Toolbox for ensemble learning on class-imbalanced dataset.

Project description

IMBENS: Class-Imbalance Benchmark and Solutions
[📕Documentation] [🖼️Gallery] [🛠Installation] [📜Changelog]
⏳Quick Start with our 5-minute Guide & Detailed Examples
| Status |






|
| Releases |



|
| Traffic |





|
| Documentation |




|
| Articles |



|
| Language |


|
IMBENS (imported as imbens) is an extensible Python library for quick implementation, evaluation, and comparison for general class-imbalanced learning solutions.
Currently, IMBENS includes 30+ algorithms for class-imbalanced classification, including under-sampling (selection or generation-based), over-sampling (e.g., SMOTE and its variants), cost-sensitive learning (e.g., AdaCost), and ensemble methods that integrate these techniques (SMOTEBagging, RUSBoost, SelfPacedEnsemble, etc).
IMBENS is built on top of scikit-learn design principles and was initially built based on imbalanced-learn, but has since evolved independently and no longer depends on it. Users can take advantage of various utilities from the sklearn community for data processing/cross-validation/hyper-parameter tuning, etc.
🌈 IMBENS Highlights
- 🧑💻 Ease-of-use: Unified user-friendly scikit-learn-style APIs.
- 📒 Documentation: Detailed documentation and examples.
- 🚀 Efficiency: Optimized efficiency with parallelization using joblib.
- 📊 Benchmarking: Running & comparing multiple models with our visualizer.
- 📺 Monitoring: Powerful, customizable, interactive training logging.
- 🍻 Compatibility: Work seamlessly with scikit-learn and other tools for sklearn community.
- 📈 Functionality: Extended existing binary techniques to multi-class setting.
- 👯 Extensibility: Implement new methods via well-designed inheritance and polymorphism.
✂️ Use IMBENS for class-imbalanced classification with <5 lines of code:
# Train an SPE classifier
from imbens.ensemble import SelfPacedEnsembleClassifier
clf = SelfPacedEnsembleClassifier(random_state=42)
clf.fit(X_train, y_train)
# Predict with an SPE classifier
y_pred = clf.predict(X_test)
🤗 Citing IMBENS Package
We appreciate your citation if you find our work helpful! The BibTeX entry:
@misc{liu2022imbens,
author = {Zhining Liu},
title = {IMBENS: Python Toolbox for Class-Imbalanced Ensemble Learning},
howpublished = {\url{https://github.com/ZhiningLiu1998/imbalanced-ensemble}},
year = {2025},
}
👯♂️ Contribute to IMBENS
Join us and become a contributor! Please refer to the contributing guidelines.
📚 Table of Contents
- Installation
- 5-min Quick Start with IMBENS
- About imbalanced learning
- Acknowledgements
- List of Methods and References
- Related Projects
- Contributors ✨
Installation
It is recommended to use pip for installation.
Please make sure the latest version is installed to avoid potential problems:
$ pip install imbalanced-ensemble # normal install
$ pip install --upgrade imbalanced-ensemble # update if needed
Or you can install imbalanced-ensemble by clone this repository:
$ git clone https://github.com/ZhiningLiu1998/imbalanced-ensemble.git
$ cd imbalanced-ensemble
$ pip install .
imbalanced-ensemble requires following dependencies:
- Python (>=3.6)
- numpy (>=1.16.0)
- pandas (>=1.1.3)
- scipy (>=1.9.1)
- joblib (>=0.11)
- scikit-learn (>=1.2.0)
- matplotlib (>=3.3.2)
- seaborn (>=0.11.0)
- tqdm (>=4.50.2)
- openml (>=0.14.0)
5-min Quick Start with IMBENS
Here, we provide some quick guides to help you get started with IMBENS.
We strongly encourage users to check out the example gallery for more comprehensive usage examples, which demonstrate many advanced features of IMBENS.
A minimal working example
Taking self-paced ensemble [1] as an example, it only requires less than 10 lines of code to deploy it:
>>> from imbens.ensemble import SelfPacedEnsembleClassifier
>>> from sklearn.datasets import make_classification
>>> from sklearn.model_selection import train_test_split
>>>
>>> X, y = make_classification(n_samples=1000, n_classes=3,
... n_informative=4, weights=[0.2, 0.3, 0.5],
... random_state=0)
>>> X_train, X_test, y_train, y_test = train_test_split(
... X, y, test_size=0.2, random_state=42)
>>> clf = SelfPacedEnsembleClassifier(random_state=0)
>>> clf.fit(X_train, y_train)
SelfPacedEnsembleClassifier(...)
>>> clf.predict(X_test)
array([...])
Visualize ensemble classifiers
The imbens.visualizer sub-module provide an ImbalancedEnsembleVisualizer.
It can be used to visualize the ensemble estimator(s) for further information or comparison.
Please refer to visualizer documentation and examples for more details.
Fit an ImbalancedEnsembleVisualizer
from imbens.ensemble import SelfPacedEnsembleClassifier
from imbens.ensemble import RUSBoostClassifier
from imbens.ensemble import EasyEnsembleClassifier
from sklearn.tree import DecisionTreeClassifier
# Fit ensemble classifiers
init_kwargs = {'estimator': DecisionTreeClassifier()}
ensembles = {
'spe': SelfPacedEnsembleClassifier(**init_kwargs).fit(X_train, y_train),
'rusboost': RUSBoostClassifier(**init_kwargs).fit(X_train, y_train),
'easyens': EasyEnsembleClassifier(**init_kwargs).fit(X_train, y_train),
}
# Fit visualizer
from imbens.visualizer import ImbalancedEnsembleVisualizer
visualizer = ImbalancedEnsembleVisualizer().fit(ensembles=ensembles)
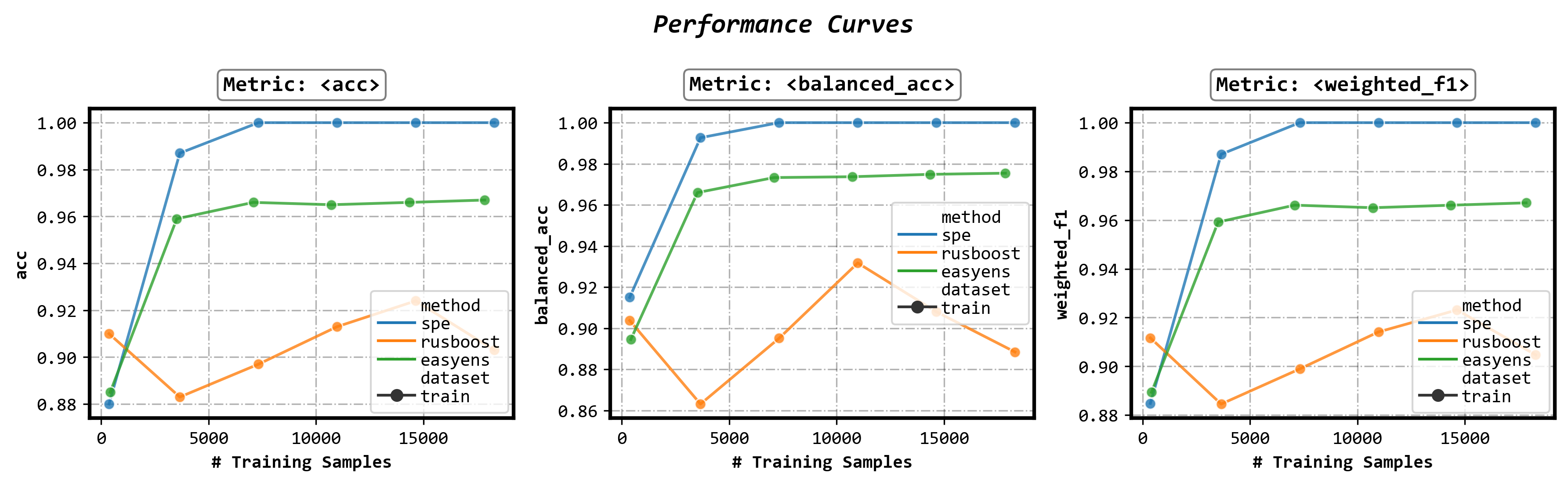
Plot performance curves
fig, axes = visualizer.performance_lineplot()
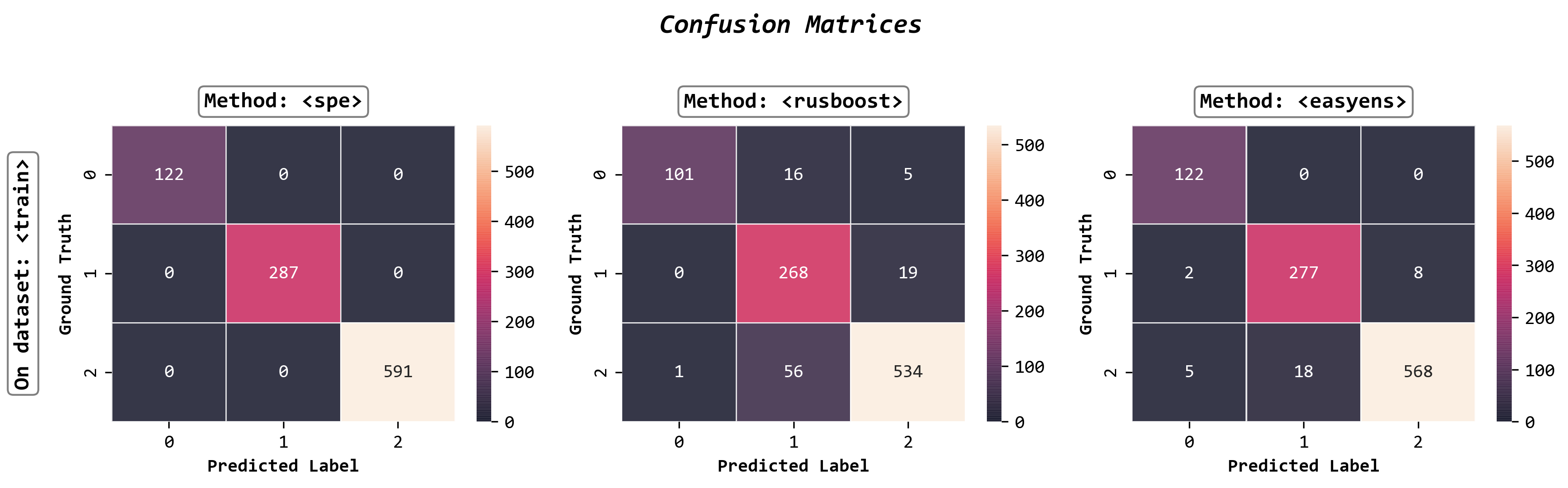
Plot confusion matrices
fig, axes = visualizer.confusion_matrix_heatmap()
Customizing training log
All ensemble classifiers in IMBENS support customizable training logging.
The training log is controlled by 3 parameters eval_datasets, eval_metrics, and training_verbose of the fit() method.
Read more details in the fit documentation.
Enable auto training log
clf.fit(..., train_verbose=True)
┏━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ ┃ ┃ Data: train ┃
┃ #Estimators ┃ Class Distribution ┃ Metric ┃
┃ ┃ ┃ acc balanced_acc weighted_f1 ┃
┣━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┫
┃ 1 ┃ {0: 150, 1: 150, 2: 150} ┃ 0.838 0.877 0.839 ┃
┃ 5 ┃ {0: 150, 1: 150, 2: 150} ┃ 0.924 0.949 0.924 ┃
┃ 10 ┃ {0: 150, 1: 150, 2: 150} ┃ 0.954 0.970 0.954 ┃
┃ 15 ┃ {0: 150, 1: 150, 2: 150} ┃ 0.979 0.986 0.979 ┃
┃ 20 ┃ {0: 150, 1: 150, 2: 150} ┃ 0.990 0.993 0.990 ┃
┃ 25 ┃ {0: 150, 1: 150, 2: 150} ┃ 0.994 0.996 0.994 ┃
┃ 30 ┃ {0: 150, 1: 150, 2: 150} ┃ 0.988 0.992 0.988 ┃
┃ 35 ┃ {0: 150, 1: 150, 2: 150} ┃ 0.999 0.999 0.999 ┃
┃ 40 ┃ {0: 150, 1: 150, 2: 150} ┃ 0.995 0.997 0.995 ┃
┃ 45 ┃ {0: 150, 1: 150, 2: 150} ┃ 0.995 0.997 0.995 ┃
┃ 50 ┃ {0: 150, 1: 150, 2: 150} ┃ 0.993 0.995 0.993 ┃
┣━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┫
┃ final ┃ {0: 150, 1: 150, 2: 150} ┃ 0.993 0.995 0.993 ┃
┗━━━━━━━━━━━━━┻━━━━━━━━━━━━━━━━━━━━━━━━━━┻━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
Customize granularity and content of the training log
clf.fit(...,
train_verbose={
'granularity': 10,
'print_distribution': False,
'print_metrics': True,
})
Click to view example output
┏━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ ┃ Data: train ┃
┃ #Estimators ┃ Metric ┃
┃ ┃ acc balanced_acc weighted_f1 ┃
┣━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┫
┃ 1 ┃ 0.964 0.970 0.964 ┃
┃ 10 ┃ 1.000 1.000 1.000 ┃
┃ 20 ┃ 1.000 1.000 1.000 ┃
┃ 30 ┃ 1.000 1.000 1.000 ┃
┃ 40 ┃ 1.000 1.000 1.000 ┃
┃ 50 ┃ 1.000 1.000 1.000 ┃
┣━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┫
┃ final ┃ 1.000 1.000 1.000 ┃
┗━━━━━━━━━━━━━┻━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
Add evaluation dataset(s)
clf.fit(...,
eval_datasets={
'valid': (X_valid, y_valid)
})
Click to view example output
┏━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ ┃ Data: train ┃ Data: valid ┃
┃ #Estimators ┃ Metric ┃ Metric ┃
┃ ┃ acc balanced_acc weighted_f1 ┃ acc balanced_acc weighted_f1 ┃
┣━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┫
┃ 1 ┃ 0.939 0.961 0.940 ┃ 0.935 0.933 0.936 ┃
┃ 10 ┃ 1.000 1.000 1.000 ┃ 0.971 0.974 0.971 ┃
┃ 20 ┃ 1.000 1.000 1.000 ┃ 0.982 0.981 0.982 ┃
┃ 30 ┃ 1.000 1.000 1.000 ┃ 0.983 0.983 0.983 ┃
┃ 40 ┃ 1.000 1.000 1.000 ┃ 0.983 0.982 0.983 ┃
┃ 50 ┃ 1.000 1.000 1.000 ┃ 0.983 0.982 0.983 ┃
┣━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┫
┃ final ┃ 1.000 1.000 1.000 ┃ 0.983 0.982 0.983 ┃
┗━━━━━━━━━━━━━┻━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┻━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
Customize evaluation metric(s)
from sklearn.metrics import accuracy_score, f1_score
clf.fit(...,
eval_metrics={
'acc': (accuracy_score, {}),
'weighted_f1': (f1_score, {'average':'weighted'}),
})
Click to view example output
┏━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━┓
┃ ┃ Data: train ┃ Data: valid ┃
┃ #Estimators ┃ Metric ┃ Metric ┃
┃ ┃ acc weighted_f1 ┃ acc weighted_f1 ┃
┣━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━━━━━┫
┃ 1 ┃ 0.942 0.961 ┃ 0.919 0.936 ┃
┃ 10 ┃ 1.000 1.000 ┃ 0.976 0.976 ┃
┃ 20 ┃ 1.000 1.000 ┃ 0.977 0.977 ┃
┃ 30 ┃ 1.000 1.000 ┃ 0.981 0.980 ┃
┃ 40 ┃ 1.000 1.000 ┃ 0.980 0.979 ┃
┃ 50 ┃ 1.000 1.000 ┃ 0.981 0.980 ┃
┣━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━━━━━╋━━━━━━━━━━━━━━━━━━━━━━┫
┃ final ┃ 1.000 1.000 ┃ 0.981 0.980 ┃
┗━━━━━━━━━━━━━┻━━━━━━━━━━━━━━━━━━━━━━┻━━━━━━━━━━━━━━━━━━━━━━┛
About imbalanced learning
Class-imbalance (also known as the long-tail problem) is the fact that the classes are not represented equally in a classification problem, which is quite common in practice. For instance, fraud detection, prediction of rare adverse drug reactions and prediction gene families. Failure to account for the class imbalance often causes inaccurate and decreased predictive performance of many classification algorithms. Imbalanced learning aims to tackle the class imbalance problem to learn an unbiased model from imbalanced data.
For more resources on imbalanced learning, please refer to awesome-imbalanced-learning.
Acknowledgements
IMBENS was initially developed on top of the awesome imbalanced-learn, but has undergone heavy developments to implement many important techniques and features. The infrastructure also underwent significant refactoring to support advanced ensemble learning features that are essential to practical usability (fine-grained training control, parallel computing, multi-class support, training logs, visualization, etc).
List of Methods and References
*(Click to jump to the API reference page)
- Under-sampling
- Selection-based
RandomUnderSamplerNearMissMani, I., & Zhang, I. (2003, August). kNN approach to unbalanced data distributions: a case study involving information extraction. In Proceedings of workshop on learning from imbalanced datasets (Vol. 126, No. 1, pp. 1-7). United States: ICML.InstanceHardnessThresholdSmith, M. R., Martinez, T., & Giraud-Carrier, C. (2014). An instance level analysis of data complexity. Machine learning, 95, 225-256.
- Generation-based
ClusterCentroidsLin, W. C., Tsai, C. F., Hu, Y. H., & Jhang, J. S. (2017). Clustering-based undersampling in class-imbalanced data. Information Sciences, 409, 17-26.
- Selection-based
- Cleaning
- Distance-based
TomekLinksTomek, I. (1976). Two modifications of CNN.EditedNearestNeighboursWilson, D. L. (1972). Asymptotic properties of nearest neighbor rules using edited data. IEEE Transactions on Systems, Man, and Cybernetics, (3), 408-421.RepeatedEditedNearestNeighboursTomek, I. (1976). An experiment with the edited nearest-nieghbor ruleAllKNNTomek, I. (1976). An experiment with the edited nearest-nieghbor rule.OneSidedSelectionKubat, M., & Matwin, S. (1997, July). Addressing the curse of imbalanced training sets: one-sided selection. In Icml (Vol. 97, No. 1, p. 179).NeighbourhoodCleaningRuleLaurikkala, J. (2001). Improving identification of difficult small classes by balancing class distribution. In Artificial Intelligence in Medicine: 8th Conference on Artificial Intelligence in Medicine in Europe, AIME 2001 Cascais, Portugal, July 1–4, 2001, Proceedings 8 (pp. 63-66). Springer Berlin Heidelberg.
- Distance-based
- Oversamping
- Generation-based
RandomOverSamplerSMOTEChawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). SMOTE: synthetic minority over-sampling technique. Journal of artificial intelligence research, 16, 321-357.BorderlineSMOTEHan, H., Wang, W. Y., & Mao, B. H. (2005, August). Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning. In International conference on intelligent computing (pp. 878-887). Berlin, Heidelberg: Springer Berlin Heidelberg.SVMSMOTENguyen, H. M., Cooper, E. W., & Kamei, K. (2011). Borderline over-sampling for imbalanced data classification. International Journal of Knowledge Engineering and Soft Data Paradigms, 3(1), 4-21.ADASYNHe, H., Bai, Y., Garcia, E. A., & Li, S. (2008, June). ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In 2008 IEEE international joint conference on neural networks (IEEE world congress on computational intelligence) (pp. 1322-1328). Ieee.
- Generation-based
- Ensemble Modeling
- Under-sampling + Ensemble
SelfPacedEnsembleClassifierLiu, Z., Cao, W., Gao, Z., Bian, J., Chen, H., Chang, Y., & Liu, T. Y. (2020, April). Self-paced ensemble for highly imbalanced massive data classification. In 2020 IEEE 36th international conference on data engineering (ICDE) (pp. 841-852). IEEE.BalanceCascadeClassifierLiu, X. Y., Wu, J., & Zhou, Z. H. (2008). Exploratory undersampling for class-imbalance learning. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 39(2), 539-550.BalancedRandomForestClassifierKhoshgoftaar, T. M., Golawala, M., & Van Hulse, J. (2007, October). An empirical study of learning from imbalanced data using random forest. In 19th IEEE international conference on tools with artificial intelligence (ICTAI 2007) (Vol. 2, pp. 310-317). IEEE.EasyEnsembleClassifierLiu, X. Y., Wu, J., & Zhou, Z. H. (2008). Exploratory undersampling for class-imbalance learning. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 39(2), 539-550.RUSBoostClassifierSeiffert, C., Khoshgoftaar, T. M., Van Hulse, J., & Napolitano, A. (2009). RUSBoost: A hybrid approach to alleviating class imbalance. IEEE transactions on systems, man, and cybernetics-part A: systems and humans, 40(1), 185-197.UnderBaggingClassifierBarandela, R., Valdovinos, R. M., & Sánchez, J. S. (2003). New applications of ensembles of classifiers. Pattern Analysis & Applications, 6, 245-256.
- Over-sampling + Ensemble
OverBoostClassifierChawla, N. V., Lazarevic, A., Hall, L. O., & Bowyer, K. W. (2003, September). SMOTEBoost: Improving prediction of the minority class in boosting. In European conference on principles of data mining and knowledge discovery (pp. 107-119). Berlin, Heidelberg: Springer Berlin Heidelberg.SMOTEBoostClassifierChawla, N. V., Lazarevic, A., Hall, L. O., & Bowyer, K. W. (2003, September). SMOTEBoost: Improving prediction of the minority class in boosting. In European conference on principles of data mining and knowledge discovery (pp. 107-119). Berlin, Heidelberg: Springer Berlin Heidelberg.OverBaggingClassifierWang, S., & Yao, X. (2009, March). Diversity analysis on imbalanced data sets by using ensemble models. In 2009 IEEE symposium on computational intelligence and data mining (pp. 324-331). IEEE.SMOTEBaggingClassifierWang, S., & Yao, X. (2009, March). Diversity analysis on imbalanced data sets by using ensemble models. In 2009 IEEE symposium on computational intelligence and data mining (pp. 324-331). IEEE.
- Under-sampling + Ensemble
- Reweighting-based
- Cost-sensitive Learning
AdaCostClassifierFan, W., Stolfo, S. J., Zhang, J., & Chan, P. K. (1999, June). AdaCost: misclassification cost-sensitive boosting. In Icml (Vol. 99, pp. 97-105).AdaUBoostClassifierKarakoulas, G., & Shawe-Taylor, J. (1998). Optimizing classifers for imbalanced training sets. Advances in neural information processing systems, 11.AsymBoostClassifierViola, P., & Jones, M. (2001). Fast and robust classification using asymmetric adaboost and a detector cascade. Advances in neural information processing systems, 14.
- Cost-sensitive Learning
- Compatible
CompatibleAdaBoostClassifierFreund, Y., & Schapire, R. E. (1997). A decision-theoretic generalization of on-line learning and an application to boosting. Journal of computer and system sciences, 55(1), 119-139.CompatibleBaggingClassifierGuillaume Lemaître, Fernando Nogueira, and Christos K. Aridas. Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning. Journal of Machine Learning Research, 18(17):1–5, 2017.
Related Projects
Check out Zhining's other open-source projects!
 Imbalanced Learning [Awesome] 
|
 Machine Learning [Awesome] 
|
 Self-paced Ensemble [ICDE] 
|
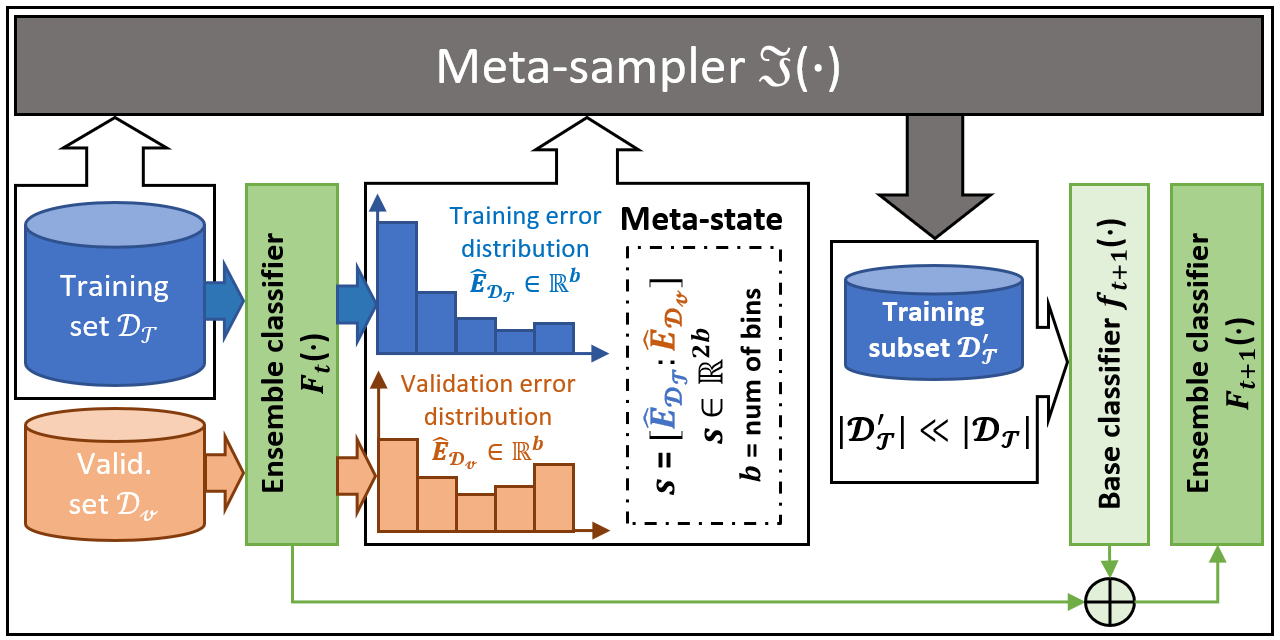 Meta-Sampler [NeurIPS] 
|
Contributors ✨
Thanks goes to these wonderful people (emoji key):
 Zhining Liu 💻 🤔 🚧 🐛 📖 |
 leaphan 🐛 |
 hannanhtang 🐛 |
 H.J.Ren 🐛 |
 Marc Skov Madsen 🐛 |
This project follows the all-contributors specification. Contributions of any kind welcome!
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file imbalanced-ensemble-0.2.3.tar.gz.
File metadata
- Download URL: imbalanced-ensemble-0.2.3.tar.gz
- Upload date:
- Size: 6.4 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.9.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a5b50e97c3f382ad0a836fe9ccd4ca5ece42ceda0dc9c90600dda01e248f7958
|
|
| MD5 |
31983b2cc7f02f29c106055480607422
|
|
| BLAKE2b-256 |
ee3b9586365c67e3e48280ea8362d267cae0b24628f659316ad6a97c5ed07002
|
File details
Details for the file imbalanced_ensemble-0.2.3-py2.py3-none-any.whl.
File metadata
- Download URL: imbalanced_ensemble-0.2.3-py2.py3-none-any.whl
- Upload date:
- Size: 752.0 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.9.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
26dd7ca823ae0facd36e51ef2d64fbd7c8a6550a5b5eef172c0df3f1cdf0ee32
|
|
| MD5 |
a938ef754ca03a0612d1d18fefaffb88
|
|
| BLAKE2b-256 |
4224ce4e797fe74b5f2bb9656c208d39cf1d53254a93a870805595c8f0bc3a6d
|







