Scrape public available jobs on Linkedin using headless browser

Project description
linkedin-jobs-scraper
Scrape public available jobs on Linkedin using headless browser. For each job, the following fields are extracted:
job_id,link,apply_link,title,company,company_link,company_img_link,place,description,description_html,date,insights.It's also available an equivalent npm package.
⚠ DISCLAIMER This package is meant for personal or educational use only. All the data extracted by using this package is publicly available on the LinkedIn website and it remains owned by LinkedIn company. I am not responsible in any way for the inappropriate use of data extracted through this library.
Table of Contents
- Requirements
- Installation
- Usage
- Anonymous vs authenticated session
- Rate limiting
- Proxy mode
- Filters
- Company filter
- Logging
- License
Requirements
- Chrome or Chromium
- Chromedriver: latest version tested is
125.0.6422.141(Dockerfile) - Python >= 3.7
Installation
Install package:
pip install linkedin-jobs-scraper
Usage
import logging
from linkedin_jobs_scraper import LinkedinScraper
from linkedin_jobs_scraper.events import Events, EventData, EventMetrics
from linkedin_jobs_scraper.query import Query, QueryOptions, QueryFilters
from linkedin_jobs_scraper.filters import RelevanceFilters, TimeFilters, TypeFilters, ExperienceLevelFilters, \
OnSiteOrRemoteFilters, SalaryBaseFilters
# Change root logger level (default is WARN)
logging.basicConfig(level=logging.INFO)
# Fired once for each successfully processed job
def on_data(data: EventData):
print('[ON_DATA]', data.title, data.company, data.company_link, data.date, data.date_text, data.link, data.insights,
len(data.description))
# Fired once for each page (25 jobs)
def on_metrics(metrics: EventMetrics):
print('[ON_METRICS]', str(metrics))
def on_error(error):
print('[ON_ERROR]', error)
def on_end():
print('[ON_END]')
scraper = LinkedinScraper(
chrome_executable_path=None, # Custom Chrome executable path (e.g. /foo/bar/bin/chromedriver)
chrome_binary_location=None, # Custom path to Chrome/Chromium binary (e.g. /foo/bar/chrome-mac/Chromium.app/Contents/MacOS/Chromium)
chrome_options=None, # Custom Chrome options here
headless=True, # Overrides headless mode only if chrome_options is None
max_workers=1, # How many threads will be spawned to run queries concurrently (one Chrome driver for each thread)
slow_mo=0.5, # Slow down the scraper to avoid 'Too many requests 429' errors (in seconds)
page_load_timeout=40 # Page load timeout (in seconds)
)
# Add event listeners
scraper.on(Events.DATA, on_data)
scraper.on(Events.ERROR, on_error)
scraper.on(Events.END, on_end)
queries = [
Query(
options=QueryOptions(
limit=27 # Limit the number of jobs to scrape.
)
),
Query(
query='Engineer',
options=QueryOptions(
locations=['United States', 'Europe'],
apply_link=True, # Try to extract apply link (easy applies are skipped). If set to True, scraping is slower because an additional page must be navigated. Default to False.
skip_promoted_jobs=True, # Skip promoted jobs. Default to False.
page_offset=2, # How many pages to skip
limit=5,
filters=QueryFilters(
company_jobs_url='https://www.linkedin.com/jobs/search/?f_C=1441%2C17876832%2C791962%2C2374003%2C18950635%2C16140%2C10440912&geoId=92000000', # Filter by companies.
relevance=RelevanceFilters.RECENT,
time=TimeFilters.MONTH,
type=[TypeFilters.FULL_TIME, TypeFilters.INTERNSHIP],
on_site_or_remote=[OnSiteOrRemoteFilters.REMOTE],
experience=[ExperienceLevelFilters.MID_SENIOR],
base_salary=SalaryBaseFilters.SALARY_100K
)
)
),
]
scraper.run(queries)
Anonymous vs authenticated session
⚠ WARNING: due to lack of time, anonymous session strategy is no longer maintained. If someone wants to keep support for this feature and become a project maintainer, please be free to pm me.
By default the scraper will run in anonymous mode (no authentication required). In some environments (e.g. AWS or Heroku) this may be not possible though. You may face the following error message:
Scraper failed to run in anonymous mode, authentication may be necessary for this environment.
In that case the only option available is to run using an authenticated session. These are the steps required:
- Login to LinkedIn using an account of your choice.
- Open Chrome developer tools:
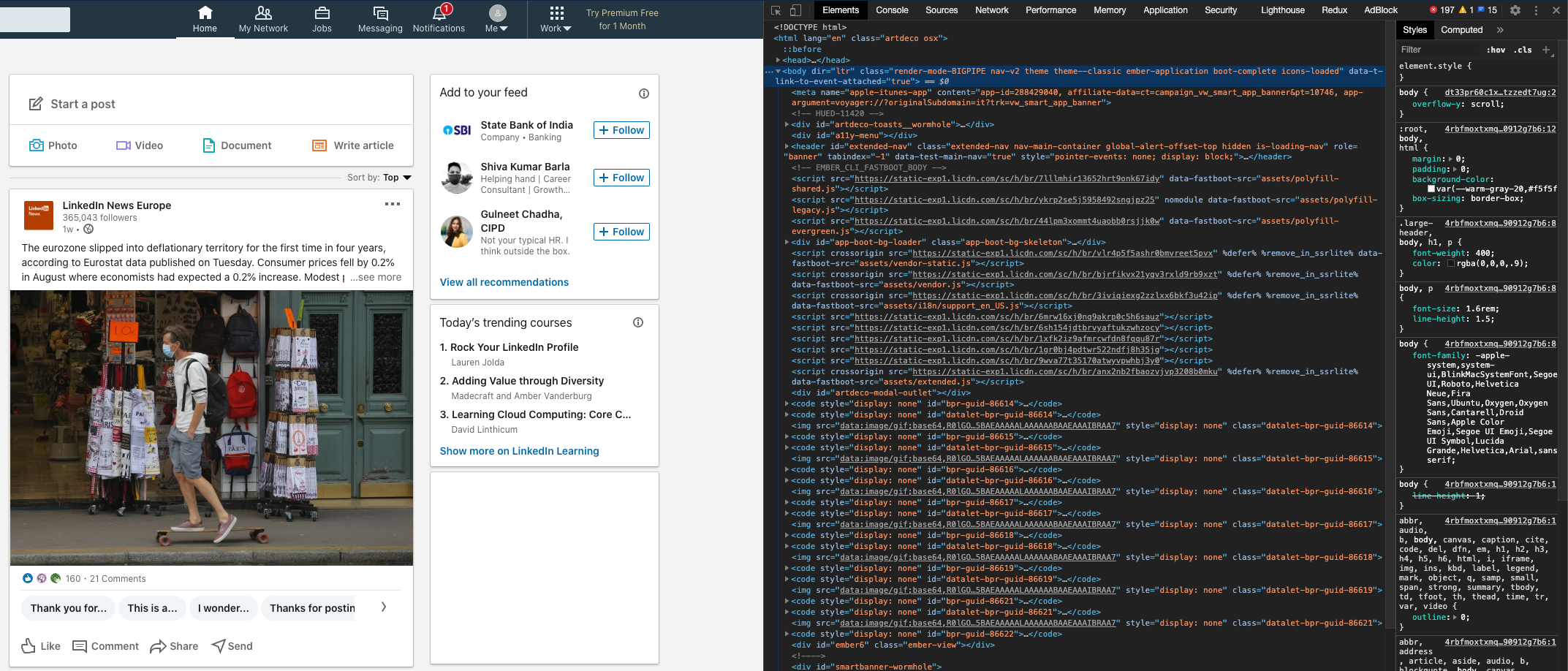
- Go to tab
Application, then from left panel selectStorage->Cookies->https://www.linkedin.com. In the main view locate row with nameli_atand copy content from the columnValue.
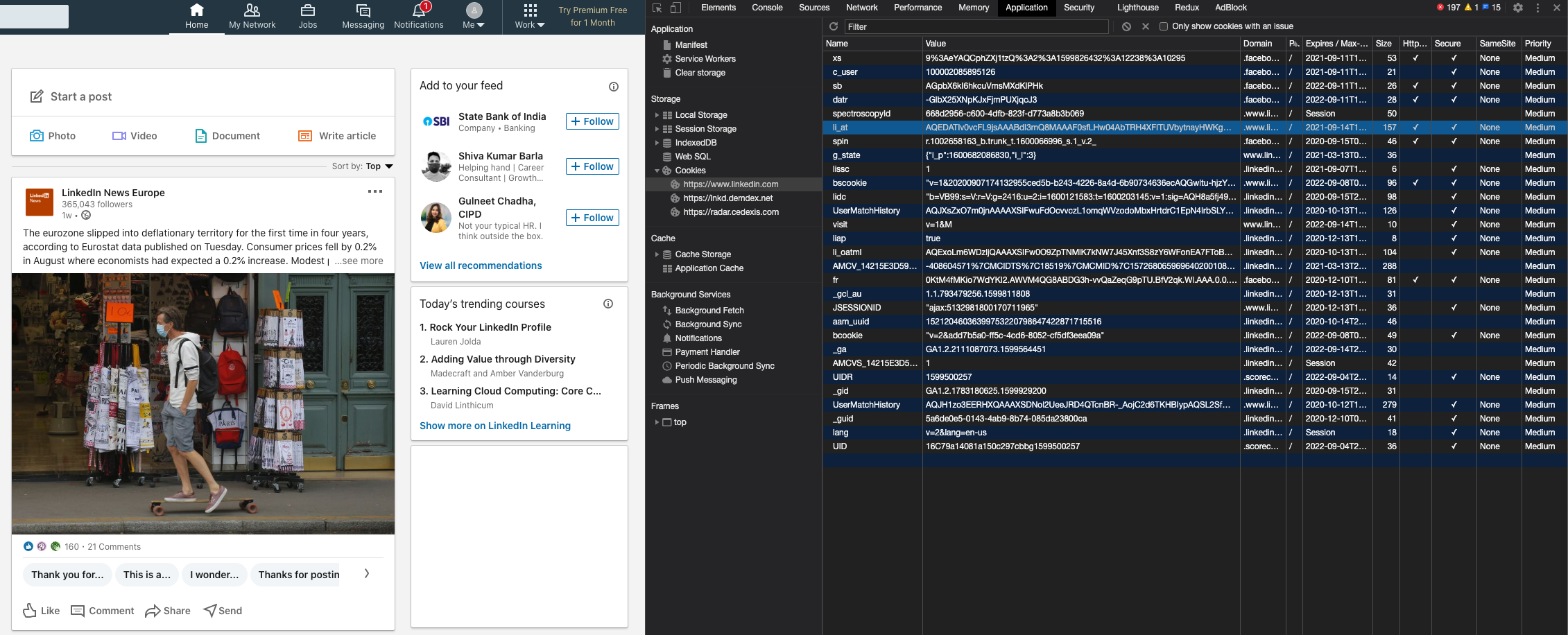
- Set the environment variable
LI_AT_COOKIEwith the value obtained in step 3, then run your application as normal. Example:
LI_AT_COOKIE=<your li_at cookie value here> python your_app.py
Rate limiting
You may experience failing requests with the status code 429. This means you are sending too many request to the server and they are being throttled. You can overcome this by:
- Trying a higher value for
slow_moparameter (this will slow down scraper execution). - Reducing the value of
max_workersto limit concurrency. I recommend to use no more than one worker in authenticated mode.
The right value for slow_mo parameter largely depends on rate-limiting settings on Linkedin servers (and this can
vary over time). For the time being, I suggest a value of at least 1.3 in anonymous mode and 0.5 in authenticated
mode.
Filters
It is possible to customize queries with the following filters:
- RELEVANCE:
RELEVANTRECENT
- TIME:
DAYWEEKMONTHANY
- TYPE:
FULL_TIMEPART_TIMETEMPORARYCONTRACT
- EXPERIENCE LEVEL:
INTERNSHIPENTRY_LEVELASSOCIATEMID_SENIORDIRECTOR
- ON SITE OR REMOTE:
ON_SITEREMOTEHYBRID
- INDUSTRY:
AIRLINES_AVIATIONBANKINGCIVIL_ENGINEERINGCOMPUTER_GAMESENVIRONMENTAL_SERVICESELECTRONIC_MANUFACTURINGFINANCIAL_SERVICESINFORMATION_SERVICESINVESTMENT_BANKINGINVESTMENT_MANAGEMENTIT_SERVICESLEGAL_SERVICESMOTOR_VEHICLESOIL_GASSOFTWARE_DEVELOPMENTSTAFFING_RECRUITINGTECHNOLOGY_INTERNET
- BASE SALARY:
SALARY_40KSALARY_60KSALARY_80KSALARY_100KSALARY_120KSALARY_140KSALARY_160KSALARY_180KSALARY_200K
- COMPANY:
- See below
See the following example for more details:
from linkedin_jobs_scraper.query import Query, QueryOptions, QueryFilters
from linkedin_jobs_scraper.filters import RelevanceFilters, TimeFilters, TypeFilters, ExperienceLevelFilters, \
OnSiteOrRemoteFilters, IndustryFilters, SalaryBaseFilters
query = Query(
query='Engineer',
options=QueryOptions(
locations=['United States'],
apply_link=True,
skip_promoted_jobs=True,
limit=5,
filters=QueryFilters(
relevance=RelevanceFilters.RECENT,
time=TimeFilters.MONTH,
type=[TypeFilters.FULL_TIME, TypeFilters.INTERNSHIP],
experience=[ExperienceLevelFilters.INTERNSHIP, ExperienceLevelFilters.MID_SENIOR],
on_site_or_remote=[OnSiteOrRemoteFilters.REMOTE],
industry=[IndustryFilters.IT_SERVICES],
base_salary=SalaryBaseFilters.SALARY_100K
)
)
)
Industry Filter
You will probably need to add the industry filter to the IndustryFilters class in filters.py
To find the numeric code for the industry:
- Perform the search on LinkedIn in a browser, with the industry filter applied.
- The numeric code is in the URL, immediately after
f_I. For example URL https://www.linkedin.com/jobs/search/?currentJobId=3661007408&distance=25&f_E=3%2C4&f_I=43%2C46%2C41%2C45&f_JT=F%2CC&geoId=102257491&keywords=Product%20Owner&refresh=true contains textf_I=43%2C46%2C41%2C45indicating a filter is applied on industry codes 43, 46, 41 and 45.
Company Filter
It is also possible to filter by company using the public company jobs url on LinkedIn. To find this url you have to:
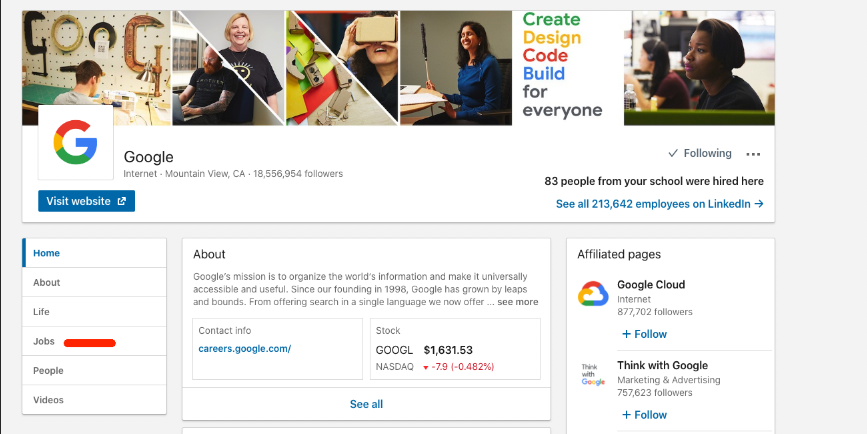
- Login to LinkedIn using an account of your choice.
- Go to the LinkedIn page of the company you are interested in (e.g. https://www.linkedin.com/company/google).
- Click on
jobsfrom the left menu.
- Scroll down and locate
See all jobsorSee jobsbutton.
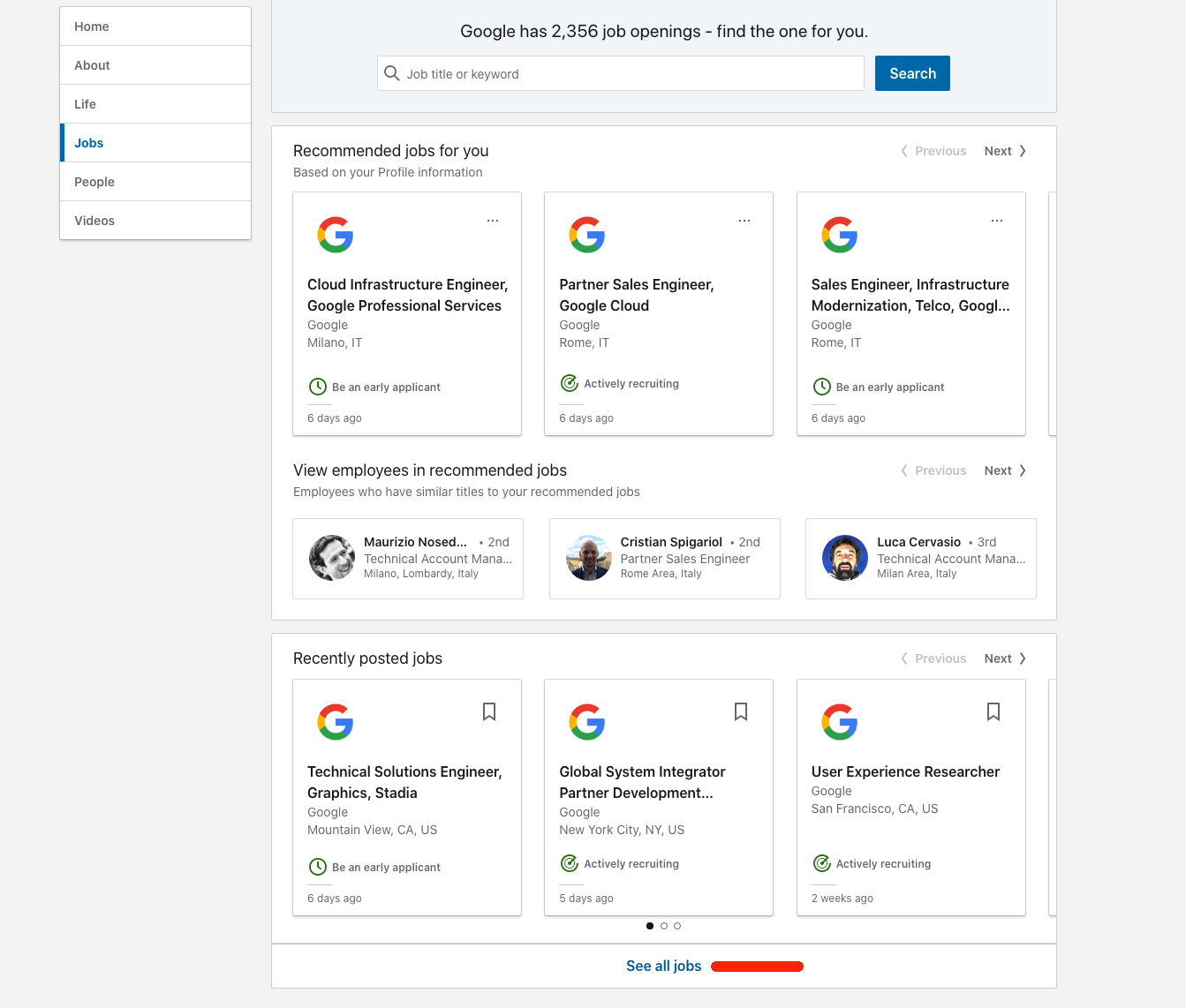
- Right click and copy link address (or navigate the link and copy it from the address bar).
- Paste the link address in code as follows:
query = Query(
options=QueryOptions(
filters=QueryFilters(
# Paste link below
company_jobs_url='https://www.linkedin.com/jobs/search/?f_C=1441%2C17876832%2C791962%2C2374003%2C18950635%2C16140%2C10440912&geoId=92000000',
)
)
)
Logging
Package logger can be retrieved using namespace li:scraper. Default level is INFO.
It is possible to change logger level using environment variable LOG_LEVEL or in code:
import logging
# Change root logger level (default is WARN)
logging.basicConfig(level = logging.DEBUG)
# Change package logger level
logging.getLogger('li:scraper').setLevel(logging.DEBUG)
# Optional: change level to other loggers
logging.getLogger('urllib3').setLevel(logging.WARN)
logging.getLogger('selenium').setLevel(logging.WARN)
License
If you like the project and want to contribute you can donate something here!
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file linkedin-jobs-scraper-5.0.2.tar.gz.
File metadata
- Download URL: linkedin-jobs-scraper-5.0.2.tar.gz
- Upload date:
- Size: 25.7 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
028a404f8cea27cac503dd13d23e9cd092091250db89defaefee0b6aa270325f
|
|
| MD5 |
bf4291b57ecee1dd47db2e614d7a5fca
|
|
| BLAKE2b-256 |
576c1e16f9239cc4bbfc98c54acb32e52088cb185be1f9b1087cf95c20aa49b6
|
File details
Details for the file linkedin_jobs_scraper-5.0.2-py3-none-any.whl.
File metadata
- Download URL: linkedin_jobs_scraper-5.0.2-py3-none-any.whl
- Upload date:
- Size: 28.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9be99a3548dc23f7348dc9adfe6e2e71407a2fd3d7b6d9425aeb7a74071423b0
|
|
| MD5 |
7983701e36aac6e9d4fd0cea44a6ad44
|
|
| BLAKE2b-256 |
d5fdfd5a22aceeead726dfb3bee65bb4aae4d0b6e46dc756f37cff1b2d7e1cc0
|







