Data-driven progressive overload

Project description
kaiserlift
A smarter way to choose your next workout: data-driven progressive overload
Why keep doing 10 rep sets? Are you pushing in a smart way?
The core idea I’m exploring is simple: I want a science-based system for determining what’s the best workout to do next if your goal is muscle growth. The foundation of this is progressive overload—the principle that muscles grow when you consistently challenge them beyond what they’re used to.
One of the most effective ways to apply progressive overload is by taking sets to failure. But doing that intelligently requires knowing what you’ve done before. If you have a record of your best sets on a given exercise, you can deliberately aim to push past those PRs. That history becomes your benchmark.
Now, there’s another dimension to this: rep range adaptation. If you always train for, say, 10 reps, your muscles can get used to that rep range—even if you’re still pushing for PRs. Switching things up and going for, say, 20-rep maxes (even with lighter weight) can stimulate growth by forcing the muscle to adapt to new challenges. Then, when you go back to 10 reps, you might find you’ve blown through a plateau.
To make this system more precise, I propose using a one-rep max (1RM) equivalence formula—a way of mapping rep and weight combinations onto a single curve. It gives you a way to compare different PRs across rep ranges. Using that, you can identify which rep range you’re weakest in—meaning, which PR has the lowest 1RM equivalent. That’s where your next opportunity lies.
For the 1 rep max we use The Epley Formula:
$$
\text{estimated_1rm} = \text{weight} \times \left(1 + \frac{\text{reps}}{30.0}\right)
$$
Here's how to operationalize it:
- Collect your full workout history for a given exercise—every weight and rep combo you’ve done.
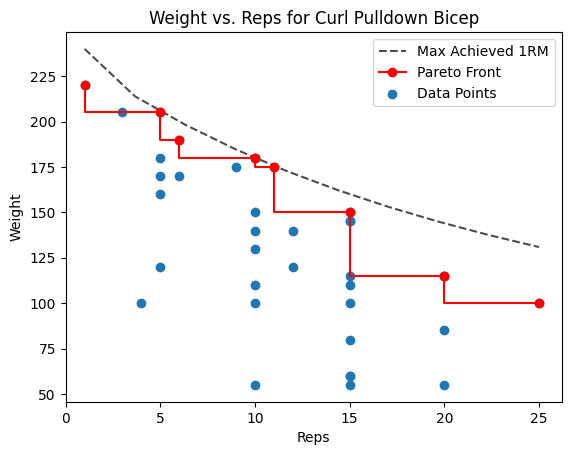
- Calculate the Pareto front of that data. This is the set of “non-dominated” performances: the heaviest weights at each rep range that can’t be beaten in both weight and reps at the same time.
- For each point on the Pareto front, compute the 1RM equivalent using a decay-style formula.
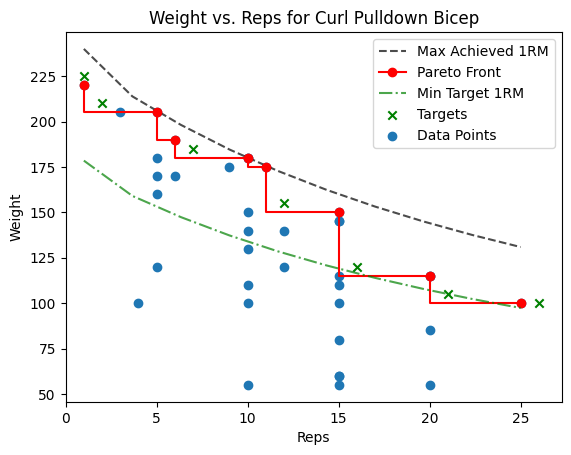
- Identify the Pareto front point with the lowest 1RM equivalent—that’s your weakest spot.
- Now, generate a “next step” PR target: a new set that just barely beats that weakest point, by the smallest reasonable margin (e.g., +1 rep or +5 lbs). That becomes your next workout goal.
This method gives you a structured, data-driven way to chase the easiest possible PR—which is still a PR. That keeps you progressing without burning out.
You can extend this concept across exercises too. Let’s say it’s biceps day. Instead of defaulting to the same curl variation you always do, you can rotate in a bicep exercise you haven’t done recently in order to assure a new PR. This introduces variability, which is another powerful way to drive adaptation while still targeting the same muscle group.
The end goal here is simple: use your data to intelligently apply progressive overload, break through plateaus, and train more effectively—with zero guesswork.
To this end I also made an HTML page that can organize these in a text searchable way and can be accessed from my phone at the gym. This table of taget sets can be ordered by 1RPM and so easilly parsed.
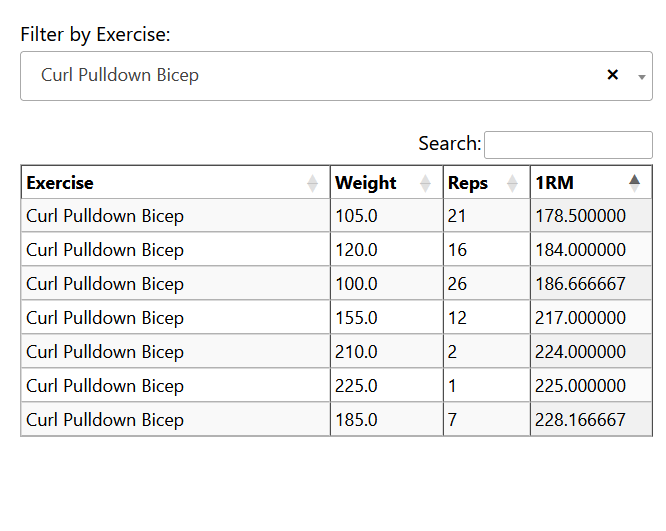
How to use
Current needs for the data format in a .csv
Date,Exercise,Category,Weight,Reps
2022-09-14,Flat Barbell Bench Press,Chest,45.0,10""
2022-09-14,Flat Barbell Bench Press,Chest,65.0,15""
2022-09-14,Dumbbell Curl,Biceps,35.0,10""
2022-09-14,Dumbbell Curl,Biceps,40.0,1,""
2022-09-25,Parallel Bar Triceps Dip,Triceps,1.0,10""
2022-09-25,Parallel Bar Triceps Dip,Triceps,1.0,12""
Installation
> pip install kaiserlift
Import data and run the pareto calculations:
from kaiserlift import (
import_fitnotes_csv,
highest_weight_per_rep,
df_next_pareto,
)
csv_files = glob.glob("*.csv")
df = import_fitnotes_csv(csv_files)
df_pareto = highest_weight_per_rep(df)
df_targets = df_next_pareto(df_pareto)
Plotting the data:
from kaiserlift import plot_df
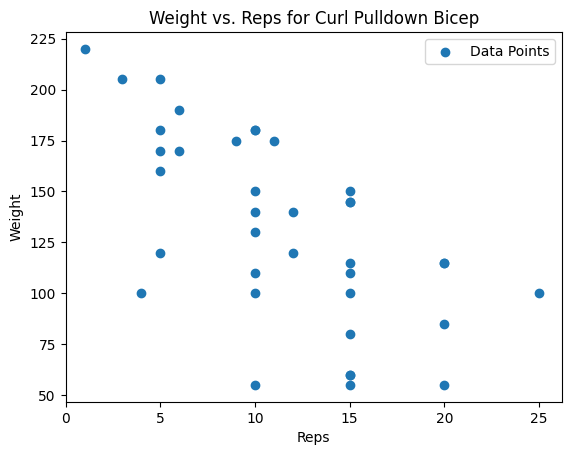
# Simple view of all data (only the blue dots)
fig = plot_df(df, Exercise="Dumbbell Curl")
fig.savefig("build/Dumbbell_Curl_Raw.png")
# View with pareto front plotted (the red line)
fig = plot_df(df, df_pareto=df_pareto, Exercise="Dumbbell Curl")
fig.savefig("build/Dumbbell_Curl_Pareto.png")
# View with pareto and targets (the green x's)
fig = plot_df(df, df_pareto=df_pareto, df_targets=df_targets, Exercise="Dumbbell Curl")
fig.savefig("build/Dumbbell_Curl_Pareto_and_Targets.png")
Generate views:
from kaiserlift import (
print_oldest_excercise,
gen_html_viewer,
)
print_oldest_excercise(df)
gen_html_viewer(df)
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file kaiserlift-0.1.12.tar.gz.
File metadata
- Download URL: kaiserlift-0.1.12.tar.gz
- Upload date:
- Size: 13.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
95f36a048e99a1691cba7088821b98976902b42ee56f88f1d26d6688f524c41c
|
|
| MD5 |
7c0d0821685bfece4acde88e660125c4
|
|
| BLAKE2b-256 |
d67044defa645fd3106e062914ff752f130c29f7d18f0641e3b27c26a882e057
|
File details
Details for the file kaiserlift-0.1.12-py3-none-any.whl.
File metadata
- Download URL: kaiserlift-0.1.12-py3-none-any.whl
- Upload date:
- Size: 11.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0a398e0b248729de2da4ebee73f7847f2ab8e930fb50306598fd779af94536df
|
|
| MD5 |
ee719e48c3a4a5c6e8af7ba1afb0cbf7
|
|
| BLAKE2b-256 |
af200a960309ed0b3bca16fc865738aee76a823ca993f28d710fff3f7ce7eff1
|







