Efficient querying of genomic databases.

Project description
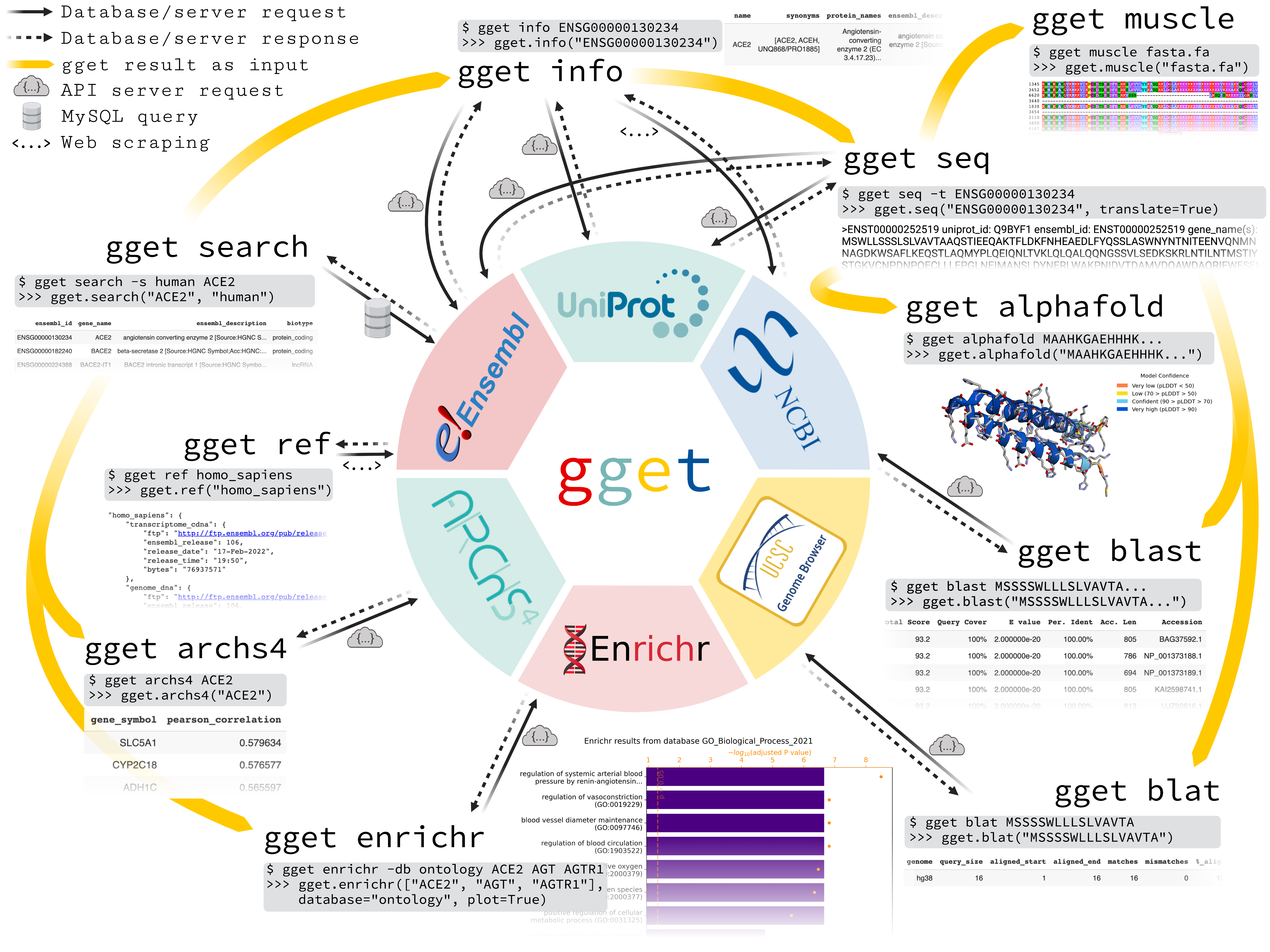
gget







gget is a free, open-source command-line tool and Python package that enables efficient querying of genomic databases. gget consists of a collection of separate but interoperable modules, each designed to facilitate one type of database querying in a single line of code.
If you use gget in a publication, please cite*:
Luebbert, L., & Pachter, L. (2023). Efficient querying of genomic reference databases with gget. Bioinformatics. https://doi.org/10.1093/bioinformatics/btac836
Read the article here: https://doi.org/10.1093/bioinformatics/btac836
Installation
uv pip install gget
or
pip install --upgrade gget
Install from source:
git clone https://github.com/pachterlab/gget.git
cd gget
uv pip install .
For use in Jupyter Lab / Google Colab:
# Python
import gget
🔗 Manual
🪄 Quick start guide
Command line:
# Fetch all Homo sapiens reference and annotation FTPs from the latest Ensembl release
$ gget ref homo_sapiens
# Get Ensembl IDs of human genes with "ace2" or "angiotensin converting enzyme 2" in their name/description
$ gget search -s homo_sapiens 'ace2' 'angiotensin converting enzyme 2'
# Look up gene ENSG00000130234 (ACE2) and its transcript ENST00000252519
$ gget info ENSG00000130234 ENST00000252519
# Fetch the amino acid sequence of the canonical transcript of gene ENSG00000130234
$ gget seq --translate ENSG00000130234
# Quickly find the genomic location of (the start of) that amino acid sequence
$ gget blat MSSSSWLLLSLVAVTAAQSTIEEQAKTFLDKFNHEAEDLFYQSSLAS
# BLAST (the start of) that amino acid sequence
$ gget blast MSSSSWLLLSLVAVTAAQSTIEEQAKTFLDKFNHEAEDLFYQSSLAS
# Align multiple nucleotide or amino acid sequences against each other (also accepts path to FASTA file)
$ gget muscle MSSSSWLLLSLVAVTAAQSTIEEQAKTFLDKFNHEAEDLFYQSSLAS MSSSSWLLLSLVEVTAAQSTIEQQAKTFLDKFHEAEDLFYQSLLAS
# Align one or more amino acid sequences against a reference (containing one or more sequences) (local BLAST) (also accepts paths to FASTA files)
$ gget diamond MSSSSWLLLSLVAVTAAQSTIEEQAKTFLDKFNHEAEDLFYQSSLAS -ref MSSSSWLLLSLVEVTAAQSTIEQQAKTFLDKFHEAEDLFYQSLLAS
# Use Enrichr for an ontology analysis of a list of genes
$ gget enrichr -db ontology ACE2 AGT AGTR1 ACE AGTRAP AGTR2 ACE3P
# Get the human tissue expression of gene ACE2
$ gget archs4 -w tissue ACE2
# Get the protein structure (in PDB format) of ACE2 as stored in the Protein Data Bank (PDB ID returned by gget info)
$ gget pdb 1R42 -o 1R42.pdb
# Download virus genome datasets from NCBI Virus (e.g., Zika virus sequences)
$ gget virus "Zika virus" --host "Homo sapiens" --nuc_completeness complete
# Find Eukaryotic Linear Motifs (ELMs) in a protein sequence
$ gget setup elm # setup only needs to be run once
$ gget elm -o results MSSSSWLLLSLVAVTAAQSTIEEQAKTFLDKFNHEAEDLFYQSSLAS
# Fetch a scRNAseq count matrix (AnnData format) based on specified gene(s), tissue(s), and cell type(s) (default species: human)
$ gget setup cellxgene # setup only needs to be run once
$ gget cellxgene --gene ACE2 SLC5A1 --tissue lung --cell_type 'mucus secreting cell' -o example_adata.h5ad
# Predict the protein structure of GFP from its amino acid sequence
$ gget setup alphafold # setup only needs to be run once
$ gget alphafold MSKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDATYGKLTLKFICTTGKLPVPWPTLVTTFSYGVQCFSRYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYIMADKQKNGIKVNFKIRHNIEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGITHGMDELYK
Python (Jupyter Lab / Google Colab):
import gget
gget.ref("homo_sapiens")
gget.search(["ace2", "angiotensin converting enzyme 2"], "homo_sapiens")
gget.info(["ENSG00000130234", "ENST00000252519"])
gget.seq("ENSG00000130234", translate=True)
gget.blat("MSSSSWLLLSLVAVTAAQSTIEEQAKTFLDKFNHEAEDLFYQSSLAS")
gget.blast("MSSSSWLLLSLVAVTAAQSTIEEQAKTFLDKFNHEAEDLFYQSSLAS")
gget.muscle(["MSSSSWLLLSLVAVTAAQSTIEEQAKTFLDKFNHEAEDLFYQSSLAS", "MSSSSWLLLSLVEVTAAQSTIEQQAKTFLDKFHEAEDLFYQSLLAS"])
gget.diamond("MSSSSWLLLSLVAVTAAQSTIEEQAKTFLDKFNHEAEDLFYQSSLAS", reference="MSSSSWLLLSLVEVTAAQSTIEQQAKTFLDKFHEAEDLFYQSLLAS")
gget.enrichr(["ACE2", "AGT", "AGTR1", "ACE", "AGTRAP", "AGTR2", "ACE3P"], database="ontology", plot=True)
gget.archs4("ACE2", which="tissue")
gget.pdb("1R42", save=True)
gget.virus("Zika virus", host="Homo sapiens", nuc_completeness="complete")
gget.setup("elm") # setup only needs to be run once
ortho_df, regex_df = gget.elm("MSSSSWLLLSLVAVTAAQSTIEEQAKTFLDKFNHEAEDLFYQSSLAS")
gget.setup("cellxgene") # setup only needs to be run once
gget.cellxgene(gene = ["ACE2", "SLC5A1"], tissue = "lung", cell_type = "mucus secreting cell")
gget.setup("alphafold") # setup only needs to be run once
gget.alphafold("MSKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDATYGKLTLKFICTTGKLPVPWPTLVTTFSYGVQCFSRYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYIMADKQKNGIKVNFKIRHNIEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGITHGMDELYK")
Call gget from R using reticulate:
system("pip install gget")
install.packages("reticulate")
library(reticulate)
gget <- import("gget")
gget$ref("homo_sapiens")
gget$search(list("ace2", "angiotensin converting enzyme 2"), "homo_sapiens")
gget$info(list("ENSG00000130234", "ENST00000252519"))
gget$seq("ENSG00000130234", translate=TRUE)
gget$blat("MSSSSWLLLSLVAVTAAQSTIEEQAKTFLDKFNHEAEDLFYQSSLAS")
gget$blast("MSSSSWLLLSLVAVTAAQSTIEEQAKTFLDKFNHEAEDLFYQSSLAS")
gget$muscle(list("MSSSSWLLLSLVAVTAAQSTIEEQAKTFLDKFNHEAEDLFYQSSLAS", "MSSSSWLLLSLVEVTAAQSTIEQQAKTFLDKFHEAEDLFYQSLLAS"), out="out.afa")
gget$diamond("MSSSSWLLLSLVAVTAAQSTIEEQAKTFLDKFNHEAEDLFYQSSLAS", reference="MSSSSWLLLSLVEVTAAQSTIEQQAKTFLDKFHEAEDLFYQSLLAS")
gget$enrichr(list("ACE2", "AGT", "AGTR1", "ACE", "AGTRAP", "AGTR2", "ACE3P"), database="ontology")
gget$archs4("ACE2", which="tissue")
gget$pdb("1R42", save=TRUE)
gget$virus("Zika virus", host="Homo sapiens", nuc_completeness="complete")
More tutorials
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file gget-0.30.2.tar.gz.
File metadata
- Download URL: gget-0.30.2.tar.gz
- Upload date:
- Size: 78.9 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
20254dcb6d7ea544a3a580675848fc0084000eef5b565bb774ff4f9ef5bbf2d5
|
|
| MD5 |
a20ffd5db811a36f52c3ec0895cb5747
|
|
| BLAKE2b-256 |
15837a25ba036a520f78f3fefab9a8248b97157967a0c19e9dd3878c50fd1b7d
|
File details
Details for the file gget-0.30.2-py3-none-any.whl.
File metadata
- Download URL: gget-0.30.2-py3-none-any.whl
- Upload date:
- Size: 79.3 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6aa96b2d35212f8f376e15bd02f4f7f4a9769ec99395b562b7b385798d7ca497
|
|
| MD5 |
fabd7ecf55a06a37dbeb46dad6d07229
|
|
| BLAKE2b-256 |
1a0d7c86e8eea7a49cd2db60f9412442c9229378552a767482af5d23e8e141f5
|







