing)
export FLOCKPARSE_API_KEY="your-secret-key-here"
# Start server
python flock_ai_api.py
The server will run on http://0.0.0.0:8000 by default.
🔒 Authentication (NEW!)
All endpoints except / require an API key in the X-API-Key header:
# Default API key (change in production!)
X-API-Key: your-secret-api-key-change-this
# Or set via environment variable
export FLOCKPARSE_API_KEY="my-super-secret-key"
Available Endpoints:
| Endpoint | Method | Auth Required | Description |
|---|---|---|---|
/ |
GET | ❌ No | API status and version info |
/upload/ |
POST | ✅ Yes | Upload and process a PDF file |
/summarize/{file_name} |
GET | ✅ Yes | Get an AI-generated summary |
/search/?query=... |
GET | ✅ Yes | Search for relevant documents |
Example API Usage:
Check API status (no auth required):
curl http://localhost:8000/
Upload a document (with authentication):
curl -X POST \
-H "X-API-Key: your-secret-api-key-change-this" \
-F "file=@your_document.pdf" \
http://localhost:8000/upload/
Get a document summary:
curl -H "X-API-Key: your-secret-api-key-change-this" \
http://localhost:8000/summarize/your_document.pdf
Search across documents:
curl -H "X-API-Key: your-secret-api-key-change-this" \
"http://localhost:8000/search/?query=your%20search%20query"
⚠️ Production Security:
- Always change the default API key
- Use environment variables, never hardcode keys
- Use HTTPS in production (nginx/apache reverse proxy)
- Consider rate limiting for public deployments
MCP Server (flock_mcp_server.py)
The MCP server allows FlockParse to be used as a tool by AI assistants like Claude Desktop.
Setting up with Claude Desktop
-
Start the MCP server:
python flock_mcp_server.py -
Configure Claude Desktop: Add to your Claude Desktop config file (
~/Library/Application Support/Claude/claude_desktop_config.jsonon macOS, or%APPDATA%\Claude\claude_desktop_config.jsonon Windows):{ "mcpServers": { "flockparse": { "command": "python", "args": ["/absolute/path/to/FlockParser/flock_mcp_server.py"] } } }
-
Restart Claude Desktop and you'll see FlockParse tools available!
Available MCP Tools:
process_pdf- Process and add PDFs to the knowledge basequery_documents- Search documents using semantic searchchat_with_documents- Ask questions about your documentslist_documents- List all processed documentsget_load_balancer_stats- View node performance metricsdiscover_ollama_nodes- Auto-discover Ollama nodesadd_ollama_node- Add an Ollama node manuallyremove_ollama_node- Remove an Ollama node
Example MCP Usage:
In Claude Desktop, you can now ask:
- "Process the PDF at /path/to/document.pdf"
- "What documents do I have in my knowledge base?"
- "Search my documents for information about quantum computing"
- "What does my research say about black holes?"
💡 Practical Use Cases
Knowledge Management
- Create searchable archives of research papers, legal documents, and technical manuals
- Generate summaries of lengthy documents for quick review
- Chat with your document collection to find specific information without manual searching
Legal & Compliance
- Process contract repositories for semantic search capabilities
- Extract key terms and clauses from legal documents
- Analyze regulatory documents for compliance requirements
Research & Academia
- Process and convert academic papers for easier reference
- Create a personal research assistant that can reference your document library
- Generate summaries of complex research for presentations or reviews
Business Intelligence
- Convert business reports into searchable formats
- Extract insights from PDF-based market research
- Make proprietary documents more accessible throughout an organization
🌐 Distributed Processing with Load Balancer
FlockParse includes a sophisticated load balancer that can distribute embedding generation across multiple Ollama instances on your local network.
Setting Up Distributed Processing
Option 1: Auto-Discovery (Easiest)
# Start FlockParse
python flockparsecli.py
# Auto-discover Ollama nodes on your network
⚡ Enter command: discover_nodes
The system will automatically scan your local network (/24 subnet) and detect any running Ollama instances.
Option 2: Manual Node Management
# Add a specific node
⚡ Enter command: add_node http://192.168.1.100:11434
# List all configured nodes
⚡ Enter command: list_nodes
# Remove a node
⚡ Enter command: remove_node http://192.168.1.100:11434
# View load balancer statistics
⚡ Enter command: lb_stats
Benefits of Distributed Processing
- Speed: Process documents 2-10x faster with multiple nodes
- GPU Awareness: Automatically detects and prioritizes GPU nodes over CPU nodes
- VRAM Monitoring: Detects when GPU nodes fall back to CPU due to insufficient VRAM
- Fault Tolerance: Automatic failover if a node becomes unavailable
- Load Distribution: Smart routing based on node performance, GPU availability, and VRAM capacity
- Easy Scaling: Just add more machines with Ollama installed
Setting Up Additional Ollama Nodes
On each additional machine:
# Install Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Pull the embedding model
ollama pull mxbai-embed-large
# Start Ollama (accessible from network)
OLLAMA_HOST=0.0.0.0:11434 ollama serve
Then use discover_nodes or add_node to add them to FlockParse.
GPU and VRAM Optimization
FlockParse automatically detects GPU availability and VRAM usage using Ollama's /api/ps endpoint:
- 🚀 GPU nodes with models loaded in VRAM get +200 health score bonus
- ⚠️ VRAM-limited nodes that fall back to CPU get only +50 bonus
- 🐢 CPU-only nodes get -50 penalty
To ensure your GPU is being used:
- Check GPU detection: Run
lb_statscommand to see node status - Preload model into GPU: Run a small inference to load model into VRAM
ollama run mxbai-embed-large "test"
- Verify VRAM usage: Check that
size_vram > 0in/api/ps:curl http://localhost:11434/api/ps - Increase VRAM allocation: If model won't load into VRAM, free up GPU memory or use a smaller model
Dynamic VRAM monitoring: FlockParse continuously monitors embedding performance and automatically detects when a GPU node falls back to CPU due to VRAM exhaustion during heavy load.
🔄 Example Workflows
CLI Workflow: Research Paper Processing
-
Check Dependencies:
⚡ Enter command: check_deps -
Process a Directory of Research Papers:
⚡ Enter command: open_dir ~/research_papers -
Chat with Your Research Collection:
⚡ Enter command: chat 🙋 You: What are the key methods used in the Smith 2023 paper?
API Workflow: Document Processing Service
-
Start the API Server:
python flock_ai_api.py -
Upload Documents via API:
curl -X POST -F "file=@quarterly_report.pdf" http://localhost:8000/upload/
-
Generate a Summary:
curl http://localhost:8000/summarize/quarterly_report.pdf -
Search Across Documents:
curl http://localhost:8000/search/?query=revenue%20growth%20Q3
🔧 Troubleshooting Guide
Ollama Connection Issues
Problem: Error messages about Ollama not being available or connection failures.
Solution:
- Verify Ollama is running:
ps aux | grep ollama - Restart the Ollama service:
killall ollama ollama serve
- Check that you've pulled the required models:
ollama list - If models are missing:
ollama pull mxbai-embed-large ollama pull llama3.1:latest
PDF Text Extraction Failures
Problem: No text extracted from certain PDFs.
Solution:
-
Check if the PDF is scanned/image-based:
- Install OCR tools:
sudo apt-get install tesseract-ocr(Linux) - For better scanned PDF handling:
pip install ocrmypdf - Process with OCR:
ocrmypdf input.pdf output.pdf
- Install OCR tools:
-
If the PDF has unusual fonts or formatting:
- Install poppler-utils for better extraction
- Try using the
-layoutoption with pdftotext manually:pdftotext -layout problem_document.pdf output.txt
Memory Issues with Large Documents
Problem: Application crashes with large PDFs or many documents.
Solution:
- Process one document at a time for very large PDFs
- Reduce the chunk size in the code (default is 512 characters)
- Increase your system's available memory or use a swap file
- For server deployments, consider using a machine with more RAM
API Server Not Starting
Problem: Error when trying to start the API server.
Solution:
- Check for port conflicts:
lsof -i :8000 - If another process is using port 8000, kill it or change the port
- Verify FastAPI is installed:
pip install fastapi uvicorn - Check for Python version compatibility (requires Python 3.7+)
🔐 Security & Production Notes
REST API Security
⚠️ The default API key is NOT secure - change it immediately!
# Set a strong API key via environment variable
export FLOCKPARSE_API_KEY="your-super-secret-key-change-this-now"
# Or generate a random one
export FLOCKPARSE_API_KEY=$(openssl rand -hex 32)
# Start the API server
python flock_ai_api.py
Production Checklist:
- ✅ Change default API key - Never use
your-secret-api-key-change-this - ✅ Use environment variables - Never hardcode secrets in code
- ✅ Enable HTTPS - Use nginx or Apache as reverse proxy with SSL/TLS
- ✅ Add rate limiting - Use nginx
limit_reqor FastAPI middleware - ✅ Network isolation - Don't expose API to public internet unless necessary
- ✅ Monitor logs - Watch for authentication failures and abuse
Example nginx config with TLS:
server {
listen 443 ssl;
server_name your-domain.com;
ssl_certificate /path/to/cert.pem;
ssl_certificate_key /path/to/key.pem;
location / {
proxy_pass http://127.0.0.1:8000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
MCP Privacy & Security
What data leaves your machine:
- 🔴 Document queries - Sent to Claude Desktop → Anthropic API
- 🔴 Document snippets - Retrieved context chunks sent as part of prompts
- 🔴 Chat messages - All RAG conversations processed by Claude
- 🟢 Document files - Never uploaded (processed locally, only embeddings stored)
To disable MCP and stay 100% local:
- Remove FlockParse from Claude Desktop config
- Use CLI (
flockparsecli.py) or Web UI (flock_webui.py) instead - Both provide full RAG functionality without external API calls
MCP is safe for:
- ✅ Public documents (research papers, manuals, non-sensitive data)
- ✅ Testing and development
- ✅ Personal use where you trust Anthropic's privacy policy
MCP is NOT recommended for:
- ❌ Confidential business documents
- ❌ Personal identifiable information (PII)
- ❌ Regulated data (HIPAA, GDPR sensitive content)
- ❌ Air-gapped or classified environments
Database Security
SQLite limitations (ChromaDB backend):
- ⚠️ No concurrent writes from multiple processes
- ⚠️ File permissions determine access (not true auth)
- ⚠️ No encryption at rest by default
For production with multiple users:
# Option 1: Separate databases per interface
CLI: chroma_db_cli/
API: chroma_db_api/
MCP: chroma_db_mcp/
# Option 2: Use PostgreSQL backend (ChromaDB supports it)
# See ChromaDB docs: https://docs.trychroma.com/
VRAM Detection Method
FlockParse detects GPU usage via Ollama's /api/ps endpoint:
# Check what Ollama reports
curl http://localhost:11434/api/ps
# Response shows VRAM usage:
{
"models": [{
"name": "mxbai-embed-large:latest",
"size": 705530880,
"size_vram": 705530880, # <-- If >0, model is in GPU
...
}]
}
Health score calculation:
size_vram > 0→ +200 points (GPU in use)size_vram == 0but GPU present → +50 points (GPU available, not used)- CPU-only → -50 points
This is presence-based detection, not utilization monitoring. It detects if the model loaded into VRAM, not how efficiently it's being used.
💡 Features
| Feature | Description |
|---|---|
| Multi-method PDF Extraction | Uses both PyPDF2 and pdftotext for best results |
| Format Conversion | Converts PDFs to TXT, Markdown, DOCX, and JSON |
| Semantic Search | Uses vector embeddings to find relevant information |
| Interactive Chat | Discuss your documents with AI assistance |
| Privacy Options | Web UI/CLI: 100% offline; REST API: local network; MCP: Claude Desktop (cloud) |
| Distributed Processing | Load balancer with auto-discovery for multiple Ollama nodes |
| Accurate VRAM Monitoring | Real GPU memory tracking with nvidia-smi/rocm-smi + Ollama API (NEW!) |
| GPU & VRAM Awareness | Automatically detects GPU nodes and prevents CPU fallback |
| Intelligent Routing | 4 strategies (adaptive, round_robin, least_loaded, lowest_latency) with GPU priority |
| Flexible Model Matching | Supports model name variants (llama3.1, llama3.1:latest, llama3.1:8b, etc.) |
| ChromaDB Vector Store | Production-ready persistent vector database with cosine similarity |
| Embedding Cache | MD5-based caching prevents reprocessing same content |
| Model Weight Caching | Keep models in VRAM for faster repeated inference |
| Parallel Batch Processing | Process multiple embeddings simultaneously |
| Database Management | Clear cache and clear DB commands for easy maintenance (NEW!) |
| Filename Preservation | Maintains original document names in converted files |
| REST API | Web server for multi-user/application integration |
| Document Summarization | AI-generated summaries of uploaded documents |
| OCR Processing | Extract text from scanned documents using image recognition |
Comparing FlockParse Interfaces
| Feature | flock_webui.py | flockparsecli.py | flock_ai_api.py | flock_mcp_server.py |
|---|---|---|---|---|
| Interface | 🎨 Web Browser (Streamlit) | Command line | REST API over HTTP | Model Context Protocol |
| Ease of Use | ⭐⭐⭐⭐⭐ Easiest | ⭐⭐⭐⭐ Easy | ⭐⭐⭐ Moderate | ⭐⭐⭐ Moderate |
| Use case | Interactive GUI usage | Personal CLI processing | Service integration | AI Assistant integration |
| Document formats | Creates TXT, MD, DOCX, JSON | Creates TXT, MD, DOCX, JSON | Stores extracted text only | Creates TXT, MD, DOCX, JSON |
| Interaction | Point-and-click + chat | Interactive chat mode | Query/response via API | Tool calls from AI assistants |
| Multi-user | Single user (local) | Single user | Multiple users/applications | Single user (via AI assistant) |
| Storage | Local file-based | Local file-based | ChromaDB vector database | Local file-based |
| Load Balancing | ✅ Yes (visual dashboard) | ✅ Yes | ❌ No | ✅ Yes |
| Node Discovery | ✅ Yes (one-click) | ✅ Yes | ❌ No | ✅ Yes |
| GPU Monitoring | ✅ Yes (real-time charts) | ✅ Yes | ❌ No | ✅ Yes |
| Batch Operations | ⚠️ Multiple upload | ❌ No | ❌ No | ❌ No |
| Privacy Level | 🟢 100% Local | 🟢 100% Local | 🟡 Local Network | 🔴 Cloud (Claude) |
| Best for | 🌟 General users, GUI lovers | Direct CLI usage | Integration with apps | Claude Desktop, AI workflows |
📁 Project Structure
/converted_files- Stores the converted document formats (flockparsecli.py)/knowledge_base- Legacy JSON storage (backwards compatibility only)/chroma_db_cli- ChromaDB vector database for CLI (flockparsecli.py) - Production storage/uploads- Temporary storage for uploaded documents (flock_ai_api.py)/chroma_db- ChromaDB vector database (flock_ai_api.py)
🚀 Recent Additions
- ✅ GPU Auto-Optimization - Background process ensures models use GPU automatically (NEW!)
- ✅ Programmatic GPU Control - Force models to GPU/CPU across distributed nodes (NEW!)
- ✅ Accurate VRAM Monitoring - Real GPU memory tracking across distributed nodes
- ✅ ChromaDB Production Integration - Professional vector database for 100x faster search
- ✅ Clear Cache & Clear DB Commands - Manage embeddings and database efficiently
- ✅ Model Weight Caching - Keep models in VRAM for 5-10x faster inference
- ✅ Web UI - Beautiful Streamlit interface for easy document management
- ✅ Advanced OCR Support - Automatic fallback to OCR for scanned documents
- ✅ API Authentication - Secure API key authentication for REST API endpoints
- ⬜ Document versioning - Track changes over time (Coming soon)
📚 Complete Documentation
Core Documentation
- 📖 Architecture Deep Dive - System design, routing algorithms, technical decisions
- 🌐 Distributed Setup Guide - ⭐ Set up your own multi-node cluster
- 📊 Performance Benchmarks - Real-world performance data and scaling tests
- ⚠️ Known Issues & Limitations - 🔴 READ THIS - Honest assessment of current state
- 🔒 Security Policy - Security best practices and vulnerability reporting
- 🐛 Error Handling Guide - Troubleshooting common issues
- 🤝 Contributing Guide - How to contribute to the project
- 📋 Code of Conduct - Community guidelines
- 📝 Changelog - Version history
Technical Guides
- ⚡ Performance Optimization - Tuning for maximum speed
- 🔧 GPU Router Setup - Distributed cluster configuration
- 🤖 GPU Auto-Optimization - Automatic GPU management
- 📊 VRAM Monitoring - GPU memory tracking
- 🎯 Adaptive Parallelism - Smart workload distribution
- 🗄️ ChromaDB Production - Vector database scaling
- 💾 Model Caching - Performance through caching
- 🖥️ Node Management - Managing distributed nodes
- ⚡ Quick Setup - Fast track to getting started
Additional Resources
- 📹 Demo Video (76 seconds) - Watch FlockParser in action
- 📦 Docker Setup - Containerized deployment
- ⚙️ Environment Config - Configuration template
- 🧪 Tests - Test suite and CI/CD
📝 Development Process
This project was developed iteratively using Claude and Claude Code as coding assistants. All design decisions, architecture choices, and integration strategy were directed and reviewed by me.
🤝 Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
📄 License
This project is licensed under the MIT License - see the LICENSE file for details.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file flockparser-1.0.4.tar.gz.
File metadata
- Download URL: flockparser-1.0.4.tar.gz
- Upload date:
- Size: 153.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
fb3a0e88ff5d6b783c5edcbdb347b6c46d17e6e266acca8e6efbc104d16e1125
|
|
| MD5 |
72134049d2b85565fb336368fae672fb
|
|
| BLAKE2b-256 |
ff39f2409fde6c1aaff002c3ec2de38dba93cf56feb7088b855bd9161c24aebe
|
File details
Details for the file flockparser-1.0.4-py3-none-any.whl.
File metadata
- Download URL: flockparser-1.0.4-py3-none-any.whl
- Upload date:
- Size: 77.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ce0cfa9181e3c01acc3d4266952754c4f2db739ee40af0f7b2eac0797a60685c
|
|
| MD5 |
fb04654c53757de49457988d9f6707cb
|
|
| BLAKE2b-256 |
8b3b4dd4265d4c9e6f14a5f10fb6a4eb14cb7315f9f0af89fddb8b339c04c77d
|







