A scalable memory system for AI agents using graph-based sharding and hierarchical clustering.

Project description
Lazzaro
Scalable Memory System Library for AI Agents
Lazzaro is a Python library that provides AI agents with long-term, scalable, and structured memory. Moving beyond simple vector databases, Lazzaro implements a graph-based memory architecture featuring semantic sharding, hierarchical clustering, and biological-inspired decay. It simulates human memory by maintaining an active context buffer, consolidating interactions into persistent structures, and evolving a multi-domain user profile.
Installation
Install the core library:
pip install lazzaro
Optional Dependencies
Enable specific providers or features:
- Google Gemini:
pip install google-generativeai - Together AI:
pip install together - LangChain:
pip install langchain-core - Autogen:
pip install pyautogen - Visualization:
pip install matplotlib plotly
Core Architecture
Lazzaro manages memory through a multi-layered graph system.
1. Memory Shards (Topic-Based Isolation)
Unlike traditional database sharding by ID, Lazzaro shards memories semantically. Each MemoryShard acts as an independent subgraph containing nodes and edges related to a specific topic (e.g., "coding", "personal health", "travel").
- Shard Inference: When new facts are extracted, Lazzaro uses an LLM to categorize them into existing or new shards.
- Retrieval Heuristic: To maintain low latency, Lazzaro prioritizes recently accessed shards and those with higher node density for initial search.
2. The Buffer Graph
The BufferGraph manages the global state of all shards and super-nodes. It handles:
- Node Integrity: Maintaining content, embeddings, salience, and access metrics.
- Edge Weighting: Tracking the strength of associations between memories based on co-occurrence and semantic similarity.
3. Hierarchical Clustering (Super-Nodes)
When a shard grows beyond a configurable threshold, Lazzaro creates "Super-Nodes". These are synthetic nodes that represent the aggregate content of a cluster.
- Accelerated Search: Retrieval begins at the super-node level to quickly narrow down relevant subgraphs.
- Abstract Reasoning: Super-nodes allow agents to access high-level summaries of broad topics without loading every individual memory.
The Memory Lifecycle
Stage 1: Short-Term Buffer
Every interaction (user message and assistant response) is initially cached in a short-term episodic buffer. This provides immediate context for the current conversation.
Stage 2: Asynchronous Consolidation
Lazzaro runs a multi-stage background process to move buffer data into long-term storage:
- Atomic Fact Extraction: An LLM extracts discrete facts from the conversation stream.
- Deduplication: New facts are compared against existing nodes in the target shard. If a match is found (cosine similarity > 0.95), the existing node's salience and access count are boosted instead of creating a duplicate.
- Graph Linking: New nodes are linked to each other (episodic link) and to semantically related existing nodes (associative link).
- Profile Update: Relevant facts are used to refine the multi-domain User Profile.
Stage 3: Temporal Decay and Pruning
Lazzaro prevents memory bloat through biological-inspired pruning:
- Sigmoidal Decay: Node salience and edge weights decrease over time. The decay follows a non-linear curve that flattens at 0.2, ensuring important memories persist longer while weak associations fade.
- Weak Edge Pruning: Edges with weights falling below a threshold (default 0.5) are automatically removed.
- Buffer Enforcement: If the total node count exceeds
max_buffer_size, the system archives the least salient nodes to maintain performance.
User Profile Evolution
Lazzaro maintains a structured Profile across five key domains:
- Preferences: Specific likes, dislikes, and technical choices.
- Personality Traits: The user's observed demeanor and values.
- Knowledge Domains: Areas where the user exhibits expertise or deep interest.
- Interaction Style: How the user prefers to communicate (e.g., concise, formal, technical).
- Key Experiences: Significant life events or project milestones.
Updates occur during consolidation, where an LLM synthesizes new interactions into existing profile fields.
Retrieval Engine
Retrieval is optimized for both speed and relevance:
- Shard Selection: Only the most relevant shards are searched based on the query.
- Hybrid Search: Combines cosine similarity of embeddings with recency weighting and salience scores.
- Associative Boosting: When a node is retrieved, its immediate neighbors in the graph receive a temporary "accessibility boost," pulling related memories into the current context.
- Query Caching: Frequent queries are cached to minimize LLM and embedding overhead.
Usage
Provider Configuration
from lazzaro.core.memory_system import MemorySystem
from lazzaro.core.providers import GeminiLLM, GeminiEmbedder
# Initialize providers
llm = GeminiLLM(api_key="API_KEY", model="gemini-1.5-flash")
embedder = GeminiEmbedder(api_key="API_KEY")
# Initialize Memory System
ms = MemorySystem(
llm_provider=llm,
embedding_provider=embedder,
enable_sharding=True,
enable_hierarchy=True,
max_buffer_size=100
)
# Chat with built-in memory retrieval
ms.start_conversation()
response = ms.chat("I'm working on a Rust project and I prefer using async-std.")
print(response)
# Finalize and trigger background consolidation
print(ms.end_conversation())
Visual Dashboard
For a high-fidelity, interactive experience, Lazzaro includes a custom web-based dashboard:
lazzaro-dashboard
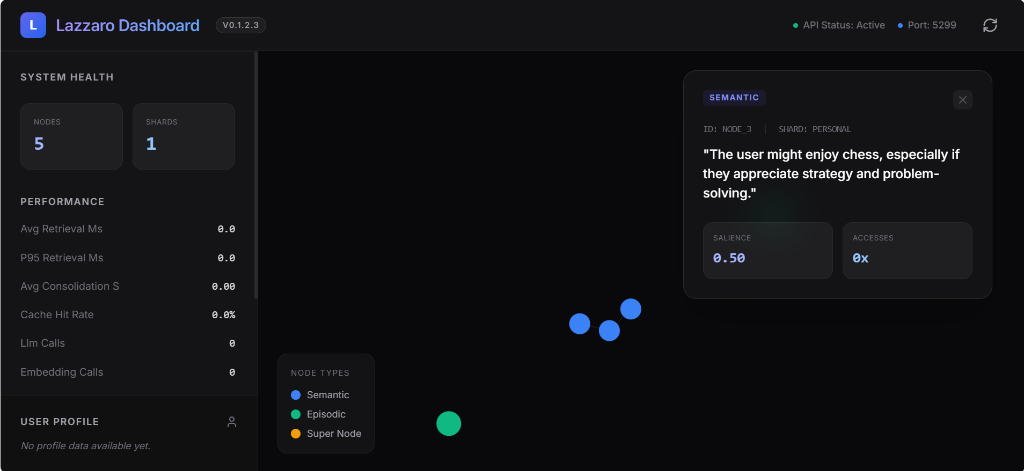
The dashboard will be available at http://localhost:5299 and features:
- Live Force-Graph: Interactive visualization of your memory shards and node relationships.
- Real-time Metrics: Monitor LLM calls, embedding costs, and retrieval latency.
- Profile Explorer: View your evolved user persona domains in a sleek side drawer.
Integrations
LangChain
from lazzaro.integrations import LazzaroLangChainMemory
from langchain.chains import ConversationChain
memory = LazzaroLangChainMemory(memory_system=ms)
chain = ConversationChain(llm=chat_model, memory=memory)
LangGraph
from lazzaro.integrations import LazzaroLangGraph
lg = LazzaroLangGraph(ms)
builder.add_node("retrieve", lg.get_memory_node())
builder.add_node("record", lg.get_record_node())
CLI Reference
Launch the interactive shell:
lazzaro-cli
Command Table
| Command | Description |
|---|---|
/start |
Manual session initialization. |
/end |
Manual session termination and consolidation trigger. |
/stats |
Display node counts, shard density, and performance metrics. |
/profile |
View evolved user profile data. |
/memories [n] |
Inspect the n most recent memory nodes. |
/consolidate |
Force immediate graph-wide consolidation. |
/config |
View and modify runtime parameters. |
/save [file] |
Export current state to JSON. |
/load [file] |
Import state from JSON. |
Parameter Reference
| Parameter | Default | Description |
|---|---|---|
auto_consolidate |
True |
Extract facts after every N conversations. |
consolidate_every |
3 |
Conversation frequency for consolidation. |
max_buffer_size |
10 |
Total nodes allowed before archiving. |
enable_async |
True |
Background thread processing for consolidation. |
enable_sharding |
True |
Use topic-based subgraph isolation. |
prune_threshold |
0.5 |
Minimum weight to retain an edge. |
load_from_disk |
True |
Restore state from db/lazzaro.pkl on startup. |
Persistence and Safety
- Atomic Persistence: Lazzaro writes to a temporary file before renaming it to
lazzaro.pklto prevent corruption during crashes. - Backup System: A
.bakfile is maintained as a fallback to the previous valid state. - JSON Export: Human-readable snapshots can be exported using
save_state().
Development
Run tests:
pytest tests/
License
This project is licensed under the MIT License.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file lazzaro-0.2.0.tar.gz.
File metadata
- Download URL: lazzaro-0.2.0.tar.gz
- Upload date:
- Size: 37.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
dc0d342869c1eb56314937ebfbaa93592235749e90366661a7a1aa2c38806ee3
|
|
| MD5 |
2fc13d81c2aa75634a4a751617dd8b19
|
|
| BLAKE2b-256 |
84bb45a6dd776af9e761f19561970860e86c6316945080bb7058d02daa4951a0
|
File details
Details for the file lazzaro-0.2.0-py3-none-any.whl.
File metadata
- Download URL: lazzaro-0.2.0-py3-none-any.whl
- Upload date:
- Size: 36.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
dc97b75a8b594ecc7fa79dcf47acd3d130da026ad8b22d4068028cf02679e7ac
|
|
| MD5 |
13d645e1c7eb4acd6fe2eb00d2d16898
|
|
| BLAKE2b-256 |
b3da3ef3634e8e7df5d1d0f10c9a534faa6bfe8b6e11ae1e9623f2b8a3bd6250
|







