Ichigo Whisper is a compact (22M parameters), open-source speech tokenizer for the whisper-medium model, designed to enhance performance on multilingual with minimal impact on its original English capabilities. Unlike models that output continuous embeddings, Ichigo Whisper compresses speech into discrete tokens, making it more compatible with large language models (LLMs) for immediate speech understanding.

Project description






About
Ichigo-ASR is a compact (22M parameters), open-source speech tokenizer designed to enhance the performance of the Whisper-medium model, particularly for multilingual, while maintaining strong English language capabilities.
Unlike models that output continuous embeddings, Ichigo-ASR compresses speech into discrete tokens. This approach makes it more compatible with large language models (LLMs) for immediate speech understanding and downstream tasks.
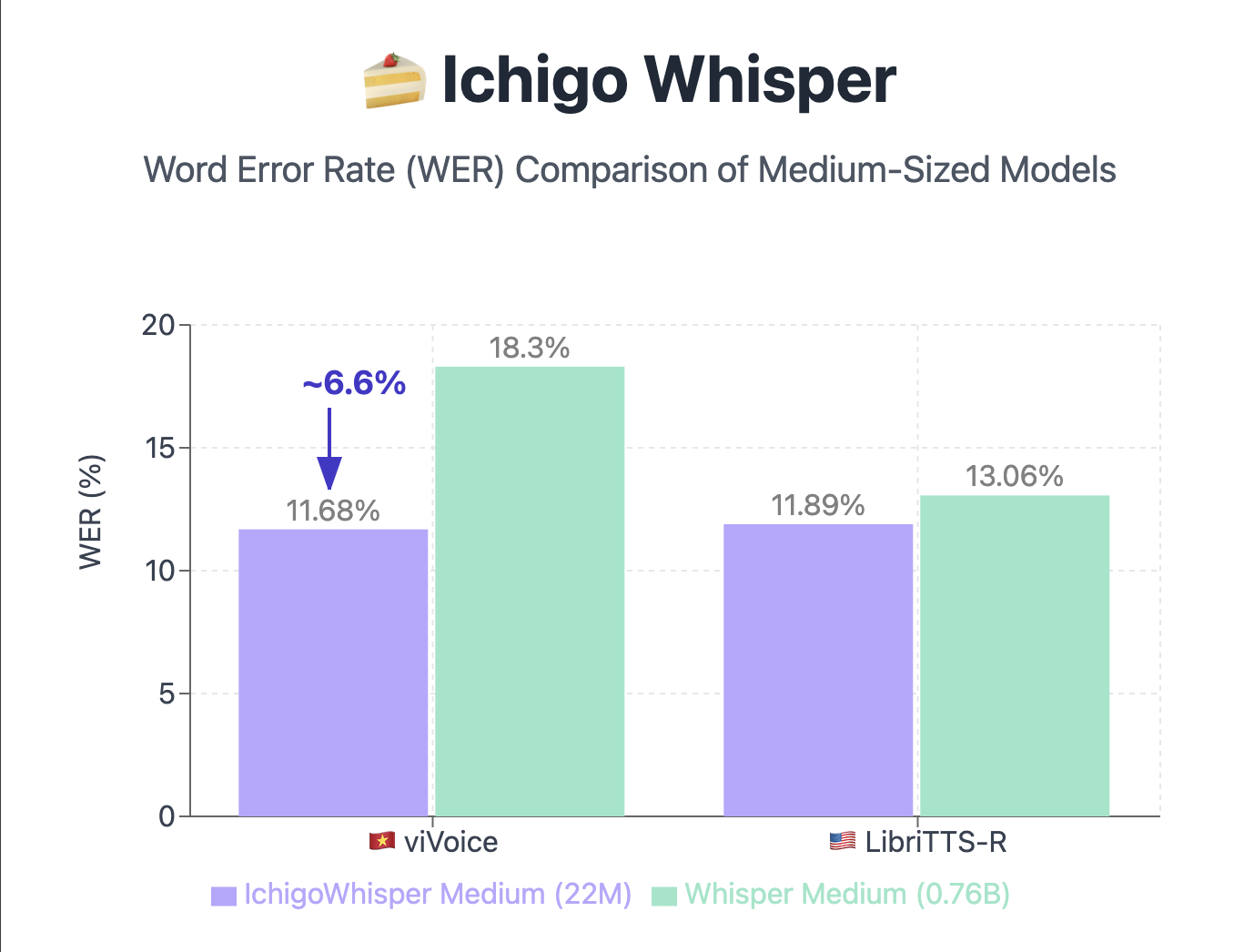
Evaluation of Ichigo Whisper's performance
Key Features
- Only 22M parameters, enabling deployment in resource-constrained environments.
- Specifically trained to improve performance on languages with limited data.
- Outputs discrete tokens, facilitating integration with LLMs.
- Trained on ~400 hours of English and ~1000 hours of Vietnamese data, demonstrating strong performance in both languages.
- Part of a larger family of models for multilingual speech processing.
Model Summary
Architecture
Ichigo-ASR's architecture is inspired by the WhisperVQ model from WhisperSpeech. It is a quantizer built on top of the Whisper-medium model, transforming continuous audio embeddings into discrete codebook entries. This quantization process allows for more efficient integration with LLMs, enabling direct speech understanding without the need for intermediate text representation.
Codebook Initialization
We introduce a method for initializing the codebook weights in the VQ model. Instead of random initialization, we leverage the pre-trained weights from the WhisperVQ 7-language model. We then duplicate these codebooks and introduce small random noise to each copy. After training, we merge the original WhisperVQ 7-language codebooks back into the model.
Codebook initialization of Ichigo Whisper
Codebook Expansion Workflow:
# 1. Initial State
Codebook 512: [512 codes + 1 mask token]
[C1 C2 C3 ... C512 M]
Codebook 2048: [2048 codes + 1 mask token]
[D1 D2 D3 ... D2048 M]
# 2. Remove Mask Token from 512
Codebook 512 (without mask):
[C1 C2 C3 ... C512] # 512 codes
Codebook 2048 (keeps mask):
[D1 D2 D3 ... D2048 M] # 2049 codes
# 3. Create New Empty Codebook
New Size = 512 + 2049 = 2561 codes
[_ _ _ ... _ _ _] # 2561 empty slots
# 4. Merge Process
Step 2: Copy 2048+mask first
[D1 D2 D3 ... D2048 M | _ _ _ ... _ _ _ _ ]
|----2049 codes----| |-----512 slots-----|
Step 2: Copy 512 codes after
[D1 D2 D3 ... D2048 M | C1 C2 C3 ... C512 |]
|----2049 codes----| |-----512 codes-----|
For further details on ablation studies related to codebook initialization, please refer to this GitHub issue.
Two-Phase Training Methodology
We employ a two-phase training strategy to optimize Ichigo-ASR's performance:
- Phase 1: We train the model using a KL divergence loss against the output of the Whisper-medium model. This phase establishes a strong foundation and aligns the quantizer with the original model's representations.
- Phase 2: Recognizing that solely relying on Whisper-medium's output can limit performance, we introduce further training in this phase.
- Data Mixing: We mix Vietnamese and English data in a ratio of approximately 7:3 during training. This helps maintain English capabilities while significantly enhancing Vietnamese performance.
How to Get Started
PyPI
- Install python package
pip install ichigo_asr
- Inference with your audio
import torch, torchaudio
from ichigo_asr.demo.utils import load_model
# Load Ichigo Whisper
ichigo_model = load_model(
ref="homebrewltd/ichigo-whisper:merge-medium-vi-2d-2560c-dim64.pth",
size="merge-medium-vi-2d-2560c-dim64",
)
device = "cuda" if torch.cuda.is_available() else "cpu"
ichigo_model.ensure_whisper(device)
ichigo_model.to(device)
# Inference
wav, sr = torchaudio.load("path/to/your/audio")
if sr != 16000:
wav = torchaudio.functional.resample(wav, sr, 16000)
transcribe = ichigo_model.inference(wav.to(device))
print(transcribe[0].text)
Installation from source
-
Create virtual environment
# venv python -m venv ichigo-whisper source ichigo-whisper/bin/activate # conda conda create -n ichigo-whisper python=3.11 conda activate ichigo-whisper
-
Clone the repository and install requirement packages
git clone https://github.com/janhq/WhisperSpeech.git cd WhisperSpeech/ichigo-whisper pip install -r requirements.txt cd src/ichigo-whisper
-
Login Huggingface CLI and WandB (Optional for training)
huggingface-cli login wandb login
Training
Modify config and run scripts
sh scripts/train_multi.sh
Testing
After training, modify inference config and run scripts
sh scripts/test.sh
Inference
python demo/inference.py -i path/to/your/audio.wav
Demo
python demo/app.py
Join Us
🍰 Ichigo Whisper is an open research project. We're looking for collaborators, and will likely move towards crowdsourcing speech datasets in the future.
Acknowledgement
- WhisperSpeech: Text-to-speech model for synthetic audio generation
- Gradio: A user-friendly library for building Ichigo-ASR demo
You can try the demo directly in here.
Citation
@article{IchigoWhisper-2024,
title={Ichigo Whisper},
author={Homebrew Research},
year=2024,
month=December},
url={https://huggingface.co/homebrewltd/Ichigo-whisper-v0.1}
Acknowledgement
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file ichigo_asr-0.1.1.tar.gz.
File metadata
- Download URL: ichigo_asr-0.1.1.tar.gz
- Upload date:
- Size: 5.0 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.0.1 CPython/3.10.16
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c15a538fab23140fa1e6524f8373c7849a2364f8a42ba67c20af7490e9067dc1
|
|
| MD5 |
4e4057f6352e80432716a080357893c4
|
|
| BLAKE2b-256 |
031fb65ee21c265f8844f0b0a0383ba8c6cca79df8579c706dcefa5672282104
|
File details
Details for the file ichigo_asr-0.1.1-py3-none-any.whl.
File metadata
- Download URL: ichigo_asr-0.1.1-py3-none-any.whl
- Upload date:
- Size: 5.0 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.0.1 CPython/3.10.16
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6e4337c0c9a25f5a27d322750703b1b32511aa7fedc1d82b2ab66bd3d22da986
|
|
| MD5 |
14ba9d29b1f72a4229e878c288ef1d17
|
|
| BLAKE2b-256 |
f0ee4707be04a7d324324826562a883d0cd5296a86e26da1cca7e7f153c301b9
|







