Production-ready LASER multilingual embeddings

Project description
LASER embeddings




Out-of-the-box multilingual sentence embeddings.
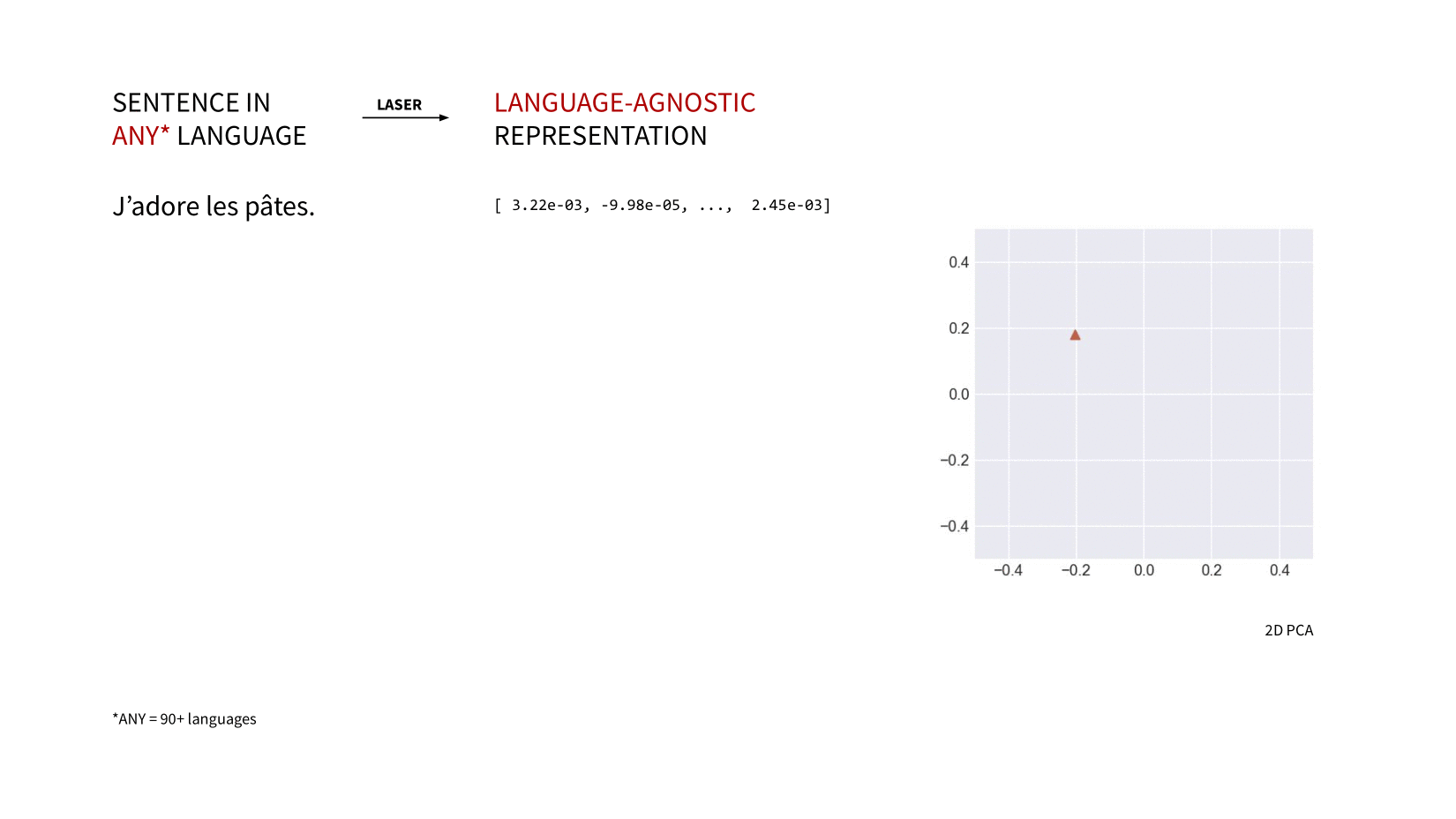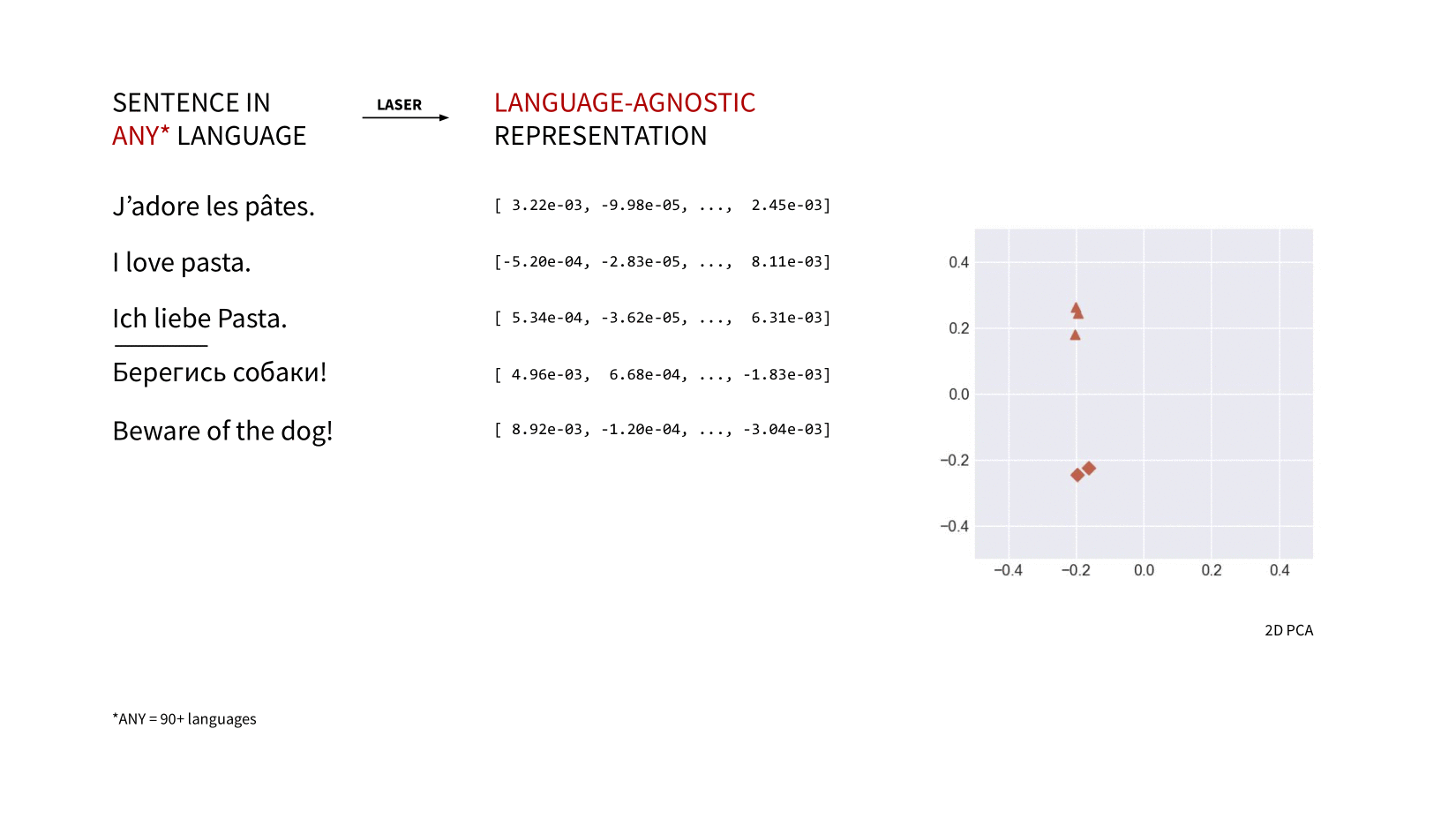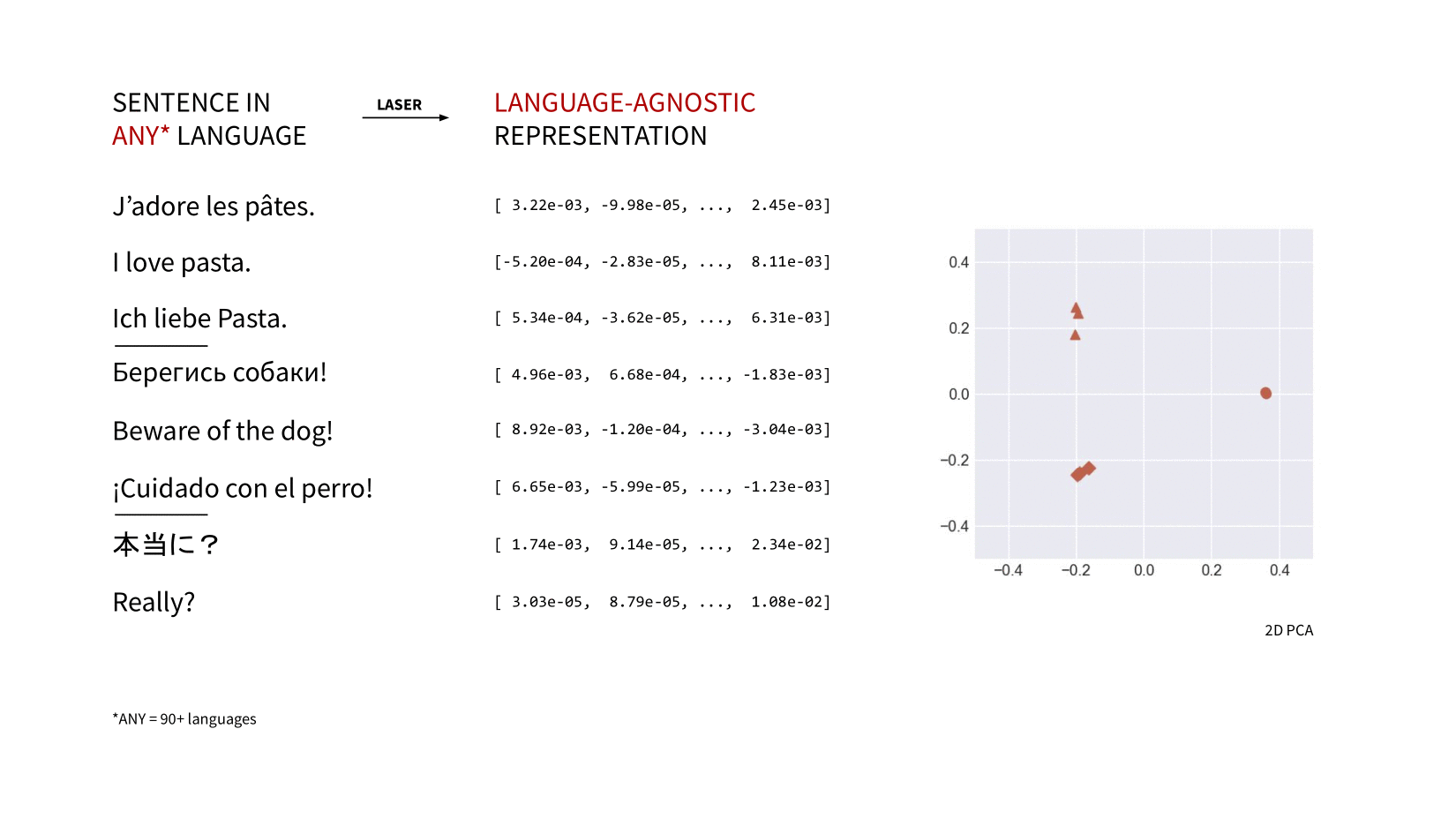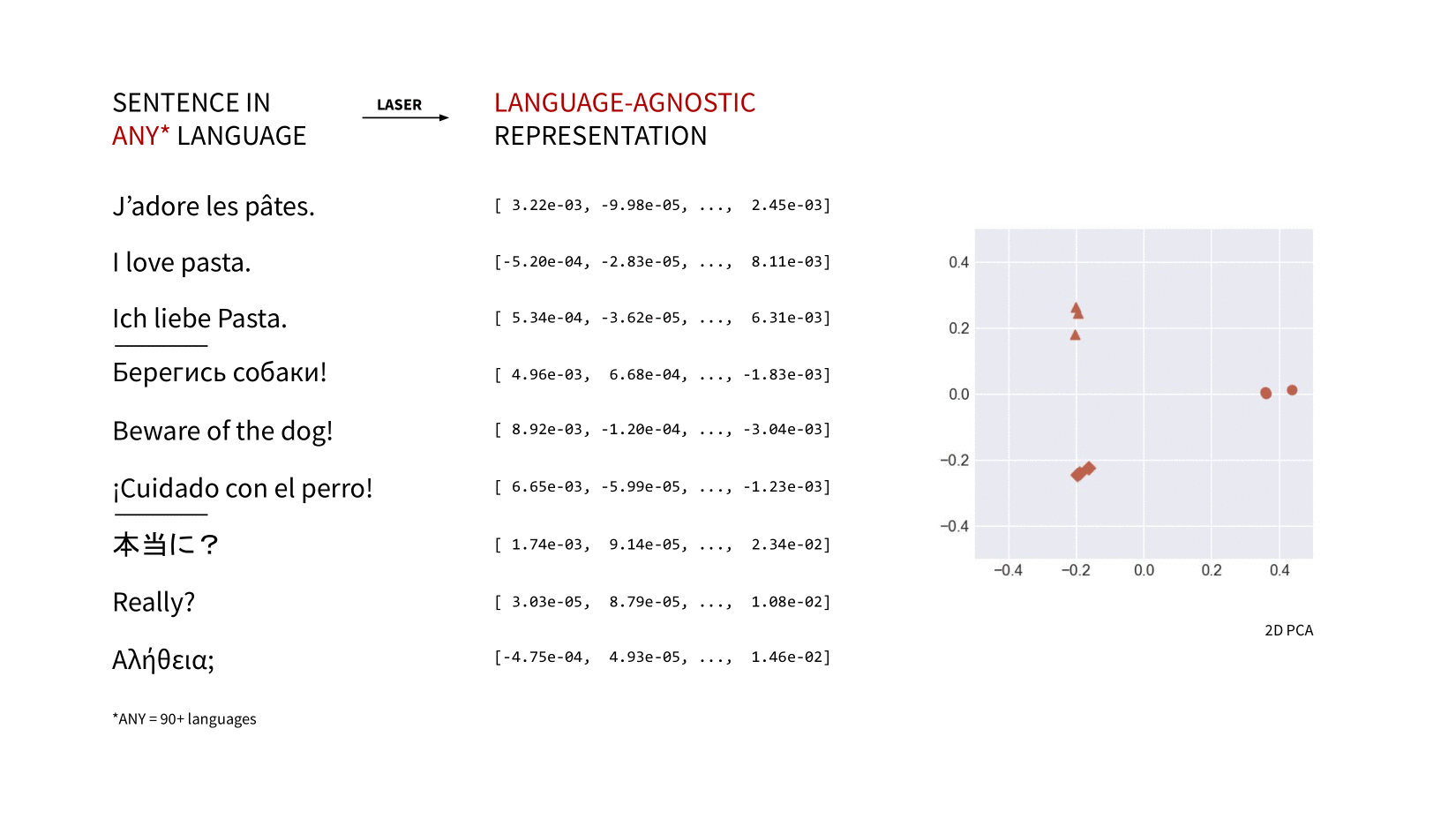
laserembeddings is a pip-packaged, production-ready port of Facebook Research's LASER (Language-Agnostic SEntence Representations) to compute multilingual sentence embeddings.
Have a look at the project's repo (master branch or this release) for the full documentation.
Getting started
Prerequisites
You'll need Python 3.6+ and PyTorch. Please refer to PyTorch installation instructions.
Installation
pip install laserembeddings
Chinese language
Chinese is not supported by default. If you need to embed Chinese sentences, please install laserembeddings with the "zh" extra. This extra includes jieba.
pip install laserembeddings[zh]
Japanese language
Japanese is not supported by default. If you need to embed Japanese sentences, please install laserembeddings with the "ja" extra. This extra includes mecab-python3 and the ipadic dictionary, which is used in the original LASER project.
If you have issues running laserembeddings on Japanese sentences, please refer to mecab-python3 documentation for troubleshooting.
pip install laserembeddings[ja]
Downloading the pre-trained models
python -m laserembeddings download-models
This will download the models to the default data directory next to the source code of the package. Use python -m laserembeddings download-models path/to/model/directory to download the models to a specific location.
Usage
from laserembeddings import Laser
laser = Laser()
# if all sentences are in the same language:
embeddings = laser.embed_sentences(
['let your neural network be polyglot',
'use multilingual embeddings!'],
lang='en') # lang is only used for tokenization
# embeddings is a N*1024 (N = number of sentences) NumPy array
If the sentences are not in the same language, you can pass a list of language codes:
embeddings = laser.embed_sentences(
['I love pasta.',
"J'adore les pâtes.",
'Ich liebe Pasta.'],
lang=['en', 'fr', 'de'])
If you downloaded the models into a specific directory:
from laserembeddings import Laser
path_to_bpe_codes = ...
path_to_bpe_vocab = ...
path_to_encoder = ...
laser = Laser(path_to_bpe_codes, path_to_bpe_vocab, path_to_encoder)
# you can also supply file objects instead of file paths
If you want to pull the models from S3:
from io import BytesIO, StringIO
from laserembeddings import Laser
import boto3
s3 = boto3.resource('s3')
MODELS_BUCKET = ...
f_bpe_codes = StringIO(s3.Object(MODELS_BUCKET, 'path_to_bpe_codes.fcodes').get()['Body'].read().decode('utf-8'))
f_bpe_vocab = StringIO(s3.Object(MODELS_BUCKET, 'path_to_bpe_vocabulary.fvocab').get()['Body'].read().decode('utf-8'))
f_encoder = BytesIO(s3.Object(MODELS_BUCKET, 'path_to_encoder.pt').get()['Body'].read())
laser = Laser(f_bpe_codes, f_bpe_vocab, f_encoder)
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file laserembeddings-1.1.2.tar.gz.
File metadata
- Download URL: laserembeddings-1.1.2.tar.gz
- Upload date:
- Size: 12.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.1.11 CPython/3.9.2 Darwin/21.1.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1d0edf86c3ec800d9715d3dd530a04c1a4022ffc355b6d91d1ea6b23bd47a2fb
|
|
| MD5 |
22ad3225289be7ed7822bfe5ee0163f1
|
|
| BLAKE2b-256 |
d1d4334569ff2a318e8d587506d4dd1b54260b2391a5759e0614326bc17969bc
|
File details
Details for the file laserembeddings-1.1.2-py3-none-any.whl.
File metadata
- Download URL: laserembeddings-1.1.2-py3-none-any.whl
- Upload date:
- Size: 13.4 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: poetry/1.1.11 CPython/3.9.2 Darwin/21.1.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
1504af7f2a3353b75cef9ce1f6ea4260779e434906fd1b002d671477216232f7
|
|
| MD5 |
7249e0dbd691038becc5efb8634829dd
|
|
| BLAKE2b-256 |
bbc2d52b3171b53352ec5b67196b437d3fbf77b615d529ffa57b5772f84b2ad1
|







