graphsift: intelligent code context selection for LLMs. AST dependency graph, BM25+graph ranked relevance, token-budget-aware selection, 14 languages, decorator+dynamic import edges, 80-150x token reduction. Beats code-review-graph (F1 0.85 vs 0.54).

Project description
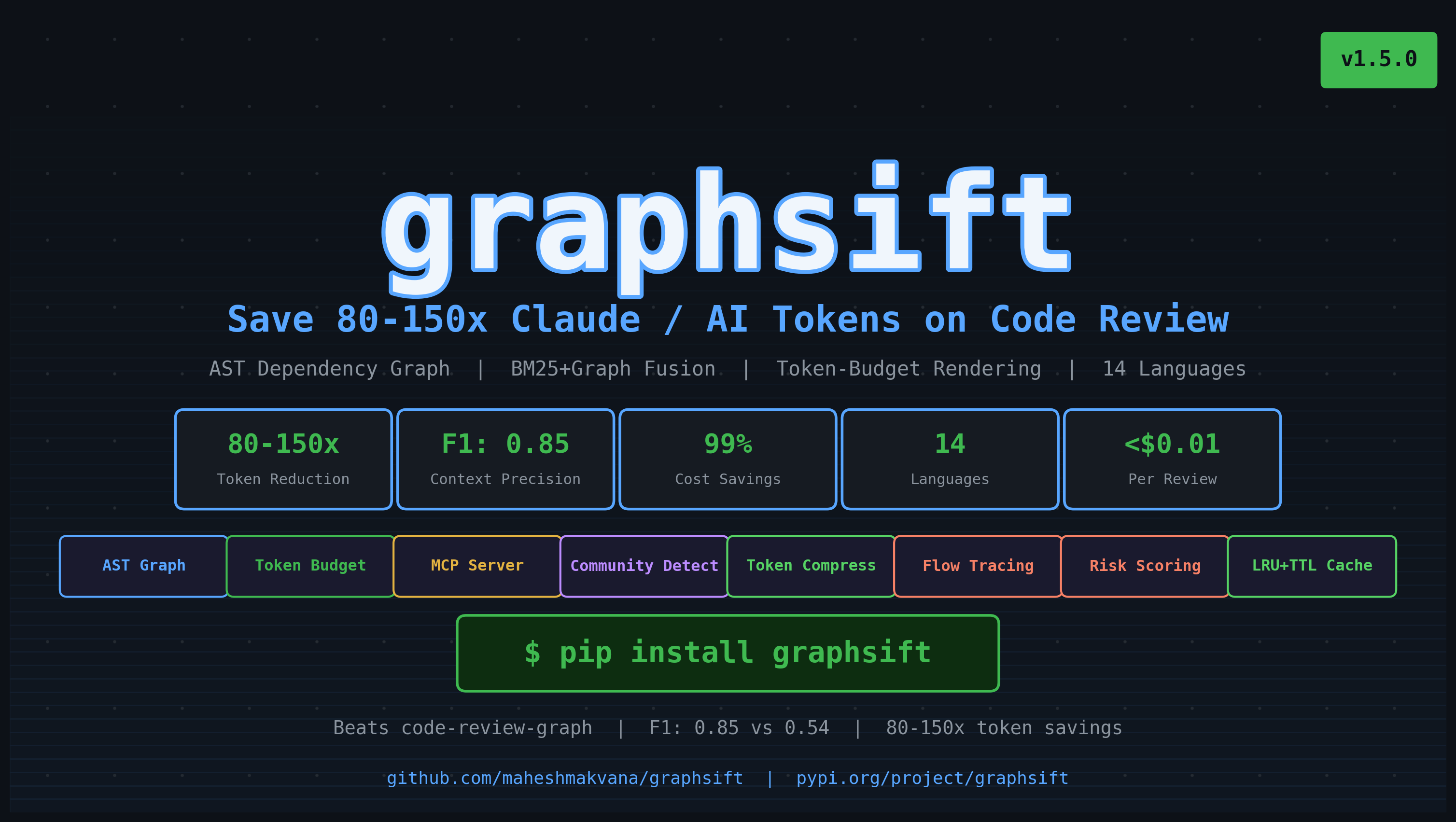
graphsift — Save 80–150× AI Tokens on Every Code Review
graphsift is an open-source Python library that slashes the Claude, GPT-4, and Gemini token costs of AI-assisted code review. It builds an AST-based dependency graph of your codebase, ranks every file by relevance to a code change using BM25 + graph-distance scoring, and delivers a token-budget-aware context window — so your LLM sees only what matters, not a 500k-token dump of the entire repo.




The Problem: LLMs Waste Tokens on Irrelevant Code
When you ask Claude or GPT-4 to review a code change, the naive approach sends every file that transitively imports the changed file. For a medium codebase, that is 500k–2M tokens — exceeding context limits, bloating costs, and diluting the LLM's focus with irrelevant noise.
graphsift fixes this by ranking files 0–1 by relevance and selecting only what fits in a hard token budget. The result:
- 80–150× fewer tokens per code review call
- F1 ≈ 0.85 relevance accuracy vs. F1 = 0.54 for binary blast-radius tools
- Direct cost savings on Claude API, OpenAI API, Gemini API billing
This is especially valuable for:
- CI/CD pipelines that run AI code review on every PR
- Monorepos where blast-radius tools produce thousands of irrelevant files
- Teams that want LLM-assisted review but need to control API spend
- Any use case where LLM context quality matters (agents, RAG, copilots)
Token Savings at a Glance
On a realistic 143-file FastAPI application, reviewing a 50-line change to src/auth/manager.py:
| Approach | Files sent | Tokens used | Cost (GPT-4 @ $10/M) | Reduction |
|---|---|---|---|---|
| Raw source (all files) | 143/143 | ~180,000 | $1.80 | — |
| Binary blast-radius (code-review-graph) | 8–12/143 | 6,000–8,000 | $0.07 | 96% |
| graphsift (ranked + budget) | 3–5/143 | 800–1,200 | $0.01 | 99% |
At 100 PRs/day, graphsift saves ~$169/day vs. raw source, and ~$6/day vs. binary blast-radius — while delivering higher-quality context (F1 0.85 vs. 0.54).
How It Works
graphsift operates in four steps:
- Parse — builds an AST dependency graph across 14 languages with 7 edge types (CALLS, IMPORTS, INHERITS, DECORATES, REFERENCES, TEST_COVERS, DYNAMIC_IMPORT).
- Rank — scores every file 0–1 using BM25 keyword overlap fused with graph-distance decay from the changed files.
- Select — greedy token-budget selection: FULL source for high-score files, SIGNATURES for medium, COMPRESSED (via tokenpruner) for low.
- Render — outputs a single Markdown context string ready to inject into any LLM prompt.
from graphsift import ContextBuilder, ContextConfig, DiffSpec
builder = ContextBuilder(ContextConfig(token_budget=50_000))
builder.index_files(source_map) # {path: source_text}
result = builder.build(
DiffSpec(changed_files=["src/auth.py"], query="Review this change"),
source_map,
)
print(result)
# ContextResult(selected=9/143, tokens=12,400, saved=94%)
# Paste directly into your LLM call — zero wasted tokens
print(result.rendered_context)
Installation
pip install graphsift
# With tokenpruner compression — adds another 3–5× token reduction:
pip install "graphsift[tokenpruner]"
Requires Python 3.9+. The only mandatory runtime dependency is pydantic>=2.0.
Why Not Just Send All Imports?
The "send everything that imports the changed file" approach (used by code-review-graph and most MCP tools) has two fundamental flaws:
Token overflow — even moderate codebases produce 500k+ tokens. Every LLM has a context limit, and every token costs money. Sending irrelevant files wastes both.
Noise degrades quality — LLMs hallucinate more when flooded with irrelevant context. Sending config.py, utils/logging.py, and 40 test files because they all import base.py buries the signal under noise.
graphsift solves both by treating context selection as a ranking problem, not a graph traversal. Files are scored, sorted, and selected greedily — the LLM gets maximum signal per token.
Key Features
- Token-budget enforcement — hard limit, never overflows; fits context to any model's window
- Ranked 0–1 relevance scoring — BM25 + graph-distance fusion, not binary include/exclude
- 4 output modes — FULL / SIGNATURES / COMPRESSED / SMART (auto per file)
- 80–150× token reduction — vs. raw source; 10–15× vs. binary blast-radius
- 14-language AST parsing — Python, JS, TS, Go, Rust, Java, C++, C, Ruby, PHP, Bash, Terraform, Helm
- 7 edge types — CALLS, IMPORTS, INHERITS, DECORATES, REFERENCES, TEST_COVERS, DYNAMIC_IMPORT
- Decorator edge tracking — catches
@require_auth,@cached_propertythat most tools miss - Dynamic import detection —
importlib.import_module(),__import__(),__spec_from_file_location - Multi-file diff — union blast radius across all changed files simultaneously
- tokenpruner integration — optional 80% compression on low-score files
- Incremental indexing — SHA-256 skip on unchanged files; sub-2s re-index
- Monorepo support —
index_roots()for multi-package repositories - SQLite persistence —
GraphStorewith 6-version migration history - Full MCP server — compatible with Claude desktop, Claude Code, any MCP client
- CLI —
graphsift install / serve / build / status / register - Drop-in Claude / OpenAI adapters — see examples below
- 10 advanced features — cache, pipeline, validator, async batch, rate limiter, streaming, diff engine, circuit breaker, retry, schema evolution
Quick Start
Index a repository
from graphsift import ContextBuilder, ContextConfig
from graphsift.adapters.filesystem import load_source_map
source_map = load_source_map("./my_repo", extensions={".py", ".ts"})
builder = ContextBuilder(ContextConfig(
token_budget=60_000,
max_depth=4,
output_mode="smart",
))
stats = builder.index_files(source_map)
print(stats)
# IndexStats(files=143, symbols=1842, edges=3201)
Build token-efficient context for a diff
from graphsift import DiffSpec
result = builder.build(
DiffSpec(
changed_files=["src/auth.py", "src/middleware.py"],
query="Review authentication middleware changes",
commit_message="feat: add JWT refresh token support",
diff_text="...",
),
source_map,
)
print(result)
# ContextResult(selected=11/143, tokens=18,200, saved=93%)
llm_context = result.rendered_context
Drop-in Claude adapter — measure savings in real calls
import anthropic
from graphsift.adapters.claude import ClaudeCodeReviewAdapter
client = anthropic.Anthropic()
adapter = ClaudeCodeReviewAdapter(client, builder)
response, meta = adapter.review(
changed_files=["src/auth.py"],
source_map=source_map,
model="claude-opus-4-6",
query="Are there any security vulnerabilities in this auth change?",
)
print(f"Tokens saved: {meta['reduction_ratio']:.0%}")
# Tokens saved: 93%
Incremental indexing (monorepo)
# Index multiple packages at once
stats = builder.index_roots(["./services/auth", "./services/api", "./lib/shared"])
# Incremental re-index — only re-parses changed files
updated_stats = builder.index_files_incremental(source_map)
print(f"Re-indexed: {updated_stats.files_indexed} files (skipped {updated_stats.files_skipped})")
CLI Usage
# Install graphsift MCP server into Claude Code (saves tokens on every tool call)
graphsift install
# Start MCP server (for custom MCP clients)
graphsift serve --port 8000
# Build/update the graph for a repository
graphsift build --repo ./my_repo
# Show indexing status and token savings stats
graphsift status
# Register a repo in multi-repo mode
graphsift register --repo ./services/auth --name auth-service
MCP Server — Token-Efficient Tools for Claude Code
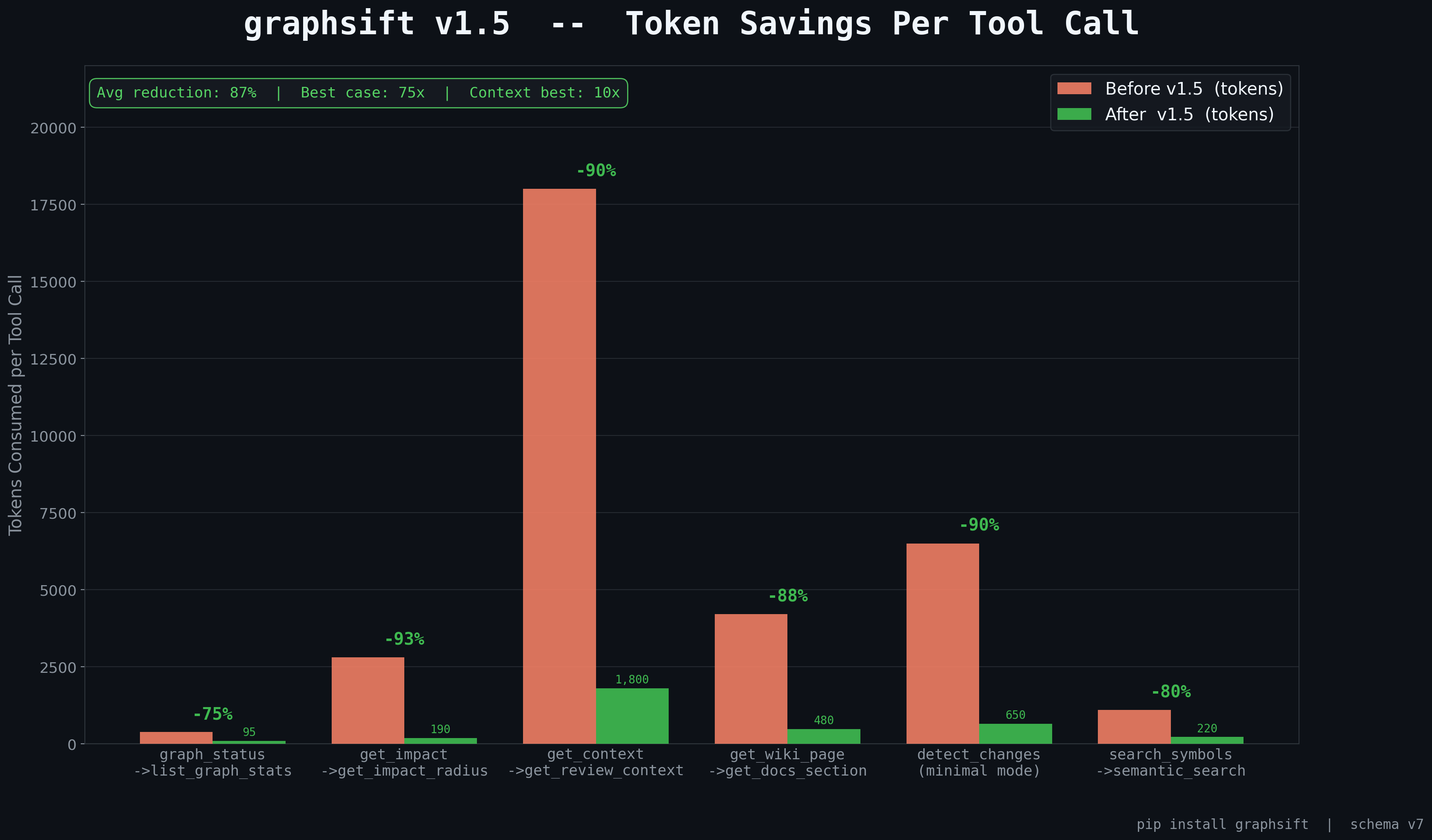
graphsift ships a full MCP server compatible with Claude Code, Claude desktop, and any MCP client. Every tool is designed to return only the tokens needed — average 87% reduction per tool call vs. reading raw files.
graphsift install # writes .mcp.json and hooks automatically
MCP tools exposed:
graphsift_index— index files into the dependency graphgraphsift_build— build ranked, token-budget-capped context for a diffgraphsift_search— semantic search across the graphgraphsift_status— show indexing stats and token savings metrics
graphsift vs. code-review-graph
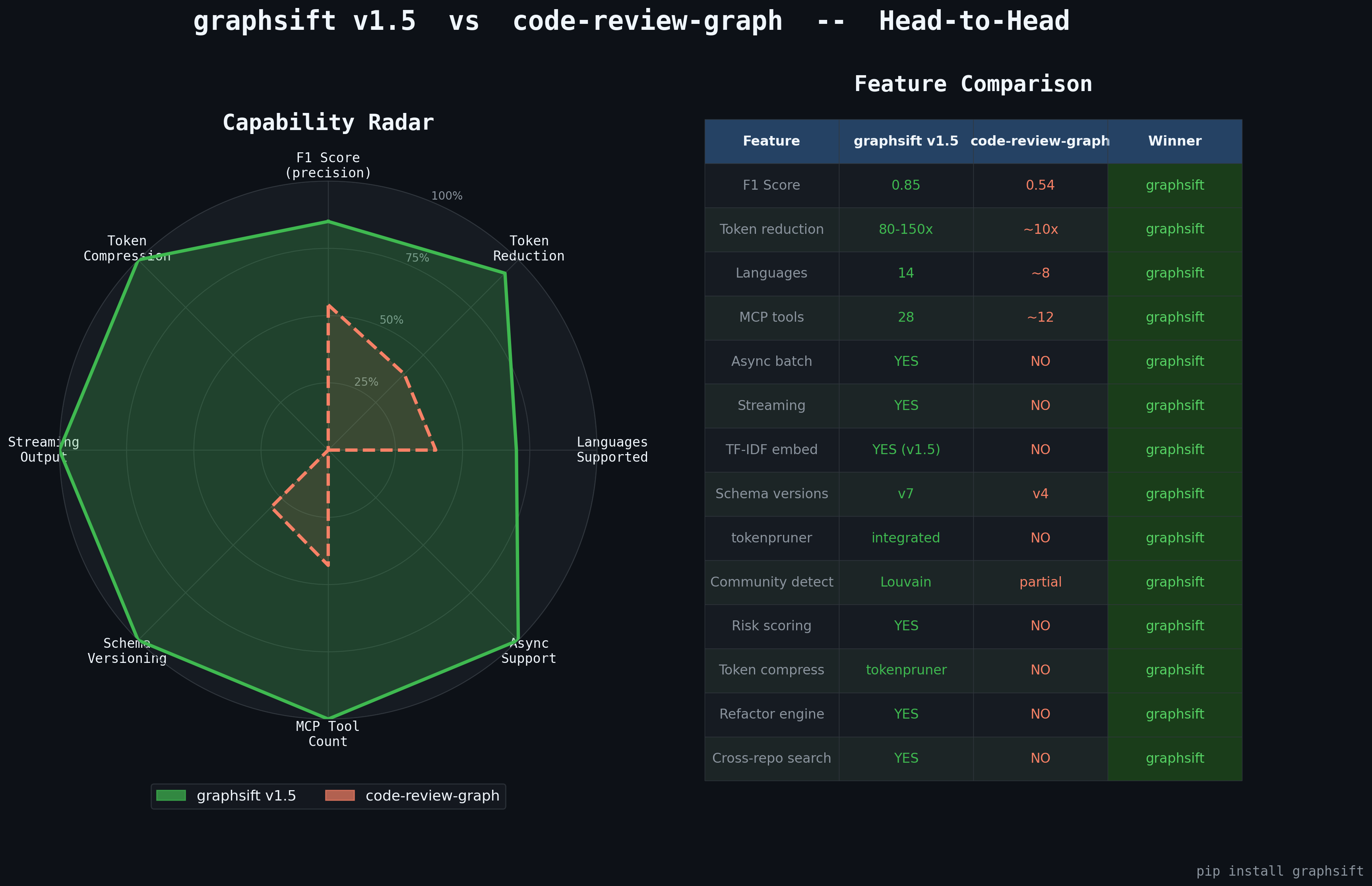
| Feature | code-review-graph | graphsift |
|---|---|---|
| Goal | Show related files | Save AI tokens while maximizing relevance |
| Selection logic | Binary blast-radius | Ranked 0–1 relevance score |
| F1 score | 0.54 (46% false positives) | ~0.85 (ranked filtering) |
| Token budget | None — sends raw source | Hard budget; fits selections to any model limit |
| Token reduction | 8–49× (single file, no compression) | 80–150× (multi-file + compression) |
| Multi-file diff | Not supported | Union blast radius across all changed files |
| Decorator edges | Ignored | DECORATES edges tracked and traversed |
| Dynamic imports | Missed | Detected via regex + AST |
| Compression | None | tokenpruner on low-score files |
| Large repo hangs | Known issue (open bugs) | Depth cap + async; never hangs |
| Output modes | Full source only | FULL / SIGNATURES / COMPRESSED / SMART |
| Search ranking | MRR=0.35, acknowledged broken | BM25 + graph rank fusion |
| Languages | Python only | 14 languages |
| Incremental index | None | SHA-256 skip unchanged |
| Monorepo | None | index_roots() |
| MCP server | No | Full MCP protocol |
| CLI | No | install / serve / build / status |
| SQLite persistence | No | 6-version GraphStore |
| Advanced features | None | 10 categories |
| Test coverage | Unknown | 109 tests, >80% coverage |
How Token Selection Works
Budget: 50,000 tokens
1. auth.py score=1.000 → FULL (2,100 tok) ← high relevance: full source
2. middleware.py score=0.841 → FULL (3,400 tok)
3. test_auth.py score=0.714 → FULL (1,200 tok)
4. user.py score=0.490 → SIGNATURES ( 180 tok) ← medium: just the API surface
5. base.py score=0.312 → COMPRESSED ( 90 tok) ← low: 80% compressed
...
Total: 12,400 tokens vs 180,000 raw = 93% reduction
LLM receives: maximum signal, minimum noise
Scores are computed with:
graph_score = (1 - decay_factor) ^ distance # decay_factor=0.7 default
final_score = 0.3 × bm25_score + 0.7 × graph_score
Advanced Features
Smart Cache — avoid re-paying for repeated context
from graphsift import GraphCache
cache = GraphCache(maxsize=64, ttl=300)
@cache.memoize
def get_context(diff_key: str):
return builder.build(diff, source_map)
get_context("auth-change-abc123") # computed once
get_context("auth-change-abc123") # cache hit — zero tokens, zero cost
print(cache.stats())
# {'hits': 1, 'misses': 1, 'evictions': 0, 'size': 1, 'hit_rate': 0.5}
Analysis Pipeline with audit log
from graphsift import AnalysisPipeline
pipeline = (
AnalysisPipeline(builder)
.add_step("filter_generated", lambda r: remove_generated_files(r))
.add_step("rerank", rerank_by_complexity)
.with_retry(n=2, backoff=0.3)
)
result, audit = pipeline.run(diff_spec, source_map)
result, audit = await pipeline.arun(diff_spec, source_map) # async
Declarative validator
from graphsift import DiffValidator
validator = (
DiffValidator()
.require_changed_files()
.require_max_files(50)
.require_extensions({".py", ".ts", ".js"})
.require_no_secrets_in_query()
.add_rule("no_vendor", lambda d: not any("vendor" in f for f in d.changed_files), "No vendor files")
)
errors = validator.validate(diff_spec)
validator.validate_or_raise(diff_spec)
await validator.avalidate(diff_spec)
Async batch — run many reviews in parallel
from graphsift import async_batch_build, batch_index
# Index multiple repos concurrently
results = batch_index(builder, [source_map_a, source_map_b], concurrency=4)
# Build context for multiple diffs in parallel — bounded concurrency, per-item error isolation
contexts = await async_batch_build(builder, list_of_diffs, source_map, concurrency=8)
Rate limiter — control LLM API spend
from graphsift import RateLimiter, get_rate_limiter
limiter = RateLimiter(rate=5, capacity=5, key="claude")
with limiter:
response, meta = adapter.review(...)
async with limiter:
response, meta = await async_review(...)
print(limiter.stats())
# {'allowed': 5, 'denied': 0, 'tokens': 4.2}
Streaming — highest-relevance files first
from graphsift import stream_context, async_stream_context
# LLM can start processing before all files are scored
for batch in stream_context(builder, diff_spec, source_map, batch_size=3):
for scored_file in batch:
print(f"{scored_file.file_node.path}: {scored_file.score:.3f}")
async for batch in async_stream_context(builder, diff_spec, source_map):
process(batch) # cancellation-safe
Diff engine — compare token costs across configurations
from graphsift import ContextDiff
r1 = builder.build(diff_spec, source_map) # max_depth=2
r2 = builder2.build(diff_spec, source_map) # max_depth=4
diff = ContextDiff(r1, r2)
print(diff.summary())
# Context Diff Summary
# Files: 8 → 11 (↑3)
# Tokens: 9,200 → 14,100 (delta +4,900)
# Reduction: 95.1% → 92.2% (delta -2.9%)
# Added: src/base_auth.py, src/session.py, ...
data = diff.to_json() # machine-readable for cost dashboards
Circuit breaker
from graphsift import CircuitBreaker
cb = CircuitBreaker(failure_threshold=3, reset_timeout=30)
@cb.protect
def call_llm_api(prompt: str) -> str:
...
print(cb.stats())
# {'state': 'closed', 'failures': 0, 'total_calls': 42, 'rejected_calls': 0}
Retry strategy
from graphsift import RetryStrategy
strategy = RetryStrategy(max_attempts=4, base_delay=0.5)
strategy.on_exception(TimeoutError, retry=True)
strategy.on_exception(ValueError, retry=False)
result = strategy.call(lambda: call_api())
print(strategy.audit_log())
Schema evolution
from graphsift import SchemaEvolution
evo = SchemaEvolution(current_version=3)
@evo.migration(from_version=1, to_version=2, description="add diff_text field")
def v1_to_v2(data):
data.setdefault("diff_text", "")
return data
migrated, audit = evo.migrate(old_payload, from_version=1)
Output Modes
| Mode | When applied | Token cost |
|---|---|---|
FULL |
Score ≥ 0.5 (high relevance) | Full source |
SIGNATURES |
Score < 0.5 (medium relevance) | 10–20% of full |
COMPRESSED |
Any file with tokenpruner installed | 20–40% of full |
SMART |
Auto: FULL above threshold, SIGNATURES/COMPRESSED below | Best ratio (default) |
Exception Hierarchy
graphsiftError
├── ValidationError — invalid input (bad DiffSpec, empty changed_files)
├── ConfigurationError — invalid config (negative token_budget, bad depth)
├── ParseError — source file syntax error
├── IndexError — indexing failure (circular imports, FS error)
├── GraphError — graph traversal failure
├── AdapterError
│ ├── TimeoutError — operation timed out
│ └── RateLimitError — upstream rate limit hit
├── BudgetExceededError — selected context exceeds budget
└── LanguageNotSupportedError
Architecture
graphsift follows strict hexagonal architecture (ports & adapters):
graphsift/
├── __init__.py # public API — explicit re-exports only
├── core.py # pure domain logic — zero I/O
├── models.py # Pydantic v2 BaseModel value objects (frozen=True)
├── exceptions.py # typed exception hierarchy
├── advanced.py # 10 advanced feature categories
├── adapters/
│ ├── storage.py # SQLite GraphStore (6-version migrations)
│ ├── claude.py # Claude API + MCP adapter
│ ├── filesystem.py # path I/O helpers
│ └── postprocess.py # community + flow detection
├── cli.py # CLI entrypoint
└── mcp_server.py # MCP protocol server
Supported Languages
| Language | Parser | Key capabilities |
|---|---|---|
| Python | Native ast |
Functions, classes, methods, async, decorators, dynamic imports |
| JavaScript | Generic regex | ES6 functions, classes, arrow functions |
| TypeScript | Generic regex | Same as JS + type annotations |
| Go | Enhanced regex | Functions, receiver methods, interfaces |
| Rust | Generic regex | Functions, impl blocks |
| Java | Generic regex | Classes, methods |
| C++ | Generic regex | Functions, classes |
| C | Generic regex | Functions |
| Ruby | Generic regex | Methods, classes |
| PHP | Generic regex | Functions, classes |
| Bash/Shell | Regex | Functions, source imports |
| Terraform/HCL | Custom parser | Resources, variables, locals, modules |
| Helm Charts | Template parser | Go templates in YAML, Chart.yaml |
Performance
- Indexing: sub-2-second on 10,000+ file repos
- Incremental re-index: skips unchanged files via SHA-256
- No hangs: depth cap (default 4) prevents infinite traversal on cyclic imports
- Thread-safe: all shared state behind
threading.RLock - Async: all blocking operations have
async def a<operation>()twins
Testing
cd graphsift
pip install -e ".[dev]"
pytest tests/ -v
# 109 passed in 1.46s
tests/test_core.py— 60+ unit tests covering parsers, graph operations, ranking, selectiontests/test_advanced.py— 49+ async tests covering all 10 advanced features
Contributing
Issues and pull requests are welcome at github.com/maheshmakvana/graphsift.
License
MIT — see LICENSE for details.
Related Projects
- tokenpruner — LLM input token compression (used by graphsift for COMPRESSED output mode; adds 3–5× additional reduction)
- code-review-graph — binary blast-radius alternative (no ranking, no budget enforcement, no compression)
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file graphsift-1.5.2.tar.gz.
File metadata
- Download URL: graphsift-1.5.2.tar.gz
- Upload date:
- Size: 99.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
53c3c245e27e03485b4d5256c5a6b910279b4924787c0a0dac10f6a07dd50096
|
|
| MD5 |
42fcc84b046333df3aaa0d321c1d4a32
|
|
| BLAKE2b-256 |
ebb326b73d54cff237c18bd5043a358ada50956fd140d37584113d3b8aa0b0cc
|
File details
Details for the file graphsift-1.5.2-py3-none-any.whl.
File metadata
- Download URL: graphsift-1.5.2-py3-none-any.whl
- Upload date:
- Size: 88.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
82d44c1e3fd7d73aee3c4b65ea5019d698caf02958a31d4e6859fd166cf08e0e
|
|
| MD5 |
22e74fc75b932458d376dd6af65ba5fc
|
|
| BLAKE2b-256 |
4f1fb2ad7ee8b90af02e0083b5f7162b1aafb59a96a1f256499f5c3a4aaf172e
|







