Tenant-fair LLM inference orchestration on a single GPU. No Kubernetes.

Project description
kvwarden




Tenant-fair LLM inference on one GPU. Sits in front of vLLM/SGLang, rate-limits per tenant at admission, and keeps a quiet user fast while a noisy neighbor floods the same engine.
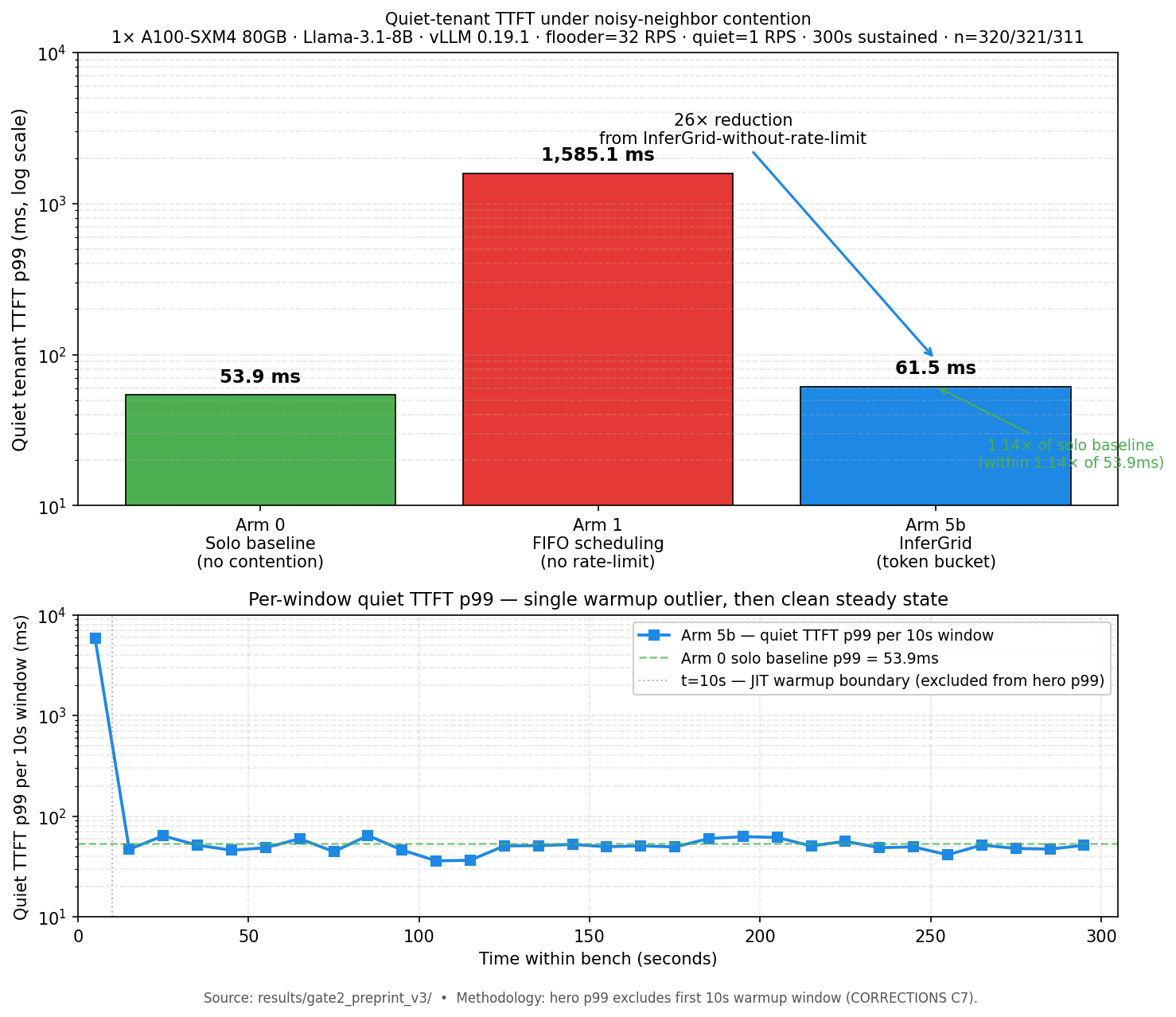
Hero number. A100-SXM4, Llama-3.1-8B, vLLM 0.19.1, two tenants sharing one engine, 300 s sustained:
| Quiet user TTFT p99 | |
|---|---|
| Solo (no contention) | 53.9 ms |
| FIFO under flooder (no rate-limit) | 1,585 ms (29x starvation) |
| kvwarden token-bucket under flooder | 61.5 ms (1.14x solo) |
Ten lines of YAML. No application code change. Raw artifacts: results/gate2_preprint_v3/.
pip install kvwarden
Quickstart
kvwarden does not bundle vLLM. Install an engine separately, then let kvwarden spawn and proxy it.
# 1. Install kvwarden + the engine.
pip install kvwarden
pip install vllm # needs a GPU box; see vLLM docs for your CUDA stack
# 2. Start kvwarden. It launches vLLM as a subprocess per the model list
# in the config and exposes one OpenAI-compatible endpoint.
kvwarden serve --config configs/quickstart_fairness.yaml
# 3. In another shell, wait for /health and send two tenants at the same model.
until curl -fs localhost:8000/health > /dev/null; do sleep 2; done
curl localhost:8000/v1/completions -H "X-Tenant-ID: noisy" \
-d '{"model":"llama31-8b","prompt":"Hello","max_tokens":64,"stream":true}'
curl localhost:8000/v1/completions -H "X-Tenant-ID: quiet" \
-d '{"model":"llama31-8b","prompt":"Hello","max_tokens":64,"stream":true}'
# 4. Watch the token bucket fire and the engine queue stay composed.
curl localhost:8000/metrics | grep -E "tenant_rejected|admission_queue_depth"
First call returns 503 until vLLM finishes loading (30-90 s on A100 for an 8B). The config at configs/quickstart_fairness.yaml is heavily commented; every knob traces back to a specific experiment.
Docker Compose
A two-service compose bundle brings up vLLM + kvwarden with one command. Requires a Linux GPU host with the NVIDIA Container Toolkit; CPU-only and Apple Silicon hosts cannot run this end-to-end (vLLM needs CUDA).
export HF_TOKEN=hf_... # gated Llama-3.1-8B model
docker compose -f docker/docker-compose.yml up
# in another shell, once both services report healthy (~3 min cold):
curl localhost:8000/v1/completions -H 'X-Tenant-ID: quiet' \
-d '{"model":"llama31-8b","prompt":"Hello","max_tokens":32}'
Compose pins vllm/vllm-openai:v0.19.1 (the image the hero number was measured against) and serves the bundled docker/quickstart-compose.yaml — same two-tenant token-bucket shape as configs/quickstart_fairness.yaml, port-pinned for the bundle.
When it breaks
| Symptom | Likely cause | Fix |
|---|---|---|
kvwarden doctor reports "SSL trust unavailable" |
macOS stock Python venv missing CA roots | pip install --upgrade certifi, then re-run |
/health returns 503 right after kvwarden serve |
vLLM JIT-compiling the model (30-90 s for an 8B on A100) | Wait, then until curl -fs localhost:8000/health; do sleep 2; done |
/v1/completions returns 401 |
HuggingFace gated-model auth missing | huggingface-cli login, or export HF_TOKEN=... before kvwarden serve |
| Quiet tenant still starved under flooder | rate_limit_rpm too high in config |
Drop the per-tenant rate_limit_rpm in your config; the hero uses 600 with rate_limit_burst: 10 |
| All requests return 429 immediately | rate_limit_burst set tighter than your client's burst |
Raise rate_limit_burst or unset it (default = rate_limit_rpm) |
| vLLM subprocess crashes with CUDA OOM | gpu_memory_utilization too high for the loaded model + KV cache |
Drop the model's gpu_memory_utilization to 0.40 (hero default) and retry |
Address already in use on port 8000 |
Stale daemon or another local service | kvwarden serve --port 8001, or lsof -i :8000 to find the holder |
ModuleNotFoundError: kvwarden after pip install kvwarden |
venv mismatch — installed into the wrong interpreter | python -c "import kvwarden; print(kvwarden.__version__)" to confirm; reinstall in the venv that runs kvwarden |
| Engine pre-load takes >5 min | First-time model download from HuggingFace | Pre-warm the cache: huggingface-cli download <model_id> before kvwarden serve |
If your symptom is not in the table, file an issue with the output of kvwarden doctor and kvwarden serve --log-level DEBUG.
Is this for me?
| Tool | Orchestration | Tenant fairness | Engines | Target scale |
|---|---|---|---|---|
| NVIDIA Dynamo | Kubernetes | No | Multi | Datacenter |
| llm-d | Kubernetes | No | vLLM | Datacenter |
| Ollama | None | No | llama.cpp | Single-user |
| kvwarden | None | Yes | vLLM + SGLang | Single-node, 2-8 tenants |
kvwarden is the "shared GPU, a handful of tenants, no cluster" cell. If you already run Kubernetes or you're a single user on your own box, you probably want one of the others.
How it works
A thin orchestration layer (~3,500 LOC src) sits between your app and vLLM/SGLang. On request arrival, a per-tenant token bucket decides admit-or-429 before the request reaches the engine queue. Admitted requests flow through a length-bucketed admission controller and a DRR priority scheduler, then out to the engine subprocess kvwarden manages. Engines never see tenant identity; kvwarden does, and that's the entire trick. Multi-model lifecycle (freq+recency eviction, hot-swap) lives at the same layer. The HTTP API is OpenAI-compatible so your client code doesn't change.
Deeper read and the component diagram live in docs/architecture/overview.md.
Reproduce the hero number
# Terminal A — start kvwarden on the hero config (vLLM 0.19.1, Llama-3.1-8B).
kvwarden serve --config configs/gate2_fairness_token_bucket.yaml --port 8000
# Terminal B — wait for /health, then run the 300-second bench.
until curl -fs localhost:8000/health > /dev/null; do sleep 5; done
kvwarden bench reproduce-hero --flavor=2tenant
Needs an A100-SXM4 80GB (or equivalent — 1xH100 works) with vLLM 0.19.1 installed. Runtime is about 300 s for the bench plus ~30 s preflight. Output goes to ./kvwarden-reproduce-<timestamp>/report.json with your numbers side-by-side against the published reference so you can file an issue with concrete data if they diverge. Other flavors: --flavor=n6, --flavor=n8. Full doc: docs/reproduce_hero.md.
Frontier coverage
The same admission mechanism holds on larger models. Gate 2.3 (70B dense, TP=4 on 4x H100) and Gate 2.4 (Mixtral-8x7B MoE, TP=2 on 2x H100) both land quiet-to-solo p50 ratios between 1.07x and 1.94x — the mechanism lives before the engine boundary, so sharding topology, expert routing, and attention shape don't change the fairness picture. Matrix, caveats, and raw bench pointers in docs/launch/frontier_coverage.md. The 8B A100 run is the only one with a single-command reproduce path today; 70B and Mixtral wrappers are a roadmap item.
About the name
kvwarden ships tenant-fair admission today. The name still over-promises: nothing in 0.1.x reads or writes the KV cache. The actual trajectory:
- 0.1.x (today): tenant-aware admission — token bucket at the budget gate. Engine-blind to tenants; we put the policy one layer up.
- 0.2 (mid-June): cache-pressure-aware admission. Same gate, now informed by the engine's
vllm:kv_cache_usage_percgauge, so the bucket scales priority by cache load. Still admission, still doesn't touch the cache — but smarter gating. RFC: docs/rfcs/T2-cache-pressure-admission.md. The original "tenant-aware KV eviction" framing for 0.2 was reframed on 2026-04-28 after we verified the eviction scaffold is a shadow ledger no engine reads — see #103 for the supersession trail. - 0.3+ (LMCache substrate): actual per-tenant KV cache management. This is where the name finally becomes literal.
0.2 limitation, surfaced upfront: vllm:kv_cache_usage_perc is labeled only by model_name, not by tenant. 0.2 lets kvwarden react to global cache pressure; it cannot see which tenant is occupying the cache. Per-tenant cache visibility waits on LMCache (0.3+).
If you pip install 0.1.5 expecting KV-cache isolation today, you will not get it; you get admission-gate fairness, which is what the hero number measures.
What's next
- #102 T1: Distribution — 10 onboarding installs in week 1
- #103 T2: Name-truth — cache-pressure admission for 0.2; LMCache-based per-tenant cache for 0.3+
- #104 T3: Moat — vllm-project/production-stack router + LiteLLM adapter
- #105 W1: Launch blockers — pre-launch QA + day-0 ops
Telemetry
kvwarden ships opt-in, anonymous install/usage telemetry. First interactive run prompts once; default is no; answer n or hit Enter and nothing is ever transmitted. Opt in and each command sends seven fields: a locally-minted uuid4 install ID, kvwarden version, Python major.minor, OS, bucketed GPU class, command name, and a unix timestamp. No prompts, model names, tenant IDs, or receiver-side IP capture. Toggle with kvwarden telemetry off/on/status; hard-disable with export KVWARDEN_TELEMETRY=0. Non-interactive sessions auto-opt-out. Worker source: telemetry-worker/. Full policy: docs/privacy/telemetry.md.
Tests
pytest tests/unit/ # ~200 tests, no GPU needed, ~10 s
ruff check src/ tests/
ruff format --check src/ tests/
CI runs this matrix on Python 3.11 and 3.12; a red PR cannot merge.
Honesty log
Every metric we under-counted and the fix is in results/CORRECTIONS.md. TTFT measurement was rebuilt mid-project after a shadow review caught the original harness timing SSE first-frame RTT instead of first non-empty token (C2/C5). The 8B hero numbers exclude a 10 s JIT warmup window per C7; all 29 post-warmup windows sit between 36 ms and 65 ms.
Getting help
- File a bug: GitHub Issues. A
prometheus_dump.txtplusserver.logis worth more than a star. - Questions + launch ops context:
docs/ops/onboarding_playbook.md. - Contributing:
CONTRIBUTING.md. Start with a good first issue.
License
MIT. See LICENSE.
Cite as
@software{kvwarden_2026,
title = {kvwarden: tenant-fair LLM inference on a single GPU},
author = {Patel, Shrey and {Coconut Labs contributors}},
year = {2026},
version = {0.1.3},
url = {https://github.com/coconut-labs/kvwarden}
}


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file kvwarden-0.1.5.tar.gz.
File metadata
- Download URL: kvwarden-0.1.5.tar.gz
- Upload date:
- Size: 69.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c8a7770636956de5f8b9d8eefb02dc1c2b6eca31c3fe0c32b4aaef1956478419
|
|
| MD5 |
af2a1e6c856e94cbfd9becbc1d67b788
|
|
| BLAKE2b-256 |
f025e96adb140043d0a60f62eab2304f3b5b60bfb015a1bd37c3ebf3faeff28d
|
File details
Details for the file kvwarden-0.1.5-py3-none-any.whl.
File metadata
- Download URL: kvwarden-0.1.5-py3-none-any.whl
- Upload date:
- Size: 73.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3c52d082500c96a36bbc27e83155ed348635a15e994cae1fe0b007e147b40e39
|
|
| MD5 |
6a943d143b7ab923ff9daa43ea522f07
|
|
| BLAKE2b-256 |
91a13671d49e011e7de12e0b4c60901855eb573aa3a9747008e7a64177db56b2
|







