GPU-accelerated video stabilization with a deep-learning homography model and a custom fused CUDA autograd kernel.

Project description
gimbal-engine
GPU video stabilization with two interchangeable camera motion estimators, a custom CUDA pipeline and a learned homography network, benchmarked head to head.
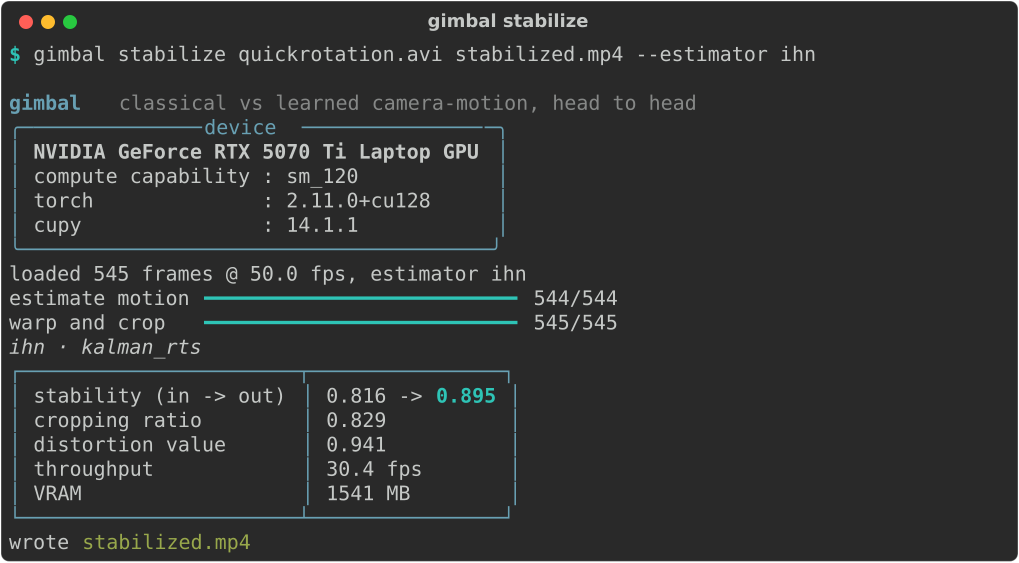
Install
pip install gimbal_engineBuilding the compiled CUDA extension needs an NVIDIA GPU and a CUDA toolkit. The trained weights ship inside the package, so a successful install can stabilize immediately with no extra download. If you do not have a local toolchain, the Docker path under Build and install builds everything.
Gimbal Engine stabilizes shaky video on the GPU. Its real subject is a head to head comparison of two interchangeable camera motion estimators: a classical pipeline written in CUDA (pyramidal Lucas-Kanade tracking with RANSAC homography fitting) and an iterative homography network (IHN) trained from scratch. Both sit behind one shared Estimator interface and feed the same back end (trajectory smoothing, GPU warping, auto crop, and the standard stabilization metrics), so they can be swapped and measured on identical footage. The two share more than that interface: each turns its four corner estimates into a homography through the same differentiable Tensor-DLT, solved on the GPU.
Stabilization, side by side
Three NUS clips, across rotation, running, and crowd scenes. Each row is one clip: the shaky input, the gimbal IHN result, and the classical CUDA result, with the stability score under each.
 |
 |
 |
| Shaky input | gimbal IHN stability 0.928 |
Classical stability 0.264 |
| QuickRotation/19.avi | ||
 |
 |
 |
| Shaky input | gimbal IHN stability 0.973 |
Classical stability 0.631 |
| Running/1.avi | ||
 |
 |
 |
| Shaky input | gimbal IHN stability 0.908 |
Classical stability 0.495 |
| Crowd/14.avi | ||
These are clips where the IHN is strongest. On large zoom and parallax the classical pipeline is steadier, and the full per category numbers, wins and losses, are in Results.
Highlights · What is inside · Architecture · Results · Correctness · Build and install
Highlights
- A fused local correlation CUDA operator with its own forward and backward pass. Against the PyTorch reference it is 26.3x faster and uses 1.72x less memory (forward and backward, RTX 5070 Ti laptop).
- The trained IHN reaches a sub pixel mean average corner error of 0.863 px on held out synthetic pairs, against 6.489 px for a single shot regression baseline. The iterative refinement is the difference.
- A mesh (multi homography) model that fits a grid of local homographies and reduces exactly to the single global homography at a 1x1 grid. On synthetic parallax it lowers corner error against the global model by 6.5 px (see the mesh study).
- One
Estimatorinterface for all three. The classical pipeline, the global IHN, and the mesh model return the sameMotionField, so the pipeline never knows which one it is running. - Field standard evaluation: the NUS dataset, reported as the cropping ratio, distortion value, and stability score triplet, plus CUDA event timing.
- The whole inference loop captured into a CUDA graph, which removes the launch overhead that dominates at this size and gives an 11.4x end to end speedup.
What is inside
Two estimators, one back end. The core of the project is the comparison between them and the geometry they share.
| Component | What it is |
|---|---|
| Classical estimator | Shi-Tomasi corners, pyramidal Lucas-Kanade tracking, RANSAC homography fitting, all in CUDA |
| Learned estimator (IHN) | Feature encoder, local correlation cost volume, iterative 4 point refinement, differentiable Tensor-DLT |
| Regression baseline | Single shot 4 point regression (the ablation control for the IHN) |
| Mesh estimator | A grid of per cell homographies (MeshFlow style), reducing to the global model at a 1x1 grid |
| Fused correlation op | A compiled CUDA autograd operator for the cost volume, gated behind a gradient check |
| Shared back end | Trajectory smoothing, GPU warp, auto crop, and the stabilization metric triplet |
| Smoothers | Gaussian, Kalman RTS, and L1-TV camera path smoothing |
The classical and learned estimators are interchangeable because they agree on one contract: take two consecutive grayscale frames, return a MotionField that maps frame A coordinates to frame B coordinates. Everything downstream, the smoothing, the warp, the metrics, sees only that result and never the model that produced it.
Architecture
flowchart LR
V[Input clip] --> P[grayscale frame pairs]
P --> E{Estimator interface}
E -->|classical| C[CUDA LK plus RANSAC]
E -->|learned| I[IHN]
E -->|mesh| M[MeshIHN]
C --> F[MotionField]
I --> F
M --> F
F --> S[trajectory smoothing]
S --> W[GPU warp and auto crop]
W --> O[Stabilized clip plus metrics]
The classical estimator runs the parallel path entirely in CUDA: Shi-Tomasi corner detection, pyramidal Lucas-Kanade tracking of those corners across the frame pair, and a RANSAC homography fit over the surviving matches, with a degenerate fit falling back to identity rather than a bad warp.
The IHN follows the iterative homography idea. A shared encoder turns both frames into feature maps. At each of six iterations the model builds a local correlation cost volume between the current warped features and the target, predicts an update to four corner offsets, and turns those offsets into a homography with the Tensor-DLT. The cost volume is the hot path, which is why it has a dedicated fused CUDA operator. The mesh model replaces the single set of four corners with a grid of cells, each with its own local homography, blended into a smooth sampling field; with a 1x1 grid it is identical to the global IHN.
Both paths produce a homography per frame pair. The shared back end turns that sequence into a stabilized clip: it accumulates the per frame motion into a camera path, smooths the path (Gaussian, Kalman RTS, or L1-TV), warps each frame by the difference between the original and smoothed path on the GPU, and auto crops to the largest rectangle that stays inside every warped frame.
Results
All numbers below are measured on an RTX 5070 Ti laptop GPU (Blackwell, sm_120), torch 2.11.0+cu128.
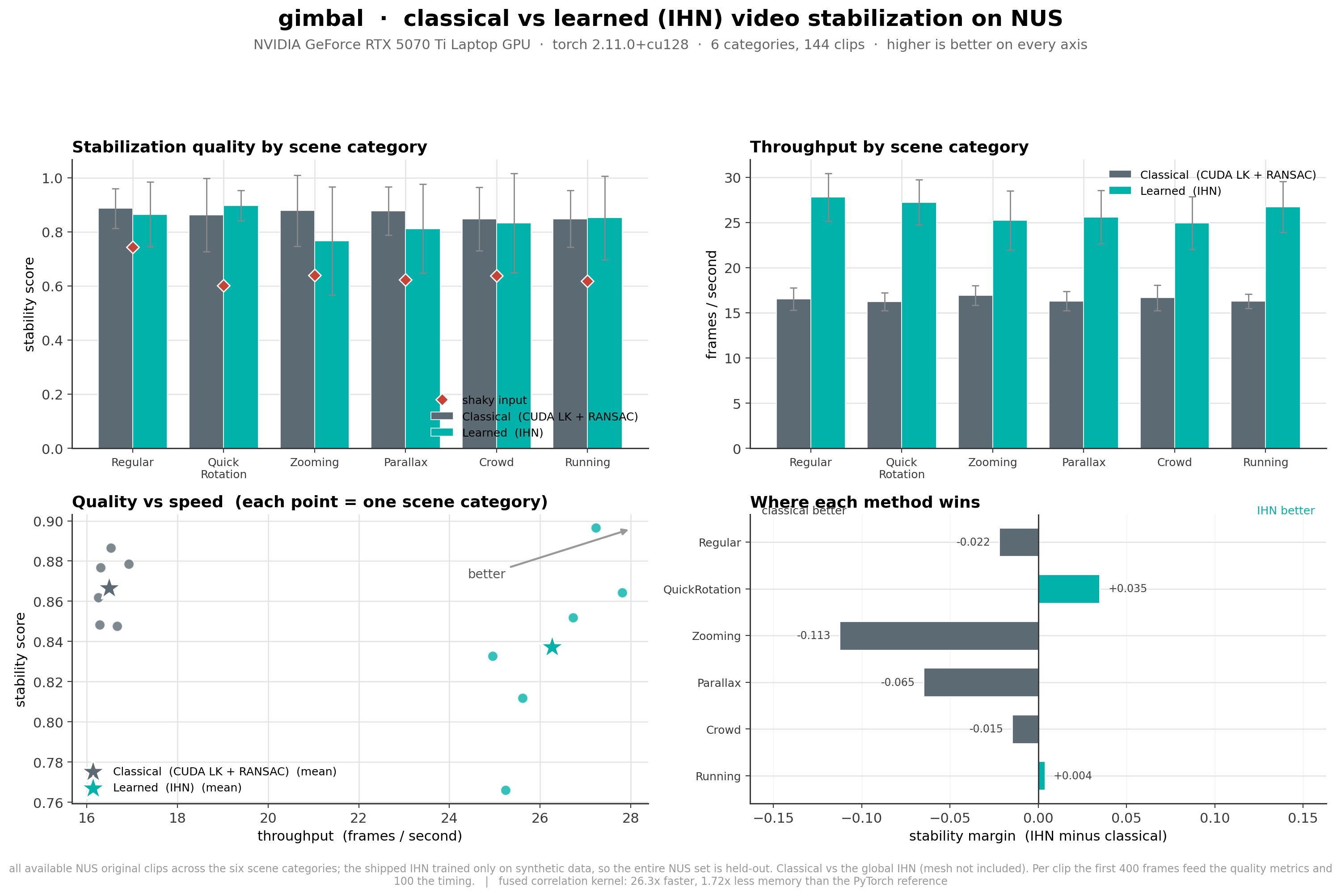
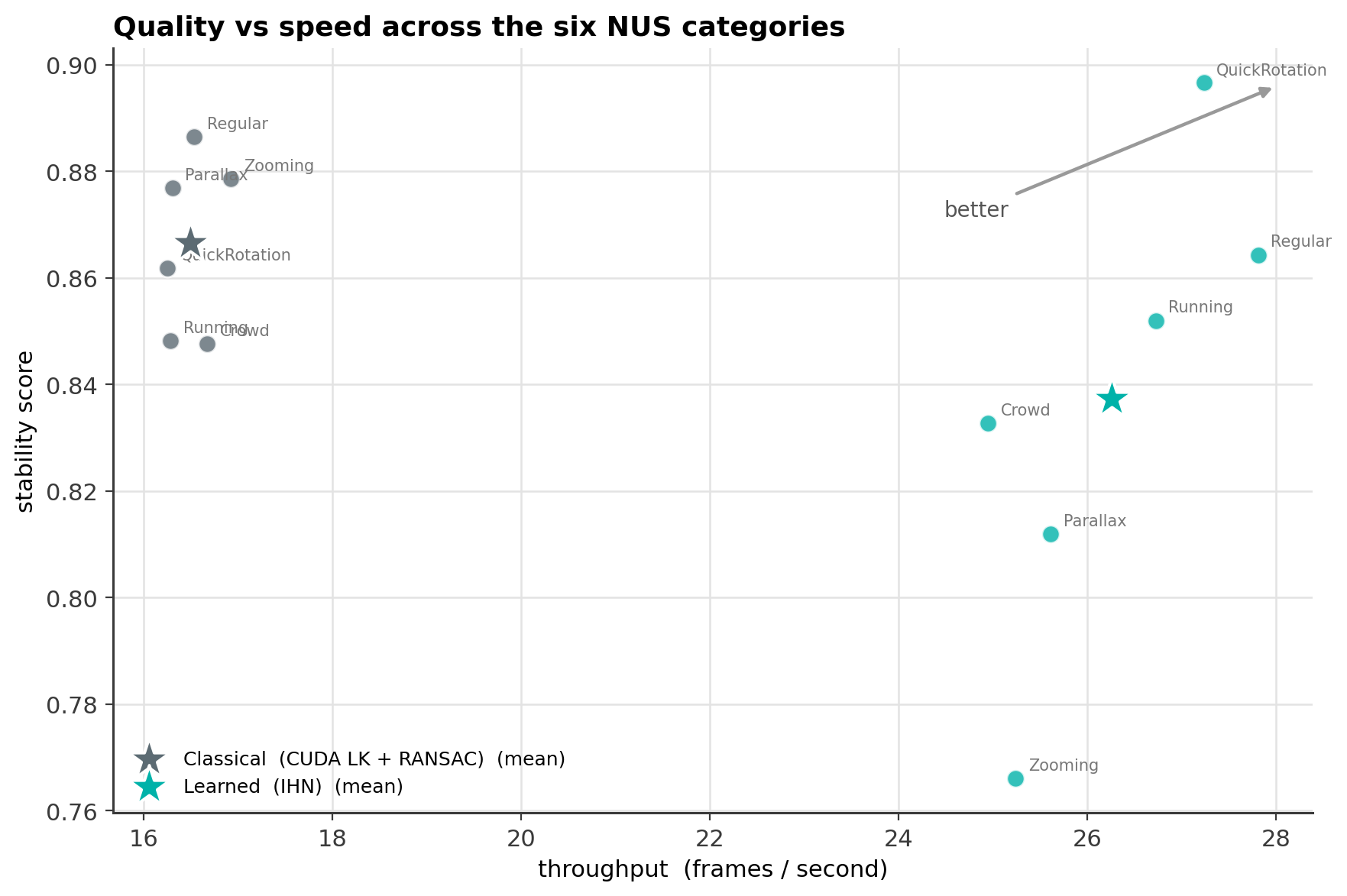
Stabilization on NUS
Classical against the learned IHN across all six NUS scene categories (144 clips, the shipped IHN trained only on synthetic data so the entire NUS set is held out). Higher stability is better; the throughput column is the per frame rate.
| Category | Classical stability | IHN stability | Classical fps | IHN fps |
|---|---|---|---|---|
| Regular | 0.886 | 0.864 | 16.5 | 27.8 |
| QuickRotation | 0.862 | 0.897 | 16.3 | 27.2 |
| Zooming | 0.879 | 0.766 | 16.9 | 25.2 |
| Parallax | 0.877 | 0.812 | 16.3 | 25.6 |
| Crowd | 0.848 | 0.833 | 16.7 | 24.9 |
| Running | 0.848 | 0.852 | 16.3 | 26.7 |
| Mean | 0.867 | 0.837 | 16.5 | 26.3 |
The IHN wins the hard rotation case and runs about 1.6x faster everywhere. The classical pipeline is steadier on large zoom and parallax, which are the motions furthest from the IHN's synthetic training distribution.
Training ablation
Mean average corner error (MACE) on held out synthetic COCO pairs, lower is better. The iterative model and the single shot regression baseline use the same data and encoder.
| Model | Best MACE |
|---|---|
| IHN (iterative, 6 steps) | 0.863 px |
| Regression baseline (single shot) | 6.489 px |
Iterative refinement is roughly 7.5x more accurate than predicting the homography in one shot, and it lands at sub pixel error.
Systems study
The cost volume operator and the inference loop, measured on the same GPU. The full study, including the roofline and the optimization log, is in perf_study.
| Measurement | Result |
|---|---|
| Fused correlation against the PyTorch reference | 26.3x faster, 1.72x less memory |
| CUDA graph replay against eager inference | 11.4x faster (41.2 ms to 3.61 ms per call) |
| fp16 accuracy cost (MACE) | +0.002 px |
| bf16 accuracy cost (MACE) | +0.029 px |
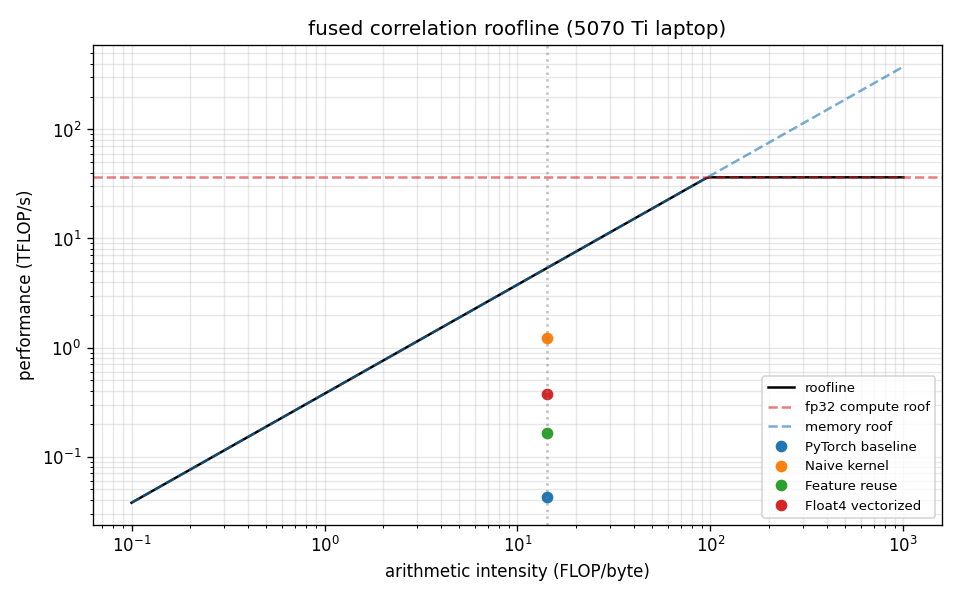
The roofline shows why the simplest kernel wins: at a 16x16 cost volume the operation is latency and occupancy bound, not compute bound, so launching enough threads with coalesced loads beats reducing arithmetic.
Correctness
Each GPU component is checked against an independent reference. The full suite is 41 tests.
| Check | Reference | Result |
|---|---|---|
| Scharr gradient kernel | OpenCV cv2.Scharr |
match to 1e-3 |
| Gaussian downsample kernel | OpenCV cv2.pyrDown |
match to 1e-2 |
| Shi-Tomasi corner response | NumPy and OpenCV reference | match |
| Classical estimator | known homography (cv2.warpPerspective) |
recovers translation and rotation |
| Tensor-DLT | known homography | match to 1e-3 |
| Tensor-DLT gradient | torch.autograd.gradcheck |
passes |
| Fused correlation forward | PyTorch reference | match to 1e-4 |
| Fused correlation backward | PyTorch autograd | match to 1e-4 |
| Fused correlation gradient | gradcheck in float64 | passes |
| No pivot DLT solve | cuSOLVER (torch.linalg.solve) |
match to 1e-4 |
| CUDA graph replay | eager execution | max error 4e-5 |
| Mesh 1x1 grid | single global homography | match to 1e-5 |
| Global MotionField path | raw homography product | bit exact |
| Phase B adoption guard | a deliberately degrading run | reverts to the kept weights |
The fused correlation operator is gated: it is only used after it passes the gradient check against the PyTorch reference, otherwise the model falls back to the reference implementation.
Build and install
The package is published as a source distribution. pip compiles the CUDA extension on your machine at install time, so it adapts to your CUDA version and GPU architecture, and the trained weights are bundled inside the package.
With a CUDA toolchain
pip install gimbal_engine
This needs an NVIDIA GPU and a CUDA toolkit (nvcc) that matches your PyTorch build. The build detects your GPU architecture; if nvcc is missing it stops with a clear message rather than a compiler error.
With Docker
If you do not have a local toolchain, the included image carries CUDA, PyTorch, and the build tools.
./run.ps1 image # build the image
./run.ps1 cli stabilize input.mp4 output.mp4 --estimator ihn
Use it
gimbal stabilize input.mp4 output.mp4 --estimator ihn # learned model, bundled weights
gimbal stabilize input.mp4 output.mp4 --estimator classical
gimbal benchmark # classical against IHN on NUS
gimbal info # GPU and library versions
gimbal requires CUDA cores, so will likely require an external GPU. It will proceed to error without this.
License
MIT. See LICENSE.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file gimbal_engine-2.1.1.tar.gz.
File metadata
- Download URL: gimbal_engine-2.1.1.tar.gz
- Upload date:
- Size: 3.2 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.14.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d8af1b6580e79ce0d258bdeb063c7c20729404a26ef2c704fefe2c0f5d04ed0f
|
|
| MD5 |
7543d02777a2f73af4e29eb3756d5351
|
|
| BLAKE2b-256 |
b4f8fd7029be1d9471ef79de86e2c06a810bc3020e6159e24bb651bd645e1ef7
|







