Benchmark performance of **any model** on **any supported instance type** on Amazon SageMaker.

Project description
Foundation Model benchmarking tool (FMBench) built using Amazon SageMaker

A key challenge with FMs is the ability to benchmark their performance in terms of inference latency, throughput and cost so as to determine which model running with what combination of the hardware and serving stack provides the best price-performance combination for a given workload.
Stated as business problem, the ask is “What is the dollar cost per transaction for a given generative AI workload that serves a given number of users while keeping the response time under a target threshold?”
But to really answer this question, we need to answer an engineering question (an optimization problem, actually) corresponding to this business problem: “What is the minimum number of instances N, of most cost optimal instance type T, that are needed to serve a workload W while keeping the average transaction latency under L seconds?”
W: = {R transactions per-minute, average prompt token length P, average generation token length G}
This foundation model benchmarking tool (a.k.a. FMBench) is a tool to answer the above engineering question and thus answer the original business question about how to get the best price performance for a given workload. Here is one of the plots generated by FMBench to help answer the above question (the numbers on the y-axis, transactions per minute and latency have been removed from the image below, you can find them in the actual plot generated on running FMBench).
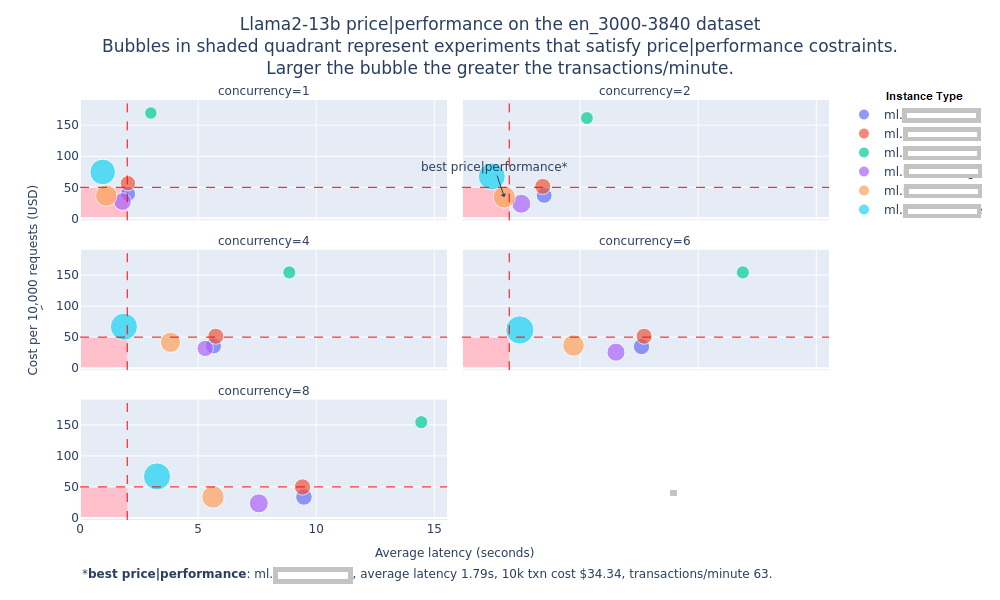
Description
The FMBench is a Python package for running performance benchmarks for any model on any supported instance type (g5, p4d, Inf2). FMBench deploys models on Amazon SageMaker and use the endpoint to send inference requests to and measure metrics such as inference latency, error rate, transactions per second etc. for different combinations of instance type, inference container and settings such as tensor parallelism etc. Because FMBench works for any model therefore it can be used not only testing third party models available on SageMaker, open-source models but also proprietary models trained by enterprises on their own data.
In a production system you may choose to deploy models outside of SageMaker such as on EC2 or EKS but even in those scenarios the benchmarking results from this tool can be used as a guide for determining the optimal instance type and serving stack (inference containers, configuration).
FMBench can be run on any AWS platform where we can run Python, such as Amazon EC2, Amazon SageMaker, or even the AWS CloudShell. It is important to run this tool on an AWS platform so that internet round trip time does not get included in the end-to-end response time latency.
The workflow for FMBench is as follows:
Create configuration file
|
|-----> Deploy model on SageMaker
|
|-----> Run inference against deployed endpoint(s)
|
|------> Create a benchmarking report
-
Create a dataset of different prompt sizes and select one or more such datasets for running the tests.
- Currently
FMBenchsupports datasets from LongBench and filter out individual items from the dataset based on their size in tokens (for example, prompts less than 500 tokens, between 500 to 1000 tokens and so on and so forth). Alternatively, you can download the folder from this link to load the data.
- Currently
-
Deploy any model that is deployable on SageMaker on any supported instance type (
g5,p4d,Inf2).- Models could be either available via SageMaker JumpStart (list available here) as well as models not available via JumpStart but still deployable on SageMaker through the low level boto3 (Python) SDK (Bring Your Own Script).
- Model deployment is completely configurable in terms of the inference container to use, environment variable to set,
setting.propertiesfile to provide (for inference containers such as DJL that use it) and instance type to use.
-
Benchmark FM performance in terms of inference latency, transactions per minute and dollar cost per transaction for any FM that can be deployed on SageMaker.
- Tests are run for each combination of the configured concurrency levels i.e. transactions (inference requests) sent to the endpoint in parallel and dataset. For example, run multiple datasets of say prompt sizes between 3000 to 4000 tokens at concurrency levels of 1, 2, 4, 6, 8 etc. so as to test how many transactions of what token length can the endpoint handle while still maintaining an acceptable level of inference latency.
-
Generate a report that compares and contrasts the performance of the model over different test configurations and stores the reports in an Amazon S3 bucket.
- The report is generated in the Markdown format and consists of plots, tables and text that highlight the key results and provide an overall recommendation on what is the best combination of instance type and serving stack to use for the model under stack for a dataset of interest.
- The report is created as an artifact of reproducible research so that anyone having access to the model, instance type and serving stack can run the code and recreate the same results and report.
-
Multiple configuration files that can be used as reference for benchmarking new models and instance types.
Getting started
FMBench is available as a Python package on PyPi and is run as a command line tool once it is installed. All data that includes metrics, reports and results are stored in an Amazon S3 bucket.
Quickstart
-
Launch the AWS CloudFormation template included in this repository using one of the buttons from the table below. The CloudFormation template creates the following resources within your AWS account: Amazon S3 buckets, Amazon IAM role and an Amazon SageMaker Notebook with this repository cloned. A read S3 bucket is created which contains all the files (configuration files, datasets) required to run
FMBenchand a write S3 bucket is created which will hold the metrics and reports generated byFMBench. The CloudFormation stack takes about 5-minutes to create.AWS Region Link us-east-1 (N. Virginia) -
Once the CloudFormation stack is created, navigate to SageMaker Notebooks and open the
fmbench-notebook. -
On the
fmbench-notebookopen a Terminal and run the following commands.conda create --name fmbench_python311 -y python=3.11 ipykernel source activate fmbench_python311; pip install fmbench
-
Now you are ready to
fmbenchwith the following command line. This would take about ~30 minutes to complete and will produce a report comparing the performance of Llama2-7b on different inference stacks.-
The following benchmark test requires one instance each of
ml.g5.xlargeandml.g5.2xlargeinstance types in your AWS account. -
It uses a simple relationship of 750 words equals 1000 tokens, to get a more accurate representation of token counts use the
Llama2 tokenizer(instructions are provided in the next section).
account=`aws sts get-caller-identity | jq .Account | tr -d '"'` fmbench --config-file s3://sagemaker-fmbench-read-${account}/configs/config-llama2-7b-g5-quick.yml -
-
The generated reports and metrics are available in the
sagemaker-fmbench-write-<replace_w_your_aws_account_id>bucket. The metrics and report files are also downloaded locally and in theresultsdirectory (created byFMBench) and the benchmarking report is available as a markdown file calledreport.mdin theresultsdirectory. You can view the rendered Markdown report in the SageMaker notebook itself. -
Download the metrics and report files from the
sagemaker-fmbench-write-<replace_w_your_aws_account_id>bucket or the SageMaker notebook to your machine for offline analysis.

The DIY version (with gory details)
Follow the prerequisites below to set up your environment before running the code:
-
Python 3.11: Setup a Python 3.11 virtual environment and install
FMBench.python -m venv .fmbench pip install fmbench
-
S3 buckets for test data, scripts, and results: Create two buckets within your AWS account:
-
Read bucket: This bucket contains
tokenizer files,prompt template,source dataanddeployment scriptsstored in a directory structure as shown below.FMBenchneeds to have read access to this bucket.s3://<read-bucket-name> ├── source_data/ ├── source_data/<source-data-file-name>.json ├── prompt_template/ ├── prompt_template/prompt_template.txt ├── scripts/ ├── scripts/<deployment-script-name>.py ├── tokenizer/ ├── tokenizer/tokenizer.json ├── tokenizer/config.json-
The details of the bucket structure is as follows:
-
Source Data Directory: Create a
source_datadirectory that stores the dataset you want to benchmark with.FMBenchusesQ&Adatasets from theLongBench datasetor alternatively from this link. Support for bring your own dataset will be added soon.-
Download the different files specified in the LongBench dataset into the
source_datadirectory. Following is a good list to get started with:2wikimqahotpotqanarrativeqatriviaqa
Store these files in the
source_datadirectory.
-
-
Prompt Template Directory: Create a
prompt_templatedirectory that contains aprompt_template.txtfile. This.txtfile contains the prompt template that your specific model supports.FMBenchalready supports the prompt template compatible withLlamamodels. -
Scripts Directory:
FMBenchalso supports abring your own script (BYOS)mode for deploying models that are not natively available via SageMaker JumpStart i.e. anything not included in this list. Here are the steps to use BYOS.-
Create a Python script to deploy your model on a SageMaker endpoint. This script needs to have a
deployfunction that2_deploy_model.ipynbcan invoke. Seep4d_hf_tgi.pyfor reference. -
Place your deployment script in the
scriptsdirectory in your read bucket. If your script deploys a model directly from HuggingFace and needs to have access to a HuggingFace auth token, then create a file calledhf_token.txtand put the auth token in that file. The.gitignorefile in this repo has rules to not commit thehf_token.txtto the repo. Today,FMBenchprovides inference scripts for:- All SageMaker Jumpstart Models
- Text-Generation-Inference (TGI) container supported models
- Deep Java Library DeepSpeed container supported models
Deployment scripts for the options above are available in the scripts directory, you can use these as reference for creating your own deployment scripts as well.
-
-
Tokenizer Directory: Place the
tokenizer.json,config.jsonand any other files required for your model's tokenizer in thetokenizerdirectory. The tokenizer for your model should be compatible with thetokenizerspackage.FMBenchusesAutoTokenizer.from_pretrainedto load the tokenizer.As an example, to use the
Llama 2 Tokenizerfor counting prompt and generation tokens for theLlama 2family of models: Accept the License here: meta approval form and download thetokenizer.jsonandconfig.jsonfiles from Hugging Face website and place them in thetokenizerdirectory.
-
-
-
Write bucket: All prompt payloads, model endpoint and metrics generated by
FMBenchare stored in this bucket.FMBenchrequires write permissions to store the results in this bucket. No directory structure needs to be pre-created in this bucket, everything is created byFMBenchat runtime.s3://<write-bucket-name> ├── <test-name> ├── <test-name>/data ├── <test-name>/data/metrics ├── <test-name>/data/models ├── <test-name>/data/prompts
-
Steps to run
-
pip installtheFMBenchpackage from PyPi. -
Create a config file using one of the config files available here.
- The configuration file is a YAML file containing configuration for all steps of the benchmarking process. It is recommended to create a copy of an existing config file and tweak it as necessary to create a new one for your experiment.
-
Create the read and write buckets as mentioned in the prerequisites section. Mention the respective directories for your read and write buckets within the config files.
-
Run the
FMBenchtool from the command line.# the config file path could be an S3 path and https path # or even a path to a file on the local filesystem fmbench --config-file \path\to\config\file
-
Depending upon the experiments in the config file, the
FMBenchrun may take a few minutes to several hours. Once the run completes, you can find the report and metrics in the write S3 bucket set in the config file. The report is generated as a markdown file calledreport.mdand is available in the metrics directory in the write S3 bucket.
Results
Here is a screenshot of the report.md file generated by FMBench.
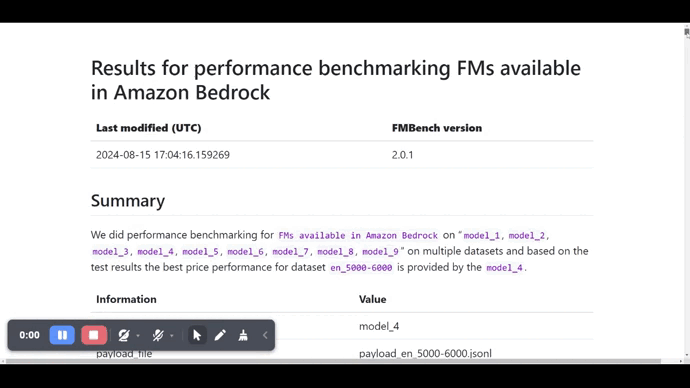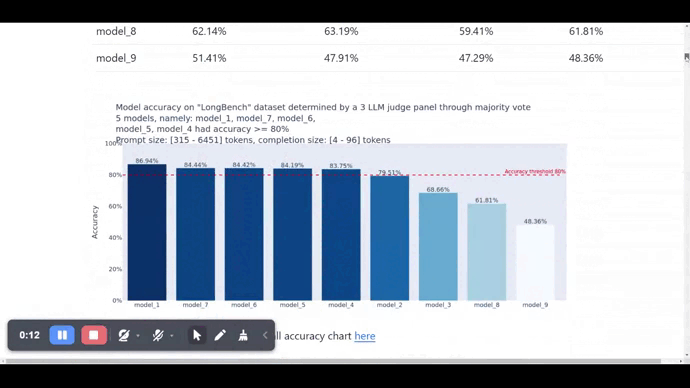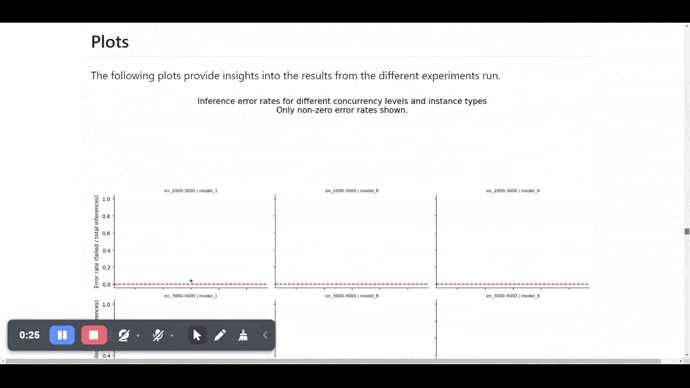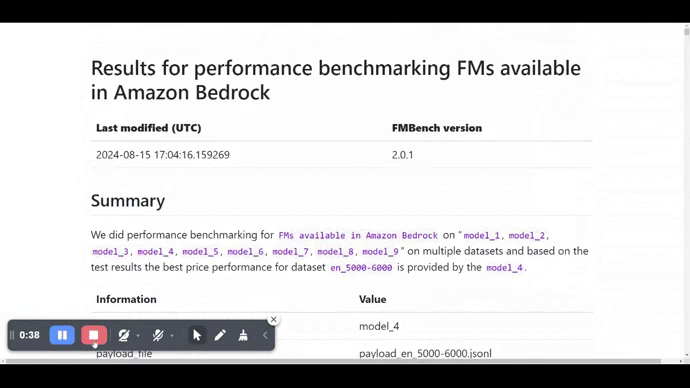
Building the FMBench Python package
The following steps describe how to build the FMBench Python package.
-
Clone the
FMBenchrepo from GitHub. -
Make any code changes as needed.
-
Install
poetry.pip install poetry
-
Change directory to the
FMBenchrepo directory and run poetry build.poetry build
-
The
.whlfile is generated in thedistfolder. Install the.whlin your current Python environment.pip install .\dist\fmbench-X.Y.Z.tar.gz
-
Run
FMBenchas usual through theFMBenchCLI command.
Pending enhancements
The following enhancements are identified as next steps for FMBench.
-
Containerize
FMBenchand provide instructions for running the container on EC2. -
Support for different payload formats that might be needed for different inference containers. Currently the HF TGI container, and DJL Deep Speed container on SageMaker both use the same format but in future other containers might need a different payload format.
-
Emit live metrics so that they can be monitored through Grafana via live dashboard.
-
Allow users to publish their experiment configs and results by doing a POST to an AWS Lambda that writes results to a common S3 bucket that can serve as storage for a simple website.
-
Create a leaderboard of model benchmarks.
View the ISSUES on github and add any you might think be an beneficial iteration to this benchmarking harness.
Security
See CONTRIBUTING for more information.
License
This library is licensed under the MIT-0 License. See the LICENSE file.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file fmbench-1.0.14.tar.gz.
File metadata
- Download URL: fmbench-1.0.14.tar.gz
- Upload date:
- Size: 52.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.7.1 CPython/3.11.5 Windows/10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
990a8bd6082c074435ac57f5368a69e64f8de4d82c1b0d98d2be440c215d7090
|
|
| MD5 |
8ac53501a18f9266432d6a762e015541
|
|
| BLAKE2b-256 |
057c0e9e9f718569fcc81144f3f8421034fb1d54b0c295b20fc0a5dc2acb2c64
|
File details
Details for the file fmbench-1.0.14-py3-none-any.whl.
File metadata
- Download URL: fmbench-1.0.14-py3-none-any.whl
- Upload date:
- Size: 65.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.7.1 CPython/3.11.5 Windows/10
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
fc2d694fbed162f845bfa8bf204128d2d5b7578fb8ffa9a0fb6090e1339a8499
|
|
| MD5 |
18a186b5e70451a91edb97d890d4f072
|
|
| BLAKE2b-256 |
b76233b7237506f456229bdf03188a930d3707f357de3ca09f5c0866c2cdcdd5
|







