Neptune.ai integration with Kedro

Project description
Kedro-Neptune plugin
Main docs page for Kedro-Neptune plugin
What will you get with this integration?
Kedro is a popular open-source project that helps standardize ML workflows. It gives you a clean and powerful pipeline abstraction where you put all your ML code logic.
Kedro-Neptune plugin lets you have all the benefits of a nicely organized kedro pipeline with a powerful user interface built for ML metadata management that lets you:
- browse, filter, and sort your model training runs
- compare nodes and pipelines on metrics, visual node outputs, and more
- display all pipeline metadata including learning curves for metrics, plots, and images, rich media like video and audio or interactive visualizations from Plotly, Altair, or Bokeh
- and do whatever else you would expect from a modern ML metadata store
Installation
Before you start, make sure that:
- You have
Python 3.6+in your system, - You are already a registered user so that you can log metadata to your private projects.
- You have your Neptune API token set to the
NEPTUNE_API_TOKENenvironment variable.
Install neptune-client, kedro, and kedro-neptune
Depending on your operating system open a terminal or CMD and run this command. All required libraries are available via pip and conda:
pip install neptune-client kedro kedro-neptune
For more, see installing neptune-client.
Quickstart
|
|
|
|---|


This quickstart will show you how to:
- Connect Neptune to your Kedro project
- Log pipeline and dataset metadata to Neptune
- Add explicit metadata logging to a node in your pipeline
- Explore logged metadata in the Neptune UI.
Before you start
Step 1: Create a Kedro project from "pandas-iris" starter
- Go to your console and create a Kedro starter project "pandas-iris"
kedro new --starter=pandas-iris
- Follow instructions and choose a name for your Kedro project. For example, "Great-Kedro-Project"
- Go to your new Kedro project directory
If everything was set up correctly you should see the following directory structure:
Great-Kedro-Project # Parent directory of the template
├── conf # Project configuration files
├── data # Local project data (not committed to version control)
├── docs # Project documentation
├── logs # Project output logs (not committed to version control)
├── notebooks # Project related Jupyter notebooks (can be used for experimental code before moving the code to src)
├── README.md # Project README
├── setup.cfg # Configuration options for `pytest` when doing `kedro test` and for the `isort` utility when doing `kedro lint`
├── src # Project source code
├── pipelines
├── data_science
├── nodes.py
├── pipelines.py
└── ...
You will use nodes.py and pipelines.py files in this quickstart.
Step 2: Initialize kedro-neptune plugin
- Go to your Kedro project directory and run
kedro neptune init
The command line will ask for your Neptune API token
- Input your Neptune API token:
- Press enter if it was set to the
NEPTUNE_API_TOKENenvironment variable - Pass a different environment variable to which you set your Neptune API token. For example
MY_SPECIAL_NEPTUNE_TOKEN_VARIABLE - Pass your Neptune API token as a string
- Press enter if it was set to the
The command line will ask for your Neptune project name
- Input your Neptune project name:
- Press enter if it was set to the
NEPTUNE_PROJECTenvironment variable - Pass a different environment variable to which you set your Neptune project name. For example
MY_SPECIAL_NEPTUNE_PROJECT_VARIABLE - Pass your project name as a string in a format
WORKSPACE/PROJECT
- Press enter if it was set to the
If everything was set up correctly you should:
- see the message: "kedro-neptune plugin successfully configured"
- see three new files in your kedro project:
- Credentials file:
YOUR_KEDRO_PROJECT/conf/local/credentials_neptune.yml - Config file:
YOUR_KEDRO_PROJECT/conf/base/neptune.yml - Catalog file:
YOUR_KEDRO_PROJECT/conf/base/neptune_catalog.yml
- Credentials file:
You can always go to those files and change the initial configuration.
Step 3: Add Neptune logging to a Kedro node
- Go to a pipeline node src/KEDRO_PROJECT/pipelines/data_science/nodes.py
- Import Neptune client toward the top of the nodes.py
import neptune.new as neptune
- Add neptune_run argument of type
neptune.run.Handlerto thereport_accuracyfunction
def report_accuracy(predictions: np.ndarray, test_y: pd.DataFrame,
neptune_run: neptune.run.Handler) -> None:
...
You can treat neptune_run like a normal Neptune Run and log any ML metadata to it.
Important
You have to use a special string "neptune_run" to use the Neptune Run handler in Kedro pipelines.
- Log metrics like accuracy to neptune_run
def report_accuracy(predictions: np.ndarray, test_y: pd.DataFrame,
neptune_run: neptune.run.Handler) -> None:
target = np.argmax(test_y.to_numpy(), axis=1)
accuracy = np.sum(predictions == target) / target.shape[0]
neptune_run['nodes/report/accuracy'] = accuracy * 100
You can log metadata from any node to any Neptune namespace you want.
- Log images like a confusion matrix to neptune_run
def report_accuracy(predictions: np.ndarray, test_y: pd.DataFrame,
neptune_run: neptune.run.Handler) -> None:
target = np.argmax(test_y.to_numpy(), axis=1)
accuracy = np.sum(predictions == target) / target.shape[0]
fig, ax = plt.subplots()
plot_confusion_matrix(target, predictions, ax=ax)
neptune_run['nodes/report/confusion_matrix'].upload(fig)
Note
You can log metrics, text, images, video, interactive visualizations, and more.
See a full list of What you can log and display in Neptune.
Step 4: Add Neptune Run handler to the Kedro pipeline
- Go to a pipeline definition, src/KEDRO_PROJECT/pipelines/data_science/pipelines.py
- Add neptune_run Run handler as an input to the
reportnode
node(
report_accuracy,
["example_predictions", "example_test_y", "neptune_run"],
None,
name="report"),
Step 5: Run Kedro pipeline
Go to your console and execute your Kedro pipeline
kedro run
A link to the Neptune Run associated with the Kedro pipeline execution will be printed to the console.
Step 6: Explore results in the Neptune UI
- Click on the Neptune Run link in your console or use an example link
https://app.neptune.ai/common/kedro-integration/e/KED-632
- Go to the kedro namespace where metadata about Kedro pipelines are logged (see how to change the default logging location)
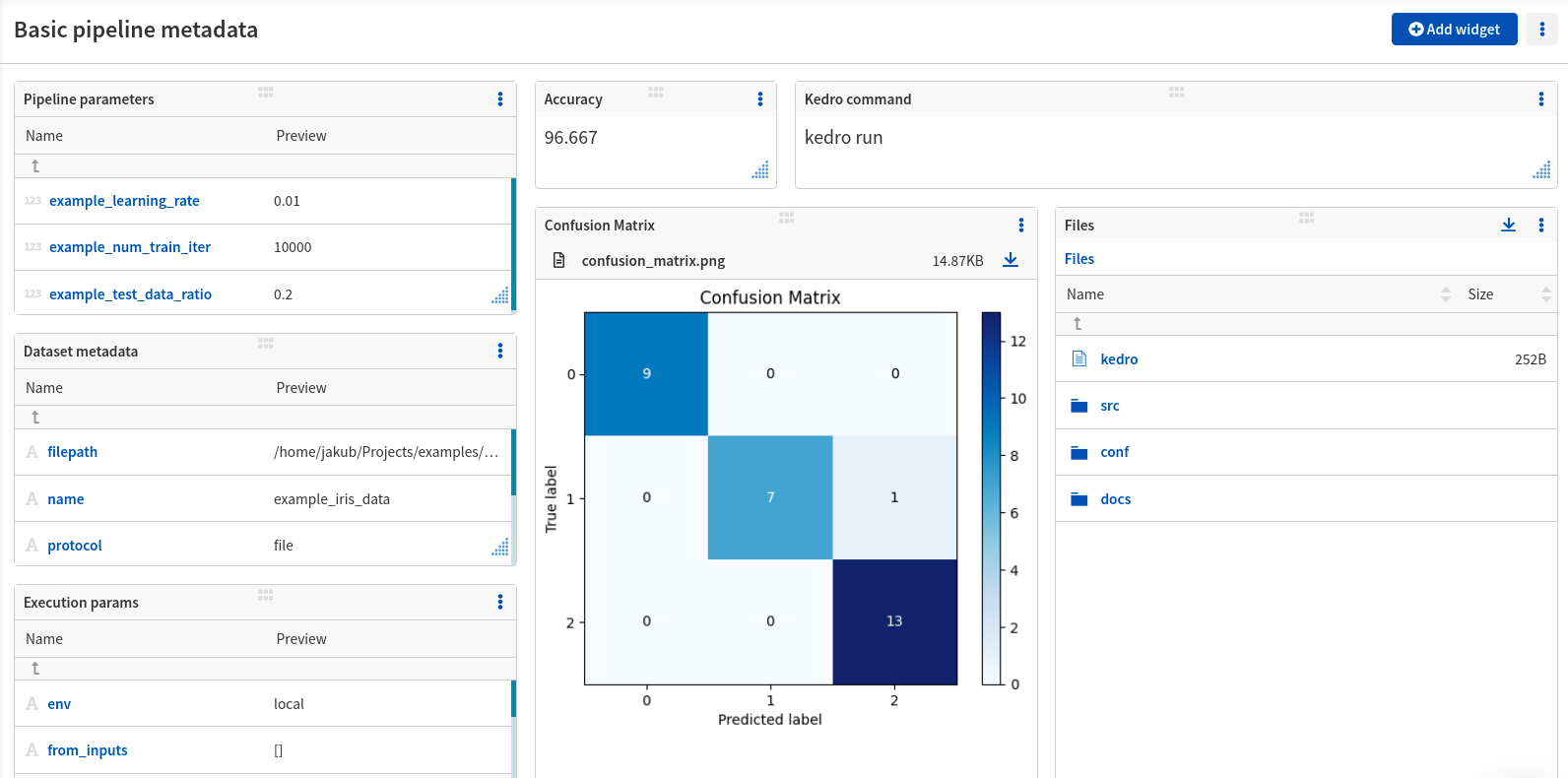
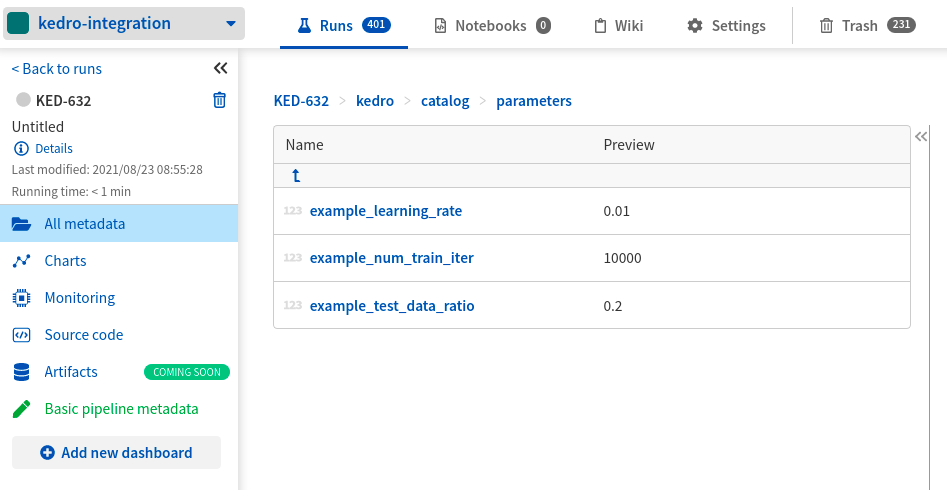
- See pipeline and node parameters in kedro/catalog/parameters
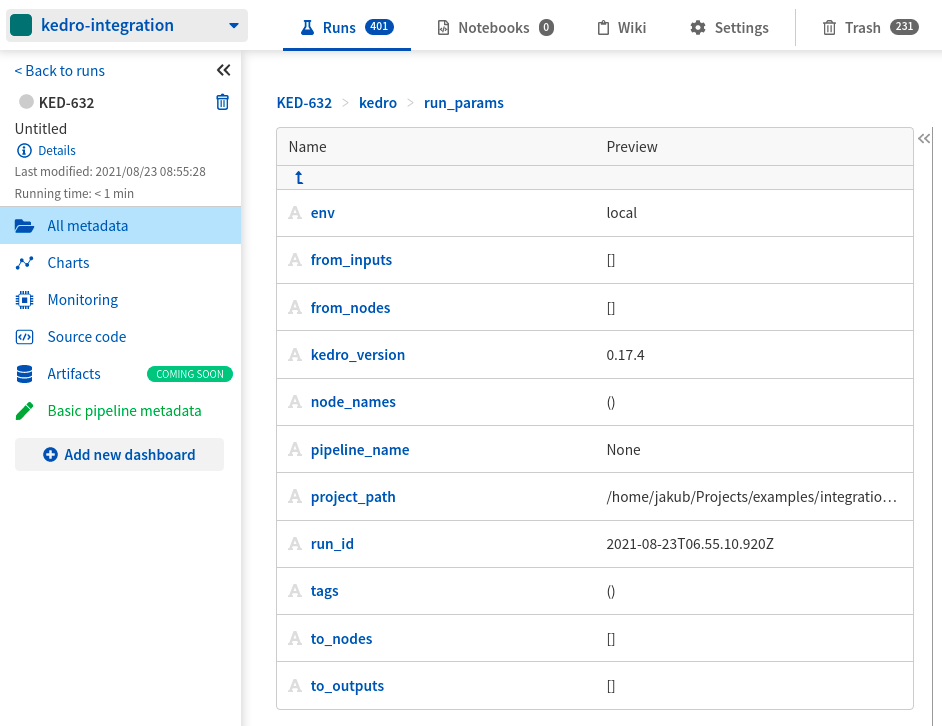
- See execution parameters in kedro/run_params
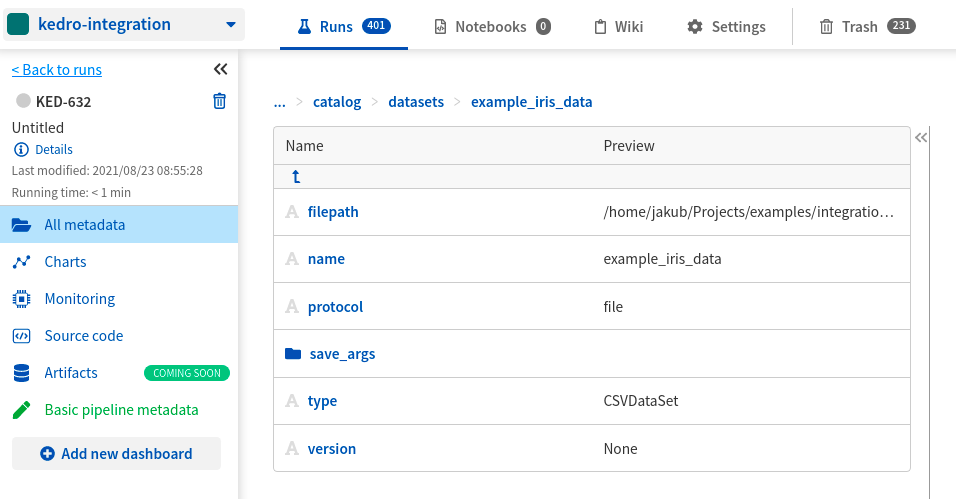
- See metadata about the datasets in kedro/catalog/datasets/example_iris_data
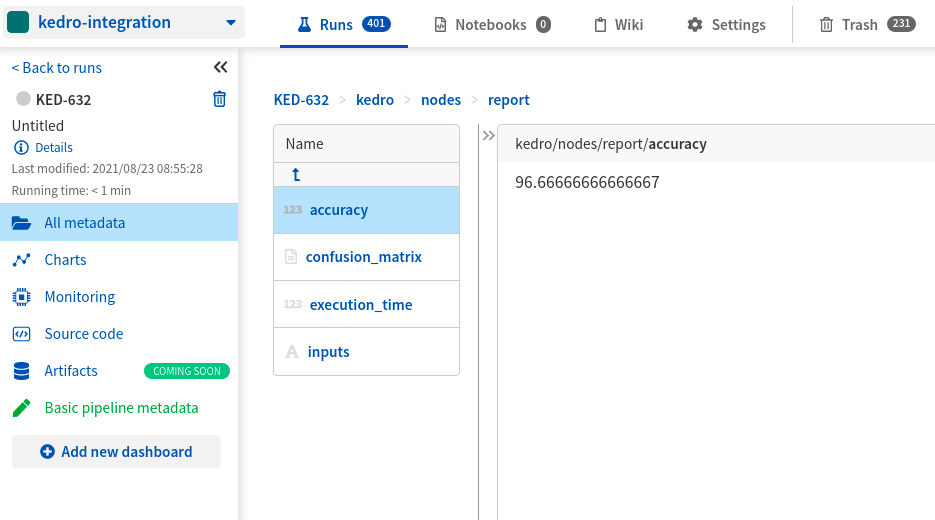
- See the metrics (accuracy) you logged explicitly in the kedro/nodes/report/accuracy
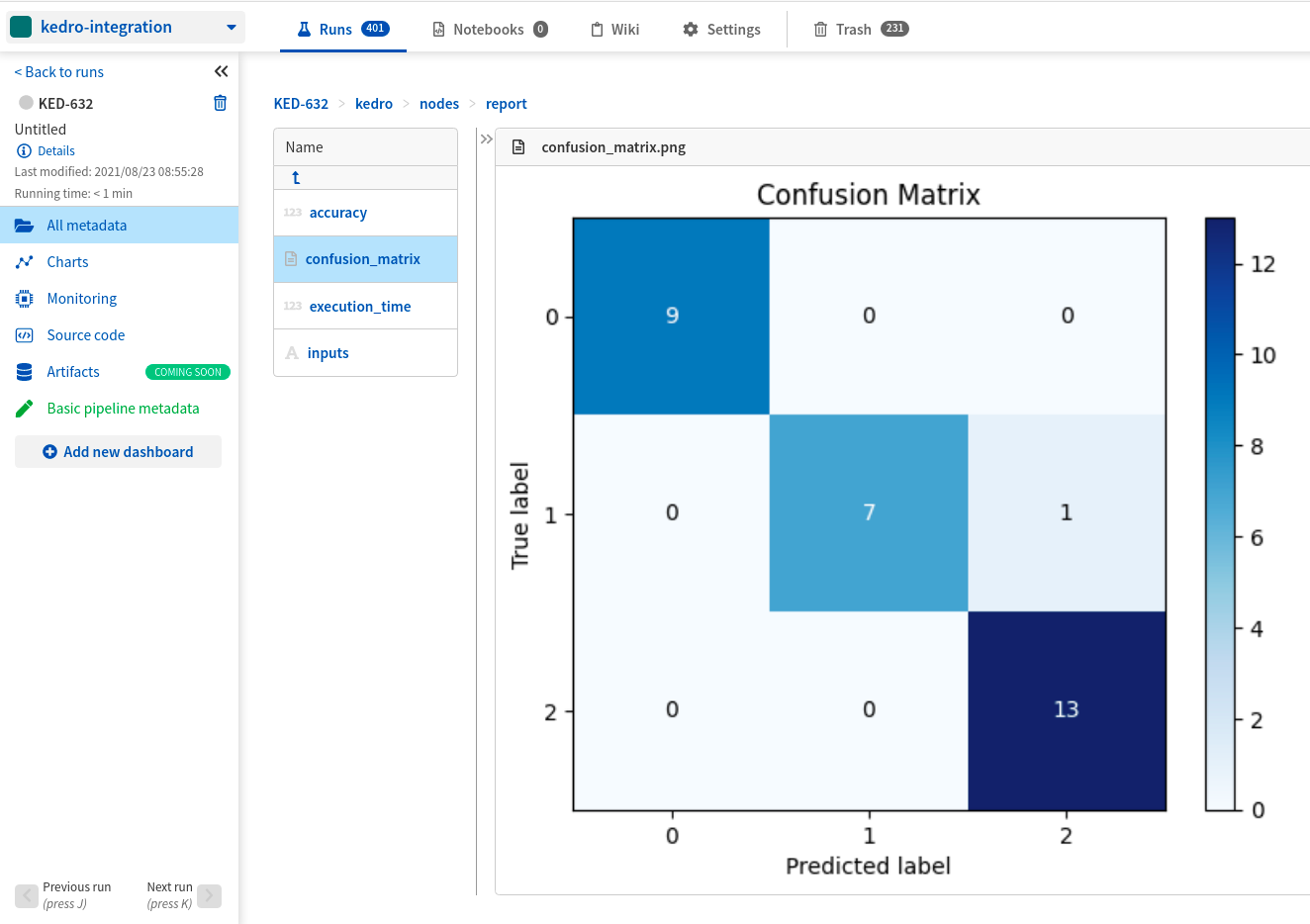
- See charts (confusion matrix) you logged explicitly in the kedro/nodes/report/confusion_matrix
See also
- Main docs page for Kedro-Neptune plugin
- How to Compare Kedro pipelines
- How to Compare results between Kedro nodes
- How to Display Kedro node metadata and outputs
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file kedro-neptune-0.0.6.tar.gz.
File metadata
- Download URL: kedro-neptune-0.0.6.tar.gz
- Upload date:
- Size: 38.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/3.5.0 importlib_metadata/4.8.1 pkginfo/1.7.1 requests/2.26.0 requests-toolbelt/0.9.1 tqdm/4.62.3 CPython/3.8.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a3f886e49469c5e489791f93faed96cb0064f24f04228dcea0849198584b68a2
|
|
| MD5 |
efe57347f3818474b215092303ab0058
|
|
| BLAKE2b-256 |
7629a2485efcae62ed71f2b2526f8158ed38404eae7793835df2cc1f616227b5
|







