Production-grade document chunking library for RAG systems - Rust-powered Python library

Project description
Krira Augment Presents Krira Chunker(beta)
High-Performance Rust Chunking Engine for RAG Pipelines
Process gigabytes of text in seconds. 40x faster than LangChain with O(1) memory usage.
Installation
pip install krira-augment
Quick Usage
from krira_augment.krira_chunker import Pipeline, PipelineConfig, SplitStrategy
config = PipelineConfig(
chunk_size=512,
strategy=SplitStrategy.SMART,
clean_html=True,
clean_unicode=True,
)
pipeline = Pipeline(config=config)
result = pipeline.process("sample.csv", output_path="output.jsonl")
print(result)
print(f"Chunks Created: {result.chunks_created}")
print(f"Execution Time: {result.execution_time:.2f}s")
print(f"Throughput: {result.mb_per_second:.2f} MB/s")
print(f"Preview: {result.preview_chunks[:3]}")
Performance Benchmark
Processing 42.4 million chunks in 105 seconds (51.16 MB/s).
============================================================
✅ KRIRA AUGMENT - Processing Complete
============================================================
📊 Chunks Created: 42,448,765
⏱️ Execution Time: 113.79 seconds
🚀 Throughput: 47.51 MB/s
📁 Output File: output.jsonl
============================================================
📝 Preview (Top 3 Chunks):
------------------------------------------------------------
[1] event_time,event_type,product_id,category_id,category_code,brand,price,user_id,user_session
[2] 2019-10-01 00:00:00 UTC,view,44600062,2103807459595387724,,shiseido,35.79,541312140,72d76fde-8bb3-4e00-8c23-a032dfed738c
[3] 2019-10-01 00:00:00 UTC,view,3900821,2053013552326770905,appliances.environment.water_heater...
Krira-Chunker Architecture
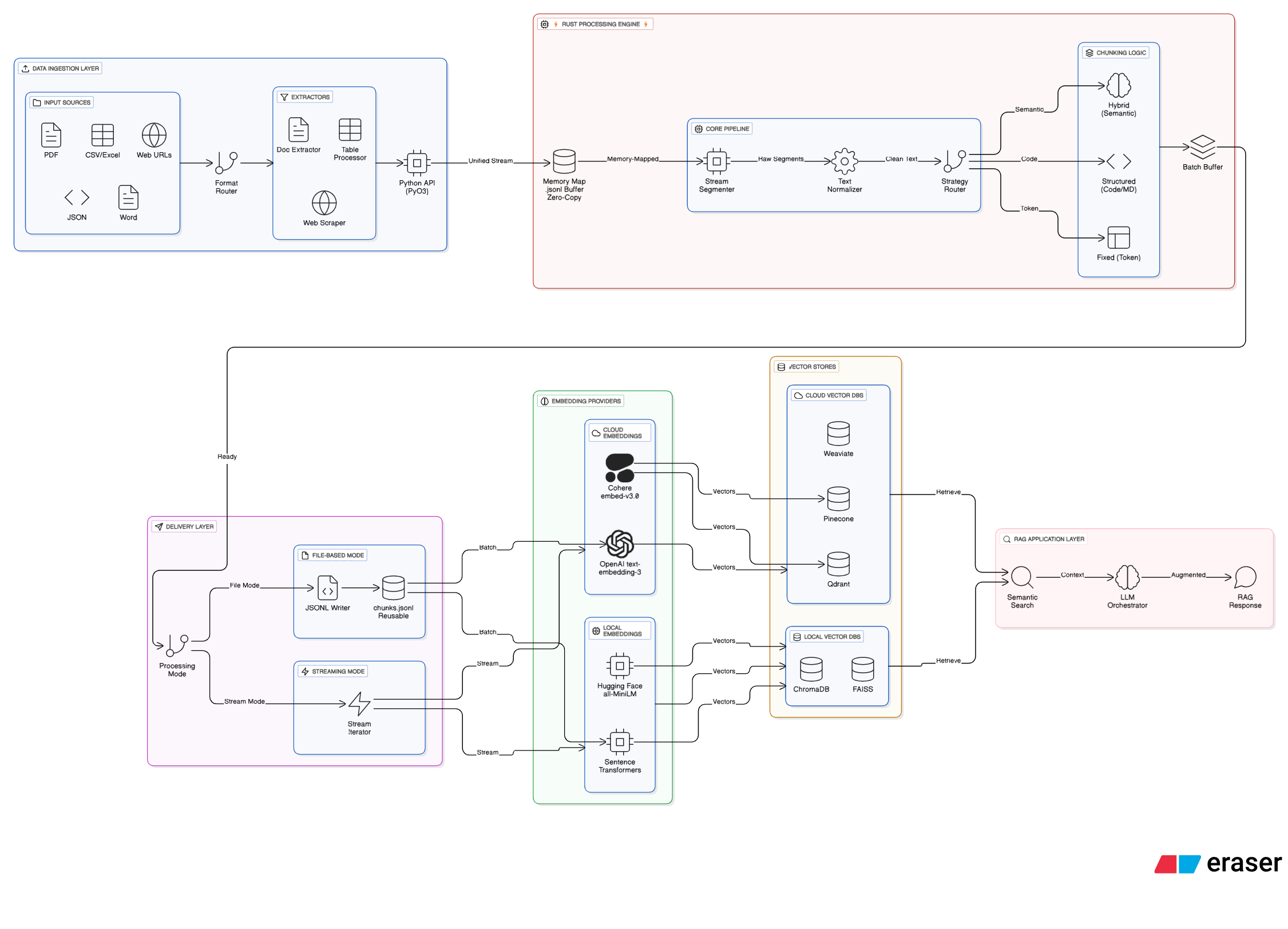
Working of Krira-Chunker
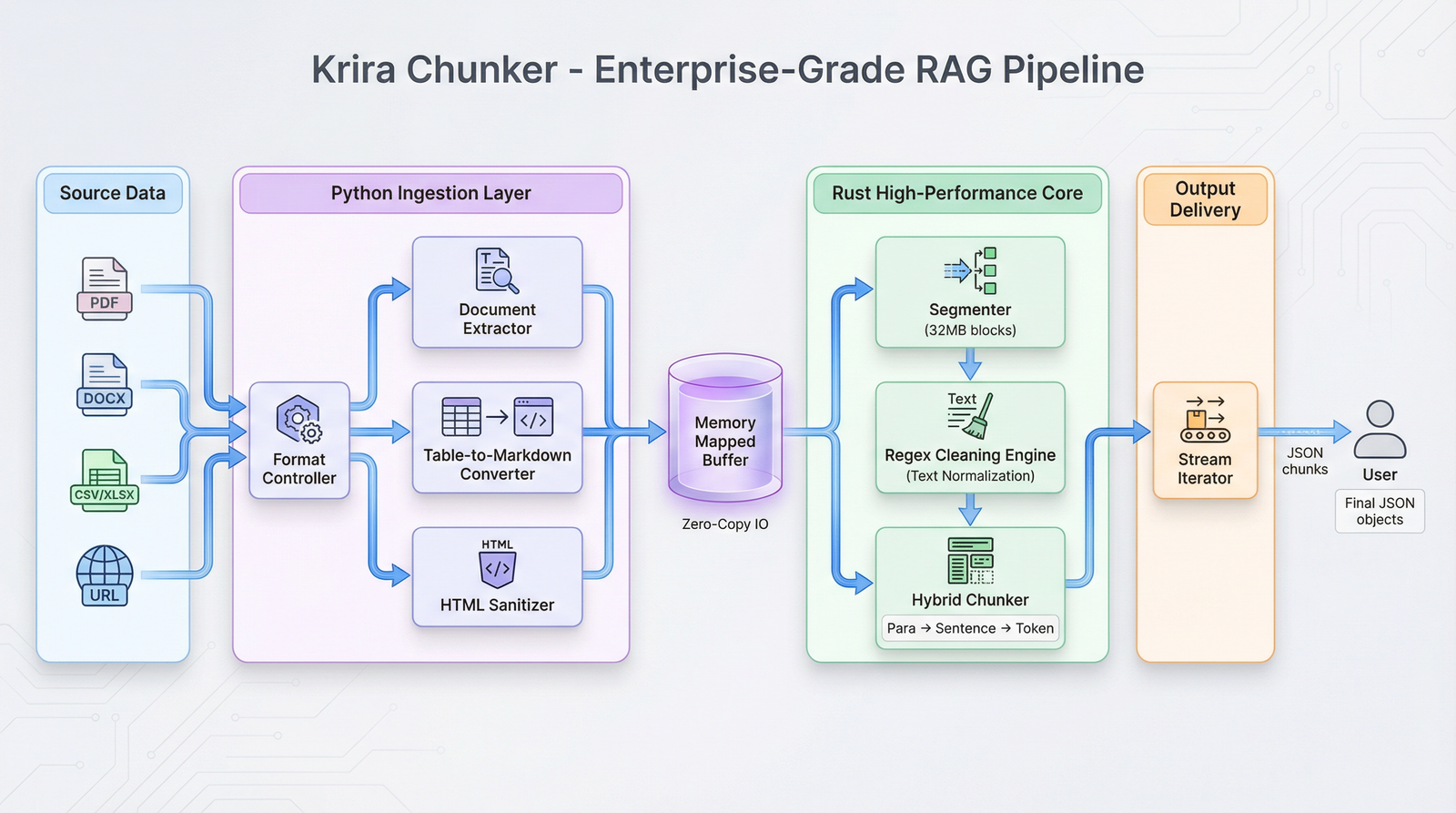
Complete Example: Local (ChromaDB) - FREE
No API keys required. Runs entirely on your machine.
pip install sentence-transformers chromadb
from krira_augment.krira_chunker import Pipeline, PipelineConfig
from sentence_transformers import SentenceTransformer
import chromadb
import json
# Step 1: Chunk the file (Rust Core)
config = PipelineConfig(chunk_size=512, chunk_overlap=50)
pipeline = Pipeline(config=config)
result = pipeline.process("sample.csv", output_path="chunks.jsonl")
print(f"Chunks Created: {result.chunks_created}")
print(f"Execution Time: {result.execution_time:.2f}s")
print(f"Throughput: {result.mb_per_second:.2f} MB/s")
print(f"Preview: {result.preview_chunks[:3]}")
# Step 2: Embed and store (Local)
print("Loading model...")
model = SentenceTransformer('all-MiniLM-L6-v2')
client = chromadb.Client()
# Note: In new versions of Chroma, use get_or_create_collection
collection = client.get_or_create_collection("my_rag_db")
with open("chunks.jsonl", "r") as f:
for line_num, line in enumerate(f, 1):
chunk = json.loads(line)
embedding = model.encode(chunk["text"])
# Handle empty metadata
meta = chunk.get("metadata")
collection.add(
ids=[f"chunk_{line_num}"],
embeddings=[embedding.tolist()],
metadatas=[meta] if meta else None,
documents=[chunk["text"]]
)
if line_num % 100 == 0:
print(f"Processed {line_num} chunks...")
print("Done! All chunks stored in ChromaDB.")
Cloud Integrations (OpenAI, Pinecone, Cohere)
If you have API keys, you can swap Step 2 with these integrations:
OpenAI + Pinecone
pip install openai pinecone-client
from openai import OpenAI
from pinecone import Pinecone
# API Keys
OPENAI_API_KEY = "sk-..."
PINECONE_API_KEY = "pcone-..."
PINECONE_INDEX_NAME = "my-rag"
client = OpenAI(api_key=OPENAI_API_KEY)
pc = Pinecone(api_key=PINECONE_API_KEY)
index = pc.Index(PINECONE_INDEX_NAME)
with open("chunks.jsonl", "r") as f:
for line_num, line in enumerate(f, 1):
chunk = json.loads(line)
response = client.embeddings.create(
input=chunk["text"],
model="text-embedding-3-small"
)
embedding = response.data[0].embedding
index.upsert(vectors=[(f"chunk_{line_num}", embedding, chunk.get("metadata", {}))])
if line_num % 100 == 0:
print(f"Processed {line_num} chunks...")
OpenAI + Qdrant
pip install openai qdrant-client
from openai import OpenAI
from qdrant_client import QdrantClient
from qdrant_client.models import PointStruct
client = OpenAI(api_key="sk-...")
qdrant = QdrantClient(url="https://xyz.qdrant.io", api_key="qdrant-...")
with open("chunks.jsonl", "r") as f:
for line_num, line in enumerate(f, 1):
chunk = json.loads(line)
response = client.embeddings.create(input=chunk["text"], model="text-embedding-3-small")
embedding = response.data[0].embedding
qdrant.upsert(collection_name="my-chunks", points=[PointStruct(id=line_num, vector=embedding, payload=chunk.get("metadata", {}))])
if line_num % 100 == 0:
print(f"Processed {line_num} chunks...")
OpenAI + Weaviate
pip install openai weaviate-client
import weaviate
import weaviate.classes as wvc
from openai import OpenAI
# Connect to Weaviate Cloud
client_w = weaviate.connect_to_wcs(
cluster_url="https://xyz.weaviate.network",
auth_credentials=weaviate.auth.AuthApiKey("weaviate-...")
)
client_o = OpenAI(api_key="sk-...")
# Get collection
collection = client_w.collections.get("Chunk")
with open("chunks.jsonl", "r") as f:
for line_num, line in enumerate(f, 1):
chunk = json.loads(line)
response = client_o.embeddings.create(input=chunk["text"], model="text-embedding-3-small")
embedding = response.data[0].embedding
# Insert with vector
collection.data.insert(
properties={"text": chunk["text"], "metadata": str(chunk.get("metadata", {}))},
vector=embedding
)
if line_num % 100 == 0:
print(f"Processed {line_num} chunks...")
Cohere + Pinecone
pip install cohere pinecone-client
import cohere
from pinecone import Pinecone
co = cohere.Client("co-...")
pc = Pinecone(api_key="pcone-...")
index = pc.Index("my-rag")
with open("chunks.jsonl", "r") as f:
for line_num, line in enumerate(f, 1):
chunk = json.loads(line)
response = co.embed(texts=[chunk["text"]], model="embed-english-v3.0")
embedding = response.embeddings[0]
index.upsert(vectors=[(f"chunk_{line_num}", embedding, chunk.get("metadata", {}))])
if line_num % 100 == 0:
print(f"Processed {line_num} chunks...")
Cohere + Qdrant
pip install cohere qdrant-client
import cohere
from qdrant_client import QdrantClient
from qdrant_client.models import PointStruct
co = cohere.Client("co-...")
qdrant = QdrantClient(url="https://xyz.qdrant.io", api_key="qdrant-...")
with open("chunks.jsonl", "r") as f:
for line_num, line in enumerate(f, 1):
chunk = json.loads(line)
response = co.embed(texts=[chunk["text"]], model="embed-english-v3.0")
embedding = response.embeddings[0]
qdrant.upsert(
collection_name="my-chunks",
points=[PointStruct(id=line_num, vector=embedding, payload=chunk.get("metadata", {}))]
)
if line_num % 100 == 0:
print(f"Processed {line_num} chunks...")
Hugging Face + FAISS (FREE)
pip install transformers torch faiss-cpu
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
import faiss
import numpy as np
import json
# Helper for Mean Pooling
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
print("Loading model...")
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
index = faiss.IndexFlatL2(384)
batch_embeddings = []
BATCH_SIZE = 64
with open("chunks.jsonl", "r") as f:
for line_num, line in enumerate(f, 1):
chunk = json.loads(line)
# Tokenize
encoded_input = tokenizer(chunk["text"], padding=True, truncation=True, max_length=512, return_tensors='pt')
# Compute Token Embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Pooling & Normalization
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
batch_embeddings.append(sentence_embeddings.squeeze().numpy())
if len(batch_embeddings) >= BATCH_SIZE:
index.add(np.vstack(batch_embeddings).astype('float32'))
batch_embeddings = []
if line_num % 100 == 0:
print(f"Processed {line_num} chunks...")
if batch_embeddings:
index.add(np.vstack(batch_embeddings).astype('float32'))
faiss.write_index(index, "my_vectors.index")
print("Done! Vectors saved to my_vectors.index")
Streaming Mode (No Files)
Process chunks without saving to disk - maximum efficiency for real-time pipelines:
Complete Example: OpenAI + Pinecone (Streaming)
pip install openai pinecone-client
from krira_augment.krira_chunker import Pipeline, PipelineConfig
from openai import OpenAI
from pinecone import Pinecone
# API Keys
OPENAI_API_KEY = "sk-..." # https://platform.openai.com/api-keys
PINECONE_API_KEY = "pcone-..." # https://app.pinecone.io/
PINECONE_INDEX_NAME = "my-rag"
# Initialize
client = OpenAI(api_key=OPENAI_API_KEY)
pc = Pinecone(api_key=PINECONE_API_KEY)
index = pc.Index(PINECONE_INDEX_NAME)
# Configure pipeline
config = PipelineConfig(chunk_size=512, chunk_overlap=50)
pipeline = Pipeline(config=config)
# Stream and embed (no file created)
chunk_count = 0
print("Starting streaming pipeline...")
for chunk in pipeline.process_stream("data.csv"):
chunk_count += 1
# Embed
response = client.embeddings.create(
input=chunk["text"],
model="text-embedding-3-small"
)
embedding = response.data[0].embedding
# Store immediately
index.upsert(vectors=[(
f"chunk_{chunk_count}",
embedding,
chunk["metadata"]
)])
# Progress
if chunk_count % 100 == 0:
print(f"Processed {chunk_count} chunks...")
print(f"Done! Embedded {chunk_count} chunks. No intermediate file created.")
Other Streaming Integrations
Replace the embedding/storage logic with any of these:
OpenAI + Qdrant (Streaming)
pip install openai qdrant-client
from krira_augment.krira_chunker import Pipeline, PipelineConfig
from openai import OpenAI
from qdrant_client import QdrantClient
from qdrant_client.models import PointStruct
# Initialize
client = OpenAI(api_key="sk-...")
qdrant = QdrantClient(url="https://xyz.qdrant.io", api_key="qdrant-...")
# Configure and stream
config = PipelineConfig(chunk_size=512, chunk_overlap=50)
pipeline = Pipeline(config=config)
chunk_count = 0
for chunk in pipeline.process_stream("data.csv"):
chunk_count += 1
# Embed
response = client.embeddings.create(input=chunk["text"], model="text-embedding-3-small")
embedding = response.data[0].embedding
# Store
qdrant.upsert(
collection_name="my-chunks",
points=[PointStruct(id=chunk_count, vector=embedding, payload=chunk["metadata"])]
)
if chunk_count % 100 == 0:
print(f"Processed {chunk_count} chunks...")
print(f"Done! {chunk_count} chunks embedded.")
OpenAI + Weaviate (Streaming)
pip install openai weaviate-client
from krira_augment.krira_chunker import Pipeline, PipelineConfig
from openai import OpenAI
import weaviate
# Initialize
client_o = OpenAI(api_key="sk-...")
client_w = weaviate.connect_to_wcs(
cluster_url="https://xyz.weaviate.network",
auth_credentials=weaviate.auth.AuthApiKey("weaviate-...")
)
collection = client_w.collections.get("Chunk")
# Configure and stream
config = PipelineConfig(chunk_size=512, chunk_overlap=50)
pipeline = Pipeline(config=config)
chunk_count = 0
for chunk in pipeline.process_stream("data.csv"):
chunk_count += 1
# Embed
response = client_o.embeddings.create(input=chunk["text"], model="text-embedding-3-small")
embedding = response.data[0].embedding
# Store
collection.data.insert(
properties={"text": chunk["text"], "metadata": str(chunk["metadata"])},
vector=embedding
)
if chunk_count % 100 == 0:
print(f"Processed {chunk_count} chunks...")
print(f"Done! {chunk_count} chunks embedded.")
Cohere + Pinecone (Streaming)
pip install cohere pinecone-client
from krira_augment.krira_chunker import Pipeline, PipelineConfig
import cohere
from pinecone import Pinecone
# Initialize
co = cohere.Client("co-...")
pc = Pinecone(api_key="pcone-...")
index = pc.Index("my-rag")
# Configure and stream
config = PipelineConfig(chunk_size=512, chunk_overlap=50)
pipeline = Pipeline(config=config)
chunk_count = 0
for chunk in pipeline.process_stream("data.csv"):
chunk_count += 1
# Embed
response = co.embed(texts=[chunk["text"]], model="embed-english-v3.0")
embedding = response.embeddings[0]
# Store
index.upsert(vectors=[(f"chunk_{chunk_count}", embedding, chunk["metadata"])])
if chunk_count % 100 == 0:
print(f"Processed {chunk_count} chunks...")
print(f"Done! {chunk_count} chunks embedded.")
Cohere + Qdrant (Streaming)
pip install cohere qdrant-client
from krira_augment.krira_chunker import Pipeline, PipelineConfig
import cohere
from qdrant_client import QdrantClient
from qdrant_client.models import PointStruct
# Initialize
co = cohere.Client("co-...")
qdrant = QdrantClient(url="https://xyz.qdrant.io", api_key="qdrant-...")
# Configure and stream
config = PipelineConfig(chunk_size=512, chunk_overlap=50)
pipeline = Pipeline(config=config)
chunk_count = 0
for chunk in pipeline.process_stream("data.csv"):
chunk_count += 1
# Embed
response = co.embed(texts=[chunk["text"]], model="embed-english-v3.0")
embedding = response.embeddings[0]
# Store
qdrant.upsert(
collection_name="my-chunks",
points=[PointStruct(id=chunk_count, vector=embedding, payload=chunk["metadata"])]
)
if chunk_count % 100 == 0:
print(f"Processed {chunk_count} chunks...")
print(f"Done! {chunk_count} chunks embedded.")
Local (Sentence Transformers) + ChromaDB (Streaming, FREE)
pip install sentence-transformers chromadb
from krira_augment.krira_chunker import Pipeline, PipelineConfig
from sentence_transformers import SentenceTransformer
import chromadb
# Initialize (no API keys needed)
model = SentenceTransformer('all-MiniLM-L6-v2')
client = chromadb.Client()
collection = client.create_collection("my_chunks")
# Configure and stream
config = PipelineConfig(chunk_size=512, chunk_overlap=50)
pipeline = Pipeline(config=config)
chunk_count = 0
for chunk in pipeline.process_stream("data.csv"):
chunk_count += 1
# Embed locally (free, runs on your machine)
embedding = model.encode(chunk["text"])
# Store locally
collection.add(
ids=[f"chunk_{chunk_count}"],
embeddings=[embedding.tolist()],
metadatas=[chunk["metadata"]],
documents=[chunk["text"]]
)
if chunk_count % 100 == 0:
print(f"Processed {chunk_count} chunks...")
print(f"Done! {chunk_count} chunks embedded. All local, no API costs.")
Hugging Face + FAISS (Streaming, FREE)
pip install transformers torch faiss-cpu
from krira_augment.krira_chunker import Pipeline, PipelineConfig
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
import faiss
import numpy as np
# Helper for Mean Pooling
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Initialize (no API keys needed)
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
index = faiss.IndexFlatL2(384)
# Configure and stream
config = PipelineConfig(chunk_size=512, chunk_overlap=50)
pipeline = Pipeline(config=config)
chunk_count = 0
embeddings_batch = []
BATCH_SIZE = 64
for chunk in pipeline.process_stream("data.csv"):
chunk_count += 1
# Tokenize
inputs = tokenizer(chunk["text"], return_tensors="pt", padding=True, truncation=True, max_length=512)
# Embed
with torch.no_grad():
outputs = model(**inputs)
embedding = mean_pooling(outputs, inputs['attention_mask'])
embedding = F.normalize(embedding, p=2, dim=1)
embedding = embedding.squeeze().numpy()
embeddings_batch.append(embedding)
# Add to FAISS in batches
if len(embeddings_batch) >= BATCH_SIZE:
index.add(np.vstack(embeddings_batch).astype('float32'))
embeddings_batch = []
print(f"Processed {chunk_count} chunks...")
# Add remaining embeddings
if embeddings_batch:
index.add(np.vstack(embeddings_batch).astype('float32'))
# Save index
faiss.write_index(index, "my_vectors.index")
print(f"Done! {chunk_count} chunks embedded and saved to my_vectors.index")
Streaming Mode Advantages
| Feature | File-Based | Streaming |
|---|---|---|
| Disk I/O | Creates chunks.jsonl | None |
| Memory Usage | O(1) constant | O(1) constant |
| Speed | Chunking + Embedding | Overlapped (faster) |
| Use Case | Large files, batch processing | Real-time, no storage |
| Flexibility | Can re-process chunks | Single pass only |
When to Use Streaming vs File-Based
Use Streaming When:
- You want maximum speed (no disk writes)
- You don't need to save chunks for later
- You're building real-time pipelines
- You have limited disk space
Use File-Based When:
- You want to inspect/debug chunks
- You need to re-process with different embeddings
- You want to share chunks with your team
- You're experimenting with different models
Error Handling (Production Ready)
from krira_augment.krira_chunker import Pipeline, PipelineConfig
from openai import OpenAI
from pinecone import Pinecone
import time
client = OpenAI(api_key="sk-...")
pc = Pinecone(api_key="pcone-...")
index = pc.Index("my-rag")
config = PipelineConfig(chunk_size=512, chunk_overlap=50)
pipeline = Pipeline(config=config)
chunk_count = 0
error_count = 0
for chunk in pipeline.process_stream("data.csv"):
chunk_count += 1
try:
# Embed
response = client.embeddings.create(input=chunk["text"], model="text-embedding-3-small")
embedding = response.data[0].embedding
# Store
index.upsert(vectors=[(f"chunk_{chunk_count}", embedding, chunk["metadata"])])
except Exception as e:
error_count += 1
print(f"Error on chunk {chunk_count}: {e}")
# Retry logic
if "rate_limit" in str(e).lower():
print("Rate limited, waiting 60 seconds...")
time.sleep(60)
# Retry (add your retry logic here)
if chunk_count % 100 == 0:
print(f"Processed {chunk_count} chunks, {error_count} errors")
print(f"Done! {chunk_count} chunks processed, {error_count} errors")
Supported Formats
| Format | Extension | Method |
|---|---|---|
| CSV | .csv |
Direct processing |
| Text | .txt |
Direct processing |
| JSONL | .jsonl |
Direct processing |
| JSON | .json |
Auto-flattening |
.pdf |
pdfplumber extraction | |
| Word | .docx |
python-docx extraction |
| Excel | .xlsx |
openpyxl extraction |
| XML | .xml |
ElementTree parsing |
| URLs | http:// |
BeautifulSoup scraping |
Provider Comparison
| Embedding | Vector Store | Cost | API Keys | Streaming Support |
|---|---|---|---|---|
| OpenAI | Pinecone | Paid | 2 | ✅ Yes |
| OpenAI | Qdrant | Paid | 2 | ✅ Yes |
| OpenAI | Weaviate | Paid | 2 | ✅ Yes |
| Cohere | Pinecone | Paid | 2 | ✅ Yes |
| Cohere | Qdrant | Paid | 2 | ✅ Yes |
| SentenceTransformers | ChromaDB | FREE | 0 | ✅ Yes |
| Hugging Face | FAISS | FREE | 0 | ✅ Yes |
API Keys Setup
Get your keys from:
- OpenAI: https://platform.openai.com/api-keys
- Cohere: https://dashboard.cohere.com/api-keys
- Pinecone: https://app.pinecone.io/
- Qdrant: https://cloud.qdrant.io/
- Weaviate: https://console.weaviate.cloud/
Development
- Clone the repo
- Install Maturin
pip install maturin
- Build and Install locally
maturin develop
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file krira_augment-2.1.13.tar.gz.
File metadata
- Download URL: krira_augment-2.1.13.tar.gz
- Upload date:
- Size: 71.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
56c9bcbfacfa54af9a1836daa99566a4fe49f2b66375cabb8154e69b88246b5c
|
|
| MD5 |
dc96fcece85abd1b7be70eb9ec729f87
|
|
| BLAKE2b-256 |
6d38e29ab3762a2ca14d0703746ba66db0fcf0b9a4b452157a316526393b2fb2
|
File details
Details for the file krira_augment-2.1.13-cp313-cp313-win_amd64.whl.
File metadata
- Download URL: krira_augment-2.1.13-cp313-cp313-win_amd64.whl
- Upload date:
- Size: 717.5 kB
- Tags: CPython 3.13, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6164947440aee71322f50808c4bf76cbf0fa560b6784b5513cd98b1c94b297e7
|
|
| MD5 |
9e03d4ad0d62499367e9b09779594212
|
|
| BLAKE2b-256 |
4bb564a8e6e0104492a14f87d17ab495a55e15ad7eadcca3bdebc187ce082f59
|







