Jupyter widget for applying nlp to pdf documents

Project description
iPyPDF
A Jupyter-based tool to help parse out structured text from a PDF document and explore the contents.
Installation
Windows Installer
https://drive.google.com/drive/folders/1wmQisECMor04dgv9ZXFc07zq6zcHuija?usp=sharing
This will make a start-menu shortcut called "iPyPDF" which will open up the notebook for parsing documents.
From Source
- Clone this repo
- Install Anaconda or Miniconda if you do not already have it
- Install mamba
conda install mamba- Solving the environment is impossibly slow without mamba
- Create the environment and install ipypdf from source
mamba env create -f environment.yml -p env/ipypdf
conda activate env/ipypdf
pip install -e .
Note: you can replace "mamba" with "conda" if you don't have mamba installed. It will just take longer to solve the environment.
From pip
- Create a conda environment with
TesseractandJupyterlab
conda create -n ipypdf jupyterlab tesseract -c conda-forge`
conda activate ipypdf
pip install ipypdf
- Get a spacy model (the previous method accomplishes this automatically in the
environment.ymlfile)python -m spacy download en_core_web_sm- Or
conda install spacy-model-en_core_web_sm -c conda-forge
Usage
ipypdf is built for jupyter lab but should also work in jupyter notebooks.
- Launch jupyter lab with
jupyter lab
from ipypdf import App
app = App("path/to/your/pdfs", bulk_render=False)
app
see notebooks for additional info
Development
see DEVELOPMENT.md
Common Issues
- AutoTools widget keeps saying layoutparser is not installed
- This is usually a problem with pywin32.
- Try
conda install pywin32 - Also make sure that numpy is <1.19.3
Features
Within the GUI are 3 panels, Table of Contents, PDF viewer, and Tools. In this section we are going over all of the various options available in the tools panel.
Auto-Tools
This tab contains tools which will iterate through each page of the pdf.
Text Only: Runs each page through Tesseract to obtain plain text.Parse Layout: Uses layoutparser to label portions of the document as either (title, text, image, or table). The sections are then assembled together using a few simple rules in order to appoximate a shallow content hierarchy.- Title and Text blocks are cropped out and sent through Tesseract to obtain the text.
- Tables are processed using a rule-based table parsing scheme described here.
- Image blocks have no additional processing.

Notice that section 3 is missing. The process is not perfect. In this case, a section title was mislabled by layoutparser as standard text. Mistakes like this are fairly common. To correct them, you can edit the table of contents using the arrow keys (the cursor must be hovering over the table of contents).
Table Parsing

Cytoscape
Folders, PDF Documents, and Sections have a tab labeled Cytoscape. This runs a tfidf similarity calculation over all nodes beneath the selected item. I.e. if you select the root node, then all defined nodes will be included in the calculation. However, only those with a link to another node will be drawn (this is for speed, may change this in the future).
The color of each node denotes the pdf document it originated from.
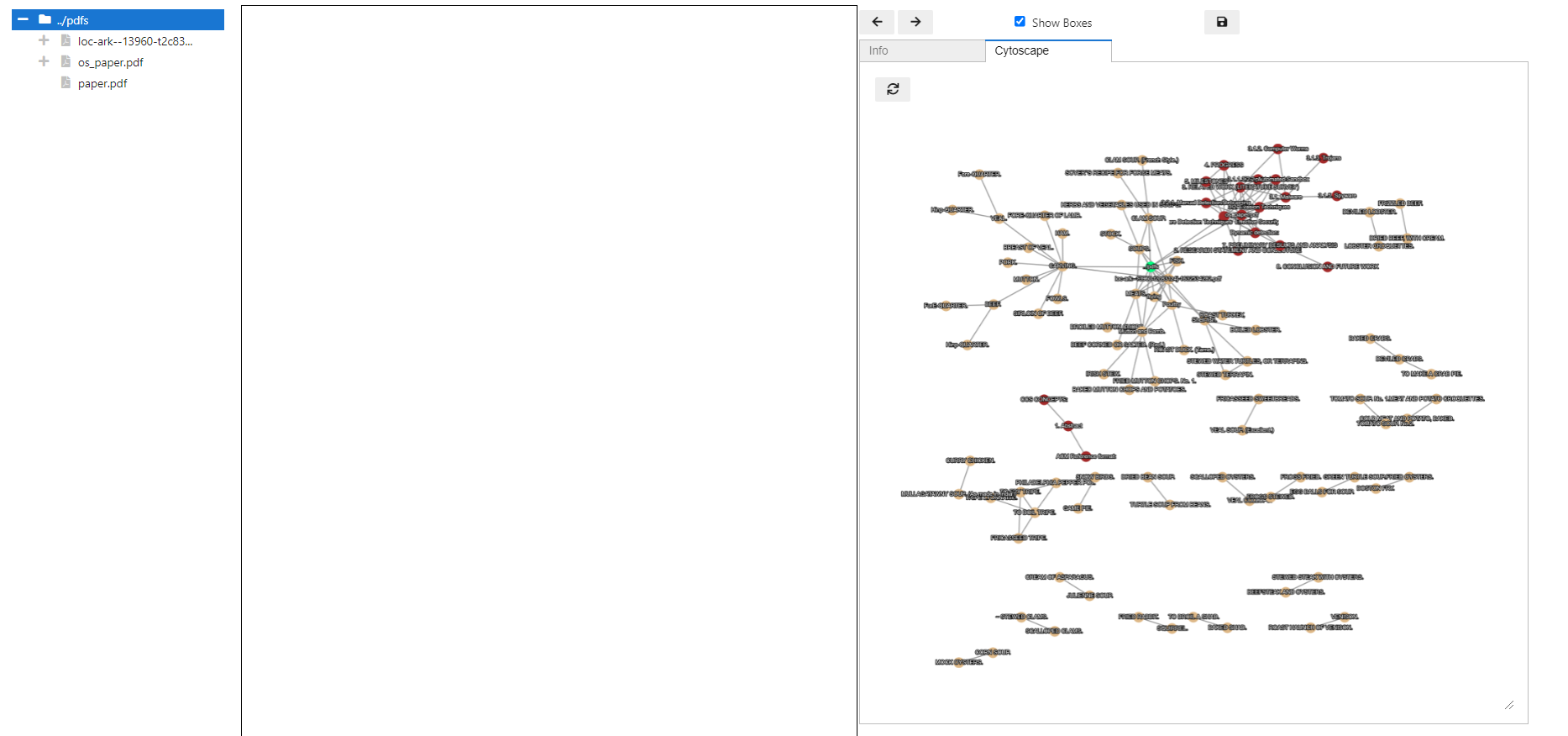
Selecting a node in the graph will highlight the node in the DocTree. Clicking the node in the DocTree will render the first page of the node.

Spacy
Extracts named entities from the selected branch of the document tree. I.e.,
the raw text is compiled from a depth first search on whichever node is selected
in the table of contents. Then, spacy.nlp(text).ents returns the named entities
found within the section.

Digitizing Utilities
I recommend turning off
Show Boxesas this changes pages every time you add a node (working on a better solution)
Each node has a specific set of tools available to use. Here are the tools provided when a Section node is selected.
Starting from the left:
Add Section Nodeadds a sub-node of typeSectionand selects itAdd Text Nodeadds a sub-node of typeTextand selects itAdd Image Node...Delete NodeDelete the selected node and all of its children
Content Selector
Content is extracted from the rendered image. Text is extracted using Optical Character Recognition (OCR). Images don't do any image analysis, they just denote coordinates and page number so that they can be retreived later if need be.
When a Section node is selected, the selection tool will attempt to parse text from the portion of the page selected by the user. This text will overwrite the label assigned to the node.
When a Text node is selected, the selection tool will attempt to parse text from the selected area and append it to the node's content. This is because text blocks are not always perfectly rectangular, and often span multiple pages.
When an Image node is selected, the coordinates of the box are appended to the node's content.
Save Button
This will generate json files for each document. When the tool is initialized, these are used to reconstruct the table of contents. You can also use the json file directly.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file ipypdf-0.1.7.tar.gz.
File metadata
- Download URL: ipypdf-0.1.7.tar.gz
- Upload date:
- Size: 38.0 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.8.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7fe290b2dd504ed4cdc1c3a6ecfa304936f5e0f58e304867dfa640be09c4688f
|
|
| MD5 |
3f6d74bea2052ed2a84eadf511b2842b
|
|
| BLAKE2b-256 |
eaa022ff59ebf5de7f69dbe9054af5b1362f6a2211b32fa2b38548223afc1a41
|
File details
Details for the file ipypdf-0.1.7-py2.py3-none-any.whl.
File metadata
- Download URL: ipypdf-0.1.7-py2.py3-none-any.whl
- Upload date:
- Size: 40.9 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.8.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
bdfe23f1d14c5de32b18a4f0b7d17c50f3d81b9c47cf7d3fb3b39e778ce9d1ca
|
|
| MD5 |
d2dbd50f72210e2a59875d2d1c8f8566
|
|
| BLAKE2b-256 |
fb3a4bd609facab4764e7f229da82643342bf8645277a57724a2d92ed7c0d498
|







