Forte is extensible framework for building composable and modularized NLP workflows.

Project description







Download • Quick Start • Contribution Guide • License • Documentation • Publication
Bring good software engineering to your ML solutions, starting from Data!
Forte is a data-centric framework designed to engineer complex ML workflows. Forte allows practitioners to build ML components in a composable and modular way. Behind the scene, it introduces DataPack, a standardized data structure for unstructured data, distilling good software engineering practices such as reusability, extensibility, and flexibility into ML solutions.
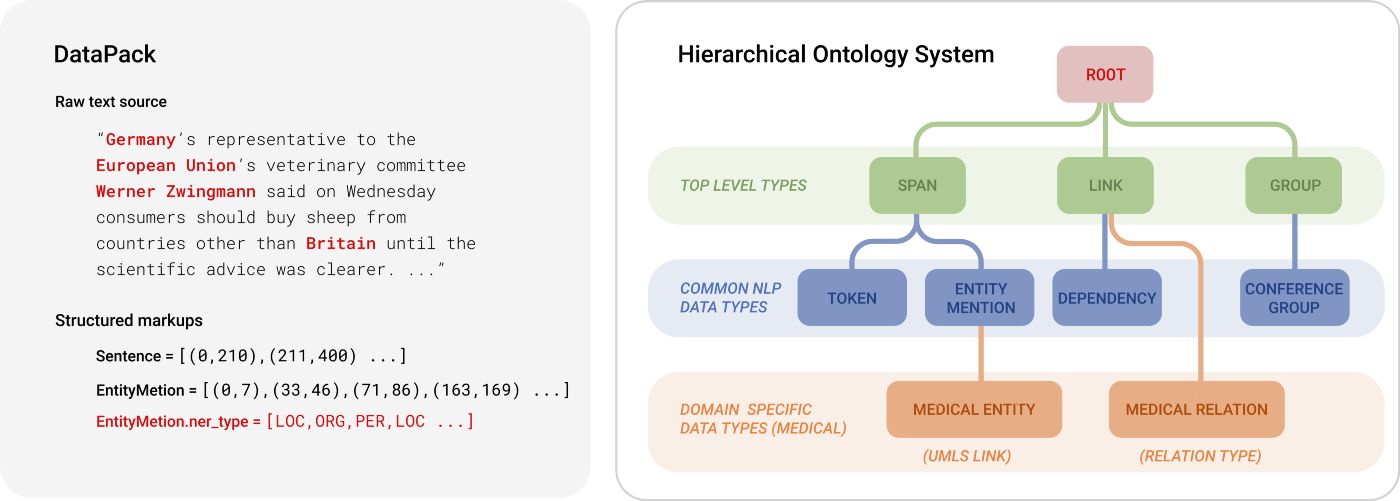
DataPacks are standard data packages in an ML workflow, that can represent the source data (e.g. text, audio, images) and additional markups (e.g. entity mentions, bounding boxes). It is powered by a customizable data schema named "Ontology", allowing domain experts to inject their knowledge into ML engineering processes easily.
Installation
To install the released version from PyPI:
pip install forte
To install from source:
git clone https://github.com/asyml/forte.git
cd forte
pip install .
To install some forte adapter for some existing libraries:
Install from PyPI:
# To install other tools. Check here https://github.com/asyml/forte-wrappers#libraries-and-tools-supported for available tools.
pip install forte.spacy
Install from source:
git clone https://github.com/asyml/forte-wrappers.git
cd forte-wrappers
# Change spacy to other tools. Check here https://github.com/asyml/forte-wrappers#libraries-and-tools-supported for available tools.
pip install src/spacy
Some components or modules in forte may require some extra requirements:
pip install forte[data_aug]: Install packages required for data augmentation modules.pip install forte[ir]: Install packages required for Information Retrieval Supportspip install forte[remote]: Install packages required for pipeline serving functionalities, such as Remote Processor.pip install forte[audio_ext]: Install packages required for Forte Audio support, such as Audio Reader.pip install forte[stave]: Install packages required for Stave integration.pip install forte[models]: Install packages required for ner training, srl, srl with new training system, and srl_predictor and ner_predictorpip install forte[test]: Install packages required for running unit tests.pip install forte[wikipedia]: Install packages required for reading wikipedia datasets.pip install forte[nlp]: Install packages required for additional NLP supports, such as subword_tokenizer and texar encoderpip install forte[extractor]: Install packages required for extractor-based training system, extractor, train_preprocessor, tagging trainer, DataPack dataset, types, and converter.
Quick Start Guide
Writing NLP pipelines with Forte is easy. The following example creates a simple pipeline that analyzes the sentences, tokens, and named entities from a piece of text.
Before we start, make sure the SpaCy wrapper is installed.
pip install forte.spacy
Let's start by writing a simple processor that analyze POS tags to tokens using the good old NLTK library.
import nltk
from forte.processors.base import PackProcessor
from forte.data.data_pack import DataPack
from ft.onto.base_ontology import Token
class NLTKPOSTagger(PackProcessor):
r"""A wrapper of NLTK pos tagger."""
def initialize(self, resources, configs):
super().initialize(resources, configs)
# download the NLTK average perceptron tagger
nltk.download("averaged_perceptron_tagger")
def _process(self, input_pack: DataPack):
# get a list of token data entries from `input_pack`
# using `DataPack.get()`` method
token_texts = [token.text for token in input_pack.get(Token)]
# use nltk pos tagging module to tag token texts
taggings = nltk.pos_tag(token_texts)
# assign nltk taggings to token attributes
for token, tag in zip(token_entries, taggings):
token.pos = tag[1]
If we break it down, we will notice there are two main functions.
In the initialize function, we download and prepare the model. And then in the _process
function, we actually process the DataPack object, take the some tokens from it, and
use the NLTK tagger to create POS tags. The results are stored as the pos attribute of
the tokens.
Before we go into the details of the implementation, let's try it in a full pipeline.
from forte import Pipeline
from forte.data.readers import TerminalReader
from fortex.spacy import SpacyProcessor
pipeline: Pipeline = Pipeline[DataPack]()
pipeline.set_reader(TerminalReader())
pipeline.add(SpacyProcessor(), {"processors": ["sentence", "tokenize"]})
pipeline.add(NLTKPOSTagger())
Here we have successfully created a pipeline with a few components:
- a
TerminalReaderthat reads data from terminal - a
SpacyProcessorthat calls SpaCy to split the sentences and create tokenization - and finally the brand new
NLTKPOSTaggerwe just implemented,
Let's see it run in action!
for pack in pipeline.initialize().process_dataset():
for sentence in pack.get("ft.onto.base_ontology.Sentence"):
print("The sentence is: ", sentence.text)
print("The POS tags of the tokens are:")
for token in pack.get(Token, sentence):
print(f" {token.text}({token.pos})", end = " ")
print()
We have successfully created a simple pipeline. In the nutshell, the DataPacks are
the standard packages "flowing" on the pipeline. They are created by the reader, and
then pass along the pipeline.
Each processor, such as our NLTKPOSTagger,
interfaces directly with DataPacks and do not need to worry about the
other part of the pipeline, making the engineering process more modular. In this example
pipeline, SpacyProcessor creates the Sentence and Token, and then we implemented
the NLTKPOSTagger to add Part-of-Speech tags to the tokens.
To learn more about the details, check out of documentation! The classes used in this guide can also be found in this repository or the Forte Wrappers repository
And There's More
The data-centric abstraction of Forte opens the gate to many other opportunities. Not only does Forte allow engineers to develop reusable components easily, it further provides a simple way to develop composable ML modules. For example, Forte allows us to:
- create composable ML solutions with reusable models and processing logic
- easily interface with a great collection of 3rd party toolkits built by the community
- build plug-and-play data augmentation tools
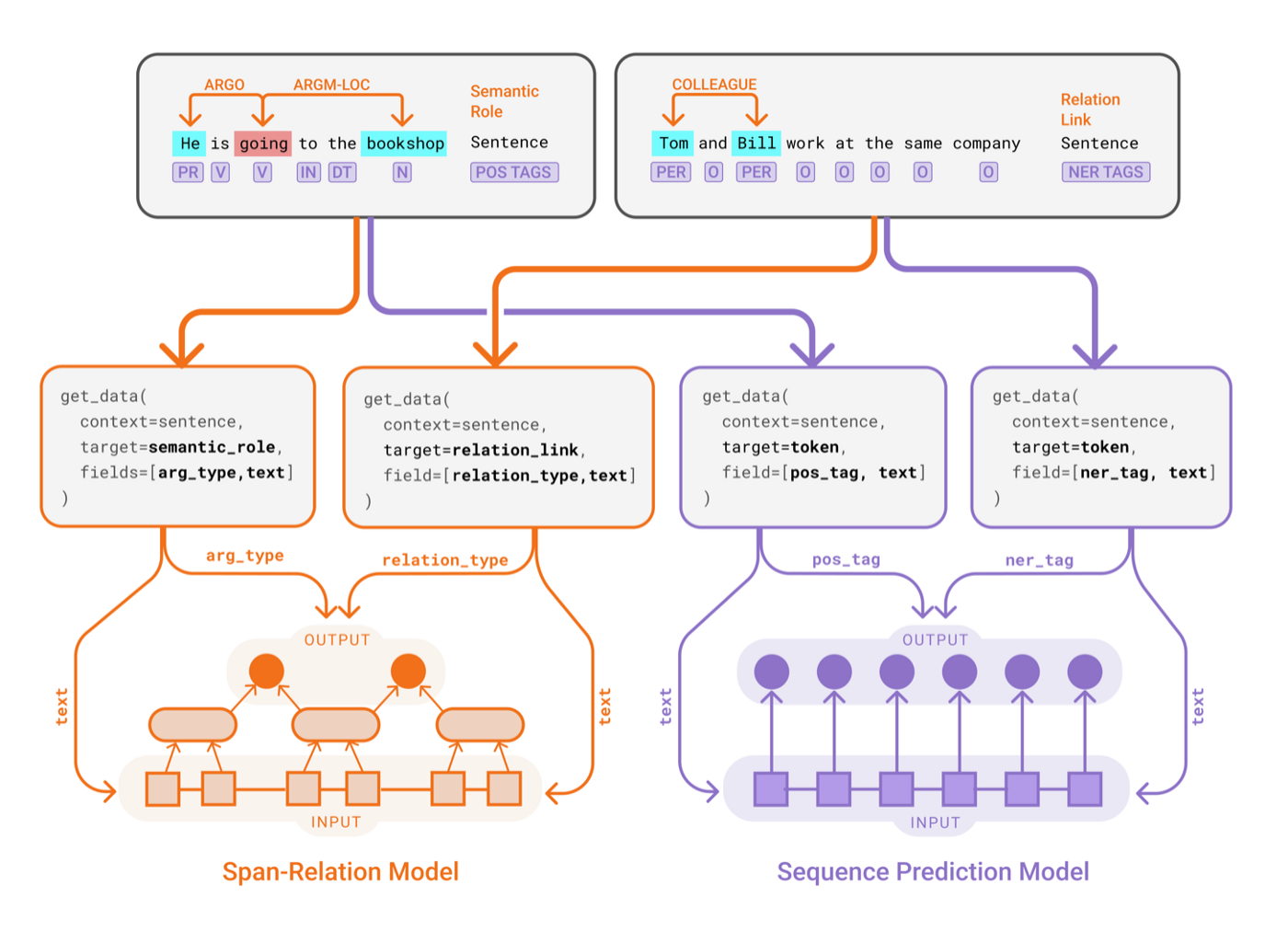
To learn more about these, you can visit:
- Examples
- Documentation
- Currently we are working on some interesting tutorials, stay tuned for a full set of documentation on how to do NLP with Forte!
Contributing
Forte was originally developed in CMU and is actively contributed by Petuum in collaboration with other institutes. This project is part of the CASL Open Source family.
If you are interested in making enhancement to Forte, please first go over our Code of Conduct and Contribution Guideline
About
Supported By



License
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file forte-0.2.0.tar.gz.
File metadata
- Download URL: forte-0.2.0.tar.gz
- Upload date:
- Size: 319.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.0 CPython/3.9.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
06ac3c9fd4942bb34217da1513f0766d50447b39436d657dcf3f1e9b8fe4c599
|
|
| MD5 |
bbb272f6bedeedcd3336424c933949fd
|
|
| BLAKE2b-256 |
edb49860c8386bf263c6aab9c49b9971f14908164313342e20f0cbd909443213
|
File details
Details for the file forte-0.2.0-py3-none-any.whl.
File metadata
- Download URL: forte-0.2.0-py3-none-any.whl
- Upload date:
- Size: 457.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.0 CPython/3.9.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f612bd92e2e298ba37f2d96617d9111c035014f5c853a6b25070ea2dbed8beec
|
|
| MD5 |
2421418187ae4b3488ee0a563740406a
|
|
| BLAKE2b-256 |
ad6b537f9f241b7141041a74be6987765e4c37a012835f9cded7913e20e26e1a
|







