A simple AI Tool set application

Project description
 jllama-py
jllama-py
主要技术栈
前端
Vue、ElementUI
后端
python3.11、pywebview、llama-cpp-python、transformers、pytorch
介绍
jllama-py是jllama的Python版本,并且得益于使用了python作为技术底座,在原本jllama的基础上做了一些功能增强。 是一个基于python构建的桌面端AI模型工具集。集成了 模型下载、模型部署、服务监控、gguf模型量化、gguf拆分合并 、权重格式转换、模型微调等工具合集。让使用者无需掌握各种AI相关技术就能快速在本地运行模型进行模型推理、量化等操作、模型微调工作。
限制
jllama-py目前只支持大语言模型(LLM)。未来会考虑支持视觉、音频等多模态模型。jllama-py支持huggingface、gguf模型格式文件的本地推理,但是在本地部署方案上仅支持gguf模型权重格式,不过jllama-py也提供了将huggingface格式模型转换为gguf模型格式的功能。此外jllama-py仅支持Windows操作系统。目前jllama-py也只支持cuda的GPU加速方案。
安装和使用
1. 使用pip安装
jllama-py使用了llama-cpp-python作为模型推理技术底座,需要本机配置了C++编译环境。推荐先安装llama-cpp-python之后再安装jllama-py。llama-cpp-python安装请参考如下。
CPU版本安装请参考llama-cpp-python-cpu
CUDA版本安装请参考llama-cpp-python-cuda
也可以直接安装llama-cpp-python官方的whl。 Releases · abetlen/llama-cpp-python
# 省略llama-cpp-python的安装过程
...
pip install jllama-py
# 运行
jllama
直接安装请参考如下。CPU版本安装请提前下载好MinGW或安装Visual Studio;CUDA版本安装请安装Visual Studio 2022软件并安装C++运行环境。
# CPU版本安装
$env:CMAKE_GENERATOR = "MinGW Makefiles"
$env:CMAKE_ARGS = "-DGGML_OPENBLAS=on -DCMAKE_C_COMPILER=${MinGW安装目录}/mingw64/bin/gcc.exe -DCMAKE_CXX_COMPILER=${MinGW安装目录}/mingw64/bin/g++.exe"
pip install jllama-py
# CUDA版本安装
$env:CMAKE_ARGS = "-DGGML_CUDA=ON"
pip install jllama-py
关于pytorch的cuda加速,请额外执行如下命令。可参考pytorch官方说明 。tips: 50系显卡驱动比较新,请使用cuda12.8版本。在jllama-py中,pytorch用于hf格式的模型推理以及模型微调。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/${你的cuda版本}

2. 使用源码编译安装
基础依赖安装:执行如下安装命令
git clone https://github.com/zjwan461/jllama-py
cd jllama-py
pip install -r requirements.txt
cd ui
npm install
npm run build
# copy ui/dist文件夹到jllama/ui/dist目录下
cd ../jllama
python main.py
jllama-py使用了llama-cpp-python作为模型推理技术底座,默认情况下安装的是CPU版本的llama-cpp-python。如果需要使用cuda进行加速推理,请参考如下。
CPU版本安装请参考llama-cpp-python-cpu
CUDA版本安装请参考llama-cpp-python-cuda
默认情况下基础依赖安装会安装上CPU版本的pytorch包,如需要安装cuda版本请执行
pip install -r pytorch-cuda.txt
功能介绍
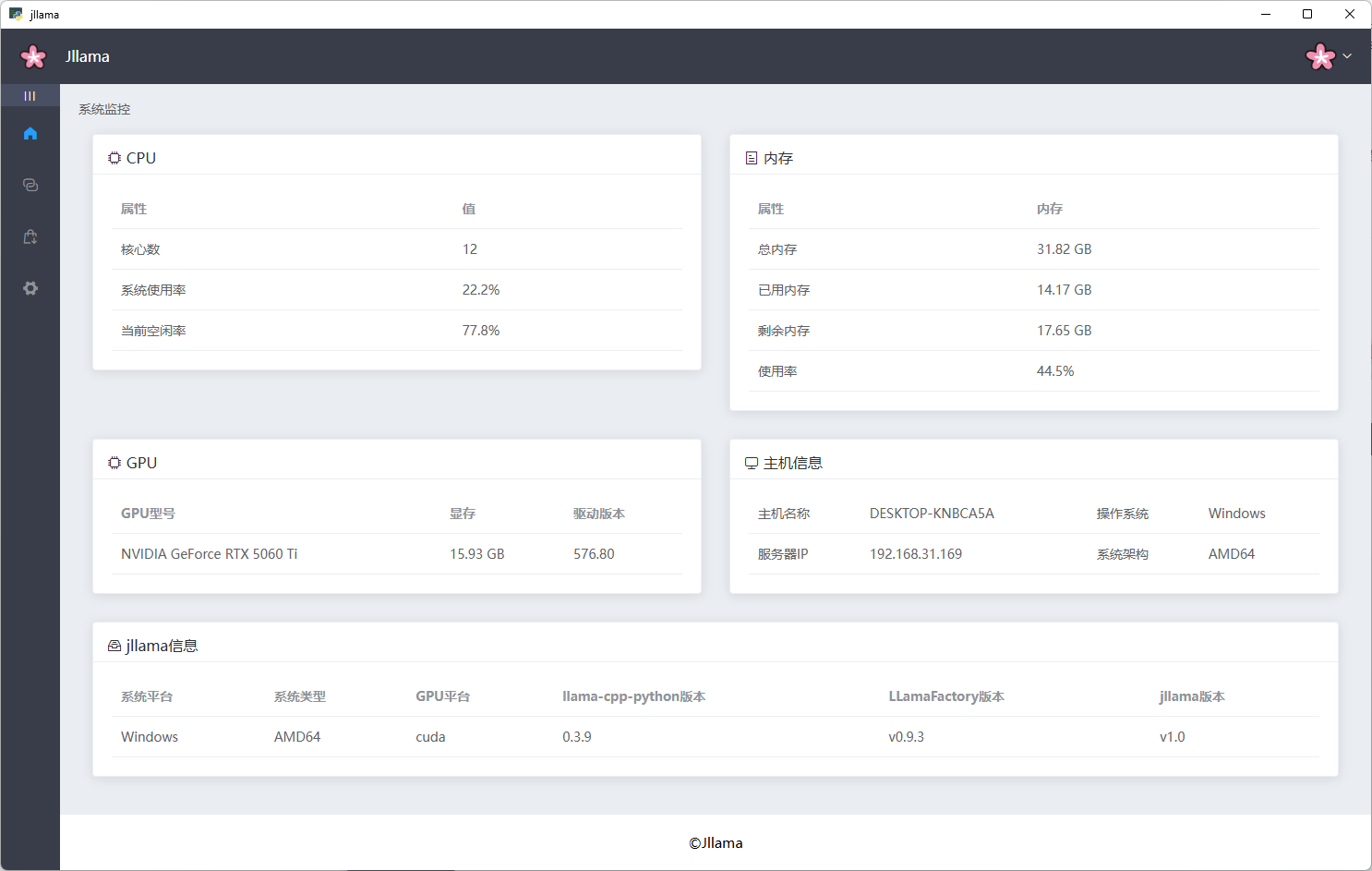
一、系统监控
一个简单的系统资源监控面板
二、模型管理
jllama-py提供了两种模型文件下载方式。Hugging Face.和model scope 不过考虑到国内网络问题建议使用modelscope的方式下载模型。
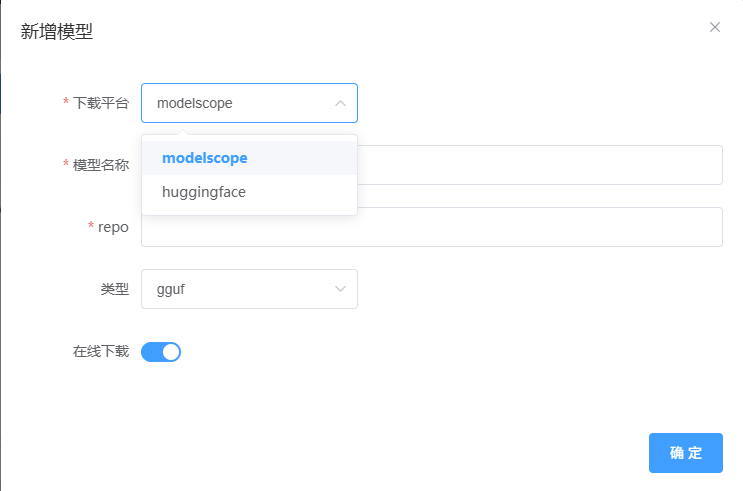
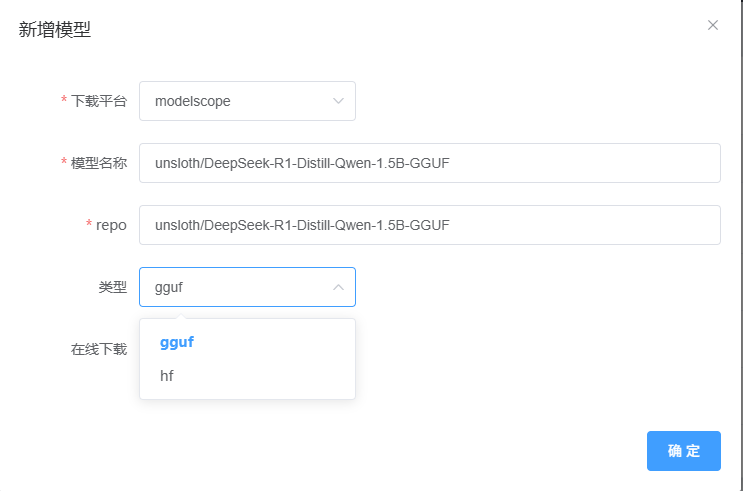
你可以在模型下载菜单中点击新增按钮。选择模型下载平台。模型名称可自定义,repo需要和modelscope的模型仓库名一致。比如如下图的unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF。点击确认后Jllama将会从modelscope上拉取可供下载的文件列表。选择你需要下载的GGUF模型权重文件进行下载即可。

需要指定模型类型。如果是gguf的模型则选择gguf,此外huggingface格式模型则选择hf
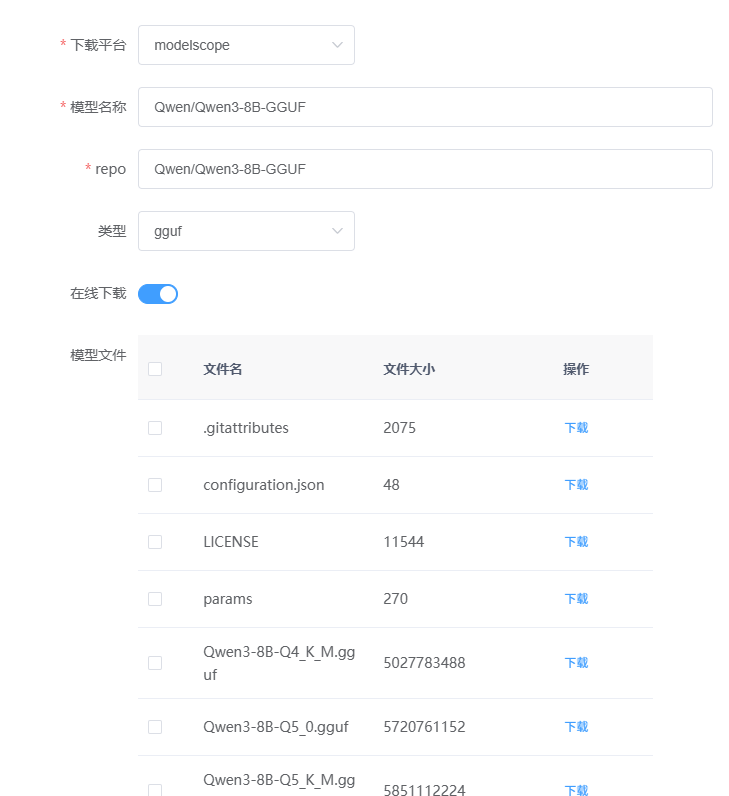
在弹出的模型文件item中,选择你想要下载的模型文件即可进行在线下载。如果不想使用jllama-py的在线下载功能,可以不勾选在线下载开关,直接关闭对话框即可。
三、AI推理和本地部署
AI 推理
AI推理是本地测试模型能力的工具,其并不具备并发能力。其作用是用来快速运行一个模型,完成一些简单的AI问答功能。虽然底层也是通过一个http api的方式来进行交互,但其并不兼容openAI的请求报文格式。
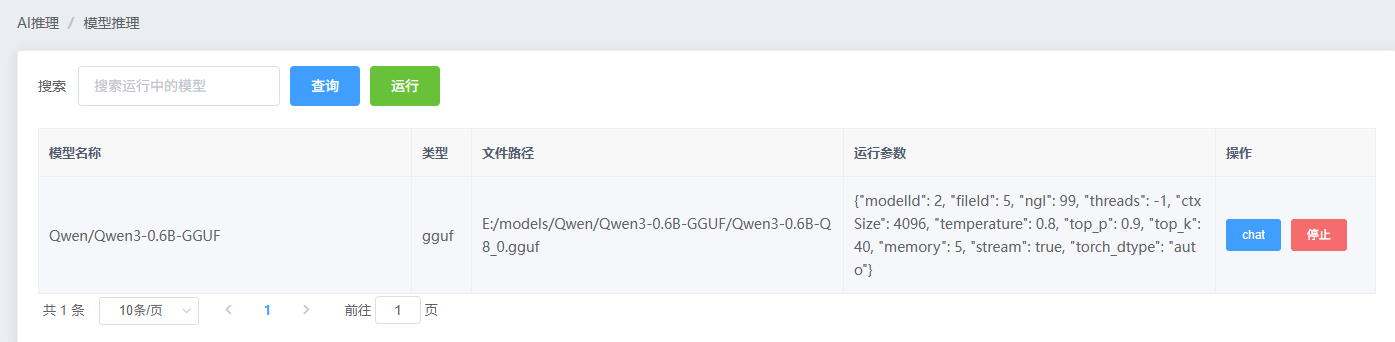
AI Chat:
在开启了模型推理服务后,点击列表右侧的chat按钮即可进入AI Chat页。在这个页面你可以和大模型进行简单的AI问答。
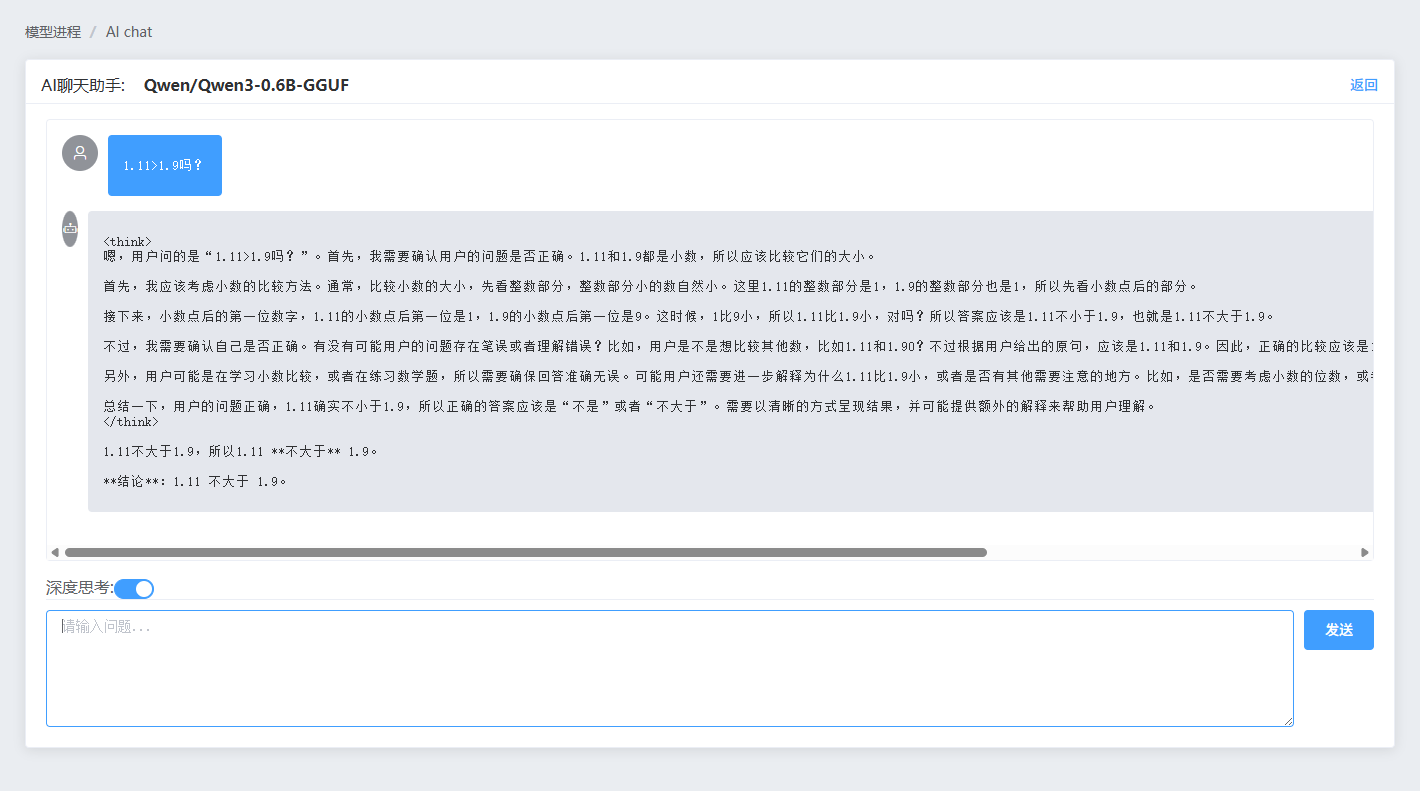
本地部署
本地部署仅支持gguf类型的模型。底层使用llama-cpp-python部署一个兼容openAI的http server。本地部署会在jllama-py中维护一个llama-cpp-python的配置,通过修改这个配置来对本地部署的模型进行维护。jllama-py支持直接编辑和通过本地编辑器编辑的方式来修改此配置文件。在执行部署选项卡中即可以在本地开启一个兼容openAI的http server。开启后你可以将本地服务配置到各种RAG工具中,如Cherry Studio、Dify。关于配置项怎么写,请参考llama-cpp-python官方说明OpenAI Compatible Web Server - llama-cpp-python中的Configuration and Multi-Model Support章节。

在Cherry Studio中配置jllama-py服务

四、gguf模型权重拆分、合并
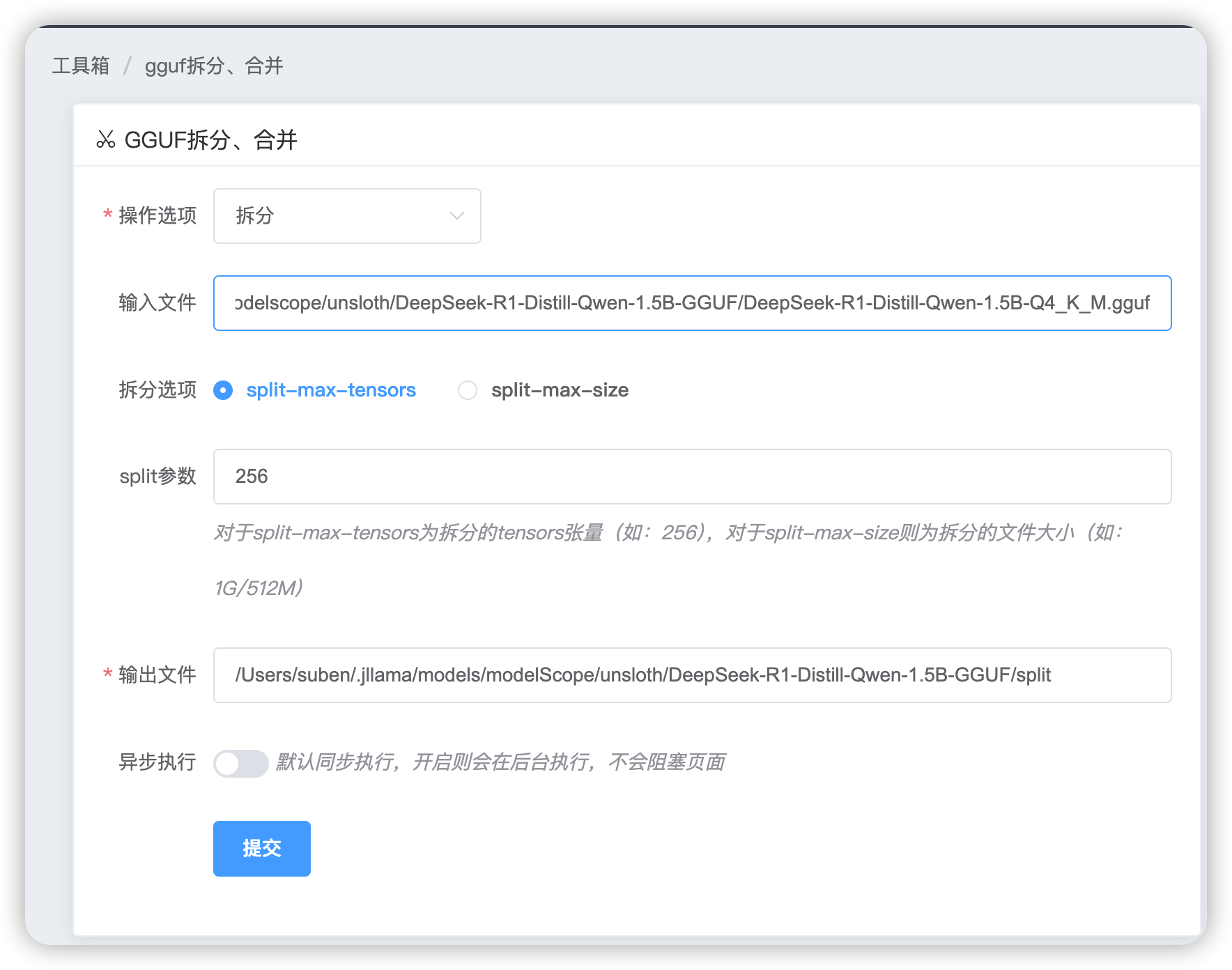
拆分
填写好输入文件、拆分选项、拆分参数、输出文件点击提交。jllama-py使用了llama.cpp的llama-gguf-split功能把原始的gguf拆分为多个gguf文件。利于超大模型权重文件的传输和保存。

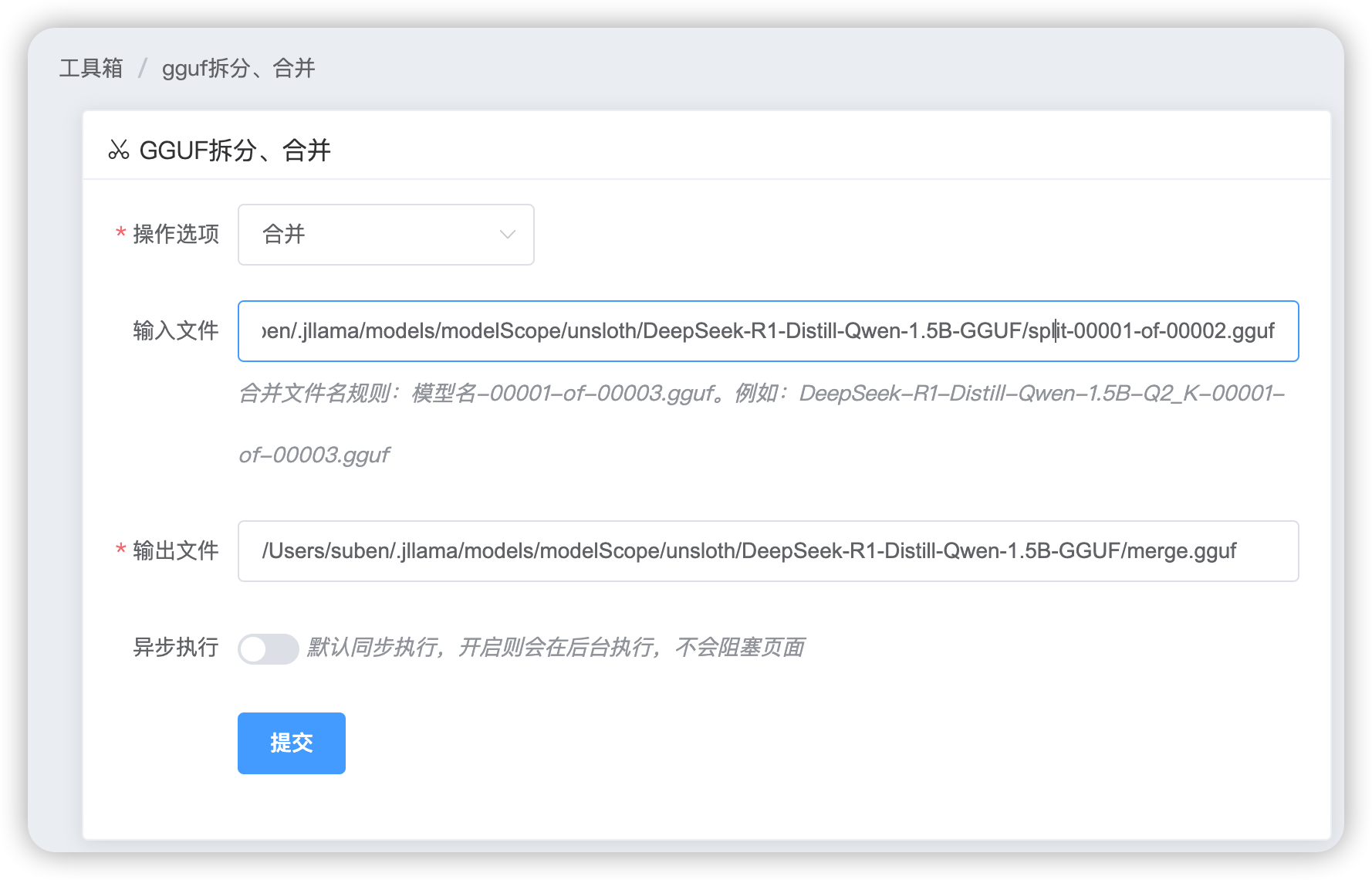
合并
填写好输入文件,即需要合并的gguf文件路径(00001-of-0000n命名的文件)、输出文件。jllama-py使用了llama.cpp的llama-gguf-split功能把分散的几个gguf文件合并为一个gguf模型权重文件。
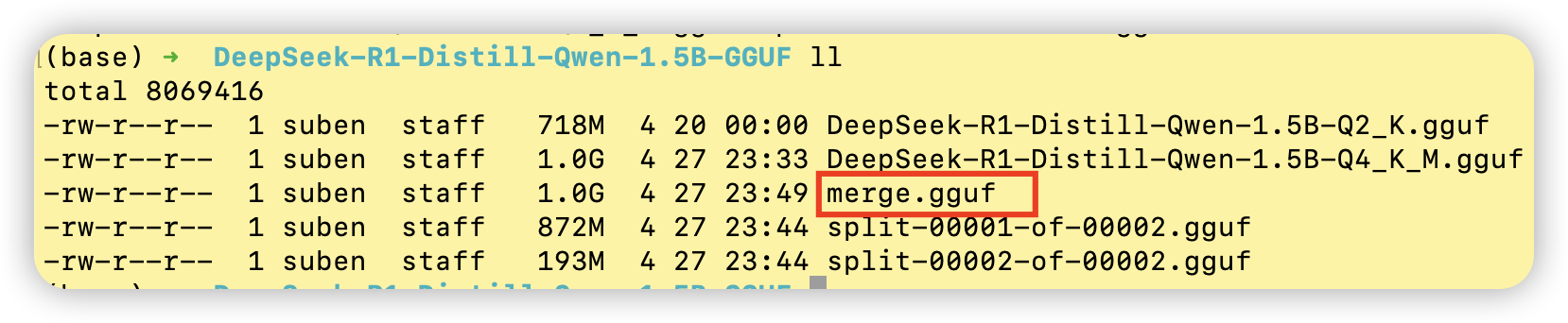
五、模型量化
对于较大参数量的模型权重文件直接进行本地部署的硬件要求是非常高的,即使使用了CUDA这种GPU加速的方案,其对显存大小的要求也是比较高的。部署一个7B的gguf模型所需显存资源大致如下:
- 16 位浮点数(FP16):通常情况下,每个参数占用 2 字节(16 位)。7B 模型意味着有 70 亿个参数,因此大约需要 70 亿 ×2 字节 = 140 亿字节,换算后约为 13.5GB 显存。
- 8 位整数(INT8):如果采用 8 位量化,每个参数占用 1 字节(8 位),那么 7B 模型大约需要 70 亿 ×1 字节 = 70 亿字节,即约 6.6GB 显存。
因此,如果使用模型量化技术,将一个FP16的模型量化为INT8的模型,能够减少一半左右的显存占用。能够帮助个人利用有限的硬件进行模型的本地部署。
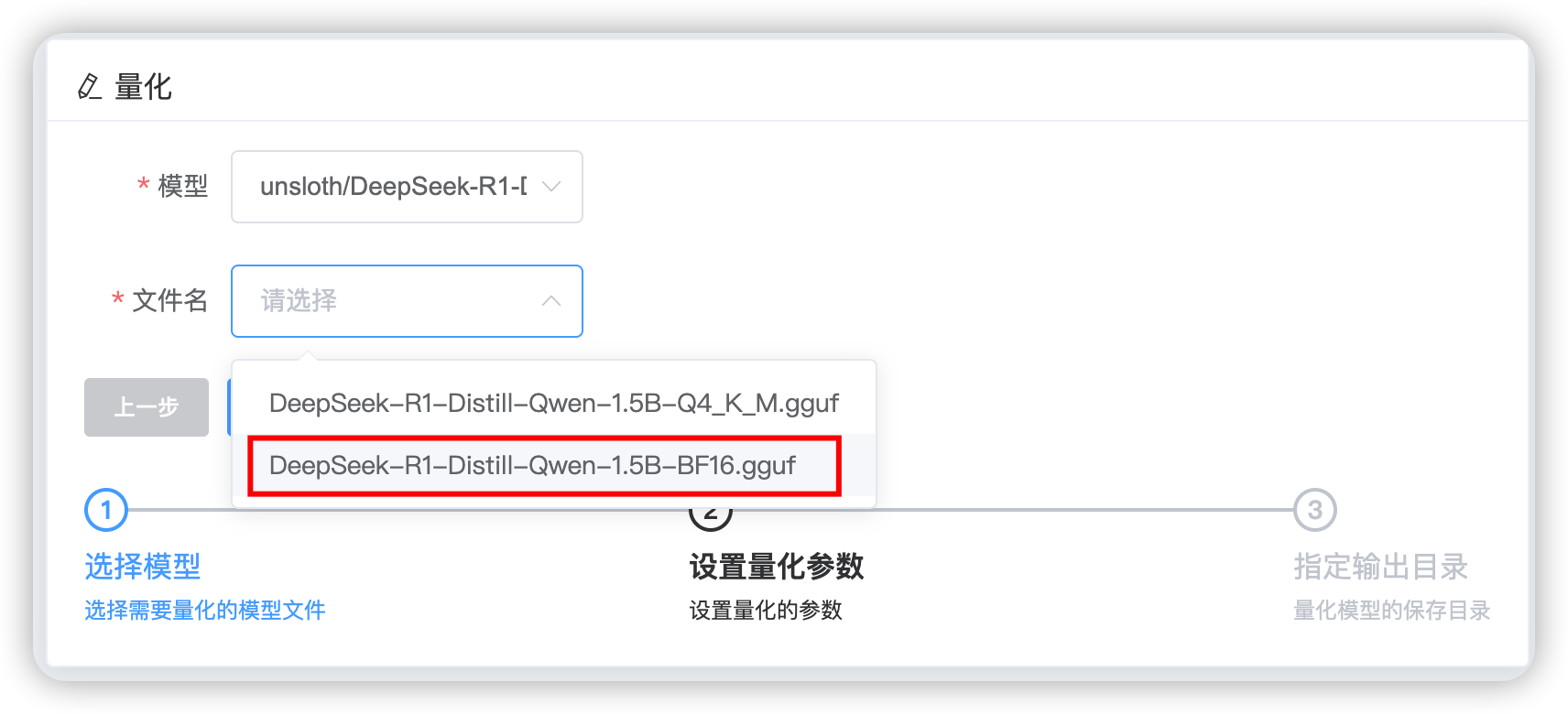
如下,这里我准备了一个BF16精度的deepseek-r1:1.5B的模型权重文件,将其量化为一个Q4_0精度的模型权重文件。量化完成后,得到一个Q4_0的量化后的模型权重文件。文件大小从BF16的3.3G降低到了1G。
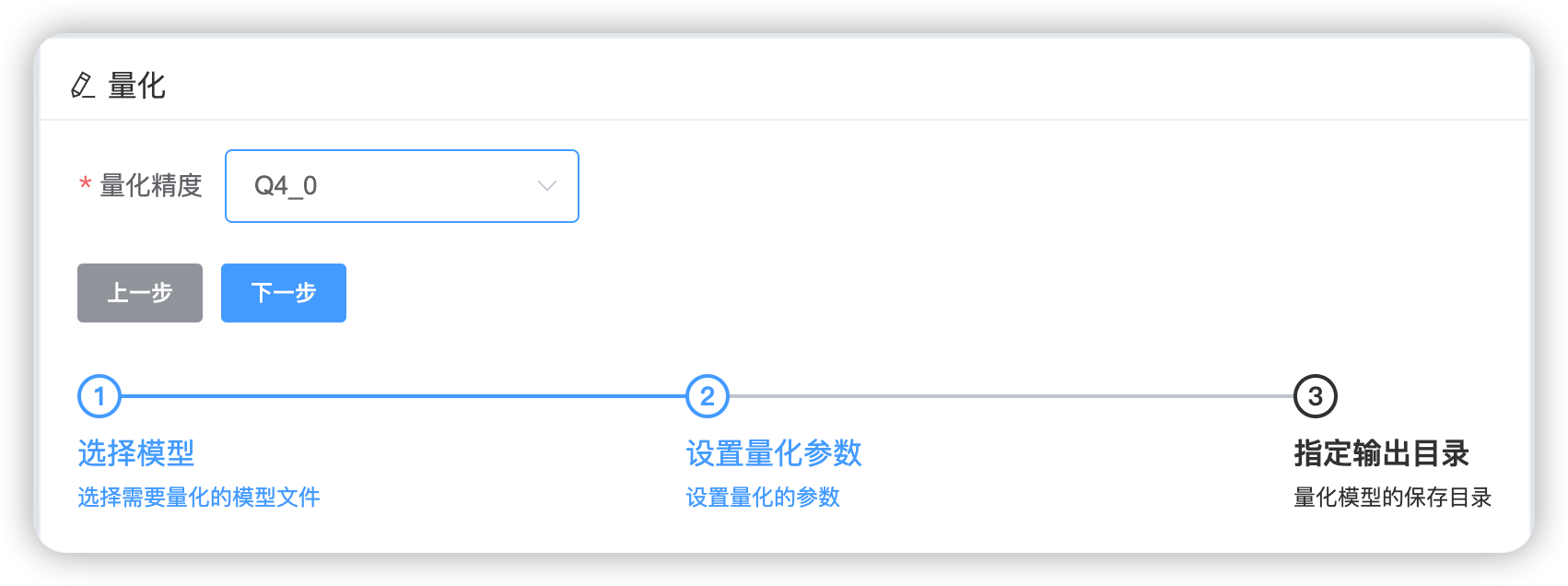

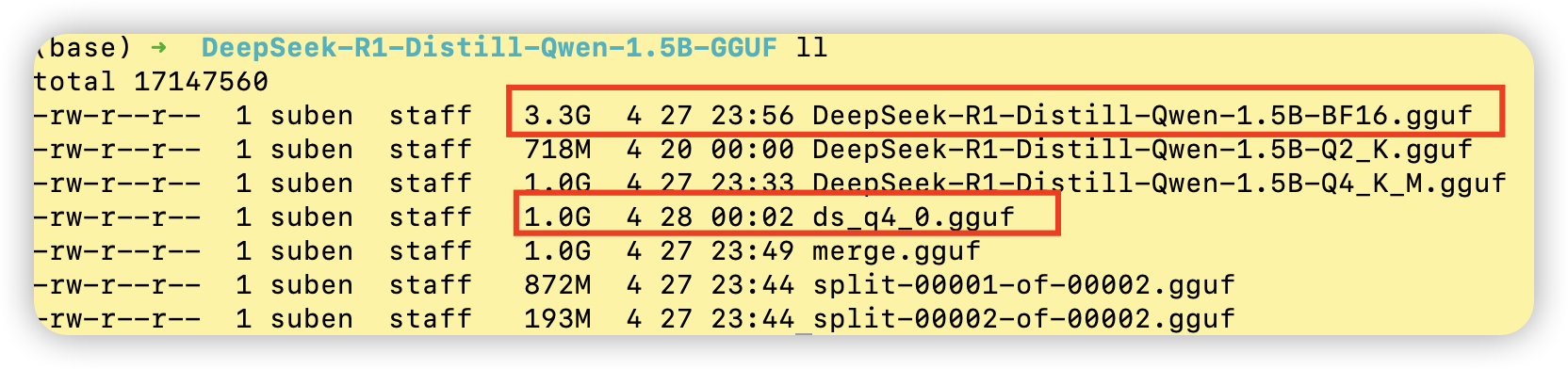
六、模型导入
如果在第二点的模型管理中并没有使用在线下载模型,jllama-py也提供了手动导入模型的方式。
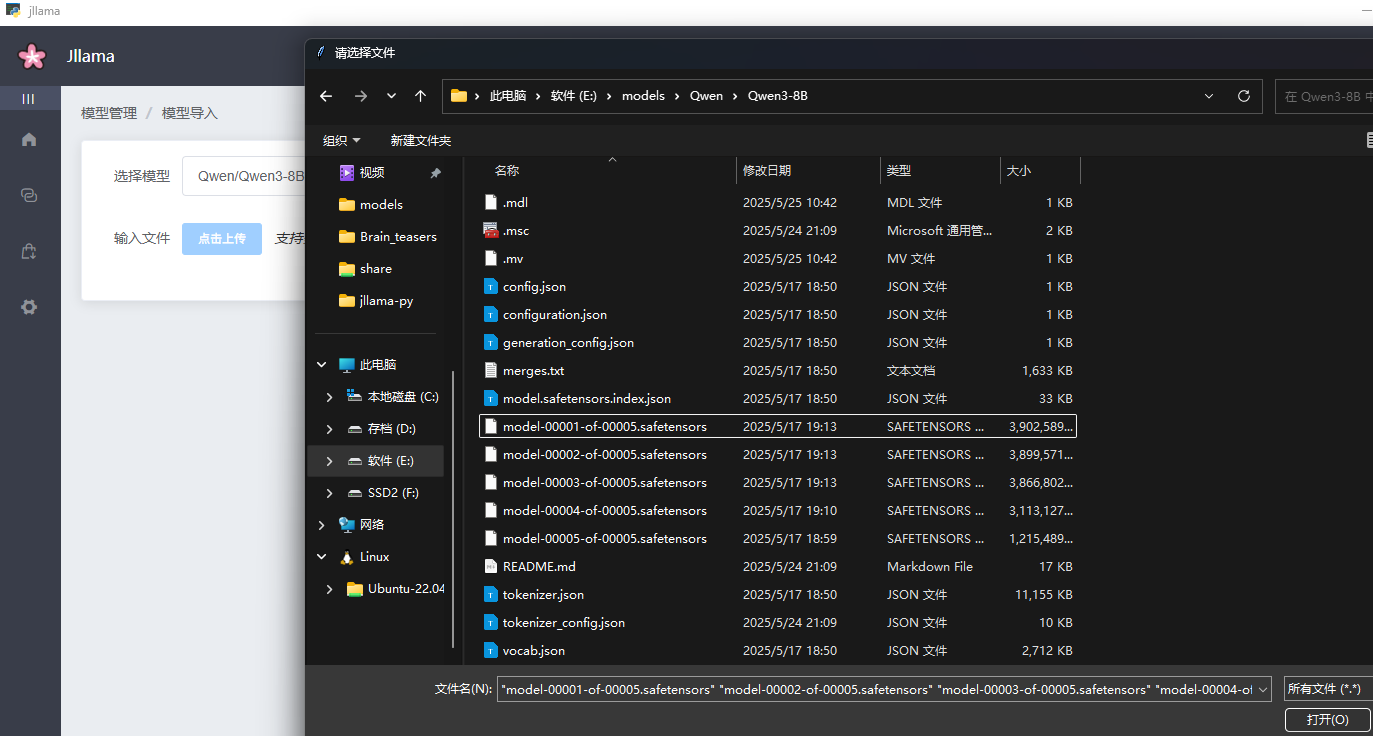
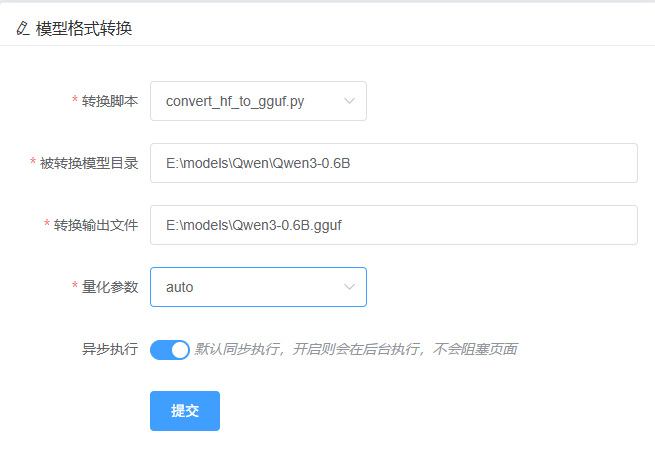
七、模型格式转换
因为jllama-py的本地部署方式只支持gguf模型格式。所以如果是transformers的原生模型格式想要使用本地部署功能需要将.safetensors格式的模型文件转换为gguf文件格式。在jllama-py中,你可以通过内置的脚本实现这一功能。
八、模型微调
本地微调
此功能对本地机器的性能有较高要求,建议显存在16G+的机器使用本地微调功能。配置项请参考右侧的参数说明。此外本地微调只支持lora微调这一种方式,如需要进行全参数微调或者freeze参数微调请使用llamafactory微调模式。在微调之前也可以使用微调代码预览的功能,进行大致的代码review。


远程微调
远程微调,需要提前在远端机器上安装好相关python软件包。请参考如下提供的requirements.txt。
accelerate==1.8.1
aiohappyeyeballs==2.6.1
aiohttp==3.12.13
aiosignal==1.3.2
attrs==25.3.0
certifi==2025.6.15
charset-normalizer==3.4.2
datasets==3.6.0
dill==0.3.8
filelock==3.13.1
frozenlist==1.7.0
fsspec==2024.6.1
hf-xet==1.1.5
huggingface-hub==0.33.1
idna==3.10
Jinja2==3.1.4
MarkupSafe==2.1.5
mpmath==1.3.0
multidict==6.6.2
multiprocess==0.70.16
networkx==3.3
numpy==2.1.2
nvidia-cublas-cu12==12.8.3.14
nvidia-cuda-cupti-cu12==12.8.57
nvidia-cuda-nvrtc-cu12==12.8.61
nvidia-cuda-runtime-cu12==12.8.57
nvidia-cudnn-cu12==9.7.1.26
nvidia-cufft-cu12==11.3.3.41
nvidia-cufile-cu12==1.13.0.11
nvidia-curand-cu12==10.3.9.55
nvidia-cusolver-cu12==11.7.2.55
nvidia-cusparse-cu12==12.5.7.53
nvidia-cusparselt-cu12==0.6.3
nvidia-nccl-cu12==2.26.2
nvidia-nvjitlink-cu12==12.8.61
nvidia-nvtx-cu12==12.8.55
packaging==25.0
pandas==2.3.0
peft==0.15.2
pillow==11.0.0
propcache==0.3.2
psutil==7.0.0
pyarrow==20.0.0
python-dateutil==2.9.0.post0
pytz==2025.2
PyYAML==6.0.2
regex==2024.11.6
requests==2.32.4
safetensors==0.5.3
six==1.17.0
sympy==1.13.3
tokenizers==0.21.2
torch==2.7.1+cu128
torchaudio==2.7.1+cu128
torchvision==0.22.1+cu128
tqdm==4.67.1
transformers==4.53.0
triton==3.3.1
typing_extensions==4.12.2
tzdata==2025.2
urllib3==2.5.0
xxhash==3.5.0
yarl==1.20.1
在微调之前先按要求填写好微调参数,之后点击远程微调按钮。在弹出的对话框中填写好远程Linux服务器的信息和微调目录以及python安装目录。
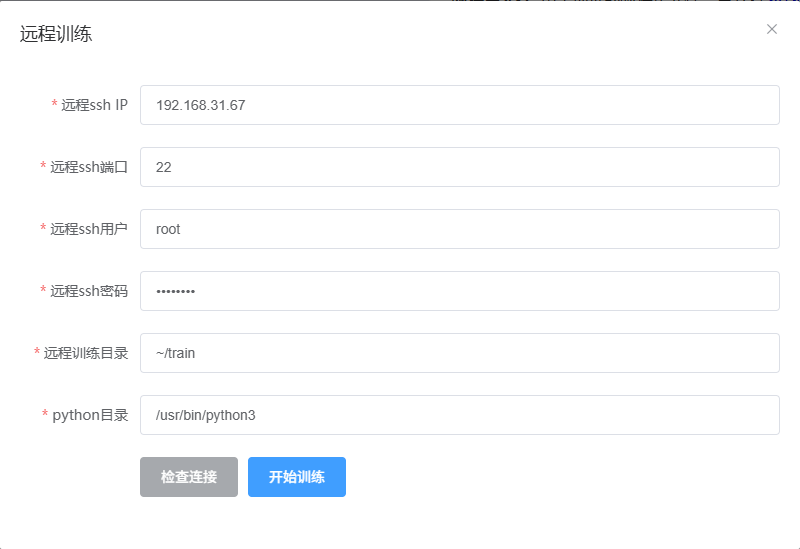
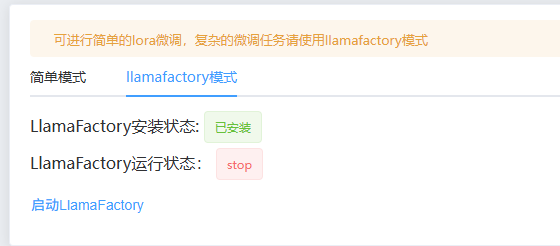
llamafactory微调
jllama-py内置了llamafactory-0.9.3版本。关于llamafactory,请参考LLaMA Factory官方网站
开发接入
修改当前用户名录下配置文件${USER}/jllama/config.json中的model为dev,修改ai_config配置项中本地保存模型的目录。如果需要设置网络代理,请修改proxy配置项中的代理地址(使用huggingface下载模型时需要配置此项)。
{
"db_url": "sqlite:///db/jllama.db",
"server": {
"host": "127.0.0.1",
"port": 5000
},
"model": "dev",
"auto_start_dev_server": false,
"app_name": "jllama",
"app_width": 1366,
"app_height": 768,
"ai_config": {
"model_save_dir": "E:/models",
"llama_factory_port": 7860
},
"proxy": {
"http_proxy": "",
"https_proxy": ""
}
}
进入ui目录,并执行npm构建命令
cd ui
npm install
npm run serve
运行主程序
python main.py
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file jllama_py-1.1.5.tar.gz.
File metadata
- Download URL: jllama_py-1.1.5.tar.gz
- Upload date:
- Size: 16.7 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.11.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b7f82d2aea56bf4d63219a48a4bdbe601966707df493b8cdf6ec4006d14c5c54
|
|
| MD5 |
341b8918d3b1ff30f32af9b4e022f3eb
|
|
| BLAKE2b-256 |
a6f759a23bcb0f0b475a7efc64d232b9b9c215668f92f9c2b340440bc735c9f7
|
File details
Details for the file jllama_py-1.1.5-py3-none-any.whl.
File metadata
- Download URL: jllama_py-1.1.5-py3-none-any.whl
- Upload date:
- Size: 16.8 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.11.13
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f81295dc36be3bd14f2f9865f04bcd79cec8b1c27102b89efe9d10f634b86b43
|
|
| MD5 |
873f233dda405338bb5553347141ac00
|
|
| BLAKE2b-256 |
d3ad55042b4275163839c716da4ab24c2335473cba862b1556b9a9d36f8c55b6
|







