Leveraging graph data structures for complex feature engineering pipelines.

Project description
GraphReduce
Description
GraphReduce is an abstraction for building machine learning feature engineering pipelines that involve many tables in a composable way. The library is intended to help bridge the gap between research feature definitions and production deployment without the overhead of a full feature store. Underneath the hood, GraphReduce uses graph data structures to represent tables/files as nodes and foreign keys as edges.
GraphReduce allows for a unified feature engineering interface
to plug & play with multiple backends: dask, pandas, and spark are currently supported
Installation
# from pypi
pip install graphreduce
# from github
pip install 'graphreduce@git+https://github.com/wesmadrigal/graphreduce.git'
# install from source
git clone https://github.com/wesmadrigal/graphreduce && cd graphreduce && python setup.py install
Motivation
Machine learning requires vectors of data, but our tabular datasets
are disconnected. They can be represented as a graph, where tables
are nodes and join keys are edges. In many model building scenarios
there isn't a nice ML-ready vector waiting for us, so we must curate
the data by joining many tables together to flatten them into a vector.
This is the problem graphreduce sets out to solve.
An example dataset might look like the following:
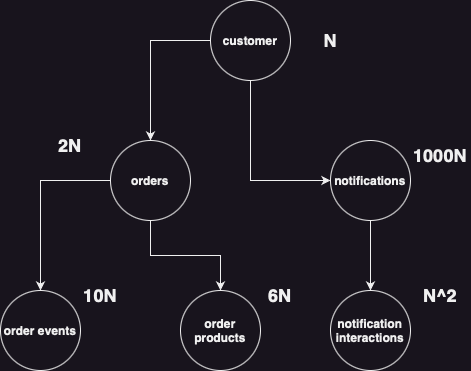
data granularity and time travel
But we need to flatten this to a specific granularity.
To further complicate things we need to handle orientation in time to prevent
data leakage and properly frame our train/test datasets. All of this
is controlled in graphreduce from top-level parameters.
example of granularity and time travel parameters
cut_datecontrols the date around which we orient the data in the graphcompute_period_valcontrols the amount of time back in history we consider during compute over the graphcompute_period_unittells us what unit of time we're usingparent_nodespecifies the parent-most node in the graph and, typically, the granularity to which to reduce the data
from graphreduce.graph_reduce import GraphReduce
from graphreduce.enums import PeriodUnit
gr = GraphReduce(
cut_date=datetime.datetime(2023, 2, 1),
compute_period_val=365,
compute_period_unit=PeriodUnit.day,
parent_node=customer
)
Node definition and parameterization
GraphReduce takes convention over configuration, so the user is required to define a number of methods on each node class:
do_annotateannotation definitions (e.g., split a string column into a new column)do_filtersfilter the data on column(s)do_clip_colsclip anomalies like exceedingly large values and do normalizationpost_join_annotateannotations on current node after relations are merged in and we have access to their columns, toodo_reducethe most import node function, reduction operations: group bys, sum, min, max, etc.do_labelslabel definitions if any At the instance level we need to parameterize a few things, such as where the data is coming from, the date key, the primary key, prefixes for preserving where the data originated after compute, and a few other optional parameters.
from graphreduce.node import GraphReduceNode
# define the customer node
class CustomerNode(GraphReduceNode):
def do_annotate(self):
# use the `self.colabbr` function to use prefixes
self.df[self.colabbr('is_big_spender')] = self.df[self.colabbr('total_revenue')].apply(
lambda x: x > 1000.00 then 1 else 0
)
def do_filters(self):
self.df = self.df[self.df[self.colabbr('some_bool_col')] == 0]
def do_clip_cols(self):
self.df[self.colabbr('high_variance_column')] = self.df[self.colabbr('high_variance_column')].apply(
lambda col: 1000 if col > 1000 else col
)
def post_join_annotate(self):
# filters after children are joined
pass
def do_reduce(self, reduce_key):
pass
def do_labels(self, reduce_key):
pass
cust = CustomerNode(
fpath='s3://somebucket/some/path/customer.parquet',
fmt='parquet',
prefix='cust',
date_key='last_login',
pk='customer_id'
)
Usage
Pandas
from graphreduce.node import GraphReduceNode
from graphreduce.graph_reduce import GraphReduce
class NodeA(GraphReduceNode):
def do_annotate(self):
pass
def do_filters(self):
pass
def do_clip_cols(self):
pass
def do_slice_data(self):
pass
def do_post_join_annotate(self):
import uuid
self.df[self.colabbr('uuid')] = self.df[self.colabbr(self.pk)].apply(lambda x: str(uuid.uuid4()))
def do_reduce(self, key):
pass
def do_labels(self, key):
pass
class NodeB(GraphReduce):
def do_annotate(self):
pass
def do_filters(self):
pass
def do_clip_cols(self):
pass
def do_slice_data(self):
pass
def do_post_join_annotate(self):
import uuid
self.df[self.colabbr('uuid')] = self.df[self.colabbr(self.pk)].apply(lambda x: str(uuid.uuid4()))
def do_reduce(self, key):
return self.prep_for_features().groupby(self.colabbr(reduce_key)).agg(
**{
self.colabbr(f'{self.pk}_counts') : pd.NamedAgg(column=self.colabbr(self.pk), aggfunc='count'),
self.colabbr(f'{self.pk}_min') : pd.NamedAgg(column=self.colabbr(self.pk), aggfunc='min'),
self.colabbr(f'{self.pk}_min'): pd.NamedAgg(column=self.colabbr(self.pk), aggfunc='max'),
self.colabbr(f'{self.date_key}_min') : pd.NamedAgg(column=self.colabbr(self.date_key), aggfunc='min'),
self.colabbr(f'{self.date_key}_max') : pd.NamedAgg(column=self.colabbr(self.date_key), aggfunc='max')
}
).reset_index()
def do_labels(self, key):
pass
nodea = NodeA(fpath='nodea.parquet', fmt='parquet', date_key='ts', prefix='nodea', pk='id')
nodeb = NodeB(fpath='nodeb.parquet', fmt='parquet', date_key='created_at', prefix='nodeb', pk='id')
gr = GraphReduce(
cut_date=datetime.datetime(2023,5,1),
parent_node=nodea,
compute_layer=ComputeLayerEnum.pandas
)
gr.add_entity_edge(
parent_node=nodea,
relation_node=nodeb,
parent_key='id',
relation_key='nodea_foreign_key_id',
relation_type='parent_child',
reduce=True
)
# plot the graph to see what compute graph will run
# note, you may have to open this file in a browser
gr.plot_graph(fname='demo_graph.html')
# perform all transformations
gr.do_transformations()
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file graphreduce-0.6.tar.gz.
File metadata
- Download URL: graphreduce-0.6.tar.gz
- Upload date:
- Size: 12.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.9.16
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2517740d9f18acc270b96163e41d69924f4d59295aae416e79a8a042b7e690d8
|
|
| MD5 |
1222d27e9db077fecf354e13bbfdacf1
|
|
| BLAKE2b-256 |
9bf5483fdf02050eebfe057115f4638cf8f7f8099c7a1906871a71b081152abc
|







