No project description provided

Project description








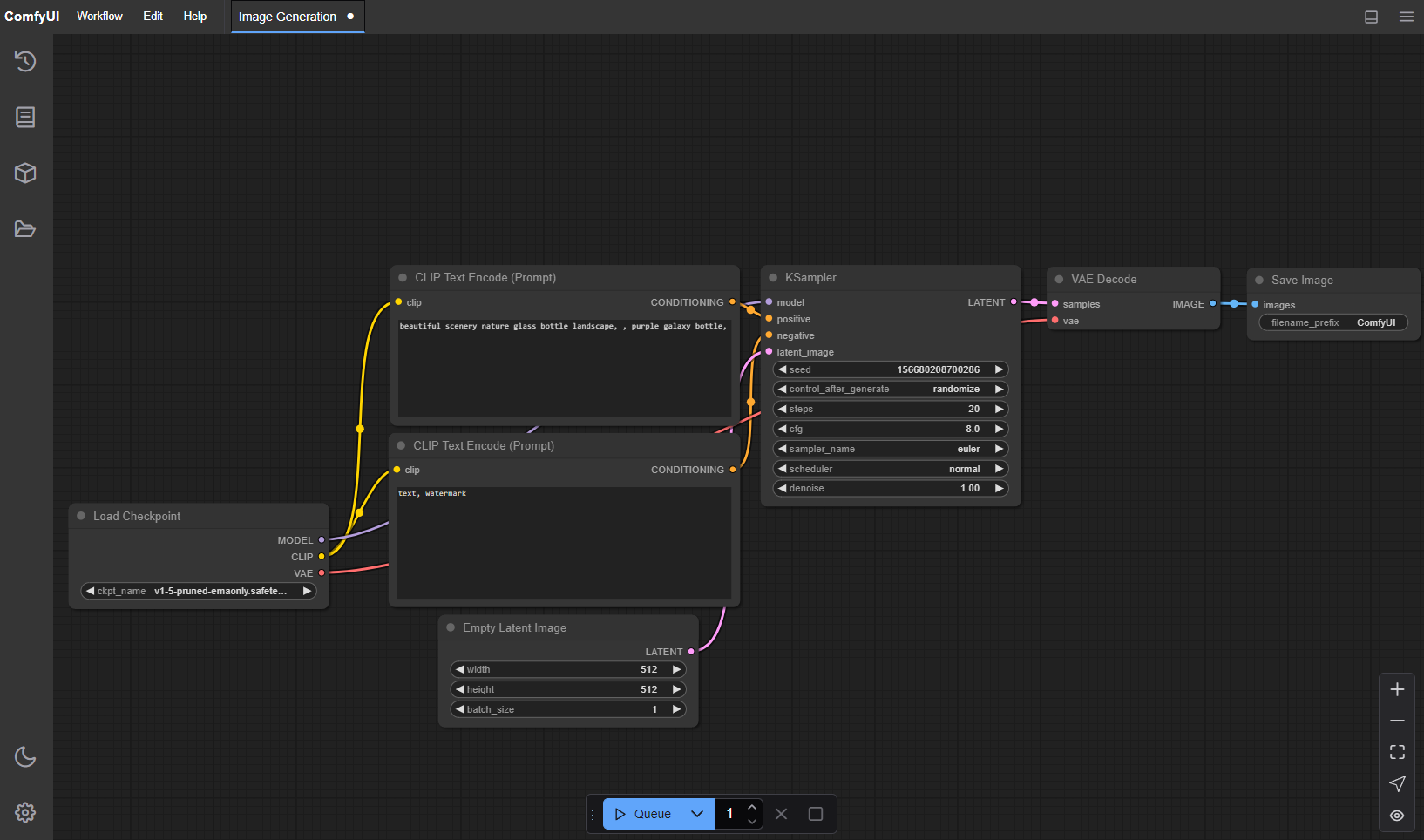
Studio lets you design and execute advanced stable diffusion pipelines using a graph/nodes/flowchart based interface. Available on Windows, Linux, and macOS.
Get Started
Desktop Application
- The easiest way to get started.
- Available on Windows & macOS.
Windows Portable Package
- Get the latest commits and completely portable.
- Available on Windows.
Manual Install
Supports all operating systems and GPU types (NVIDIA, AMD, Intel, Apple Silicon, Ascend).
Examples
See what Studio can do with the example workflows.
Features
- Nodes/graph/flowchart interface to experiment and create complex Stable Diffusion workflows without needing to code anything.
- Image Models
- SD1.x, SD2.x (unCLIP)
- SDXL, SDXL Turbo
- Stable Cascade
- SD3 and SD3.5
- Pixart Alpha and Sigma
- AuraFlow
- HunyuanDiT
- Flux
- Lumina Image 2.0
- HiDream
- Qwen Image
- Hunyuan Image 2.1
- Image Editing Models
- Video Models
- Audio Models
- 3D Models
- Asynchronous Queue system
- Many optimizations: Only re-executes the parts of the workflow that changes between executions.
- Smart memory management: can automatically run large models on GPUs with as low as 1GB vram with smart offloading.
- Works even if you don't have a GPU with:
--cpu(slow) - Can load ckpt and safetensors: All in one checkpoints or standalone diffusion models, VAEs and CLIP models.
- Safe loading of ckpt, pt, pth, etc.. files.
- Embeddings/Textual inversion
- Loras (regular, locon and loha)
- Hypernetworks
- Loading full workflows (with seeds) from generated PNG, WebP and FLAC files.
- Saving/Loading workflows as Json files.
- Nodes interface can be used to create complex workflows like one for Hires fix or much more advanced ones.
- Area Composition
- Inpainting with both regular and inpainting models.
- ControlNet and T2I-Adapter
- Upscale Models (ESRGAN, ESRGAN variants, SwinIR, Swin2SR, etc...)
- GLIGEN
- Model Merging
- LCM models and Loras
- Latent previews with TAESD
- Works fully offline: core will never download anything unless you want to.
- Optional API nodes to use paid models from external providers through the online Studio API.
- Config file to set the search paths for models.
Workflow examples can be found on the Examples page
Release Process
Studio follows a weekly release cycle targeting Monday but this regularly changes because of model releases or large changes to the codebase. There are three interconnected repositories:
-
- Releases a new stable version (e.g., v0.7.0) roughly every week.
- Commits outside of the stable release tags may be very unstable and break many custom nodes.
- Serves as the foundation for the desktop release
-
- Builds a new release using the latest stable core version
-
- Weekly frontend updates are merged into the core repository
- Features are frozen for the upcoming core release
- Development continues for the next release cycle
Shortcuts
| Keybind | Explanation |
|---|---|
Ctrl + Enter |
Queue up current graph for generation |
Ctrl + Shift + Enter |
Queue up current graph as first for generation |
Ctrl + Alt + Enter |
Cancel current generation |
Ctrl + Z/Ctrl + Y |
Undo/Redo |
Ctrl + S |
Save workflow |
Ctrl + O |
Load workflow |
Ctrl + A |
Select all nodes |
Alt + C |
Collapse/uncollapse selected nodes |
Ctrl + M |
Mute/unmute selected nodes |
Ctrl + B |
Bypass selected nodes (acts like the node was removed from the graph and the wires reconnected through) |
Delete/Backspace |
Delete selected nodes |
Ctrl + Backspace |
Delete the current graph |
Space |
Move the canvas around when held and moving the cursor |
Ctrl/Shift + Click |
Add clicked node to selection |
Ctrl + C/Ctrl + V |
Copy and paste selected nodes (without maintaining connections to outputs of unselected nodes) |
Ctrl + C/Ctrl + Shift + V |
Copy and paste selected nodes (maintaining connections from outputs of unselected nodes to inputs of pasted nodes) |
Shift + Drag |
Move multiple selected nodes at the same time |
Ctrl + D |
Load default graph |
Alt + + |
Canvas Zoom in |
Alt + - |
Canvas Zoom out |
Ctrl + Shift + LMB + Vertical drag |
Canvas Zoom in/out |
P |
Pin/Unpin selected nodes |
Ctrl + G |
Group selected nodes |
Q |
Toggle visibility of the queue |
H |
Toggle visibility of history |
R |
Refresh graph |
F |
Show/Hide menu |
. |
Fit view to selection (Whole graph when nothing is selected) |
| Double-Click LMB | Open node quick search palette |
Shift + Drag |
Move multiple wires at once |
Ctrl + Alt + LMB |
Disconnect all wires from clicked slot |
Ctrl can also be replaced with Cmd instead for macOS users
Installing
Windows Portable
There is a portable standalone build for Windows that should work for running on Nvidia GPUs or for running on your CPU only on the releases page.
Direct link to download
Simply download, extract with 7-Zip or with the windows explorer on recent windows versions and run. For smaller models you normally only need to put the checkpoints (the huge ckpt/safetensors files) in: Studio\models\checkpoints but many of the larger models have multiple files. Make sure to follow the instructions to know which subfolder to put them in Studio\models\
If you have trouble extracting it, right click the file -> properties -> unblock
Update your Nvidia drivers if it doesn't start.
Alternative Downloads:
Experimental portable for AMD GPUs
Portable with pytorch cuda 12.8 and python 3.12.
Portable with pytorch cuda 12.6 and python 3.12 (Supports Nvidia 10 series and older GPUs).
How do I share models between another UI and Studio?
See the Config file to set the search paths for models. In the standalone windows build you can find this file in the Studio directory. Rename this file to extra_model_paths.yaml and edit it with your favorite text editor.
studio-cli
You can install and start Studio using studio-cli:
pip install studio-cli
studio install
Manual Install (Windows, Linux)
Python 3.14 works but you may encounter issues with the torch compile node. The free threaded variant is still missing some dependencies.
Python 3.13 is very well supported. If you have trouble with some custom node dependencies on 3.13 you can try 3.12
Instructions:
Git clone this repo.
Put your SD checkpoints (the huge ckpt/safetensors files) in: models/checkpoints
Put your VAE in: models/vae
AMD GPUs (Linux)
AMD users can install rocm and pytorch with pip if you don't have it already installed, this is the command to install the stable version:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm6.4
This is the command to install the nightly with ROCm 7.0 which might have some performance improvements:
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/rocm7.1
AMD GPUs (Experimental: Windows and Linux), RDNA 3, 3.5 and 4 only.
These have less hardware support than the builds above but they work on windows. You also need to install the pytorch version specific to your hardware.
RDNA 3 (RX 7000 series):
pip install --pre torch torchvision torchaudio --index-url https://rocm.nightlies.amd.com/v2/gfx110X-dgpu/
RDNA 3.5 (Strix halo/Ryzen AI Max+ 365):
pip install --pre torch torchvision torchaudio --index-url https://rocm.nightlies.amd.com/v2/gfx1151/
RDNA 4 (RX 9000 series):
pip install --pre torch torchvision torchaudio --index-url https://rocm.nightlies.amd.com/v2/gfx120X-all/
Intel GPUs (Windows and Linux)
Intel Arc GPU users can install native PyTorch with torch.xpu support using pip. More information can be found here
- To install PyTorch xpu, use the following command:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/xpu
This is the command to install the Pytorch xpu nightly which might have some performance improvements:
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/xpu
NVIDIA
Nvidia users should install stable pytorch using this command:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu130
This is the command to install pytorch nightly instead which might have performance improvements.
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu130
Troubleshooting
If you get the "Torch not compiled with CUDA enabled" error, uninstall torch with:
pip uninstall torch
And install it again with the command above.
Dependencies
Install the dependencies by opening your terminal inside the Studio folder and:
pip install -r requirements.txt
After this you should have everything installed and can proceed to running Studio.
Others:
Apple Mac silicon
You can install Studio in Apple Mac silicon (M1 or M2) with any recent macOS version.
- Install pytorch nightly. For instructions, read the Accelerated PyTorch training on Mac Apple Developer guide (make sure to install the latest pytorch nightly).
- Follow the Studio manual installation instructions for Windows and Linux.
- Install the Studio dependencies. If you have another Stable Diffusion UI you might be able to reuse the dependencies.
- Launch Studio by running
python main.py
Note: Remember to add your models, VAE, LoRAs etc. to the corresponding Studio folders, as discussed in Studio manual installation.
Ascend NPUs
For models compatible with Ascend Extension for PyTorch (torch_npu). To get started, ensure your environment meets the prerequisites outlined on the installation page. Here's a step-by-step guide tailored to your platform and installation method:
- Begin by installing the recommended or newer kernel version for Linux as specified in the Installation page of torch-npu, if necessary.
- Proceed with the installation of Ascend Basekit, which includes the driver, firmware, and CANN, following the instructions provided for your specific platform.
- Next, install the necessary packages for torch-npu by adhering to the platform-specific instructions on the Installation page.
- Finally, adhere to the Studio manual installation guide for Linux. Once all components are installed, you can run Studio as described earlier.
Cambricon MLUs
For models compatible with Cambricon Extension for PyTorch (torch_mlu). Here's a step-by-step guide tailored to your platform and installation method:
- Install the Cambricon CNToolkit by adhering to the platform-specific instructions on the Installation
- Next, install the PyTorch(torch_mlu) following the instructions on the Installation
- Launch Studio by running
python main.py
Iluvatar Corex
For models compatible with Iluvatar Extension for PyTorch. Here's a step-by-step guide tailored to your platform and installation method:
- Install the Iluvatar Corex Toolkit by adhering to the platform-specific instructions on the Installation
- Launch Studio by running
python main.py
Running
python main.py
For AMD cards not officially supported by ROCm
Try running it with this command if you have issues:
For 6700, 6600 and maybe other RDNA2 or older: HSA_OVERRIDE_GFX_VERSION=10.3.0 python main.py
For AMD 7600 and maybe other RDNA3 cards: HSA_OVERRIDE_GFX_VERSION=11.0.0 python main.py
AMD ROCm Tips
You can enable experimental memory efficient attention on recent pytorch in Studio on some AMD GPUs using this command, it should already be enabled by default on RDNA3. If this improves speed for you on latest pytorch on your GPU please report it so that I can enable it by default.
TORCH_ROCM_AOTRITON_ENABLE_EXPERIMENTAL=1 python main.py --use-pytorch-cross-attention
You can also try setting this env variable PYTORCH_TUNABLEOP_ENABLED=1 which might speed things up at the cost of a very slow initial run.
Notes
Only parts of the graph that have an output with all the correct inputs will be executed.
Only parts of the graph that change from each execution to the next will be executed, if you submit the same graph twice only the first will be executed. If you change the last part of the graph only the part you changed and the part that depends on it will be executed.
Dragging a generated png on the webpage or loading one will give you the full workflow including seeds that were used to create it.
You can use () to change emphasis of a word or phrase like: (good code:1.2) or (bad code:0.8). The default emphasis for () is 1.1. To use () characters in your actual prompt escape them like \( or \).
You can use {day|night}, for wildcard/dynamic prompts. With this syntax "{wild|card|test}" will be randomly replaced by either "wild", "card" or "test" by the frontend every time you queue the prompt. To use {} characters in your actual prompt escape them like: \{ or \}.
Dynamic prompts also support C-style comments, like // comment or /* comment */.
To use a textual inversion concepts/embeddings in a text prompt put them in the models/embeddings directory and use them in the CLIPTextEncode node like this (you can omit the .pt extension):
embedding:embedding_filename.pt
How to show high-quality previews?
Use --preview-method auto to enable previews.
The default installation includes a fast latent preview method that's low-resolution. To enable higher-quality previews with TAESD, download the taesd_decoder.pth, taesdxl_decoder.pth, taesd3_decoder.pth and taef1_decoder.pth and place them in the models/vae_approx folder. Once they're installed, restart Studio and launch it with --preview-method taesd to enable high-quality previews.
How to use TLS/SSL?
Generate a self-signed certificate (not appropriate for shared/production use) and key by running the command: openssl req -x509 -newkey rsa:4096 -keyout key.pem -out cert.pem -sha256 -days 3650 -nodes -subj "/C=XX/ST=StateName/L=CityName/O=CompanyName/OU=CompanySectionName/CN=CommonNameOrHostname"
Use --tls-keyfile key.pem --tls-certfile cert.pem to enable TLS/SSL, the app will now be accessible with https://... instead of http://....
Note: Windows users can use alexisrolland/docker-openssl or one of the 3rd party binary distributions to run the command example above.
If you use a container, note that the volume mount-vcan be a relative path so... -v ".\:/openssl-certs" ...would create the key & cert files in the current directory of your command prompt or powershell terminal.
Support and dev channel
Discord: Try the #help or #feedback channels.
Matrix space: #studioui_space:matrix.org (it's like discord but open source).
See also: https://studio.hanzo.ai/
Frontend Development
As of August 15, 2024, we have transitioned to a new frontend, which is now hosted in a separate repository: Studio Frontend. This repository now hosts the compiled JS (from TS/Vue) under the web/ directory.
Reporting Issues and Requesting Features
For any bugs, issues, or feature requests related to the frontend, please use the Studio Frontend repository. This will help us manage and address frontend-specific concerns more efficiently.
Using the Latest Frontend
The new frontend is now the default for Studio. However, please note:
- The frontend in the main Studio repository is updated fortnightly.
- Daily releases are available in the separate frontend repository.
To use the most up-to-date frontend version:
-
For the latest daily release, launch Studio with this command line argument:
--front-end-version Studio-Org/Studio_frontend@latest -
For a specific version, replace
latestwith the desired version number:--front-end-version Studio-Org/Studio_frontend@1.2.2
This approach allows you to easily switch between the stable fortnightly release and the cutting-edge daily updates, or even specific versions for testing purposes.
Accessing the Legacy Frontend
If you need to use the legacy frontend for any reason, you can access it using the following command line argument:
--front-end-version Studio-Org/Studio_legacy_frontend@latest
This will use a snapshot of the legacy frontend preserved in the Studio Legacy Frontend repository.
QA
Which GPU should I buy for this?
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file hanzo_studio-0.3.71.tar.gz.
File metadata
- Download URL: hanzo_studio-0.3.71.tar.gz
- Upload date:
- Size: 480.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6bf27c87f6a7edaceefabe552489bc7eb046e7a3cb46952990f757c5b6826b4c
|
|
| MD5 |
4e0a9d5496a1c81339a65c84bc91e021
|
|
| BLAKE2b-256 |
14fbada3fa79ea3199d284dc53ed6272efccd7ae7e4965cefffd5ba0c5ea80f4
|
File details
Details for the file hanzo_studio-0.3.71-py3-none-any.whl.
File metadata
- Download URL: hanzo_studio-0.3.71-py3-none-any.whl
- Upload date:
- Size: 532.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.11.14
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c63f774b5f4aa4ec6e842e2348f919bd306bacb075fce5b0667b203d7d988398
|
|
| MD5 |
6d0173f25db7922c0ddf04554b0ef50f
|
|
| BLAKE2b-256 |
b2cb4ac902a82d5953ae11bf8b53ca4eab6764da6e2771f51aa6ad157ae6aa61
|







