A minimal gridworld environment for embodied question answering.

Project description
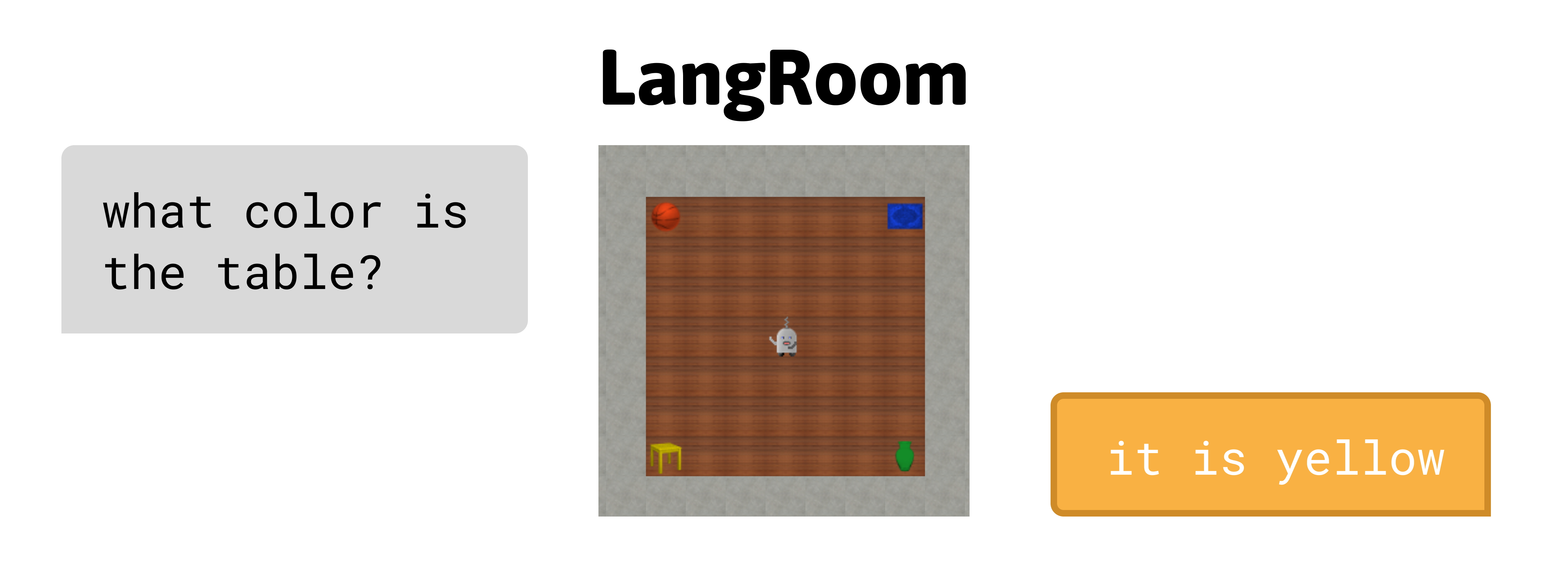
A minimal environment to evaluate embodied question answering in interactive agents.
In LangRoom, agents must learn to both move and talk. LangRoom contains four objects with randomly generated colors. Agents have a partial view of the environment and receives questions "what color is ?". In response, they must seek out the correct object and generate the right answer.
💬 Getting Started
Play as a human:
pip install langroom
# Move with WASD
# Speak tokens 1-10 with number keys 1234567890
python run_gui.py
Create an environment instance:
import langroom
env = langroom.LangRoom()
ac = {"move": 0, "talk": 0, "reset": True}
obs = env.step(ac)
📑 Documentation
Task Structure
There are four objects with fixed positions and randomized colors. By default, the agent has a partially observed view of 5x5 grid cells and cannot see all the objects at once. The environment generates questions "what color is <object>?" and then waits ten timesteps before starting to say "it is <color>". Agents answer correctly if they output the correct <color> token at the same timestep as the environment. After each question-answer sequence, the colors of the objects are re-randomized.
Three reward variants are implemented, specified by the task argument:
answer-only: agent is rewarded only for saying the correct color at the right timestep and penalized a small amount for saying things at other timesteps. Use this reward structure for comparability to the original paper Lin et al. (2023).answer-and-echo: agent is rewarded for predicting tokens that the environment generates (including silences and questions), with a larger reward for saying the correct color at the right timestep.echo: agent is rewarded for predicting all tokens the environment generates equally.
Observation Space
The observation and action space definition follows the embodied environment interface.
image (uint8 (resolution, resolution, 3)): pixel agent-centric local viewtext (uint32 ()): ID of the token at the current timesteplog_image (uint8 (resolution, 4 * resolution, 3)): debugging view with additional information rendered with agent view
Following the embodied env interface, these keys are also provided in the observation:
reward (float32): reward at the current timestepis_first (bool): True if this timestep is the first timestep of an episodeis_last (bool): True if this timestep is the last timestep of an episode (terminated or truncated)is_terminal (bool): True if this timestep is the last timestep of an episode (terminated)
Action Space
LangRoom has a dictionary action space that allows the agent to output actions and tokens (i.e. move and speak) simultaneously at each timestep.
move (int32 ()): ID of the movement action from movement action space[stay down up right left]talk (int32 ()): ID of the generated token
Following the embodied env interface, the action space also includes:
reset (bool): set to True to reset the episode
Vocabulary Size
By default, the vocabulary size is 15 (the minimal number of tokens to ask and answer questions). To test how agents deal with larger vocabularies (and thus larger action spaces), set the vocab_size argument. Additional words in the vocabulary will be filled with dummy tokens.
🛠️ Development and Issues
New development and extensions to the environment are welcome! For any questions or issues, please open a GitHub issue.
Citation
@article{lin2023learning,
title={Learning to Model the World with Language},
author={Jessy Lin and Yuqing Du and Olivia Watkins and Danijar Hafner and Pieter Abbeel and Dan Klein and Anca Dragan},
year={2023},
eprint={2308.01399},
archivePrefix={arXiv},
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file langroom-0.1.1.tar.gz.
File metadata
- Download URL: langroom-0.1.1.tar.gz
- Upload date:
- Size: 5.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.8.17
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f5a31564140abbc08e1850afafd75db510a1572e5bf0368b9b6ea3abe30d7fe7
|
|
| MD5 |
d7c904675e2d308acb47e596393af30d
|
|
| BLAKE2b-256 |
af24869e10c57dd0c318f61f2f2a64a384ca314931279462fc453489d5fc593d
|
File details
Details for the file langroom-0.1.1-py3-none-any.whl.
File metadata
- Download URL: langroom-0.1.1-py3-none-any.whl
- Upload date:
- Size: 5.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.8.17
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f1e89b6557bb9e8a52c42e2c2dbdf78fc6040c48a0d76fee76d2a37ba2879c53
|
|
| MD5 |
1f4129590520e438525eeace1487e9e7
|
|
| BLAKE2b-256 |
f0b3610c5e860128bc16c0f4d5e8b8fe3268d4d9e0d8f78431242e89b31b9afe
|







