LangDiff is a Python library that solves the hard problems of streaming structured LLM outputs to frontends.


Project description
⚖️ LangDiff: Progressive UI from LLM




LangDiff is a Python library that solves the hard problems of streaming structured LLM outputs to frontends.

LangDiff provides intelligent partial parsing with granular, type-safe events as JSON structures build token by token, plus automatic JSON Patch generation for efficient frontend synchronization. Build responsive AI applications where your backend structures and frontend experiences can evolve independently. Read more about it on the Motivation section.
Demo
Click the image below.
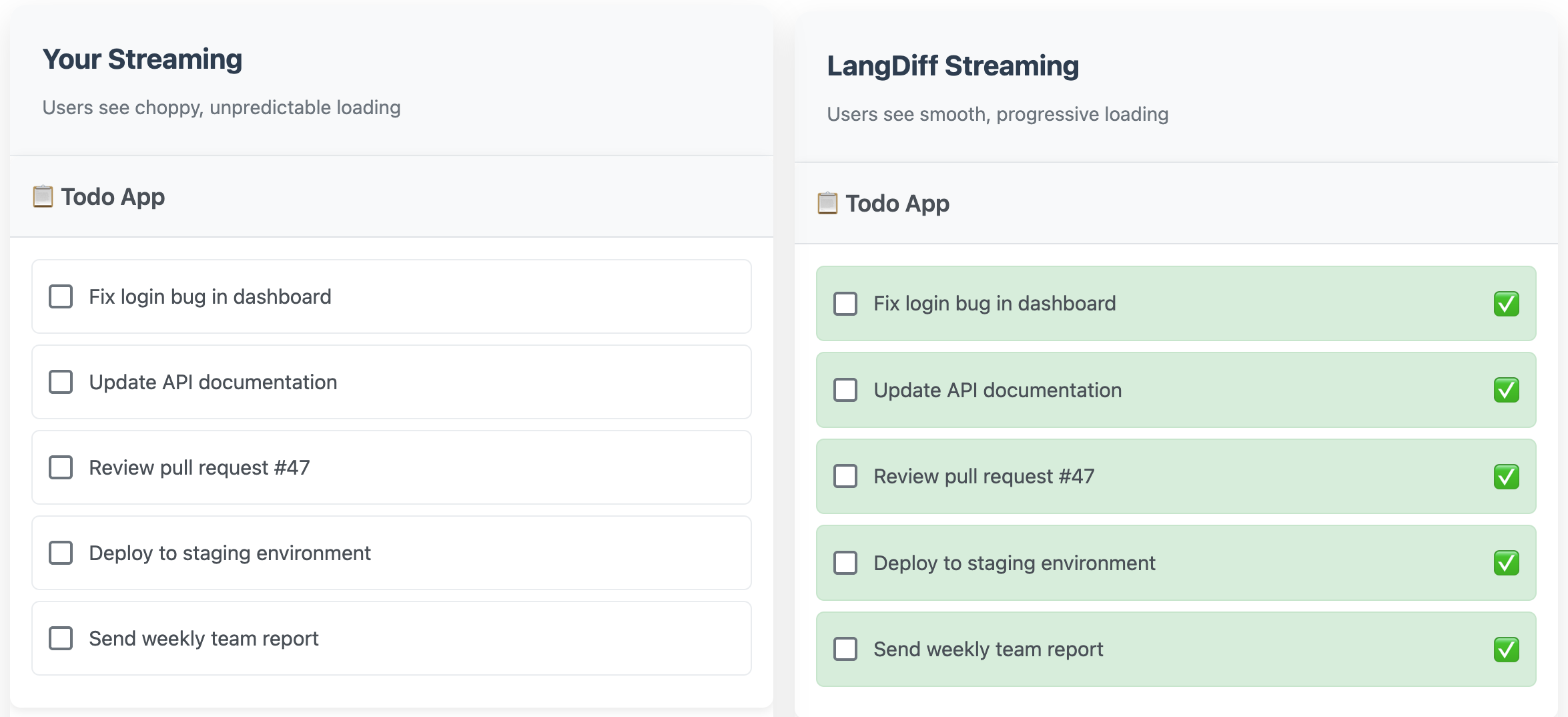
Core Features
Streaming Parsing
- Define schemas for streaming structured outputs using Pydantic-style models.
- Receive granular, type-safe callbacks (
on_append,on_update,on_complete) as tokens stream in. - Derive Pydantic models from LangDiff models for seamless interop with existing libraries and SDKs like OpenAI SDK.
| Without LangDiff | With LangDiff |
parse_partial('{"it')
parse_partial('{"items":')
parse_partial('{"items": ["Buy a b')
parse_partial('{"items": ["Buy a banana", "')
parse_partial('{"items": ["Buy a banana", "Pack b')
parse_partial('{"items": ["Buy a banana", "Pack bags"]}')
|
on_item_list_append("", index=0)
on_item_append("Buy a b")
on_item_append("anana")
on_item_list_append("", index=1)
on_item_append("Pack b")
on_item_append("ags")
|
Change Tracking
- Track mutations without changing your code patterns by instrumenting existing Pydantic models, or plain Python dict/list/objects.
- Generate JSON Patch diffs automatically for efficient state synchronization between frontend and backend.
| Without LangDiff | With LangDiff |
data: {"it
data: ems":
data: ["Buy a b
data: anana", "
data: Pack b
data: ags"]}
|
data: {"op": "add", "path": "/items/-", "value": "Buy a b"}
data: {"op": "append", "path": "/items/0", "value": "anana"}
data: {"op": "add", "path": "/items/-", "value": "Pack b"}
data: {"op": "append", "path": "/items/1", "value": "ags"}
|
Usage
Installation
uv add langdiff
For pip,
pip install langdiff
Streaming Parsing
Suppose you want to generate a multi-section article with an LLM. Rather than waiting for the entire response, you can stream the article progressively by first generating section titles as they're determined, then streaming each section's content as it's written.

Start by defining model classes that specify your streaming structure:
import langdiff as ld
class ArticleGenerationResponse(ld.Object):
section_titles: ld.List[ld.String]
section_contents: ld.List[ld.String]
The ld.Object and ld.List classes handle internal streaming progression automatically.
Create an instance and attach event handlers to respond to streaming events:
ui = Article(sections=[])
response = ArticleGenerationResponse()
@response.section_titles.on_append
def on_section_title_append(title: ld.String, index: int):
ui.sections.append(Section(title="", content="", done=False))
@title.on_append
def on_title_append(chunk: str):
ui.sections[index].title += chunk
@response.section_contents.on_append
def on_section_content_append(content: ld.String, index: int):
if index >= len(ui.sections):
return
@content.on_append
def on_content_append(chunk: str):
ui.sections[index].content += chunk
@content.on_complete
def on_content_complete(_):
ui.sections[index].done = True
Create a streaming parser with ld.Parser and feed token chunks from your LLM stream (push()):
import openai
client = openai.OpenAI()
with client.chat.completions.stream(
model="gpt-5-mini",
messages=[{"role": "user", "content": "Write me a guide to open source a Python library."}],
# You can derive a Pydantic model
# from a LangDiff model and use it with OpenAI SDK.
response_format=ArticleGenerationResponse.to_pydantic(),
) as stream:
with ld.Parser(response) as parser:
for event in stream:
if event.type == "content.delta":
parser.push(event.delta)
print(ui)
print(ui)
Change Tracking
To automatically track changes to your Article object, wrap it with ld.track_change():
- ui = Article(sections=[])
+ ui, diff_buf = ld.track_change(Article(sections=[]))
Now all modifications to ui and its nested objects are automatically captured in diff_buf.
Access the accumulated changes using diff_buf.flush():
import openai
client = openai.OpenAI()
with client.chat.completions.stream(
...
) as stream:
with ld.Parser(response) as parser:
for event in stream:
if event.type == "content.delta":
parser.push(event.delta)
print(diff_buf.flush()) # list of JSON Patch objects
print(diff_buf.flush())
# Output:
# [{"op": "add", "path": "/sections/-", "value": {"title": "", "content": "", "done": false}}]
# [{"op": "append", "path": "/sections/0/title", "value": "Abs"}]
# [{"op": "append", "path": "/sections/0/title", "value": "tract"}]
# ...
Notes:
flush()returns and clears the accumulated changes, so each call gives you only new modifications- Send these lightweight diffs to your frontend instead of retransmitting entire objects
- Diffs use JSON Patch format (RFC 6902) with an additional
appendoperation for efficient string building - For standard JSON Patch compatibility, use
ld.track_change(..., tracker_cls=ld.JSONPatchChangeTracker)
Motivation
Modern AI applications increasingly rely on LLMs to generate structured data rather than just conversational text. While LLM providers offer structured output capabilities (like OpenAI's JSON mode), streaming these outputs poses unique challenges that existing tools don't adequately address.
The Problem with Traditional Streaming Approaches
When LLMs generate complex JSON structures, waiting for the complete response creates poor user experiences. Standard streaming JSON parsers can't handle incomplete tokens - for example, {"sentence": "Hello, remains unparseable until the closing quote arrives. This means users see nothing until substantial chunks complete, defeating the purpose of streaming.
Even partial JSON parsing libraries that "repair" incomplete JSON don't fully solve the issues:
- No type safety: You lose static type checking when dealing with partial objects
- No granular control: Can't distinguish between complete and incomplete fields
The Coupling Problem
A more fundamental issue emerges in production applications: tightly coupling frontend UIs to LLM output schemas. When you stream raw JSON chunks from backend to frontend, several problems arise:
Schema Evolution: Improving prompts often requires changing JSON schemas. If your frontend directly consumes LLM output, every schema change may cause a breaking change.
Backward Compatibility: Consider a restaurant review summarizer that originally outputs:
{"summary": ["Food is great", "Nice interior"]}
Adding emoji support requires a new schema:
{"summaryV2": [{"emoji": "🍽️", "text": "Food is great"}]}
Supporting both versions in a single LLM output creates inefficiencies and synchronization issues between the redundant fields.
Implementation Detail Leakage: Frontend code becomes dependent on LLM provider specifics, prompt engineering decisions, and token streaming patterns.
The LangDiff Approach
LangDiff solves these problems through two key innovations:
- Intelligent Streaming Parsing: Define schemas that understand the streaming nature of LLM outputs. Get type-safe callbacks for partial updates, complete fields, and new array items as they arrive.
- Change-Based Synchronization: Instead of streaming raw JSON, track mutations on your application objects and send lightweight JSON Patch diffs to frontends. This decouples UI state from LLM output format.
This architecture allows:
- Independent Evolution: Change LLM prompts and schemas without breaking frontends
- Efficient Updates: Send only what changed, not entire objects
- Type Safety: Maintain static type checking throughout the streaming process
LangDiff enables you to build responsive, maintainable AI applications where the backend prompt engineering and frontend user experience can evolve independently.
License
Apache-2.0. See the LICENSE file for details.
Demo
See example.py for a runnable end-to-end demo using streaming parsing and diff tracking.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file langdiff-0.2.0.tar.gz.
File metadata
- Download URL: langdiff-0.2.0.tar.gz
- Upload date:
- Size: 65.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.8.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
dd12b33dfa33799348c77eb27422cdc8ccf11c123a89b2264ed5618e09285510
|
|
| MD5 |
16a34c8ac5be7612cf1fe7d17956d375
|
|
| BLAKE2b-256 |
92961c5b39394912dafdfe211d70064c0fdd047190a837ef2236c45cf4ca351c
|
File details
Details for the file langdiff-0.2.0-py3-none-any.whl.
File metadata
- Download URL: langdiff-0.2.0-py3-none-any.whl
- Upload date:
- Size: 19.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: uv/0.8.8
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
645fdbb6ce5271a98653438f3250e03f43f7221a9c88039fd78998aced686569
|
|
| MD5 |
dd3e88a26bba0970ffb7e5530e9e2ec6
|
|
| BLAKE2b-256 |
e112c1c3569e4fde9a2be7dcdec631af258f12bcc3d10b7a5830a821aac0e7c7
|







