KFoldImblearn handles the resampling of data in a k fold fashion, taking care of information leakage so that our results are not overly optimistic. It is built over the imblearn package and is compatible with all the oversampling as well as under sampling methods provided in the imblearn package.

Project description
KFoldImblearn Introduction
KFoldImblearn handles the resampling of data in a k fold fashion, taking care of
information leakage so that our results are not overly optimistic. It is built over
the imblearn package and is compatible with all the oversampling as well as under
sampling methods provided in the imblearn package.
While performing over-sampling, under-sampling and balanced-sampling we need to make
sure that we are not touching/manipulating our validation or test set. Making changes
to our validation set can lead us to have results that are overly optimistic.
This over optimism of the results is called information leakage caused by the sampling
techniques applied to the test set as well.
In a typical holdout method (holdout simply means splitting data into test and train),
over-optimism can be handled by simply resampling the training data, training the models
on this resampled training data and finally testing it on the untouched test data.
But if we want to apply sampling techniques over k folds
(because we want to test our model over the k folds and want to have a
general idea of how it is performing), then we would have to frame the logic
and write the code ourselves. KFoldImblearn does the exact same process for us.
The wrong approach of performing sampling in KFold Cross Validation:
Most of the people would perform up-sampling/down-sampling on the whole dataset, and then would apply K-Fold Cross Validation on the complete dataset. This is a wrong way as this approach is over-optimistic and leads to information leakage. The validation set should always be kept untouched, or in other words no sampling should be applied to the validation set.
The correct approach would be first splitting the data into multiple folds and then applying sampling just to the training data and let the validation data be as is.
The image below states the correct approach of how the dataset should be resampled in a K-fold fashion.
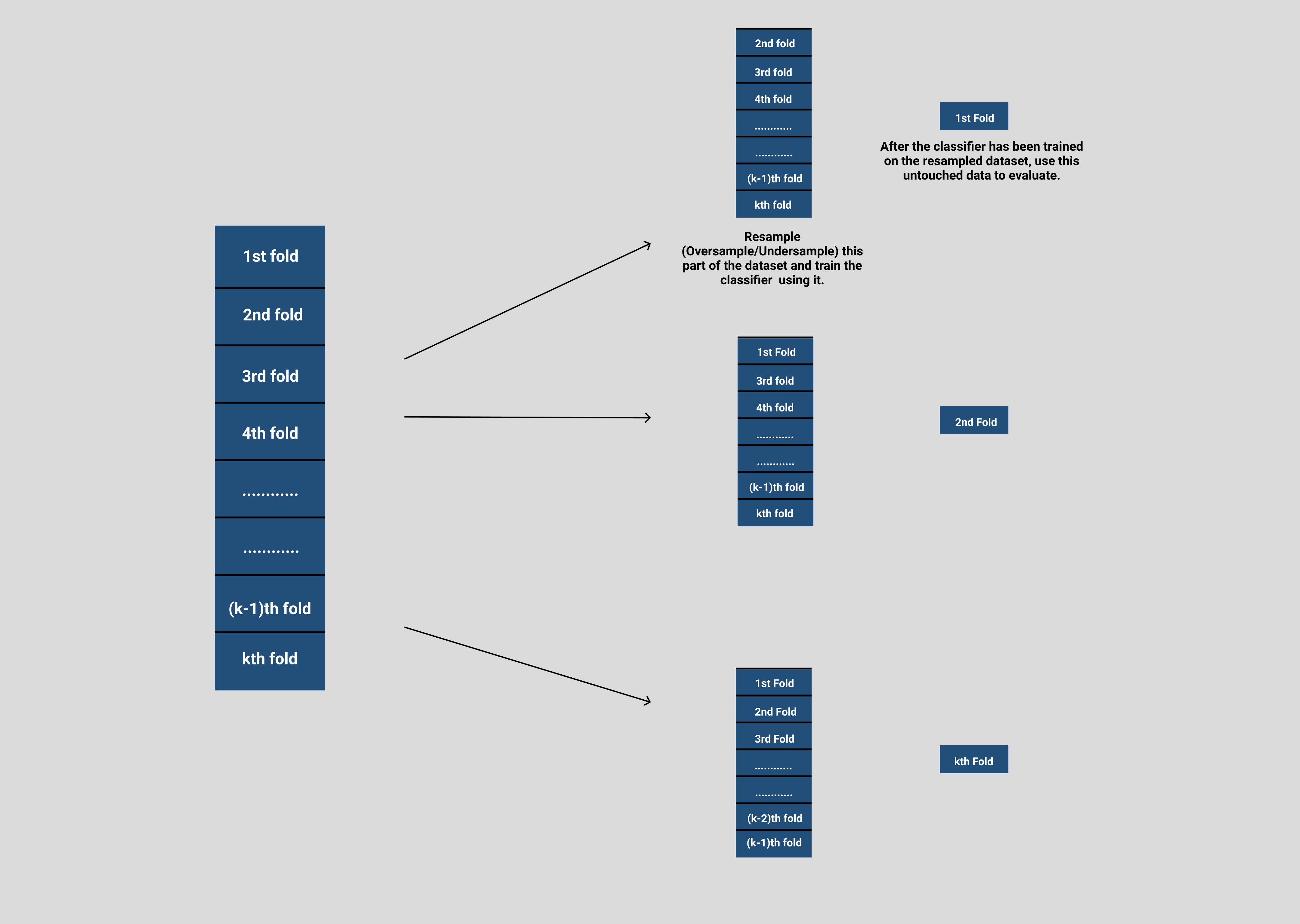
The correct way of performing Cross validation in a K-fold fashion is described above, and this is exactly what KFoldImblearn offers.
KFoldImblearn internally uses joblib to spawn multiple python processes so as to fasten the resampling of various folds in a parallel fashion. The n_jobs parameter is used to specify the number of CPU cores we want to use.
Installation
pip install -i https://test.pypi.org/simple/ Test-KFoldImblearn==1.0.6
If you get any third-party module errors while installing the package such as "could not find a version that satisfies the requirement <package_name>==X.X.X" then simply pip install the package mentioned by using the command below:
pip install <package_name>==X.X.X
And then again try installing install KFoldImblearn
If you get errors relating to imbalanced-learn package, try running this command:
pip install -U imbalanced-learn
after this try pip installing KFoldImblearn again.
Instantiating
from k_fold_imblearn import KFoldImblearn
k_fold_imblearn_object = KFoldImblearn(
sampling_method="RandomOverSampler",
k_folds=10,
k_fold_shuffle=True,
logging_level=10
)
"""
Constructor Parameters
----------
sampling_method : string
The sampling method which is the user wants to apply to the data in a k-fold
fashion. Can take the following values:
"ADASYN", "BorderlineSMOTE", "KMeansSMOTE", "RandomOverSampler", "SMOTE",
"SMOTENC", "SVMSMOTE", "CondensedNearestNeighbour", "EditedNearestNeighbours",
"RepeatedEditedNearestNeighbours", "AllKNN", "InstanceHardnessThreshold", "NearMiss",
"NeighbourhoodCleaningRule", "OneSidedSelection", "RandomUnderSampler", "TomekLinks"
The above sampling methods contain both over and under sampling techniques contained
in the imblearn package.
sampling_params : dict, default=None
A parameter dictionary containing the arguments that will be fed to the sampling_method
mentioned above. For eg. if we decide to choose "SMOTE", then sampling_params will be a
dict of arguments that one will use while instantiating the SMOTE class
k_folds : int, default=5
Number of folds. Must be at least 2.
k_fold_shuffle : bool, default=False
Whether to shuffle the data before splitting into batches.
Note that the samples within each split will not be shuffled.
k_fold_random_state : int, default=None
When `k_fold_shuffle` is True, `k_fold_random_state` affects the ordering of the
indices, which controls the randomness of each fold. Otherwise, this
parameter has no effect.
logging_level : int, default=50
logging level for the custom logger setup for this class.
values that can be assigned: 0, 10, 20, 30, 40 and 50
"""
Complete Example
from k_fold_imblearn import KFoldImblearn
from sklearn.datasets import make_classification
import pandas as pd
from datetime import datetime
# you can use your own X and y here, we have just made dummy data for the sake of example.
X, y = make_classification(n_samples=10000, weights=(0.1, ))
# instantiate KFoldImblearn by simply providing sampling_method and k_folds
k_fold_imblearn_object = KFoldImblearn(
sampling_method="SMOTE",
k_folds=10,
k_fold_shuffle=True,
logging_level=10
)
start_time = datetime.today()
# call the k_fold_fit_resample method by passing dataframe of X, y, verbose and n_jobs
k_fold_imblearn_object.k_fold_fit_resample(pd.DataFrame(X), pd.DataFrame(y), verbose=10, n_jobs=8)
# accessing the re-sampled dataset list
'''
this dataset list is a list of length 'k', each element is a dictionary having 2 keys: "resampled_train_set" and
"validation_set". Both the keys contain a tuple of 2 DataFrames (X and y)
'''
dataset_list = k_fold_imblearn_object.k_fold_dataset_list # classifier are applied to this list of datasets.
# saving the dataset list as a pickle file
k_fold_imblearn_object.serialise_k_datasets_list(filepath="dataset_list.pkl")
end_time = datetime.today()
print(f"Total time taken: {end_time-start_time}")
# printing the object
print(k_fold_imblearn_object)
Output
[Parallel(n_jobs=8)]: Using backend LokyBackend with 8 concurrent workers.
[Parallel(n_jobs=8)]: Done 3 out of 10 | elapsed: 6.6s remaining: 15.6s
[Parallel(n_jobs=8)]: Done 5 out of 10 | elapsed: 6.6s remaining: 6.6s
[Parallel(n_jobs=8)]: Done 7 out of 10 | elapsed: 6.7s remaining: 2.8s
[Parallel(n_jobs=8)]: Done 10 out of 10 | elapsed: 6.7s finished
Total time taken: 0:00:07.035128
KFoldImblearn Instance
Sampling method: SMOTE
Number of folds: 10
Process finished with exit code
References
- Imblearn - https://imbalanced-learn.org/stable/
- Joblib - https://joblib.readthedocs.io/en/latest/
- Pandas - https://pandas.pydata.org/
Release history Release notifications | RSS feed

Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file k_fold_imblearn-1.0.0.tar.gz.
File metadata
- Download URL: k_fold_imblearn-1.0.0.tar.gz
- Upload date:
- Size: 7.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/3.7.3 pkginfo/1.7.0 requests/2.25.1 requests-toolbelt/0.9.1 tqdm/4.59.0 CPython/3.7.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8fe0d4a8600c6d60537bf822eb858257208a6150b284d5ebb9cb06e91c80c8a6
|
|
| MD5 |
2fc8a584c27217681f75e69ce2d2ecfb
|
|
| BLAKE2b-256 |
7a9a138519969cea257cd1f6196aef86a97db9084cd46165c4bd6dd4e5fbabc2
|
File details
Details for the file k_fold_imblearn-1.0.0-py3-none-any.whl.
File metadata
- Download URL: k_fold_imblearn-1.0.0-py3-none-any.whl
- Upload date:
- Size: 9.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.4.1 importlib_metadata/3.7.3 pkginfo/1.7.0 requests/2.25.1 requests-toolbelt/0.9.1 tqdm/4.59.0 CPython/3.7.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0e0613238ea9818f37c506dea6e6dfe544f601218346d99c46fb75e98ad3a546
|
|
| MD5 |
e2d8dae3aaefc3db49c058f0276ade7e
|
|
| BLAKE2b-256 |
158c4ae886629bf16e4f00255b7252ff5408e9f6de7993eacf280d51578c01d7
|







