A powerful graph-based RAG framework that enables LLMs to identify and leverage connections within new knowledge for improved retrieval.

Project description
HippoRAG 2: From RAG to Memory





HippoRAG 2 is a powerful memory framework for LLMs that enhances their ability to recognize and utilize connections in new knowledge—mirroring a key function of human long-term memory.
Our experiments show that HippoRAG 2 improves associativity (multi-hop retrieval) and sense-making (the process of integrating large and complex contexts) in even the most advanced RAG systems, without sacrificing their performance on simpler tasks.
Like its predecessor, HippoRAG 2 remains cost and latency efficient in online processes, while using significantly fewer resources for offline indexing compared to other graph-based solutions such as GraphRAG, RAPTOR, and LightRAG.
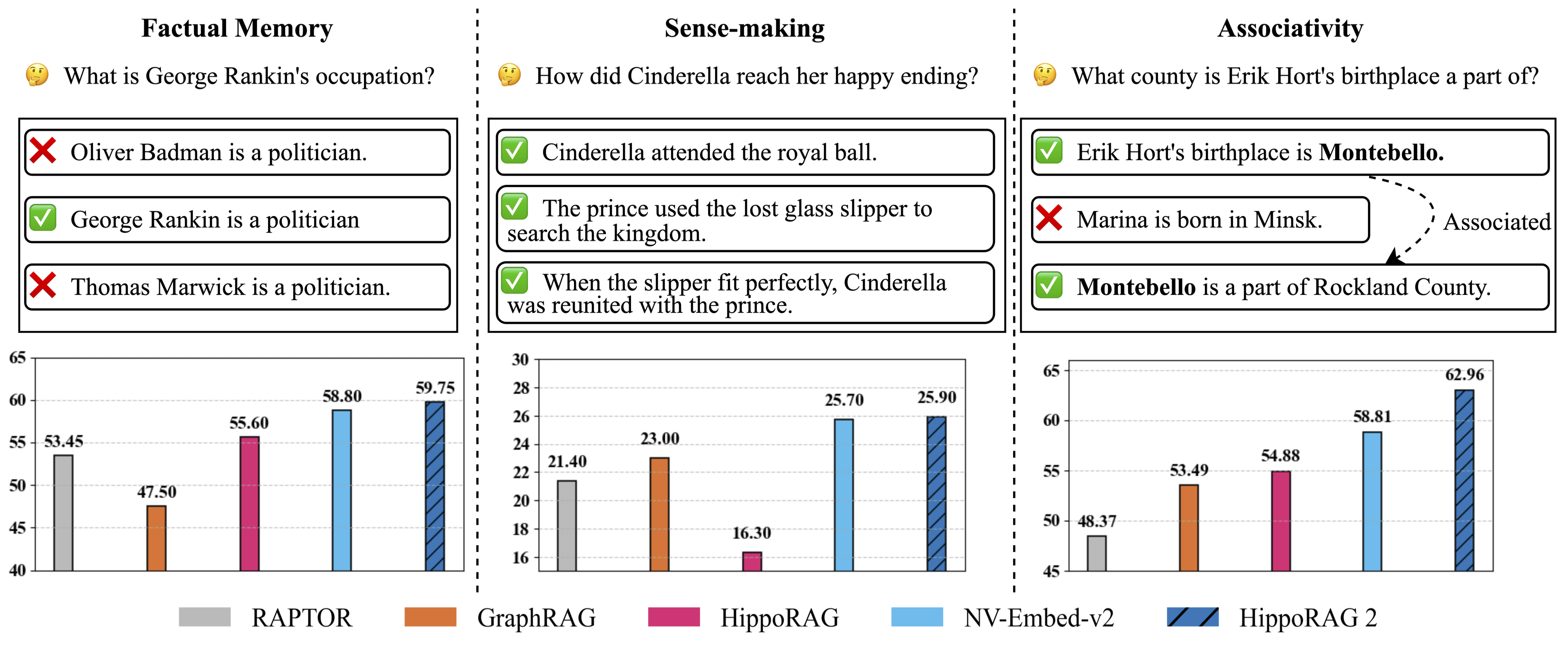
Figure 1: Evaluation of continual learning capabilities across three key dimensions: factual memory (NaturalQuestions, PopQA), sense-making (NarrativeQA), and associativity (MuSiQue, 2Wiki, HotpotQA, and LV-Eval). HippoRAG 2 surpasses other methods across all categories, bringing it one step closer to true long-term memory.
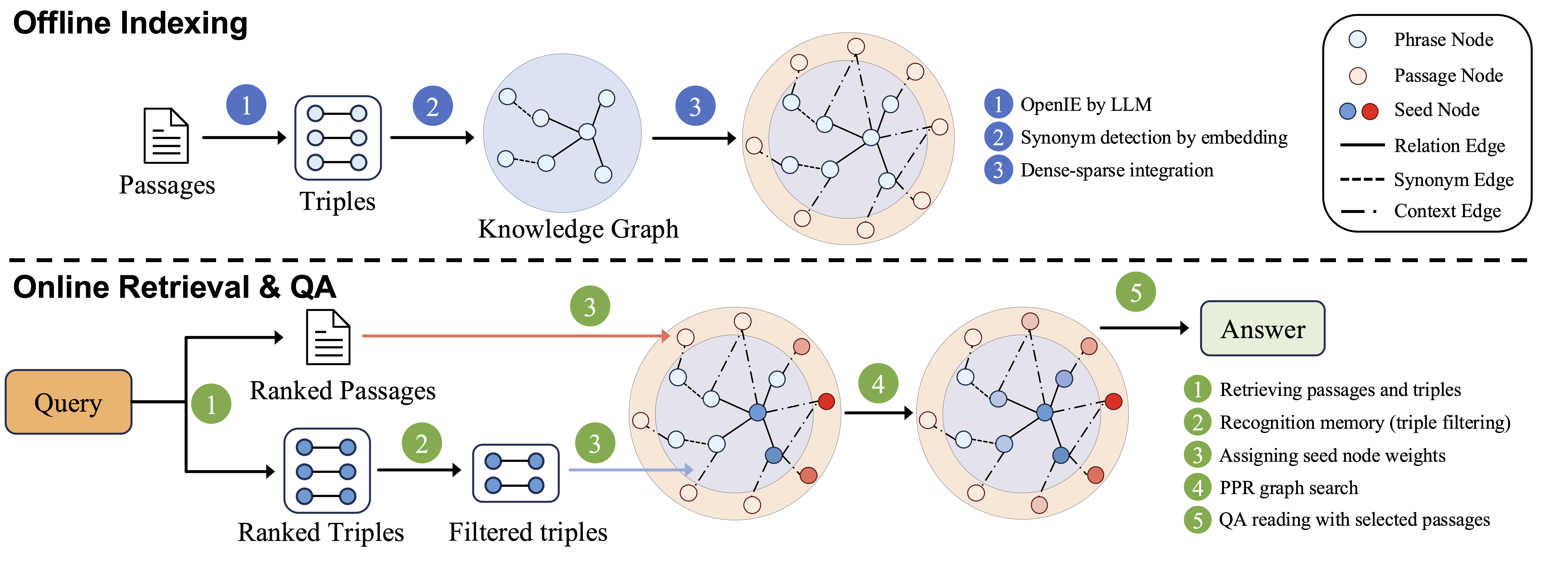
Figure 2: HippoRAG 2 methodology.
Check out our papers to learn more:
- HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models [NeurIPS '24].
- From RAG to Memory: Non-Parametric Continual Learning for Large Language Models [ICML '25].
Installation
conda create -n hipporag python=3.10
conda activate hipporag
pip install hipporag
Initialize the environmental variables and activate the environment:
export CUDA_VISIBLE_DEVICES=0,1,2,3
export HF_HOME=<path to Huggingface home directory>
export OPENAI_API_KEY=<your openai api key> # if you want to use OpenAI model
conda activate hipporag
Quick Start
OpenAI Models
This simple example will illustrate how to use hipporag with any OpenAI model:
from hipporag import HippoRAG
# Prepare datasets and evaluation
docs = [
"Oliver Badman is a politician.",
"George Rankin is a politician.",
"Thomas Marwick is a politician.",
"Cinderella attended the royal ball.",
"The prince used the lost glass slipper to search the kingdom.",
"When the slipper fit perfectly, Cinderella was reunited with the prince.",
"Erik Hort's birthplace is Montebello.",
"Marina is bom in Minsk.",
"Montebello is a part of Rockland County."
]
save_dir = 'outputs'# Define save directory for HippoRAG objects (each LLM/Embedding model combination will create a new subdirectory)
llm_model_name = 'gpt-4o-mini' # Any OpenAI model name
embedding_model_name = 'nvidia/NV-Embed-v2'# Embedding model name (NV-Embed, GritLM or Contriever for now)
#Startup a HippoRAG instance
hipporag = HippoRAG(save_dir=save_dir,
llm_model_name=llm_model_name,
embedding_model_name=embedding_model_name)
#Run indexing
hipporag.index(docs=docs)
#Separate Retrieval & QA
queries = [
"What is George Rankin's occupation?",
"How did Cinderella reach her happy ending?",
"What county is Erik Hort's birthplace a part of?"
]
retrieval_results = hipporag.retrieve(queries=queries, num_to_retrieve=2)
qa_results = hipporag.rag_qa(retrieval_results)
#Combined Retrieval & QA
rag_results = hipporag.rag_qa(queries=queries)
#For Evaluation
answers = [
["Politician"],
["By going to the ball."],
["Rockland County"]
]
gold_docs = [
["George Rankin is a politician."],
["Cinderella attended the royal ball.",
"The prince used the lost glass slipper to search the kingdom.",
"When the slipper fit perfectly, Cinderella was reunited with the prince."],
["Erik Hort's birthplace is Montebello.",
"Montebello is a part of Rockland County."]
]
rag_results = hipporag.rag_qa(queries=queries,
gold_docs=gold_docs,
gold_answers=answers)
Example (OpenAI Compatible Embeddings)
If you want to use LLMs and Embeddings Compatible to OpenAI, please use the following methods.
hipporag = HippoRAG(save_dir=save_dir,
llm_model_name='Your LLM Model name',
llm_base_url='Your LLM Model url',
embedding_model_name='Your Embedding model name',
embedding_base_url='Your Embedding model url')
Local Deployment (vLLM)
This simple example will illustrate how to use hipporag with any vLLM-compatible locally deployed LLM.
- Run a local OpenAI-compatible vLLM server with specified GPUs (make sure you leave enough memory for your embedding model).
export CUDA_VISIBLE_DEVICES=0,1
export VLLM_WORKER_MULTIPROC_METHOD=spawn
export HF_HOME=<path to Huggingface home directory>
conda activate hipporag # vllm should be in this environment
# Tune gpu-memory-utilization or max_model_len to fit your GPU memory, if OOM occurs
vllm serve meta-llama/Llama-3.3-70B-Instruct --tensor-parallel-size 2 --max_model_len 4096 --gpu-memory-utilization 0.95
- Now you can use very similar code to the one above to use
hipporag:
save_dir = 'outputs'# Define save directory for HippoRAG objects (each LLM/Embedding model combination will create a new subdirectory)
llm_model_name = # Any OpenAI model name
embedding_model_name = # Embedding model name (NV-Embed, GritLM or Contriever for now)
llm_base_url= # Base url for your deployed LLM (i.e. http://localhost:8000/v1)
hipporag = HippoRAG(save_dir=save_dir,
llm_model_name=llm_model,
embedding_model_name=embedding_model_name,
llm_base_url=llm_base_url)
# Same Indexing, Retrieval and QA as running OpenAI models above
Testing
When making a contribution to HippoRAG, please run the scripts below to ensure that your changes do not result in unexpected behavior from our core modules.
These scripts test for indexing, graph loading, document deletion and incremental updates to a HippoRAG object.
OpenAI Test
To test HippoRAG with an OpenAI LLM and embedding model, simply run the following. The cost of this test will be negligible.
export OPENAI_API_KEY=<your openai api key>
conda activate hipporag
python tests_openai.py
Local Test
To test locally, you must deploy a vLLM instance. We choose to deploy a smaller 8B model Llama-3.1-8B-Instruct for cheaper testing.
export CUDA_VISIBLE_DEVICES=0
export VLLM_WORKER_MULTIPROC_METHOD=spawn
export HF_HOME=<path to Huggingface home directory>
conda activate hipporag # vllm should be in this environment
# Tune gpu-memory-utilization or max_model_len to fit your GPU memory, if OOM occurs
vllm serve meta-llama/Llama-3.1-8B-Instruct --tensor-parallel-size 2 --max_model_len 4096 --gpu-memory-utilization 0.95 --port 6578
Then, we run the following test script:
CUDA_VISIBLE=1 python tests_local.py
Reproducing our Experiments
To use our code to run experiments we recommend you clone this repository and follow the structure of the main.py script.
Data for Reproducibility
We evaluated several sampled datasets in our paper, some of which are already included in the reproduce/dataset directory of this repo. For the complete set of datasets, please visit
our HuggingFace dataset and place them under reproduce/dataset. We also provide the OpenIE results for both gpt-4o-mini and Llama-3.3-70B-Instruct for our musique sample under outputs/musique.
To test your environment is properly set up, you can use the small dataset reproduce/dataset/sample.json for debugging as shown below.
Running Indexing & QA
Initialize the environmental variables and activate the environment:
export CUDA_VISIBLE_DEVICES=0,1,2,3
export HF_HOME=<path to Huggingface home directory>
export OPENAI_API_KEY=<your openai api key> # if you want to use OpenAI model
conda activate hipporag
Run with OpenAI Model
dataset=sample # or any other dataset under `reproduce/dataset`
# Run OpenAI model
python main.py --dataset $dataset --llm_base_url https://api.openai.com/v1 --llm_name gpt-4o-mini --embedding_name nvidia/NV-Embed-v2
Run with vLLM (Llama)
- As above, run a local OpenAI-compatible vLLM server with specified GPU.
export CUDA_VISIBLE_DEVICES=0,1
export VLLM_WORKER_MULTIPROC_METHOD=spawn
export HF_HOME=<path to Huggingface home directory>
conda activate hipporag # vllm should be in this environment
# Tune gpu-memory-utilization or max_model_len to fit your GPU memory, if OOM occurs
vllm serve meta-llama/Llama-3.3-70B-Instruct --tensor-parallel-size 2 --max_model_len 4096 --gpu-memory-utilization 0.95
- Use another GPUs to run the main program in another terminal.
export CUDA_VISIBLE_DEVICES=2,3 # set another GPUs while vLLM server is running
export HF_HOME=<path to Huggingface home directory>
dataset=sample
python main.py --dataset $dataset --llm_base_url http://localhost:8000/v1 --llm_name meta-llama/Llama-3.3-70B-Instruct --embedding_name nvidia/NV-Embed-v2
Advanced: Run with vLLM offline batch
vLLM offers an offline batch mode for faster inference, which could bring us more than 3x faster indexing compared to vLLM online server.
- Use the following command to run the main program with vLLM offline batch mode.
export CUDA_VISIBLE_DEVICES=0,1,2,3 # use all GPUs for faster offline indexing
export VLLM_WORKER_MULTIPROC_METHOD=spawn
export HF_HOME=<path to Huggingface home directory>
export OPENAI_API_KEY=''
dataset=sample
python main.py --dataset $dataset --llm_name meta-llama/Llama-3.3-70B-Instruct --openie_mode offline --skip_graph
- After the first step, OpenIE result is saved to file. Go back to run vLLM online server and main program as described in the
Run with vLLM (Llama)main section.
Debugging Note
/reproduce/dataset/sample.jsonis a small dataset specifically for debugging.- When debugging vLLM offline mode, set
tensor_parallel_sizeas1inhipporag/llm/vllm_offline.py. - If you want to rerun a particular experiment, remember to clear the saved files, including OpenIE results and knowledge graph, e.g.,
rm reproduce/dataset/openie_results/openie_sample_results_ner_meta-llama_Llama-3.3-70B-Instruct_3.json
rm -rf outputs/sample/sample_meta-llama_Llama-3.3-70B-Instruct_nvidia_NV-Embed-v2
Custom Datasets
To setup your own custom dataset for evaluation, follow the format and naming convention shown in reproduce/dataset/sample_corpus.json (your dataset's name should be followed by _corpus.json). If running an experiment with pre-defined questions, organize your query corpus according to the query file reproduce/dataset/sample.json, be sure to also follow our naming convention.
The corpus and optional query JSON files should have the following format:
Retrieval Corpus JSON
[
{
"title": "FIRST PASSAGE TITLE",
"text": "FIRST PASSAGE TEXT",
"idx": 0
},
{
"title": "SECOND PASSAGE TITLE",
"text": "SECOND PASSAGE TEXT",
"idx": 1
}
]
(Optional) Query JSON
[
{
"id": "sample/question_1.json",
"question": "QUESTION",
"answer": [
"ANSWER"
],
"answerable": true,
"paragraphs": [
{
"title": "{FIRST SUPPORTING PASSAGE TITLE}",
"text": "{FIRST SUPPORTING PASSAGE TEXT}",
"is_supporting": true,
"idx": 0
},
{
"title": "{SECOND SUPPORTING PASSAGE TITLE}",
"text": "{SECOND SUPPORTING PASSAGE TEXT}",
"is_supporting": true,
"idx": 1
}
]
}
]
(Optional) Chunking Corpus
When preparing your data, you may need to chunk each passage, as longer passage may be too complex for the OpenIE process.
Code Structure
📦 .
│-- 📂 src/hipporag
│ ├── 📂 embedding_model # Implementation of all embedding models
│ │ ├── __init__.py # Getter function for get specific embedding model classes
| | ├── base.py # Base embedding model class `BaseEmbeddingModel` to inherit and `EmbeddingConfig`
| | ├── NVEmbedV2.py # Implementation of NV-Embed-v2 model
| | ├── ...
│ ├── 📂 evaluation # Implementation of all evaluation metrics
│ │ ├── __init__.py
| | ├── base.py # Base evaluation metric class `BaseMetric` to inherit
│ │ ├── qa_eval.py # Eval metrics for QA
│ │ ├── retrieval_eval.py # Eval metrics for retrieval
│ ├── 📂 information_extraction # Implementation of all information extraction models
│ │ ├── __init__.py
| | ├── openie_openai_gpt.py # Model for OpenIE with OpenAI GPT
| | ├── openie_vllm_offline.py # Model for OpenIE with LLMs deployed offline with vLLM
│ ├── 📂 llm # Classes for inference with large language models
│ │ ├── __init__.py # Getter function
| | ├── base.py # Config class for LLM inference and base LLM inference class to inherit
| | ├── openai_gpt.py # Class for inference with OpenAI GPT
| | ├── vllm_llama.py # Class for inference using a local vLLM server
| | ├── vllm_offline.py # Class for inference using the vLLM API directly
│ ├── 📂 prompts # Prompt templates and prompt template manager class
| │ ├── 📂 dspy_prompts # Prompts for filtering
| │ │ ├── ...
| │ ├── 📂 templates # All prompt templates for template manager to load
| │ │ ├── README.md # Documentations of usage of prompte template manager and prompt template files
| │ │ ├── __init__.py
| │ │ ├── triple_extraction.py
| │ │ ├── ...
│ │ ├── __init__.py
| | ├── linking.py # Instruction for linking
| | ├── prompt_template_manager.py # Implementation of prompt template manager
│ ├── 📂 utils # All utility functions used across this repo (the file name indicates its relevant usage)
│ │ ├── config_utils.py # We use only one config across all modules and its setup is specified here
| | ├── ...
│ ├── __init__.py
│ ├── HippoRAG.py # Highest level class for initiating retrieval, question answering, and evaluations
│ ├── embedding_store.py # Storage database to load, manage and save embeddings for passages, entities and facts.
│ ├── rerank.py # Reranking and filtering methods
│-- 📂 examples
│ ├── ...
│ ├── ...
│-- 📜 README.md
│-- 📜 requirements.txt # Dependencies list
│-- 📜 .gitignore # Files to exclude from Git
Contact
Questions or issues? File an issue or contact Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Su, The Ohio State University
Citation
If you find this work useful, please consider citing our papers:
HippoRAG 2
@misc{gutiérrez2025ragmemorynonparametriccontinual,
title={From RAG to Memory: Non-Parametric Continual Learning for Large Language Models},
author={Bernal Jiménez Gutiérrez and Yiheng Shu and Weijian Qi and Sizhe Zhou and Yu Su},
year={2025},
eprint={2502.14802},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2502.14802},
}
HippoRAG
@inproceedings{gutiérrez2024hipporag,
title={HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models},
author={Bernal Jiménez Gutiérrez and Yiheng Shu and Yu Gu and Michihiro Yasunaga and Yu Su},
booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems},
year={2024},
url={https://openreview.net/forum?id=hkujvAPVsg}
TODO:
- Add support for more embedding models
- Add support for embedding endpoints
- Add support for vector database integration
Please feel free to open an issue or PR if you have any questions or suggestions.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file hipporag-2.0.0a4.tar.gz.
File metadata
- Download URL: hipporag-2.0.0a4.tar.gz
- Upload date:
- Size: 74.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.11.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e75a42071ba24d27ec983bb5db618f6b7fd5f330cb749ef984242c3c34d076a6
|
|
| MD5 |
d1e706354345f66c4d76b5992bd8737e
|
|
| BLAKE2b-256 |
4515401b8628dd593a9847249ab797c147e811e0fe13d53fd633bc18dec9966e
|
File details
Details for the file hipporag-2.0.0a4-py3-none-any.whl.
File metadata
- Download URL: hipporag-2.0.0a4-py3-none-any.whl
- Upload date:
- Size: 87.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.11.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
eee80804299cd37b485c7d09caa0b03a1e00609aaf884759e4ba3cdbd4a99a7a
|
|
| MD5 |
0e5fad5ee27ac707c52e404d48863aa7
|
|
| BLAKE2b-256 |
b3a0e45bdaf1af3f92bb0d63614109ca8a7764efba258e347063ffb3bce5586f
|







