Fast, Conditioned KAN

Project description
KANditioned: Fast Training of Kolmogorov-Arnold Networks via Dynamic Input-Indexed Sparse Matrix Multiplication
Kolmogorov-Arnold Networks (KANs) training and inference are accelerated by orders of magnitude through exploiting the structure of the uniform linear (C⁰) B-spline (see Fig. 1). Because the intervals are uniform, evaluating spline(x) reduces to a constant-time index calculation, followed by looking up the two relevant control points and linearly interpolating between them. This contrasts with the summation over basis functions typically seen in splines, reducing the amount of computation required and enabling effectively sublinear scaling across the control points dimension.
Going one step further, we reinterpret this lookup interpolation approach as a dynamic input-indexed sparse-dense matrix multiplication (SpMM), squeezing out additional performance through cuSPARSE, a highly optimized CUDA library. This computational approach falls within the framework of conditional computation, albeit at a more granular level compared to Mixture of Experts (MoEs), the most popular form of conditional computation.
Install
pip install kanditioned
Usage
[!IMPORTANT]
It is highly recommended to use this layer with torch.compile, which may provide very significant speedups, in addition to a normalization layer before each KANLayer. Custom kernel is coming sometimes later. Stay tuned.
from kanditioned.kan_layer import KANLayer
layer = KANLayer(in_features=3, out_features=3, init="random_normal", num_control_points=8, spline_width=4.0)
layer.visualize_all_mappings(save_path="kan_mappings.png")
Arguments
in_features (int)
Size of each input sample.
out_features (int)
Size of each output sample.
init (str)
Initialization method:
-
"random_normal"Each spline initialized to a linear line with its slope drawn from a normal distribution, then normalized so each “neuron” has unit weight norm.
-
"identity"Each spline initialized to a linear line with slope one (requires
in_features == out_features). Output initially equals input. -
"zero"Each spline initialized to a linear line with slope zero.
num_control_points (int, default = 32)
Number of uniformly spaced control points per input feature.
spline_width (float, default = 4.0)
Domain the spline control points are uniformly defined on: [-spline_width / 2, spline_width / 2]. Outside the domain, the spline will linearly extrapolate.
impl (str, default = "embedding_bag")
Implementation choice:
-
"embedding_bag"Much faster for inference with
torch.compileenabled, or for either training or inference withouttorch.compile. -
"embedding"Appears to be somewhat faster when training with
torch.compileenabled.
[!NOTE] Experiment with both to achieve peak performance.
Methods
visualize_all_mappings(save_path: str, optional)
Plots the shape of each spline along with its corresponding input and output feature.
Figure
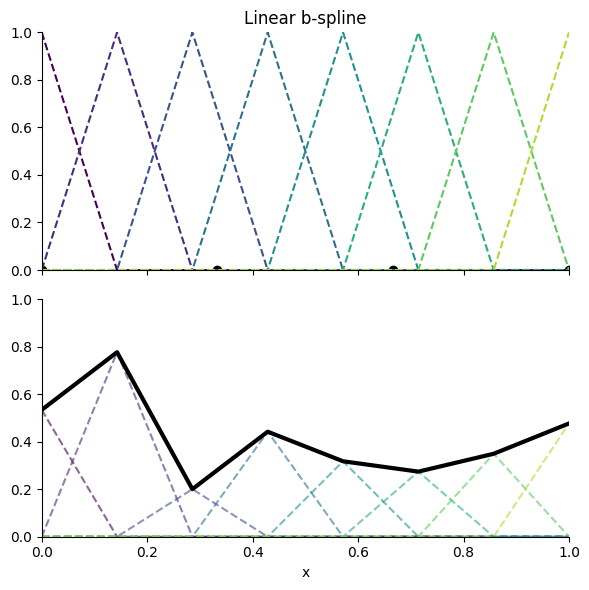
Figure 1. Linear B-spline example (each triangle-like shape is a basis):
Roadmap (more like TODO list XD)
Use F.embedding_bagAdd CSR sparse-dense matmul implementation- Check out other sparse storage formats for sparse matmul
- Add support for index select with lerp implementation and investigate index_add
- Update doc for variant and other new parameters introduced
- Support sparse gradients
- Update package with cleaned up, efficient Discrete Cosine Transform (with rank-2 correction) and parallel scan (prefix sum) parameterizations.
- Both provide isotropic O(1) condition scaling for the discrete second difference penalty, as opposed to O(N^4) conditioning for the naive B-spline parameterization. This only matters if you care about regularization.
- May add linearDCT variant first. Although it's O(N^2), it's more parallelized and optimized on GPU for small N since it's essentially a matmul with weight being a DCT matrix
- Proper baselines against MLP and various other KAN implementations on backward and forward passes
- Add sorting on indices and unsorting as an option (potentially radix sort, which is common optimization on embedding) to improve computational time through global memory "coalesced" access
- Add in feature-major input variant
- May change to either unfold or as_strided (slight performance improvement)
- Benchmark against NanoGPT
- Make announcements on various platforms
- Run benchmarks and further optimize memory locality
- Feature-major input variant versus batch-major input variant
- Interleaved indices [l1, u1, l2, u2, ...] versus stacked indices [l1, l2, ..., u1, u2, ...]
- Add optimized Triton kernel
- Update visualize_all_mappings method to something like .plot with option for plotting everything
- Add a nice looking figure
- Check out https://github.com/NVIDIA/cuEmbed
- Research adding Legendre polynomials parameterization
- Preliminary: does not seem to offer much benefits or have isotropic penalty conditioning
- Experiment with inputs bucketing instead of index-based calculation
- Add similar papers in
- Polish writing
Open To Collaborators. Contributions Are Welcomed!
LICENSE
This project is licensed under the Apache License 2.0.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file kanditioned-1.0.4.tar.gz.
File metadata
- Download URL: kanditioned-1.0.4.tar.gz
- Upload date:
- Size: 10.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a86a150c385b499cf1a7d358a60df84473a1d489f4ad48cebe6b0f196c282743
|
|
| MD5 |
031a88e5714d929463aa3bb6a96fece7
|
|
| BLAKE2b-256 |
1457b25f161655a467d1b5a88c35541b09912f360604c57a3d3d8ff3783b3791
|
File details
Details for the file kanditioned-1.0.4-py3-none-any.whl.
File metadata
- Download URL: kanditioned-1.0.4-py3-none-any.whl
- Upload date:
- Size: 11.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.2
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
61e21a15820ced7800e91bbf1a0a4ab726947cf3460962814f55a6434349d37c
|
|
| MD5 |
98246efdfc2c0339dfea21fddac0042c
|
|
| BLAKE2b-256 |
c587a7ab08144f10f60b4f855b299276eb302f80f98a08384fd469c87ce6f1e3
|







