Lithos: plotting package for categorical and nested data.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description




Lithos
Lithos is a simple plotting package written in Python and intended for scientific publications. There is a strong focus on plotting clustered data within groups. This is particularly useful for studies where many neurons are measured per mouse or subjects per location or repeated measures per subject. Data can be transformed (log10, inverse, etc) easily and/or aggregated (mean, median, circular mean, etc) within Lithos. You can also design plots, save the metadata and load the metadata for us in other plots making this comparable to GraphPad "magic" function.
Below is a quick tutorial of how to use Lithos. There are two main classes: CategoricalPlot for plotting means, medians, etc and LinePlot for plotting continuous variables like KDEs, scatterplots. Both of these classes have a number of methods that can be used to transform the data, aggregate it, design plots, save metadata, etc. There are a variety of ways you can format the plots to generate visual appealing plots that greatly simplifies what you would have to do in other packages. Lithos takes Pandas dataframes, dictionaries, and 2D numpy arrays as input.
Installation
Install from PyPI
pip install lithos
Install from github (need to have git installed)
pip install git+https://github.com/LarsHenrikNelson/Lithos.git
Install locally
- Download the package
- Open a shell or terminal
- Activate your python environment
- Type
cd - Then drag and drop the folder into the terminal and hit enter
- Then type
pip install .and hit enter
Example plots
Some example plots with synthetic data.
Import the plots and data generator (or use your own data).
from lithos import CategoricalPlot, LinePlot, Group, Subgroup, UniqueGroups
from lithos.utils import create_synthetic_data
import matplotlib.pyplot as plt
Create some data
df is a dictionary but you could convert it to a Pandas DataFrame
df = create_synthetic_data(n_groups=2, n_subgroups=6, n_points=30)
Formatting a plot
Show the plot with default settings. You may notice several differences in the default settings compared to Matplotlib and Seaborn. Labels are larger since and the y-axis (as well as the x-axis) end at the ticks.
plot = (
CategoricalPlot(data=df)
.grouping(
group="grouping_1",
subgroup="grouping_2",
group_spacing=0.9,
)
.plot_data(y="y", ylabel="test", title="")
.plot()
)
Update labels, axis formating, etc.
plot = (
CategoricalPlot(data=df)
.grouping(
group="grouping_1",
subgroup="grouping_2",
group_spacing=0.9,
)
.labels(
labelsize=22,
titlesize=22,
ticklabel_size=20,
font="DejaVu Sans",
label_fontweight="normal",
tick_fontweight="light",
title_fontweight="bold",
xlabel_rotation="vertical",
ytick_rotation="horizontal",
)
.axis_format(linewidth=0.5, tickwidth=0.5, ticklength=2)
.plot_data(y="y", ylabel="test", title="Test")
.plot()
)
If you like the format then just save the metadata with name of your choice
plot.save_metadata("my_plot")
Then just load the metadata in the future and your plots will be formatted the same way without having to write the code again. You can also set the metadata directory to where ever you want incase you want to set your metadata directory to a folder that is synchronized with a cloud backupkup, like OneDrive or Dropbox. This way your metadata is accesible from where ever you want without forcing you to pay for yet another subscription. Additionally you can choose a folder that is shared with many people if you are working on a collaborative project. Just use the .set_metadata_dir() method on the plot object or use the set_metadata_directory() method from metadata_utils to change your metadata directory. Please note that neither of these methods directly connects to a cloud storage account so the folder must be on your computer.
plot = CategoricalPlot(data=df).load_metadata("my_plot").plot()
There are many parameters you can save. To inspect the plot format settings just check the plot_format attribute. plot_format is just a dictionary so attributes can be set directly or indirectly through function calls. More parameters will shown in future examples.
plot.plot_format
{'labels': {'labelsize': 22,
'titlesize': 22,
'font': 'DejaVu Sans',
'ticklabel_size': 20,
'title_fontweight': 'bold',
'label_fontweight': 'normal',
'tick_fontweight': 'light',
'xlabel_rotation': 'vertical',
'ylabel_rotation': 'vertical',
'xtick_rotation': 'horizontal',
'ytick_rotation': 'horizontal'},
'axis': {'yscale': 'linear',
'xscale': 'linear',
'ylim': (None, None),
'xlim': (None, None),
'yaxis_lim': None,
'xaxis_lim': None,
'ydecimals': None,
'xdecimals': None,
'xunits': None,
'yunits': None,
'xformat': 'f',
'yformat': 'f'},
'axis_format': {'tickwidth': 0.5,
'ticklength': 2,
'linewidth': {'left': 0.5, 'bottom': 0.5, 'top': 0, 'right': 0},
'minor_tickwidth': 1.5,
'minor_ticklength': 2.5,
'yminorticks': 0,
'xminorticks': 0,
'xsteps': (5, 0, 5),
'ysteps': (5, 0, 5),
'style': 'lithos',
'truncate_xaxis': False,
'truncate_yaxis': False},
'figure': {'gridspec_kw': None,
'margins': 0.05,
'aspect': None,
'figsize': None,
'nrows': None,
'ncols': None,
'projection': 'rectilinear'},
'grid': {'ygrid': 0,
'xgrid': 0,
'yminor_grid': 0,
'xminor_grid': 0,
'linestyle': 'solid',
'minor_linestyle': 'solid'}}
Jitter + Summary plot
Below is jitter plot with several custom settings.
- The metadata previously saved is loaded first.
- Plots elements can be layered by just adding a plot method call. The order the plot methods are called matters. The ealiers plot methods will have a lower zorder and will be plot underneath any plot methods that are called after that plot method.
- Colors can set using a string color, None, a dictionary of colors with values in either the subgroup or group as the keys and colors as the values, a Group, Subgroup, or UniqueGroups or as a colormap provided by colorcet or Matplotlib. Colormaps can be passed with an index, restricting the number of values use in the 255 value colormap by adding an integer start and end as
-10:250to the name of the color map. Currently you can pass a Matplotlib color map or colorcet colormap in this manner. - The number of steps in the yaxis and the number of decimals to use set. Unlike matplotlib, Lithos always plots ticks at the end. This makes for more uniform plots and is visually appealing with the potential problem of too much white space. I generally do not have issues with too much white space.
- The optional unique_id is passed to jitter plot to plot nested data with individual marker types.
- Edgecolor defaults to "none" which means no edge color is used around the points. You can also pass the same types of arguments as color or you can pass "color" to use the same colors as the color argument.
- For summary plot you can pass an aggregating function as string for a built-in aggregating function. The built-in aggregating function can be accessed by using
CategoricalPlot.aggregating_funcsorLinePlot.aggregrating_funcs. You can also pass you own custom function or callable. - For summary plot you can pass an error function as string for a built-in error function. The built-in error function can be accessed by using
CategoricalPlot.error_funcsorLinePlot.error_funcs. You can also pass you own custom function or callable. - If you pass unique_id to jitter plot the nested subgroups will be plotted with different marker types.
df = create_synthetic_data(
n_groups=2, n_subgroups=2, n_unique_ids=5, n_points=5, distribution="gamma"
)
fig, ax = plt.subplots(ncols=2, figsize=(6.4 * 2, 4.8 * 1), layout="constrained")
plot = (
CategoricalPlot(data=df)
.load_metadata("my_plot")
.grouping(
group="grouping_1",
subgroup="grouping_2",
group_spacing=0.9,
)
.jitter(
marker="o",
markercolor="blues-100:200",
edgecolor="black",
alpha=0.7,
width=0.5,
markersize=8,
seed=30,
)
.summary(
func="mean",
capsize=0,
capstyle="round",
barwidth=0.8,
err_func="sem",
linewidth=3,
)
.axis_format(ysteps=7) # Adding a custom number of steps to the y-axis
.axis(ydecimals=2) # Formatting the number of decimals to use.
.plot_data(y="y", ylabel="test", title="")
.plot(figure=fig, axes=ax[0])
)
plot = (
CategoricalPlot(data=df)
.load_metadata("my_plot")
.grouping(
group="grouping_1",
subgroup="grouping_2",
group_spacing=0.9,
)
.jitter(
unique_id="unique_grouping",
marker="o",
markercolor="Oranges-100:200",
edgecolor="black",
alpha=0.7,
width=0.5,
markersize=8,
seed=30,
)
.summary(
func="mean",
capsize=0,
capstyle="round",
barwidth=0.8,
err_func="sem",
linewidth=3,
)
.axis_format(ysteps=7) # Adding a custom number of steps to the y-axis
.axis(ydecimals=2) # Formatting the number of decimals to use.
.plot_data(y="y", ylabel="test", title="")
.plot(figure=fig, axes=ax[1])
)
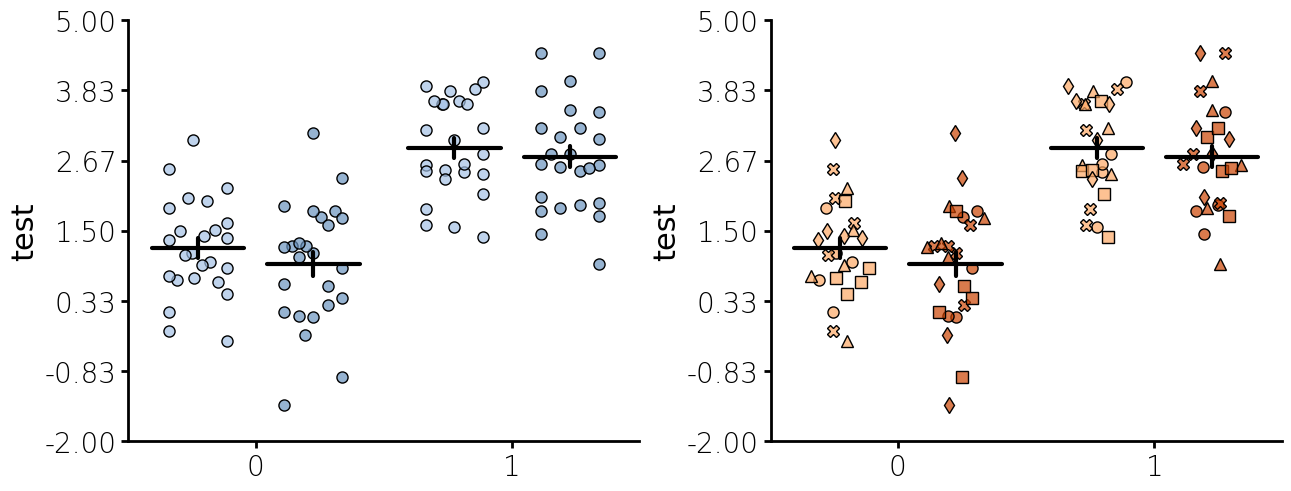
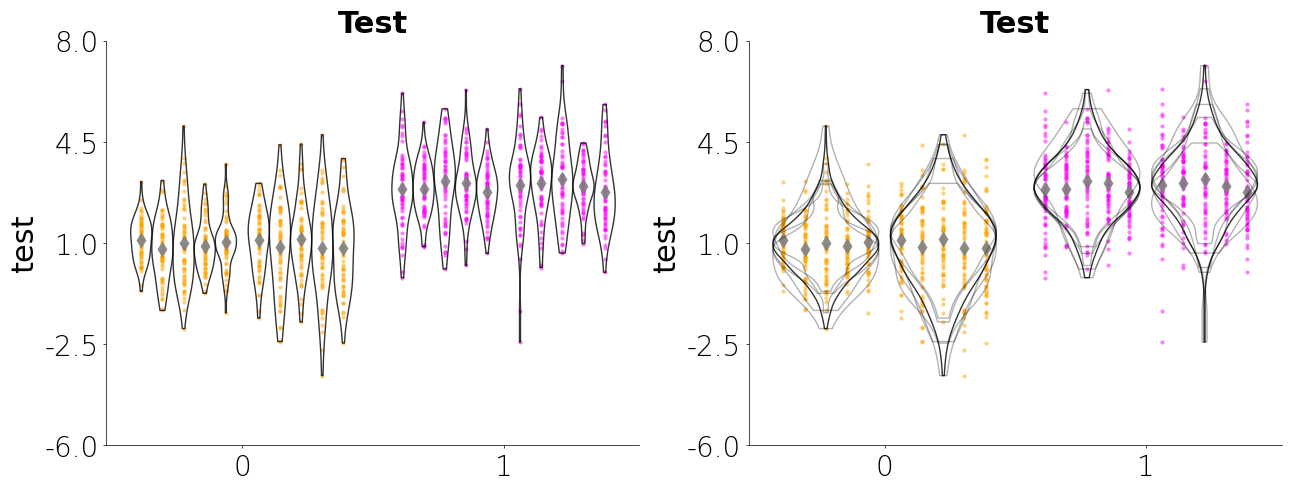
Jitteru + Violinplot
Below is a jitteru plot with a violin plot. Jitteru is my personal favorites since it really gives you a good look at how the data for each nested variable is distributed. The violin plot gives you an idea about the shape of the distribution. By combining the two you can see how each unique subject is contributing to the overall data. Here are several parameters I use below:
- Jitteru requires a unique_id
- For jitteru plot you can pass an aggregating function as string for a built-in aggregating function. The aggregrating function will plot a single point for the nested variable. The built-in aggregating functions can be accessed by using
CategoricalPlot.aggregating_funcsorLinePlot.aggregrating_funcs. You can also pass you own custom function or callable. - Violin accepts a unique_id argument. When passing the the unique_id argument you choose the split (see below) the individual violins similar to jitteru or you can overlap the violins using unique_style="overlap". If you pass overlap as the unique_style then you can choose to aggregate the KDEs
- You can also create a Matplotlib figure separately and the pass the figure and axes items to Lithos. This allows you to create a figure with multiple subplots.
df = create_synthetic_data(n_groups=2, n_subgroups=2, n_unique_ids=5, n_points=60)
fig, ax = plt.subplots(
ncols=2, nrows=1, figsize=(6.4 * 2, 4.8 * 1), layout="constrained"
)
plot = (
CategoricalPlot(data=df)
.load_metadata("my_plot")
.grouping(group="grouping_1", subgroup="grouping_2", group_spacing=0.9)
.jitteru(
unique_id="unique_grouping",
marker="o",
markercolor=Group(("orange", "magenta")),
edgecolor="none",
alpha=0.5,
width=0.9,
markersize=3,
)
.jitteru(
unique_id="unique_grouping",
marker="d",
markercolor="grey",
edgecolor="none",
alpha=0.9,
width=0.9,
markersize=8,
agg_func="mean",
)
)
plot.save_metadata("violin_example")
plot1 = (
CategoricalPlot(data=df)
.load_metadata("violin_example")
.violin(
unique_id="unique_grouping",
facecolor="none",
edgecolor="black",
linewidth=1,
edge_alpha=0.8,
width=0.9,
unique_style="split",
)
.plot(figure=fig, axes=ax.flat[0])
)
plot2 = (
CategoricalPlot(data=df)
.load_metadata("violin_example")
.violin(
unique_id="unique_grouping",
facecolor="none",
edgecolor="black",
linewidth=1,
edge_alpha=0.8,
width=0.9,
agg_func="mean",
)
.violin(
unique_id="unique_grouping",
facecolor="none",
edgecolor="black",
linewidth=1,
edge_alpha=0.3,
width=0.9,
)
.plot(figure=fig, axes=ax.flat[1])
)
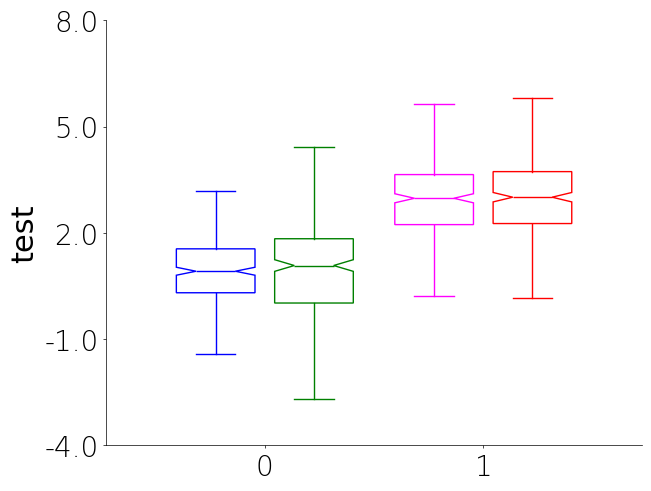
Boxplot
Boxplots are a great way to visualize the distribution of data. They can be used to compare different groups and identify outliers in your data. Currently there is no unique_id parameter for boxplot due to how they show data and the fact the plots get overly complicated to look at when there are many tiny boxes.
- You will notice that you can specify the color of the unique groups by passing a list or tuple of colors to UniqueGroups. The colors will be follow group order the subgroup order. So group 1 subgroups, group 2 subgroups, etc.
df = create_synthetic_data(n_groups=2, n_subgroups=2, n_unique_ids=5, n_points=60)
plot = (
CategoricalPlot(data=df)
.load_metadata("my_plot")
.grouping(
group="grouping_1",
subgroup="grouping_2",
group_spacing=0.9,
)
.box(
facecolor="none",
edgecolor=UniqueGroups(["blue", "green", "magenta", "red"]),
width=0.8,
alpha=0.8,
# showmeans=True, # You can shows means but it looks weird with show_ci
show_ci=True,
)
.plot_data(y="y", ylabel="test", title="")
.plot()
)
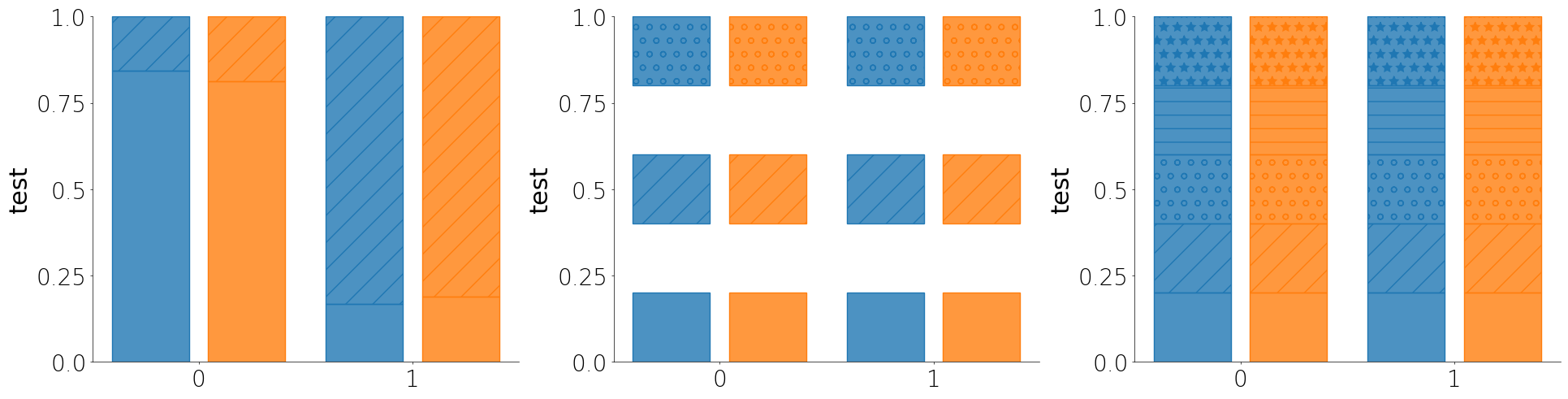
Percent plot
The percent plot is a like a histogram but stacked by categorical features. It is a good way to assess the distribution of data for a small number of bins or categorical groups.
- Like most other plot methods, the percent plot takes a unique_id parameter that will assess each unique group within the larger group or subgroup.
- If you don't pass a cutoff or pass None for cutoff, then Lithos assumes that your y column contains categorical values and will plot the percent of each category.
- You can either pass a list of hatches you want to use or you can just pass True to auto-assign hatches to the individual groups.
- You can pass an include_bins argument as a list of boolean values to only plot the bins you want.
df = create_synthetic_data(n_groups=2, n_subgroups=2, n_unique_ids=5, n_points=100)
fig, ax = plt.subplots(ncols=3, layout="constrained", figsize=(6.4 * 3, 4.8 * 1))
plot = (
CategoricalPlot(data=df)
.load_metadata("my_plot")
.grouping(
group="grouping_1",
subgroup="grouping_2",
group_spacing=0.9,
)
.percent(
cutoff=sum(df["y"]) / len(df["y"]),
barwidth=0.8,
alpha=0.8,
)
.plot_data(y="y", ylabel="test", title="")
.plot(figure=fig, axes=ax[0])
)
plot = (
CategoricalPlot(data=df)
.load_metadata("my_plot")
.grouping(
group="grouping_1",
subgroup="grouping_2",
group_spacing=0.9,
)
.percent(
cutoff=None,
barwidth=0.8,
alpha=0.8,
include_bins=[True, False, True, False, True],
)
.plot_data(y="unique_grouping", ylabel="test", title="")
.plot(figure=fig, axes=ax[1])
)
plot = (
CategoricalPlot(data=df)
.load_metadata("my_plot")
.grouping(
group="grouping_1",
subgroup="grouping_2",
group_spacing=0.9,
)
.percent(cutoff=None, barwidth=0.8, alpha=0.8, hatch=True)
.plot_data(y="unique_grouping", ylabel="test", title="")
.plot(figure=fig, axes=ax[2])
)
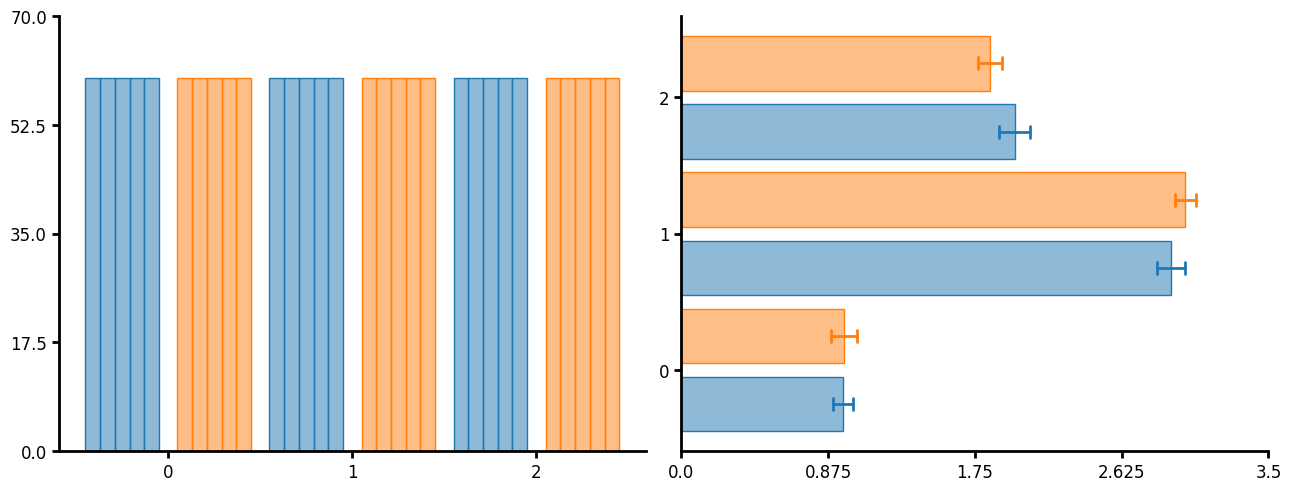
Bar plot
Traditional bar plot. You can pass a variety of functions such as count and mean. If you need to show errors you can just layer of summary or summaryu and set the barwidth to 0 or agg_width to 0 respectively.
df = create_synthetic_data(n_groups=3, n_subgroups=2, n_unique_ids=5, n_points=60)
fig, ax = plt.subplots(ncols=2, layout="constrained", figsize=(6.4 * 2, 4.8 * 1))
plot = (
CategoricalPlot(data=df)
.grouping(group="grouping_1", subgroup="grouping_2")
.bar(unique_id="unique_grouping", func="count", barwidth=0.8)
.plot_data(y="y")
.plot(figure=fig, axes=ax[0])
)
plot = (
CategoricalPlot(data=df)
.grouping(group="grouping_1", subgroup="grouping_2")
.bar(unique_id="unique_grouping", func="mean", agg_func="mean", barwidth=0.8)
.summaryu(
unique_id="unique_grouping",
func="mean",
agg_width=0,
agg_func="mean",
barwidth=0.0,
capsize=4,
)
.plot_data(y="y")
.plot(figure=fig, axes=ax[1])
)
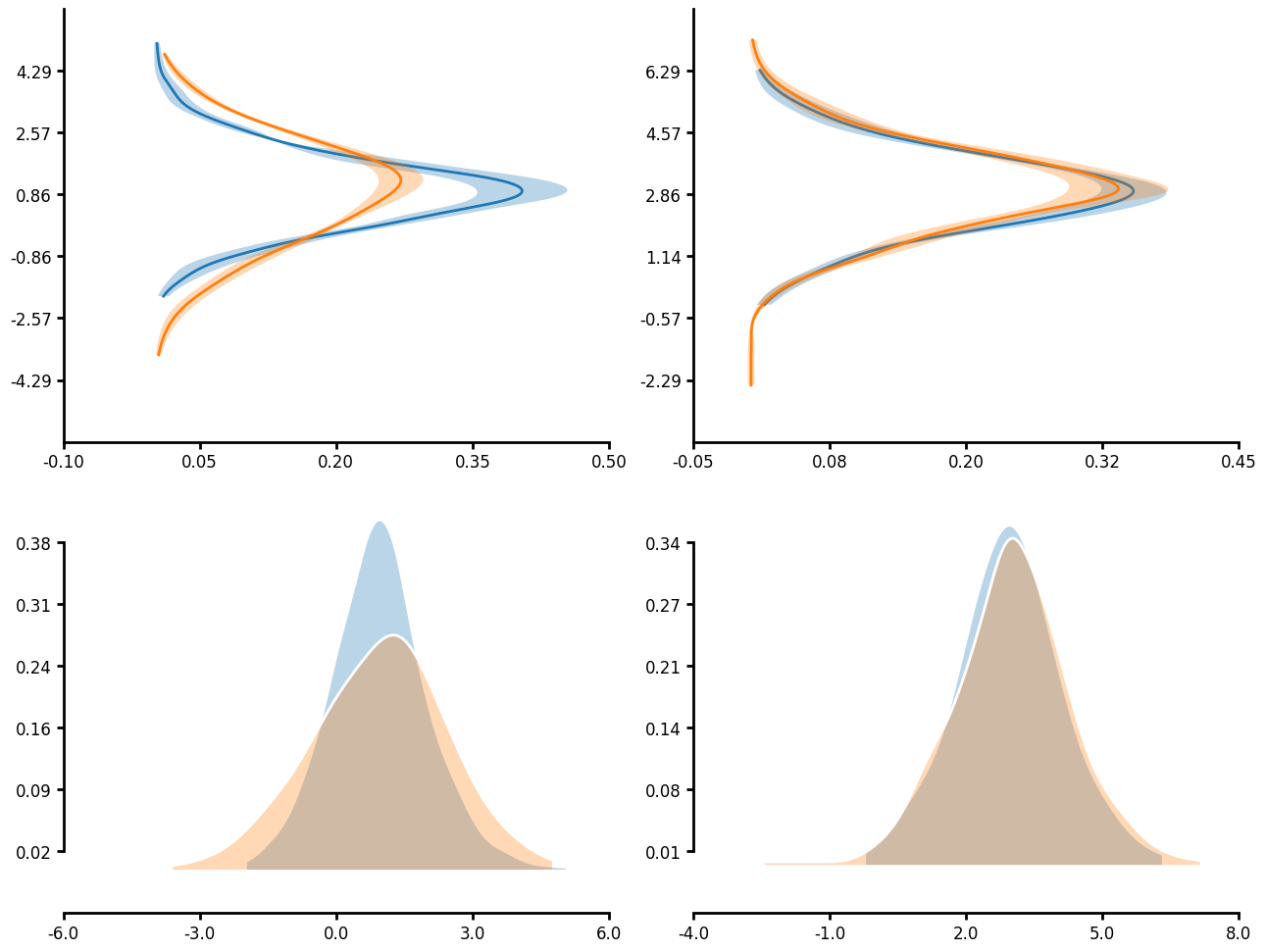
KDE plot
Many functions have unique_id parameter which allows for nested aggregations and transforms. In the case of a KDE plot, you can first run KDE on the unique_groupings then aggregate the individual KDEs together to create a single KDE plot. When you pass an agg_func you can also pass an err_func. This allows you to plot the error in your KDE measure. Additionally, you will notice that you can truncate the axis limits by passing a tuple that goes (number of ticks, start, end) to control the ticks that are displayed on each axis. Note that start and end follow python indexing so that start is zero indexe and end is not inclusive.
df = create_synthetic_data(n_groups=2, n_subgroups=2, n_unique_ids=5, n_points=60)
fig, ax = plt.subplots(
ncols=2, nrows=2, figsize=(6.4 * 2, 4.8 * 2), layout="constrained"
)
ax = ax.flatten()
plot = (
LinePlot(data=df)
.grouping(group="grouping_1", subgroup="grouping_2", facet=True)
.kde(
unique_id="unique_grouping",
agg_func="mean",
err_func="sem",
fill_between=True,
linewidth=2,
fillalpha=0.3,
kde_length=1028,
)
.plot_data(x="y")
.axis_format(ysteps=(8, 1, 7))
.axis(ydecimals=2)
.figure(ncols=2)
.plot(figure=fig, axes=ax[:2])
)
plot = (
LinePlot(data=df)
.grouping(group="grouping_1", subgroup="grouping_2", facet=True)
.kde(
unique_id="unique_grouping",
agg_func="mean",
fill_under=True,
linecolor="white",
fillcolor="glasbey_category10",
linewidth=2,
fillalpha=0.3,
kde_length=1028,
)
.plot_data(x="y")
.axis_format(ysteps=(8, 1, 7), truncate_yaxis=True)
.axis(ydecimals=2)
.figure(ncols=2)
.plot(figure=fig, axes=ax[2:])
)
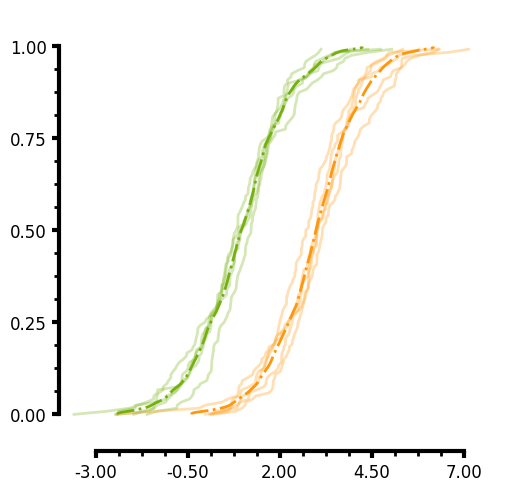
ECDF plot
Similar to the KDE, you can pass a unique_id to the ECDF. In the case of the plot below I do not pass an aggregate function and you can see that the individual lines for each unique_group are plotted. Additionally you will notice that you can specify two different axis limits to control the range of values displayed on each axis and control the range of the ticks thus creating a truncated axis with the plot data "floating" which is more visually appealing to some. Here are several parameters this plots uses:
- You can easily add minorticks by specifying more than 0 minor ticks.
- Minorticks can be formatted similarily to the main ticks by specifying the minor_tickwidth and minor_ticklength parameters.
- Major ticks can be formatted by tickwidth and ticklength.
df = create_synthetic_data(n_groups=2, n_subgroups=2, n_unique_ids=5, n_points=60)
plot = (
LinePlot(data=df)
.grouping(group="grouping_1")
.ecdf(
linecolor="rainbow-100:200",
linealpha=0.3,
agg_func=None,
err_func=None,
unique_id="unique_grouping",
fill_between=True,
)
.ecdf(
linecolor="rainbow-100:200",
linealpha=1.0,
linestyle="dashdot",
agg_func="mean",
err_func=None,
unique_id="unique_grouping",
fill_between=True,
)
.plot_data(y="y")
.figure(ncols=2)
.axis(
ylim=(-0.1, 1.1),
yaxis_lim=(0.0, 1.0),
xlim=(-4, 8),
xaxis_lim=(-3, 7),
ydecimals=2,
xdecimals=2,
)
.axis_format(
linewidth=3,
tickwidth=3,
xminorticks=3,
yminorticks=3,
minor_ticklength=3.5,
minor_tickwidth=2,
)
.figure(aspect=1)
.plot()
)
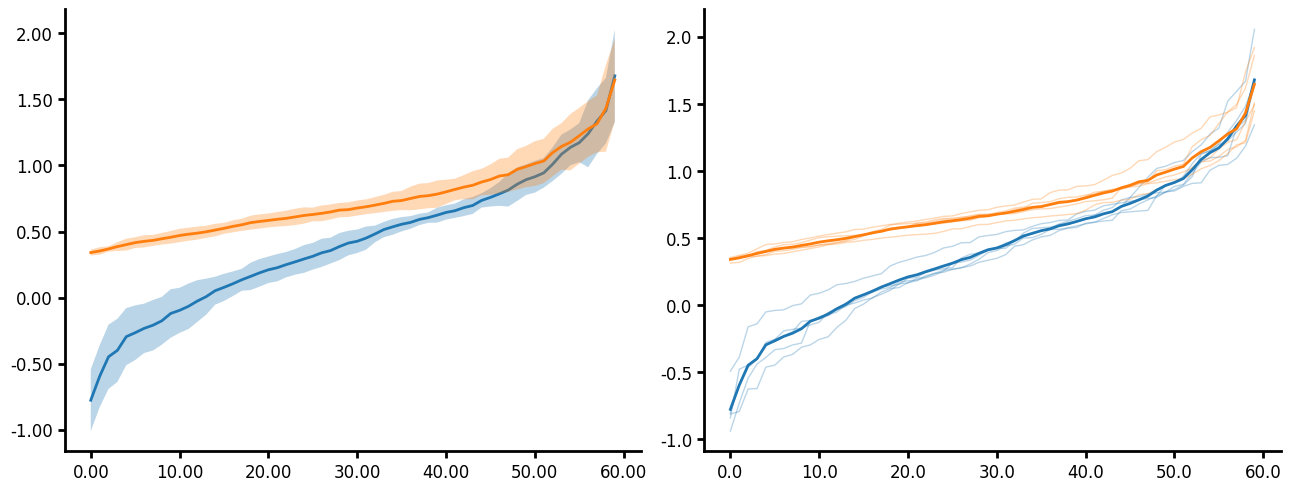
Aggline
Aggline allows you to aggregate points before plotting the data. This is useful when you have time series or distance data that you want to aggregate the y values (but not x) at discrete times or distances. Here are several parameters this plots uses:
- You can choose to plot the aggregating error however only the error for the y values is plotted.
- You can choose to plot the individual lines of the unique_id by passing agg_func=None.
- You can transform data. All transforms in Lithos occur before aggregating.
- Aggline contains a agg_func argument which aggregates unique_ids and func which aggregates the subgroups. This can be a little confusing but allows for control over how the data is aggregated. For example when you pass a unique_id with an agg_func, the data is aggregated for the unique_id first using func then it uses the agg_func to aggregate the next level up. If you don't pass agg_func then the unique_ids are not aggregated an instead plotted separately.
- Linestyle defaults to a simple line for all groups. If you want to change the linestyle you will need to pass a dictionary specifying the linestyle for each group.
- If you like the default the axis style but just want to format the font and size of the labels then just pass style as "default" to the axis_format method. This will use the default axis style, which in this case is the Matplotlib default. The only settings that do not get ignore by the default style are the decimal settings.
df = create_synthetic_data(
n_groups=2, n_subgroups=2, n_unique_ids=5, n_points=60, distribution="lognormal"
)
fig, ax = plt.subplots(
ncols=2, nrows=1, figsize=(6.4 * 2, 4.8 * 1), layout="constrained"
)
ax = ax.flatten()
plot1 = (
LinePlot(data=df)
.grouping(group="grouping_1")
.aggline(
unique_id="unique_grouping",
agg_func="mean",
fill_between=True,
linewidth=2,
fillalpha=0.3,
err_func="ci",
)
.transform(ytransform="log10")
.axis(ydecimals=2, xdecimals=2)
.axis_format(style="default")
.plot_data(y="y", x="x")
.plot(figure=fig, axes=ax[0])
)
plot2 = (
LinePlot(data=df)
.grouping(group="grouping_1")
.aggline(
unique_id="unique_grouping",
agg_func=None,
fill_between=True,
linewidth=1,
linealpha=0.3,
err_func=None,
)
.aggline(
unique_id="unique_grouping",
agg_func="mean",
fill_between=True,
linewidth=2,
linealpha=1,
err_func=None,
)
.transform(ytransform="log10")
.axis(ydecimals=1, xdecimals=1)
.axis_format(style="default")
.plot_data(y="y", x="x")
.plot(figure=fig, axes=ax[1])
)
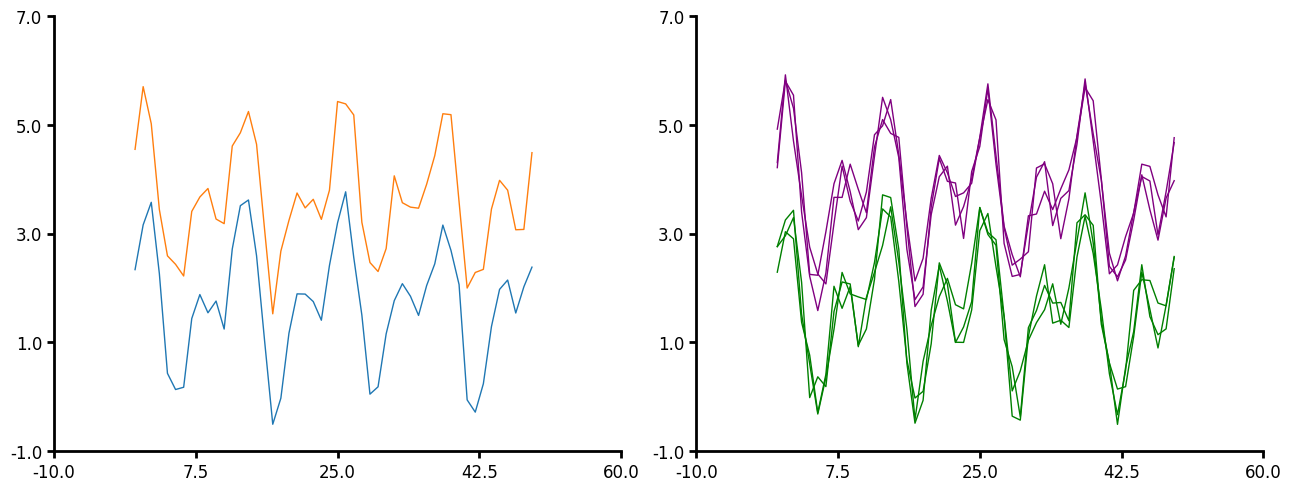
Line plot
If you have a simple line that does not need to be aggregated then use the line method. This provides a simple line plot for timeseries data. Here are the few parameters that line can take:
- You do not have to pass x to plot_data. Lithos will just create an x of increasing numbers.
- You can pass a unique_id to line plot.
- Similar to aggline you can aggregate the lines however, line expects that you have the same number of x-values per unique_id but not the same x-values per unique_id. The data also must be pre-sorted since the data is just pulled out by index order. The data is also not aggregated at the unique_id level but at the group or subgroup level. Line is intended for time series data whereas aggline is intended for many y per x (distribution per x).
- Line will be more performant than aggline when you have many x-values you want to aggregate over.
- You pass a linecolor, either a string or a dictionary.
- Error is currently only plotted for the y value.
df1 = create_synthetic_data(n_groups=2, n_points=50, distribution="timeseries")
fig, ax = plt.subplots(
ncols=2, nrows=1, figsize=(6.4 * 2, 4.8 * 1), layout="constrained"
)
plot = (
LinePlot(data=df1)
.grouping(group="grouping_1")
.line()
.plot_data(x="x", y="y")
.figure(ncols=2)
.plot(figure=fig, axes=ax[0])
)
df2 = create_synthetic_data(
n_groups=2, n_subgroups=3, n_points=50, distribution="timeseries"
)
plot = (
LinePlot(data=df2)
.grouping(group="grouping_1")
.line(unique_id="grouping_2", linecolor={0: "green", 1: "purple"}, linewidth=1)
.plot_data(y="y")
.figure(ncols=2)
.plot(figure=fig, axes=ax[1])
)
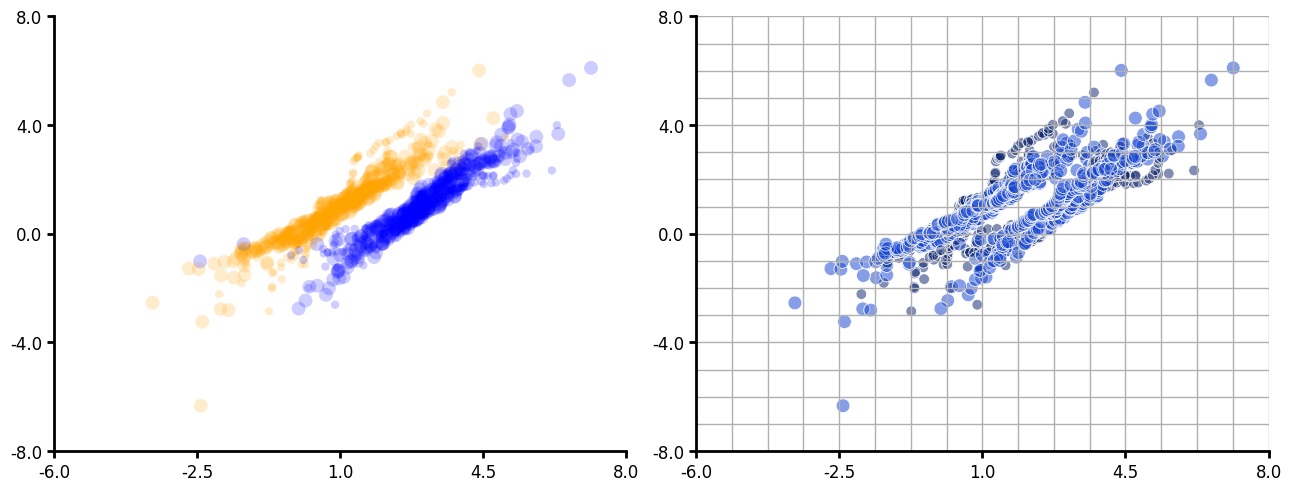
Scatter plot
df = create_synthetic_data(n_groups=2, n_subgroups=2, n_unique_ids=5, n_points=60)
df1 = create_synthetic_data(
n_groups=2, n_subgroups=2, n_unique_ids=5, n_points=60, seed=30
)
df["y1"] = df1["y"]
fig, ax = plt.subplots(ncols=2, layout="constrained", figsize=(6.4 * 2, 4.8 * 1))
plot = (
LinePlot(data=df)
.grouping(group="grouping_1")
.scatter(
markercolor={0: "orange", 1: "blue"},
alpha=0.1,
edgecolor="none",
markersize=("grouping_2", "36:100"),
marker=".",
)
.plot_data(x="y", y="y1")
.figure(ncols=2)
.plot(figure=fig, axes=ax[0])
)
plot = (
LinePlot(data=df)
.grouping(group="grouping_1")
.scatter(
markercolor=("grouping_2", "kb-100:210"),
alpha=0.3,
edgecolor="white",
linewidth=0.5,
markersize=("grouping_2", "60:100"),
marker=".",
)
.plot_data(x="y", y="y1")
.figure(ncols=2)
.grid(ygrid=1, xgrid=1, yminor_grid=1, xminor_grid=1)
.plot(figure=fig, axes=ax[1])
)
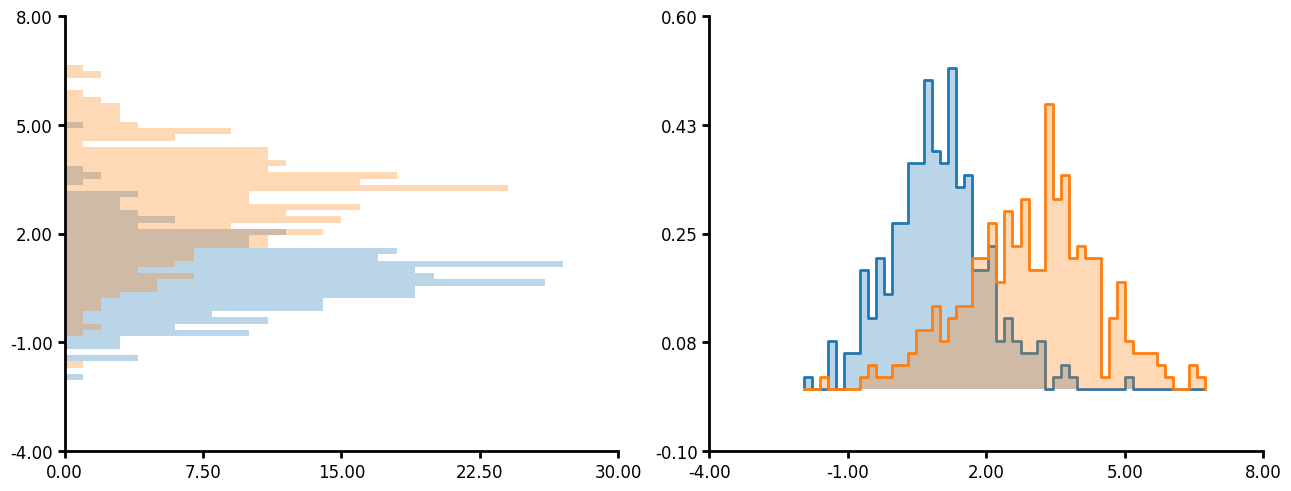
Histogram
Histogram has several unique parameters:
- You can plot on both the x and y axis.
- If you pass "common" to bin_limits then all the plots will have bins of the same size and the same max and min.
- You can also pass custom bins and custom bin limits.
- Like many other plotting methods you can pass a unique_id and agg_func which will create a histogram per unique_id then aggregate the data together.
df = create_synthetic_data(n_groups=2, n_unique_ids=5, n_points=60)
fig, ax = plt.subplots(ncols=2, layout="constrained", figsize=(6.4 * 2, 4.8 * 1))
plot1 = (
LinePlot(data=df)
.grouping(group="grouping_1")
.hist(
bin_limits="common",
linewidth=0,
fillalpha=0.3,
)
.plot_data(y="y")
.axis(ydecimals=2, xdecimals=2)
.plot(figure=fig, axes=ax[0])
)
plot1 = (
LinePlot(data=df)
.grouping(group="grouping_1")
.hist(
unique_id="unique_grouping",
agg_func="mean",
bin_limits="common",
linewidth=0,
fillalpha=0.3,
)
.plot_data(x="y")
.axis(ydecimals=2, xdecimals=2)
.plot(figure=fig, axes=ax[1])
)
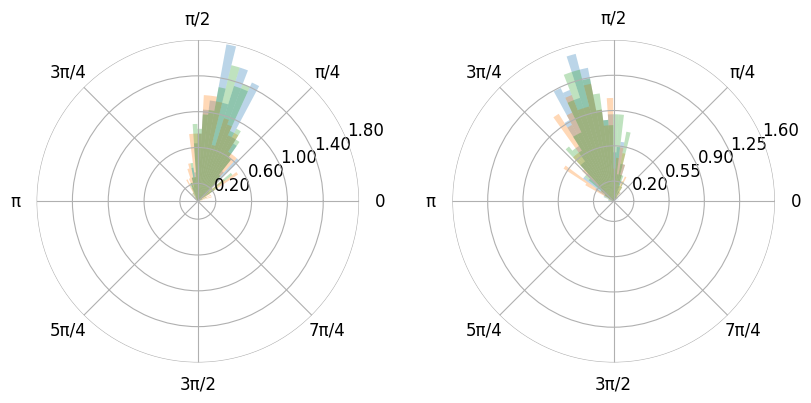
- You can also plot the histogram as a polar plot.
- Additionally you can use pi values instead of floats if you pass xunits as radian (0, 2pi) or wradian (-pi, pi).
- You can adjust the figure size by using the figure method.
- The figure method also accepts gridspec_kw. This is very useful for polar plots as matplotlib does not space multiple polar plots in one figure very well.
df = create_synthetic_data(n_groups=2, n_subgroups=3, n_unique_ids=5, n_points=60)
mx = max(df["y"])
mn = min(df["y"])
df["y"] = ((df["y"] - mn) / (mx - mn) * 3.09) + 0.00001
plot1 = (
LinePlot(data=df)
.grouping(group="grouping_1", subgroup="grouping_2", facet=True)
.hist(
bin_limits="common",
linewidth=0,
fillalpha=0.3,
)
.plot_data(x="y")
.axis(ydecimals=2, xdecimals=2, xunits="radian")
.figure(
projection="polar",
ncols=2,
gridspec_kw={"wspace": 0.1},
figsize=(8, 5),
)
.plot()
)
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file lithos-0.1.5.tar.gz.
File metadata
- Download URL: lithos-0.1.5.tar.gz
- Upload date:
- Size: 1.9 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
83a8be854a52bc45cea93fa7d02cf0104148c23467f882899be6a67036b96f77
|
|
| MD5 |
c29f818f6e7b79e0cd1eb1430c736bdd
|
|
| BLAKE2b-256 |
44f14842444bee6eab881f260209a7d8c7e8abc4a7f518ea80008b52076ea8e4
|
Provenance
The following attestation bundles were made for lithos-0.1.5.tar.gz:
Publisher:
publish.yaml on LarsHenrikNelson/lithos
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
lithos-0.1.5.tar.gz -
Subject digest:
83a8be854a52bc45cea93fa7d02cf0104148c23467f882899be6a67036b96f77 - Sigstore transparency entry: 224793845
- Sigstore integration time:
-
Permalink:
LarsHenrikNelson/lithos@96dc00ab5006e869fa7bc35b1b186579fde350f8 -
Branch / Tag:
refs/tags/v0.1.5 - Owner: https://github.com/LarsHenrikNelson
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yaml@96dc00ab5006e869fa7bc35b1b186579fde350f8 -
Trigger Event:
release
-
Statement type:
File details
Details for the file lithos-0.1.5-py3-none-any.whl.
File metadata
- Download URL: lithos-0.1.5-py3-none-any.whl
- Upload date:
- Size: 977.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.12.9
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0b9362f4f999345a2ccd5ee8253edcaab4ce2b0ddadb6c73649c5c7bc9205dac
|
|
| MD5 |
db042eebf3cfd9ad4ef0b58ec408aded
|
|
| BLAKE2b-256 |
98b082a5059d0676fa90967c0915c32d41a4c21914b78bcab315d9042e6e338b
|
Provenance
The following attestation bundles were made for lithos-0.1.5-py3-none-any.whl:
Publisher:
publish.yaml on LarsHenrikNelson/lithos
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
lithos-0.1.5-py3-none-any.whl -
Subject digest:
0b9362f4f999345a2ccd5ee8253edcaab4ce2b0ddadb6c73649c5c7bc9205dac - Sigstore transparency entry: 224793848
- Sigstore integration time:
-
Permalink:
LarsHenrikNelson/lithos@96dc00ab5006e869fa7bc35b1b186579fde350f8 -
Branch / Tag:
refs/tags/v0.1.5 - Owner: https://github.com/LarsHenrikNelson
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yaml@96dc00ab5006e869fa7bc35b1b186579fde350f8 -
Trigger Event:
release
-
Statement type:







