Indox Judge

Project description
inDoxJudge







Official Website • Documentation • Discord
NEW: Subscribe to our mailing list for updates and news!
Welcome to IndoxJudge! This repository provides a comprehensive suite of evaluation metrics for assessing the performance and quality of large language models (LLMs). Whether you're a researcher, developer, or enthusiast, this toolkit offers essential tools to measure various aspects of LLMs, including knowledge retention, bias, toxicity, and more.
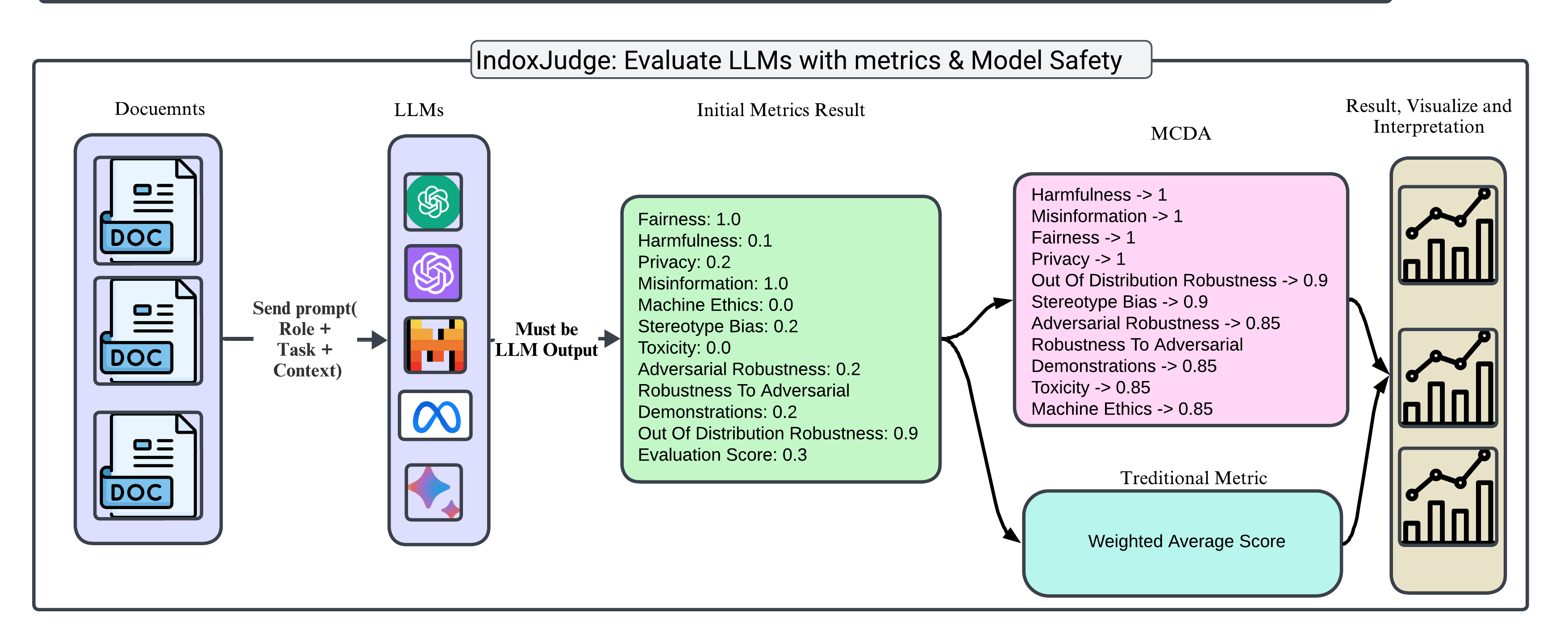
Overview
IndoxJudge is designed to provide a standardized and extensible framework for evaluating LLMs. With a focus on accuracy, fairness, and relevancy, this toolkit supports a wide range of evaluation metrics and is continuously updated to include the latest advancements in the field.
Features
- Comprehensive Metrics: Evaluate LLMs across multiple dimensions, including accuracy, bias, toxicity, and contextual relevancy.
- RAG Evaluation: Includes specialized metrics for evaluating retrieval-augmented generation (RAG) models.
- Safety Evaluation: Assess the safety of model outputs, focusing on toxicity, bias, and ethical considerations.
- Extensible Framework: Easily integrate new metrics or customize existing ones to suit specific needs.
- User-Friendly Interface: Intuitive and easy-to-use interface for seamless evaluation.
- Continuous Updates: Regular updates to incorporate new metrics and improvements.
Supported Models
IndoxJudge currently supports the following LLM models:
- OpenAi
- GoogleAi
- IndoxApi
- HuggingFaceModel
- Mistral
- Pheonix # Coming Soon - You may follow the progress phoenix_cli or phoenix
- Ollama
Metrics
IndoxJudge includes the following metrics, with more being added:
- GEval: General evaluation metric for LLMs.
- KnowledgeRetention: Assesses the ability of LLMs to retain factual information.
- BertScore: Measures the similarity between generated and reference sentences.
- Toxicity: Evaluates the presence of toxic content in model outputs.
- Bias: Analyzes the potential biases in LLM outputs.
- Hallucination: Identifies instances where the model generates false or misleading information.
- Faithfulness: Checks the alignment of generated content with source material.
- ContextualRelevancy: Assesses the relevance of responses in context.
- Rouge: Measures the overlap of n-grams between generated and reference texts.
- BLEU: Evaluates the quality of text generation based on precision.
- AnswerRelevancy: Assesses the relevance of answers to questions.
- METEOR: Evaluates machine translation quality.
- Gruen: Measures the quality of generated text by assessing grammaticality, redundancy, and focus.
- Overallscore: Provides an overall evaluation score for LLMs which is a weighted average of multiple metrics.
- MCDA: Multi-Criteria Decision Analysis for evaluating LLMs.
Installation
To install IndoxJudge, follow these steps:
git clone https://github.com/yourusername/indoxjudge.git
cd indoxjudge
Setting Up the Python Environment
If you are running this project in your local IDE, please create a Python environment to ensure all dependencies are correctly managed. You can follow the steps below to set up a virtual environment named indox_judge:
Windows
- Create the virtual environment:
python -m venv indox_judge
- Activate the virtual environment:
indox_judge\Scripts\activate
macOS/Linux
- Create the virtual environment:
python3 -m venv indox_judge
2. **Activate the virtual environment:**
```bash
source indox_judge/bin/activate
Install Dependencies
Once the virtual environment is activated, install the required dependencies by running:
pip install -r requirements.txt
Usage
To use IndoxJudge, load your API key, select the model, and choose the evaluation metrics. Here's an example demonstrating how to evaluate a model's response for faithfulness:
import os
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
# Import IndoxJudge and supported models
from indoxJudge.piplines import Evaluator
from indoxJudge.models import OpenAi
from indoxJudge.metrics import Faithfulness
# Initialize the model with your API key
model = OpenAi(api_key=OPENAI_API_KEY,model="gpt-4o")
# Define your query and retrieval context
query = "What are the benefits of a Mediterranean diet?"
retrieval_context = [
"The Mediterranean diet emphasizes eating primarily plant-based foods, such as fruits and vegetables, whole grains, legumes, and nuts. It also includes moderate amounts of fish and poultry, and low consumption of red meat. Olive oil is the main source of fat, providing monounsaturated fats which are beneficial for heart health.",
"Research has shown that the Mediterranean diet can reduce the risk of heart disease, stroke, and type 2 diabetes. It is also associated with improved cognitive function and a lower risk of Alzheimer's disease. The diet's high content of fiber, antioxidants, and healthy fats contributes to its numerous health benefits.",
"A Mediterranean diet has been linked to a longer lifespan and a reduced risk of chronic diseases. It promotes healthy aging and weight management due to its emphasis on whole, unprocessed foods and balanced nutrition."
]
# Obtain the model's response
response = "The Mediterranean diet is known for its health benefits, including reducing the risk of heart disease, stroke, and diabetes. It encourages the consumption of fruits, vegetables, whole grains, nuts, and olive oil, while limiting red meat. Additionally, this diet has been associated with better cognitive function and a reduced risk of Alzheimer's disease, promoting longevity and overall well-being."
# Initialize the Faithfulness metric
faithfulness_metrics = Faithfulness(llm_response=response, retrieval_context=retrieval_context)
# Create an evaluator with the selected metrics
evaluator = Evaluator(metrics=[faithfulness_metrics], model=model)
# Evaluate the response
faithfulness_result = evaluator.judge()
# Output the evaluation result
print(faithfulness_result)
Example Output
{
"faithfulness": {
"claims": [
"The Mediterranean diet is known for its health benefits.",
"The Mediterranean diet reduces the risk of heart disease.",
"The Mediterranean diet reduces the risk of stroke.",
"The Mediterranean diet reduces the risk of diabetes.",
"The Mediterranean diet encourages the consumption of fruits.",
"The Mediterranean diet encourages the consumption of vegetables.",
"The Mediterranean diet encourages the consumption of whole grains.",
"The Mediterranean diet encourages the consumption of nuts.",
"The Mediterranean diet encourages the consumption of olive oil.",
"The Mediterranean diet limits red meat consumption.",
"The Mediterranean diet is associated with better cognitive function.",
"The Mediterranean diet is associated with a reduced risk of Alzheimer's disease.",
"The Mediterranean diet promotes longevity.",
"The Mediterranean diet promotes overall well-being."
],
"truths": [
"The Mediterranean diet is known for its health benefits.",
"The Mediterranean diet reduces the risk of heart disease, stroke, and diabetes.",
"The Mediterranean diet encourages the consumption of fruits, vegetables, whole grains, nuts, and olive oil.",
"The Mediterranean diet limits red meat consumption.",
"The Mediterranean diet has been associated with better cognitive function.",
"The Mediterranean diet has been associated with a reduced risk of Alzheimer's disease.",
"The Mediterranean diet promotes longevity and overall well-being."
],
"reason": "The score is 1.0 because the 'actual output' aligns perfectly with the information presented in the 'retrieval context', showcasing the health benefits, disease risk reduction, cognitive function improvement, and overall well-being promotion of the Mediterranean diet."
}
}
Roadmap
We have an exciting roadmap planned for IndoxJudge:
| Plan |
|---|
| Integration of additional metrics such as Diversity and Coherence. |
| Introduction of a graphical user interface (GUI) for easier evaluation. |
| Expansion of the toolkit to support evaluation in multiple languages. |
| Release of a benchmarking suite for standardizing LLM evaluations. |
Contributing
We welcome contributions from the community! If you'd like to contribute, please fork the repository and create a pull request. For major changes, please open an issue first to discuss what you would like to change.
- Fork the repository
- Create a new branch (
git checkout -b feature-branch) - Commit your changes (
git commit -am 'Add new feature') - Push to the branch (
git push origin feature-branch) - Create a pull request
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file indoxjudge-0.1.25.tar.gz.
File metadata
- Download URL: indoxjudge-0.1.25.tar.gz
- Upload date:
- Size: 335.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.12.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c19113a1a4d84da0b462413c216ab1a8be17fd138a4304aaf774aca7d729c0c0
|
|
| MD5 |
b17c6b70a21d6f7a10acbe99affc5f96
|
|
| BLAKE2b-256 |
8b99ac9e8d4a4c0f9335fc2c139bd37e80b7cccd540b67384ce818e6a44a6579
|
File details
Details for the file indoxJudge-0.1.25-py3-none-any.whl.
File metadata
- Download URL: indoxJudge-0.1.25-py3-none-any.whl
- Upload date:
- Size: 501.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/5.1.1 CPython/3.12.4
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c4e12e357a9708d8207dde054105ce6d9e692b5e9d4541aad075c2492c9323ea
|
|
| MD5 |
da9f52f1a1c4ddbe76a1ec8dbc76c592
|
|
| BLAKE2b-256 |
237886fb06db134022bf04ed72189450fde40fb713d8d22c696afb135ca1c28d
|







