Archives YouTube channels by automatically uploading their videos to archive.org

Project description
Internetarchive-YouTube



🚀 GitHub Action and CLI tool to archive YouTube channels by automatically uploading an entire YouTube channel to archive.org in few clicks.
📌 Global Requirements
- All you need is an Internet Archive account.
🔧 Usage
- ⚡️ To use this tool as a GitHub Action, jump to GitHub Action: Getting Started.
- 🧑💻 To use this tool as a command line interface (CLI), jump to CLI: Getting Started.
⚡️ GitHub Action: Getting Started
Using internetarchive-youtube as a GitHub Action instructions
-
Enable the workflows in your fork.
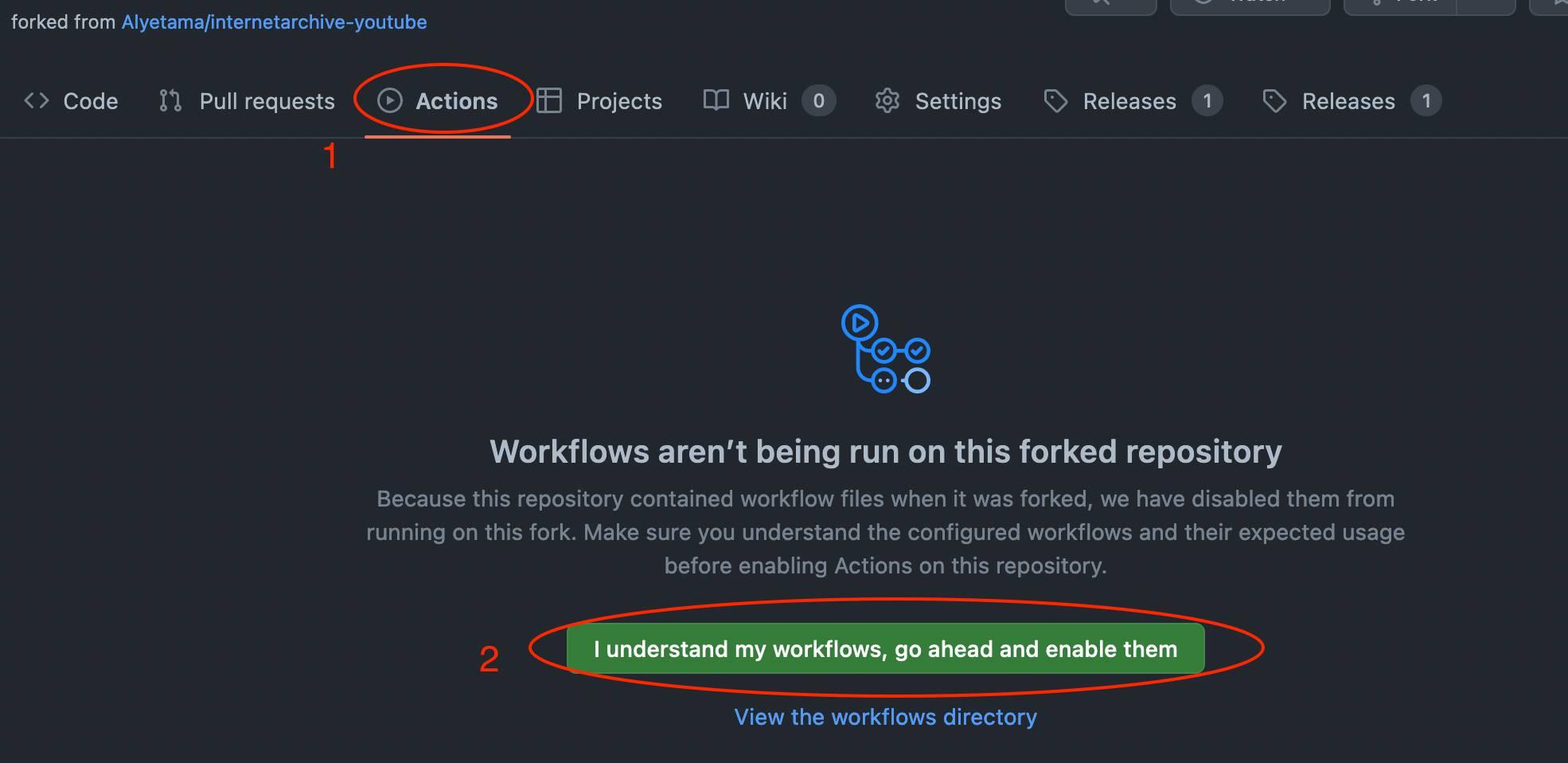
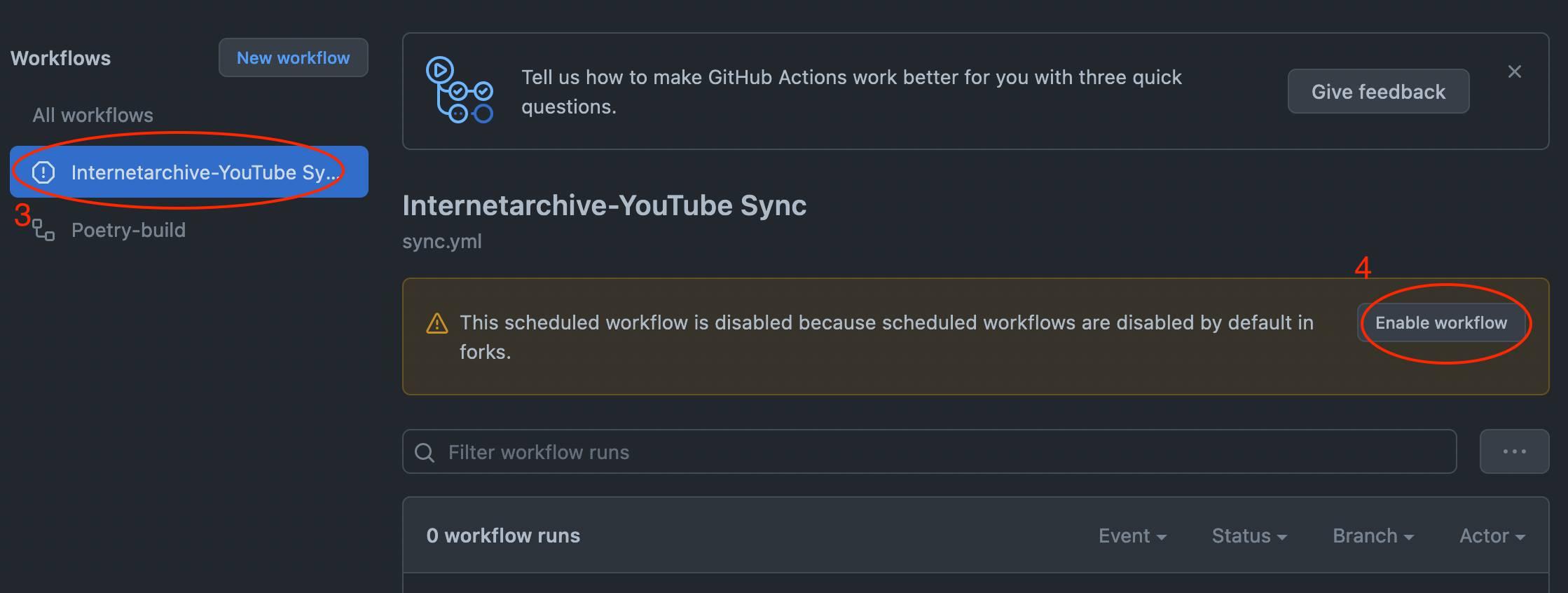
-
Add your Archive.org credentials to the repository's actions secrets:
ARCHIVE_USER_EMAILARCHIVE_PASSWORD
- Add a list of the channels you want to archive as a
CHANNELSsecret to the repository's actions secrets:
The CHANNELS secret should be formatted like this example:
CHANNEL_NAME: CHANNEL_URL
FOO: FOO_CHANNEL_URL
FOOBAR: FOOBAR_CHANNEL_URL
SOME_CHANNEL: SOME_CHANNEL_URL
Don't add any quotes around the name or the URL, and make sure to keep one space between the colon and the URL.
- Add the database secret(s) to the repository's Actions secrets:
If you picked option 1 (MongoDB), add this secret:
MONGODB_CONNECTION_STRINGThe value of the secret is the database conneciton string.
If you picked option 2 (JSON bin), add this additional secret:
JSONBIN_KEY
The value of this secret is the MASTER KEY token you copied from JSONbin.
-
(optional) You can add command line options other than the defaults by creating a secret called
CLI_OPTIONSand adding the options to the secret. See the CLI: Getting Started for a list of all the available options. -
Run the workflow under
Actionsmanually, or wait for it to run automatically every 6 hours.
That's it! 🎉
🧑💻 CLI: Getting Started
Using internetarchive-youtube as a CLI tool instructions
Requirements:
⬇️ Installation:
pip install internetarchive-youtube
Then login to internetarchive:
ia configure
🗃️ Backend database:
-
Create a backend database (or JSON bin) to track the download/upload overall progress.
-
If you choose MongoDB, export the connection string as an environment variable:
export MONGODB_CONNECTION_STRING=mongodb://username:password@host:port
# or add it to your shell configuration file:
echo "MONGODB_CONNECTION_STRING=$MONGODB_CONNECTION_STRING" >> "$HOME/.$(basename $SHELL)rc"
source "$HOME/.$(basename $SHELL)rc"
- If you choose JSONBin, export the master key as an environment variable:
export JSONBIN_KEY=xxxxxxxxxxxxxxxxx
# or add it to your shell configuration file:
echo "JSONBIN_KEY=$JSONBIN_KEY" >> "$HOME/.$(basename $SHELL)rc"
source "$HOME/.$(basename $SHELL)rc"
⌨️ Usage:
usage: ia-yt [-h] [-p PRIORITIZE] [-s SKIP_LIST] [-f] [-t TIMEOUT] [-n] [-a] [-c CHANNELS_FILE] [-S] [-C] [-m] [-T THREADS] [-k] [-i IGNORE_VIDEO_IDS] [-A] [-SC SPECIFIC_CHANNEL] [-co COOKIES_FILE]
options:
-h, --help show this help message and exit
-p PRIORITIZE, --prioritize PRIORITIZE
Comma-separated list of channel names to prioritize when processing videos.
-s SKIP_LIST, --skip-list SKIP_LIST
Comma-separated list of channel names to skip.
-f, --force-refresh Refresh the database after every video (Can slow down the workflow significantly, but is useful when running multiple concurrent
jobs).
-t TIMEOUT, --timeout TIMEOUT
Kill the job after n hours (default: 5).
-n, --no-logs Don't print any log messages.
-a, --add-channel Add a channel interactively to the list of channels to archive.
-c CHANNELS_FILE, --channels-file CHANNELS_FILE
Path to the channels list file to use if the environment variable `CHANNELS` is not set (default: ~/.yt_channels.txt).
-S, --show-channels Show the list of channels in the channels file.
-C, --create-collection
Creates/appends to the backend database from the channels list.
-m, --multithreading Enables processing multiple videos concurrently.
-T THREADS, --threads THREADS
Number of threads to use when multithreading is enabled. Defaults to the optimal maximum number of workers.
-k, --keep-failed-uploads
Keep the files of failed uploads on the local disk.
-i IGNORE_VIDEO_IDS, --ignore-video-ids IGNORE_VIDEO_IDS
Comma-separated list or a path to a file containing a list of video ids to ignore.
-A, --use-aria2c Use external downloader aria2c (can significantly speed up downloads).
-SC SPECIFIC_CHANNEL, --specific-channel SPECIFIC_CHANNEL
Archive one specific channel by name.
-co COOKIES_FILE, --cookies-file COOKIES_FILE
Path to a YouTube cookies file (for age-restricted or private videos).
🏗️ Creating A Backend Database
Creating A Backend Database instructions
- Option 1: MongoDB (recommended).
- Self-hosted (see: Alyetama/quick-MongoDB or dockerhub image).
- Free cloud database on Atlas.
- Option 2: JSON bin (if you want a quick start).
- Sign up to JSONBin here.
- Click on
VIEW MASTER KEY, then copy the key.
📝 Notes
- Information about the
MONGODB_CONNECTION_STRINGcan be found here. - Jobs can run for a maximum of 6 hours, so if you're archiving a large channel, the job might die, but it will resume in a new job when it's scheduled to run.
- Instead of raw text, you can pass a file path or a file URL with a list of channels formatted as
CHANNEL_NAME: CHANNEL_URL. You can also pass raw text or a file of the channels in JSON format{"CHANNEL_NAME": "CHANNEL_URL"}.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file internetarchive_youtube-0.3.8.tar.gz.
File metadata
- Download URL: internetarchive_youtube-0.3.8.tar.gz
- Upload date:
- Size: 15.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.8.3 CPython/3.10.8 Darwin/25.5.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9b15361cfcf173ba74ab9312fcb510e84d4af620c1d64df33111dc7a41e707cd
|
|
| MD5 |
7d4a5ca8e908998f562d56b0417c9648
|
|
| BLAKE2b-256 |
11578fcd960f73597b42e36ad27a05670658767a8bf3f22e2aedc5c33a76456c
|
File details
Details for the file internetarchive_youtube-0.3.8-py3-none-any.whl.
File metadata
- Download URL: internetarchive_youtube-0.3.8-py3-none-any.whl
- Upload date:
- Size: 16.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.8.3 CPython/3.10.8 Darwin/25.5.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b7a836e96deae73af405b9eae1184b95c3eb2714216a1fe5888dfc7495b86a32
|
|
| MD5 |
dcbb5db7528e56dc84f14e9b12fbcc74
|
|
| BLAKE2b-256 |
d57300304211fe533df53a1e708989499c3607ce6e66d4362f874b4523b72e70
|







