python client for redten - a platform for building and testing distributed, self-hosted LLMs with native RAG and Reinforcement Learning with Human Feedback (RLHF) https://api.redten.io

Project description
redten - A Platform for Distributed, Self-hosted LLM RAG and Reinforcement Learning with Human Feedback (RLHF)

What is redten?
A platform for building and testing large language models. Multi-tenant model testing results are stored in a database for experts to review later using the review-answer.py tool. Supports running gguf models using llama-cpp-python.
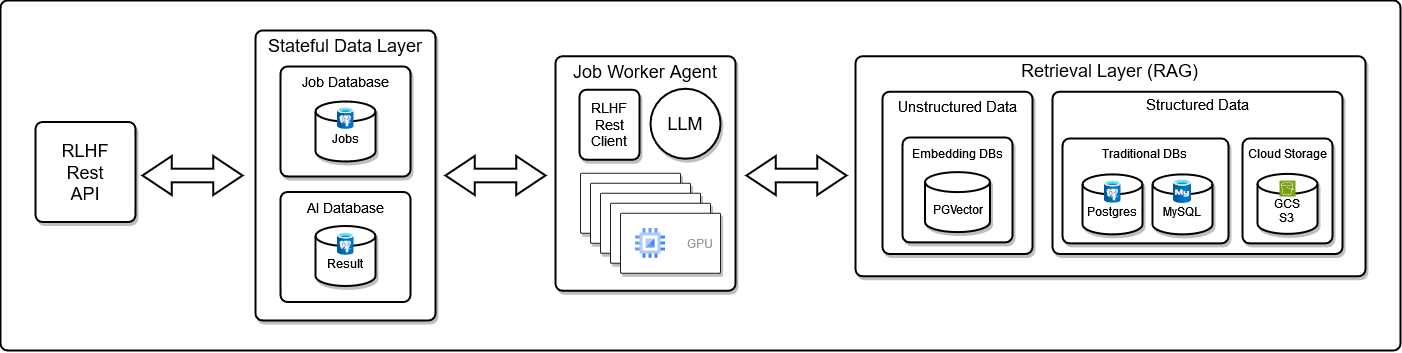
Python REST client for self-hosted llama building, testing and tuning platform at:
How does it work?
The redten RLHF REST api focuses on:
- leveraging many remote LLM agents concurrently POST-ing results (question/answer pairs or synthetic datasets) to a secured backend for review at a later time (save costs and shut down the expensive GPU cluster when it’s not needed)
- enabling subject matter experts to review results and submit expert answers for RAG source analysis which improves overall LLM response quality over time (tracking dashboard examples coming soon) decoupling LLM/gpu workloads from reinforcement learning with human feedback and RAG workloads
- finding knowledge blindspots - search api for tracking LLM response quality across many dimensions: models, quantization, batches, context sizes, tokens, and embeddings (chunks, structured vs unstructured datasets and use cases)
- Embedding as a Service (EaaS) with a multi-tenant job engine built on the v2 rust restapi crate that supports s3 uploads and s3 downloads and includes kafka fire-and-forget publishing using a persistent Postgres backend for tracking many ai workloads (e.g. question/answer, synthetic dataset generation) and results
- evaluating any open source llm model with coming-soon open question/answer datasets with more RAG data sources (pdfs/csvs/txt/parquet) in many pgvector embedding databases using an emerging Retrieval as a Service (RaaS) architecture
- building synthetic datasets from a RAG-customized LLM (lora/qlora coming soon!)
Coming Soon
Support for more models at the same time
There's limited hardware for the building and testing on the public api platform. Right now there is only one model deployed for all question responses:
Open Source Examples
Feel free to open a github issue on this repo if you think there is something more interesting/worthwhile to focus on:
- how to run a remote LLM agent (on gcp or aws) and POST the ai processing results to the reinforcement learning rest api for review
- RLHF with RAG example(s)
- RAG with pgvector ingestion example(s)
- streamlit score tracking while testing different unstructured RAG data sources (various pdf’s/csv’s/text/powerpoint/email/db data sources loaded into a tls-secured pgvector embedding database)
- LLM response customization with LoRA/QLoRA support
Ask a Question
Ask an llm a question or a question from a file and the rest api will reply with a job_id for tracking the progress. once the llm's finishes processing the question then the results are shown to stdout.
Getting Started
Install
Please install the python 3 pip:
pip install llama-client-aic
Environment Variables
The following environment variables are used to automatically create a new user (or service account) using the RLHF REST API:
export AI_USER="publicdemos100"
export AI_EMAIL="publicdemos100@redten.io"
export AI_PASSWORD="789987"
# an auto-updated
# collection of public, unstructured embeddings
# stored in a pgvector database
export AI_COLLECTION_ID="embed-security"
Examples
Ask an LLM a Question
Ask a Question from the Command Line
ask-llm.py \
-c "${AI_COLLECTION_ID}" \
-q "question"
Ask a Question from a File using the Command Line
ask-llm.py \
-c "${AI_COLLECTION_ID}" \
-q PATH_TO_FILE_WITH_QUESTION
ask-llm.py -c embed-security -q "using std::namespace; int main() { std::cout << "hello" << std::endl; return 256;}"
Find the log line showing the job id:
2023-11-08 18:05:59.149 INFO ask_a_question - info@redten.io.id=86 - job_id=212 result:
Retry Getting the Results
get-ai-result.py -i 212
Ask a Question using the Python REST Client
import client_aic.ask as ask
# if your user does not exist it will be created
username = "publicdemos"
email = "publicdemos@redten.io"
password = "789987"
collection_id = "embed-security"
question = 'using std::namespace; int main() { std::cout << "hello" << std::endl; return 256;}'
wait_for_result = False
# ask the llm the question and let the
# llm use the collection_id embeddings to perform rag
# before responding
print('asking question')
(
user,
res_job,
res_ai) = ask.ask(
question=question,
collection_id=collection_id,
username=username,
email=email,
password=password,
wait_for_result=wait_for_result)
if not user:
print(
f'failed to find user with email={email}')
elif not res_job:
print('failed to find job result')
elif wait_for_result:
if res_ai:
print(
f'{email} - job_id={res_job.job_id} '
'result:\n'
f'question: {question}\n'
f'answer: {res_ai.answer}\n'
f'score: {res_ai.score}')
else:
print(
'failed to get ai result for '
f'job_id={res_job.job_id}')
else:
print(
'did not wait for '
f'user_id={user.id} '
f'job={res_job.job_id} '
'ai result '
'please use:\n\n'
f'get-ai-result.py -i {res_job.job_id}'
'\n')
Reinforcement Learning with Human Feedback (RLHF) - Phase 1
Review individual LLM responses with subject matter expert(s) and attach reviewed:
- reviewer answer/explanation/reasoning
- reviewer confidence score
Note: confidence score is a value between 0-100.0 that the reviewer uses to state how confident the reviewer's answer is versus the llm's response. Here's some guidelines for how confidence scores work with rlhf+rag works:
- 0.0-64 - the reviewer is not confident in the answer
- 65-79 - the reviewer is somewhat confident in the answer
- 80-94 - the reviewer is confident in the answer
- 95-100.0 - the reviewer considers this answer to be a common knowledge, a known truth or something that is almost considered as a fact
review-answer.py -i 221 -a "this code has an exploit and needs to address 1, 2, 3" -s 99.9
get-ai-result.py -i 221 | grep reviewed_
Debugging
Increase logging by exporting this environment variable:
export LOG=debug
Where can I learn more?
Here are two streamlit LLM examples showing how different web applications can leverage the same mistral-7b-instruct-v0.1.Q8_0.gguf LLM model while using multiple, different RAG data sources to customize the LLM response based on the use case. Note: this LLM is currently self-hosted on 16-23 cpus (without any gpu cards) and each response takes ~40-80 seconds.
See if your C++ source code contains buffer overflow exploits using a custom-trained LLM
Create personalized questions for a 2nd grader using an LLM to align with your child's recent lessons and homework
More streamlit and open source examples coming soon!
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file llama_client_aic-1.0.2-py3-none-any.whl.
File metadata
- Download URL: llama_client_aic-1.0.2-py3-none-any.whl
- Upload date:
- Size: 40.6 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.11.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0daa28c4ccf146d45b9385d17fd39aaaaa5a66ed67a041a4baf0e7e1a82585ad
|
|
| MD5 |
242aba6f64f34cf15a40f60a65916bf9
|
|
| BLAKE2b-256 |
177084f54fb521f6cfac0efc64da5512ee3aedef3215d13b47e6faa20af5bafa
|







