Common data preprocessing and visualisation functions.

Project description






klib is a Python library for importing, cleaning, analyzing and preprocessing data. Explanations on key functionalities can be found on Medium / TowardsDataScience and in the examples section. Additionally, there are great introductions and overviews of the functionality on PythonBytes or on YouTube (Data Professor).
Installation
Use the package manager pip to install klib.


pip install -U klib
Alternatively, to install this package with conda run:


conda install -c conda-forge klib
Usage
import klib
import pandas as pd
df = pd.DataFrame(data)
# klib.describe - functions for visualizing datasets
- klib.cat_plot(df) # returns a visualization of the number and frequency of categorical features
- klib.corr_mat(df) # returns a color-encoded correlation matrix
- klib.corr_plot(df) # returns a color-encoded heatmap, ideal for correlations
- klib.corr_interactive_plot(df, split="neg").show() # returns an interactive correlation plot using plotly
- klib.dist_plot(df) # returns a distribution plot for every numeric feature
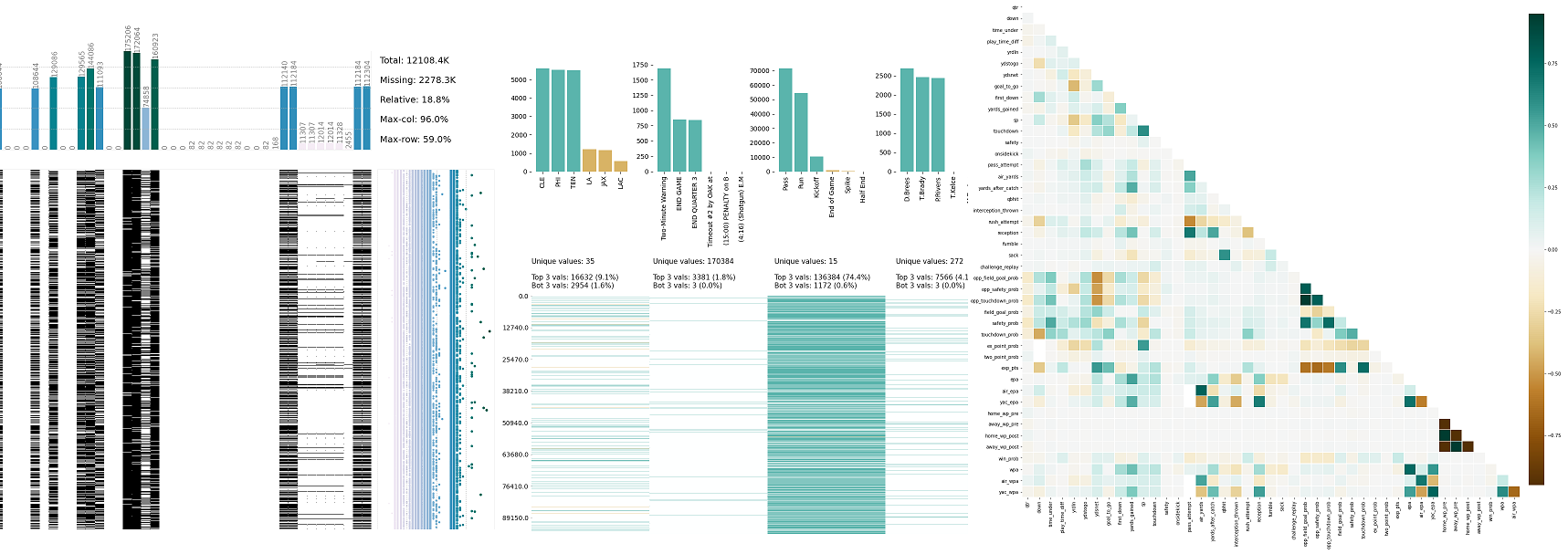
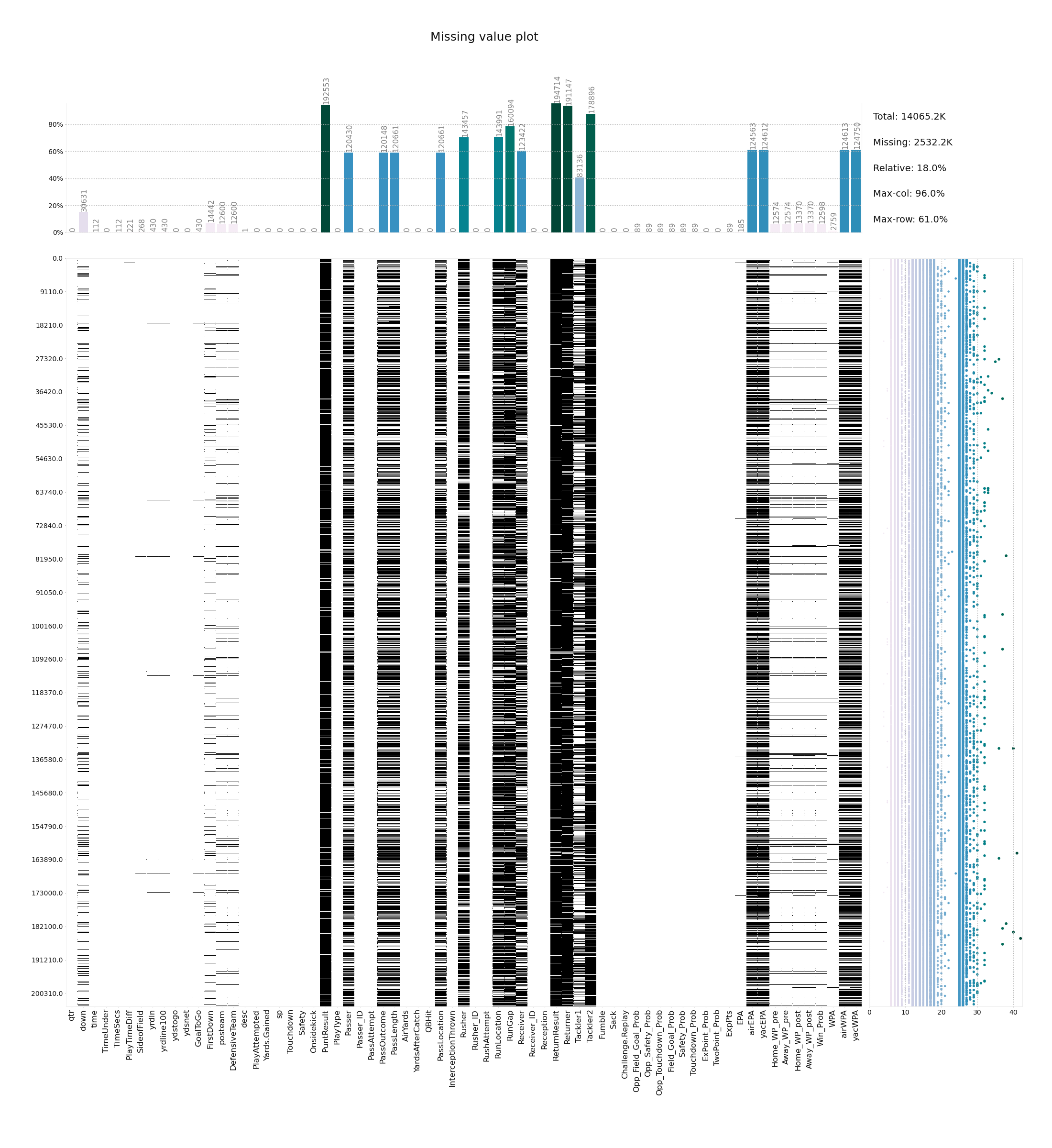
- klib.missingval_plot(df) # returns a figure containing information about missing values
# klib.clean - functions for cleaning datasets
- klib.data_cleaning(df) # performs datacleaning (drop duplicates & empty rows/cols, adjust dtypes,...)
- klib.clean_column_names(df) # cleans and standardizes column names, also called inside data_cleaning()
- klib.convert_datatypes(df) # converts existing to more efficient dtypes, also called inside data_cleaning()
- klib.drop_missing(df) # drops missing values, also called in data_cleaning()
- klib.mv_col_handling(df) # drops features with high ratio of missing vals based on informational content
- klib.pool_duplicate_subsets(df) # pools subset of cols based on duplicates with min. loss of information
Examples
Find all available examples as well as applications of the functions in klib.clean() with detailed descriptions here.
klib.missingval_plot(df) # default representation of missing values in a DataFrame, plenty of settings are available
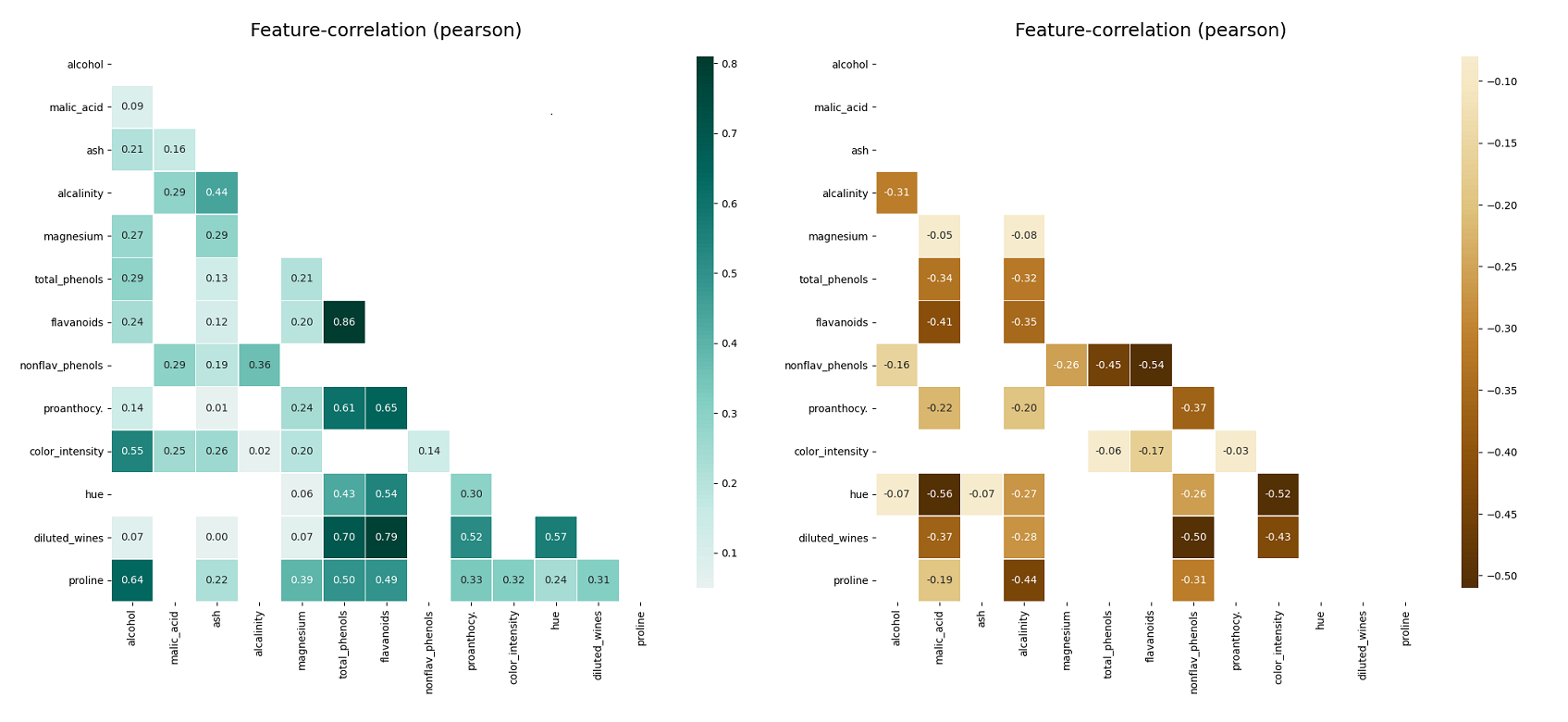
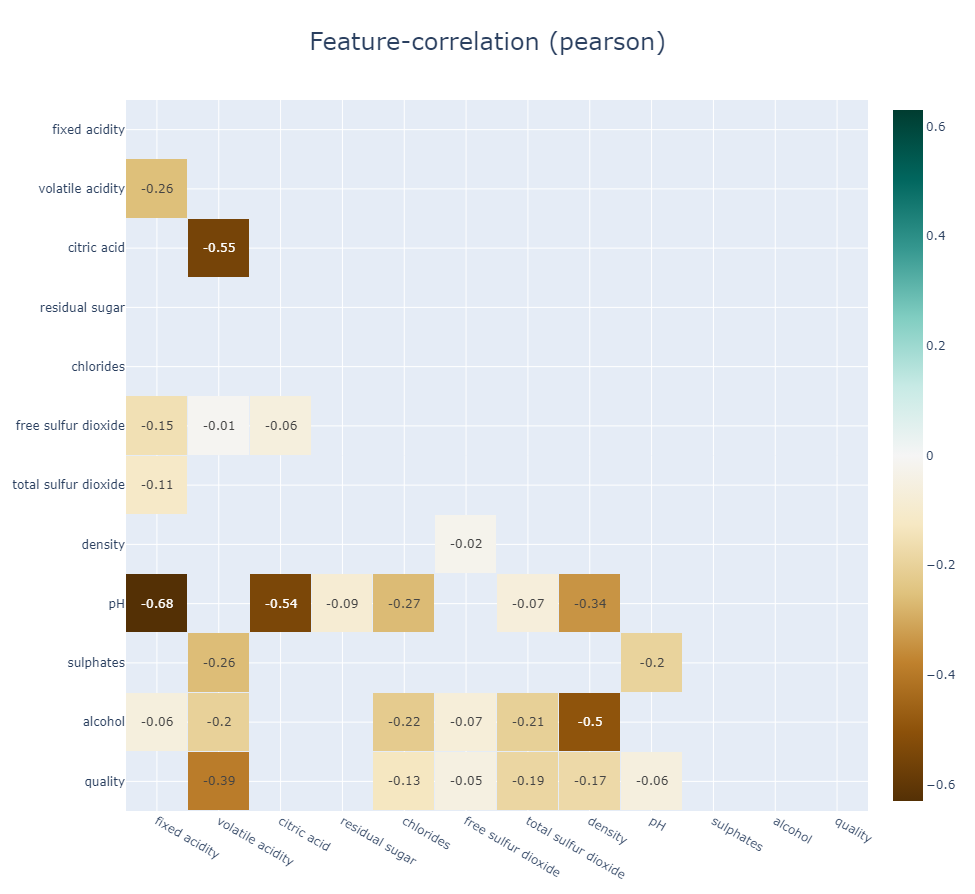
klib.corr_plot(df, split='pos') # displaying only positive correlations, other settings include threshold, cmap...
klib.corr_plot(df, split='neg') # displaying only negative correlations
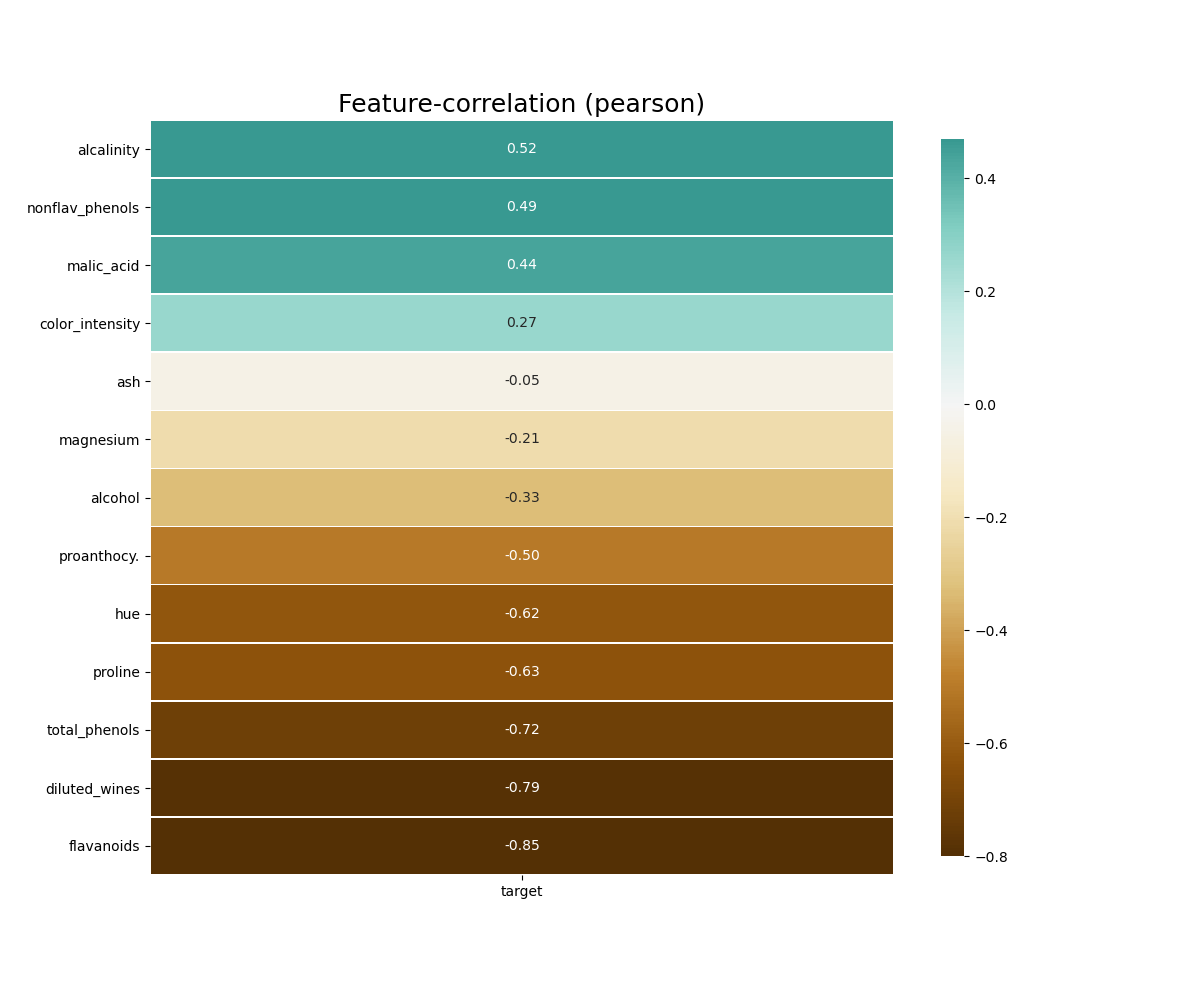
klib.corr_plot(df, target='wine') # default representation of correlations with the feature column
klib.corr_interactive_plot(df, split="neg").show()
# The interactive plot has the same parameters as the corr_plot, but with additional Plotly heatmap graph object kwargs.
klib.corr_interactive_plot(df, split="neg", zmax=0)
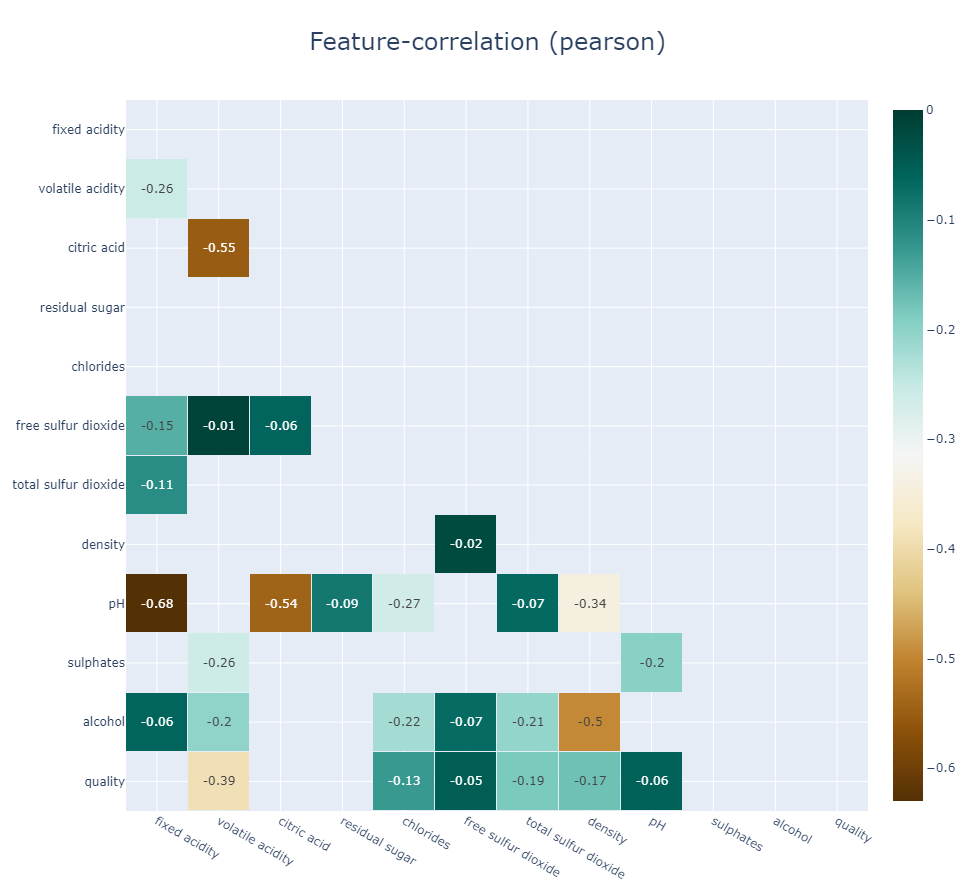
#Since corr_interactive_plot returns a Graph Object Figure, it supports the update_layout chain method.
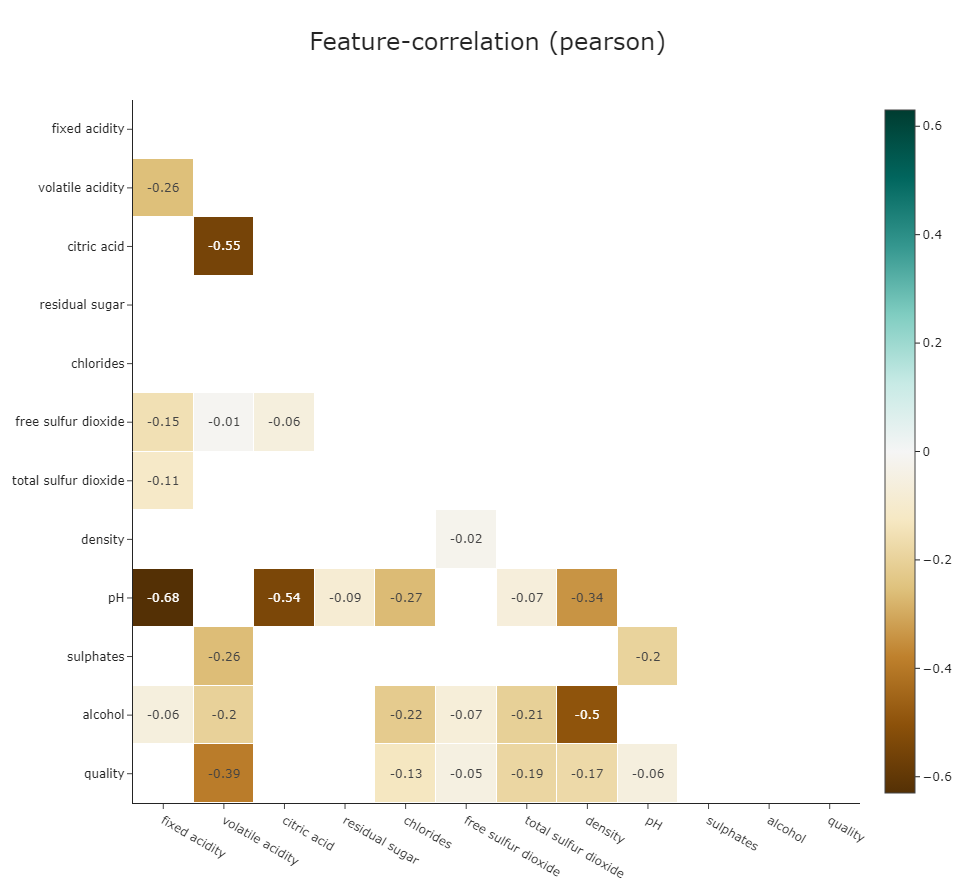
klib.corr_interactive_plot(wine, split="neg").update_layout(template="simple_white")
klib.dist_plot(df) # default representation of a distribution plot, other settings include fill_range, histogram, ...

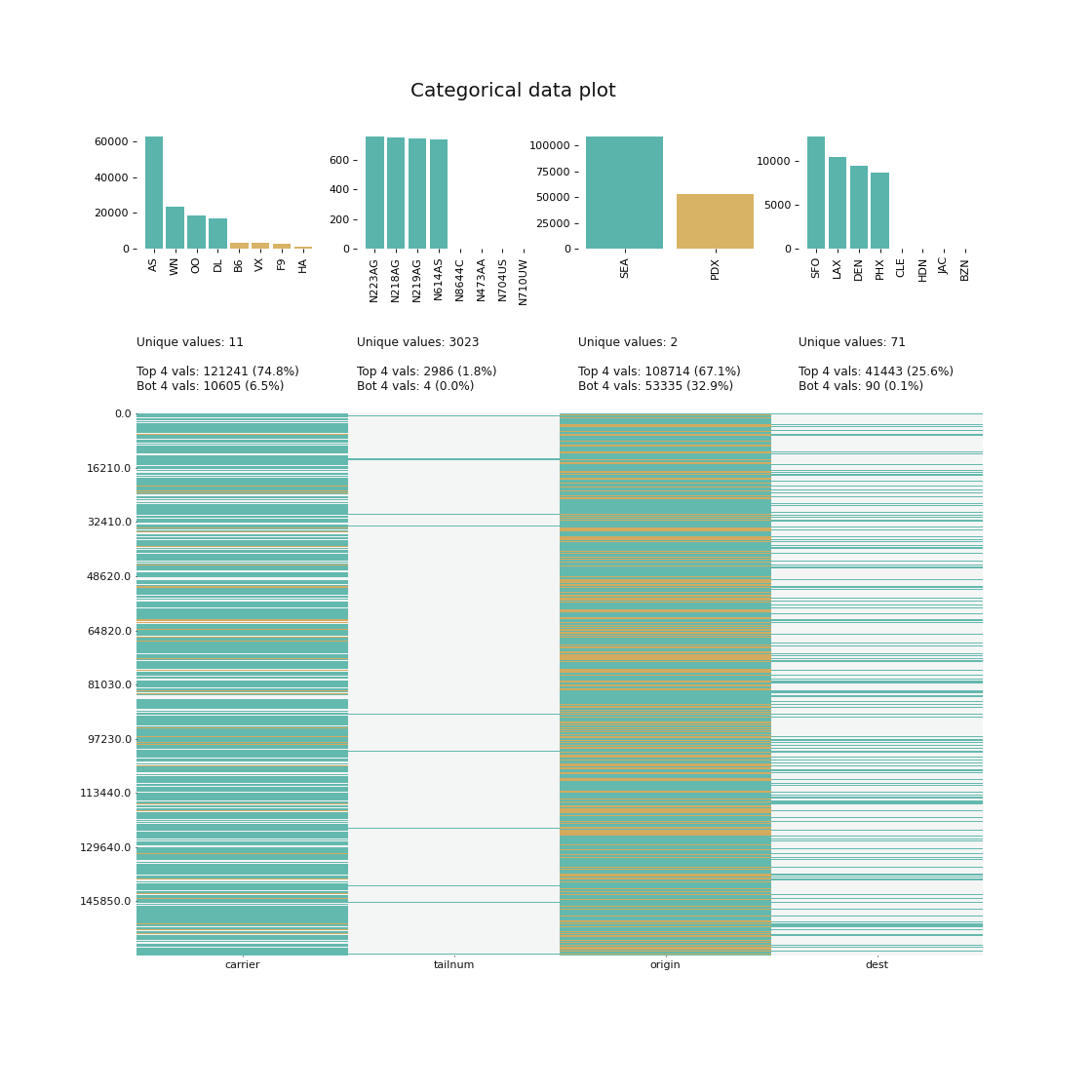
klib.cat_plot(data, top=4, bottom=4) # representation of the 4 most & least common values in each categorical column
Further examples, as well as applications of the functions in klib.clean() can be found here.
Contributing

Pull requests and ideas, especially for further functions are welcome. For major changes or feedback, please open an issue first to discuss what you would like to change.
License
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file klib-1.4.0.tar.gz.
File metadata
- Download URL: klib-1.4.0.tar.gz
- Upload date:
- Size: 40.2 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: uv/0.9.28 {"installer":{"name":"uv","version":"0.9.28","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6c41034605b13097806d3977426283171643dd66f033a9e3529b96dc698f475c
|
|
| MD5 |
6dc2f530e327cba2b82df1e4bfaf38e3
|
|
| BLAKE2b-256 |
d4769fd9c515a2b583ad77574dffdc01cf9d8aad7b1ce01739edf40763fbdb9f
|
File details
Details for the file klib-1.4.0-py3-none-any.whl.
File metadata
- Download URL: klib-1.4.0-py3-none-any.whl
- Upload date:
- Size: 23.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: uv/0.9.28 {"installer":{"name":"uv","version":"0.9.28","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
94914417aa50677ee80eec604600375ad085f383d285e6a5d4f73ba52dd234c0
|
|
| MD5 |
f47c3243ed3413ddaee83cf3821f2a1c
|
|
| BLAKE2b-256 |
f4cb0fc130f39fb81b67ff29c5bac3acc3b6bcbfe468fb4b6adf3606ba9d8fbb
|







