CLI-first harness for safety and guardrail evaluation
Project description

CLI-first harness for benchmarking guardrail, moderation, and safety classification models.







Evaluate any safety model — local HuggingFace, vLLM, OpenAI, Anthropic, or custom API — against 80+ built-in safety benchmarks with a single command.
Quickstart
pip install geh
# Run a quick eval
geh run --dataset xstest --model mock --limit 50
# Run multiple datasets
geh run --dataset xstest,toxic_chat,harmful_qa --model hf \
--model-name meta-llama/Llama-Guard-3-8B
# Run from a YAML config
geh run --config examples/run-mock-jsonl.yaml
# Use benchmark packs
geh run --pack core --model mock
Installation
Requires Python 3.10+.
# Base install
pip install geh
# With HuggingFace model support
pip install "geh[hf]"
# With vLLM support
pip install "geh[vllm]"
# With API model support (OpenAI, Anthropic)
pip install "geh[api]"
From source (for development):
git clone https://github.com/Virtue-Research/guard-eval-harness.git
cd guard-eval-harness
pip install -e ".[dev]"
Copy .env.example to .env and fill in the API keys you need.
Usage
Inline mode
The fastest way to run evals — no config files needed:
geh run --dataset <dataset> --model <adapter> [--model-name <name>] [options]
# HuggingFace model on XSTest
geh run --dataset xstest --model hf --model-name meta-llama/Llama-Guard-3-8B
# OpenAI moderation
geh run --dataset xstest,toxic_chat --model openai_moderation
# vLLM serving
geh run --dataset harmbench_behaviors --model vllm \
--model-name meta-llama/Llama-Guard-3-8B --batch-size 32
# Limit samples for quick smoke tests
geh run --dataset xstest --model mock --limit 10
YAML config mode
For full control over model args, dataset options, execution tuning, and output:
geh run --config examples/run-mock-jsonl.yaml
See examples/ for sample configs.
Benchmark packs
Curated dataset bundles for common evaluation scenarios:
geh list packs
geh run --pack core --model mock
geh run --pack jailbreak --model hf --model-name meta-llama/Llama-Guard-3-8B
Discovery
geh list datasets # 80+ built-in safety benchmarks
geh list backends # Available model adapters
geh list packs # Curated benchmark bundles
geh list metrics # Supported metrics
Inspecting results
geh inspect --run-dir out/my-run # View manifest, summary, artifacts
geh report --run-dir out/my-run # Rebuild HTML report
geh compare --run-a out/run1 --run-b out/run2 # Diff two runs
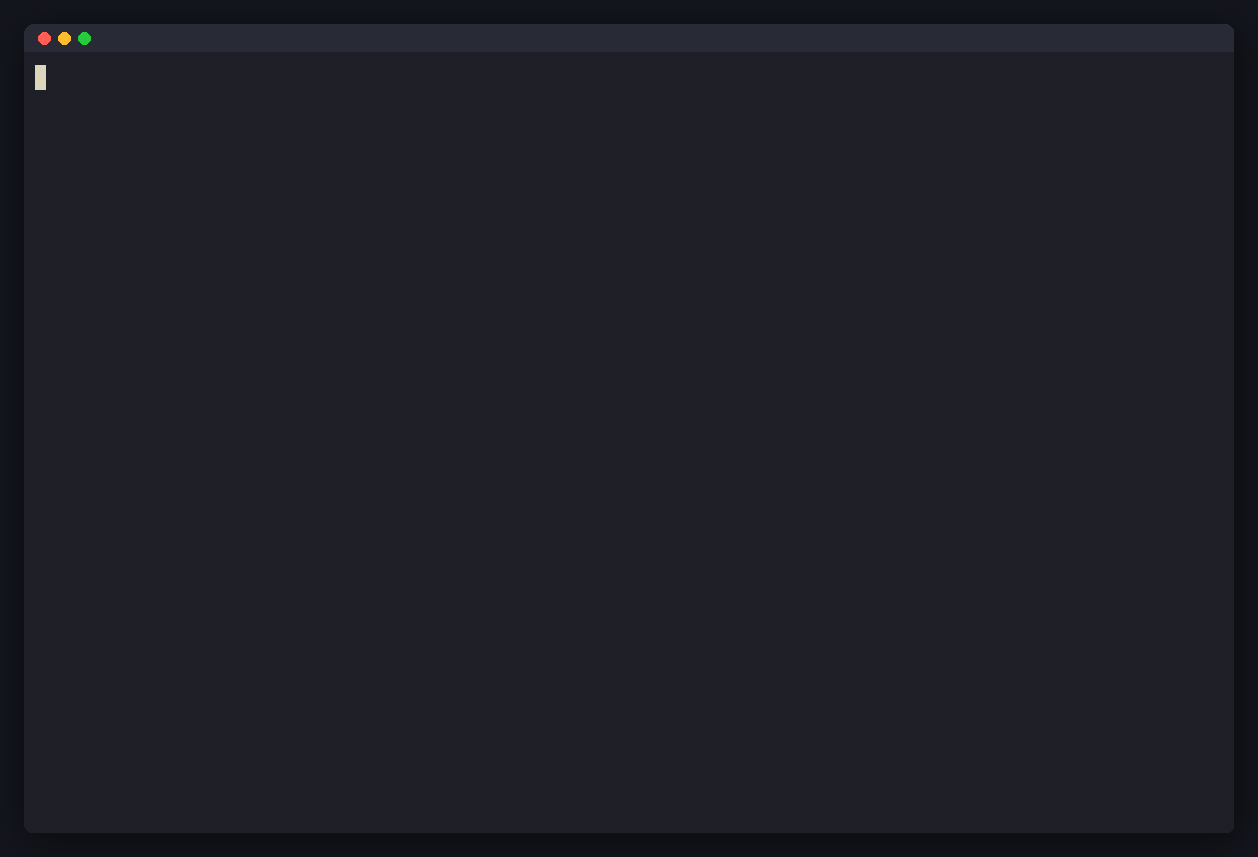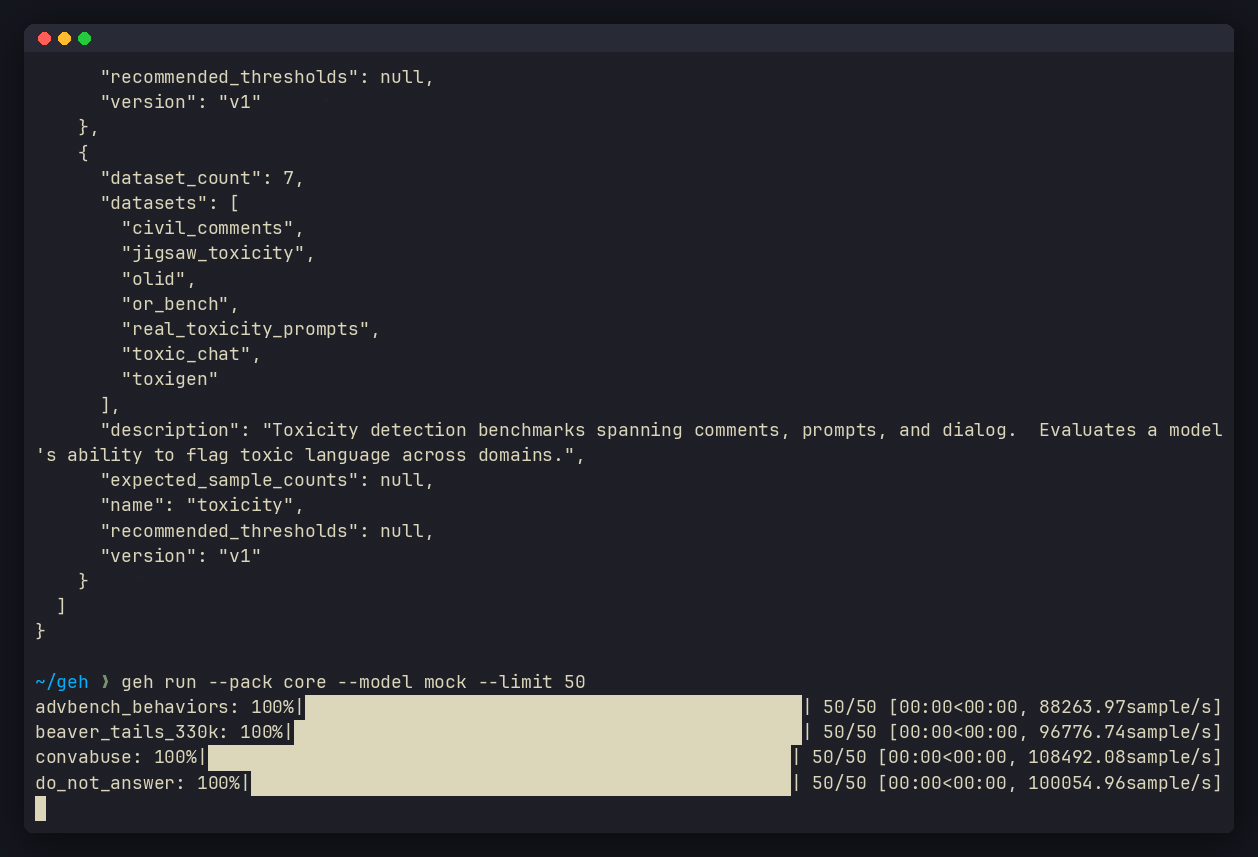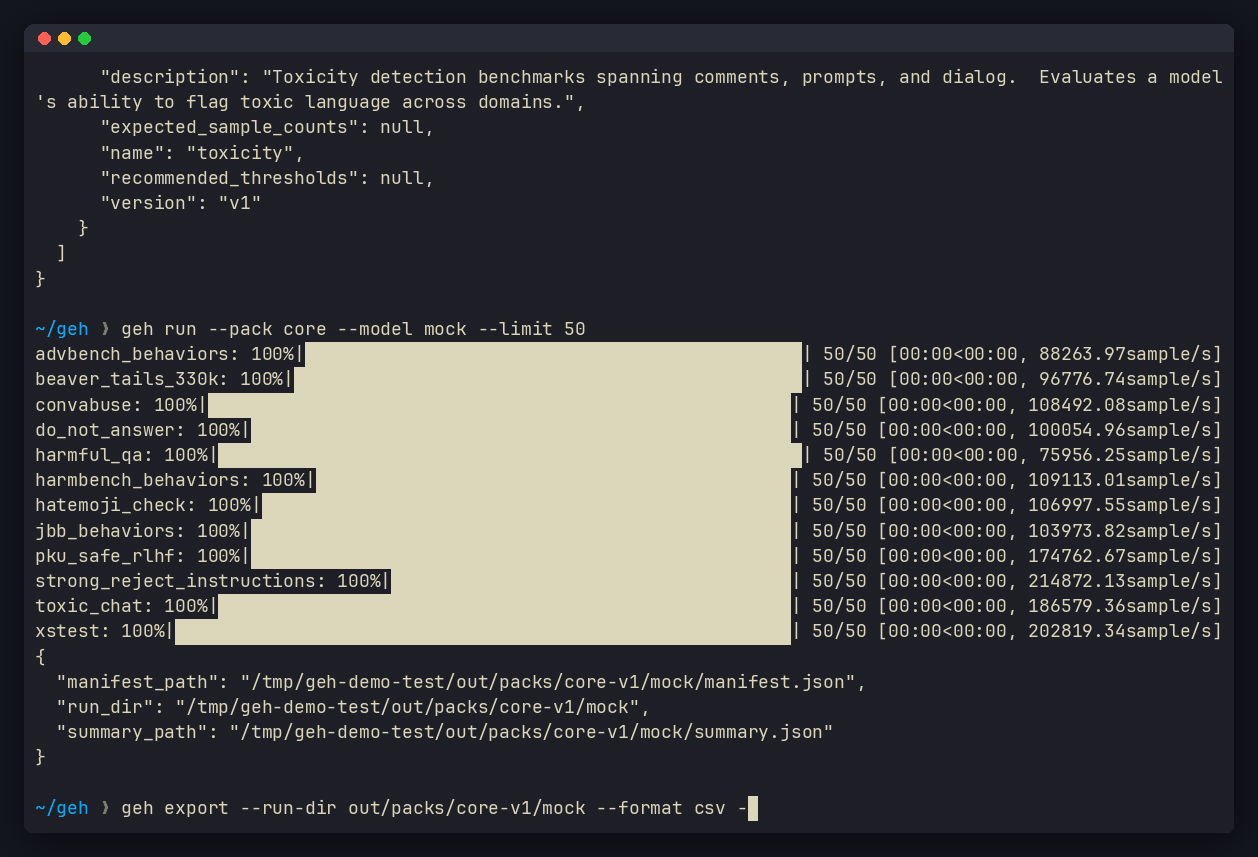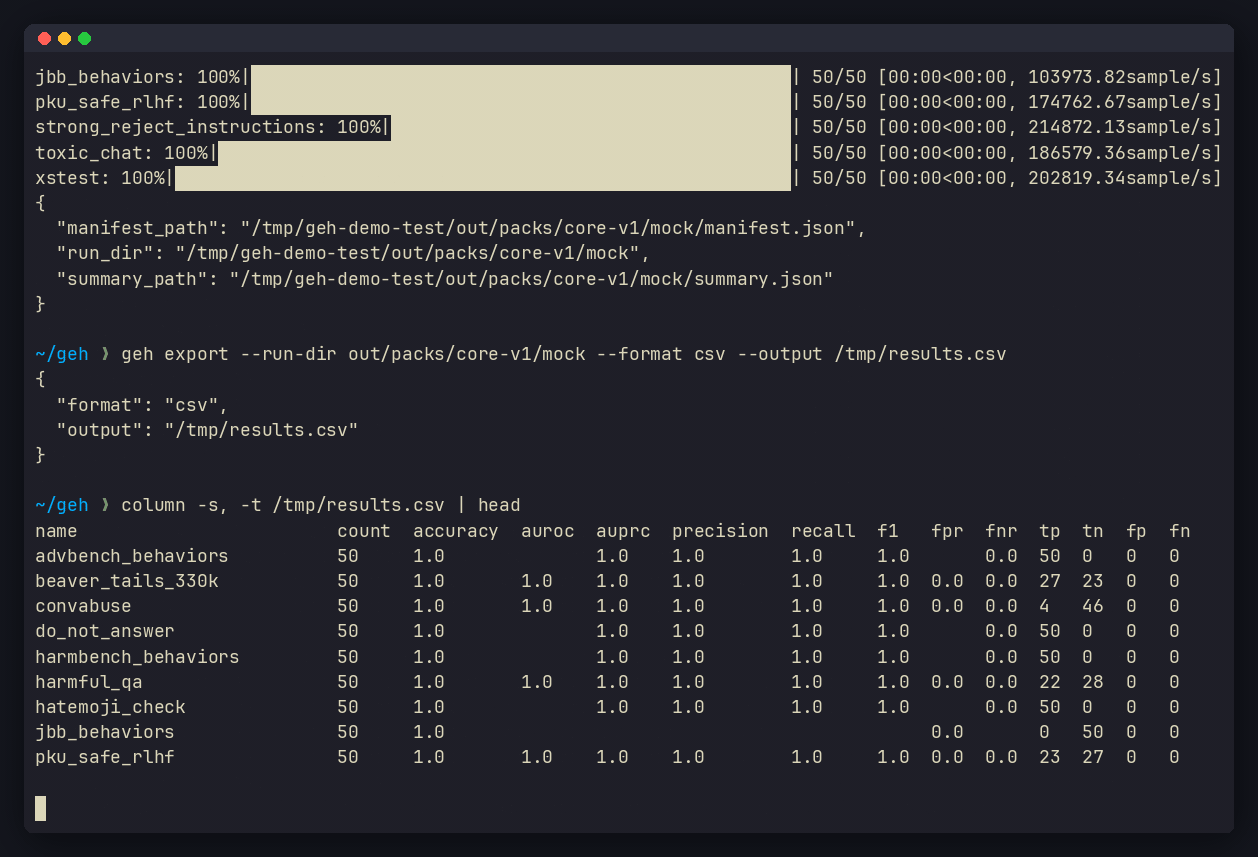
geh export --run-dir out/my-run --format csv --output results.csv
Run artifacts
Each run writes a self-contained directory:
out/my-run/
manifest.json # Run metadata
resolved-config.json # Exact config snapshot
summary.json # Aggregated metrics
report.html # Static HTML report
datasets/
<dataset>/
predictions.jsonl # Per-sample predictions
metrics.json # Dataset-level metrics
dataset-manifest.json # Dataset metadata
Model adapters
| Adapter | Description |
|---|---|
mock |
Deterministic mock for testing |
hf |
HuggingFace Transformers (local GPU) |
vllm |
vLLM inference server |
openai_compatible |
OpenAI-compatible APIs |
openai_moderation |
OpenAI Moderation endpoint |
anthropic |
Anthropic Claude API |
http |
Generic HTTP endpoint |
Datasets
80+ built-in safety benchmarks spanning two modalities:
Text
The core modality — evaluate text-based guardrails and moderation models across a range of safety dimensions:
- Jailbreak / adversarial: XSTest, HarmBench, JBB Behaviors, AdvBench, Do-Anything-Now, StrongREJECT, MaliciousInstruct, WildGuardMix
- Toxicity: ToxicChat, ToxiGen, Jigsaw Toxicity, Civil Comments, RealToxicityPrompts, OR-Bench
- Hate & harassment: HateCheck, DynaHate, ETHOS, HatExplain, Implicit Hate, Measuring Hate Speech, Social Bias Frames, ConvAbuse
- General safety: BeaverTails 330k, Do-Not-Answer, OpenAI Moderation (via API), GuardBench, CircleGuardBench
- Prompt injection: Dedicated prompt-injection benchmarks for testing input-filtering guardrails
Image
Evaluate multimodal safety models that process image+text inputs. The harness handles image downloading, caching, and normalization automatically:
- Unsafe content detection: UnsafeBench (8k+ images across safety categories), HoliSafeBench (holistic image safety with fine-grained risk types)
- Visual jailbreaks: JailbreakV (adversarial images designed to bypass vision-language model safeguards)
- Image edit safety: Safe-vs-Unsafe Image Edits (detecting harmful image manipulation requests)
- Cross-modal attacks: VLSBench, MSTS (text+image multimodal safety evaluation)
- Benign baselines: ImageNet-1k safe subset (measuring false positive rates on benign images)
- Local image data: Load from local directories or JSONL manifests with image paths/URLs
Local files
Bring your own data in any modality:
local_jsonl— text samples from a JSONL filelocal_csv— text samples from a CSV filelocal_image_jsonl— image+text samples from a JSONL manifest with image paths/URLslocal_image_dir— image samples from a directory of images
Run geh list datasets for the full list.
Secure-coding agents
Beyond classification, the harness also runs repository-level secure-coding
benchmarks under geh vibe: a coding agent writes or completes real code, and
an out-of-process oracle builds it in a container to score functional
correctness and security. See the VibeCoding Bench guide
and geh vibe datasets.
About
guard-eval-harness is built and maintained by the research team at
Virtue AI — one security solution for your entire AI stack.
License
Project details
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file geh-0.2.1.tar.gz.
File metadata
- Download URL: geh-0.2.1.tar.gz
- Upload date:
- Size: 1.8 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
78b4773c6fd1cfbf4c0f78a7ce6d5836575c6937f5f8ba8d0544996cf6c3d168
|
|
| MD5 |
a0cd55e67a2e0c4d84d11da6a4090fb3
|
|
| BLAKE2b-256 |
0b6a2d5df91e7bb7102d533302b500b16d0d361118240f64843c686ece0d2e35
|
Provenance
The following attestation bundles were made for geh-0.2.1.tar.gz:
Publisher:
release.yml on Virtue-Research/guard-eval-harness
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
geh-0.2.1.tar.gz -
Subject digest:
78b4773c6fd1cfbf4c0f78a7ce6d5836575c6937f5f8ba8d0544996cf6c3d168 - Sigstore transparency entry: 1971641753
- Sigstore integration time:
-
Permalink:
Virtue-Research/guard-eval-harness@f0c8575dfad2c5f2eaec169b59249609fa97697a -
Branch / Tag:
refs/tags/v0.2.1 - Owner: https://github.com/Virtue-Research
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@f0c8575dfad2c5f2eaec169b59249609fa97697a -
Trigger Event:
release
-
Statement type:
File details
Details for the file geh-0.2.1-py3-none-any.whl.
File metadata
- Download URL: geh-0.2.1-py3-none-any.whl
- Upload date:
- Size: 461.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
59a59a65847866dd455df8028de6f767329521192883dcb1b647f4c23c9ae95b
|
|
| MD5 |
69c2ca2316a9884df91ca3a26c439272
|
|
| BLAKE2b-256 |
8001bd56a77dce2adc1ac371941778fa3147efc5cf4009b062c0247a7684fb2f
|
Provenance
The following attestation bundles were made for geh-0.2.1-py3-none-any.whl:
Publisher:
release.yml on Virtue-Research/guard-eval-harness
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
geh-0.2.1-py3-none-any.whl -
Subject digest:
59a59a65847866dd455df8028de6f767329521192883dcb1b647f4c23c9ae95b - Sigstore transparency entry: 1971641786
- Sigstore integration time:
-
Permalink:
Virtue-Research/guard-eval-harness@f0c8575dfad2c5f2eaec169b59249609fa97697a -
Branch / Tag:
refs/tags/v0.2.1 - Owner: https://github.com/Virtue-Research
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
release.yml@f0c8575dfad2c5f2eaec169b59249609fa97697a -
Trigger Event:
release
-
Statement type:







