Automated detection of social group appeals in text

Project description
Group Appeal Detector




This Python package detects social group mentions in text and classifies the author's stance toward each group as positive, negative, or neutral via fine-tuned BERT models. It also supports grouping appeals into qualitative categories by performing k-means clustering on the appeals' vector representations.
Installation
pip install group-appeal-detector
Quick Start
Detect social group mentions and the author's stance toward each group in a single call. Use device="cuda" or device="mps" to run on GPU.
from group_appeal_detector import GroupAppealDetector
sentence = "Our party supports the interests of young people and working families."
detector = GroupAppealDetector(device="cpu")
results = detector.detect(sentence)
for r in results:
print(r["span"], r["stance"])
Usage
Users can classify social group mentions and the authors' stances toward the groups separately from each other or do both in one run. Qualitative category assignments for distinguishing between different social groups can be obtained by performing clustering on the embedding space.
Group Mention Detection
Detect group mentions in a single text or a batch. For batches, pass a list of sentences and control how many should be processed in parallel by setting the batch_size. Increase it on GPU, decrease it if you run into memory issues. Results can be returned as a list of dicts or a pandas DataFrame via as_df=True.
# classify a single sentence
sentence = "Our party supports the interests of young people and working families."
results = detector.detect_mentions(sentence)
for r in results:
print(r["span"], r["start"], r["end"])
# classify a batch of sentences
sentence_1 = "Farmers must earn more money."
sentence_2 = "The government must do more to protect the women living in this country."
sentences = [sentence_1, sentence_2]
results_df = detector.detect_mentions_batch(sentences, batch_size=8, as_df=True)
results_df.head()
Stance Classification
Classify the author's stance toward a specific group as positive, negative, or neutral. For batches, pass a list of (text, group) pairs. Results include the predicted stance and the probability for each class.
# classify a single text
sentence = "We must protect the rights of farmers."
target_group = "farmers"
result = detector.classify_stance(sentence, target_group)
print(result["predicted_stance"], result["stance_probs"])
# classify a batch of (text, group) pairs
pairs = [
("We must protect the rights of farmers.", "farmers"),
("We do a lot for elderly people.", "elderly people"),
]
results_df = detector.classify_stance_batch(pairs, batch_size=8, as_df=True)
results_df.head()
Combined Detection
If the interest is of both the location of a social group mention and the author's stance toward it, classify both in one go. This can again be done for a single sentence as well as for a larger number of sentences via batch processing.
# classify a single sentence
sentence = "Our party supports the interests of young people and working families."
results = detector.detect(sentence)
for r in results:
print(r["span"], r["stance"])
# classify a batch of sentences
sentence_1 = "Farmers must earn more money."
sentence_2 = "The government must do more to protect the women living in this country."
sentences = [sentence_1, sentence_2]
results_df = detector.detect_batch(sentences, batch_size=8, as_df=True)
results_df.head()
Clustering
Cluster detected group mentions into categories using GroupMentionClusterer. It performs k-means clustering on vector representations produced by a BERT model fine-tuned via contrastive learning to maximize separability between different social groups. Set n_clustersto the number of clusters the algorithm should produce.
from group_appeal_detector import GroupAppealDetector, GroupMentionClusterer
# collect mentions from a corpus
texts = [...]
all_mentions = detector.detect_mentions_batch(texts, batch_size=16, as_df=False)
mentions = [m["span"] for mentions in all_mentions for m in mentions]
# cluster the mentions
clusterer = GroupMentionClusterer(mentions, device="cpu")
results_df = clusterer.cluster(n_clusters=5, as_df=True)
results_df.head()
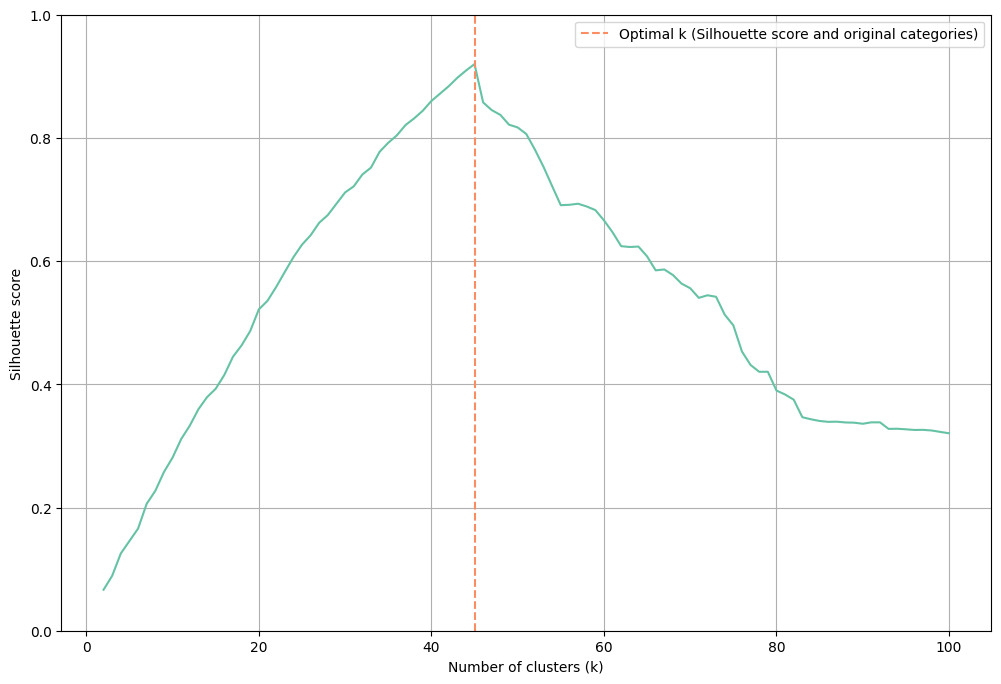
If there is no prior knowledge on a likely number of clusters, make use of find_optimal_k to determine the best number of clusters before running cluster. This method computes the average silhouette score and returns the kthat maximizes this internal validation metric. Inspect the development of silhouette scores over increasing number of kif desired.
# collect mentions from a corpus
texts = [...]
all_mentions = detector.detect_mentions_batch(texts, batch_size=16, as_df=False)
mentions = [m["span"] for mentions in all_mentions for m in mentions]
# find the optimal k based on silhouette score
best_k, all_scores = clusterer.find_optimal_k(k_range=(2, 20), metric="silhouette", visualize=True)
# run with best k
results_df = clusterer.cluster(n_clusters=best_k, as_df=True)
results_df.head()
Alternatively, if a reference dictionary of known social group categories is available, the optimal k can be determined by maximizing the Normalized Mutual Information (NMI) score between cluster assignments and dictionary-based category labels. Pass the dictionary as a pandas DataFrame where each column represents a category and each row contains example terms. The method then finds all group mentions that match any example term and computes the NMI-score based on the known social group categories of the detected terms and the cluster assignments for these terms.
By maximizing the NMI-score one maximizes the reproducibility of the known social group categories within the data while still being able to detect new categories. Users can also decide based on both the silhouette and NMI-score in order to balance both internal and external validation metrics.
import pandas as pd
dictionary_df = pd.read_csv("social_groups.csv")
# find the optimal k based on nmi score
best_k, all_scores = clusterer.find_optimal_k(
k_range=(2, 20),
metric="nmi",
dictionary_df=dictionary_df,
visualize=True,
)
# run with best k
results_df = clusterer.cluster(n_clusters=best_k, as_df=True)
results_df.head()
Visualization
The development of silhoutte or NMI scores over an increasing number of clusters kcan be easily visualized by setting visualize = True in the find_optimal_k() This directly leads to a graph similar to this one. Inspecting the scores visually can be especially helpful to detect plateaus in performance scores which would remain unnoticed if one only concentrates on the highest value.
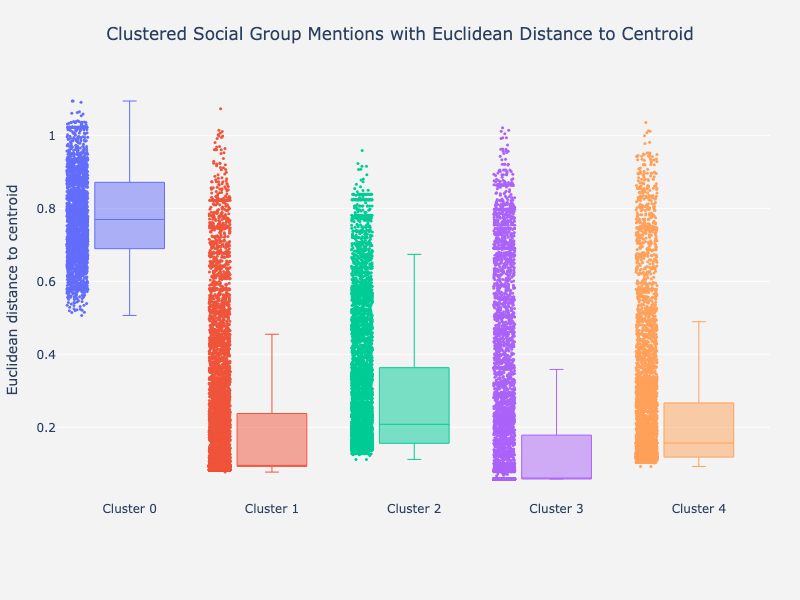
When having decided on one cluster structure, one can visualize the clusters' composition by plotting the Euclidean distance of all group appeals' embeddings to their respective cluster centroid as boxplots. Note that because the embeddings have been L2-normalized the Euclidean distance directly corresponds to the Cosine similarity. For drawing the boxplots the plotly package is used which allows for an interactive examination of all data points (i.e. looking at the mentions' text and the exact distance). This enables to inspect the clustering quality and to assign each cluster a meaningful name if desired.
clusterer.visualize_clusters_boxplot(
cluster_df = results_df,
cluster_col = "cluster_id",
distance_col = "distance_to_centroid",
mention_col = "mention"
)
Conceptual Background
The definitions of a social group and a social group appeal used for annotating the training data package are largely inspired by Lena Maria Huber and Alona O. Dolinsky and Will Horne, Alona O. Dolinsky and Lena Maria Huber.
A social group is a segment of society or a collection of people who share common sociodemographic traits or attributes that are ascriptive and/or acquired. A reference to a social group in text is called a group mention. A group appeal is an intentional act that associates a political actor with a social group in either a supportive or critical manner.
Models
Group Mention Detection — maxwlnd/roberta_group_mention_detector
A RoBERTa-base token classification model fine-tuned on 5,000 manually annotated sentences drawn from parliamentary debates in the UK House of Commons (2010–2019). The training set was augmented with 25% synthetic paraphrases and trained using the BIO tagging scheme.
Cross-validated performance on seqeval (95% confidence intervals based on the estimated standard error across folds in brackets):
| Seqeval-Metric | Score |
|---|---|
| F1 | 0.82 [0.82, 0.83] |
| Precision | 0.80 [0.79, 0.81] |
| Recall | 0.84 [0.83, 0.85] |
Stance Classification — maxwlnd/socialgroup_stance_classification_nli
A DeBERTa-v3-base NLI model fine-tuned for social group stance classification, built on top of MoritzLaurer/deberta-v3-base-zeroshot-v2.0. The zero-shot classifier got further fine-tuned based on the social group mentions manually detected in 5,000 sentences drawn from parliamentary debates in the UK House of Commons (2010–2019). The negative class was oversampled by adding synthetic paraphrases for half of all negative social group appeals.
For each detected group mention, three hypotheses are formulated: positive, negative, and neutral. The model chooses the class with the largest entailment probability as the predicted stance.
Cross-validated performance (95% confidence intervals based on the estimated standard error across folds in brackets):
| Metric | Negative | Neutral | Positive | Macro-Avg. |
|---|---|---|---|---|
| F1 | 0.76 [0.72, 0.80] | 0.80 [0.78, 0.81] | 0.89 [0.89, 0.89] | 0.81 [0.80, 0.83] |
| Precision | 0.85 [0.77, 0.94] | 0.81 [0.79, 0.84] | 0.87 [0.86, 0.88] | 0.85 [0.82, 0.87] |
| Recall | 0.70 [0.62, 0.77] | 0.78 [0.76, 0.80] | 0.91 [0.89, 0.92] | 0.79 [0.77, 0.82] |
Mention Embedding — maxwlnd/cl_mention_embedding
A BERT-base model with a linear projection head (dimensionality 128) fine-tuned via contrastive learning to produce embeddings that maximize separability between mentions of different social groups.
Each mention is fed into the model using the following template:
Social group of {mention} is: [MASK].
The model extracts the hidden state at the [MASK] position as the mention representation, passes it through the projection layer and L2-normalizes the embedding to make the distance computation independent of the vectors' magnitude.
The model was trained on the social group dictionary provided by Will Horne, Alona O. Dolinsky, Lena Maria Huber using the triplet loss. Each anchor is a term from a category, paired with a randomly sampled positive from the same category and a hard negative mined from a different category.
License
This project is licensed under the MIT License. See the LICENSE file for details.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file group_appeal_detector-0.2.0.tar.gz.
File metadata
- Download URL: group_appeal_detector-0.2.0.tar.gz
- Upload date:
- Size: 26.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4fce2afcd98541812e774211ee5ba5931acb3723e97004780aa0436a7e4853fc
|
|
| MD5 |
a9d14df05d67a560ab29868d5f9e6923
|
|
| BLAKE2b-256 |
197fc070af1fa5272ffd0fe7936a171e50bdba8244feb6c0e1eef9a73f6fbe1e
|
File details
Details for the file group_appeal_detector-0.2.0-py3-none-any.whl.
File metadata
- Download URL: group_appeal_detector-0.2.0-py3-none-any.whl
- Upload date:
- Size: 20.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
266fe26f28eea6cdbcaeca0590392e8efe0a95a56074cca65740de0ea91c4ec0
|
|
| MD5 |
f73b50af2518da0cd620a4913c8d0f29
|
|
| BLAKE2b-256 |
c894530160592d9a58794f90f76afb2ca1531969dd33c0c6aed038a2206f3b49
|







