Ichigo is an open, ongoing research experiment to extend a text-based LLM to have native listening ability. Think of it as an open data, open weight, on device Siri.

Project description
:strawberry: Ichigo: A simple speech package for developers
About | Installation | Ichigo-ASR | Ichigo-LLM | Ichigo-TTS | Benchmarks

About
Welcome to Ichigo, a streamlined speech package designed to empower developers with cutting-edge speech models and tools, cultivated by the innovative Ichigo team. The rapidly evolving landscape of speech technology demands a solution that simplifies and unifies speech tasks. Ichigo does just that, enabling developers with straightforward access to powerful models through intuitive Python interfaces or a scalable FastAPI service, leaving behind the tedious intricacies of audio processing so you can focus on what truly matters—deploying and improving your systems.
List of Capabilities
This package does 3 things:
- Automatic Speech Recognition: Ichigo-ASR
- Text to Speech: Coming Soon
- Speech Language Model: Ichigo-LLM (experimental)
It contains only inference code, and caters to most local inference use cases around these three tasks.
Installation
To get started, simply install the package.
pip install ichigo
Ichigo-ASR

Ichigo-ASR is a compact (22M parameters), open-source speech tokenizer for the Whisper-medium model, designed to enhance performance on multilingual with minimal impact on its original English capabilities. Unlike models that output continuous embeddings, Ịchigo-ASR compresses speech into discrete tokens, making it more compatible with large language models (LLMs) for immediate speech understanding. This speech tokenizer has been trained on over ~400 hours of English data and ~1000 hours of Vietnamese data.
Batch Processing
The ichigo package can handle batch processing of audio files using a single line of code, with additional parameters for available for more control.
- For single files
# Quick one-liner for transcription
from ichigo.asr import transcribe
results = transcribe("path/to/your/file")
# Expected output: "{filename: transcription}"
A transcription.txt will also stored in the same folder as "path/to/your/file"
- For multiple files (folder)
# Quick one-liner for transcription
from ichigo.asr import transcribe
results = transcribe("path/to/your/folder")
# Expected output: "{filename1: transcription1, filename2: transcription2, ... filenameN: transcriptionN,}"
A subfolder will be created in path/to/your/folder and transcriptions will be stored as filenameN.txt in the subfolder.
API
For integration with frontend, a python fastAPI is also available. This api also does batch processing. Streaming is currently not supported.
- Start the server
# Uvicorn
cd api && uvicorn asr:app --host 0.0.0.0 --port 8000
# or Docker
docker compose up -d
- curl
# S2T
curl "http://localhost:8000/v1/audio/transcriptions" \
-H "accept: application/json" \
-H "Content-Type: multipart/form-data" \
-F "file=@sample.wav" -F "model=ichigo"
# S2R
curl "http://localhost:8000/s2r" \
-H "accept: application/json" \
-H "Content-Type: multipart/form-data" \
-F "file=@sample.wav"
# R2T
curl "http://localhost:8000/r2t" -X POST \
-H "accept: application/json" \
-H "Content-Type: application/json" \
--data '{"tokens":"<|sound_start|><|sound_1012|><|sound_1508|><|sound_1508|><|sound_0636|><|sound_1090|><|sound_0567|><|sound_0901|><|sound_0901|><|sound_1192|><|sound_1820|><|sound_0547|><|sound_1999|><|sound_0157|><|sound_0157|><|sound_1454|><|sound_1223|><|sound_1223|><|sound_1223|><|sound_1223|><|sound_1808|><|sound_1808|><|sound_1573|><|sound_0065|><|sound_1508|><|sound_1508|><|sound_1268|><|sound_0568|><|sound_1745|><|sound_1508|><|sound_0084|><|sound_1768|><|sound_0192|><|sound_1048|><|sound_0826|><|sound_0192|><|sound_0517|><|sound_0192|><|sound_0826|><|sound_0971|><|sound_1845|><|sound_1694|><|sound_1048|><|sound_0192|><|sound_1048|><|sound_1268|><|sound_end|>"}'
You can also access the API documentation at http://localhost:8000/docs
Ichigo-LLM
:strawberry: Ichigo-LLM is an open, ongoing research experiment to extend a text-based LLM to have native "listening" ability. Think of it as an open data, open weight, on device Siri.
It uses an early fusion technique inspired by Meta's Chameleon paper.
We build train in public:
Ichigo-TTS
Coming Soon
Background
Not your grandfather's speech package
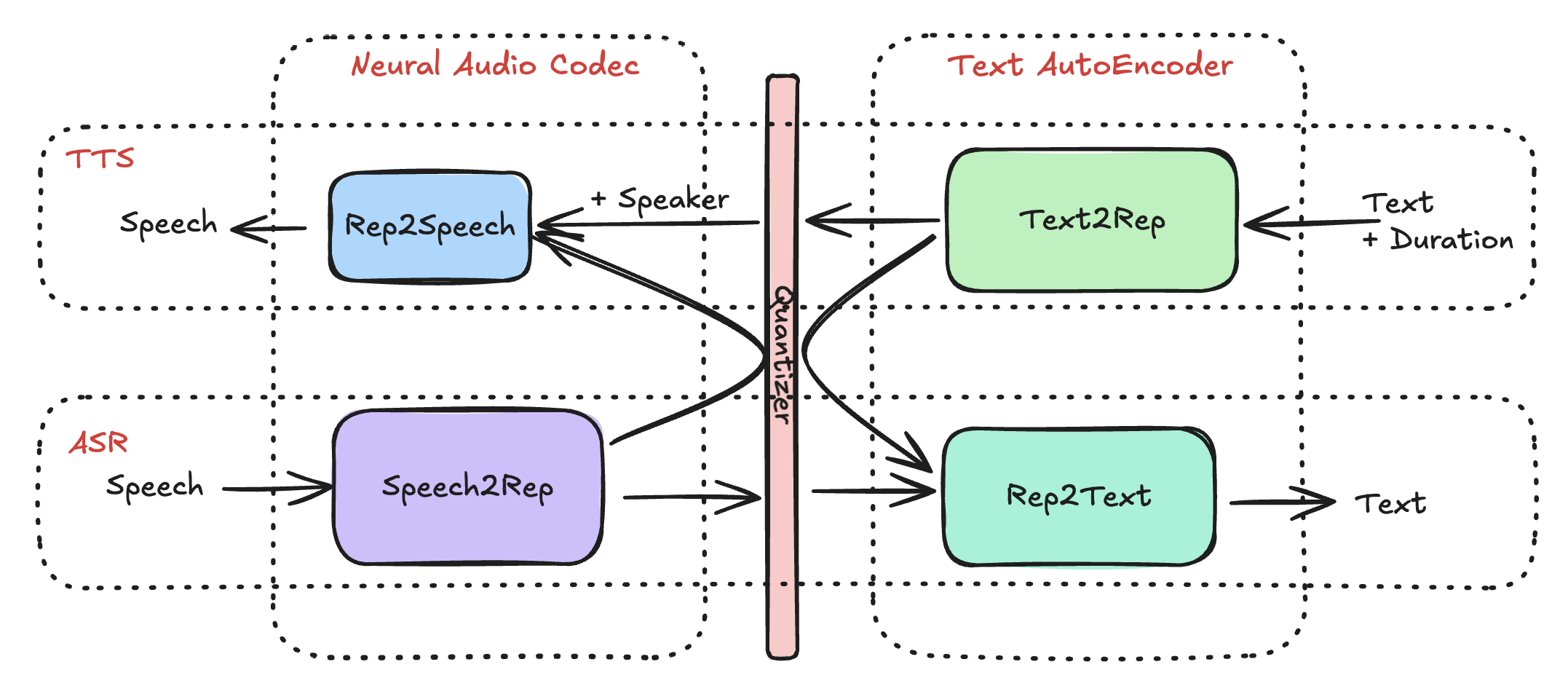
We built this package around what we our vision of the future of speech -- the unification of speech tasks into a single representation framework. Today, many speech models are monolithic models trained end-to-end for a single task. However, subcomponents of these models are in fact reusable for other tasks. This means that ASR fine-tuning can be pre-training for TTS, allowing us to bootstrap better models even with limited training data. We designed this package with the right level of modularity to enable people to train their own models in this manner.
Our package supports underlying abstractions that can support different kinds of models and we welcome researchers to work with us to build these models if you find this way of doing things helpful. You should join our discord community where we can talk about this. A technical report explaining how this framework works and how we think about the future of speech will be uploaded soon.
Everything here is a work in progress, and we welcome all kinds of feedback and collaborations
Benchmarks
| Model | LS Clean (2.6k) | LS Other (2.9k) | Earnings22 (57.3k) | LargeScaleASR (8.09k) | viVoice (10k) |
|---|---|---|---|---|---|
ichigo-asr-2501-en |
4.28 | 9.35 | 35.55 | 16.09 | 11.68 |
whispervq-2405-en |
9.79 | 14.40 | 38.45 | 18.38 | - |
medium.en |
2.88 | 6.04 | 16.64 | 8.21 | 18.30 |
Join Us
:strawberry: Ichigo-LLM and 🍰 Ichigo-ASR is an open research project. We're looking for collaborators, and will likely move towards crowdsourcing speech datasets in the future.
References
@article{dao2024ichigo,
title={Ichigo: Mixed-Modal Early-Fusion Realtime Voice Assistant},
author={Dao, Alan and Vu, Dinh Bach and Ha, Huy Hoang},
journal={arXiv preprint arXiv:2410.15316},
year={2024}
}
@misc{chameleonteam2024chameleonmixedmodalearlyfusionfoundation,
title={Chameleon: Mixed-Modal Early-Fusion Foundation Models},
author={Chameleon Team},
year={2024},
eprint={2405.09818},
archivePrefix={arXiv},
primaryClass={cs.CL},
journal={arXiv preprint}
}
@misc{WhisperSpeech,
title={WhisperSpeech: An Open Source Text-to-Speech System Built by Inverting Whisper},
author={Collabora and LAION},
year={2024},
url={https://github.com/collabora/WhisperSpeech},
note={GitHub repository}
}
Acknowledgement
- torchtune: The codebase we built upon
- WhisperSpeech: Text-to-speech model for synthetic audio generation
- llama3: the Family of Models that we based on that has the amazing language capabilities
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file ichigo-0.0.14.tar.gz.
File metadata
- Download URL: ichigo-0.0.14.tar.gz
- Upload date:
- Size: 19.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.11.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d8045e5e2db83d1808e6093b053b0a9b95fe0629e17c67ab944d383bfc9ca9d8
|
|
| MD5 |
6dc53c59ced817ce1425db08afe53eea
|
|
| BLAKE2b-256 |
e3c479262af937991e9158ad56b0e4bd0844da4f84fe7942699d300c57630ba9
|
File details
Details for the file ichigo-0.0.14-py3-none-any.whl.
File metadata
- Download URL: ichigo-0.0.14-py3-none-any.whl
- Upload date:
- Size: 19.8 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.11.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c05b311f66757dc1bf62a6a47efb70aea6a429c00f2601efb65bf9fd09230445
|
|
| MD5 |
83d993a3eaaa3baf8eca22ecbe842b74
|
|
| BLAKE2b-256 |
3b49edf326f03504782bcd98da22c8a19093ad967cc7ae210392e6b1e27c193a
|







