Lightning HPO

Project description
Lightning HPO & Research Studio App




Lightning HPO provides a pythonic implementation for Scalable Hyperparameter Tuning.
This library relies on Optuna for providing state-of-the-art sampling hyper-parameters algorithms and efficient experiment pruning strategies.
This is built upon the highly scalable and distributed Lightning App framework from lightning.ai.
The Research Studio App relies on Lightning HPO to provide abilities to run, show, stop, delete Sweeps, Notebooks, Tensorboard, etc.
Learn more here.
Installation
Create a new virtual environment with python 3.8+
python -m venv .venv
source .venv/bin/activate
Clone and install lightning-hpo.
git clone https://github.com/Lightning-AI/lightning-hpo && cd lightning-hpo
pip install -e . -r requirements.txt --find-links https://download.pytorch.org/whl/cpu/torch_stable.html
Make sure everything works fine.
python -m lightning run app app.py
Getting started
Imagine you want to optimize a simple function called objective inside a objective.py file.
def objective(x: float):
return (x - 2) ** 2
Import a Sweep component, provide the path to your script and what you want to optimize on.
import os.path as ops
from lightning import LightningApp
from lightning_hpo import Sweep
from lightning_hpo.distributions import Uniform
app = LightningApp(
Sweep(
script_path="objective.py",
total_experiments=50,
parallel_experiments=10,
direction="maximize",
distributions={"x": Uniform(-10, 10)},
)
)
Now, you can optimize it locally.
python -m lightning run app examples/1_app_agnostic.py
or with --cloud to run it in the cloud.
python -m lightning run app examples/1_app_agnostic.py --cloud
Note: Locally, each experiment runs into its own process, so there is an overhead if your objective is quick to run.
Find the example here
PyTorch Lightning Users
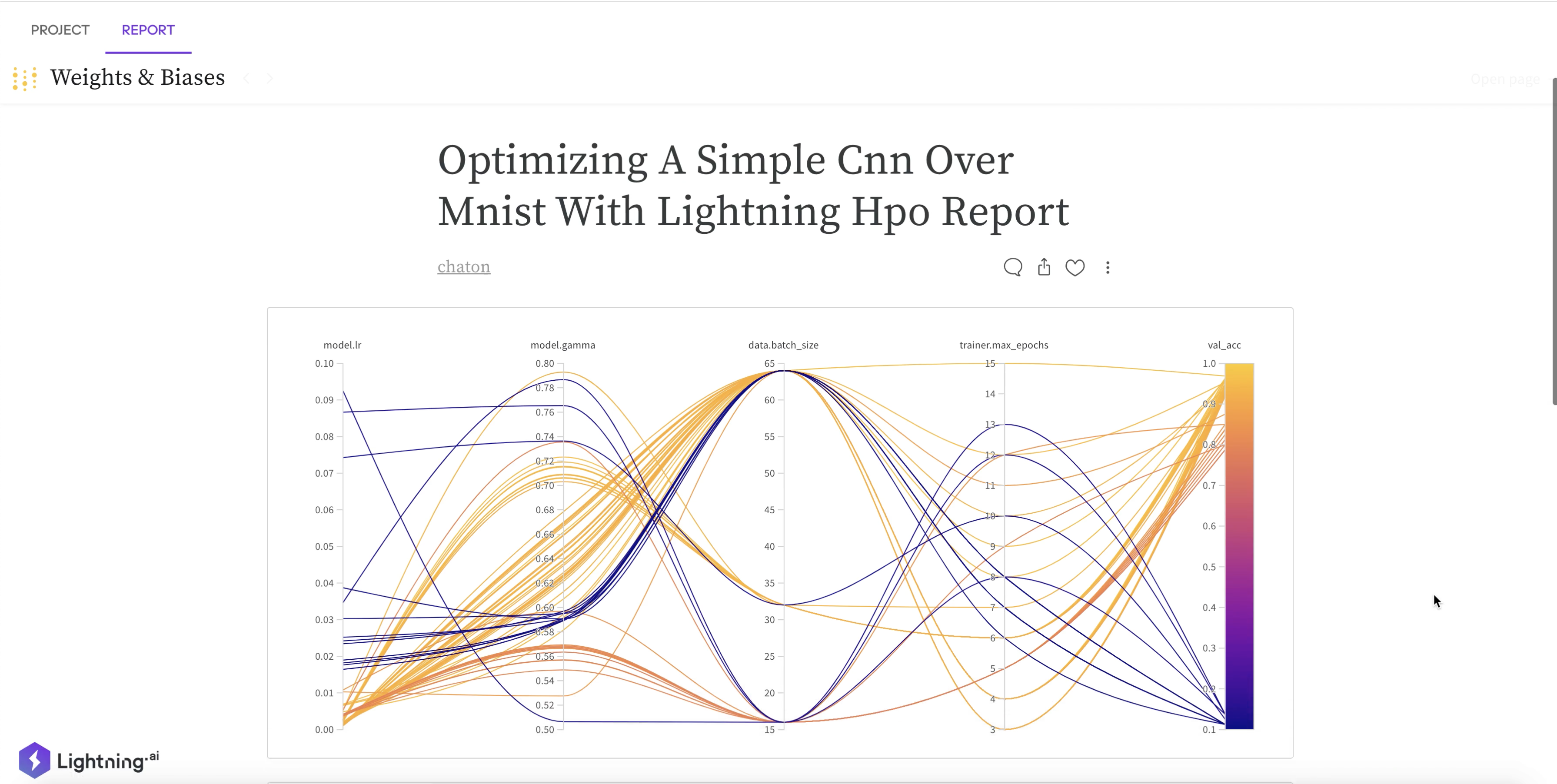
Here is how to launch 100 experiments 10 at a times with 2 nodes of 4 GPUs for each in the cloud.
import os.path as ops
from lightning import LightningApp
from lightning_hpo.algorithm import OptunaAlgorithm
from lightning_hpo import Sweep, CloudCompute
from lightning_hpo.distributions import Uniform, IntUniform, Categorical, LogUniform
app = LightningApp(
Sweep(
script_path="train.py",
total_experiments=100,
parallel_experiments=10,
distributions={
"model.lr": LogUniform(0.001, 0.1),
"model.gamma": Uniform(0.5, 0.8),
"data.batch_size": Categorical([16, 32, 64]),
"trainer.max_epochs": IntUniform(3, 15),
},
algorithm=OptunaAlgorithm(direction="maximize"),
cloud_compute=CloudCompute("gpu-fast-multi", count=2), # 2 * 4 V100
framework="pytorch_lightning",
logger="wandb",
sweep_id="Optimizing a Simple CNN over MNIST with Lightning HPO",
)
)
python -m lightning run app examples/2_app_pytorch_lightning.py --cloud --env WANDB_ENTITY={WANDB_ENTITY} --env WANDB_API_KEY={WANDB_API_KEY}
Find the example here
Train a 1B+ Large Language Modeling Model with Multi Node Training
Run the App in the cloud
lightning run app app.py --cloud
Connect to the App once ready.
lightning connect {APP_NAME} -y
Below is an example of how you can train a 1.6B parameter GPT2 transformer model using Lightning Transformers and DeepSpeed using the Lightning Transformers library.
import pytorch_lightning as pl
from lightning_transformers.task.nlp.language_modeling import LanguageModelingDataModule, LanguageModelingTransformer
from transformers import AutoTokenizer
model_name = "gpt2-xl"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = LanguageModelingTransformer(
pretrained_model_name_or_path=model_name,
tokenizer=tokenizer,
deepspeed_sharding=True, # defer initialization of the model to shard/load pre-train weights
)
dm = LanguageModelingDataModule(
batch_size=1,
dataset_name="wikitext",
dataset_config_name="wikitext-2-raw-v1",
tokenizer=tokenizer,
)
trainer = pl.Trainer(
accelerator="gpu",
devices="auto",
strategy="deepspeed_stage_3",
precision=16,
max_epochs=1,
)
trainer.fit(model, dm)
Run the following command to run a multi node training (2 nodes of 4 V100 GPUS each).
lightning run experiment big_model.py --requirements deepspeed lightning-transformers==0.2.3 --num_nodes=2 --cloud_compute=gpu-fast-multi --disk_size=80
Convert raw Optuna to Lightning HPO
Below, we are going to convert Optuna Efficient Optimization Algorithms into a Lightning App.
The Optuna example optimize the value (e.g learning-rate) of a SGDClassifier from sklearn trained over the Iris Dataset.
The example above has been re-organized below in order to run as Lightning App.
from lightning import LightningApp
from sklearn import datasets
import optuna
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import train_test_split
from lightning_hpo.distributions import LogUniform
from lightning_hpo.algorithm import OptunaAlgorithm
from lightning_hpo import Objective, Sweep
class MyObjective(Objective):
def objective(self, alpha: float):
iris = datasets.load_iris()
classes = list(set(iris.target))
train_x, valid_x, train_y, valid_y = train_test_split(iris.data, iris.target, test_size=0.25, random_state=0)
clf = SGDClassifier(alpha=alpha)
self.monitor = "accuracy"
for step in range(100):
clf.partial_fit(train_x, train_y, classes=classes)
intermediate_value = clf.score(valid_x, valid_y)
# WARNING: Assign to reports,
# so the state is instantly sent to the flow.
self.reports = self.reports + [[intermediate_value, step]]
self.best_model_score = clf.score(valid_x, valid_y)
app = LightningApp(
Sweep(
objective_cls=MyObjective,
total_experiments=20,
algorithm=OptunaAlgorithm(
optuna.create_study(pruner=optuna.pruners.MedianPruner()),
direction="maximize",
),
distributions={"alpha": LogUniform(1e-5, 1e-1)}
)
)
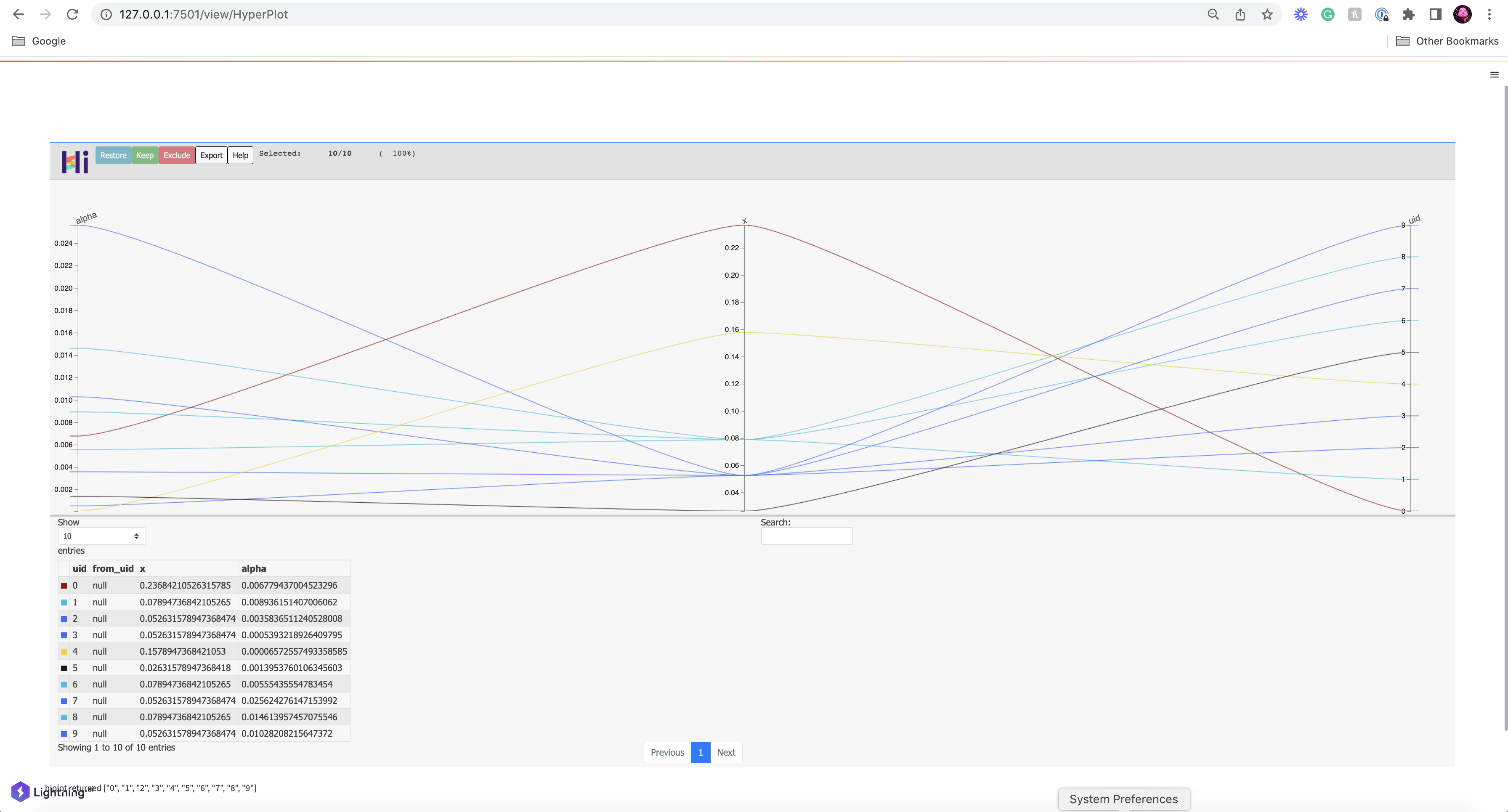
python -m lightning run app examples/3_app_sklearn.py
As you can see, several experimentss were pruned (stopped) before they finished all of the iterations. Same as when using pure optuna.
A new study created in memory with name: no-name-a93d848e-a225-4df3-a9c3-5f86680e295d
Experiment 0 finished with value: 0.23684210526315785 and parameters: {'alpha': 0.006779437004523296}. Best is experiment 0 with value: 0.23684210526315785.
Experiment 1 finished with value: 0.07894736842105265 and parameters: {'alpha': 0.008936151407006062}. Best is experiment 1 with value: 0.07894736842105265.
Experiment 2 finished with value: 0.052631578947368474 and parameters: {'alpha': 0.0035836511240528008}. Best is experiment 2 with value: 0.052631578947368474.
Experiment 3 finished with value: 0.052631578947368474 and parameters: {'alpha': 0.0005393218926409795}. Best is experiment 2 with value: 0.052631578947368474.
Experiment 4 finished with value: 0.1578947368421053 and parameters: {'alpha': 6.572557493358585e-05}. Best is experiment 2 with value: 0.052631578947368474.
Experiment 5 finished with value: 0.02631578947368418 and parameters: {'alpha': 0.0013953760106345603}. Best is experiment 5 with value: 0.02631578947368418.
Trail 6 pruned.
Trail 7 pruned.
Trail 8 pruned.
Trail 9 pruned.
Experiment 10 finished with value: 0.07894736842105265 and parameters: {'alpha': 0.00555435554783454}. Best is experiment 5 with value: 0.02631578947368418.
Trail 11 pruned.
Experiment 12 finished with value: 0.052631578947368474 and parameters: {'alpha': 0.025624276147153992}. Best is experiment 5 with value: 0.02631578947368418.
Experiment 13 finished with value: 0.07894736842105265 and parameters: {'alpha': 0.014613957457075546}. Best is experiment 5 with value: 0.02631578947368418.
Trail 14 pruned.
Trail 15 pruned.
Trail 16 pruned.
Experiment 17 finished with value: 0.052631578947368474 and parameters: {'alpha': 0.01028208215647372}. Best is experiment 5 with value: 0.02631578947368418.
Trail 18 pruned.
Trail 19 pruned.
Find the example here
Select your logger
Lightning HPO supports Wandb and Streamlit by default.
import optuna
Sweep(..., logger="wandb")
python -m lightning run app app.py --env WANDB_ENTITY=YOUR_USERNAME --env WANDB_API_KEY=YOUR_API_KEY --cloud
Use advanced algorithms with your Lightning App
Here is how to use the latest research such as Hyperband paper
from lightning_hpo.algorithm import OptunaAlgorithm
import optuna
Sweep(
algorithm=OptunaAlgorithm(
optuna.create_study(
direction="maximize",
pruner=optuna.pruners.HyperbandPruner(
min_resource=1,
max_resource=3,
reduction_factor=3,
),
)
)
)
Learn more here
The Research Studio App
In terminal 1, run the Lightning App.
lightning run app app.py --env WANDB_ENTITY={ENTITY} --env WANDB_API_KEY={API_KEY}
In terminal 2, connect to the Lightning App and run your first sweep or notebook.
lightning connect localhost
lightning --help
You are connected to the local Lightning App.
Usage: lightning [OPTIONS] COMMAND [ARGS]...
--help Show this message and exit.
Lightning App Commands
delete sweep
download artifacts
run notebook
run sweep
show artifacts
show notebooks
show sweeps
stop notebook
stop sweep
cd examples/scripts
lightning run sweep train.py \
--total_experiments=100 \
--parallel_experiments=5 \
--logger="tensorboard" \
--direction=maximize \
--cloud_compute=cpu-medium \
--model.lr="log_uniform(0.001, 0.01)" \
--model.gamma="uniform(0.5, 0.8)" \
--requirements torchvision wandb 'jsonargparse[signatures]' \
--data.batch_size="categorical([32, 64])" \
--algorithm="bayesian"


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file lightning_hpo-0.0.3.tar.gz.
File metadata
- Download URL: lightning_hpo-0.0.3.tar.gz
- Upload date:
- Size: 1.0 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
43e1d928aae0608d9de3e2ee41ac60bec0bdb444f2573e5592bceca9b2f01bb1
|
|
| MD5 |
713925fb53ac22a44bf379a3f5eb321b
|
|
| BLAKE2b-256 |
455aaead765a9b5b1009789e40ae129ba48cf93340457052fdcd392d84d8f3b6
|
File details
Details for the file lightning_hpo-0.0.3-py3-none-any.whl.
File metadata
- Download URL: lightning_hpo-0.0.3-py3-none-any.whl
- Upload date:
- Size: 1.1 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.9.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
32666f060a0367af889fab490767bc22af8affe58fbca2fab10719ae03ed7f94
|
|
| MD5 |
00bc83e78fd76814fbc639c0d11877b7
|
|
| BLAKE2b-256 |
e3267819be0fa0cbe46b6176d4c6f60299614e296c8166492a1f1e672eefd1ce
|







