Groups list items using a compare function

Project description
grplist
Group list or dict items using an arbitrary comparison function. Items that satisfy the predicate are placed in the same group, with transitivity applied automatically — if A matches B and B matches C, all three end up together even if A and C would not match directly.
import grplist as gl
groups = gl.groupList([1, 3, 6, 10, 12, 14, 21, 35], lambda a, b: abs(a-b) <= 3, vals=True)
# => [[1, 3, 6], [10, 12, 14], [21], [35]]
Table of contents
Install
pip install grplist
Quick start
import grplist as gl
# Group numbers that are within 3 of each other
gl.groupList([1, 3, 6, 10, 12, 14, 21, 35], lambda a, b: abs(a-b) <= 3, vals=True)
# => [[1, 3, 6], [10, 12, 14], [21], [35]]
# Return indices instead of values (vals=False is the default)
gl.groupList([1, 3, 6, 10, 12, 14, 21, 35], lambda a, b: abs(a-b) <= 3)
# => [[0, 1, 2], [3, 4, 5], [6], [7]]
# Group a dict — returns groups of keys by default
d = {'a': 1, 'b': 3, 'c': 10, 'd': 12}
gl.groupDict(d, lambda a, b: abs(a-b) <= 3)
# => [['a', 'b'], ['c', 'd']]
API reference
All functions share the same signature pattern:
groupList(arr, fnc, vals=False) -> list[list]
groupList2(arr, fnc, vals=False) -> list[list]
groupList3(arr, fnc, vals=False) -> list[list]
groupList4(arr, fnc, vals=False) -> list[list]
groupDict(obj, fnc, vals=False) -> list[list]
groupDict2(obj, fnc, vals=False) -> list[list]
groupDict3(obj, fnc, vals=False) -> list[list]
groupDict4(obj, fnc, vals=False) -> list[list]
Parameters
| Parameter | Type | Description |
|---|---|---|
arr / obj |
list / dict |
The collection to group |
fnc |
callable(a, b) -> bool |
Returns True if two items belong in the same group |
vals |
bool |
True → return item values; False (default) → return indices (list) or keys (dict) |
Return value
A list of groups. Each group is a list of either values (when vals=True) or
indices/keys (when vals=False).
Choosing between the variants
All variants produce equivalent results for symmetric, transitive predicates. The differences are performance characteristics:
| Variant | Predicate calls | Merge cost | When to use |
|---|---|---|---|
groupList |
All n·(n−1)/2 pairs | O(n) per merge | Baseline; simplest code |
groupList2 |
~5–30% of pairs (chain-walk) | O(chain length) per merge | Good general choice |
groupList3 |
All pairs (lazy find) | O(α(n)) — Union-Find | Very large n where merge cost dominates |
groupList4 |
~5–30% of pairs (same as groupList2) | O(1) — tail pointer | Best general-purpose default |
groupList4 is the recommended default. It combines groupList2's chain-walk
comparison (far fewer predicate calls than a full scan) with an O(1) merge step
using a tail pointer per group — eliminating the only remaining inefficiency in
groupList2. It is never slower than groupList2 and marginally faster whenever
groups are merged.
groupDict, groupDict2, groupDict3, and groupDict4 are thin wrappers that
extract a dict's values, delegate to the corresponding groupList variant, then
remap indices back to keys.
Examples
Numeric proximity
import grplist as gl
# Items within 3 of each other (values)
gl.groupList([1, 3, 6, 10, 12, 14, 21, 35], lambda a, b: abs(a-b) <= 3, vals=True)
# => [[1, 3, 6], [10, 12, 14], [21], [35]]
# Note: 7 bridges what would otherwise be two separate groups
gl.groupList([1, 3, 6, 10, 12, 14, 21, 35, 7, 23], lambda a, b: abs(a-b) <= 3, vals=True)
# => [[1, 3, 6, 10, 12, 14, 7], [21, 23], [35]]
Grouping by shared characters
import grplist as gl
def shares_a_letter(a, b):
return any(c in b for c in a)
words = ['on', 'tw', 'th', 'fo', 'fi', 'si', 'te', 'zk']
gl.groupList4(words, shares_a_letter, vals=True)
# => [['on', 'fo', 'fi', 'si'], ['tw', 'te', 'th'], ['zk']]
Grouping dict items by value
import grplist as gl
scores = {'alice': 91, 'bob': 88, 'carol': 74, 'dave': 76, 'eve': 95}
# Group people whose scores are within 5 points of each other
gl.groupDict(scores, lambda a, b: abs(a-b) <= 5)
# => [['alice', 'bob', 'eve'], ['carol', 'dave']]
# Return the score values instead of names
gl.groupDict(scores, lambda a, b: abs(a-b) <= 5, vals=True)
# => [[91, 88, 95], [74, 76]]
Grouping objects with a custom predicate — overlapping time ranges
import grplist as gl
tracks = [
{'start': 2, 'end': 10},
{'start': 8, 'end': 17},
{'start': 4, 'end': 7},
{'start': 20, 'end': 25},
{'start': 22, 'end': 28},
{'start': 30, 'end': 45},
]
def overlaps(a, b):
return a['start'] <= b['end'] and a['end'] >= b['start']
groups = gl.groupList4(tracks, overlaps, vals=True)
# Group 1: tracks 0, 1, 2 (2-10, 8-17, 4-7 all overlap)
# Group 2: tracks 3, 4 (20-25, 22-28 overlap)
# Group 3: track 5 (30-45, no overlap with others)
How it works
The underlying problem: connected components
grplist solves the connected components problem from graph theory. Given
your list of items, think of each item as a node in an undirected graph. Your
comparison function fnc(a, b) defines the edges: an edge is drawn between
two nodes whenever fnc returns True. The groups returned by grplist are
the connected components of that graph — the clusters of nodes that are
reachable from each other through any chain of edges.
This naturally handles transitivity. If item A connects to item B, and item B
connects to item C, then A, B, and C all end up in the same group — even if
fnc(A, C) would return False.
A classic illustration: grouping integers where any two values within 3 of each other are connected.
Items: 1 — 3 — 6 10 — 12 — 14 21 35
\ /
(gap > 3)
Components: [1, 3, 6] [10, 12, 14] [21] [35]
If we add 7 to the list, it sits within 3 of both 6 and 10, acting as a
bridge that merges the first two components:
Items: 1 — 3 — 6 — 7 — 10 — 12 — 14 21 — 23 35
Components: [1, 3, 6, 7, 10, 12, 14] [21, 23] [35]
groupList — group-ID scan
groupList performs a complete O(n²) pairwise scan. Each item is assigned a
group ID, and when two items with different IDs are found to match, their groups
are merged by renumbering all affected entries. Conceptually similar to
Union-Find but
without path compression.
groupList2 — chain-walk comparison
groupList2 maintains a linked list per group and processes items one at a
time. Each new item is compared only against existing group members (not all
pairs), and is inserted adjacent to its match. This reduces predicate calls to
~5–30% of the full n² scan on typical inputs. The merge step walks the chain
to find its tail, which is O(chain length).
groupList3 — Union-Find merge
groupList3 uses a full O(n²) comparison scan (like groupList) but replaces
the O(n) merge step with Union-Find path compression and union-by-rank,
making each merge O(α(n)) — effectively constant. find() is called lazily,
only on True predicate results. Useful when n is very large and the merge cost
dominates.
groupList4 — chain-walk + tail-pointer merge (recommended)
groupList4 combines the two independent optimisations: groupList2's
chain-walk comparison (same predicate call count and insertion order) with a
t[] tail-pointer array that makes the merge step O(1) instead of O(chain
length). It is strictly better than or equal to groupList2 on every input.
Performance guide
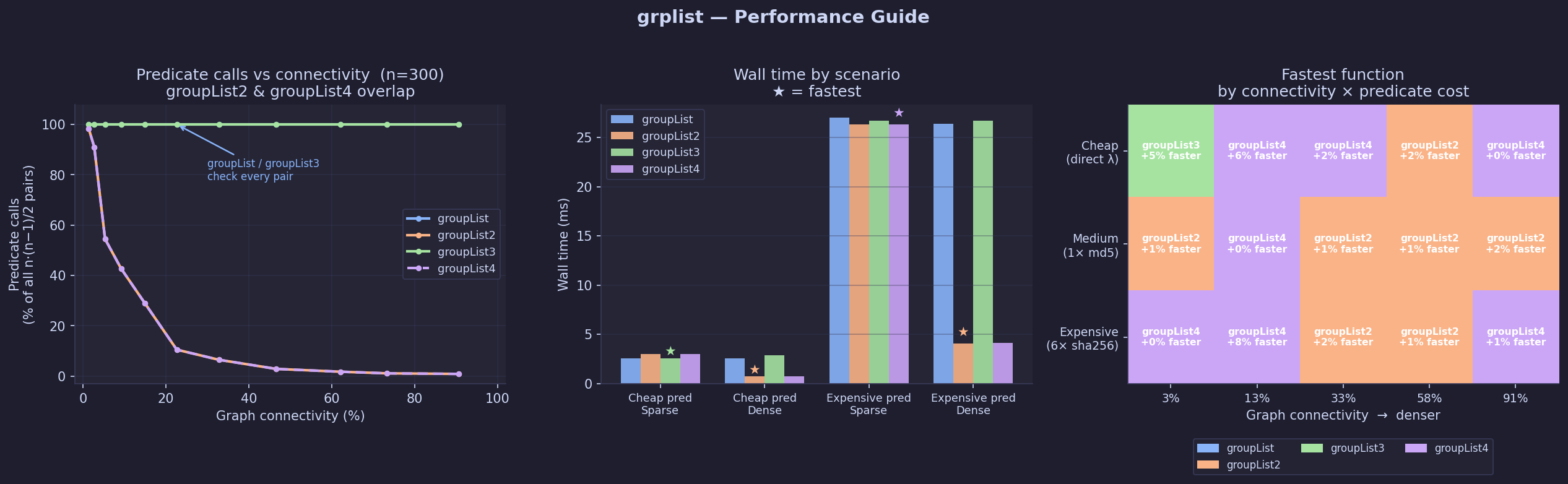
The three panels above show:
-
Predicate call counts —
groupListandgroupList3check every pair (flat lines at 100%).groupList2andgroupList4overlap — both use the same chain-walk comparison and make identical predicate calls, dropping to ~5–30% of all pairs as connectivity grows. -
Wall time by scenario — the star marks the fastest function.
groupList4(lavender) wins in most conditions, matchinggroupList2's call count while eliminating the chain-end walk during merges. On very sparse inputs with a cheap predicate,groupListedges ahead due to its simpler inner loop. -
Winner heatmap — which function is fastest at every combination of graph connectivity and predicate cost.
groupList4(lavender) dominates for medium and dense graphs at all predicate costs.groupList3(green) wins the sparse- cheap corner: when almost no pairs match, its simple
if not fnc: continuehot path has slightly less per-iteration overhead than the other variants.
- cheap corner: when almost no pairs match, its simple
To regenerate the chart after changing the code:
pip install matplotlib numpy
python bench/generate_charts.py
Further reading
- Connected components (graph theory) — Wikipedia
- Disjoint-set data structure (Union-Find) — Wikipedia
- Single-linkage clustering — Wikipedia (the ML framing of the same problem)
Comparison to similar projects
Several other libraries solve the same underlying problem. The right choice depends on your data types, scale, and what else you need to do with the results.
NetworkX — nx.connected_components(G)
NetworkX is the standard Python graph library. To
replicate grplist, you build a Graph object, call your predicate for every
pair of items to add edges, then call nx.connected_components(G). This gives
you full connected-component detection backed by a mature, well-tested library.
The result is a generator of sets of node labels rather than grouped sub-lists,
so a small amount of post-processing is needed to get the same output shape.
NetworkX carries substantial dependencies (NumPy, and optionally SciPy) and is
heavyweight for this single task, but it pays off when you need additional graph
analysis — shortest paths, centrality, community detection, etc.
Best for: Projects already using NetworkX, or any case where connected components is one step in a broader graph analysis pipeline.
SciPy — scipy.sparse.csgraph.connected_components
SciPy's graph module
provides a fast, C-backed connected-components implementation that operates on
a sparse adjacency matrix. For large numerical datasets it significantly
outperforms grplist, but you must first express your predicate as a numeric
matrix, which requires your items to be representable as indices. Non-numeric
or heterogeneous objects need a manual encoding step. The result is a NumPy
label array rather than grouped sub-lists.
Best for: Large numerical datasets (thousands of items or more) where performance matters and items can be naturally represented as a matrix.
scikit-learn — AgglomerativeClustering(linkage='single')
scikit-learn's single-linkage clustering is mathematically equivalent to connected components when the distance threshold is set to match your grouping criterion. However, it requires a numeric distance metric (or a precomputed distance matrix) rather than an arbitrary boolean predicate — you cannot pass in a function that operates on strings, dicts, or custom objects without first embedding them in a numeric space. Results come back as a flat integer label array. It also requires specifying the number of clusters or a distance threshold in advance, and pulls in the full scikit-learn dependency.
Best for: Metric-based clustering problems that are already part of a machine learning or data science pipeline using scikit-learn.
disjoint-set — PyPI package disjoint-set
The disjoint-set package is a
clean, lightweight Union-Find / Disjoint Set Union implementation with proper
path compression and union-by-rank. It is algorithmically more efficient than
grplist for large inputs and supports incremental / streaming use (you can
call union at any time). The tradeoff is that it exposes a data structure
rather than a one-call function — you write the iteration loop yourself:
from disjoint_set import DisjointSet
ds = DisjointSet()
for i, a in enumerate(items):
for j, b in enumerate(items):
if i < j and predicate(a, b):
ds.union(a, b)
groups = ds.itersets()
This gives full control, but grplist is more convenient when you just want
to hand over a list and get groups back.
Best for: Performance-critical code, incremental/streaming grouping, or when you want to manage the data structure directly.
Summary table
| grplist | NetworkX | SciPy csgraph | scikit-learn | disjoint-set | |
|---|---|---|---|---|---|
| One-call API (list in, groups out) | Yes | No | No | No | No |
| Accepts arbitrary boolean predicate | Yes | With a loop | With a loop | No | With a loop |
| Works with any Python object | Yes | Yes | No | No | Yes |
| Returns grouped sub-lists directly | Yes | No (sets) | No (label array) | No (label array) | No (itersets) |
| No external dependencies | Yes | No | No | No | Yes |
| Efficient at n > 10,000 | No (O(n²)) | Yes | Yes | Yes | Yes |
| Full graph analysis capabilities | No | Yes | Partial | No | No |
In summary: grplist is the right choice when you want a single function
call, your predicate is arbitrary (non-numeric, custom objects, strings, etc.),
your list has at most a few thousand items, and you do not want to pull in
external dependencies. For larger inputs, or when you are already working
within NetworkX, SciPy, or scikit-learn, those tools will serve you better.
References


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file grplist-0.1.5.tar.gz.
File metadata
- Download URL: grplist-0.1.5.tar.gz
- Upload date:
- Size: 21.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
56d0a8bcce6e45efd7d155c439b62f882e183451ebdffa3c9782bb42d3208dfb
|
|
| MD5 |
303e64c9fe2a063b1fd6fc25a734dedb
|
|
| BLAKE2b-256 |
675a7ad49dd7303a56252e3d270615eb4e471a2bcf9c88daf37e2cd10aff4d45
|
File details
Details for the file grplist-0.1.5-py3-none-any.whl.
File metadata
- Download URL: grplist-0.1.5-py3-none-any.whl
- Upload date:
- Size: 11.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
94794c9e9361db29ffdf7dffd0cc570efd55d47f514d376952a89f64c664b4ec
|
|
| MD5 |
914660c4dce81e9f826759f9d2e5aed6
|
|
| BLAKE2b-256 |
9eac9c3e0c482f9cd75bb97568254300cd0ed679a3a2e1e10cb3538517bb2936
|







