Package for computing the mean squared error between `y_true` and `y_pred` objects with prior assignment using the Hungarian algorithm.

Project description
Hungarian Loss








When training a model that detects multiple objects in an image, both the ground-truth y_true and predicted y_pred tensors contain sets of bounding boxes — and sets have no natural order. A naive approach that matches boxes by position (first predicted box to first true box, etc.) is unstable: the model receives inconsistent gradient signals depending on the arbitrary order boxes appear in the batch, which can prevent training from converging.
The correct approach is to find, for each sample, the optimal one-to-one assignment between the predicted boxes and the ground-truth boxes — the pairing that minimises total matching cost. This is the classic assignment problem, and the Hungarian algorithm solves it in polynomial time. This project provides a pure TensorFlow implementation of Hungarian-based loss that is fully differentiable and runs on GPU, making it suitable for end-to-end training.
Installing
Install and update using pip:
~$ pip install hungarian-loss
Note, this package does not have extra dependencies except Tensorflow :tada:.
How to use it
Both interfaces expect 3-D tensors of shape (batch_size, num_objects, num_features). For example, (32, 10, 4) represents a batch of 32 images each with up to 10 objects described by 4 bounding-box coordinates.
Simple usage — function interface
Drop hungarian_loss directly into model.compile as you would any built-in Keras loss:
from hungarian_loss import hungarian_loss
model = ...
model.compile(
optimizer='adam',
loss={"bbox": hungarian_loss},
loss_weights={"bbox": 1},
)
Advanced usage — class interface
Use HungarianLoss when your model head outputs more than just bounding-box coordinates — for example, coordinates plus class scores. The slices parameter lets you specify which parts of the feature vector are used for computing the assignment cost and which loss function applies to each part:
import tensorflow as tf
from hungarian_loss import HungarianLoss, compute_euclidean_distance
loss = HungarianLoss(
slices=[4, 10], # 4 bbox coords + 10 class logits
slice_index_to_compute_assignment=0, # use bbox coords for matching
compute_cost_matrix_fn=compute_euclidean_distance,
slice_losses_fn=[
tf.keras.losses.mse, # bbox regression loss
tf.keras.losses.categorical_crossentropy, # class loss
],
slice_weights=[1.0, 2.0], # relative weight of each part
)
model.compile(optimizer='adam', loss=loss)
Where to use it
Let's assume you are working on a deep learning model detecting multiple objects on an image. For simplicity of this example, let's consider, that our model intends to detect just two objects of kittens (see example below).
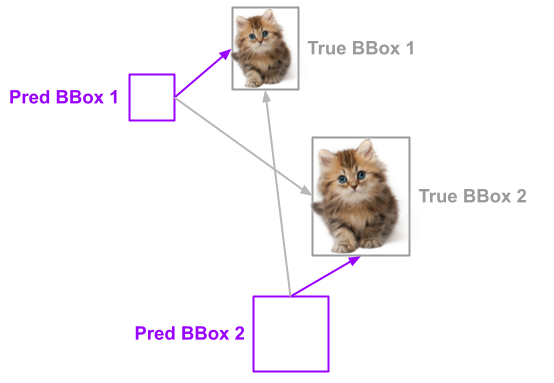
Our model predicts 2 bounding boxes where it "thinks" kittens are located. We need to compute the difference between true and predicted bounding boxes to update model weights via back-propagation. But how to know which predicted boxes belong to which true boxes? Without the optimal assignment algorithm which consistently assigns the predicted boxes to the true boxes, we will not be able to successfully train our model.
The loss function implemented in this project can help you. Intuitively you can see that predicted BBox 1 is close to the true BBox 1 and likewise predicted BBox 2 is close to the true BBox 2. the cost of assigning these pairs would be minimal compared to any other combinations. As you can see, this is a classical assignment problem. You can solve this problem using the Hungarian Algorithm. Its Python implementation can be found here. It is also used by DERT Facebook End-to-End Object Detection with Transformers model. However, if you wish to use pure Tensor-based implementation this library is for you.
How it works
To give you more insights into this implementation we will review a hypothetical example. Let define true-bounding boxes for objects T1 and T2:
| Object | Bounding boxes |
|---|---|
| T1 | 1., 2., 3., 4. |
| T2 | 5., 6., 7., 8. |
Do the same for the predicted boxes P1 and P2:
| Object | Bounding boxes |
|---|---|
| P1 | 1., 1., 1., 1. |
| P2 | 2., 2., 2., 2. |
Let's compute the Euclidean distances between all combinations of True and Predicted bounding boxes:
| P1 | P2 | |
|---|---|---|
| T1 | 3.7416575 | 2.449489 |
| T2 | 11.224972 | 9.273619 |
This algorithm will compute the assignment mask first:
| P1 | P2 | |
|---|---|---|
| T1 | 1 | 0 |
| T2 | 0 | 1 |
And then compute the final error:
loss = (3.7416575 + 9.273619) / 2 = 6.50763825
In contrast, if we would use the different assignment:
loss = (2.449489 + 11.224972) / 2 = 6.8372305
As you can see the error for the optimal assignment is smaller compared to the other solution(s).
When to use it (and when not to)
✅ Optimal matching. The Hungarian algorithm finds the assignment that minimizes total matching cost, giving the model a stable and consistent training signal regardless of the order boxes appear in the batch.
✅ Fully differentiable. Implemented in pure TensorFlow, so gradients flow through the assignment step and the model can be trained end-to-end on GPU without any NumPy or SciPy dependency.
✅ Flexible. The HungarianLoss class supports mixed outputs (e.g. bounding boxes + class scores) with per-slice loss functions and weights, making it easy to adapt to different model heads.
❌ Quadratic cost. The Hungarian algorithm runs in O(n³) time with respect to the number of objects. For a small fixed number of slots (≤ ~20) this is negligible, but for very large prediction sets it can become a training bottleneck.
❌ Fixed set size. Both y_true and y_pred must have the same number of object slots per sample. Models that predict a variable number of objects need to pad to a maximum, which adds implementation overhead.
❌ Harder to debug. The assignment step is opaque — if the loss behaves unexpectedly, inspecting which predicted boxes were matched to which ground-truth boxes requires extra instrumentation.
Contributing
For information on how to set up a development environment and how to make a contribution to Hungarian Loss, see the contributing guidelines.
Links
- PyPI Releases: https://pypi.org/project/hungarian-loss/
- Source Code: https://github.com/mmgalushka/hungarian-loss
- Issue Tracker: https://github.com/mmgalushka/hungarian-loss/issues
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file hungarian_loss-1.0.2.tar.gz.
File metadata
- Download URL: hungarian_loss-1.0.2.tar.gz
- Upload date:
- Size: 305.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.25
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
864f614dd925af2280c65a8ad075687efc1427a9745dda9251be42824fc0ef36
|
|
| MD5 |
da742c8ca072e512004ce265b6ab5912
|
|
| BLAKE2b-256 |
01923b7323ef42f3b0e88266fcaec40368dbd3bdaf7c8b7d7678d0ddd9c1d55a
|
File details
Details for the file hungarian_loss-1.0.2-py3-none-any.whl.
File metadata
- Download URL: hungarian_loss-1.0.2-py3-none-any.whl
- Upload date:
- Size: 13.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.25
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
037500d2ba8b405b761a4b2761ca679515fc2b60acda06c534842a1f358e475f
|
|
| MD5 |
73ab7323dfce157d9101c9202b600239
|
|
| BLAKE2b-256 |
b3127d44e7d6d3aca397bfc4e02fe2e21146bae172e618d838e39a814c66262d
|







