A Python package for Llama CPP.

Project description
Llama CPP
This is a Python package for Llama CPP ( https://github.com/ggml-org/llama.cpp ).
Installation
You can install the pre-built wheel from the releases page or build it from source.
pip install llama-cpp-pydist
Usage
This section provides a basic overview of how to use the llama_cpp_pydist library.
Deploying Windows Binaries
If you are on Windows, the package attempts to automatically deploy pre-compiled binaries. You can also manually trigger this process.
from llama_cpp import deploy_windows_binary
# Specify the target directory for the binaries
# This is typically within your Python environment's site-packages
# or a custom location if you prefer.
target_dir = "./my_llama_cpp_binaries"
if deploy_windows_binary(target_dir):
print(f"Windows binaries deployed successfully to {target_dir}")
else:
print(f"Failed to deploy Windows binaries or no binaries were found for your system.")
# Once deployed, you would typically add the directory containing llama.dll (or similar)
# to your system's PATH or ensure your application can find it.
# For example, if llama.dll is in target_dir/bin:
# import os
# os.environ["PATH"] += os.pathsep + os.path.join(target_dir, "bin")
Conversion Library Installation
To perform Hugging Face to GGUF model conversions, you need to install additional Python libraries. You can install them via pip:
pip install transformers numpy torch safetensors sentencepiece
Alternatively, you can install them programmatically in Python:
from llama_cpp.install_conversion_libs import install_conversion_libs
if install_conversion_libs():
print("Conversion libraries installed successfully.")
else:
print("Failed to install conversion libraries.")
Converting Hugging Face Models to GGUF
This package provides a utility to convert Hugging Face models (including those using Safetensors) into the GGUF format, which is used by llama.cpp. This process leverages the conversion scripts from the underlying llama.cpp submodule.
1. Install Conversion Libraries:
Before converting models, ensure you have the necessary Python libraries. You can install them using a helper function:
from llama_cpp import install_conversion_libs
if install_conversion_libs():
print("Conversion libraries installed successfully.")
else:
print("Failed to install conversion libraries. Please check the output for errors.")
2. Convert the Model:
Once the dependencies are installed, you can use the convert_hf_to_gguf function:
from llama_cpp import convert_hf_to_gguf
# Specify the Hugging Face model name or local path
model_name_or_path = "TinyLlama/TinyLlama-1.1B-Chat-v1.0" # Example: A small model from Hugging Face Hub
# Or, a local path: model_name_or_path = "/path/to/your/hf_model_directory"
output_directory = "./converted_gguf_models" # Directory to save the GGUF file
output_filename = "tinyllama_1.1b_chat_q8_0.gguf" # Optional: specify a filename
quantization_type = "q8_0" # Example: 8-bit quantization. Common types: "f16", "q4_0", "q4_K_M", "q5_K_M", "q8_0"
print(f"Starting conversion for model: {model_name_or_path}")
success, result_message = convert_hf_to_gguf(
model_path_or_name=model_name_or_path,
output_dir=output_directory,
output_filename=output_filename, # Can be None to auto-generate
outtype=quantization_type
)
if success:
print(f"Model converted successfully! GGUF file saved at: {result_message}")
else:
print(f"Model conversion failed: {result_message}")
# The `result_message` will contain the path to the GGUF file on success,
# or an error message on failure.
This function will download the model from Hugging Face Hub if a model name is provided and it's not already cached locally by Hugging Face transformers. It then invokes the convert_hf_to_gguf.py script from llama.cpp.
For more detailed examples and advanced usage, please refer to the documentation of the underlying llama.cpp project and explore the examples provided there.
Building and Development
For instructions on how to build the package from source, update the llama.cpp submodule, or other development-related tasks, please see BUILDING.md.
Changelog
2026-06-27: Update to llama.cpp b9821
Summary
Updated llama.cpp from b9780 to b9821, incorporating 23 upstream commits with breaking changes, new features, and performance improvements.
Notable Changes
⚠️ Breaking Changes
- b9780: vulkan-shaders-gen : fail the build when a shader fails to compile (#24450)
vulkan-shaders-genignores shader-compile subprocess failures, so a brokenlibggml-vulkancan be produced while the build reports success — the breakage only- surfaces at run time. This PR makes the generator fail the build loudly instead:
- b9780: vulkan-shaders-gen : fail the build when a shader fails to compile (#24450)
vulkan-shaders-genignores shader-compile subprocess failures, so a brokenlibggml-vulkancan be produced while the build reports success — the breakage only- surfaces at run time. This PR makes the generator fail the build loudly instead:
- b9782: common: remove unused json-partial (#24968)
- Unused code, seems like a left over from the old minja system
- I have read and agree with the contributing guidelines
- b9804: mamba2: remove hardcoded 2x expansion factor and invalid d_inner % d_state check (#23082)
- This PR removes two unnecessary restrictions in Mamba2 that prevent loading models with custom architectures.
- Changes:
-
- Remove hardcoded 2x expansion factor (
GGML_ASSERT(2 * n_embd == d_inner))
- Remove hardcoded 2x expansion factor (
🆕 New Features
- b9786: opencl: support non-contig rows in norm (#24965)
- Support non-contig rows in norm, fix test-backend-ops failure.
- b9803: opencl: flush profiling batch at shutdown for incomplete batches (#25016)
- Profiling entries stay in profiling_info until the 2048 threshold, so smaller batches are never written. This PR adds a flush_profiling_batch() call before writing to include all entries.
- b9810: CUDA: add cublasSgemmBatched mapping for HIP/MUSA vendor headers (#25033)
- Fixes the HIP/MUSA build break introduced by #24426. Adds the missing cublasSgemmBatched to hipblasSgemmBatched /mublasSgemmBatched mapping to the vendor headers.
- I have read and agree with the contributing guidelines
- b9813: vulkan: add INTEL_XE1 arch enum and enable coopmat1 on Intel Xe-LPG Plus (#24404)
- Target platforms: Xe-LPG Plus (Arrow Lake-H iGPU)
- Adds
INTEL_XE1enum variant tovk_device_architecture - Adds PTL (Panther Lake) device ID detection for future platform coverage
- b9814: vulkan: opt mul_mat_vecq for mi50 (#22933)
- In
ggml-vulkan.cpp, this adds asubgroups_gcn_enableddevice flag and enables subgroup arithmetic for a small allowlisted set of AMD GPUs based on device name matching. - Previously, AMD GCN devices were excluded from this subgroup path entirely. With this change, supported GCN 5.x devices can use subgroup arithmetic in
ggml_vk_load_shaders.
- In
- b9817: Improved quantize script (#222)
- I improved the quantize script by adding error handling and allowing to select many models for quantization at once in the command line. I also converted it to Python for generalization as well as extensibility.
🚀 Performance Improvements
- b9820: CUDA: Improve performance via less synchronizations between token (#17795)
- See comment below
- This PR suggest to remove some superfluous synchronization calls between tokens to be faster on CUDA backends. I see between 1% and 2% perf gain depending on the model, GPU and settings.
🐛 Bug Fixes
- b9781: vulkan: allow reducing graph submission batches to avoid device timeouts (#24872)
disable graph submission batching on UMA devices, to avoid "device lost" errorsreduce discrete GPU batching from 100 to 64- allow overriding the max batching value with the GGML_VK_MAX_NODES_PER_SUBMIT env var
- b9787: [SYCL] fix the failed UT cases of conv_3d (#24900)
- fix the failed UT cases of conv_3d。
- all related cases are passed.
- b9789: quant : fix quantizing moe with mtp (#24986)
- Fixes #24379
- Fixes #24661
- Due to the following check and the fact that
n_layer()instead ofn_layer_allwas being used it was impossible to quantize MoEs with MTP.
- b9811: vulkan: Workaround compiler bug in conv2d coopmat2 path (#24924)
- This fixes a failure seen in https://github.com/leejet/stable-diffusion.cpp. The compiler messed up alignment with the odd size array.
- I have read and agree with the contributing guidelines
- AI usage disclosure: YES, for debugging.
- b9820: Sched: Reintroduce less synchronizations between token, with fixed pipeline parallelism. (#20793)
- Follow up to https://github.com/ggml-org/llama.cpp/pull/20463#issuecomment-4091342946.
- https://github.com/ggml-org/llama.cpp/pull/17795 improved performance in the single GPU setting on CUDA, but it was rolled back due to a bug surfacing in multi-GPU pipeline parallel settings.
- For the single GPU setting, it moved the scheduling from
sassassasgto the more efficientsaaasgpattern, wheres= sync,a= async copy,g= graph execution.
Additional Changes
7 minor improvements: 3 documentation, 2 examples, 2 maintenance.
Full Commit Range
- b9780 to b9821 (23 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b9780...b9821
2026-06-24: Update to llama.cpp b9780
Summary
Updated llama.cpp from b9733 to b9780, incorporating 36 upstream commits with breaking changes, new features, and performance improvements.
Notable Changes
⚠️ Breaking Changes
- b9757: Top-N-Sigma: Remove unconditional softmax+sort (#22645)
- Currently, the Top-N-Sigma sampler does an unconditional softmax+sort at the end.
- In the (common, I believe) case of Top-N-Sigma being followed by Dist, this expensive work is completely wasted.
- On my M3 Max MacBook Pro, this PR increases the t/s for
google_gemma-4-E4B-it-Q8_0by 50%, from ~30t/s to ~45t/s, reducing the time per token by 10ms.
- b9780: vulkan-shaders-gen : fail the build when a shader fails to compile (#24450)
vulkan-shaders-genignores shader-compile subprocess failures, so a brokenlibggml-vulkancan be produced while the build reports success — the breakage only- surfaces at run time. This PR makes the generator fail the build loudly instead:
- b9780: vulkan-shaders-gen : fail the build when a shader fails to compile (#24450)
vulkan-shaders-genignores shader-compile subprocess failures, so a brokenlibggml-vulkancan be produced while the build reports success — the breakage only- surfaces at run time. This PR makes the generator fail the build loudly instead:
🆕 New Features
- b9736: model : glm-dsa load DSA indexer tensors as optional (#24770)
- Loading any GLM-5.2 GGUF (
GlmMoeDsaForCausalLM/GLM_DSA) fails withmissing tensor 'blk.3.indexer.k_norm.weight'. GLM-5.2 ships the DSA lightning indexer on only a subset of layers, butllama_model_glm_dsa::load_arch_tensorscreated the fiveindexer_*tensors on every layer as required. GLM_DSAusesllama_model_deepseek2::graph(plain MLA) and never references the indexer tensors (the DSA indexer runtime isn't implemented yet), so they are loaded-but-unused. Marking themTENSOR_NOT_REQUIREDlets layers without an indexer load asnullptr; the model runs as full MLA attention. DeepSeek-V3.2 (uniform indexer on every layer) is unaffected.- Complements the conversion support in #19460. Verified by loading and generating from a GLM-5.2 GGUF on Metal (previously failed at load).
- Loading any GLM-5.2 GGUF (
- b9739: add missing link for win opencl adreno arm64 in release notes (#24809)
- add missing link for win opencl adreno arm64 in release notes
- b9741: llama : use LLM_KV for quantization_version & file_type (#24802)
LLM_KV_GENERAL_FILE_TYPEdid not exist yet when the// TODO: use LLM_KVcomment was added
- b9745: Support Step3.5/3.7 flash mtp3 (#24340)
- follow-up to #23274.(cc @pwilkin )
-
-
📜 Full data-flow trace — couldn't think of a good way to draw this, so I wrote it all down instead. It's long, but every byte is load-bearing.
- b9750: jinja : implement call statement (#24847)
- Implement
callstatement. - Adds support for (with and without
call/callerparameters): -
</code></pre> </li> </ul> </li> <li><strong>b9754</strong>: common/peg : implement ac parser for stricter grammar generation (<a href="https://github.com/ggml-org/llama.cpp/pull/24869">#24869</a>) <ul> <li>Even after #24839, users are still seeing the model escape the grammar. It's because the exclusion grammar can accept a partial prefix of the delimiter and each use of <code>until(delim)</code> is typically followed by a <code>literal(delim)</code>.</li> <li>This PR uses the same AC type and adds an including variant: consume all characters up to and including a delimiter. This way it terminates on first occurrence of <code>\n</parameter>\n</code>.</li> <li>Fixes #24863</li> </ul> </li> <li><strong>b9758</strong>: [SYCL] support bf16 on bin_bcast OP and unary OPs (<a href="https://github.com/ggml-org/llama.cpp/pull/24838">#24838</a>) <ul> <li>The UT cases of bin_bcast OP and unary OPs for bf16 are created.</li> <li>SYCL backend didn't support the new cases.</li> <li>Support bf16 on bin_bcast OP and unary OPs.</li> </ul> </li> <li><strong>b9773</strong>: vulkan: Support GET_ROWS_BACK (<a href="https://github.com/ggml-org/llama.cpp/pull/24883">#24883</a>) <ul> <li>Support GET_ROWS_BACK, similar level of support to ggml-cuda.</li> <li>I have read and agree with the <a href="https://github.com/ggml-org/llama.cpp/blob/master/CONTRIBUTING.md">contributing guidelines</a></li> <li>AI usage disclosure: YES, used codex to implement, I reviewed/tweaked.</li> </ul> </li> <li><strong>b9774</strong>: vulkan: support all backend tests for SQR/SQRT/SIN/COS/CLAMP/LEAKY_RELU/NORM (<a href="https://github.com/ggml-org/llama.cpp/pull/24582">#24582</a>) <ul> <li>SQR/SQRT/SIN/COS/CLAMP/LEAKY_RELU already supported noncontig, but were missing f16 variants. Port them to use unary.comp since they're all unary ops. NORM was missing support for noncontiguous tensors.</li> <li>I have read and agree with the <a href="https://github.com/ggml-org/llama.cpp/blob/master/CONTRIBUTING.md">contributing guidelines</a></li> <li>AI usage disclosure: YES, used codex. I told it what to do and reviewed all the changes.</li> </ul> </li> <li><strong>b9777</strong>: model : Add LFM2.5-ColBERT-350M and LFM2.5-Embedding-350M (<a href="https://github.com/ggml-org/llama.cpp/pull/24913">#24913</a>) <ul> <li>Add support for Liquid AI embedding models</li> <li><a href="https://huggingface.co/LiquidAI/LFM2.5-ColBERT-350M">LiquidAI/LFM2.5-ColBERT-350M</a></li> <li><a href="https://huggingface.co/LiquidAI/LFM2.5-Embedding-350M">LiquidAI/LFM2.5-Embedding-350M</a></li> </ul> </li> </ul> <h4><a href="#user-content--performance-improvements-1" aria-hidden="true" class="anchor" id="user-content--performance-improvements-1"></a>🚀 Performance Improvements</h4> <ul> <li><strong>b9735</strong>: ggml : optimize AMX (<a href="https://github.com/ggml-org/llama.cpp/pull/24806">#24806</a>) <ul> <li>Flatten the partition over n_batch * M so every thread participates in the quantization</li> <li>| CPU | Model | Test | t/s OLD | t/s NEW | Speedup |</li> <li>|:--------------------------------|:------------------------------|:-------|----------:|----------:|----------:|</li> </ul> </li> <li><strong>b9767</strong>: ggml-webgpu: improve MTP inference by using mat-vec path for small batches (<a href="https://github.com/ggml-org/llama.cpp/pull/24811">#24811</a>) <ul> <li>This PR improves small-batch decoding performance by applying the mat-vec path to these cases. This is particularly expected to improve the performance of speculative decoding, such as MTP.</li> <li>The following table shows the performance of token decoding with <code>llama-server</code> on native WebGPU on M2 Pro (32 GiB RAM).</li> <li>Based on <a href="https://huggingface.co/Qwen/Qwen3.5-4B">Qwen/Qwen3.5-4B</a></li> </ul> </li> </ul> <h4><a href="#user-content--bug-fixes-1" aria-hidden="true" class="anchor" id="user-content--bug-fixes-1"></a>🐛 Bug Fixes</h4> <ul> <li><strong>b9740</strong>: arg: try fixing test-args-parser randomly fails (<a href="https://github.com/ggml-org/llama.cpp/pull/24826">#24826</a>) <ul> <li>no idea why <code>openvino-windows-2022</code> workflow randomly fails: <a href="https://github.com/ggml-org/llama.cpp/actions/runs/27849196743/job/82424736785">https://github.com/ggml-org/llama.cpp/actions/runs/27849196743/job/82424736785</a></li> <li>the reported error is quite unexpected:</li> <li> <img width="997" height="397" alt="image" src="https://github.com/user-attachments/assets/d576867c-e22a-4324-a59d-ae09e74f2daf" /> </li> </ul> </li> <li><strong>b9742</strong>: fix(hexagon): use padded stride for ssm-conv weights (<a href="https://github.com/ggml-org/llama.cpp/pull/24470">#24470</a>) <ul> <li>Qwen3.5-0.8B Q4_0 and Qwen3.5-2B Q4_0 already produced coherent output on HTP0, but Qwen3.5-4B Q4_0 could degrade into corrupted text on the same backend even though it uses the same model family structure. That made the issue look shape- or partition-dependent rather than a general Qwen3.5 HTP failure.</li> <li>The difference comes from how the SSM_CONV HVX path partitions <code>d_inner</code> across threads. For 0.8B and 2B with the tested thread configuration, the per-thread row partitions were aligned to the HVX vector width, so the existing staged weight layout happened to be safe. For 4B, the partition was not always <code>VLEN_FP32</code> aligned, which exposed a stride mismatch in <code>src1_T</code>: the buffer was sized with the padded per-thread row count, but <code>transpose_src1</code> and the HVX weight loads used the unpadded row count as the stride.</li> <li>This change makes the padded stride explicit for <code>src1_T</code> and aligns the per-thread row count to <code>VLEN_FP32</code>, so the staged VTCM weight layout matches the HVX vector access pattern.</li> </ul> </li> <li><strong>b9769</strong>: vulkan: link ggml-cpu when GGML_VULKAN_CHECK_RESULTS / RUN_TESTS are enabled (<a href="https://github.com/ggml-org/llama.cpp/pull/24444">#24444</a>) <ul> <li>-DGGML_VULKAN_CHECK_RESULTS=ON and -DGGML_VULKAN_RUN_TESTS=ON failed to link for some reason, and I noticed the debug code in ggml-vulkan.cpp calls ggml_graph_compute_with_ctx from ggml-cpu, but ggml-vulkan only links ggml-base and Vulkan. CI misses it because neither flag is built there i think..?</li> <li>Fix: link ggml-cpu under those two options</li> <li>Tested on Windows/MSVC: fails to link before, builds fine after.</li> </ul> </li> <li><strong>b9776</strong>: vulkan: Apply bias before softmax in FA, to avoid overflow (<a href="https://github.com/ggml-org/llama.cpp/pull/24909">#24909</a>) <ul> <li>Apply a bias in the scalar/cm1 FA paths to avoid fp16 overflow. Should fix <a href="https://github.com/leejet/stable-diffusion.cpp/pull/1678">https://github.com/leejet/stable-diffusion.cpp/pull/1678</a>.</li> <li>This bias was already in the cm2 path. cm2 is still generating a bad image, but it appears to be related to conv2d rather than FA (works if I disable coopmat2 for conv2d).</li> <li>I have read and agree with the <a href="https://github.com/ggml-org/llama.cpp/blob/master/CONTRIBUTING.md">contributing guidelines</a></li> </ul> </li> </ul> <h3><a href="#user-content-additional-changes-1" aria-hidden="true" class="anchor" id="user-content-additional-changes-1"></a>Additional Changes</h3> <p>17 minor improvements: 15 examples, 2 maintenance.</p> <h3><a href="#user-content-full-commit-range-1" aria-hidden="true" class="anchor" id="user-content-full-commit-range-1"></a>Full Commit Range</h3> <ul> <li>b9733 to b9780 (36 commits)</li> <li>Upstream releases: <a href="https://github.com/ggml-org/llama.cpp/compare/b9733...b9780">https://github.com/ggml-org/llama.cpp/compare/b9733...b9780</a></li> </ul> <hr /> <h2><a href="#user-content-2026-06-20-update-to-llamacpp-b9733" aria-hidden="true" class="anchor" id="user-content-2026-06-20-update-to-llamacpp-b9733"></a>2026-06-20: Update to llama.cpp b9733</h2> <h3><a href="#user-content-summary-2" aria-hidden="true" class="anchor" id="user-content-summary-2"></a>Summary</h3> <p>Updated llama.cpp from b9707 to b9733, incorporating 21 upstream commits with new features and performance improvements.</p> <h3><a href="#user-content-notable-changes-2" aria-hidden="true" class="anchor" id="user-content-notable-changes-2"></a>Notable Changes</h3> <h4><a href="#user-content--new-features-2" aria-hidden="true" class="anchor" id="user-content--new-features-2"></a>🆕 New Features</h4> <ul> <li><strong>b9715</strong>: Ggml/cuda col2im 1d (<a href="https://github.com/ggml-org/llama.cpp/pull/24417">#24417</a>) <ul> <li>CUDA backend follow-up to the CPU op ( <a href="https://github.com/ggml-org/llama.cpp/pull/24206">https://github.com/ggml-org/llama.cpp/pull/24206</a> ), same formulation: a gather kernel, one thread per output, each reading only the ceil(K/s0) columns that scatter into it. F32 / F16 / BF16 with an F32 accumulator.</li> <li>The flat idx -> (channel, time) decomposition uses fast_div_modulo, which buys back time on the cache resident F32 / F16 shapes where the kernel is ALU exposed; on the DRAM bound long shape it is a no op, as expected.</li> <li>Validated against the test-backend-ops grid merged with the CPU op, zero additional test code: 33/33 on CUDA0 across the eight geometries and three types, plus the three perf entries. CMake globs the new .cu, so the only wiring is the dispatch case and the supports_op entry next to conv_transpose_1d.</li> </ul> </li> </ul> <h4><a href="#user-content--performance-improvements-2" aria-hidden="true" class="anchor" id="user-content--performance-improvements-2"></a>🚀 Performance Improvements</h4> <ul> <li><strong>b9717</strong>: ggml-cpu: support K tails in power10 Q8/Q4 MMA matmul (<a href="https://github.com/ggml-org/llama.cpp/pull/24753">#24753</a>) <ul> <li>This patch removes the requirement that K be divisible by kc in the tinyBlas_Q0_PPC tiled matmul path. Process the final K panel using its actual depth and pass the reduced panel size through packing and kernel execution. This allows more workloads to use the MMA kernel and reduces fallback to mnpack.</li> <li>Performance Impact:</li> <li>~ 60% gain in PP speed with granite-3.38b-instruct Q8_0 and Q4_0 models tested with llama-bench -p 512 -n 1 on power10 ppc64le box.</li> </ul> </li> </ul> <h4><a href="#user-content--bug-fixes-2" aria-hidden="true" class="anchor" id="user-content--bug-fixes-2"></a>🐛 Bug Fixes</h4> <ul> <li><strong>b9712</strong>: cmake : fix ui build with read-only source (<a href="https://github.com/ggml-org/llama.cpp/pull/24752">#24752</a>) <ul> <li>When building out-of-tree against a read-only source, UI provisioning runs npm in the source tree, so it fails creating <code>node_modules</code> there. The fix stages the UI sources into a writable copy under the build dir and runs npm there, leaving the source tree untouched.</li> <li>Related issue:</li> <li><a href="https://github.com/ggml-org/llama.cpp/issues/24745">https://github.com/ggml-org/llama.cpp/issues/24745</a></li> </ul> </li> </ul> <h3><a href="#user-content-additional-changes-2" aria-hidden="true" class="anchor" id="user-content-additional-changes-2"></a>Additional Changes</h3> <p>18 minor improvements: 15 examples, 3 maintenance.</p> <h3><a href="#user-content-full-commit-range-2" aria-hidden="true" class="anchor" id="user-content-full-commit-range-2"></a>Full Commit Range</h3> <ul> <li>b9707 to b9733 (21 commits)</li> <li>Upstream releases: <a href="https://github.com/ggml-org/llama.cpp/compare/b9707...b9733">https://github.com/ggml-org/llama.cpp/compare/b9707...b9733</a></li> </ul> <hr /> <h2><a href="#user-content-2026-06-18-update-to-llamacpp-b9701" aria-hidden="true" class="anchor" id="user-content-2026-06-18-update-to-llamacpp-b9701"></a>2026-06-18: Update to llama.cpp b9701</h2> <h3><a href="#user-content-summary-3" aria-hidden="true" class="anchor" id="user-content-summary-3"></a>Summary</h3> <p>Updated llama.cpp from b9656 to b9701, incorporating 36 upstream commits with new features and performance improvements.</p> <h3><a href="#user-content-notable-changes-3" aria-hidden="true" class="anchor" id="user-content-notable-changes-3"></a>Notable Changes</h3> <h4><a href="#user-content--new-features-3" aria-hidden="true" class="anchor" id="user-content--new-features-3"></a>🆕 New Features</h4> <ul> <li><strong>b9661</strong>: vulkan: add col2im_1d op (<a href="https://github.com/ggml-org/llama.cpp/pull/24425">#24425</a>) <ul> <li>Vulkan backend follow-up to the CPU op ( <a href="https://github.com/ggml-org/llama.cpp/pull/24206">https://github.com/ggml-org/llama.cpp/pull/24206</a> ), same formulation: a gather shader, one invocation per output, each reading only the ceil(K/stride) columns that scatter into it. F32 / F16 / BF16, the BF16 path stores as uint16_t and converts through bf16_to_fp32 so it runs even on devices without native bf16.</li> <li>A 2D dispatch maps invocations directly to (t_out, oc), so there is no flat index decomposition and no div/mod to begin with, unlike the CUDA side.</li> <li>Validated against the test-backend-ops grid merged with the CPU op, zero additional test code: 33/33 on Vulkan0 across the eight geometries and three types, plus the three perf entries. Wiring sits next to conv_transpose_1d: shader registration in vulkan-shaders-gen, pipelines, push constants, dispatch and the supports_op entry.</li> </ul> </li> <li><strong>b9664</strong>: sycl: support reordered Q4_K/Q5_K/Q6_K MoE MUL_MAT_ID (<a href="https://github.com/ggml-org/llama.cpp/pull/24452">#24452</a>) <ul> <li>Extends the existing SYCL MoE <code>mul_mat_id</code> reorder path to Q6_K expert weights.</li> <li>This completes reordered MoE coverage for mixed K-quant MoE models whose down-projection experts are Q6_K. Existing Q4_K/Q5_K behavior is unchanged.</li> <li>Validation:</li> </ul> </li> <li><strong>b9667</strong>: vulkan: Support gated_delta_net with S_v=16 (<a href="https://github.com/ggml-org/llama.cpp/pull/24581">#24581</a>) <ul> <li>Add a pipeline variant for S_v=16, and logic to make sure the constraints in the shader are still satisfied.</li> <li>I have read and agree with the <a href="https://github.com/ggml-org/llama.cpp/blob/master/CONTRIBUTING.md">contributing guidelines</a></li> <li>AI usage disclosure: Used codex, I reviewed all the changes.</li> </ul> </li> <li><strong>b9668</strong>: vulkan: prefer host-visible memory buffers on UMA devices (<a href="https://github.com/ggml-org/llama.cpp/pull/22930">#22930</a>) <ul> <li>On UMA (Unified Memory Architecture) devices the CPU and GPU share the same physical memory. Despite this, the Vulkan backend was still allocating device-local buffers without the eHostVisible flag, which prevented the CPU from directly accessing GPU tensor data. This meant that even on hardware where a zero-copy path was physically possible, the backend was forced to go through an unnecessary staging copy whenever tensor data needed to be read back to the host (e.g. during loss evaluation or prediction readback in training). The UMA zero copy was not implemented in this PR.</li> <li> <!-- You can provide more details and link related discussions here. Delete this section if not applicable --> </li> </ul> </li> <li><strong>b9669</strong>: spec: add backend sampling support for eagle3 (<a href="https://github.com/ggml-org/llama.cpp/pull/24655">#24655</a>) <ul> <li> <!-- Describe what this PR does and why. Be concise but complete --> </li> <li>Following <a href="https://github.com/ggml-org/llama.cpp/pull/23287">https://github.com/ggml-org/llama.cpp/pull/23287</a> to add backend sampling support for eagle3.</li> <li>Performance results on SpeedBench</li> </ul> </li> <li><strong>b9670</strong>: Fix and restrict NVFP4 edge-cases in llama-graph (<a href="https://github.com/ggml-org/llama.cpp/pull/24331">#24331</a>) <ul> <li>Resolve edge-cases for NVFP4 surfaced in <a href="https://github.com/ggml-org/llama.cpp/pull/23484">https://github.com/ggml-org/llama.cpp/pull/23484</a>. I presume the intended flow of interaction between NVFP4 and lora/bias-adds to be:</li> <li><code>MUL_MAT / MUL_MAT_ID -> NVFP4-post-mul | lora-residuals | bias-add | LLM-arch-w_s</code></li> <li>where <code>|</code> denotes optional operators. Current implementation did not adhere to this previously.</li> </ul> </li> <li><strong>b9677</strong>: common: update logging to enforce max_capacity and optimize queue resizing (<a href="https://github.com/ggml-org/llama.cpp/pull/24490">#24490</a>) <ul> <li>I'm working on adding more Op tracing to the hexagon backend and ran into an issue with our current logging implementation. If the logging rate is consistently much higher than the flushing rate then the queue will just keep growing and growing without any bounds eventually resulting in an exception when malloc finally fails.</li> <li>This PR updates the logger to enforce <code>max_capacity</code> limit which is currently set to 4K entries.</li> <li>I also re-wrote how the queue resizing is done. Now the producer threads are super simple they just block on full queue.</li> </ul> </li> <li><strong>b9689</strong>: metal : add f16 and bf16 support for concat operator (<a href="https://github.com/ggml-org/llama.cpp/pull/24724">#24724</a>) <ul> <li>Extend the Metal backend concat operator to support f16, bf16, i8, i16, and i64.</li> <li>I have read and agree with the <a href="https://github.com/ggml-org/llama.cpp/blob/master/CONTRIBUTING.md">contributing guidelines</a></li> <li>AI usage disclosure: YES. pi:llama.cpp/Qwen3.6-27B</li> </ul> </li> <li><strong>b9690</strong>: metal : implement rope_back operator (<a href="https://github.com/ggml-org/llama.cpp/pull/24725">#24725</a>) <ul> <li>Add Metal backend support for <code>ROPE_BACK</code> by reusing existing rope kernels with a function constant to toggle forward/backward rotation.</li> <li><input type="checkbox" checked="" disabled="" /> I have read and agree with the <a href="https://github.com/ggml-org/llama.cpp/blob/master/CONTRIBUTING.md">contributing guidelines</a></li> <li>AI usage disclosure: YES. pi:llama.cpp/Qwen3.6-27B</li> </ul> </li> <li><strong>b9691</strong>: ggml: Conditionally enable power11 backend based on compiler support (<a href="https://github.com/ggml-org/llama.cpp/pull/24687">#24687</a>) <ul> <li>Guard POWER11 backend creation behind a compiler flag check for -mcpu=power11. This avoids build failures on current GCC/Clang toolchains while preserving forward compatibility once POWER11 support becomes available.</li> <li> <!-- Describe what this PR does and why. Be concise but complete --> </li> <li> <!-- You can provide more details and link related discussions here. Delete this section if not applicable --> </li> </ul> </li> <li><strong>b9699</strong>: [SYCL] support MUL_MAT and OUT_PROD with Q1_0 (<a href="https://github.com/ggml-org/llama.cpp/pull/24721">#24721</a>) <ul> <li>Implement the feature request: <a href="https://github.com/ggml-org/llama.cpp/issues/21641">https://github.com/ggml-org/llama.cpp/issues/21641</a></li> <li>support MUL_MAT and OUT_PROD with Q1_0.</li> <li>all related UT cases are passed.</li> </ul> </li> </ul> <h4><a href="#user-content--performance-improvements-3" aria-hidden="true" class="anchor" id="user-content--performance-improvements-3"></a>🚀 Performance Improvements</h4> <ul> <li><strong>b9678</strong>: opencl: optimize mul_mat_f16_f32 for decode (<a href="https://github.com/ggml-org/llama.cpp/pull/24504">#24504</a>) <ul> <li> <!-- Describe what this PR does and why. Be concise but complete --> </li> <li>The mul_mat_f16_f32 kernels do not perform well for decoding due to its work assignment, where each subgroup either produces a single result or in some cases half of a subgroup stays idle. This PR increase the work of each workgroup to better utilize the GPU.</li> <li> <!-- You can provide more details and link related discussions here. Delete this section if not applicable --> </li> </ul> </li> </ul> <h4><a href="#user-content--bug-fixes-3" aria-hidden="true" class="anchor" id="user-content--bug-fixes-3"></a>🐛 Bug Fixes</h4> <ul> <li><strong>b9656</strong>: chat: harden peg-native tool call parsing (<a href="https://github.com/ggml-org/llama.cpp/pull/24329">#24329</a>) <ul> <li>While working we hit a silent bug on llama 3.3 dense: the assistant turn came back empty, no error shown. It only happened with tools enabled. The model emits a tool call in a variant format that the peg-native parser rejects, which blew up the whole turn. I landed a debug log first to confirm exactly what the model was emitting, then the actual fix: accept the "type": "function" variant, and fail soft on parse errors instead of tearing down the turn.</li> <li>A bug was discovered while working on this PR <a href="https://github.com/ggml-org/llama.cpp/pull/23226">https://github.com/ggml-org/llama.cpp/pull/23226</a> that allows the system to see when an error occurs; otherwise, it's silent (empty assistant turn). This PR adds the missing error if the PEG fails.</li> <li> <img width="579" height="279" alt="604615515-bd9a70de-baf7-44bb-99c4-9701cd714d17" src="https://github.com/user-attachments/assets/f09ec7f8-eab5-402b-a503-3b19133747bb" /> </li> </ul> </li> <li><strong>b9658</strong>: chat: include full unparsed prompt in debug message on parse error (<a href="https://github.com/ggml-org/llama.cpp/pull/24650">#24650</a>) <ul> <li>As in topic.</li> <li>Minimal change to enable dumping full unparsed prompt.</li> <li>Need for debugging parser errors.</li> </ul> </li> <li><strong>b9660</strong>: chat : fix LFM2 tool-call parsing double-escaping (<a href="https://github.com/ggml-org/llama.cpp/pull/24667">#24667</a>) <ul> <li>Prevent double escaping in the LFM2 tool-calling parser</li> <li>Output before fix:</li> <li> <pre><code class="language-json">
- Implement
- b9674: SYCL: fix use-after-free bug with async memcpy in MoE prefill (#24676)
- Make the source buffer persistent to make sure it survives the async host-to-device SYCL copy beyond the function scope. We rely on the existing synchronization to protect it against use-after-scope (or overwrite-before-drain).
- This dedicated buffer is metadata-only; for current MoE models it is well under 1 MiB.
- This a bugfix for a use-after-free bug in #23142.
- b9680: ci: fix vulkan docker images (#24595)
- Starting with
b9438vulkan docker images produced by CI are broken. We run out of memory during shaders generation. CI doesn't report an error, but build artifact are corrupted. - https://github.com/ggml-org/llama.cpp/actions/runs/27397273833/job/80967212036#step:9:2828
-
- Starting with
- b9686: spec: fix segfault error on long prompts for eagle3 (#24707)
- Fix https://github.com/ggml-org/llama.cpp/issues/24637
- Eagle3 speculative decoding crashes with a segmentation on long prompts. The draft decoder sizes its input-embeddings batch with the wrong embedding dimension, producing an out-of-bounds read that only manifests once the prompt is long enough for the copy offset to cross the allocated buffer.
- Printing
n_embd_inp/n_embd/n_embd_outshows a draft-only mismatch (Gemma4 26B-A4B):
- b9687: fix: skip main_gpu validation when no gpus are available (#23405)
- Setting
--split-mode noneon a CPU-only build causes model loading to fail (see trace below), because main_gpu defaults to 0 and the bounds check fired against an empty device list. The accompanying warning already states that split mode should have no effect without GPU support - so this PR makes it so we skip the GPU filtering block entirely. -
</code></pre> </li> <li>[52521] warning: llama.cpp was compiled without support for GPU offload. Setting the split mode has no effect.</li> </ul> </li> <li><strong>b9693</strong>: metal : check for BF16 support in concat kernel (<a href="https://github.com/ggml-org/llama.cpp/pull/24747">#24747</a>) <ul> <li>cont #24724</li> <li>Fixes <a href="https://github.com/ggml-org/llama.cpp/pull/24724#issuecomment-4736311329">https://github.com/ggml-org/llama.cpp/pull/24724#issuecomment-4736311329</a></li> <li> <!-- IMPORTANT: Please do NOT delete this section, otherwise your PR may be rejected --> </li> </ul> </li> <li><strong>b9694</strong>: openvino: Fix Windows x64 (OpenVINO) release link. (<a href="https://github.com/ggml-org/llama.cpp/pull/24731">#24731</a>) <ul> <li>Fixes the Windows x64 (OpenVINO) release link.</li> <li>The <code>windows-openvino</code> release job output-writing step is updated to use <code>shell: bash</code> to match the <code> >> $GITHUB_OUTPUT</code> syntax.</li> <li>This step ran with PowerShell, which requires the $ env:$GITHUB_OUTPUT syntax. As a result, <code>needs.windows-openvino.outputs.openvino_version</code> was empty when generating the release notes and produced a broken link like:</li> </ul> </li> <li><strong>b9697</strong>: ci : fix check-release message parsing (<a href="https://github.com/ggml-org/llama.cpp/pull/24751">#24751</a>) <ul> <li>cont #23734</li> <li>Fixes <a href="https://github.com/ggml-org/llama.cpp/actions/runs/27677733066/job/81899124840">https://github.com/ggml-org/llama.cpp/actions/runs/27677733066/job/81899124840</a></li> <li>The <code>check-release</code> job would fail if the commit message had quotes in it.</li> </ul> </li> </ul> <h3><a href="#user-content-additional-changes-3" aria-hidden="true" class="anchor" id="user-content-additional-changes-3"></a>Additional Changes</h3> <p>14 minor improvements: 7 documentation, 4 examples, 3 maintenance.</p> <h3><a href="#user-content-full-commit-range-3" aria-hidden="true" class="anchor" id="user-content-full-commit-range-3"></a>Full Commit Range</h3> <ul> <li>b9656 to b9701 (36 commits)</li> <li>Upstream releases: <a href="https://github.com/ggml-org/llama.cpp/compare/b9656...b9701">https://github.com/ggml-org/llama.cpp/compare/b9656...b9701</a></li> </ul> <hr /> <h2><a href="#user-content-2026-06-15-update-to-llamacpp-b9645" aria-hidden="true" class="anchor" id="user-content-2026-06-15-update-to-llamacpp-b9645"></a>2026-06-15: Update to llama.cpp b9645</h2> <h3><a href="#user-content-summary-4" aria-hidden="true" class="anchor" id="user-content-summary-4"></a>Summary</h3> <p>Updated llama.cpp from b9611 to b9645, incorporating 19 upstream commits with breaking changes, new features, and performance improvements.</p> <h3><a href="#user-content-notable-changes-4" aria-hidden="true" class="anchor" id="user-content-notable-changes-4"></a>Notable Changes</h3> <h4><a href="#user-content-️-breaking-changes-2" aria-hidden="true" class="anchor" id="user-content-️-breaking-changes-2"></a>⚠️ Breaking Changes</h4> <ul> <li><strong>b9611</strong>: fit : avoid including llama-ext.h in fit.h (<a href="https://github.com/ggml-org/llama.cpp/pull/24506">#24506</a>) <ul> <li>cont #23485</li> <li>We should be careful to not include <code>llama-ext.h</code> in too many places. The header contains mostly temporary workarounds and it's impact has to be limited so that we can remove them over time.</li> <li> <!-- IMPORTANT: Please do NOT delete this section, otherwise your PR may be rejected --> </li> </ul> </li> <li><strong>b9616</strong>: ci : unbreak release harder (<a href="https://github.com/ggml-org/llama.cpp/pull/24545">#24545</a>) <ul> <li>cont #23871</li> <li>Some release builds broke due to missing line continuation.</li> </ul> </li> </ul> <h4><a href="#user-content--new-features-4" aria-hidden="true" class="anchor" id="user-content--new-features-4"></a>🆕 New Features</h4> <ul> <li><strong>b9626</strong>: Add arch support for cohere2-MoE (<a href="https://github.com/ggml-org/llama.cpp/pull/24260">#24260</a>) <ul> <li> <!-- Describe what this PR does and why. Be concise but complete --> </li> <li>There's a new [early preview](<a href="https://www.reddit.com/r/LocalLLaMA/comments/1tylzy2/coheres_unreleased_coding_model_early_access_for/">https://www.reddit.com/r/LocalLLaMA/comments/1tylzy2/coheres_unreleased_coding_model_early_access_for/</a></li> <li>) of CohereLab's <code>North-Mini-Code-1.0</code> MoE coding model with <a href="https://huggingface.co/CohereLabs/North-Mini-Code-1.0/tree/main">weights</a> that I wanted to test and add full implementation for.</li> </ul> </li> <li><strong>b9628</strong>: ci : add sycl to check-release (<a href="https://github.com/ggml-org/llama.cpp/pull/24583">#24583</a>) <ul> <li>cont #24387</li> <li>Forgot to add <code>check-release</code> on SYCL jobs.</li> </ul> </li> <li><strong>b9630</strong>: Add cohere2moe to llama-vocab for TINY_AYA (<a href="https://github.com/ggml-org/llama.cpp/pull/24601">#24601</a>) <ul> <li><code>cohere2moe</code> is missing from llama-vocap.cpp, resulting in it not being recognized and not loading</li> <li> <!-- IMPORTANT: Please do NOT delete this section, otherwise your PR may be rejected --> </li> <li>I have read and agree with the <a href="https://github.com/ggml-org/llama.cpp/blob/master/CONTRIBUTING.md">contributing guidelines</a></li> </ul> </li> <li><strong>b9632</strong>: jinja : add count/d/e filter aliases (<a href="https://github.com/ggml-org/llama.cpp/pull/24606">#24606</a>) <ul> <li>Add missing filter aliases.</li> <li><code>count</code> -> <code>length</code></li> <li><code>d</code> -> <code>default</code></li> </ul> </li> <li><strong>b9637</strong>: chat: add dedicated Cohere2MoE (North Code) parser (<a href="https://github.com/ggml-org/llama.cpp/pull/24615">#24615</a>) <ul> <li>The Cohere2 MoE template is pretty special, so using the autoparser even with workarounds didn't really work. Needed a dedicated parser.</li> <li>Please use the template in <code>models/templates/Cohere2-MoE.jinja</code> - some GGUFs have an old / incorrect template for some reason.</li> </ul> </li> <li><strong>b9642</strong>: CUDA: only support F32/F16 for GGML_OP_REPEAT (<a href="https://github.com/ggml-org/llama.cpp/pull/24533">#24533</a>) <ul> <li><code>ggml_backend_cuda_device_supports_op</code> reported <code>GGML_OP_REPEAT</code> as supported for every type except <code>I32</code>/<code>I16</code> (a blacklist). The CUDA path only implements <code>F32</code> and <code>F16</code>: other types (<code>BF16</code>, k-quants, ...) hit a <code>GGML_ASSERT</code> / <code>GGML_ABORT</code> in <code>ggml_cuda_op_bin_bcast</code> (<code>binbcast.cu</code>) at runtime instead of falling back to the CPU backend. <code>supports_op</code> should not advertise dtypes whose CUDA execution path asserts.</li> <li>Switch the check to a whitelist of the types the kernel actually implements (<code>F32</code>/<code>F16</code>). Unsupported types now fall back to CPU; <code>I32</code>/<code>I16</code> behaviour is unchanged.</li> </ul> </li> <li><strong>b9645</strong>: metal : add repeat bf16 (<a href="https://github.com/ggml-org/llama.cpp/pull/24638">#24638</a>) <ul> <li>cont #24533</li> <li>Add BF16 variant of repeat kernel.</li> <li> <!-- IMPORTANT: Please do NOT delete this section, otherwise your PR may be rejected --> </li> </ul> </li> </ul> <h4><a href="#user-content--performance-improvements-4" aria-hidden="true" class="anchor" id="user-content--performance-improvements-4"></a>🚀 Performance Improvements</h4> <ul> <li><strong>b9622</strong>: vulkan: Use cm2 decode_vector for mul_mat_id B matrix loads (<a href="https://github.com/ggml-org/llama.cpp/pull/23991">#23991</a>) <ul> <li>This allows vec4 loads of the B elements. Also increase BK to 64 when this is enabled. Neither of these alone is consistently faster, but together these give a nice speedup.</li> <li>In ggml-vulkan.cpp, we need to make sure the B matrix alignment and stride are multiples of 4.</li> <li> <pre><code>
- Setting
🐛 Bug Fixes
- b9623: jinja : fix split and replace with empty first arg (#24574)
- Fixes #24555
- Properly support
split/rsplit/replacemethods with empty string as first argument (the two former will raise an error, as opposed to currently unsupported non-specified split (consecutive whitespace)).
- b9625: jinja : fix negative step slice with start/stop values (#24580)
- Fixes #24556
- When doing negative step slices the
startandstopvalues were being ignored.
Additional Changes
7 minor improvements: 1 documentation, 6 examples.
Full Commit Range
- b9611 to b9645 (19 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b9611...b9645
2026-06-12: Update to llama.cpp b9611
Summary
Updated llama.cpp from b9611 to b9611, incorporating 1 upstream commits with breaking changes.
Notable Changes
⚠️ Breaking Changes
- b9611: fit : avoid including llama-ext.h in fit.h (#24506)
- cont #23485
- We should be careful to not include
llama-ext.hin too many places. The header contains mostly temporary workarounds and it's impact has to be limited so that we can remove them over time.
Full Commit Range
- b9611 to b9611 (1 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b9611...b9611
2026-06-12: Update to llama.cpp b9611
Summary
Updated llama.cpp from b9611 to b9611, incorporating 1 upstream commits with breaking changes.
Notable Changes
⚠️ Breaking Changes
- b9611: fit : avoid including llama-ext.h in fit.h (#24506)
- cont #23485
- We should be careful to not include
llama-ext.hin too many places. The header contains mostly temporary workarounds and it's impact has to be limited so that we can remove them over time.
Full Commit Range
- b9611 to b9611 (1 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b9611...b9611
2026-06-12: Update to llama.cpp b9611
Summary
Updated llama.cpp from b9596 to b9611, incorporating 10 upstream commits with breaking changes, new features, and performance improvements.
Notable Changes
⚠️ Breaking Changes
- b9604: [SYCL] Fix CI build & release for SYCL backend (#24387)
- Fix CI build & release for SYCL backend:
-
- restore build & release SYCL backend in CI
-
- remove action for github cache.
- b9611: fit : avoid including llama-ext.h in fit.h (#24506)
- cont #23485
- We should be careful to not include
llama-ext.hin too many places. The header contains mostly temporary workarounds and it's impact has to be limited so that we can remove them over time.
🆕 New Features
- b9601: vulkan: ifdef eMesaHoneykrisp (build fix) (#24479)
- Fixes build/CI after #24306.
- I have read and agree with the contributing guidelines
- AI usage disclosure: YES, had codex find which version adds the enum, and then added the ifdef
- b9605: ggml: support concat for scalar types at cuda backend (#24011)
- Make CUDA CONCAT support common non-quantized scalar tensor types, not just F32.
- The CUDA CONCAT kernel now works for same-type, non-quantized scalar tensors with 1, 2, 4, or 8 byte elements.
- F16, BF16, I8, I16, I32, I64, and F32.
🚀 Performance Improvements
- b9601: vulkan: use medium matmul tile on Asahi Linux (#24306)
- This PR detects Apple AGX architecture and sets matmul tile size to medium. Currently the Asahi driver in Mesa reports a different vendor ID than VK_VENDOR_ID_APPLE so the 'picking medium tile size for apple' route doesn't trigger and falls back to large. This causes degraded prefill performance.
-
- xingjianliu@fedora:~/repos/llama.cpp$ ./build/bin/llama-bench -m ~/repos/llama-2-7b.Q4_0.gguf
- b9603: opencl: add q5_0/q5_1 gemm and gemv kernels for Adreno (#24319)
- Add q5_0 and q5_1 GEMM and GEMV kernels to the Adreno backend to improve performance for q5 quantized models.
Additional Changes
4 minor improvements: 2 examples, 2 maintenance.
- b9596: server: skip unused log lines on router mode (#24463)
- Skip irrelevant log lines to avoid confusion
- I have read and agree with the contributing guidelines
- b9606: [Speculative decoding] feat: add EAGLE3 speculative decoding support (#18039)
-
[!IMPORTANT]
-
The old PR has been backed up in this branch: https://github.com/ruixiang63/llama.cpp/tree/eagle3-v1-backup
- The new commits in this PR have been rebased onto the latest master branch, refactored to use the new speculative API, cherry-picked from https://github.com/ggml-org/llama.cpp/pull/22728, and made compatible with MTP.
-
- b9608: vendor : update cpp-httplib to 0.47.0 (#24395)
- b9610: b9610
-
Full Commit Range
- b9596 to b9611 (10 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b9596...b9611
2026-06-11: Update to llama.cpp b9596
Summary
Updated llama.cpp from b9581 to b9596, incorporating 10 upstream commits with breaking changes and new features.
Notable Changes
⚠️ Breaking Changes
- b9584: ci : fix windows release (#24369)
- Fix Windows release build.
- The
windows-2025runner has started forwarding towindows-2025-vs2026, breaking build. - Test run: https://github.com/CISC/llama.cpp/actions/runs/27220214596
- b9591: Remove padding and multiple D2D copies for MTP (#24086)
- Based on @ggerganov's suggestion at https://github.com/ggml-org/llama.cpp/pull/23940#issuecomment-4602287259
- Make
ggml_gated_delta_nettake only the initial recurrent state (D, 1, n_seqs) and pass the snapshot count K as an op parameter instead of inferring it from state->ne[1]. - Remove the padding hack and copy all emitted snapshots into the recurrent cache with a single strided ggml_cpy
🆕 New Features
- b9581: vulkan: reduce iq1 shared memory usage for mul_mm (#24287)
- Ifdef iq1s_grid_gpu so it's only used in mmvq, this keeps the shared memory usage under 16KB for mul_mm.
- Fixes #24284.
- I have read and agree with the contributing guidelines
- b9587: speculative : fix "ngram-map-k4v" name in logging (#24253)
- This is a non-functional change.
- When using
--spec-type ngram-map-k4v, the log messages at startup and runtime sayngram-map-k. Added logic in the in the constructor ofcommon_speculative_impl_ngram_map_kto pass the correctCOMMON_SPECULATIVE_TYPE_NGRAM_MAP_K4Vwhenconfig.key_onlyisfalse. - After this change, the log messages use the correct name.
- b9594: vocab : refactor normalizer flags into options struct, add strip_accents (#24371)
- WPM previously applied NFD unconditionally, so accented words on case-sensitive models (e.g.
German_Semantic_V3, which setsstrip_accents: false) didn't matchtransformers. - NFD is now applied only when
strip_accentsis set.
- WPM previously applied NFD unconditionally, so accented words on case-sensitive models (e.g.
🐛 Bug Fixes
- b9589: CUDA: Fix ssm_scan_f32 data-races (#24360)
- Add required
__synchthreads()to avoid data-races inssm_scan_f32. Also remove unused smem from the kernel. - Should supersede https://github.com/ggml-org/llama.cpp/pull/23983 as it fixes the underlying issues (which are data-races, where https://github.com/ggml-org/llama.cpp/commit/4fbecf73a583e9312249f8b7ef7c587b0eb1fcc3 applies to HIP/MUSA backends as well). For more details on the races, refer the individual commit messages.
- Should resolve sporadic failures of CUDA CI such as https://github.com/ggml-org/llama.cpp/actions/runs/27192383880/job/80275487186?pr=24331 (verified this on a local DGX Spark)
- Add required
- b9590: chat: fix LFM2/LFM2.5 ignoring json_schema (#24377)
- The LFM2 specialized template handler only built a grammar for tool-calling, silently ignoring json_schema from response_format.
- Use
Additional Changes
3 minor improvements: 2 examples, 1 maintenance.
- b9585: Fix granite speech model inference by applying embedding scale when deepstack is not used (#24357)
- Granite speech inference stopped working as a result of #23545 (found via git bisect). It would just output a bunch of asterisks indefinitely. The culprit was an if statement in llama-graph.cpp that didn't scale raw embeddings, which was correct for granite vision (since it has deepstack layers), but not for granite speech.
- This commit fixes that by adding a guard for deepstack layers to that if statement. This fixes granite speech without affecting granite vision.
- I have read and agree with the contributing guidelines
- b9596: server: skip unused log lines on router mode (#24463)
- Skip irrelevant log lines to avoid confusion
- I have read and agree with the contributing guidelines
- b9592: vendor : update LibreSSL to 4.3.2 (#24397)
Full Commit Range
- b9581 to b9596 (10 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b9581...b9596
2026-06-09: Update to llama.cpp b9581
Summary
Updated llama.cpp from b9541 to b9581, incorporating 32 upstream commits with new features and performance improvements.
Notable Changes
🆕 New Features
- b9564: [ggml-webgpu] Implement 2D workgroups for scale, binary, and unary ops (#24044)
- When running the WebGPU backend with stable-diffusion.cpp, it dispatched the following kernels with too many workgroups:
scale, add, mul, silu. - Apply the same technique as https://github.com/ggml-org/llama.cpp/pull/23750/ to dispatch 2D workgroups to run these models.
- Tested with
test-backend-ops -b WebGPUand CI suite locally.
- When running the WebGPU backend with stable-diffusion.cpp, it dispatched the following kernels with too many workgroups:
- b9568: mtp: support for gemma-4 E2B and E4B assistants (#24282)
- Just a few small updates to enable conversion and loading of the smaller E2B and E4B gemma-4 assistant models.
- The main issue was that those models include two additional tensors that we currently do not support.
masked_embedding.centroids.weightandmasked_embedding.token_ordering.
- b9570: ggml-webgpu: Add clang-format job (#24308)
- To avoid dealing with conflicting clang-format versions for contributors, this job ensures that the formatting is standardized. See discussion in https://github.com/ggml-org/llama.cpp/pull/24044.
- I have read and agree with the contributing guidelines
- b9575: Ggml/cpu col2im 1d (#24206)
- CPU part of #23424, split per review feedback; the CUDA backend follows in a separate PR.
- Modern neural audio vocoders (the BigVGAN family and its descendants) build their generator from upsampling blocks: a transposed 1D convolution followed by an AMP / Snake stack. The transposed conv is the upsampler, Snake ( https://github.com/ggml-org/llama.cpp/pull/22667 ) is the periodic activation, and both sit on the hot path of every generated frame.
- A ConvTranspose1d factorizes exactly as a GEMM followed by an overlap-add:
- b9580: vulkan: add
v_dot2_f32_f16support in matrix-matrix multiplication and Flash Attention (#24123)- This PR adds basic support for the Vulkan extension
VK_VALVE_shader_mixed_float_dot_product. The background to this is that AMD Vega20, Navi14 and RDNA2+ GPUs have fp16 dot2 instructions for machine learning acceleration that are not emitted by the shader compiler due to numerical inconsistencies. The extension allows shaders to manually emit them. - This PR adds support for the
v_dot2_f32_f16fp16 packed dot product with fp32 accumulator in matrix-matrix multiplications and Flash Attention. This is a good improvement for AMD GPUs with this instruction, but without coopmat support. -
- This PR adds basic support for the Vulkan extension
- b9581: vulkan: reduce iq1 shared memory usage for mul_mm (#24287)
- Ifdef iq1s_grid_gpu so it's only used in mmvq, this keeps the shared memory usage under 16KB for mul_mm.
- Fixes #24284.
- I have read and agree with the contributing guidelines
🚀 Performance Improvements
- b9551: kv-cache : avoid kv cells copies (#24277)
- cont #23398
- alt #24270
- The
llama_kv_cellscopy inapply_ubatchcan become expensive in some host configurations. This will be refactored properly, but for now a quick patch to avoid the performance hit.
- b9558: vulkan: Use cm2 decode_vector for mul_mat_id B matrix loads (#23991)
- This allows vec4 loads of the B elements. Also increase BK to 64 when this is enabled. Neither of these alone is consistently faster, but together these give a nice speedup.
- In ggml-vulkan.cpp, we need to make sure the B matrix alignment and stride are multiples of 4.
-
🐛 Bug Fixes
- b9544: common/chat : fix LFM2/LFM2.5 reasoning round-trip and leak (#24234)
- Follow-up on review comment https://github.com/ggml-org/llama.cpp/pull/24178#pullrequestreview-4438323720 made by @aldehir.
- For LFM2/LFM2.5 models, copy
reasoning_contentintothinking. - LFM2.5-8B-A1B is always a reasoning model. The chat template doesn't have a switch to disable it. This leads to a leak of
thinkingintocontentwith reasoning disabled (-rea off). (reported here https://github.com/ggml-org/llama.cpp/pull/24178#issuecomment-4638237698).
- b9548: speculative : fix vocab compatibility check (#24256)
- Fixes
enumbeing coerced toboolbefore comparison. - This effectively made the check always succeed.
- Fixes
- b9550: kv-cache: follow the source cache size when sharing cells (#24267)
- With --fit the trunk context can shrink below the draft default, the assistant then builds views sized for its own kv_size into the smaller shared K/V tensors and trips the ggml_view_4d assert during graph reserve. Follow the source cache size when sharing cells.
- Reproduced and verified on CUDA (RTX PRO 6000 Blackwell, single GPU) and confirmed by @Stastez on ROCm (dual GPU) in the original report: https://github.com/ggml-org/llama.cpp/pull/23398#issuecomment-4643048368
- The override also normalizes a small base/SWA sizing mismatch between the two caches (4608 vs 4096) that exists independently of --fit.
- b9555: metal : fix im2col 1D case (audio models) (#24220)
- Fix a regression cause by #23901 , happens on conv1d op (audio models)
- With this change, audio models work correctly:
-
- b9556: HIP: add gfx1152 and gfx1153 to RDNA3.5 (#24129)
- Add gfx1152 and gfx1153 definitions to RDNA3.5 macro in
ggml/src/ggml-cuda/vendors/hip.h. - Resolves https://github.com/ROCm/TheRock/issues/5579 where users report corrupted output with TheRock nightlies + llama.cpp build from source. Patching this change in resolves the issue.
- Add gfx1152 and gfx1153 definitions to RDNA3.5 macro in
- b9565: [ggml-webgpu] Handle buffer overlap / buffer aliasing for concat operator (#24000)
- While testing the WebGPU backend with stable-diffusion.cpp, I encountered the following error:
-
- Device error! Reason: 2, Message: Writable storage buffer binding aliasing found between [BindGroup "concat_f32"]
- b9566: graph: guard iswa kq_mask on its own buffer (#24294)
- Fix load crash for draft-mtp models with a SWA-only draft head (e.g. StepFun Step-3.7-Flash). The draft's base (non-SWA) sub-cache has no layers, so its kq_mask buffer stays null and set_input_kq_mask asserts during the seq_rm probe at load. Guard each kq_mask on its own buffer in set_input and can_reuse, base and swa.
- Following #23398 (Gemma 4 MTP), regression on StepFun Step-3.7-Flash loading reported by @vbooka1, confirmed by @forforever73. Thanks @ggerganov for the can_reuse guards; guarding on the mask's own buffer (not self_k_idxs_swa) covers the SWA-only case too. Tested on Step-3.7-Flash (Q2_K_XL + Q8/BF16 draft, q8_0 and f16 KV): loads clean, greedy output identical with/without MTP. Needs --spec-draft-n-max 1 (Step MTP head is single-token).
- b9572: ggml-cpu : fix rms_norm_back wrong output under in-place aliasing (#24305)
ggml_compute_forward_rms_norm_back_f32could produce wrong results when the destination aliases an input.GGML_OP_RMS_NORM_BACKis listed inggml_op_can_inplace, so the scheduler may reusesrc0(dz) orsrc1(x)'s buffer fordx. The old multi-stepcpy/scale/acc/scalesequence overwrote that buffer in thedx := xstep and then re-read it in the+= dzstep. This replaces it with a single fused read-before-write loop, which is safe under either aliasing.- Requested by @ggerganov in ggml-org/ggml#1519, where I originally reported and fixed this (#1491). Submitting the single ops.cpp change here as asked; no regression test per that thread. Built
ggml-cpulocally on macOS to confirm it compiles.
- b9573: model : fix plamo2 attention_key/value_length regression (#24317)
- Fixes incorrect tensor sizes and FPE due to bad assert.
- At some point after #16075, possibly during one of the refactors; hard to tell, these metadata overrides got lost.
- The assert was probably copy-pasted from
mamba-base, but theren_headis reassigned while the same (hparams.ssm_dt_rank) variable is calledn_headshere.
Additional Changes
15 minor improvements: 1 documentation, 11 examples, 3 maintenance.
Full Commit Range
- b9541 to b9581 (32 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b9541...b9581
2026-06-06: Update to llama.cpp b9538
Summary
Updated llama.cpp from b9528 to b9538, incorporating 10 upstream commits with new features and performance improvements.
Notable Changes
🆕 New Features
- b9528: ui: run npm install when package-lock.json is newer than node_modules (#24171)
- This PR makes ui-assets.cmake rerun npm install whenever package-lock.json is newer than the node_modules/.package-lock.json marker that npm writes on every successful install. Same timestamp comparison technique already used by npm_build_should_skip. No extra install on up-to-date trees.
- Follow-up to #24119 (reported by @el00ruobuob): when node_modules predates that PR, the build script skips npm install (it only runs it when node_modules is missing), so the new
@vitest/browser-playwrightimport in vite.config.ts fails with ERR_MODULE_NOT_FOUND.
- b9534: vulkan: add fwht support for Intel with shmem reduction (#23964)
- Add a FWHT shader path that does not rely on subgroup size and collectives for Intel GPUs.
- I have read and agree with the contributing guidelines
- AI usage disclosure: YES, Claude wrote the code, I corrected and reviewed.
- b9536: opencl: improve get_rows, cpy, concat and q6_k flat gemv (#24160)
- Current implementations of get_rows, cpy and concat perform poorly with Qwen3.5. In particular, they all assign one workgroup to one row. When there is only one large row or a lot of very small rows, GPU becomes underutilized. This is improved in this PR.
- This PR also tweaks how threads are mapped to data to improve coalescing in Q6_K flat gemv kernel. This helps with models with Q6_K output weights.
🚀 Performance Improvements
- b9531: TP: round up granularity to 128 (#24180)
- On master for
-sm tensorthe tensors are split to the minimum possible granularity. However, for performance it seems to be preferable to round the granularity up to a larger power of 2, 128 seems to be a good value. This should only make a difference when -
- the number of GPUs or the tensor dimensions are not a power of 2 and if
-
- FP16/BF16/FP32 or a legacy quant are used.
- On master for
🐛 Bug Fixes
- b9529: model : fix llama_model::n_gpu_layers() (#24188)
- cont #24060
- fix #24183
- fix #24182
- b9533: model: fix build failed (#24193)
- Small merge conflict from https://github.com/ggml-org/llama.cpp/pull/23545
- cc @ggml-org/maintainers if someone can give a quick approval
- b9535: common/chat : unify and fix LFM2/LFM2.5 tool parser (#24178)
- LFM2 and LFM2.5 share the same pythonic style tool-calling format, with the only difference being that LFM2 also wraps the system tool list in <|tool_list_start|>/<|tool_list_end|>.
- Two parsers are merged into
common_chat_params_init_lfm2(..., tool_list_tokens)and share logic. - Also fix and extend argument parsing:
- b9537: context : fix off-by-one comparisons to n_gpu_layers (#24208)
- cont #24060
- Compare
n_gpu_layersagainstn_layer_allinstead ofn_layer.
Additional Changes
2 minor improvements: 1 examples, 1 maintenance.
- b9530: llama-cli: fix model params not propagated (#23893)
- Fixes #23847
- I have read and agree with the contributing guidelines
- b9538: model : rename local n_layer_all variable (#24209)
- cont #24060
- Non-functional change, just variable clarification.
Full Commit Range
- b9528 to b9538 (10 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b9528...b9538
2026-06-05: Update to llama.cpp b9528
Summary
Updated llama.cpp from b9510 to b9528, incorporating 10 upstream commits with new features and performance improvements.
Notable Changes
🆕 New Features
- b9522: kleidiai : dynamic chunck-based scheduling for hybrid execution (#23819)
- This update is to replace the static weighting model with a dynamic chunk-based scheduling approach, leveraging the recently introduced repack matmul chunking mechanism (PR #16833). The goal is to enable adaptive, runtime-driven work distribution between SME and NEON kernels without relying on hardcoded ratios.
- Benchmarks from Samsung S26 Exynos — Llama-3.2-1B-Instruct-Q4_0 (pp512)
- Threads | Global Queue (t/s) | Static Quadratic (t/s) | Δ (%)
- b9528: ui: run npm install when package-lock.json is newer than node_modules (#24171)
- This PR makes ui-assets.cmake rerun npm install whenever package-lock.json is newer than the node_modules/.package-lock.json marker that npm writes on every successful install. Same timestamp comparison technique already used by npm_build_should_skip. No extra install on up-to-date trees.
- Follow-up to #24119 (reported by @el00ruobuob): when node_modules predates that PR, the build script skips npm install (it only runs it when node_modules is missing), so the new
@vitest/browser-playwrightimport in vite.config.ts fails with ERR_MODULE_NOT_FOUND.
🚀 Performance Improvements
- b9519: sycl : port multi-column MMVQ from CUDA backend (~45% speculative decoding speedup on Intel Arc) (#21845)
- Speculative decoding on SYCL is currently slower than single-token-prediction because the MMVQ dispatch launches a separate kernel per column, reading the full weight matrix N times.
- Port the multi-column optimization from the CUDA backend (
ggml/src/ggml-cuda/mmvq.cu) so weights are read once and all columns are computed in a single dispatch. - AND
- b9523: hparams : refactor
hparams.n_layer(#24060)- Attempting to improve the logic of enumerating layers:
hparams.n_layer_all-> all layers loaded from the model file (including extra layers such asnextn)hparams.n_layer()-> number of layers of the model
🐛 Bug Fixes
- b9512: fix: step35 MTP does not allocate KV cache for all layers (#24125)
- While testing the Step3.5 mtp feature from #23274 (cc @pwilkin ), the memory watermark felt high. Turns out draft context allocates a KV cache for all layers, even though it only runs the NextN block(s).
- STEP35 isn't a hybrid arch, so it misses the per-context KV layer filter that Qwen3.5 already has. This just adds the same filter for STEP35: the MTP context keeps only the NextN blocks (
il >= n_main), the main context keeps the trunk (il < n_main). - Before:
- b9524: minor : fix lint issues (#24165)
- cont #24060
- I have read and agree with the contributing guidelines
Additional Changes
4 minor improvements: 2 examples, 2 maintenance.
- b9515: Move duplicated imatrix code into single common imatrix-loader.cpp (#22445)
quantize.cppandimatrix.cppduplicated the same code for loading the imatrix- This change pulls those functions out to a common file with the same imatrix and legacy imatrix loading functions
- b9518: server : disable on-device spec checkpoints (#24108)
- fix #23929
- cont #22679
- On-device checkpoints require extra device memory which is currently not accounted upon startup. Also, they are not fully compatible with meta devices.
- b9510: ggml: vectorize ggml_vec_dot_q4_1_q8_1 with WASM SIMD128 (#22209)
- Vectorizes the inner loop of
ggml_vec_dot_q4_1_q8_1_genericusing WASM SIMD128 intrinsics. The change is gated behind#ifdef __wasm_simd128__so non-wasm builds are completely unaffected and fall through to the existing scalar path. - Approach:
- single
wasm_v128_loadcovers all 32 packed 4-bit weights
- Vectorizes the inner loop of
- b9521: CUDA: enroll mul_mat_vec_q_moe into pdl (#24087)
- Gives small perf boost in 1 < BS < 8 setting.
- Numbers collected on a B4500
-
Full Commit Range
- b9510 to b9528 (10 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b9510...b9528
2026-06-04: Update to llama.cpp b9505
Summary
Updated llama.cpp from b9505 to b9505, incorporating 1 upstream commits.
Additional Changes
1 minor improvements: 1 examples.
- b9505: fix issue #22920 by including unordered_map in tools/server/server-ht… (#24089)
- …tp.h
- This includes a fix for issue https://github.com/ggml-org/llama.cpp/issues/22920 where a missing include for
unordered_mapintools/server/server-http.hcauses a compile-time break in macos 15.xx. The latest main branch now builds on macos 15.7.7. - I have read and agree with the contributing guidelines
Full Commit Range
- b9505 to b9505 (1 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b9505...b9505
2026-06-04: Update to llama.cpp b9505
Summary
Updated llama.cpp from b9453 to b9505, incorporating 40 upstream commits with breaking changes, new features, and performance improvements.
Notable Changes
⚠️ Breaking Changes
- b9483: hexagon: profiler output fix and script updates (#24042)
- My previous fix for Op fusion ended up breaking the profiler output (started adding a bunch of NONEs for empty tensors).
- This PR fixes that issue and updates the post-proc script to add support for total-usec column.
- I have read and agree with the contributing guidelines
- b9485: removed unecesary mmproj download when users pass --no-mmproj (#23425)
- When --no-mmproj is passed the mmproj file is still being downloaded before the flag was checked. The flag was only used to clear params.mmproj after the download already completed. Also .. in common/arg.cpp the download_mmproj flag in
common_download_modelwas hardcoded to true. - The fix uses the no_mmproj bool in the common_params struct when
common_params_handle_modelis called - Fixes #23265
- When --no-mmproj is passed the mmproj file is still being downloaded before the flag was checked. The flag was only used to clear params.mmproj after the download already completed. Also .. in common/arg.cpp the download_mmproj flag in
- b9489: cuda: reserve space for quantize kv-cache at startup (#23907)
- ref https://github.com/ggml-org/llama.cpp/pull/23646#issuecomment-4532354461. Quantized kv-cache can lead to OOM even when using
--fitsince it does not know about these backend allocations. There are some other quantization buffers in FA and MMQ which should also be removed, but this one seems it takes the most space as it scales with ctx size.
- ref https://github.com/ggml-org/llama.cpp/pull/23646#issuecomment-4532354461. Quantized kv-cache can lead to OOM even when using
🆕 New Features
- b9455: TP: quantized KV cache support (#23792)
- This PR implements support for the combination of
-sm tensorand quantized KV cache. The reason why this doesn't work on master is that the flattening of tensors for the KV cache rotation leads to the loss of shape information which the meta backend cannot handle. There were previous PRs which resolved the issue by changing the shapes of the KV cache rotation but that is an undesirable solution because batched matrix multiplications may not be as well-supported in ggml backends as a single large matrix multiplication. Also it is generally better to extend the meta backend with capabilities to handle a compute graph than to require compute graphs to conform to the meta backend's requirments. - The approach in this PR is to extend the specification
ggml_backend_meta_split_statewith a value that specifies how often a given segment repeats. When a tensor is flattened the meta backend uses segments to specify the data layout within the flattened dimension so that upon a further reshape the correct data layout can be restored. No changes to the llama.cpp compute graphs are required.
- This PR implements support for the combination of
- b9457: vulkan: reduces lock contention (#23376)
- In a production runtime, write operations are restricted to initial setup, graph allocation, or the dynamic loading of new model layers. Once the execution graph is finalized, the layout of
device->pinned_memoryremains entirely static for the duration of the inference step. Utilizing ashared_mutexensures that concurrent read operations can execute in parallel without blocking one another. - The comparison benchmark code simulates this specific read-heavy workflow; the raw output from my machine is captured below:
- b9458: vulkan: don't hold the device mutex while compiling pipelines (#23641)
- We need to hold a lock while we traverse all pipelines and lazily initialize them, but we don't need to hold it while the pipeline is being compiled. And it doesn't need to be the same lock as the device mutex. We call load_shaders each time a pipeline is needed, so we only need to compile that one pipeline (and, for example, don't want to end up compiling a pipeline that another thread should be compiling).
- test-backend-ops timings with shader disk cache disabled: 8:24 (single thread) -> 7:23 (PR #23637) -> 2:26 (PR #23637 + this PR)
- I have read and agree with the contributing guidelines
- b9459: metal: template GLU kernels to support f16/f32 (#23882)
- Part of #14909. drops the hardcoded f32 GLU kernels in favor of a single template. we now load and store in the native tensor type (half or float) to save memory bandwidth, but keep the actual ALU compute in float to avoid exploding math in geglu/swiglu. Also opened up the dispatch gate to allow f16 inputs.
- Tested on Apple M3 Max
-
- b9468: common : support manually triggering the reasoning budget end sequence (#23949)
- Add a way to force the reasoning budget end sequence when in a
COUNTINGstate. This will allow the server to manually trigger the reasoning to close. -
</code></pre> </li> <li>bool common_sampler_reasoning_budget_force(struct common_sampler * gsmpl)</li> </ul> </li> <li><strong>b9469</strong>: hexagon: add gelu_quick (<a href="https://github.com/ggml-org/llama.cpp/pull/24007">#24007</a>) <ul> <li> <!-- Describe what this PR does and why. Be concise but complete --> Add GELU_QUICK op to Hexagon backend </li> <li> <!-- IMPORTANT: Please do NOT delete this section, otherwise your PR may be rejected --> </li> <li>I have read and agree with the <a href="https://github.com/ggml-org/llama.cpp/blob/master/CONTRIBUTING.md">contributing guidelines</a></li> </ul> </li> <li><strong>b9480</strong>: StepFun 3.5 MTP (<a href="https://github.com/ggml-org/llama.cpp/pull/23274">#23274</a>) <ul> <li>MTP implementation for StepFun 3.5.</li> <li>Required a few changes to the core logic because StepFun uses a slightly different MTP architecture - it has 3 MTP layers which are used in a round-robin manner for tokens n+1, n+2 and n+3 respectively.</li> <li>I'm running a suboptimal setup for testing this, but FWIW testing this on a <code>--cpu-moe</code> StepFun3.5 increased token generation from 15 to 18 t/s.</li> </ul> </li> <li><strong>b9481</strong>: Adding support for the granite multilingual embeddings R2 (ibm-granite/granite-embedding-{97,311}... (<a href="https://github.com/ggml-org/llama.cpp/pull/22716">#22716</a>) <ul> <li><strong>modern-bert: support SwiGLU FFN for Granite Embedding R2</strong></li> <li><strong>Update: Add support for "granite-embed-r2" in hash matching, vocab pre-types, and tokenizer configurations</strong></li> <li> <!-- Describe what this PR does and why. Be concise but complete --> </li> </ul> </li> <li><strong>b9482</strong>: model: add Mellum architecture (<a href="https://github.com/ggml-org/llama.cpp/pull/23966">#23966</a>) <ul> <li>This PR adds support for the new Mellum architecture (see <a href="https://huggingface.co/collections/JetBrains/mellum-2">hf</a>).</li> <li>It is important to note that the <code>transformers</code> version has been updated in this PR. This is because the converter does not work without the <a href="https://github.com/huggingface/transformers/pull/45887">fix</a> for one bug.</li> </ul> </li> <li><strong>b9488</strong>: tests : add support for qwen3 SSM archs (<a href="https://github.com/ggml-org/llama.cpp/pull/24031">#24031</a>) <ul> <li>Enable <code>test-llama-archs</code> for Qwen3 architectures using SSM.</li> <li> <pre><code>
- | qwen3next|Apple M2 Ultra| MoE| OK (8.53e-08)| OK|
- Add a way to force the reasoning budget end sequence when in a
- b9498: ggml-cpu: extend RVV quantization vec dot to higher VLENs (#22754)
- This PR adds RVV implementations for quantized vector dot kernels (for VLENs 512-bit and 1024-bit).
- Added the following RVV kernels:
- | Kernel | VLEN |
- b9499: ggml-webgpu: FlashAttention refactor + standardize quantization support (#23834)
- With three separate FlashAttention paths depending on sequence length and device capability, the code was getting messy. Quantized KV-caches also weren't supported by the
tilepath, which means that quantized KV-caches wouldn't run in WebGPU in the browser. This PR does a number of refactors to clean up the paths and add the same quantized KV-cache functionality everywhere: - In
ggml-webgpu.cpp: supports_op: checks only whether thesg_matrixortileshader paths will work. This is because theautoFlashAttention setting uses a sequence length of 1 to probe support, but we want to ensure that FlashAttention will also work for larger sequence lengths, e.g., during prefill. Otherwise, we may end up in scenarios where the FlashAttention tensor used at runtime (with a larger sequence length then the initial check) can't fit on the GPU and runs on the CPU instead, which would be slower than not using FlashAttention to begin with.
- With three separate FlashAttention paths depending on sequence length and device capability, the code was getting messy. Quantized KV-caches also weren't supported by the
🚀 Performance Improvements
- b9484: opencl: use flat variants of gemv for very large M (#24006)
- After some profiling, it turns out that
gemv-noshufflekernels for Q4_K and Q6_K are slow with very large M (those seen in vocab). On the contrary, the flat variants are faster. This PR uses flat GEMV variants for such large M.
- b9491: Avoid PDL race conditions by disabling restrict when PDL is used (#24030)
- Follow up to https://github.com/ggml-org/llama.cpp/pull/23825.
- Together with CUDA engineers, we identified the suspected bug of https://github.com/ggml-org/llama.cpp/pull/23825; PDL and
__restrict__cannot coexist, as__restrict__can move data reads before the PDL barrier and cause race conditions in the GPU byte code. - This PR disables
__restrict__for device code which leverages PDL, and retains__restrict__(and thus performance) for all other GPU architectures.
🐛 Bug Fixes
- b9466: opencl: fix compiler warnings for non-adreno path (#23922)
- Fix warnings for non-Adreno path - some variables are only used by Adreno.
- b9471: llama : deprecate
llama_set_warmup(#24009)- cont #11571
- Deprecate the functionality for pre-loading all MoE experts at the context/graph level. The user code would now have to be responsible to do the necessary warmup runs to guarantee that the weights are hot (in case that is needed by the application).
- The
cparams.warmupflag changes the tensor shapes in the FFN graph. Before #23861 this wasn't causing problems because we were over-allocating outputs in the compute buffer that silently covered for the extra experts during warmup. Now after being more strict with the output allocations, the issue shows up: https://github.com/ggml-org/llama.cpp/actions/runs/26794936619/job/78989134399#step:5:3668
- b9473: kv-cache : SWA checkpoints store only non-masked cells (#23981)
- fix #23720
- This change reduces the size of the SWA checkpoints and should make it possible to always restore them with unified KV cache.
- b9490: ggml-cpu: use runtime SVE width in FWHT (#24059)
- Fix CPU FWHT to use svcntw() instead of the fixed GGML_F32_EPR when SVE is enabled, avoiding incorrect lane stepping on systems with 128-bit SVE such as Graviton 4. Also updates the flash-attention tiled gate to use the runtime SVE width.
Additional Changes
19 minor improvements: 1 documentation, 15 examples, 3 maintenance.
Full Commit Range
- b9453 to b9505 (40 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b9453...b9505
2026-06-01: Update to llama.cpp b9453
Summary
Updated llama.cpp from b9442 to b9453, incorporating 5 upstream commits with breaking changes and new features.
Notable Changes
⚠️ Breaking Changes
- b9451: vulkan: Removed unused function (#23175)
- | Name | Status |
- |---------------------------------|-------------------------|
- | ggml_vk_create_binary_semaphore | Never called |
🆕 New Features
- b9442: vocab: add tokenizer support for jina-embeddings-v2-base-zh (#18756)
- The
jina-embeddings-v2-base-zhmodel uses: - Whitespace pre-tokenizer
- Raw Unicode vocabulary (tokens stored as original characters like
你好)
- The
- b9452: vulkan: Block-load Q3_K/Q6_K block data and subtract on 32b ints (#23056)
- This is the non-padding part of #22951.
- Q3_K/Q6_K do much better when using MMVQ on Intel BMG even though they're only 2-byte aligned.
- mesa isn't all that great at coalescing back-to-back loads from alternating arrays, so we force it instead. Further, we can do subtraction directly on a full int32_t rather than an i8vec4 with bit twiddling because the high bit is always free to start.
Additional Changes
2 minor improvements: 2 examples.
- b9444: server: handle If-None-Match weak ETags (#23916)
- See #23849 for details. In short, current logic of comparing ETags in
If-None-MatchHTTP header does not consider "weak" ETags (prepended withW/) to be the same as "strong" ones, while HTTP specs requires this. This causes reverse proxies which compress HTTP responses (and "weakens" the ETag in the process) to break browser cache validation. - This PR provides a "quick" fix, which assumes llama-server never generate weak ETags by itself. While HTTP specs requires handling more cases (e.g.
*wildcard, or multiple ETags), I don't think they are worth to implement here. - Fixes #23849.
- See #23849 for details. In short, current logic of comparing ETags in
- b9453: Add EXAONE 4.5 implementations (#21733)
- Add support for the EXAONE 4.5 architecture for the EXAONE 4.5 model released by LG AI Research.
Full Commit Range
- b9442 to b9453 (5 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b9442...b9453
2026-05-31: Update to llama.cpp b9441
Summary
Updated llama.cpp from b9415 to b9441, incorporating 11 upstream commits with breaking changes and new features.
Notable Changes
⚠️ Breaking Changes
- b9431: ci : update ios-xcode release job to macos-26 (#23906)
- cont https://github.com/ggml-org/llama.cpp/pull/23895#issuecomment-4582075330
- Update the job and removed
libcommonfrom the build to save some time. - Sample run: https://github.com/ggerganov/tmp2/actions/runs/26680300939/job/78639474398
🆕 New Features
- b9430: Loongarch: Add some lsx support (#23798)
- This add some lsx support for LoongArch
- Since some machines only have lsx, add lsx support for q8_0, q6_K, iq4_xs, fp16 load and store.
- b9433: metal : restore im2col implementation for large kernels (#23901)
- cont #16219
- Some use cases require 2D kernel size where
KH*KW > 1024. Restore the old implementation for those (even though it is a bit slow).
- b9436: opencl: support bf16 by converting to f16 (#23839)
- This PR adds support for bf16 by converting bf16 to f16 on host and storing the resulting f16 in GPU memory. Existing f16f32 mm/mv kernels can be reused with some host side changes.
- This reduces graph splits for models containing bf16 weights, e.g., gemma-4-E2B and gemma-4-E4B.
🐛 Bug Fixes
- b9428: ci : fix s390x release job (#23898)
- cont #23895
- Fix for https://github.com/ggml-org/llama.cpp/actions/runs/26676181236/job/78628391004
- Multi-thread the
ios-xcodebuilds
- b9432: test: (test-llama-archs) log the config name first [no release] (#23885)
- This is a QoL change
- Log the first part of a test case first, e.g.
| talkie| Meta| Dense|, flush it then run the test - If it crashes, we at least know which test case was faulty.
- b9434: TP: fix granularity for Qwen 3.5/3.6 + 3 GPUs (#23843)
- Fixes https://github.com/ggml-org/llama.cpp/issues/22817 .
- The problem is that the wrong tensors are being used to determine the granularity when splitting quantized tensors across GPUs. For the combination of Qwen 3.5/3.6, 3 GPUs, and a heterogeneous quant mix that can lead to inconsistencies regarding the data split. This PR adds the missing logic to determine the correct tensor for retrieving the quantization type whose block size to use as the granularity.
Additional Changes
4 minor improvements: 1 documentation, 3 examples.
- b9439: llama: only use one iGPU device by default (#23897)
- After #23007 Vulkan is no longer the only backend reporting devices as iGPU, so we now get the case that multiple backends report the same iGPU. On my DGX Spark that leads to the model being split between CUDA and Vulkan.
- This is the simplest solution, just only ever allow a single iGPU. I think that there should never be a case with multiple iGPUs, so this is okay. The dGPU deduplication logic by device_id would also work on DGX Spark and (Linux) AMD, but I don't think it is needed here.
- I have read and agree with the contributing guidelines
- b9415: download: add option to skip_download (#23059)
- Add a new flag
skip_downloadto thecommon_params_handle_modelsfunction. This is a clean up for the upcoming model download / management API (cc @allozaur ). It is useful to know if a download is required before running a model. - Its meaning:
offline = false--> normal case, ETag is validated and if mismatch, redownload the GGUF
- Add a new flag
- b9437: Support
-fa autoin llama-bench (#23714)- Support
-fa on|off|autoinllama-bench, similar to other tools. The default is still kept as-fa offnot to change the existing behavior, but using-fa autoallows enablingllama-serverandllama-clibehavior inllama-bench. - Make the default value of
-ngl-1, similar to other tools. For most models, this won't have any impact as the previous default was 99. - Update README with the latest usage and examples.
- Support
- b9441: ui: fix ETag truncation with MSVC compiler (#23917)
- In the process of generating ETags for embedded web UI files, the
uint64_tfile hash is casted into aunsigned longvalue before being converted into a 64-bit hexadecimal string. MSVC compiler uses 32 bitlongvalues, and thus will truncate the hash value. This don't really affect anything (aside for some ridiculous hypothetical load-balancing setup with servers running different OSes), but hey, why do a type cast when you can use the full value just like on Linux? - For consistency, type cast on the
size_tvalue above is also removed. I don't really believe we will have 4GB+ of static files, though. - Tested on Windows 11 with Visual Studio 2026.
- In the process of generating ETags for embedded web UI files, the
Full Commit Range
- b9415 to b9441 (11 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b9415...b9441
2026-05-29: Update to llama.cpp b9410
Summary
Updated llama.cpp from b9410 to b9410, incorporating 1 upstream commits.
Additional Changes
1 minor improvements: 1 maintenance.
- b9410: llama: use f16 mask for FA to save VRAM (#23764)
- Currently we reserve the KQ mask in f32 even if FA is used, which is then is converted to f16 while passing to backends. The f32 mask still uses the compute buffer even though is not used, taking up extra VRAM. This PR reserves the kq-mask in f16. This provides 1.2GB of VRAM saving at
-ub 2048and ~300Mb at-ub 512when using MTP
Full Commit Range
- b9410 to b9410 (1 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b9410...b9410
2026-05-29: Update to llama.cpp b9409
Summary
Updated llama.cpp from b9409 to b9409, incorporating 1 upstream commits.
Additional Changes
1 minor improvements: 1 maintenance.
- b9409: b9409
-
Full Commit Range
- b9409 to b9409 (1 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b9409...b9409
2026-05-28: Update to llama.cpp b9371
Summary
Updated llama.cpp from b9326 to b9371, incorporating 19 upstream commits with breaking changes, new features, and performance improvements.
Notable Changes
⚠️ Breaking Changes
- b9371: ggml-webgpu: remove legacy constants (#23672)
- Removes legacy dependency of memset pipeline on a hardcoded 288 workgroup size, which breaks some systems with lower limits (https://github.com/ngxson/wllama/issues/229). Also remove another legacy unused constant.
- I have read and agree with the contributing guidelines
🆕 New Features
- b9329: CUDA: add fast walsh-hadamard transform (#23615)
- Implement FWHT for CUDA, speed-up for cases when we quantize the kv-cache.
- Performance on a 5090 with
-ctk q8_0 -ctv q8_0
- b9330: model: tag ffn_latent as MUL_MAT to fix buft probe (#23664)
- The LLM_TENSOR_INFOS table declared ffn_latent_down and ffn_latent_up as GGML_OP_MUL, but nemotron-h feeds both through ggml_mul_mat. The loader buft probe builds a fake node from this op to pick a buffer type, so it asked the backend whether it could run an elementwise MUL on a q8_0 weight.
- That used to return true unconditionally, so the wrong tag stayed harmless and the weight landed on GPU by luck. Once supports_op started reporting the truth for ADD/SUB/MUL/DIV, the probe got an honest no, the loader pushed the latent weight and its matmul to CPU, and the split graph added host/device copies per token. Hence the regression on Nemotron 3 Super mixed quants.
- Tagging the latent projections as MUL_MAT makes the probe ask the real question, the weight stays on GPU, and the math is unchanged.
- b9333: Metal : detect Apple SoC at backend init (#23566)
- Adds a small Metal device-family detection layer. Parses [mtl_device name] into a ggml_metal_device_id enum (M1..M5 + GENERIC) and stores it in props.device_id. Unknown devices fall back to GENERIC.
- No consumers yet — this just lays the groundwork for the hardware-aware Metal work discussed in #23114
- b9352: ggml-zendnn: fixed naming of matmul function (#20964)
- This PR fixes the naming of function used to switch between proper ZenDNN MatMul kernel implementation.
- Hi, @z-vishal, here is small clarification, hope you will be agree .
- Basically, SGEMM is a Single-precision General Matrix Multiply, it means it use F32 gemm kernel.
- b9354: Add MiniCPM5 tokenizer support (#23384)
- Adds MiniCPM5 support for HF → GGUF conversion and inference.
- Detect MiniCPM5 in LlamaModel and use the correct Llama3-style BPE + ByteLevel vocab path
- Register the minicpm5 BPE pre-tokenizer fingerprint
- b9366: feat: add Vulkan REPEAT op support for f16 to f16. (#23298)
- Add Vulkan REPEAT op support for f16 to f16.
- (Please advise if the PR is redundant and/or missing steps to full implementation)
- b9367: vulkan: use GL_NV_cooperative_matrix_decode_vector for faster matmul (#23541)
- Use the new GL_NV_cooperative_matrix_decode_vector extension to decode multiple elements at a time when loading a matrix. This change does 4 elements at a time, which performs better than the 2 at a time the driver currently does, and is less fragile to shader or compiler changes that could break the commoning that the driver implementation relies on.
- If glslc supports the extension, this will generate a single set of coopmat2 shaders that use this extension, rather than variants with/without. If the driver doesn't support the extension, ggml-vulkan.cpp will strip it out of the SPIR-V.
- This extension is currently available in the NVIDIA vulkan developer driver (https://developer.nvidia.com/vulkan-driver), and will eventually be in the general driver releases.
- b9370: hexagon: add support for Q4_1 in MUL_MAT and MUL_MAT_ID (#23647)
- This PR adds support for Q4_1 quantized tensors in MUL_MAT and MUL_MAT_ID ops.
- I have read and agree with the contributing guidelines
🚀 Performance Improvements
- b9357: vulkan: avoid preferring transfer queue on AMD UMA devices (#22455)
- On discrete GPUs (dGPUs), a dedicated transfer queue is beneficial because memory is separate from the CPU, so offloading transfers improves throughput. On UMA devices, CPU and GPU share memory, so the extra queue synchronization adds overhead without benefit.
- Attached the benchmark result running on my device. The benchmark measures the performance impact of the transfer-queue UMA patch by comparing two queue scheduling behaviors in isolated, repeatable conditions.
-
- b9368: vulkan: Switch MUL_MAT_VEC to 4 K per iteration for F16/32 (#22887)
- Against mesa git, this shows a 9% performance improvement for tg128 on Qwen3.5-9B:BF16 on Intel BMG.
- A few cleanups to MUL_MAT_VEC including fixing the OOB A read, but the real commit is 1 and 2, which shows a total ~9% performance improvement on Intel Arc B60 on mesa (where we're back to beating SYCL!). I'm curious how other devices deal with this.
- I'm not really a huge fan of the code duplication but its not that bad, and more splitting stuff up didn't seem worth it. We could compile a different shader to make this all compile-time but that similarly didn't seem worth all that much.
🐛 Bug Fixes
- b9334: CUDA: missing PDL sync for FWHT, better fallback (#23690)
- Fixes problem described in https://github.com/ggml-org/llama.cpp/pull/23615#issuecomment-4536471987 .
- The problem is that the new kernel is being launched with
ggml_cuda_kernel_launchbut is missing a call toggml_cuda_pdl_sync. As a consequence on Blackwell there is a race condition that can lead to incorrect results. This PR adds the missing call (and also changes the code slightly to fall back to regular GEMM instead of aborting on failure).
- b9365: ci : move ARM jobs to self-hosted + disable kleidiai mac release (#23780)
- cont #23705
- Just realized we can run the arm jobs on the graviton runners provided by Arm
- I don't see the point of a kleidiai-enabled release for mac. On macs, we simply use the Metal backend which should always be the better option. Disabling this release for now to save CI resources. If we want to provide a kleidiai-enabled releases, they should be built on Arm-hosted runners and target appropriate Arm hardware/OS (cont #21259)
- b9369: ggml-webgpu: fix workgroup dispatching for several ops (#23750)
- This PR fixes how workgroups are dispatched for several ops.
cpy: Dispatching workgroups on a single dimension can be insufficient for the specified tensor size, so I changed it to use two dimensions. This fixes the bug described in the additional information section.mul_mat_id_gather: A single dimension is sufficient for dispatching workgroups.
Additional Changes
5 minor improvements: 1 documentation, 1 examples, 3 maintenance.
- b9360: common : fix env names to all have
LLAMA_ARG_prefix (#23778)- For consistency, make all env arguments have the same prefix:
LLAMA_ARG_ - I have read and agree with the contributing guidelines
- For consistency, make all env arguments have the same prefix:
- b9353: server : fix the log message when using SSL (#23393)
- When llama-server is started with SSL key and cert, the log says that it listens on http instead of https. This patch fixes this.
- I have read and agree with the contributing guidelines
- AI usage disclosure: yes, opus 4.7
- b9326: b9326
-
- b9331: ci : reduce PR jobs by matching backend paths (#23675)
- Move backend-specific jobs into separate workflows to be triggered less often:
hip+musarpc
- b9351: b9351
-
Full Commit Range
- b9326 to b9371 (19 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b9326...b9371
2026-05-25: Update to llama.cpp b9310
Summary
Updated llama.cpp from b9305 to b9310, incorporating 2 upstream commits.
Additional Changes
2 minor improvements: 2 examples.
- b9305: cmake : fix ui build (#23592)
- Fix llama-ui builds.
- Thought I had all the builds working, guess I missed some.
- b9310: server: fix checkpoints creation (#22929)
- Implemented as requested in https://github.com/ggml-org/llama.cpp/pull/22826#issuecomment-4403137727
- extract
message_spansfrom chat templates - use the autoparser to support more chat templates
Full Commit Range
- b9305 to b9310 (2 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b9305...b9310
2026-05-24: Update to llama.cpp b9297
Summary
Updated llama.cpp from b9296 to b9297, incorporating 2 upstream commits with new features.
Notable Changes
🆕 New Features
- b9297: Add NVFP4 MTP scale tensors (#23563)
- This PR adds the additional MTP NVFP4 weight scale and input scale tensors for:
eh_projshared_head_head
🐛 Bug Fixes
- b9296: ggml: Check the right iface method before using the fallback 2d get (#23514)
- Same oversight as #23306 but for the async (backend-based) path.
ggml_backend_tensor_get_2d_asyncwas checkingset_tensor_2d_asyncinstead ofget_tensor_2d_async, and the bounds assertion said "write" when it should say "read".- Let me know if this fix is appropriate, or if there's a better way to handle this.
Full Commit Range
- b9296 to b9297 (2 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b9296...b9297
2026-05-23: Update to llama.cpp b9295
Summary
Updated llama.cpp from b9263 to b9295, incorporating 24 upstream commits with breaking changes, new features, and performance improvements.
Notable Changes
⚠️ Breaking Changes
- b9290: [SYCL] Level Zero detection in ggml_sycl_init (#23097)
- As we already iterate over all devices in
ggml_sycl_init, let's remove the second device-enumeration loop and reuse the existing one. After all, we only need to verify L0 backend usage once. - Follow up to #21597
- The warning now goes off unconditionally (so you can see if your non-Intel device is not supported)
- As we already iterate over all devices in
🆕 New Features
- b9267: Check the right iface method before using the fallback 2d get (#23306)
- Probably no backends implement only one of 2d get/set, but this might be annoying for some future backend developer trying to add 2d get/set.
- I have read and agree with the contributing guidelines
- AI usage disclosure: NO
- b9270: vocab : add Carbon-3B (HybridDNATokenizer) support (#23410)
- Adds a new BPE pre-type LLAMA_VOCAB_PRE_TYPE_CARBON for the HybridDNATokenizer used by HuggingFaceBio/Carbon-{500M,3B,8B}. The base BPE is Qwen3-4B-Base's; what differs is that text inside ... regions is chunked into fixed 6-mers (right-padded with 'A' on the trailing partial), and any base outside ACGT maps to .
- src/llama-vocab.{h,cpp}: new pre-type, dispatched from llm_tokenizer_bpe_session::tokenize.
- src/llama-vocab-carbon.h: pure helpers (tokenize_carbon, emit_dna_kmers) factored out for unit testing — no llama_vocab dependency, vocab access goes through a std::function.
- b9279: vulkan: fuse snake activation (mul, sin, sqr, mul, add) (#22855)
- Vulkan version of the snake activation fusion. Symmetric counterpart of https://github.com/ggml-org/llama.cpp/pull/22667 (CUDA): same matcher (mul, sin, sqr, mul, add rewritten to y = x + sin(a*x)^2 * inv_b), same broadcast contract (a / inv_b shaped [1, C] over x [T, C]), same F32 / F16 / BF16 coverage.
- The shader uses a native 2D dispatch via gl_GlobalInvocationID.x/y so the c = idx / T resolution that needs fastdiv on CUDA is free here. Otherwise the design is one-to-one with the CUDA path.
- test_snake_fuse from the CUDA PR is backend-agnostic and now also covers Vulkan: it builds the 5 op chain a frontend emits and compares the CPU naive path against the Vulkan fused path via run_whole_graph(), so passing implies the rewrite preserves the math.
- b9286: ggml-zendnn : add Q8_0 quantization support (#23414)
- This PR adds Q8_0 quantization support in the ggml-zendnn backend.
- The implementation enables ZenDNN execution paths for Q8_0 models and integrates the required handling for quantized weights and matmul operations.
🚀 Performance Improvements
- b9275: metal : optimize concat kernel and fix set kernel threads (#23411)
- cont #23354
- Optimize the Metal concat kernel with row batching for small widths to improve GPU occupancy, extend test_cpy for reshaping operations, and fix the GGML_OP_SET kernel threads.
-
- b9289: SYCL gated_delta_net K>1 (#23174)
- Fix failures in test-backend-ops gated_delta_net related to K>1 by porting MTP relevant code snippets from ggml-cuda/gated_delta_net.cu to ggml-sycl/gated_delta_net.cpp. Without this patch, MTP on SYCL gives garbled output after a few tokens. After this patch, MTP on SYCL output is normal and is similar in speed to MTP on Vulkan, though it is not necessarily faster than without MTP on SYCL yet.
- No new code just copy-pasted to relevant sections.
- Prior to this PR:
- b9291: [SYCL] improve MoE prefill throughput (+70% with Qwen3.6-35B) (#23142)
- This PR improves the throughput for MoE workloads.
- This PR changes
k_copy_src1_to_contiguousso that uses a precomputed contiguous mapping where all rows "owned" by an expert are in one slice with a know starts and ends, not all over the place. So it no longer scansidson the device or uses the device atomic. That's most of the gains. - This PR also switches the
O(n_as * n_routed_rows)contraption to a counting sort-based procedure withO(n_as + n_routed_rows)complexity. It was a by-product of the original goal, but as I tried to reduce the scope of this PR, I found that it contributed up to 10% to the gains, depending on the model.
- b9294: opencl: Generalize Adreno MoE kernels on size M (#23449)
- Generalize Adreno MoE Optimized kernels to accept all experts with M that is multiple of 32 instead of 64.
- I have read and agree with the contributing guidelines
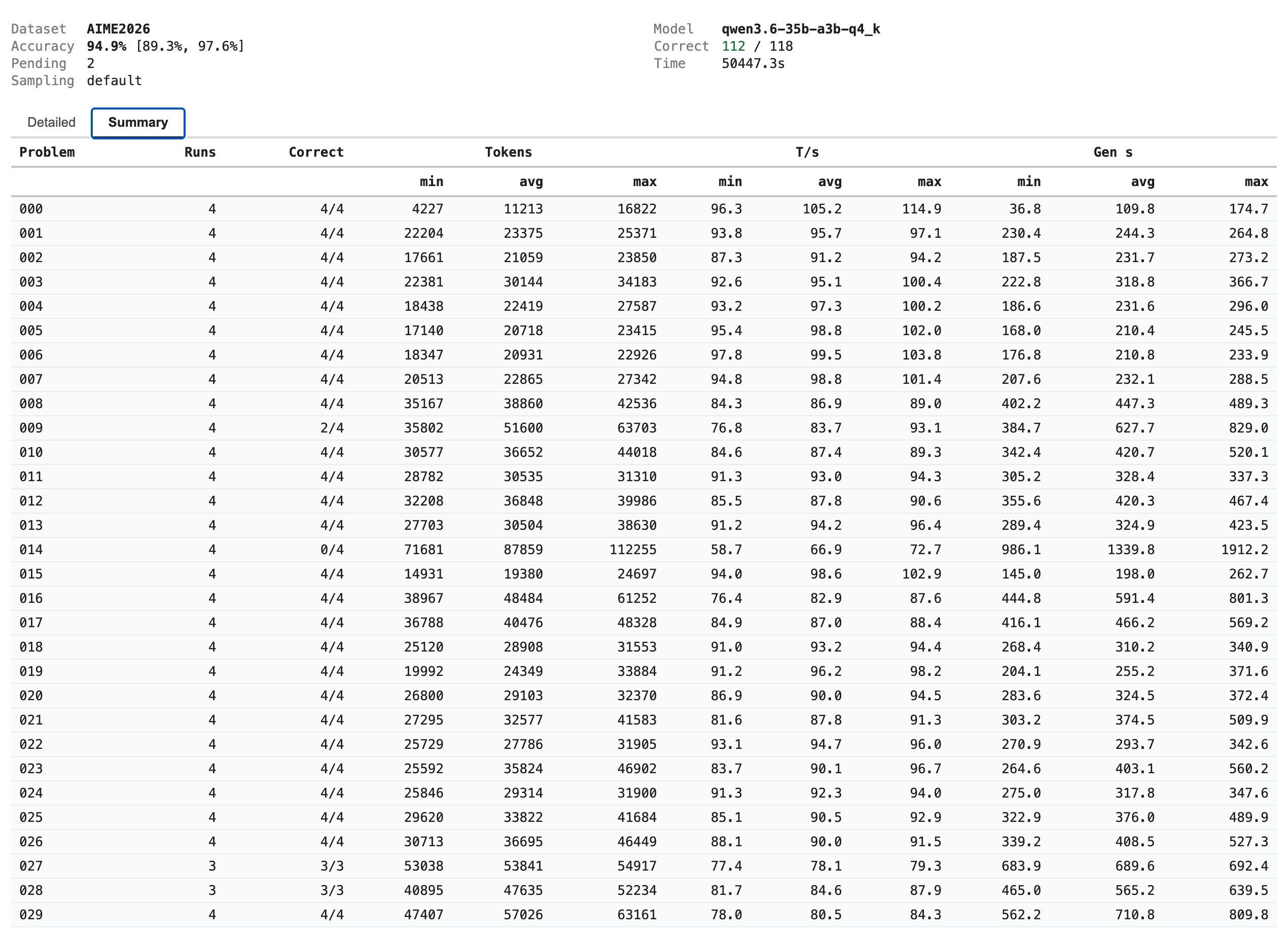
🐛 Bug Fixes
- b9265: hexagon: ssm-conv fix for large prompts (#23307)
- Refactor Hexagon SSM_CONV to use HVX path for large prompts and reduce fallback to scalar.
- b9266: llama-graph: fix null-buffer crash in llm_graph_input_attn_kv_iswa for SWA-only models (#23131)
- When a model has zero non-SWA attention layers (e.g. a SWA-only model), the base KV cache has no layer tensors. The input tensors (self_k_idxs, self_v_idxs, self_kq_mask) are created as graph input nodes but never consumed by any compute node, so the backend scheduler never allocates a buffer for them.
- Calling mctx->get_base()->set_input_k_idxs() then triggers:
- `
- b9271: mtp: use inp_out_ids for skipping logit computation (#23433)
- When doing a follow-up decode for the draft model, we were always doing the logits computation even though it is not required. Thanks for comment at https://github.com/ggml-org/llama.cpp/issues/23230#issuecomment-4493653900 for pointing this out
- b9284: vocab : keep DNA k-mer ids distinct from colliding BPE tokens (#23466)
- Follow-up to #23410. The HybridDNA tokenizer gives every DNA k-mer its own id, but one 6-mer (
CCCCCC) also exists as a Qwen3 BPE token. Becauseget_vocab()is keyed by text, the DNA id (154402) was dropped in favor of the BPE id (91443) and written out as an unused pad — so<dna>…CCCCCC…</dna>encoded to the wrong id and 154402 detokenized to[PAD154402], diverging from the Python tokenizer. - A naive conversion fix can't work: llama.cpp's vocab is a 1:1 text↔id map, so two tokens named
CCCCCCwon't load. transformers avoids this by resolving k-mers through a dedicated DNA map in<dna>context. This PR does the same insrc/llama-vocab.cpponly: inside<dna>a k-mer resolves to its own id by product-order index (not the shared text→id map), and at load the colliding k-mer's text is restored from its index so it detokenizes correctly. - Result matches transformers both ways: DNA
CCCCCC→ 154402, plainCCCCCC→ 91443, both detokenize toCCCCCC. Verified with full token-id parity againstAutoTokenizer(..., trust_remote_code=True).
- Follow-up to #23410. The HybridDNA tokenizer gives every DNA k-mer its own id, but one 6-mer (
- b9285: cmake : build router app only during standalone builds (#23521)
- CMake projects that use llama.cpp as a library currently fail to build because router app building is always ON and it fails with:
-
- /home/phm/Projects/fetch-test/build-master/_deps/llama-src/app/llama.cpp:1:10: fatal error: build-info.h: No such file or directory
- b9295: vulkan: fix windows find_package of SPIRV-Headers (#23215)
- Fix ggml-vulkan windows build (see https://github.com/ggml-org/llama.cpp/pull/22009#issuecomment-4471041844).
- I have read and agree with the contributing guidelines
- AI usage disclosure: Claude suggested this fix.
Additional Changes
9 minor improvements: 8 examples, 1 maintenance.
Full Commit Range
- b9263 to b9295 (24 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b9263...b9295
2026-05-21: Update to llama.cpp b9260
Summary
Updated llama.cpp from b9222 to b9260, incorporating 16 upstream commits with new features and performance improvements.
Notable Changes
🆕 New Features
- b9222: hexagon: add support for TRI op (#22822)
- Add
GGML_OP_TRIsupport to the Hexagon HTP backend. - Includes HVX implementation with kernels for zero and circular padding.
- Verified correctness against CPU implementation and measured on device
- Add
- b9243: hexagon: add MROPE and IMROPE support in HTP rope op (#23317)
- Add support for GGML_ROPE_TYPE_MROPE (8) and GGML_ROPE_TYPE_IMROPE (40) in the Hexagon backend.
- I have read and agree with the contributing guidelines
- b9244: opencl: add MoE support for q4_k, q5_k, q6_k on Adreno (#23303)
- Add Q4_K, Q5_K and Q6_K MoE OpenCL support for Adreno.
- b9255: hexagon: HMX quantized matmul rework (#23368)
- This PR updates the HMX matmul to use activation depth mode, and simplifies quantized HMX matmul implementation.
- Based on testing with latest models (see the sweep below) we do not really need non-pipelined kernel flavors any more.
- Perhaps, at some point those provided benefits but after all the recent updates and fixes they do not.
- b9260: opencl: refactor backend initilization (#23318)
- Currently, OpenCL backend performs full initialization at backend registration time via the registry constructor. This works but brings some problems, e.g.,
-
- Initialization is done before commandline is processed so with the new logger, initialization logs never show up because
-lvsetting is processed after initialization
- Initialization is done before commandline is processed so with the new logger, initialization logs never show up because
🚀 Performance Improvements
- b9247: metal : optimize pad + cpy (#23354)
- Improved performance with the new MTP Qwen3.6 graphs - 10%-20% TG uplift
- Optimize the
GGML_OP_PADMetal kernel by launching more threadgroups whenne00is large - Optimize the
GGML_OP_CPYMetal kernel by packingsrc0rows in the threadgroup more efficiently
- b9257: vulkan: optimize operations in the IM2COL shader (#22685)
- This optimizes the IM2COL shader by extracting redundant operations from the loops, similar to how I already did it in this: https://github.com/ggml-org/llama.cpp/pull/11826.
Radeon RX 7800XT-
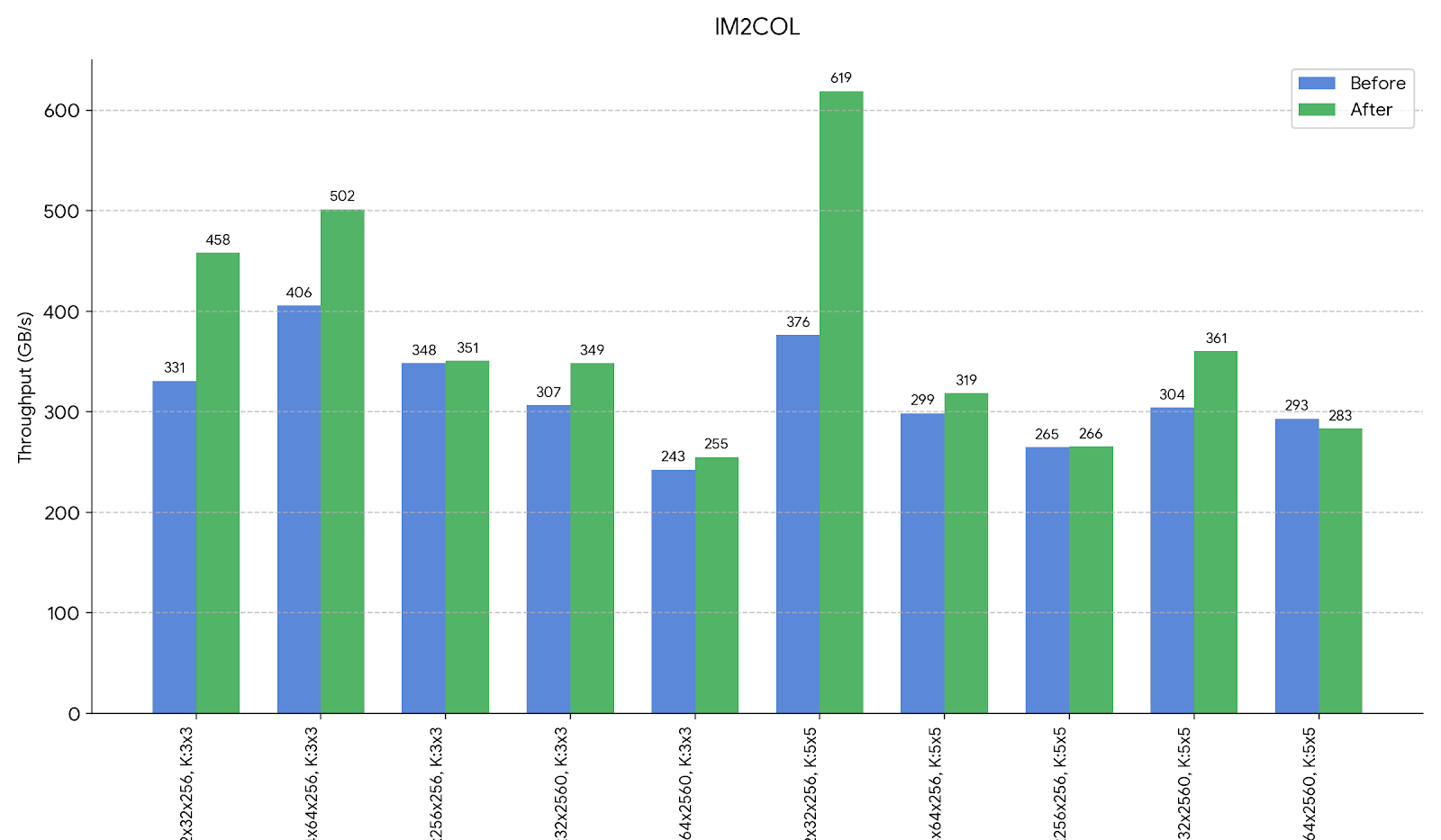
🐛 Bug Fixes
- b9240: common: fix --help for --verbosity (#23278)
- To my understanding the
--helpfor--verbosityis wrong on master. 4 is trace, 5 is debug. - I have read and agree with the contributing guidelines
- To my understanding the
- b9259: common/speculative : fix nullptr crash in get_devices_str (#23386)
- Fix crash when
ggml_backend_dev_nameis called on a nullptr sentinel entry. ggml_backend_dev_by_namealways appends a nullptr at the end of the devices- vector, which caused an assertion failure in the speculative devices string
- Fix crash when
Additional Changes
7 minor improvements: 2 documentation, 4 examples, 1 maintenance.
Full Commit Range
- b9222 to b9260 (16 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b9222...b9260
2026-05-19: Update to llama.cpp b9222
Summary
Updated llama.cpp from b9151 to b9222, incorporating 33 upstream commits with breaking changes, new features, and performance improvements.
Notable Changes
⚠️ Breaking Changes
- b9219: common : remove hf cache migration (#23266)
- Remove HF migration cache
- I think we kept it long enough and we don’t have issues with the migration itself anymore
🆕 New Features
- b9156: ggml-webgpu: Enable NVIDIA self-hosted CI (#22976)
- Enables the self-hosted NVIDIA CI for the WebGPU backend. In order to pass the CI, the NMSE threshold had to be relaxed, to avoid errors in many operations that write to
f16tensors. This includes operations likeDIV, where even if the calculation is done inf32, casting tof16causes slight drift, andSET_ROWS, where the operation is a straightahead cast. I found that the errors were usually between2e-7to3e-7, just above the default1e-7threshold set bytest-backend-ops. - Since the WebGPU backend ultimately lowers to Vulkan on this CI host, I investigated the difference in the SPIR-V code between the two, and found that while the instruction for the cast is the same (
OpFConvert), the Vulkan backend adds Vulkan's "round-to-even" mode, which matches ggml-cpu's conversion fromf32tof16. However, WebGPU does not specify the rounding mode, leaving it implementation-defined, and Dawn currently does not expose rounding mode control to my knowledge (although interestingly, rounding mode is an example in a hypothetical extension for WGSL). - Ultimately, this means that the WebGPU backend may need slightly looser tolerances for floating-point operations. While that may mean some models on some devices are slightly off compared to other backends, that is already the case right now, so I think enabling this CI and making it an explicit decision for now is worth it. If Dawn or WebGPU ever adds support for rounding mode, we can revisit this.
- Enables the self-hosted NVIDIA CI for the WebGPU backend. In order to pass the CI, the NMSE threshold had to be relaxed, to avoid errors in many operations that write to
- b9158: HIP: RDNA3 mma FA, faster AMD transpose, tune AMD (#22880)
- This PR adds RDNA3 support to the CUDA mma FA kernel. To make the RDNA3 tensor cores work with the FP16 accumulation for VKQ the tiles they need to be 32 logical units long in direction of the attention head; for head sizes 80 and 112 that are not exactly divided by 32 the regular length of 16 with FP32 accumulation is used instead. The longer tiles also enable more efficient transposition for a warp size of 32 which is why it's also used for RDNA4. However, this scrambles the data layout of the accumulators along the attention head dimension. To prevent accidental misuse I added another entry to
ggml_cuda_mma::data_layout. - I also tuned the kernel parameters for RDNA3, RDNA4, and CDNA1 in general, during which I discovered that the kernel can be made to work for head sizes up to 256 for CDNA. For RDNA3/4 I was not able to get better performance that the tile kernel for head sizes > 128.
-
- This PR adds RDNA3 support to the CUDA mma FA kernel. To make the RDNA3 tensor cores work with the FP16 accumulation for VKQ the tiles they need to be 32 logical units long in direction of the attention head; for head sizes 80 and 112 that are not exactly divided by 32 the regular length of 16 with FP32 accumulation is used instead. The longer tiles also enable more efficient transposition for a warp size of 32 which is why it's also used for RDNA4. However, this scrambles the data layout of the accumulators along the attention head dimension. To prevent accidental misuse I added another entry to
- b9159: ggml-hexagon: cpy: add contiguous fast-path in reshape copy (#23076)
- Added a fast copy path for contiguous data
- b9194: vulkan: fuse SSM_CONV + ADD + SILU (#22653)
- This implements fusion for SSM_CONV + (optional)bias+ SILU, similar to https://github.com/ggml-org/llama.cpp/pull/22478. Worth about 4% in TG on RTX 5090.
-
- before
- b9196: vulkan: Support unaligned tensors for ROPE (#22637)
- Handle unaligned tensor offsets for ROPE. May fix #22516.
- I have read and agree with the contributing guidelines
- AI usage disclosure: YES, written using Claude, I told it what specifically to do.
- b9197: vulkan: add cpy bf16 -> f32 pipelines (#22677)
- Add the missing reverse direction "cpy bf16 -> f32" to the Vulkan backend. Currently only "cpy f32 -> bf16" is supported, which causes runtime aborts when models or LoRAs stored in BF16 need to be transferred back to F32 buffers
- (typical case: BF16-trained LoRA merge at runtime, yes, I'm merging with the GPU, it's much faster: same code work on CUDA)
- Downstream issue (Successfully tested by me, awaiting user feedback): https://github.com/ServeurpersoCom/acestep.cpp/issues/69
- b9198: ggml-vulkan/CMakeLists: add a check for SPIRV-Headers (#22009)
- This makes the build fail at configure time instead of build time in case any of the sysroots included does not contain SPIRV-Headers. Generally it is preferred to fail as quickly as possible if a required dependency is not available.
- Files related to this package are installed as part of the SPIRV-Headers project (both cmake files as well as a pkg-config file).
-
- b9204: feat: Support d_conv=15 for ssm-conv.cu (#23017)
- Closes #23015
- This PR adds the missing kernel dispatch for
d_conv=15for Granite Speech 4.0 and 4.1 mmproj QFormer projectors. -
</code></pre> </li> </ul> </li> <li><strong>b9221</strong>: ggml-hexagon: add PAD op HVX kernel (<a href="https://github.com/ggml-org/llama.cpp/pull/23078">#23078</a>) <ul> <li>Add <code>GGML_OP_PAD</code> support to the Hexagon HTP backend.</li> <li>Includes HVX implementation for triangular masking, lower and upper variants.</li> <li>Verified correctness against CPU implementation and measured on device</li> </ul> </li> <li><strong>b9222</strong>: hexagon: add support for TRI op (<a href="https://github.com/ggml-org/llama.cpp/pull/22822">#22822</a>) <ul> <li>Add <code>GGML_OP_TRI</code> support to the Hexagon HTP backend.</li> <li>Includes HVX implementation with kernels for zero and circular padding.</li> <li>Verified correctness against CPU implementation and measured on device</li> </ul> </li> </ul> <h4><a href="#user-content--performance-improvements-13" aria-hidden="true" class="anchor" id="user-content--performance-improvements-13"></a>🚀 Performance Improvements</h4> <ul> <li><strong>b9165</strong>: ci : fix transform of top . entry in release archive (<a href="https://github.com/ggml-org/llama.cpp/pull/23080">#23080</a>) <ul> <li>Fixes #23048</li> <li>The top <code>.</code> entry does not match the transform with <code>/</code>, improve matching to prevent including <code>.</code> in release archives.</li> <li>Test release run: <a href="https://github.com/CISC/llama.cpp/actions/runs/25892234097">https://github.com/CISC/llama.cpp/actions/runs/25892234097</a></li> </ul> </li> </ul> <h4><a href="#user-content--bug-fixes-15" aria-hidden="true" class="anchor" id="user-content--bug-fixes-15"></a>🐛 Bug Fixes</h4> <ul> <li><strong>b9173</strong>: ci : fix release symlinks (<a href="https://github.com/ggml-org/llama.cpp/pull/23119">#23119</a>) <ul> <li>cont #23080</li> <li>Escape the <code>.</code> which also transformed the first character in symlinks (for some reason treated as a literal <code>.</code> in path elsewhere).</li> </ul> </li> <li><strong>b9202</strong>: cmake : do not install conversion script (<a href="https://github.com/ggml-org/llama.cpp/pull/23204">#23204</a>) <ul> <li>Fixes #23171</li> <li>Installing it never really made sense in the first place.</li> </ul> </li> <li><strong>b9213</strong>: fix: initialize <code>embeddings_pre_norm_masked=false</code> in <code>llama_context</code> (<a href="https://github.com/ggml-org/llama.cpp/pull/23256">#23256</a>) <ul> <li>This PR fixes a bug introduced in #23198 by the new <code>embeddings_pre_norm_masked</code> struct member for <code>llama_context</code>. When left uninitialised <code>embeddings_pre_norm_masked</code> caused a bug in the construction of Qwen3.5 graphs where <code>get_rows_f32</code> failed in an assert because it tried to grab an invalid row index.</li> <li><a href="https://github.com/abetlen/llama-cpp-python/actions/runs/26019550305/job/76477517913">Failing CI run with the relevant assert</a></li> </ul> </li> </ul> <h3><a href="#user-content-additional-changes-20" aria-hidden="true" class="anchor" id="user-content-additional-changes-20"></a>Additional Changes</h3> <p>18 minor improvements: 12 examples, 6 maintenance.</p> <h3><a href="#user-content-full-commit-range-23" aria-hidden="true" class="anchor" id="user-content-full-commit-range-23"></a>Full Commit Range</h3> <ul> <li>b9151 to b9222 (33 commits)</li> <li>Upstream releases: <a href="https://github.com/ggml-org/llama.cpp/compare/b9151...b9222">https://github.com/ggml-org/llama.cpp/compare/b9151...b9222</a></li> </ul> <hr /> <h2><a href="#user-content-2026-05-14-update-to-llamacpp-b9145" aria-hidden="true" class="anchor" id="user-content-2026-05-14-update-to-llamacpp-b9145"></a>2026-05-14: Update to llama.cpp b9145</h2> <h3><a href="#user-content-summary-24" aria-hidden="true" class="anchor" id="user-content-summary-24"></a>Summary</h3> <p>Updated llama.cpp from b9133 to b9145, incorporating 10 upstream commits with new features.</p> <h3><a href="#user-content-notable-changes-20" aria-hidden="true" class="anchor" id="user-content-notable-changes-20"></a>Notable Changes</h3> <h4><a href="#user-content--new-features-18" aria-hidden="true" class="anchor" id="user-content--new-features-18"></a>🆕 New Features</h4> <ul> <li><strong>b9139</strong>: ggml-webgpu: Support GPU profiling beyond the maximum query count (<a href="https://github.com/ggml-org/llama.cpp/pull/22995">#22995</a>) <ul> <li>This PR fixes the bug described in the Additional Information section.</li> <li>Flush timestamp slots and reset the timestamp state when the number of used timestamp slots is nearly full.</li> <li>I confirmed that GPU profiles can now be collected for <code>Qwen3.5-35B-A3B-GGUF</code> and several other models (Qwen3.5, Qwen3.6, Gemma 4, and Llama 3).</li> </ul> </li> <li><strong>b9142</strong>: opencl: add q5_0 and q5_1 MoE for Adreno (<a href="https://github.com/ggml-org/llama.cpp/pull/22985">#22985</a>) <ul> <li> <!-- Describe what this PR does and why. Be concise but complete --> </li> <li>Add Q5_0 and Q5_1 MoE OpenCL support for Adreno.</li> <li> <!-- IMPORTANT: Please do NOT delete this section, otherwise your PR may be rejected --> </li> </ul> </li> <li><strong>b9144</strong>: ggml-webgpu: only use subgroup-matrix path when head dims are divisib… (<a href="https://github.com/ggml-org/llama.cpp/pull/23020">#23020</a>) <ul> <li>Previously, WebGPU FlashAttention selected the subgroup matrix path whenever subgroup matrix support was available. However, this fails in certain cases. For example, Jetson Thor’s smallest supported subgroup matrix shape is 16x16x16, which is incompatible with head dimensions such as 40 and 72.</li> <li>This change adds a shape guard before selecting the subgroup matrix path. Specifically, it requires:</li> <li><code>head_dim_qk % sg_mat_k == 0</code> and <code>head_dim_v % sg_mat_n == 0</code>.</li> </ul> </li> </ul> <h4><a href="#user-content--bug-fixes-16" aria-hidden="true" class="anchor" id="user-content--bug-fixes-16"></a>🐛 Bug Fixes</h4> <ul> <li><strong>b9134</strong>: download: do not exit() on error (<a href="https://github.com/ggml-org/llama.cpp/pull/23008">#23008</a>) <ul> <li>Fix <a href="https://github.com/ggml-org/llama.cpp/issues/23002">https://github.com/ggml-org/llama.cpp/issues/23002</a></li> <li>throw a runtime error instead of <code>exit()</code>, allowing downstream code to catch it</li> <li> <!-- IMPORTANT: Please do NOT delete this section, otherwise your PR may be rejected --> </li> </ul> </li> <li><strong>b9140</strong>: opencl: fix crash when warming up MoE on Adreno (<a href="https://github.com/ggml-org/llama.cpp/pull/22876">#22876</a>) <ul> <li> <!-- Describe what this PR does and why. Be concise but complete --> </li> <li>When warming up MoE models on Adreno (in this case, gpt-oss-20b-mxfp4), it crashes with invalid workgroup size.</li> <li>This is because the warmup run <code>ne20 = 128</code> (use all experts) and the workgroup size ends up exceeding the max workgroup size of 1024. During a normal run, <code>ne20</code> is the number of used experts and the workgroup size does not exceed the max workgroup size.</li> </ul> </li> <li><strong>b9143</strong>: Fix for issue #22974. Cast intermediate results to float before adding. (<a href="https://github.com/ggml-org/llama.cpp/pull/22994">#22994</a>) <ul> <li>Fix for issue <a href="https://github.com/ggml-org/llama.cpp/issues/22974">22974</a>. Cast intermediate results to float before adding and casting the result to the destination type. Avoids half+half operator ambiguity.</li> <li>None. Claude was used to develop the change.</li> </ul> </li> </ul> <h3><a href="#user-content-additional-changes-21" aria-hidden="true" class="anchor" id="user-content-additional-changes-21"></a>Additional Changes</h3> <p>4 minor improvements: 1 documentation, 3 examples.</p> <ul> <li><strong>b9145</strong>: SYCL: fix multi-GPU system RAM exhaustion by using Level Zero allocations (<a href="https://github.com/ggml-org/llama.cpp/pull/21597">#21597</a>) <ul> <li>Replace <code>sycl::malloc_device</code> with <code>zeMemAllocDevice</code> for GPU memory allocation in the SYCL backend</li> <li>Replace <code>sycl::free</code> with <code>zeMemFree</code> for corresponding deallocations</li> <li>Replace host-staged <code>dev2dev_memcpy</code> with direct Level Zero cross-device copy</li> </ul> </li> <li><strong>b9133</strong>: server, webui: support continue generation on reasoning models (<a href="https://github.com/ggml-org/llama.cpp/pull/22727">#22727</a>) <ul> <li>Reasoning models can now use the Continue button. Stopping mid thought saves the partial chain of thought, F5 keeps it, and clicking Continue resumes inside the thinking block instead of restarting from scratch. Same behavior for stops after the thinking ends. Plain content prefill is unchanged.</li> <li><a href="https://github.com/user-attachments/assets/02a61a8d-c02f-4c00-86f0-f0098fc94dc4">https://github.com/user-attachments/assets/02a61a8d-c02f-4c00-86f0-f0098fc94dc4</a></li> <li>Backend resolves the old TODO in oaicompat_chat_params_parse: removes the throw blocking assistant prefill on reasoning models and the forced reasoning_format = NONE workaround, then orchestrates thinking_start_tag, thinking_end_tag and generation_prompt around the prefilled message so the prompt is rebuilt correctly and the parser introduced in PR #20424 routes the next stream chunks to reasoning_content or content depending on whether the prefill is plain content, mid reasoning, or post reasoning. Bridges the API field from #21036, the parser routing from #20424 and the webui storage from #21249.</li> </ul> </li> <li><strong>b9133</strong>: server, webui: support continue generation on reasoning models (<a href="https://github.com/ggml-org/llama.cpp/pull/22727">#22727</a>) <ul> <li>Reasoning models can now use the Continue button. Stopping mid thought saves the partial chain of thought, F5 keeps it, and clicking Continue resumes inside the thinking block instead of restarting from scratch. Same behavior for stops after the thinking ends. Plain content prefill is unchanged.</li> <li><a href="https://github.com/user-attachments/assets/02a61a8d-c02f-4c00-86f0-f0098fc94dc4">https://github.com/user-attachments/assets/02a61a8d-c02f-4c00-86f0-f0098fc94dc4</a></li> <li>Backend resolves the old TODO in oaicompat_chat_params_parse: removes the throw blocking assistant prefill on reasoning models and the forced reasoning_format = NONE workaround, then orchestrates thinking_start_tag, thinking_end_tag and generation_prompt around the prefilled message so the prompt is rebuilt correctly and the parser introduced in PR #20424 routes the next stream chunks to reasoning_content or content depending on whether the prefill is plain content, mid reasoning, or post reasoning. Bridges the API field from #21036, the parser routing from #20424 and the webui storage from #21249.</li> </ul> </li> <li><strong>b9141</strong>: server, webui: accept continue_final_message flag for vLLM API compat (<a href="https://github.com/ggml-org/llama.cpp/pull/23012">#23012</a>) <ul> <li>Add the continue_final_message body flag from the vLLM and transformers API. When set together with add_generation_prompt false, it triggers the existing prefill_assistant code path, regardless of the server side opt.prefill_assistant option. Mutual exclusion with add_generation_prompt true is enforced, matching vLLM behavior.</li> <li>WebUI sends continue_final_message and add_generation_prompt false on the Continue button, with the matching opt in option on the chat service.</li> <li>Pure API alignment, no change to the prefill logic itself. Paves the way for the upcoming per-template prefill plumbing in common/chat.</li> </ul> </li> </ul> <h3><a href="#user-content-full-commit-range-24" aria-hidden="true" class="anchor" id="user-content-full-commit-range-24"></a>Full Commit Range</h3> <ul> <li>b9133 to b9145 (10 commits)</li> <li>Upstream releases: <a href="https://github.com/ggml-org/llama.cpp/compare/b9133...b9145">https://github.com/ggml-org/llama.cpp/compare/b9133...b9145</a></li> </ul> <hr /> <h2><a href="#user-content-2026-05-13-update-to-llamacpp-b9129" aria-hidden="true" class="anchor" id="user-content-2026-05-13-update-to-llamacpp-b9129"></a>2026-05-13: Update to llama.cpp b9129</h2> <h3><a href="#user-content-summary-25" aria-hidden="true" class="anchor" id="user-content-summary-25"></a>Summary</h3> <p>Updated llama.cpp from b9106 to b9129, incorporating 15 upstream commits with breaking changes and new features.</p> <h3><a href="#user-content-notable-changes-21" aria-hidden="true" class="anchor" id="user-content-notable-changes-21"></a>Notable Changes</h3> <h4><a href="#user-content-️-breaking-changes-13" aria-hidden="true" class="anchor" id="user-content-️-breaking-changes-13"></a>⚠️ Breaking Changes</h4> <ul> <li><strong>b9128</strong>: hexagon: eliminate scalar VTCM loads via HVX splat helpers (<a href="https://github.com/ggml-org/llama.cpp/pull/22993">#22993</a>) <ul> <li> <!-- Describe what this PR does and why. Be concise but complete --> </li> <li>Scalar loads from VTCM are expensive on Hexagon. This PR removes scalar VTCM loads in matmul and flash attention, replacing them with HVX vector loads + splat (<code>vdelta</code>) operations so the data stays in HVX registers end to end.</li> <li> <!-- You can provide more details and link related discussions here. Delete this section if not applicable --> </li> </ul> </li> </ul> <h4><a href="#user-content--new-features-19" aria-hidden="true" class="anchor" id="user-content--new-features-19"></a>🆕 New Features</h4> <ul> <li><strong>b9106</strong>: vulkan: Support asymmetric FA in scalar/mmq/coopmat1 paths (<a href="https://github.com/ggml-org/llama.cpp/pull/22589">#22589</a>) <ul> <li>Enable asymmetric K/V types in scalar/mmq/coopmat1 FA.</li> <li>I ran the backend perf tests before/after on mmq/coopmat1/coopmat2 paths and there were no regressions.</li> <li>I have read and agree with the <a href="https://github.com/ggml-org/llama.cpp/blob/master/CONTRIBUTING.md">contributing guidelines</a></li> </ul> </li> <li><strong>b9113</strong>: opencl: add q4_1 MoE for Adreno (<a href="https://github.com/ggml-org/llama.cpp/pull/22856">#22856</a>) <ul> <li>Q4_1 MoE kernel optimized for Adreno OpenCL backend.</li> <li> <!-- IMPORTANT: Please do NOT delete this section, otherwise your PR may be rejected --> </li> <li>I have read and agree with the <a href="https://github.com/ggml-org/llama.cpp/blob/master/CONTRIBUTING.md">contributing guidelines</a></li> </ul> </li> <li><strong>b9116</strong>: feat: add MiMo v2.5 vision (<a href="https://github.com/ggml-org/llama.cpp/pull/22883">#22883</a>) <ul> <li>This PR adds image input mmproj support for MiMo-V2.5.</li> <li>Testing:</li> <li> <details> </li> </ul> </li> <li><strong>b9119</strong>: vulkan: Fix Windows performance regression on Intel GPU BF16 workloads for Xe2 and newer (<a href="https://github.com/ggml-org/llama.cpp/pull/22461">#22461</a>) <ul> <li>This is a minor fix to #18178 . At the moment Intel Windows GPU driver does not expose BF16 availability (=<code>VK_KHR_shader_bfloat16</code> is not listed as device extension). Since the current code does not consider a case where coopmat is available but BF16 coopmat is unavailable, we are using <code>l_warptile</code> for BF16 scalar kernels. This is causing a regression vs non-coopmat config for n=512.</li> <li>This PR addresses the regresion by using <code>l_warptile</code> only when coopmat is truly available for BF16. We are seeing 8-9% performance improvement on pp512 of gemma-4-E2B-it-BF16.gguf using Xe2/Xe3 GPUs. For Linux we see no change since BF16 is already enabled by default.</li> <li>cc: @virajwad</li> </ul> </li> <li><strong>b9122</strong>: ggml-webgpu: address precision issues for multimodal (<a href="https://github.com/ggml-org/llama.cpp/pull/22808">#22808</a>) <ul> <li>In this PR, I addressed the precision issues for multimodal. More specifically, when mixed types are used in models and projectors, I use f32 for precision in the flash attention (more specifically, in the tile path) for the browser. I did not edit <code>flash_attn.wgsl</code> since <code>subgroup_matrix</code> isn't enabled in my test environment.</li> <li>Inputs:</li> <li>Tested model: LFM2.5-VL-450M-F16 with F16 mmproj.</li> </ul> </li> <li><strong>b9127</strong>: ggml-opencl: add opt-in Adreno xmem F16xF32 GEMM for prefill (<a href="https://github.com/ggml-org/llama.cpp/pull/22755">#22755</a>) <ul> <li>This PR adds an opt-in Adreno xmem GEMM path for OpenCL prefill matmul.</li> <li>Scope:</li> <li>build-time gated by <code>GGML_OPENCL_USE_ADRENO_KERNELS</code></li> </ul> </li> <li><strong>b9129</strong>: ggml-zendnn : adaptive fallback to CPU backend for small batch sizes (<a href="https://github.com/ggml-org/llama.cpp/pull/22681">#22681</a>) <ul> <li>Introduces an adaptive fallback mechanism in the ZenDNN backend that ensures ZenDNN never regresses against the native CPU backend, and also updates to the latest ZendNN version (ZenDNN-2026-WW17).</li> <li><strong>Problem</strong></li> <li>ZenDNN's <code>lowoha::matmul</code> is slower than ggml-cpu for:</li> </ul> </li> </ul> <h4><a href="#user-content--bug-fixes-17" aria-hidden="true" class="anchor" id="user-content--bug-fixes-17"></a>🐛 Bug Fixes</h4> <ul> <li><strong>b9118</strong>: vulkan: Check shared memory size for mmq shaders (<a href="https://github.com/ggml-org/llama.cpp/pull/22693">#22693</a>) <ul> <li>Calculate shared memory usage for mmq shaders, and choose smaller tile sizes when they don't fit.</li> <li>Should fix #22690.</li> <li>I have read and agree with the <a href="https://github.com/ggml-org/llama.cpp/blob/master/CONTRIBUTING.md">contributing guidelines</a></li> </ul> </li> </ul> <h3><a href="#user-content-additional-changes-22" aria-hidden="true" class="anchor" id="user-content-additional-changes-22"></a>Additional Changes</h3> <p>6 minor improvements: 2 documentation, 2 examples, 2 maintenance.</p> <h3><a href="#user-content-full-commit-range-25" aria-hidden="true" class="anchor" id="user-content-full-commit-range-25"></a>Full Commit Range</h3> <ul> <li>b9106 to b9129 (15 commits)</li> <li>Upstream releases: <a href="https://github.com/ggml-org/llama.cpp/compare/b9106...b9129">https://github.com/ggml-org/llama.cpp/compare/b9106...b9129</a></li> </ul> <hr /> <h2><a href="#user-content-2026-05-11-update-to-llamacpp-b9105" aria-hidden="true" class="anchor" id="user-content-2026-05-11-update-to-llamacpp-b9105"></a>2026-05-11: Update to llama.cpp b9105</h2> <h3><a href="#user-content-summary-26" aria-hidden="true" class="anchor" id="user-content-summary-26"></a>Summary</h3> <p>Updated llama.cpp from b9076 to b9105, incorporating 23 upstream commits with breaking changes and new features.</p> <h3><a href="#user-content-notable-changes-22" aria-hidden="true" class="anchor" id="user-content-notable-changes-22"></a>Notable Changes</h3> <h4><a href="#user-content-️-breaking-changes-14" aria-hidden="true" class="anchor" id="user-content-️-breaking-changes-14"></a>⚠️ Breaking Changes</h4> <ul> <li><strong>b9080</strong>: Gemma4_26B_A4B_NvFp4 hf checkpoint convert to gguf format fixes (<a href="https://github.com/ggml-org/llama.cpp/pull/22804">#22804</a>) <ul> <li>Gemma4_26B_A4B_NvFp4 hf checkpoint convert to gguf format fixes. This PR fixes the following:</li> <li> <ol> <li>Excluded weight_scale, weight_scale_2, and input_scale from the existing + ".weight" rename for .experts. tensors. The original rename was causing issue with NVFP4 scale tensor names (e.g. experts.0.down_proj.weight_scale_2 => experts.0.down_proj.weight_scale_2.weight), breaking the NVFP4 lookup at _generate_nvfp4_tensors</li> </ol> </li> <li> <ol start="2"> <li>Added FFN_GATE_EXP, FFN_UP_EXP, alongside the existing FFN_GATE_UP_EXP in the GEMMA4 tensor allow-list. Originally only fused FFN_GATE_UP_EXP was allowed. HF NVFP4 checkpoints store gate/up/down as separate per-expert tensors, so the converter couldn't map them especially for NvFP4 . Other option was to re-quantize if want to fuse gate and up proj.</li> </ol> </li> </ul> </li> </ul> <h4><a href="#user-content--new-features-20" aria-hidden="true" class="anchor" id="user-content--new-features-20"></a>🆕 New Features</h4> <ul> <li><strong>b9082</strong>: Feature hexagon l2 norm (<a href="https://github.com/ggml-org/llama.cpp/pull/22816">#22816</a>) <ul> <li>Add <code>GGML_OP_L2_NORM</code> support to the Hexagon HTP backend via an HVX vectorized kernel.</li> <li>I have read and agree with the <a href="https://github.com/ggml-org/llama.cpp/blob/master/CONTRIBUTING.md">contributing guidelines</a></li> <li>AI usage disclosure: YES, used Claude Code to generate the initial version based on other HVX code then iterated/tested/updated manually.</li> </ul> </li> <li><strong>b9084</strong>: hexagon: add HTP kernel for GGML_OP_GATED_DELTA_NET (<a href="https://github.com/ggml-org/llama.cpp/pull/22837">#22837</a>) <ul> <li>Add a high-performance HVX kernel for <code>GGML_OP_GATED_DELTA_NET</code> on Hexagon HTP, enabling Gated Delta Net models (e.g. Qwen3.5) to run the recurrence entirely on-device instead of falling back to CPU.</li> <li>Key optimizations:</li> <li><strong>Fused multi-row kernels</strong> (4-row for PP, 8-row for TG): reduces K/Q/gate vector reload overhead by 2–4×</li> </ul> </li> <li><strong>b9085</strong>: Add flash attention MMA / Tiles to support MiMo-V2.5 (<a href="https://github.com/ggml-org/llama.cpp/pull/22812">#22812</a>) <ul> <li>MiMo-V2.5 has asymmetric head sizes for K=192, v=128 which causes a fallback to CPU when using CUDA with flash attention enabled. This PR adds the required MMA / Tiles entries to support compilation for those sizes.</li> <li><code>llama-sweep-bench</code> speeds, <code>master</code>:</li> <li> <pre><code>
- b9088: [SYCL] Add BF16 support to GET_ROWS operation (#21391)
- Add
GGML_TYPE_BF16support to the SYCL backend'sGET_ROWSoperation. CurrentlyGET_ROWSsupports F16, F32, and several quantized types but not BF16, causing models with BF16 tensors to fall back to CPU for this operation — triggering catastrophic performance degradation due to full GPU→CPU tensor transfers on every token. -
Disclosure: This PR was authored with the assistance of AI (GitHub Copilot / Claude). The bug was discovered through systematic debug log analysis of real-world performance issues.
- The SYCL backend's
ggml_backend_sycl_device_supports_op()does not listGGML_TYPE_BF16in theGGML_OP_GET_ROWSswitch. When a model has BF16 tensors that requireGET_ROWS, the scheduler falls back to CPU, which requires downloading the entire tensor from GPU to CPU via PCIe every single token.
- Add
- b9093: model: add sarvam_moe architecture support (#20275)
- Add support for
sarvam_moearchitecture (sarvamai/sarvam-30b). SarvamMoEForCausalLMis a straightforward extension ofBailingMoeForCausalLM(see vLLM PR #33942)- 19 layers: 1 dense FFN + 18 MoE layers (128 routed experts, top-6, 1 shared expert)
- Add support for
🐛 Bug Fixes
- b9079: common : revert reasoning budget +inf change (#22740)
- fixes #22717
- I have read and agree with the contributing guidelines
- b9081: common : do not wrap raw strings in schema parser for tagged parsers (#22827)
- Fixes #22240
- I have read and agree with the contributing guidelines
- b9094: model : fix model type check for granite/llama3 and deepseek2/glm4.7 lite (#22870)
- cont #22004
- Fixes https://github.com/ggml-org/llama.cpp/pull/22004#issuecomment-4412473268
- The checks used uninitialized
n_vocabinstead of fetching from metadata as was done before refactor.
Additional Changes
14 minor improvements: 3 documentation, 6 examples, 5 maintenance.
Full Commit Range
- b9076 to b9105 (23 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b9076...b9105
2026-05-02: Update to llama.cpp b9002
Summary
Updated llama.cpp from b8992 to b9002, incorporating 10 upstream commits with new features and performance improvements.
Notable Changes
🆕 New Features
- b8994: ggml-webgpu: add the upscale shader (#22419)
- In this PR, I added the upscale shader. Based on the test cases, nearest, bilinear (w/t antialias) and bicubic methods are implemented with/without the aligned_corner flags. Some other combinations are currectly ignored,
- All tests passed; did not find performance tests so cannot run a comparison test.
- b8995: vulkan: Support asymmetric FA in coopmat2 path (#21753)
- There has been some recent interest/experimentation with mixed quantization types for FA. I had originally designed the cm2 FA shader with this in mind (because I didn't realize it wasn't supported at the time!), this change adds the missing pieces and enables it.
- Also support Q1_0 since people have been trying that out (seems crazy, but who knows).
- We should be able to do similar things in the coopmat1/scalar path, but there's another change open against the scalar path and I don't want to conflict.
- b8998: hexagon: enable non-contiguous row tensor support for unary ops (#22574)
- Enable hexagon support for unary ops for non-contiguous row-strided tensors.
- Relax support check to accept row-contiguous tensors (
ggml_is_contiguous_rows) instead of requiring full contiguity - Add
unary_row_offset()to compute correct DDR byte offsets using actual tensor strides for non-contiguous tensors
- b8999: llama-quant : fix
--tensor-typewhen defaultqtypeis overriden (#22572)- fix #22544 (my fault!)
- Currently, when using
--tensor-type "<regex>=GGML_TYPE", if theGGML_TYPEoverride matches the default type for the chosen outputftype, the internal heuristics inllama_tensor_get_type_implmay still take effect, rather than being locked to the specifiedGGML_TYPE. - This is my own mistake that I introduced in #19770.
- b8999: llama-quant : honor --tensor-type override when it matches the global ftype (#22559)
- Fixes #22544.
- When a user supplies an explicit
--tensor-type "<pattern>=<type>"mapping that happens to match the requested global ftype, the user's intent (lock that tensor to that exact type) is silently dropped and the imatrix/heuristic path is allowed to override it. llama_tensor_get_typeonly setmanual = truefrom inside theqtype != new_typebranch:
- b9000: hexagon: hmx flash attention (#22347)
- This PR implemented hmx based flash attetion for Hexagon backend.
- Profiling shows that the main bottleneck is the
expcomputation (about 40% of total FA runtime). I experimented with a LUT-based, lossless optimization, but it appears thatvgathercannot be effectively parallelized—multithreadedvgatherprovided no measurable speedup.I’m not sure whether this is due to an issue in my implementation or an inherent hardware limitation.As mentioned here,vgatheris aborted. - As an alternative, I implemented an FP16 version of exp to improve performance. This does introduce some numerical loss, so it is disabled by default. Enabling it via
GGML_HEXAGON_FA_EXP2_HF=ONyields an additional ~10% performance gain.
- b9000: hexagon: optimization for HMX mat_mul (#21554)
- This PR introduces two additional optimizations for the Hexagon HMX backend:
-
- Enable asynchronous HMX execution
- HMX computations are now executed asynchronously, allowing them to overlap with HVX dequantization and DMA stages within the pipeline. Previously, synchronous HMX calls blocked the main thread and limited parallelism.
🚀 Performance Improvements
- b8996: ggml-webgpu: Fix vectorized handling in mul-mat and mul-mat-id (#22578)
- This PR fixes two issues with the handling of vectorized in mul-mat.
- Remove the
dst->ne[1]check ofkey.vectorizedfrom mul-mat-fast, as it looks unnecessary in bothmul_mat_reg_tileandmul_mat_subgroup_matrix. The following shows an example of the performance improvement. - Add the missing vectorized variant name to the mul-mat-id pipeline.
🐛 Bug Fixes
- b8992: Update llama-mmap to work with 32-bit emscripten (#22497)
- When compiling to 32-bit WebAssembly through Emscripten,
std::fseekandstd::ftellreturn along, which is interpreted as a 32-bit signed value. Unfortunately, this means that any files above 2GB overflow the maximum positive integer, leading to bad results. This fixes that by delegating tofseekoandftelloin Emscripten builds, which return a 64-bitoff_tthat can be interpreted correctly in both 32-bit and 64-bit WASM builds. - Note that ggml does something similar in all cases: https://github.com/ggml-org/llama.cpp/blob/master/ggml/src/gguf.cpp#L25. However I didn't make that full change here because I'm not sure if it would lead to issues in other places.
- For a little more context, this, in combination with the origin private file system (OPFS), allows models > 2GB to be loaded by the WebGPU backend in the browser without splitting the models into shards.
- When compiling to 32-bit WebAssembly through Emscripten,
Additional Changes
1 minor improvements: 1 maintenance.
- b9002: b9002
-
Full Commit Range
- b8992 to b9002 (10 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8992...b9002
2026-05-01: Update to llama.cpp b8992
Summary
Updated llama.cpp from b8946 to b8992, incorporating 41 upstream commits with breaking changes and new features.
Notable Changes
⚠️ Breaking Changes
- b8946: fix(graph): remove duplicate wo_s scale after build_attn (Qwen3, LLaMA) (#22421)
- Observed that build_attn present in llama-graph already applies NVFP4 per tensor scale (wo_s) via
- llama-graph.cpp (build_lora_mm(wo, cur, wo_s) or explicit wo_s mul).
- Also observed these model builders(qwen3, qwen3moe, llama) are also multiplied the
- b8981: common : do not pass prompt tokens to reasoning budget sampler (#22488)
- cont: #22323
- Do not pass prompt tokens through the reasoning budget sampler, mirroring grammar behavior. Renamed
accept_grammartois_generatedto better convey the purpose of this flag. - Also adjusted the prefill logic to pass the generation prompt through the reasoning budget sampler as well. I removed the
prefill_tokensparameter, as it required the prefill to match the starting token sequence exactly. Instead, we simply feed each token individually so it gets processed by the state machine.
🆕 New Features
- b8950: Additional test for common/gemma4 : handle parsing edge cases (#22420)
- Add few test cases for #21760
- b8951: ggml-webgpu: fast matrix-vector multiplication for i-quants (#22344)
- Adds fast WebGPU mat-vec implementations for all nine i-quant types (IQ1_S, IQ1_M, IQ2_XXS, IQ2_XS, IQ2_S, IQ3_XXS, IQ3_S, IQ4_NL, IQ4_XS). The kernels are added to
mul_mat_vec.wgsland selected through the existinguse_fastdispatcher inggml_webgpu_mul_mat. - Numbers below are from
test-backend-ops perf, comparing this branch vs. current master for the variant
- Adds fast WebGPU mat-vec implementations for all nine i-quant types (IQ1_S, IQ1_M, IQ2_XXS, IQ2_XS, IQ2_S, IQ3_XXS, IQ3_S, IQ4_NL, IQ4_XS). The kernels are added to
- b8953: ggml-webgpu: add Q1_0 support (#22374)
- Adds WebGPU support for the Q1_0 quantization type, including a fast mat-vec kernel (
MUL_ACC_Q1_0inmul_mat_vec.wgsl), a fast mat-mat block (INIT_SRC0_SHMEM_Q1_0inmul_mat_decls.tmpl) that enables both the register-tile and subgroup-matrix paths, and aGET_ROWSdequant (Q1_0block inget_rows.wgsl), along with the dispatcher andsupports_opupdates forMUL_MATandMUL_MAT_ID. - Q1_0 was previously not supported on the WebGPU backend, so both mat-vec and mat-mat dispatched to the CPU fallback. With this PR the kernels run on WebGPU.
- Adds WebGPU support for the Q1_0 quantization type, including a fast mat-vec kernel (
- b8956: CANN: Add support for Qwen35 ops (#21204)
- This PR adds support for several missing operators in the CANN (Ascend NPU) backend for qwen3.5
- New operators:
- b8960: vulkan: add barrier after writetimestamp (#21865)
- Add a pipelinebarrier after each writetimestamp call in the perf_logger code.
- The vulkan spec doesn't prevent commands issued after a timestamp from starting to execute before the timestamp is written. The NV driver had been ordering these, but future drivers won't. So we need a barrier after each timestamp to order the timestamp vs the next commands.
- b8962: ggml-webgpu: fix buffer aliasing for ssm_scan and refactor aliasing logic (#22456)
- @SharmaRithik noticed that when running Granite 4.0 ssm_scan aliases several tensors, which this PR fixes by adding logic to merge those tensors into a single binding in the shader. After making that change, I realized that some of the logic for calculating aliasing could be refactored so that it is consistent across all operations and takes place in the shader library during preprocessing, so I made that change as well. I also added a test for the overlapping tensors for ssm_scan.
- fyi @yomaytk
- b8964: common : re-arm reasoning budget after DONE on new (#22323)
- DONE state in reasoning budget state machine absorbs start tags, causing any block after the first to run unbudgeted. This makes it so the reasoning budget is a no-op for multi-block thinking models. Using the Qwen3.6-27B model with the recommended settings causes this issue to appear [1]. The fix is to re-arm in DONE on a match and transition to COUNTING with a fresh budget. I've added a regression test in test-reasoning-budget to test for this new behavior and all 6 tests pass.
- [1] "Thinking Preservation: we've introduced a new option to retain reasoning context from historical messages, streamlining iterative development and reducing overhead." - https://huggingface.co/Qwen/Qwen3.6-27B
- Reproducible using:
unsloth/Qwen3.6-27B-GGUF, server flags:--reasoning-budget 128 --reasoning-format deepseek --jinja, base commit: master at15fa3c493(b8920)
- b8966: ggml-cuda: add flash-attn support for DKQ=320/DV=256 with ncols2=32 (… (#22286)
- …GQA=32)
- Adds MMA-f16 and tile kernel configs, dispatch logic, template instances, and tile .cu file for Mistral Small 4 (head sizes 320/256), restricting to ncols2=32 to support GQA ratio 32 only.
- Add fattn-kernel instantiation for dimension DQK=320 and DV-256 required for Mistal small 4. forced kernel instantiation to ncols2=32
- b8967: ggml-cuda: Repost of 21896: Blackwell native NVFP4 support (#22196)
- This is a restored clone of PR #21896 ggml-cuda: Blackwell native NVFP4 support .
- Unfortunately it closed during a rebase error and it cannot be reopened
- The exact commits are here as they were before. Sorry about this mixup!
- b8969: Added sve tuned code for gemm_q8_0_4x8_q8_0() kernel (#21916)
- This PR introduces support for SVE (Scalable Vector Extensions) kernels for the q8_0_q8_0 gemm using i8mm and vector instructions. ARM Neon support for this kernel added Earlier.
- This PR contains the SVE implementation of the gemm used to compute the Q8_0 quantization.
- b8974: ggml-cpu : disable tiled matmul on AIX to fix page boundary segfault (#22293)
- vec_xst operations in the tiled path crash on AIX when writing near 4KB page boundaries due to strict memory protection. Fall back to mnpack implementation on AIX for stable execution.
- This patch fixes segmentation faults in q4_0 model inference on AIX PowerPC systems by disabling the tiled matrix multiplication path in llamafile's sgemm implementation.
vec_xstoperations crash on AIX when writing near 4KB page boundaries due to strict memory protection. Thevec_xstinstruction cannot write across page boundaries on AIX, and when the buffer offset lands at addresses like0x1100ed000(exactly at a page boundary), the write operation attempts to access unmapped memory, triggering a segfault.
- b8979: CUDA: fuse SSM_CONV + ADD(bias) + SILU (#22478)
- Adds a CUDA fusion for
SSM_CONV + ADD(bias) + SILU. The existingSSM_CONV + SILUfusion didn't match on Mamba-1 and Mamba-2 layers (used by Nemotron-H, Granite-Hybrid, Jamba, and other Mamba-style hybrids) because of a biasADDoperation between the conv and the SILU. - | Model | Test | t/s master | t/s ssm_conv-bias-silu-fusion | Speedup |
- |:------------------|:--------------|-------------:|--------------------:|----------:|
- Adds a CUDA fusion for
- b8980: hexagon: make vmem and buffer-size configurable (#22487)
- This PR adds two new knobs to the Hexagon backend
GGML_HEXAGON_VMEM- Allows for overriding default VMEM limit. The default is the same as before (around 3.2GB)
- b8984: ggml-webgpu: add fast mat-mat path for i-quants (#22504)
- Adds i-quant support to the WebGPU fast mat-mat path. Previously i-quants (IQ1_S, IQ1_M, IQ2_XXS, IQ2_XS, IQ2_S, IQ3_XXS, IQ3_S, IQ4_NL, IQ4_XS) only had a fast mat-vec kernel; mat-mat (prefill) fell back to the legacy non-tiled
mul_mat.wgslpath. This PR adds the missingINIT_SRC0_SHMEM_IQ*blocks tomul_mat_decls.tmplso the same shared memory dequant feeds both fast paths. - Numbers below are kernel-level throughput (GFLOPS) from
test-backend-ops perf -o MUL_MATatm=4096, n=512, k=14336. The register-tile column was measured by disabling thesubgroup_matrixcapability so the fallback fast path runs directly.
- Adds i-quant support to the WebGPU fast mat-mat path. Previously i-quants (IQ1_S, IQ1_M, IQ2_XXS, IQ2_XS, IQ2_S, IQ3_XXS, IQ3_S, IQ4_NL, IQ4_XS) only had a fast mat-vec kernel; mat-mat (prefill) fell back to the legacy non-tiled
- b8990: vulkan: add get/set tensor 2d functions (#22514)
- Implement the 2d tensor copy functions that were added for TP support to the Vulkan backend. This shouldn't make a performance difference, but it was not much work since the 2d functions basically already existed.
- I also noticed that the interface comments for the functions were universally wrong, so I corrected them, too. Sorry about the pings that causes.
- I have read and agree with the contributing guidelines
🐛 Bug Fixes
- b8948: common: Fix type casting for unaccounted memory calculation (#22424)
- fix unaccounted mem showing huge numbers (like 2^44, 2^44 = 2^64/1024/1024) when running llama-server --fit on.
- changed unaccounted from size_t to int64_t so it can show negative values properly.
- before pr:
- b8949: fix: rpc-server cache may not work in Windows environments (#22394)
- Even when cache is enabled on the rpc-server in a Windows environment, the rpc directory is not automatically created, and therefore, cache files within that directory are not created.
- Furthermore, only the first character of the cache file name is output to the log, making it difficult to notice that cache files are not being generated.
- Before
- b8957: ggml : revert to -lm linking instead of find_library (#22355)
find_library(MATH_LIBRARY m)was introduced recently, but it breaks CUDA compilation with GGML_STATIC. I could not find any valid use case where we would preferfind_libraryover the standard-lmapproach.- This commit is also meant to start a discussion if there is a valid reason to keep
find_library(MATH_LIBRARY m), we should clarify what problem it was solving and find an alternative fix that does not break CUDA with GGML_STATIC. - Found with installama.sh: https://github.com/angt/installama.sh/actions/runs/24885620138/job/72864816848
- b8968: TP: fix delayed AllReduce + zero-sized slices (#22489)
- Fixes https://github.com/ggml-org/llama.cpp/issues/22391 .
- The problem is that k-quants have a block size of 256 vs. the size of a single expert at 512. So for 3+ GPUs one of them ends up with a zero-sized slice. This would normally not be an issue since a zero-sized slice is supported; the corresponding nodes are disabled and the backend participates in the following AllReduce with a zeroed out buffer in order to receive the results of other backends. However, the interaction of a zero-sized slice and a delayed AllReduce for better MoE performance does not work correctly. For those the range of disabled nodes needs to be extended, otherwise one of the backends will have garbage data prior to the AllReduce.
- Using 3x RTX 4090 the Qwen 3.6 q4_K_M PPL on the first 512 tokens of Wikitext is 4.1590 for
-sm layer, for-sm tensoron master it's 8.3604, for-sm tensorwith this PR it's4.1554.
- b8970: common: Intentionally leak logger instance to fix hanging on Windows (#22273)
- Added workaround for #22142. There are three points in this PR:
- Intentional leak of logger instance
~common_log()called at DLL teardown phase was causing hanging on Windows. DLL teardown phase seems to be a fragile timing to do system calls like mutex lock, cond notify, thread join, etc. which did not provide sane results. We are working around this by intentionally leaking the logger instance to skip cleanup.
- b8971: ggml-webgpu: Fix bug in FlashAttention support check (#22492)
- https://github.com/ggml-org/llama.cpp/pull/22199 enabled FlashAttention in the browser (non subgroup-matrix paths). However, the check in supports-op had a fallback to the subgroup-matrix path if the new tile path wasn't supported (e.g., if the browser doesn't support subgroups). This caused an error when calculating some of the shader parameters. This PR fixes the issue by returning false early in the support check if none of the flashattention variants will work.
- fyi @ArberSephirotheca.
- b8972: ggml-cpu: cmake: append xsmtvdotii march for SpacemiT IME (#22317)
- When GGML_CPU_RISCV64_SPACEMIT=ON is set, ime1_kernels.cpp contains inline asm for the vmadot family which requires the xsmtvdotii custom extension.(problem can see in some blogs and make sure in K3 platform) The current CMakeLists does not include xsmtvdotii, so any toolchain that honours the explicit -march (tested with SpacemiT GCC 15.2) fails at the assembler stage:
- Error: unrecognized opcode `vmadot v16,v14,v0',
- extension `xsmtvdotii' required
- b8973: ggml-cuda: refactor fusion code (#22468)
- Refactor the fusion code to be a single function. Also fix a bug in the fusion code where it does not check the value of the env variable to disable fusion.
- b8982: spec : fix vocab compat checks (#22358)
- Fix the logic for checking compatibility of the special tokens in the target and draft vocabs.
- For example, this makes the vocabs of Qwen3.6 27B and Qwen3.5 0.8B compatible.
- b8986: CUDA: fix tile FA kernel on Pascal (#22541)
- Fixes https://github.com/ggml-org/llama.cpp/issues/22491 .
- The problem is that the new kernel for Mistral Small 4 is being compiled unconditionally with 32 columns / CUDA block. On Pascal that puts it above the 38 kiB / CUDA block shared memory limit. This PR makes it so that 32 columns/block continue to be used for AMD where this fits and on Pascal 2 CUDA blocks with 16 columns each are used instead.
- b8989: spec: fix cli argument typo (#22552)
- Fix a typo in cli arguments
- I have read and agree with the contributing guidelines
- b8992: Update llama-mmap to work with 32-bit emscripten (#22497)
- When compiling to 32-bit WebAssembly through Emscripten,
std::fseekandstd::ftellreturn along, which is interpreted as a 32-bit signed value. Unfortunately, this means that any files above 2GB overflow the maximum positive integer, leading to bad results. This fixes that by delegating tofseekoandftelloin Emscripten builds, which return a 64-bitoff_tthat can be interpreted correctly in both 32-bit and 64-bit WASM builds. - Note that ggml does something similar in all cases: https://github.com/ggml-org/llama.cpp/blob/master/ggml/src/gguf.cpp#L25. However I didn't make that full change here because I'm not sure if it would lead to issues in other places.
- For a little more context, this, in combination with the origin private file system (OPFS), allows models > 2GB to be loaded by the WebGPU backend in the browser without splitting the models into shards.
- When compiling to 32-bit WebAssembly through Emscripten,
Additional Changes
12 minor improvements: 1 documentation, 6 examples, 5 maintenance.
Full Commit Range
- b8946 to b8992 (41 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8946...b8992
2026-04-27: Update to llama.cpp b8946
Summary
Updated llama.cpp from b8863 to b8946, incorporating 63 upstream commits with breaking changes, new features, and performance improvements.
Notable Changes
⚠️ Breaking Changes
- b8917: jinja : remove unused header (#22310)
- Remove unused header
- I have read and agree with the contributing guidelines
- b8922: ggml-webgpu: enable FLASH_ATTN_EXT on browser without subgroup matrix (#22199)
- This PR addresses few things:
-
- Cleanup the vec path to remove requirement for subgroup matrix.
- b8946: fix(graph): remove duplicate wo_s scale after build_attn (Qwen3, LLaMA) (#22421)
- Observed that build_attn present in llama-graph already applies NVFP4 per tensor scale (wo_s) via
- llama-graph.cpp (build_lora_mm(wo, cur, wo_s) or explicit wo_s mul).
- Also observed these model builders(qwen3, qwen3moe, llama) are also multiplied the
🆕 New Features
- b8863: ggml-cuda: flush legacy pool on OOM and retry (#22155)
- This adds a conservative fallback for the legacy CUDA/HIP pool allocator.
- On non-VMM setups, the legacy pool can end up holding cached free buffers that are individually too small for a new request, but still occupy enough VRAM to make the next allocation fail. In that case, this patch flushes the cached legacy-pool buffers and retries the allocation once before aborting.
- The normal hit path is unchanged. This is intended as a narrow mitigation for legacy-pool OOMs, not a broader allocator redesign. I validated the retry path locally with a synthetic OOM injection on a legacy-pool build.
- b8868: llama-ext : fix exports (#22202)
- cont #22171
- Export new symbols.
- b8870: vulkan: Support F16 OP_FILL (#22177)
- Support f16 for OP_FILL. This came up in https://github.com/ggml-org/llama.cpp/pull/21149.
- I have read and agree with the contributing guidelines
- AI usage disclosure: YES, I used AI to write this, but I reviewed it.
- b8874: arg : add --spec-default (#22223)
- Add
--spec-defaultflag for enabling default configuration for speculative decoding. - I have read and agree with the contributing guidelines
- Add
- b8878: Hexagon: DAIG op (#22195)
- I have read and agree with the contributing guidelines
- AI usage disclosure: Yes, to understand some basics of how to add a hexagon op
- b8881: hexagon: add support for FILL op (#22198)
- Add support for FP32 and FP16 FILL op in hexagon backend.
test-backend-ops -b HTP0 -o FILL-
</code></pre> </li> </ul> </li> <li><strong>b8882</strong>: ggml-webgpu(shader): support conv2d kernels. (<a href="https://github.com/ggml-org/llama.cpp/pull/21964">#21964</a>) <ul> <li>In this PR, we implemented the conv2d shader kernel to support VL models that require conv2d operations.</li> <li>Backend ops tests all passed. I haven't tested this with real models yet.</li> </ul> </li> <li><strong>b8891</strong>: ggml-webgpu: Add fused RMS_NORM + MUL (<a href="https://github.com/ggml-org/llama.cpp/pull/21983">#21983</a>) <ul> <li> <!-- Describe what this PR does and why. Be concise but complete --> </li> <li>This PR adds the initial kernel fusion to WebGPU backend with RMS_NORM + MUL (it is similar to <a href="https://github.com/ggml-org/llama.cpp/pull/14800">https://github.com/ggml-org/llama.cpp/pull/14800</a>).</li> <li>The performance on the major models on my device (M2, Metal 4) is as follows, but unfortunately, the performance is almost the same on this implementation.</li> </ul> </li> <li><strong>b8892</strong>: [WebGPU] Implement async tensor api and event api (<a href="https://github.com/ggml-org/llama.cpp/pull/22099">#22099</a>) <ul> <li>This PR implements the async tensor and event api necessary for the WebGPU backend to use the async loading mode to load models. This is needed because we have strict memory requirements when running wllama with the WebGPU backend (especially on Safari and on mobile devices). The async tensor API uses only four 1MB buffers to load a model, while the default loading mode uses a single resizable buffer. Using the async tensor API reduces our memory footprint by ~20-25%.</li> <li>Some figures on memory usage in wllama with these and other changes:</li> <li> <img width="2100" height="900" alt="steady_state_bar_cold" src="https://github.com/user-attachments/assets/189bd1ee-4de1-4d9d-8da2-2e6f3a6c9e5e" /> </li> </ul> </li> <li><strong>b8893</strong>: Add hipGraph and VMM support to ROCM (<a href="https://github.com/ggml-org/llama.cpp/pull/11362">#11362</a>) <ul> <li>This adds, disabled by default, hipGraph support. Essentially this just involves adding the relevant hip defines to ggml-cuda/vendors/hip.h</li> <li>Currently is seams that hipGraph dosent improve performance at all. Looking at rocprof it seams that launching the kernels this way gains no decrease in overhead, while building the graph adds overhead. Presumably since this api was recently added to rocm and is still marked as beta (<a href="https://rocmdocs.amd.com/projects/HIP/en/latest/reference/hip_runtime_api/modules/graph_management.html">https://rocmdocs.amd.com/projects/HIP/en/latest/reference/hip_runtime_api/modules/graph_management.html</a>) It has not been tuned for performance.</li> <li>I still think its useful to have this since in the future this will likely change, and maybe on some hw configs it already helps right now.</li> </ul> </li> <li><strong>b8913</strong>: ggml-wegpu: handle the buffer aliasing for rms fuse (<a href="https://github.com/ggml-org/llama.cpp/pull/22266">#22266</a>) <ul> <li>This PR addressed an edge case of #21983. I load and run a model in the browser, and I met this error:</li> <li> <pre><code>
- ggml_webgpu: Device error! Reason: 2, Message: Writable storage buffer binding aliasing found between [BindGroup "RMS_NORM_MUL"] set at bind group index 0, binding index 0, and [BindGroup "RMS_NORM_MUL"] set at bind group index 0, binding index 2, with overlapping ranges (offset: 5242880, size: 4096) and (offset: 5242880, size: 4096) in [Buffer "tensor_buf3"].
- b8914: hexagon: add SOLVE_TRI op (#21974)
- This PR add
solve triop support for hexagon. Usehvxto accelarate the caculation. - Tests all passes with
test-backend-ops.
- b8935: opencl: add iq4_nl support (#22272)
- This PR adds support for iq4_nl. It is slightly bigger, containing both general implementation and Adreno specific implementation.
- b8944: ggml : use 64 bytes aligned tile buffers (#21058)
- While trying to fix #20824, i couldn't reproduce it so far but forcing alignment could help and doesn't hurt.
- | Model | Test | t/s OLD | t/s NEW | Speedup |
- |:---------------------------------|:-------|----------:|----------:|----------:|
🚀 Performance Improvements
- b8893: HIP: flip GGML_HIP_GRAPHS to on (#22254)
- In #11362 hip graph was disabled by default as, at the time, its performance impact was negative. Due to improvements in rocm and our usage and construction of graphs this is no longer true, so lets change the default
- gfx1100 @ 340w
- | Model | Test | t/s master | t/s hipgraph | Speedup |
- b8931: CUDA: reduce MMQ stream-k overhead (#22298)
- This PR reduces the stream-k overhead in the MMQ kernel by using
fastdivwhich precomputes some values on the CPU to speed up integer divisions. Also, as originally suggested by @nisparks in https://github.com/ggml-org/llama.cpp/pull/22170 and https://github.com/ggml-org/llama.cpp/pull/22252 optionally use tiling rather than a stream-k decomposition. The implementation in this PR is different vs the ones linked: in those an extra variant of the kernel is being compiled that has the tiling hard-coded (as is done for relatively old GPUs), in this PR the number of CUDA blocks is scaled dynamically to the number of tiles so that each CUDA block works on exactly one tile; if it turns out that there is a meaningful performance difference it may make sense to still compile the extra kernels. The choice for whether or not to use stream-k does not explicitly depend on MoE in this PR, instead it is determined from the efficiency loss that would be incurred by tiling: if it is <= 10% tiling is used in order to skip the stream-k fixup. - I have read and agree with the contributing guidelines
- This PR reduces the stream-k overhead in the MMQ kernel by using
- b8936: ggml-cpu: optimize avx2 q6_k (#22345)
- Basically I took the optimizations I did for AVX a while back and brought them over to AVX2.
- PR:
- | model | size | params | backend | threads | test | t/s |
- b8941: ggml-webgpu: performance-portable matmul tuning knobs (#22241)
- This PR updates the tuning knobs for the WebGPU register tiling and subgroup matmul kernels to improve performance across GPUs. These suggested knobs are based on exhaustive data collection from four GPUs: NVIDIA RTX 5080 FE, AMD Radeon RX 7900 XT, Intel Arc B580, and Apple M2. After running a performance portability analysis on the exhaustive data, we found configurations that provide better average performance while minimizing worst-case slowdowns.
- Here is the table:
- | Path | Metric | Default | Proposed |
🐛 Bug Fixes
- b8871: metal : workaround macOS GPU interactivity watchdog (#22216)
- fix #20141
- fix #22214
- See https://github.com/ggml-org/llama.cpp/issues/20141#issuecomment-4273461320 for more information.
- b8873: Fix build for Android (#125)
- The project can be built for Android with NDK and CMake like this:
- cmake -DCMAKE_TOOLCHAIN_FILE=$NDK/build/cmake/android.toolchain.cmake -DANDROID_ABI='arm64-v8a' -DANDROID_PLATFORM=android-23 ..
- However, vdotq_* intrinsics are not available on Android. Fix this by checking for ANDROID and use the code replaced by commit 84d9015c in this case.
- b8873: Fix potential licensing issue (#126)
- I'm not an expert on Licenses BUT,
- If you attribute Facebook in the README and description, you essentially admit/imply that this repo is a modification of their repo. Facebook's repo has "GPL-3.0 license". Which means this repo should also be like that in that case, which is something that we dont want.
- This PR fixing that potential language issue.
- b8880: ggml-webgpu: reset CPU/GPU profiling time when freeing context (#22050)
- This PR fixes https://github.com/ggml-org/llama.cpp/issues/22049.
- When I ran the command as in the above issue, the result is as follows, and we can see that the profiling times are reset for each test.
- b8882: ggml webgpu: Move to no timeout for WaitAny in graph submission to avoid deadlocks (#20618)
- Another approach to see if this avoids deadlocks in the llvm-pipe Vulkan backend. After some debugging on the Github CI I've seen cases where it seems to get stuck within the
WaitAnycall itself, even after the timeout nanoseconds have passed, leading me to believe there is a bug within the interface between Dawn and llvm-pipe. Setting timeout to 0 from the WebGPU side creates a busy-wait loop on the ggml side, but hopefully avoids deadlocking in most scenarios, and in practice the busy-wait loop does not occur that often in my tests.
- Another approach to see if this avoids deadlocks in the llvm-pipe Vulkan backend. After some debugging on the Github CI I've seen cases where it seems to get stuck within the
- b8888: sycl: Improve mul_mat_id memory efficiency and add BF16 fast path (#22119)
- This PR addresses memory exhaustion issues (
UR_RESULT_ERROR_OUT_OF_HOST_MEMORY) encountered on SYCL Level Zero when handling large-vocabulary models and MoE architectures. - Key Changes:
-
- BF16 Fast Path via DNNL:
- This PR addresses memory exhaustion issues (
- b8901: metal : fix event synchronization (#22260)
- cont #20463
- cont #18919
- Fix the event synchronization logic when using virtual Metal devices.
- b8905: ci : fix build number for sycl release (#22283)
- Fix SYCL release binaries having
b1as build number. - Build number was not calculated correctly due to checkout depth.
- Fix SYCL release binaries having
- b8919: common : fix jinja warnings with clang 21 (#22313)
- Fix jinja warnings with clang 21
- b8933: chat: fix handling of space in reasoning markers (#22353)
- Extracted from #22162 (thanks @roj234 ), just the fix for the parser
- We're putting off the prefill changes for a further PR (prepared by @aldehir ) so I'm just taking this fix as a standalone.
- b8937: cpu : re-enable fast gelu_quick_f16 (#22339)
- Enable disabled
ggml_vec_gelu_quick_f16. - I couldn't find any reason why this was disabled, and the current version is 10-20x slower.
- Another puzzling fact is that we use the same table for
ggml_vec_gelu_quick_f32(asGGML_GELU_QUICK_FP16is enabled) so there should be no issue?
- Enable disabled
- b8940: [Tensor Parallel] Fix recurrent state serialization for partial reads and writes (#22362)
- The previous code worked only for full tensor reads and writes and was hitting
GGML_ASSERT(size == ggml_nbytes(tensor));assert when tested with llama-server. - I have read and agree with the contributing guidelines
- The previous code worked only for full tensor reads and writes and was hitting
Additional Changes
30 minor improvements: 7 documentation, 18 examples, 5 maintenance.
Full Commit Range
- b8863 to b8946 (63 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8863...b8946
2026-04-21: Update to llama.cpp b8863
Summary
Updated llama.cpp from b8831 to b8863, incorporating 32 upstream commits with breaking changes, new features, and performance improvements.
Notable Changes
⚠️ Breaking Changes
- b8839: model : refactor bias tensor variable names (#22079)
- https://github.com/ggml-org/llama.cpp/pull/21971#pullrequestreview-4118994933
- Removes duplicate tensor variables.
- b8843: cmake: remove CMP0194 policy to restore MSVC builds (#21934)
- Thanks to @oobabooga for catching this: https://github.com/ggml-org/llama.cpp/pull/21630#issuecomment-4248308373
- PR #21630 added CMP0194 NEW to silence a warning, but it broke Windows MSVC+Ninja.
- the first attempt at scoping ASM to kleidiai hit an unrelated CMake scoping issue on the ARM+KleidiAI self-hosted runner, so I pivoted to a minimal revert. This removes only the 6-line CMP0194 policy block from ggml/CMakeLists.txt. project("ggml" C CXX ASM) is left untouched, which is exactly the pre-#21630 state that was working on all platforms. The CMake 4.1+ warning returns but no platform breaks.
- b8848: HIP: Remove unesscary NCCL_CHECK (#21914)
- In an intermediate state of #19378, RCCL use was behind its own define (GGML_USE_RCCL) so this was required. Before merging, #19378 was changed so that GGML_USE_NCCL enables both NCCL and RCCL, so NCCL_CHECK in common.cu became visible on HIP. At this point NCCL_CHECK in hip.h should have been removed, but this was forgotten.
- I have read and agree with the contributing guidelines
🆕 New Features
- b8833: ggml-webgpu: fix compiler warnings and refactor FlashAttention encoding (#21052)
- This PR doesn't add new functionality, but does the following:
- Removes compiler warnings due to usage of C++20 initializers and potentially unsafe casting, which cleans up the compilation and is a step towards enabling CI on the ggml NVIDIA machine
- Refactors flashattention encoding to avoid custom structs and be more in-line with encoding of the rest of the operations
- b8841: rpc : refactor the RPC transport (#21998)
- Move all transport related code into a separate file and use the socket_t interface to hide all transport implementation details.
- I have read and agree with the contributing guidelines
- AI usage disclosure: NO
- b8843: cmake: fix CMP0194 warning on Windows with MSVC (#21630)
- Fix CMP0194 CMake policy warning when building with MSVC on Windows and CMake 4.1+.
- The
ggmlsubproject enablesASMglobally viaproject("ggml" C CXX ASM)for Metal (macOS) and KleidiAI (ARM) backends. On Windows/MSVC, no assembler sources are used, but CMake 4.1+ warns becausecl.exeis not a valid ASM compiler. - This sets
CMP0194toNEWbefore theproject()call, guarded byif (POLICY CMP0194)for backward compatibility with older CMake versions. This follows the same pattern used inggml-vulkan/CMakeLists.txt(CMP0114, CMP0147).
- b8843: cmake: fix CMP0194 warning on Windows with MSVC (#21630)
- Fix CMP0194 CMake policy warning when building with MSVC on Windows and CMake 4.1+.
- The
ggmlsubproject enablesASMglobally viaproject("ggml" C CXX ASM)for Metal (macOS) and KleidiAI (ARM) backends. On Windows/MSVC, no assembler sources are used, but CMake 4.1+ warns becausecl.exeis not a valid ASM compiler. - This sets
CMP0194toNEWbefore theproject()call, guarded byif (POLICY CMP0194)for backward compatibility with older CMake versions. This follows the same pattern used inggml-vulkan/CMakeLists.txt(CMP0114, CMP0147).
- b8850: CUDA: refactor mma data loading for AMD (#22051)
- On master the AMD support in
mma.cuhis currently in a half-finished state. This PR refactors the code a bit and makes the usage more consistent, reducing the need for special handling infattn-mma-f16.cuhandmmq.cuh. Specifically: - More generic implementations for
load_ldmatrix. The current usage ofload_genericwas not quite correct since it assumed memory alignment which is only guaranteed forload_ldmatrix. - Added a generic implementation for
load_ldmatrix_trans. I experimented with transposing the data upon load in the FA kernel but I was unable to get good performance. However, the usage ofggml_cuda_memcpy_1is beneficial, including for Volta which also uses this path.
- On master the AMD support in
- b8853: [SYCL] Fix reorder MMVQ assert on unaligned vocab sizes (#22035)
- Fixes #22020. The four SYCL reorder mul_mat_vec_q dispatchers (Q4_0, Q8_0, Q4_K, Q6_K) asserted that block_num_y was a multiple of 16 subgroups. Any model whose vocab size is not divisible by 16 aborted on load when the output projection hit the assert. The original report was HY-MT 1.5 1.8B (vocab 120818) on an Arc B570.
- I replaced the hard assert with launch-grid padding. block_num_y now rounds up to a whole number of subgroup-sized workgroups, and the kernel's existing
if (row >= nrows) return;guard skips the padded rows. The row value is uniform across a subgroup (it does not depend onget_local_linear_id), sosycl::reduce_over_groupstays safe. - For aligned-vocab models,
ceil_div(nrows, 16) * 16 == nrows, so block_num_y is unchanged and the kernel launch is identical to the pre-patch code.
- b8853: [SYCL] Fix reorder MMVQ assert on unaligned vocab sizes (#22035)
- Fixes #22020. The four SYCL reorder mul_mat_vec_q dispatchers (Q4_0, Q8_0, Q4_K, Q6_K) asserted that block_num_y was a multiple of 16 subgroups. Any model whose vocab size is not divisible by 16 aborted on load when the output projection hit the assert. The original report was HY-MT 1.5 1.8B (vocab 120818) on an Arc B570.
- I replaced the hard assert with launch-grid padding. block_num_y now rounds up to a whole number of subgroup-sized workgroups, and the kernel's existing
if (row >= nrows) return;guard skips the padded rows. The row value is uniform across a subgroup (it does not depend onget_local_linear_id), sosycl::reduce_over_groupstays safe. - For aligned-vocab models,
ceil_div(nrows, 16) * 16 == nrows, so block_num_y is unchanged and the kernel launch is identical to the pre-patch code.
- b8858: ggml-cpu: Optimized x86 and generic cpu q1_0 dot (follow up) (#21636)
- Hello, I have prepared optimized implementation of cpu q1_0 dot product (mainly for Bonsai LLM models), this is a continuation of https://github.com/PrismML-Eng/llama.cpp/pull/10 PR, list of experiments conducted and some other benchmark results can be found there
- More efficient (less bit math and multiplications) generic implementation of dot product for (q1_0; q8_0)
- x86 SIMD specific implementations of dot product for (q1_0; q8_0) for most of the realistic x86_64 targets (from SSSE3 to AVX2)
- b8860: Tensor-parallel: Fix delayed AllReduce on Gemma-4 MoE (#22129)
- Skip forward past nodes that don't consume the current node, and allow a chain of MULs.
- When
down_exps_sis set, build_moe_ffn pulls the scale tensor in via reshape/repeat/get_rows. Topological sort places those betweenmul_mat_idand the MUL that consumes it, so the existing nodes[id+1] check never sees an ADD_ID or MUL and fails. - The scale MUL is followed by a second MUL; the old code only accepted one.
- b8863: ggml-cuda: flush legacy pool on OOM and retry (#22155)
- This adds a conservative fallback for the legacy CUDA/HIP pool allocator.
- On non-VMM setups, the legacy pool can end up holding cached free buffers that are individually too small for a new request, but still occupy enough VRAM to make the next allocation fail. In that case, this patch flushes the cached legacy-pool buffers and retries the allocation once before aborting.
- The normal hit path is unchanged. This is intended as a narrow mitigation for legacy-pool OOMs, not a broader allocator redesign. I validated the retry path locally with a synthetic OOM injection on a legacy-pool build.
🚀 Performance Improvements
- b8846: Reduce CPU overhead in meta backend: cache subgraph splits when cgraph is unchanged (#22041)
- Skip per-call subgraph construction in
ggml_backend_meta_graph_computewhen the sameggml_cgraphis used consecutively. - Assign
uidto every sub-graph so that CUDA's fast uid check path hits too. - Performance on 2x RTX 5090:
- Skip per-call subgraph construction in
- b8853: [SYCL] Add Q8_0 reorder optimization for Intel GPUs (~3x token generation speedup) (#21527)
- Extends the existing SYCL reorder optimization (currently Q4_0/Q4_K/Q6_K) to support Q8_0
- Q8_0 token generation on Intel Arc Pro B70 (Xe2/Battlemage): 4.88 t/s → 15.24 t/s (3.1x faster)
- Memory bandwidth utilization improves from 21% to 66% of theoretical maximum
- b8857: ggml-webgpu: updated matrix-vector multiplication (#21738)
- Improved performance of the matrix-vector multiplication kernel.
- I have read and agree with the contributing guidelines
🐛 Bug Fixes
- b8832: CUDA: use LRU based eviction for cuda graphs (#21611)
- Since introducing graphs per node to enable multiple splits to have cuda graphs in #18934, there are cases when the node pointers in ggml_cgraph keep changing and it leads to the map being unbounded leading to memory leaks (e.g #20315)
- This PR fixes the memory leaks
- b8836: ci : free disk space for rocm release (#22012)
- Fix
Releaseby freeing up disk space on rocm runner image. - Recent failures:
- https://github.com/ggml-org/llama.cpp/actions/runs/24517121219/job/71664214247
- Fix
- b8837: Fix meta backend tensor reads for split tensors during state serialization (#22063)
- This PR fixes a crash when saving recurrent state with tensor-split models using the meta backend. The previous code assumed that a tensor read would always map to a single segment, which is not always true when -sm tensor is enabled. The fix handles multi-segment tensor reads correctly instead of hitting the split_state.n_segments == 1 assertion. This should allow checkpoint/state serialization to work reliably with tensor-parallel CUDA setups. Fixes #22058
- b8849: common/autoparser : allow space after tool call (#22073)
- Allow whitespace after tool call for tagged outputs. Nemotron Nano 3 wants to emit
<tool_call>\n, but is then constrained to produce another tool call since the last tool call is not allowed to end in\n. - fixes #22043
- Allow whitespace after tool call for tagged outputs. Nemotron Nano 3 wants to emit
- b8855: fix: GLM-DSA crash in llama-tokenize when using vocab_only (#22102)
- When running llama-tokenize with GLM-DSA models, the process crashes with a fatal error in llama-hparams.cpp. This happens because vocab_only mode skips the full hparams loading, leaving n_layer and the MLA params uninitialized, but print_info still calls n_embd_head_k_mla() which internally falls back to n_embd_head_k(0) and hits the abort when n_layer is 0. Fixed by guarding the DeepSeek2/GLM-DSA/Mistral4 print block with consistent with how other non-vocab hparams are already handled in print_info. Fixes #22026
- b8859: TP: fix 0-sized tensor slices, AllReduce fallback (#21808)
- Partially fixes https://github.com/ggml-org/llama.cpp/issues/21765 .
- With Qwen 3.5
26b a4b27b there are only 2 KV heads so with 3+ GPUs some of them will get zero-sized slices of the data. This edge case is not being handled correctly on master. This PR makes it so that the corresponding nodes are disabled and the buffer for the AllReduce memset to 0 so that after the AllReduce all GPUs have the correct data. As of right now the buffer is zeroed out viaGGML_SCALEwith a factor of0.0ffor the AllReduce fallback implementation - this is not safe w.r.t. NaNs but it seems we currently lack the tooling to properly memset a tensor as part of aggml_cgraph. The same issue is present inllm_graph_context::build_rs. - Additionally, on master the synchronization of 3+ GPUs is not being handled correctly for the AllReduce fallback. The problem is that in those cases 2+ reduction steps are needed but the same buffer is used for each step so there are race conditions. This PR extends the number of buffers accordingly.
Additional Changes
10 minor improvements: 9 examples, 1 maintenance.
Full Commit Range
- b8831 to b8863 (32 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8831...b8863
2026-04-17: Update to llama.cpp b8828
Summary
Updated llama.cpp from b8816 to b8828, incorporating 11 upstream commits with new features and performance improvements.
Notable Changes
🆕 New Features
- b8816: ggml: add graph_reused (#21764)
- Add
reusedmember variable toggml_cgraphso backends can take advantage of the graph reuse functionality. Currently when graph_reuse in invoked, the CUDA backend still does the props change check to figure out if the graph has changed or not, where in factgraph_reuse(to my understanding) guarantees this to be true. This helps bypass a mildly expensive O(n) check.
- b8827: opencl: refactor q8_0 set_tensor and mul_mat host side dispatch for Adreno (#21938)
- The q8_0 set_tensor and mul_mat host side dispatch code for Adreno is a bit messy. This PR does some refactoring to make it cleaner and follow the same pattern as more recently added quantizations, e.g., q4_1, etc.
- b8828: model : Gemma4 model type detection (#22027)
- Adds model type detection logic for Gemma4 31B and 26BA4B.
- This change should be purely cosmetic, fixes "?B" model names shown by
llama-bench, etc.
🚀 Performance Improvements
- b8822: opencl: add q5_K gemm and gemv kernels for Adreno (#21595)
- Add Q5_K GEMM and GEMV kernels to the Adreno backend to improve performance for Q5_K quantized models.
- b8824: hexagon: optimize HMX matmul operations (#21071)
- Type Safety and Code Robustness:
- Replaced
intwithsize_tfor variables representing sizes, indices, and tile counts throughout the codebase to prevent potential integer overflows and improve correctness (e.g.,n_col_tiles,n_row_tiles, loop indices). [1] [2] [3] [4] [5] [6] [7] - Refactored tile and row/column stride calculations to use
size_tand clarified index calculations in matrix operations, which improves code clarity and reduces the risk of subtle bugs. [1] [2]
🐛 Bug Fixes
- b8823: model: using single llm_build per arch (#21970)
- Prepare for https://github.com/ggml-org/llama.cpp/issues/21966
- Using one single
llm_build_*class per arch will make the migration a bit easier. - Example before:
Additional Changes
5 minor improvements: 1 documentation, 4 examples.
- b8825: cmake: use glob to collect src/models sources (#22005)
- The goal is to make https://github.com/ggml-org/llama.cpp/pull/22004 a bit easier
- I have read and agree with the contributing guidelines
- b8821: server: use random media marker (#21962)
- Fix https://github.com/ggml-org/llama.cpp/issues/21955
- Generate a random media marker each time we launch the server. The string is random enough that collision is impossible to happen in practice
- How random? 32 characters, 0-9a-zA-Z, making it 62^32 combinations. And according to math stackexchange:
- b8821: server: tests: fetch random media marker via /apply-template (#21962) (#21980)
- Fix CI
- I have read and agree with the contributing guidelines
- b8821: server: use random media marker (#21962)
- Fix https://github.com/ggml-org/llama.cpp/issues/21955
- Generate a random media marker each time we launch the server. The string is random enough that collision is impossible to happen in practice
- How random? 32 characters, 0-9a-zA-Z, making it 62^32 combinations. And according to math stackexchange:
- b8826: cli : use get_media_marker (#22017)
- cont #21962
- Fixes #22010
llama-clistill usedmtmd_default_markerwhich returns the old static marker.
Full Commit Range
- b8816 to b8828 (11 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8816...b8828
2026-04-16: Update to llama.cpp b8809
Summary
Updated llama.cpp from b8804 to b8809, incorporating 7 upstream commits with new features and performance improvements.
Notable Changes
🆕 New Features
- b8806: cuda: Q1_0 initial backend (#21629)
- Follow up after merging of Q1_0 CPU PR. This PR adds the relevant CUDA backend.
- Seems also this works for AMD in some cases that was a nice surprise :)
- See a live demo of Bonsai 8B using these CUDA kernels and
llama-serveron hugging-face space prism-ml/Bonsai-demo, using a L40S GPU and getting decent speeds. Each request running on one gpu with a naive load balancer (just for demo purposes).
🚀 Performance Improvements
- b8807: vulkan: optimize im2col (#21713)
- The current layout is running very slow in some cases, to the point that drivers time out (#20249). I swapped the IM2COL work dimensions to enable coalesced writes. Cap the amount of workgroups spawned to avoid some bad cases.
-
-
- b8809: [SYCL] Add Q8_0 reorder optimization for Intel GPUs (~3x token generation speedup) (#21527)
- Extends the existing SYCL reorder optimization (currently Q4_0/Q4_K/Q6_K) to support Q8_0
- Q8_0 token generation on Intel Arc Pro B70 (Xe2/Battlemage): 4.88 t/s → 15.24 t/s (3.1x faster)
- Memory bandwidth utilization improves from 21% to 66% of theoretical maximum
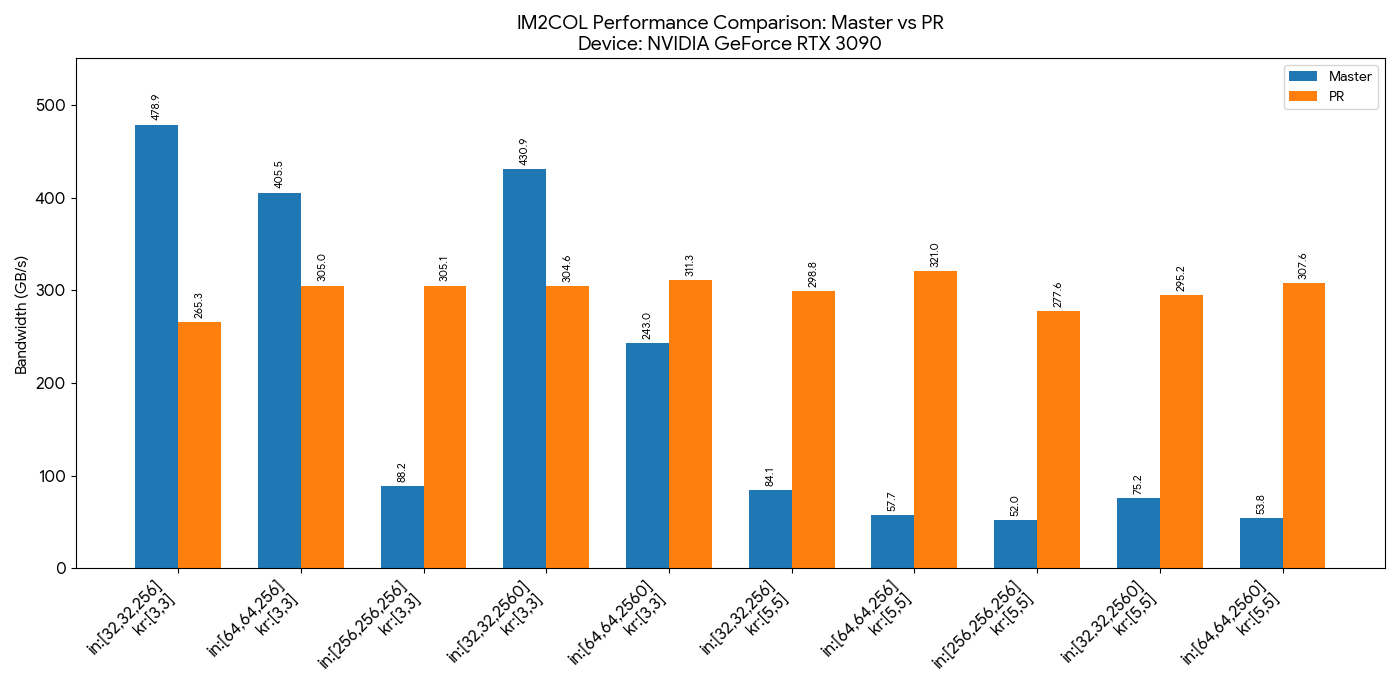
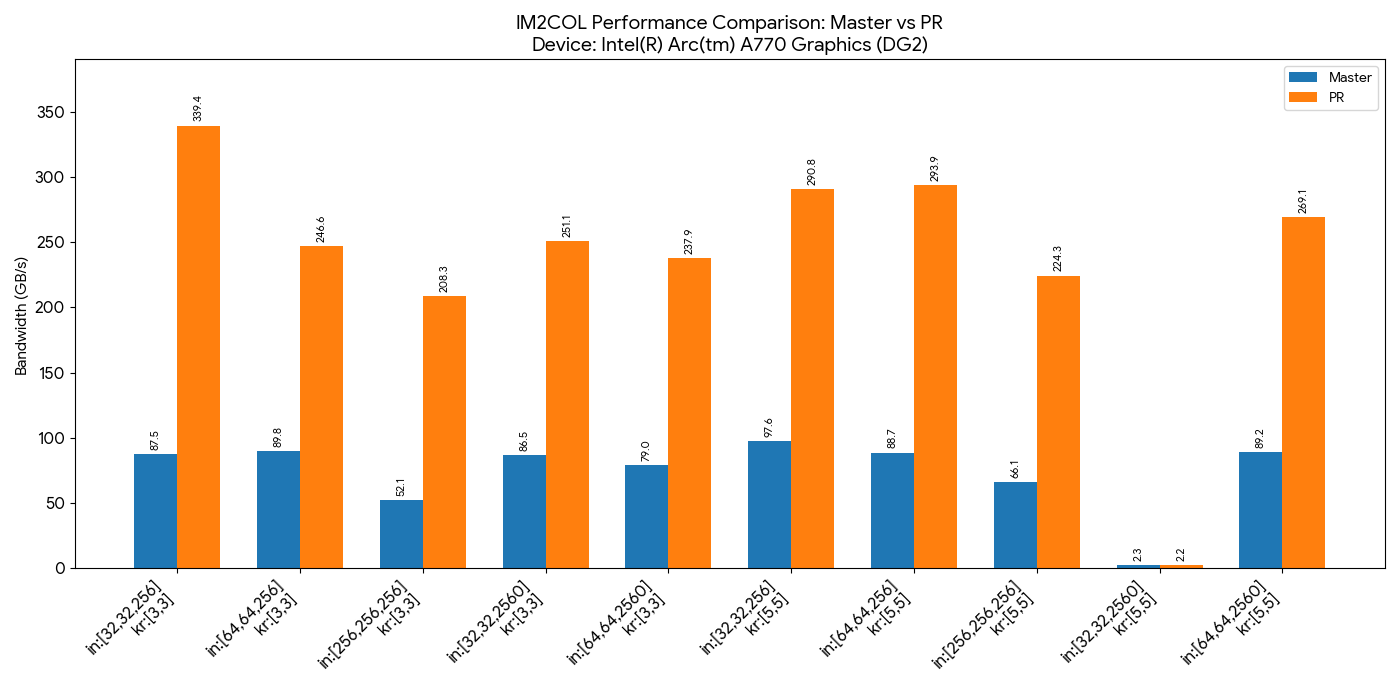
Additional Changes
4 minor improvements: 3 documentation, 1 examples.
- b8804: CUDA: require explicit opt-in for P2P access (#21910)
- In https://github.com/ggml-org/llama.cpp/pull/19378 I had naively enabled CUDA peer-to-peer access guarded only by
cudaDeviceCanAccessPeer. However, for some motherboards and BIOS settings this seems to cause crashes or corrupted outputs. I don't think we can feasibly check for this so our only option is to make peer access an explicit opt-in. - I have read and agree with the contributing guidelines
- In https://github.com/ggml-org/llama.cpp/pull/19378 I had naively enabled CUDA peer-to-peer access guarded only by
- b8809: [SYCL] Fix Q8_0 reorder: garbage on 2nd prompt + crash on full VRAM (#21638)
- Fixes two issues with the Q8_0 reorder optimization introduced in #21527.
- Bug 1: Garbage output from second prompt onward (#21589)
- The Q8_0 reorder optimization rearranges weight data during token generation (batch=1, via DMMV/MMVQ), but the general GEMM dequantization path used during prompt processing was missing a reorder-aware variant for Q8_0. After the first tg pass reordered the weights, subsequent prompt processing read them with the standard dequantizer, producing corrupt output.
- b8809: [SYCL] Fix Q8_0 reorder: garbage on 2nd prompt + crash on full VRAM (#21638)
- Fixes two issues with the Q8_0 reorder optimization introduced in #21527.
- Bug 1: Garbage output from second prompt onward (#21589)
- The Q8_0 reorder optimization rearranges weight data during token generation (batch=1, via DMMV/MMVQ), but the general GEMM dequantization path used during prompt processing was missing a reorder-aware variant for Q8_0. After the first tg pass reordered the weights, subsequent prompt processing read them with the standard dequantizer, producing corrupt output.
- b8808: server: use random media marker (#21962)
- Fix https://github.com/ggml-org/llama.cpp/issues/21955
- Generate a random media marker each time we launch the server. The string is random enough that collision is impossible to happen in practice
- How random? 32 characters, 0-9a-zA-Z, making it 62^32 combinations. And according to math stackexchange:
Full Commit Range
- b8804 to b8809 (7 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8804...b8809
2026-04-15: Update to llama.cpp b8799
Summary
Updated llama.cpp from b8794 to b8799, incorporating 6 upstream commits with new features.
Notable Changes
🆕 New Features
- b8795: metal : fix FA support logic (#21898)
- cont #20797
- Add proper logic for supported quantization types of the FA operator.
- Fix https://github.com/ggml-org/llama.cpp/actions/runs/24400236380/job/71268552842#step:3:27636
- b8797: hexagon: optimization for HMX mat_mul (#21554)
- This PR introduces two additional optimizations for the Hexagon HMX backend:
-
- Enable asynchronous HMX execution
- HMX computations are now executed asynchronously, allowing them to overlap with HVX dequantization and DMA stages within the pipeline. Previously, synchronous HMX calls blocked the main thread and limited parallelism.
🐛 Bug Fixes
- b8796: ggml: remove ggml-ext.h (#21869)
- Fix https://github.com/ggml-org/llama.cpp/issues/21867 Fix https://github.com/ggml-org/llama.cpp/issues/21860
- Not quite sure if the ggml-ext.h is intended to be a public header, but I believe it should be (so that the symbols can be exposed in the dynamic library)
- b8799: autoparser: support case of JSON_NATIVE with per-call markers (#21892)
- The JSON_NATIVE case for the autoparser wasn't handling cases where the separate calls were not aggregated in a JSON array, but instead each had their own set of opening and closing markers.
- Automatically resolves autoparser detection problems with Reka-Edge, also fixes old Hermes templates.
Additional Changes
2 minor improvements: 2 examples.
- b8794: mtmd: add mtmd_image_tokens_get_decoder_pos() API (#21851)
- Add a new mtmd API:
mtmd_image_tokens_get_decoder_pos() - Deprecate
mtmd_image_tokens_get_nx/ny() - Target support https://github.com/ggml-org/llama.cpp/pull/21045
- Add a new mtmd API:
- b8798: llama-diffusion-cli: read n_ctx back after making llama_context so the cli doesn't reject all inp... (#21939)
- Read back via
llama_n_ctxthe context window size thatllama_init_from_modeldetermines, as mentioned in comments forllama_n_ctx. The prevents the cli from rejecting all inputs because it thinks the context window is 0 length. - I ran into the issue described in https://github.com/ggml-org/llama.cpp/issues/20407 myself and the fix seemed straightforward, so I did it. @am17an - sorry for the random PR, it's very minor.
- Tested on a mac like so:
- Read back via
Full Commit Range
- b8794 to b8799 (6 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8794...b8799
2026-04-14: Update to llama.cpp b8784
Summary
Updated llama.cpp from b8763 to b8784, incorporating 14 upstream commits with new features.
Notable Changes
🆕 New Features
- b8763: CUDA: skip compilation of superfluous FA kernels (#21768)
- Fixup to https://github.com/ggml-org/llama.cpp/pull/20998 .
- The compilation of FA kernels with head size 512 is supposed to be skipped for GQA ratios of 1 and 2 because those are never used. However, because the invocation of the corresponding template specializations is not guarded with an
if constexprthey are being compiled regardless; this PR adds them. On my server with a 64 core EPYC CPU the total compilation time of the full project without CCache goes down from 330s to 300s.
- b8771: sycl: disable Q1_0 in backend and cleanup unused variables (#21807)
- test-backend-ops was crashing because backend doesn't support Q1_0 type yet. Disable it until we add support.
- Also, cleaned up unused variables.
- b8778: common : add download cancellation and temp file cleanup (#21813)
- Add download cancellation and temp file cleanup
- b8779: vulkan: Flash Attention DP4A shader for quantized KV cache (#20797)
- This PR adds DP4A (integer dot product) support to the scalar FA shader, enabled if the GPU supports DP4A. It's only used for quantized KV cache (both q8_0 or both q4_0), and not for coopmat FA shaders.
- I also unified the GLSL vector type name preprocessor macros because we had swapped from FLOAT_TYPE_VECx to FLOAT_TYPEVx in Flash Attention, and the old naming was getting in the way of code reuse here.
- Performance graphs for q8_0 kv cache:
- b8781: chat: dedicated DeepSeek v3.2 parser + "official" template (#21785)
- Adds an "official" (tested with the official Python reference) DeepSeek v3.2 template + parser with tests.
- The parser will only work with this template, so please use them together.
🐛 Bug Fixes
- b8770: fix: crash when sending image under 2x2 pixels (#21711)
- GGML_ASSERT(src.nx >= 2 && src.ny >= 2); will crash llama.cpp when processing very small images. Fix was implemented to handle 1x1 inputs safely by updating the interpolation math and clamping pixel lookups, preventing out-of-bounds memory errors while keeping the pipeline stable.
- Code was succesfully tested in production, llama-server is running with no crashes.
- Fixes https://github.com/ggml-org/llama.cpp/issues/21420
- b8772: ggml-webgpu: Fix compilation error in
ggml_backend_webgpu_debugin debug mode (#21798)- This PR fixes a compilation error that occurs when building in debug mode (related to https://github.com/ggml-org/llama.cpp/pull/21521).
-
</code></pre> </li> <li>llama.cpp/ggml/src/ggml-webgpu/ggml-webgpu.cpp:537:9: error: invalid argument</li> </ul> </li> <li><strong>b8783</strong>: common/gemma4 : handle parsing edge cases (<a href="https://github.com/ggml-org/llama.cpp/pull/21760">#21760</a>) <ul> <li>Fix a few edge cases for Gemma 4 26B A4B. I don't see these artifacts from the 31B variant.</li> <li>If the model generates content + tool call, the template will incorrectly format the prompt without the generation prompt (<code><|turn>model\n</code>):</li> <li> <pre><code>
Additional Changes
6 minor improvements: 1 documentation, 4 examples, 1 maintenance.
Full Commit Range
- b8763 to b8784 (14 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8763...b8784
2026-04-12: Update to llama.cpp b8763
Summary
Updated llama.cpp from b8762 to b8763, incorporating 2 upstream commits with new features.
Notable Changes
🆕 New Features
- b8763: CUDA: skip compilation of superfluous FA kernels (#21768)
- Fixup to https://github.com/ggml-org/llama.cpp/pull/20998 .
- The compilation of FA kernels with head size 512 is supposed to be skipped for GQA ratios of 1 and 2 because those are never used. However, because the invocation of the corresponding template specializations is not guarded with an
if constexprthey are being compiled regardless; this PR adds them. On my server with a 64 core EPYC CPU the total compilation time of the full project without CCache goes down from 330s to 300s.
Additional Changes
1 minor improvements: 1 examples.
- b8762: mtmd : add MERaLiON-2 multimodal audio support (#21756)
- This adds support for MERaLiON-2 to mtmd. MERaLiON-2 is a speech-text model developed by I2R, A*STAR Singapore, available in 3B and 10B variants. It uses a Whisper large-v2 encoder paired with a Gemma2 decoder.
- New projector type:
PROJECTOR_TYPE_MERALION - The audio adaptor stacks 15 encoder frames per output token, then runs a layer norm followed by a 4-layer MLP: compression Linear+SiLU, a GLU block (gate and pool projections), and a final out_proj to match the decoder embedding dim. The implementation reuses the existing
linear_{bid}/mm_norm_pretensor naming so the change to tensor_mapping.py is just a comment update.
Full Commit Range
- b8762 to b8763 (2 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8762...b8763
2026-04-11: Update to llama.cpp b8762
Summary
Updated llama.cpp from b8746 to b8762, incorporating 17 upstream commits with new features and performance improvements.
Notable Changes
🆕 New Features
- b8750: ggml-webgpu: support non-square subgroup matrix configs for Intel GPUs (#21669)
- Enable WebGPU subgroup matrix support for Intel GPUs (Xe2/Battlemage).
- Intel GPUs report non-square subgroup matrix configurations (e.g. M=8, N=16, K=16) via Dawn's
ChromiumExperimentalSubgroupMatrixfeature. The existing filter only accepted square configs (M==N==K), rejecting Intel GPUs entirely despite full hardware and driver support. - Changes:
- b8753: common : better align to the updated official gemma4 template (#21704)
- Google has pushed an update to their chat template: https://huggingface.co/google/gemma-4-31B-it/commit/e51e7dcdb6febd74c182fe0cb41c236363ae2ac5
- This update includes everything within our internal workarounds, as well as the custom modifications in the
models/templates/google-gemma-31B-it-interleaved.jinjatemplate. Add support by detecting it and forgoing the workarounds. Additionally, emit a warning message so users are aware there is an update. - The existing template within GGUFs, as well as the custom interleaved template, will continue to function. I even added some of the formatting changes to the bos and think tokens.
- b8759: cpu : fix a few instances of missing GGML_TYPE_Q1_0 cases (#21716)
- Add
case GGML_TYPE_Q1_0:where it was missing. - Fixes:
- https://github.com/ggml-org/llama.cpp/actions/runs/24229986393/job/70739279184
- Add
- b8761: opencl: add basic support for q5_k (#21593)
- This PR adds basic support for Q5_K quantization on GPU. With this change, Q5_K operations remain on the GPU instead of falling back to the CPU, which improves performance for models using Q5_K quantization.
- This is a general implementation. A follow‑up PR will introduce a more optimized, Adreno‑specific implementation.
🚀 Performance Improvements
- b8749: ggml-webgpu: address quantization precision and backend lifecycle managment (#21521)
- This PR improves the stability and performance of the WebGPU backend, specifically focusing on the quantization numeric precision and backend lifecycle management.
- Quantization Precision:
🐛 Bug Fixes
- b8746: common: mark --split-mode tensor as experimental (#21684)
- Fixup to https://github.com/ggml-org/llama.cpp/pull/19378 . Since there are probably still a lot of cases where
--split-mode tensordoesn't yet work correctly I marked the PR as experimental. But I forgot to also do this in the--help. - I have read and agree with the contributing guidelines
- Fixup to https://github.com/ggml-org/llama.cpp/pull/19378 . Since there are probably still a lot of cases where
- b8747: common : fix when loading a cached HF models with unavailable API (#21670)
- Fix when loading a cached HF models with unavailable API
- b8749: ggml webgpu: Move to no timeout for WaitAny in graph submission to avoid deadlocks (#20618)
- Another approach to see if this avoids deadlocks in the llvm-pipe Vulkan backend. After some debugging on the Github CI I've seen cases where it seems to get stuck within the
WaitAnycall itself, even after the timeout nanoseconds have passed, leading me to believe there is a bug within the interface between Dawn and llvm-pipe. Setting timeout to 0 from the WebGPU side creates a busy-wait loop on the ggml side, but hopefully avoids deadlocking in most scenarios, and in practice the busy-wait loop does not occur that often in my tests.
- Another approach to see if this avoids deadlocks in the llvm-pipe Vulkan backend. After some debugging on the Github CI I've seen cases where it seems to get stuck within the
- b8756: fix: Fix broken structured output when using $refs in json_schema (#21699)
- Fixes #20178
- $refs in json schema were resolved only for tool calls, now they're also resolved when using response_format
- b8757: CUDA: also store node->src ne/nb for graph equality (#21736)
- Fixes #21726. Seems like this comment is not correct when using
--nkvo, the extra srcs ne/nb can also change while keeping thedatapointer same, probably because of resizing the buffer every 256 tokens.
- b8760: TP: fix Qwen 3 Next data split (#21732)
- Fixes https://github.com/ggml-org/llama.cpp/issues/21703 .
- The problem is that I had incorrectly assumed that Qwen 3 Next and Qwen 3.5 use the same broadcasting pattern for K across V. So for Qwen 3 Next 50% of the time the wrong K and V heads are being combined. This is not immediately obvious as the generated text can still look reasonable at first glance. However, it can be clearly detected by looking at PPL. The Q3_K_M quantization goes from a PPL of 7.48 to 4.32 on the first 512tokens of Wikitext-2.
Additional Changes
6 minor improvements: 2 documentation, 3 examples, 1 maintenance.
Full Commit Range
- b8746 to b8762 (17 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8746...b8762
2026-04-10: Update to llama.cpp b8746
Summary
Updated llama.cpp from b8734 to b8746, incorporating 9 upstream commits with new features.
Notable Changes
🆕 New Features
- b8737: ggml : check return value of NVIDIA CUB calls used in argsort and top-k implementation (#21676)
- This PR adds missing CUDA error checks when calling NVIDIA CUB methods:
DeviceRadixSort::SortPairsDeviceRadixSort::SortPairsDescending
- b8739: HIP: add CDNA4 (gfx950) architecture support for MI350X/MI355X (#21570)
- Adds gfx950 (MI350X/MI355X, CDNA4) support. These are AMD's latest datacenter GPUs.
- gfx950 shares most MFMA instructions with gfx942 (CDNA3), except
mfma_f32_16x16x8_xf32which isn't available on gfx950 — routed to the f32 fallback path instead. - Changes:
- b8740: CUDA: fuse muls (#21665)
- Add fusion for mul operator, same as adds. This is useful for gemma4 models which have a down expert scale which can be fused with mul, this saves a full roundtrip of
used_experts x expert_dimsin f32 from global memory, so it seems to help PP more than TG surprisingly. Additionally, we can fuse mul-mat + (epilogue), which would benefit all MoE models, however that is not a simple change since we have account for all the different mul-mat-id paths we take. - on a 4090
- b8741: common : add fluidity to the progress bar (#21671)
- Add some fluidity to the progress bar
- b8742: vulkan: Support Q1_0 (#21539)
- Add Q1_0 support to ggml-vulkan. Supports get_rows, set_rows, mul_mat(id). Does not support the q8_1 dp4 path (though this is probably worth adding in a followon), since we get the most benefit with smaller quants.
- None.
- b8744: common : enable reasoning budget sampler for gemma4 (#21697)
- As #21487 also reports, gemma4 thinking budget doesn't work. I noticed that
common_chat_params_init_gemma4()setssupports_thinking = truebut never populatesthinking_start_tag/thinking_end_tag. The budget sampler inserver-common.cppworks conditional onthinking_end_tagbeing non-empty, so it skips gemma4 entirely. - So I added the missing tags. The main fix is just two lines (chat.cpp:1087-1088). The rest of the diff is about making budget=0 work cleanly: while testing for my personal use (see the details of the local testing environment below), I found that budget=0 causes a PEG parse error because the sampler forces the end tag before the model emits a newline after "thought". Even though
--reasoning offalready handles the no-thinking case, I didn't want to introduce a parse error at that edge case. I made the newline optional in the parser, and added a test case for it. - Fixes #21487
- As #21487 also reports, gemma4 thinking budget doesn't work. I noticed that
🐛 Bug Fixes
- b8734: common : fix ambiguous grammar rule in gemma4 (#21661)
- An ambiguous grammar caused issues when
parallel_tool_calls = falseand the model wants to generate multiple tool calls. - ref: https://github.com/ggml-org/llama.cpp/issues/21375#issuecomment-4209762714
- An ambiguous grammar caused issues when
- b8746: common: mark --split-mode tensor as experimental (#21684)
- Fixup to https://github.com/ggml-org/llama.cpp/pull/19378 . Since there are probably still a lot of cases where
--split-mode tensordoesn't yet work correctly I marked the PR as experimental. But I forgot to also do this in the--help. - I have read and agree with the contributing guidelines
- Fixup to https://github.com/ggml-org/llama.cpp/pull/19378 . Since there are probably still a lot of cases where
Additional Changes
1 minor improvements: 1 examples.
- b8738: ggml: backend-agnostic tensor parallelism (experimental) (#19378)
- This PR adds initial support for tensor parallelism, enabled via specifying
--split-mode tensor. This should be considered as an experimental feature that is not yet production ready. In principle the implementation is backend-agnostic, in practice as of right now only the CUDA backend has received the necessary extensions and performance optimizations to make the performance better than--split-mode layer(in some cases). - The preexisting
--split-mode rowcould already parallelize some matrix multiplications in the CUDA backend but this required a synchronization after every single operation. As a consequence the overhead is so large that it is only really worthwhile for old and slow GPUs like P40s where adding a bit of latency between operations makes relatively little difference to the overall runtime. The new implementation works by adding a new "meta" backend that internally wraps multiple conventional ggml backends. When given a compute graph the meta backend then automatically infers how the data is split based on the ggml compute graph and only schedules a synchronization at the necessary points. And the external interface for a meta backend is the same as for any other ggml backend. So in practice the meta backend allows ggml to use multiple GPUs in the same way as a single GPU. Importantly all of this is done at the ggml backend level and there are no hard dependencies for any extensions beyond what already exists on master (but without extensions the performance may be so bad that there is no point). - What currently works:
- This PR adds initial support for tensor parallelism, enabled via specifying
Full Commit Range
- b8734 to b8746 (9 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8734...b8746
2026-04-09: Update to llama.cpp b8722
Summary
Updated llama.cpp from b8672 to b8722, incorporating 37 upstream commits with breaking changes, new features, and performance improvements.
Notable Changes
⚠️ Breaking Changes
- b8692: ggml : deprecate GGML_OP_ADD1 (#21363)
- The
GGML_OP_ADD1was added back in #1360. However, the op is a subclass of the genericGGML_OP_ADDand in favor of simplicity, it's better to remove it. Deprecating for now. - I have read and agree with the contributing guidelines
- The
- b8694: llama: remove per-arch tensor name lists (#21531)
- In https://github.com/ggml-org/llama.cpp/pull/20503 I added a warning that is printed when a tensor name is not properly formatted, which can happen many times suring quantization. However, this only happens when there is an attempt to format a tensor name with a layer id and that tensor is not listed in
llm_get_tensor_namesfor that specific model architecture. If a tensor name is not listed for a given architecture the placeholders for e.g. the layer id are not replaced, resulting in broken tensor names. I don't think this function is providing us with any actual utility but it is causing an additional maintenance burden for model architectures. This PR makes it so that the explicit per-architecture tensor name lists are removed and that instead a tensor name is always formatted with the provided parameters. - I have read and agree with the contributing guidelines
- In https://github.com/ggml-org/llama.cpp/pull/20503 I added a warning that is printed when a tensor name is not properly formatted, which can happen many times suring quantization. However, this only happens when there is an attempt to format a tensor name with a layer id and that tensor is not listed in
- b8708: tests : remove obsolete .mjs script (#21615)
- cont #21606
- This tests was referencing a schema from the recently removed legacy files. Remove the tests to avoid CI failures:
- https://github.com/ggml-org/llama.cpp/actions/runs/24128439949/job/70398782893?pr=21612#step:6:9164
- b8717: vocab : remove eog token if gemma4 (#21492)
- The Gemma 4 tokenizer contains a token for
</s>, which conflicts with the EOG token for paddleocr. This PR removes it from Gemma 4's EOG token list. - Fixes #21471
- The Gemma 4 tokenizer contains a token for
🆕 New Features
- b8678: vocab : add byte token handling to BPE detokenizer for Gemma4 (#21488)
- Looks like the change in #21343 changed the detokenizer path which wasn't handling unicode properly.
- Fixes #21423
- b8681: console: fix stripping of \n in multiline input (#21485)
- The
\ncharacter was being stripped off the end of thelinebefore adding it to the history which resulted in thebufferbeing appended withlinenot containing the newline character at the end. Hence, the model was receiving the input as a single line even with--multiline-inputenabled. - This patch appends the newline character to
lineafter it has been added to the history. - Closes #21464
- The
- b8690: vulkan: add FA dequant for q4_1, q5_0, q5_1, iq4_nl (#21029)
- I noticed that q4_1, q5_0, q5_1, and iq4_nl KV cache types run about 3x slower than q4_0/q8_0 on my R9700 (Vulkan, gfx1201). Dug into it and found three things blocking them from the flash attention path:
-
- No
dequantize4()inflash_attn_base.glslfor these types
- No
-
- Shader generator wasn't compiling FA variants for them
- b8697: CUDA: check for buffer overlap before fusing (#21566)
- When doing GEMV fusion for gate + up + glu, the src buffer can overlap with the dst buffer. This PR adds a check so that fusion can be skipped in case this happens. Saw this happening in Gemma4 f16 models, but it can happen to other models as well.
- b8699: kv-cache : support attention rotation for heterogeneous iSWA (#21513)
- cont #21038
- Support iSWA models with different head sizes in the SWA vs non-SWA layers (such as Gemma 4).
- Sanity check PPL of https://huggingface.co/google/gemma-4-26B-A4B,
Q8_0, 512 chunks:
- b8703: kleidiai: provide KleidiAI-Enabled Arm Release Artifact (#21259)
- This PR adds a KleidiAI-enabled MacOS Arm release artifact definition to the release.yml workflow.
- The PR updates the existing MacOS jobs in the release.yml file in an attempt for the KleidiAI-enabled addition to be concise and in line with the rest of the file. This is achieved using a matrix strategy, similarly to other jobs in this file. Using the matrix strategy allows adding a KleidiAI-enabled artifact job without a large amount of duplicate code.
- b8709: autoparser: fix MiniMax handling (#21573)
- There was a problem handling the generation prompt from MiniMax because it shares a trailing newline with the non-generation-prompt line.
- Added extra tests for Minimax.
- b8712: metal: Q1_0 backend (#21528)
- Follow up after merging of Q1_0 CPU PR. This PR adds the relevant Metal backend.
- These are to speed up familly of Bonsai 1-bit models on the Mac:
- prism-ml/Bonsai-8B-gguf
🚀 Performance Improvements
- b8680: [CUDA ] Write an optimized flash_attn_stream_k_fixup kernel (#21159)
- This is a follow-up to PR: https://github.com/ggml-org/llama.cpp/pull/21086
- The observation was that
flash_attn_stream_k_fixuptakes significant time ifnblocks_stream_kis significantly larger thanntiles_dst. - The reason for this was that
flash_attn_stream_k_fixuplaunches too many blocks with either redundant or no work for many of the blocks.
- b8685: [SYCL] Add Q8_0 reorder optimization for Intel GPUs (~3x token generation speedup) (#21527)
- Extends the existing SYCL reorder optimization (currently Q4_0/Q4_K/Q6_K) to support Q8_0
- Q8_0 token generation on Intel Arc Pro B70 (Xe2/Battlemage): 4.88 t/s → 15.24 t/s (3.1x faster)
- Memory bandwidth utilization improves from 21% to 66% of theoretical maximum
- b8701: ggml-cuda: ds_read_b128 for q4_0 and q4_1 mmq kernels (#21168)
- This pr is a LDS load optimization in mmq kernels for q4_0 and q4_1.
- The activations loading loop has been restructured so that 8 * ds_read_b32 scalar operations are replaced by 2*vectorized ds_read_b128 by the HIP compiler. It ends up being about +10% in pp with the vega gpu, and a small speedup on the 6800xt.
- This modification is guarded by GGML_USE_HIP flag. Since the code is duplicated in vec_dot_q4_0_q8_1_dp4a and vec_dot_q4_1_q8_1_dp4a kernels, it could be refactored in a single function that select the loading method.
- b8702: CUDA: make cuda graphs props check faster (#21472)
- The current graph properties matching check takes a long time per token, and on models with a lot of nodes like Qwen3.5 it takes on average ~500us per token. This is probably due to the use of
std::unordered_setalthough I didn't check.This PR adds a fast hash check (FNV-1a) which should behave like the props check, it is used to short-circuit the expensive check when the props don't change for 2 consecutive runs (using similar logic as #19754) - This PR speeds up the check by removing STL containers
- On a 5090 with full offload
- The current graph properties matching check takes a long time per token, and on models with a lot of nodes like Qwen3.5 it takes on average ~500us per token. This is probably due to the use of
🐛 Bug Fixes
- b8688: ggml-cuda : fix CDNA2 compute capability constant for gfx90a (MI210) (#21519)
GGML_CUDA_CC_CDNA2was defined asGGML_CUDA_CC_OFFSET_AMD + 0x910, but0x910does not correspond to any real AMD GPU target — gfx90a (CDNA2) is0x90a. The typo (910vs90a) placed the CDNA2 threshold above the actual gfx90a compute capability, causing MI210/MI250/MI250X to be misidentified as CDNA1 byGGML_CUDA_CC_IS_CDNA2().- Fixed by setting the constant to
0x90ato match the actual gfx90a ISA. - I have read and agree with the contributing guidelines
- b8691: ggml: Vulkan build -- output error string for errno on fork failure (#20868) (#20904)
- This is a one-line change to
ggml/src/ggml-vulkan/vulkan-shaders/vulkan-shaders-gen.cpp: -
- if (pid < 0) {
- This is a one-line change to
- b8698: ggml-webgpu: parameterize submission size and add iOS specific limits (#21533)
- Working on stability of the WebGPU backend on different devices/browsers, I noticed that on iOS 26, the WebGPU backend tends to crash unless the number of operations + submitted command buffers is pretty severely throttled. This PR adds support for parameterizing the number of operations per batch and inflight submissions, which is limited on iOS.
- Detecting the platform/device being run on is not the easiest from WebGPU, since browsers don't give out this information easily (for example on an iPhone querying WebGPU information like device name/description just returns "apple"). So this PR adds some JavaScript directly into the WebGPU backend that queries the User-Agent string in the browser to determine if it's running on iOS.
- I also plan on submitting an issue/bug report with WebKit to understand if the limitation on inflight command buffers is expected, or if it's a bug/something I'm doing wrong in the WebGPU backend here.
- b8713: Query for adapter support when registering WebGPU backend (#21579)
- Investigating some failures in wllama CI, I realized that if the WebGPU backend is included but is running in a browser that does not support WebGPU, the call to
ggml_backend_webgpu_reg_get_devicewill assert and cause crashes. To avoid this, I added a probe for a WebGPU adapter inggml_backend_webgpu_reg, and only set thedevice_countto 1 if it succeeds. - I have read and agree with the contributing guidelines
- Investigating some failures in wllama CI, I realized that if the WebGPU backend is included but is running in a browser that does not support WebGPU, the call to
- b8719: fix: free ctx_copy in ggml_opt_free to plug per-training-session leak (#21592)
- ggml_opt_alloc populates opt_ctx->ctx_copy via a free+init pair every time the allocated graph shape changes. The last ctx_copy from the final ggml_opt_alloc call survives until ggml_opt_free is invoked, but ggml_opt_free was only freeing ctx_static and ctx_cpu, never ctx_copy. Each opt_ctx lifetime therefore leaks the final per-batch context — ~900 KB for a typical GNN training session in sindarin-pkg-tensor, surfaced via AddressSanitizer.
- ctx_copy is nullptr-initialized and ggml_free() handles NULL safely, so the new release is guard-free.
- This is actively being used to develop: https://github.com/SindarinSDK/sindarin-pkg-tensor
- b8720: CUDA: also store
node->src->dataptrs for equality check (#21635)- Fix #21622
- b8722: vulkan: unify type macros to use Vx instead of _VECx (#21605)
- While working on #20797 I ran into the issue that some shaders use TYPE_VEC4 and some use TYPEV4 for type macros, which makes using code from both hard. This PR changes them to the shorter version.
- I have read and agree with the contributing guidelines
- AI usage disclosure: NO
Additional Changes
14 minor improvements: 1 documentation, 9 examples, 4 maintenance.
Full Commit Range
- b8672 to b8722 (37 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8672...b8722
2026-04-06: Update to llama.cpp b8672
Summary
Updated llama.cpp from b8662 to b8672, incorporating 8 upstream commits with new features.
Notable Changes
🆕 New Features
- b8665: common : add gemma 4 specialized parser (#21418)
- Specialized Gemma 4 parser with various fixes.
- There's a lot here, so I'll do my best to summarize.
- Removed Gemma 4 parsing from the autoparser and composed a dedicated parser. The model is sufficiently different to warrant specialized parsing.
🐛 Bug Fixes
- b8662: llama-model: read final_logit_softcapping for Gemma 4 (#21390)
- The
LLM_ARCH_GEMMA4block inllama-model.cppwas never readingfinal_logit_softcappingfrom the GGUF, so the value was always stuck at the hardcoded default of30.0f. This meant editing the GGUF key or using--override-kv gemma4.final_logit_softcapping=float:Xhad no effect on inference. - Adding the missing
ml.get_keycall (optional, so older GGUFs without the key fall back gracefully to30.0f) is all that's needed, the softcapping logic ingemma4-iswa.cppis already correct. - Fix for the issue #21388.
- The
- b8663: common : respect specified tag, only fallback when tag is empty (#21413)
- Respect specified tag, only fallback when tag is empty
- Should fix https://github.com/ggml-org/llama.cpp/issues/21364#issuecomment-4184994923
- With this commit:
Additional Changes
5 minor improvements: 4 examples, 1 maintenance.
- b8664: Fix undefined timing measurement errors in server context (#21201)
- Fix UB issue reported by Valgrind involving timing measurements for prompt processing and eval
- I have read and agree with the contributing guidelines
- AI usage disclosure: I threw an AI at this, but the fix is simple enough that there's no real downside risk (independently verified this solves the issue)
- b8668: server : fix logging of build + system info (#21460)
- This PR changes the logging that occurs at startup of llama-server. Currently, it is redundant (including CPU information twice) and it is missing the build + commit info (helpful for debugging).
-
- b8670: model : add HunyuanOCR support (#21395)
- Add support for tencent/HunyuanOCR vision-language model.
- Converter: handle text + mmproj conversion, fix invalid pad_token_id: -1, read EOT from generation_config.json, support xdrope
- RoPE type
- b8671: model-loader : fix GGUF bool array conversion (#21428)
- GGUF stores bool arrays as int8_t, but the model loader was reading raw array data as const bool *
- This changes the bool-array path in src/llama-model-loader.cpp to read const int8_t * and normalize entries with x != 0 before converting to the destination type.
- This matches the GGUF definition in 'ggml/include/gguf.h': All bool values are stored as int8_t
- b8672: Hexagon: Slight optimization for argosrt output init (#21463)
- Hexagon: Slight optimization for argosrt output init

Full Commit Range
- b8662 to b8672 (8 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8662...b8672
2026-04-04: Update to llama.cpp b8662
Summary
Updated llama.cpp from b8661 to b8662, incorporating 2 upstream commits with new features.
Notable Changes
🆕 New Features
- b8661: llama: add custom newline split for Gemma 4 (#21406)
- Fixes #21401
std::regexsuffers a stack overflow while processing a very large prompt with newlines, this PR adds a custom splitting logic for newlines for gemma 4.
🐛 Bug Fixes
- b8662: llama-model: read final_logit_softcapping for Gemma 4 (#21390)
- The
LLM_ARCH_GEMMA4block inllama-model.cppwas never readingfinal_logit_softcappingfrom the GGUF, so the value was always stuck at the hardcoded default of30.0f. This meant editing the GGUF key or using--override-kv gemma4.final_logit_softcapping=float:Xhad no effect on inference. - Adding the missing
ml.get_keycall (optional, so older GGUFs without the key fall back gracefully to30.0f) is all that's needed, the softcapping logic ingemma4-iswa.cppis already correct. - Fix for the issue #21388.
- The
Full Commit Range
- b8661 to b8662 (2 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8661...b8662
2026-04-04: Update to llama.cpp b8660
Summary
Updated llama.cpp from b8653 to b8660, incorporating 5 upstream commits with breaking changes and performance improvements.
Notable Changes
⚠️ Breaking Changes
- b8656: common : fix tool call type detection for nullable and enum schemas (#21327)
- Fixes #21316
- The Gemma4 dict parser and the tagged parser both only check
type_v.is_string()when figuring out if a tool argument is a string. This breaks for schemas that use nullable types like"type": ["string", "null"]or enum fields without an explicit"type"key, both of which are pretty common in OpenAPI/Home Assistant setups. - When the type isn't recognized as
"string", the parser falls through to the raw-value path and captures<|"|>delimiter tokens as literal text, which is how you end up with output like"domain": "[<|\"|>light<|\"|>]"instead of"domain": "light".
🚀 Performance Improvements
- b8660: ggml-webgpu: move from parameter buffer pool to single buffer with offsets (#21278)
- Continuing some work to simplify and make the WebGPU backend scheduling more asynchronous, I realized that we don't actually need a pool of parameter buffers. Instead we can use a single buffer with multiple offset slots, and cycle through them on a batch of submissions. This PR replaces a pool with a
webgpu_param_arena, and moves all operations to use it. Memset is special because it lives in the global context, but because it is now asynchronous it uses a single parameter buffer. - In this PR I also updated GPU submissions to be batched into a single
CommandBuffer, instead of having aCommandBufferper operation. This increases efficiency/speed a bit on larger systems and should help with stability on mobile devices.
- Continuing some work to simplify and make the WebGPU backend scheduling more asynchronous, I realized that we don't actually need a pool of parameter buffers. Instead we can use a single buffer with multiple offset slots, and cycle through them on a batch of submissions. This PR replaces a pool with a
Additional Changes
3 minor improvements: 2 examples, 1 maintenance.
- b8657: Fix call ID detection (Mistral parser mostly) + atomicity for tag-json parsers (#21230)
- Fix autoparser handling of call ID section detection
- Should fix handling of old Mistral templates
- b8658: server: save and clear idle slots on new task (
--clear-idle) (#20993)- In unified KV cache mode, idle slots' KV cells stay in the
[0, n_kv)range - and inflate attention cost for all active sequences (even though they're masked).
--clear-idlesaves idle slots to--cache-ramand clears them from VRAM, reducingn_kvto only active tokens.
- In unified KV cache mode, idle slots' KV cells stay in the
- b8653: jinja : coerce input for string-specific filters (#21370)
- Coerce input for string-specific filters into string.
- String-specific filters will automatically coerce input to string in
jinja2, this replicates that behavior.
Full Commit Range
- b8653 to b8660 (5 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8653...b8660
2026-04-03: Update to llama.cpp b8646
Summary
Updated llama.cpp from b8635 to b8646, incorporating 10 upstream commits with new features and performance improvements.
Notable Changes
🆕 New Features
- b8635: Relax prefill parser to allow space. (#21240)
- As in title.
- Prefill parser was strictly requiring the reasoning marker at the very start of the message, which interfered with models that liked to insert eg. a newline there.
- b8639: ggml-webgpu: add vectorized flash attention (#20709)
- This PR adds a vectorized WebGPU path for
FLASH_ATTN_EXT. - The implementation follows a split pipeline:
blk: optional mask tile classification
- This PR adds a vectorized WebGPU path for
- b8642: [HIP] Bump ROCm version to 7.2.1 (#21066)
- Bumps the ROCm version from 7.2 to 7.2.1 across all CI/CD workflows and the ROCm Dockerfile, and adds the missing
gfx1102GPU target to the fat-build architecture list.
- Bumps the ROCm version from 7.2 to 7.2.1 across all CI/CD workflows and the ROCm Dockerfile, and adds the missing
- b8646: rpc : reuse compute graph buffers (#21299)
- Reuse the buffer for the ggml context which is used for creating the compute graph on the server side. This partially addresses a memory leak created by the CUDA backend due to using buffer addresses as cache keys.
- ref: #21265
- I have read and agree with the contributing guidelines
🚀 Performance Improvements
- b8638: tests: allow exporting graph ops from HF file without downloading weights (#21182)
- This expands the
export-graph-opsbinary to also allow using--hf-repoinstead of--model. It uses the HF metadata loader from #19796 to set up a dummy model graph without loading weights and parses the cgraph from that, which allows running test-backend-ops on tensors from models without downloading them. That should make checking if a backend works correctly for a specific model/quant much easier, and also allows performance benchmark comparisons without downloads. - I tried to keep the changes to disable actually downloading the model minimal, but let me know if you can see a better way to do this.
- I have read and agree with the contributing guidelines
- This expands the
🐛 Bug Fixes
- b8641: Gemma 4 template parser fixes (#21326)
- As in topic
- Quick fixes for some observed discrepancies + refactoring of the parser architecture for the dict format
Additional Changes
4 minor improvements: 2 documentation, 1 examples, 1 maintenance.
- b8640: Add unit test coverage for llama_tensor_get_type (#20112)
- This is part of a larger goal of reworking or replacing the
llama_tensor_get_typefunction - Before major work starts in that area, I want to capture the current existing behaviour thoroughly, so that any accidental changes are easy to spot, and any purposeful changes are easy to document
- To that end, this PR introduces unit test coverage for the function itself
- This is part of a larger goal of reworking or replacing the
- b8645: chat : avoid including json in chat.h (#21306)
- Avoid including
json.hppinchat.h. - I have read and agree with the contributing guidelines
- Avoid including
- b8637: model: support gemma 4 (vision + moe, no audio) (#21309)
- Fix a bug where model with both vision/audio cannot be converted properly
- I have read and agree with the contributing guidelines
- b8644: (revert) kv-cache : do not quantize SWA KV cache (#21332)
- revert #21277
- In some cases the SWA cache actually takes significant portion of memory, so it's not always a good idea to keep it full-precision. It could be controlled via flag, but probably not worth the extra logic.
Full Commit Range
- b8635 to b8646 (10 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8635...b8646
2026-04-02: Update to llama.cpp b8635
Summary
Updated llama.cpp from b8635 to b8635, incorporating 1 upstream commits with new features.
Notable Changes
🆕 New Features
- b8635: Relax prefill parser to allow space. (#21240)
- As in title.
- Prefill parser was strictly requiring the reasoning marker at the very start of the message, which interfered with models that liked to insert eg. a newline there.
Full Commit Range
- b8635 to b8635 (1 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8635...b8635
2026-04-02: Update to llama.cpp b8635
Summary
Updated llama.cpp from b8635 to b8635, incorporating 1 upstream commits with new features.
Notable Changes
🆕 New Features
- b8635: Relax prefill parser to allow space. (#21240)
- As in title.
- Prefill parser was strictly requiring the reasoning marker at the very start of the message, which interfered with models that liked to insert eg. a newline there.
Full Commit Range
- b8635 to b8635 (1 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8635...b8635
2026-03-27: Update to llama.cpp b8555
Summary
Updated llama.cpp from b8507 to b8555, incorporating 25 upstream commits with new features and performance improvements.
Notable Changes
🆕 New Features
- b8517: llama: fix llama-model-saver (#20503)
- This PR fixes
llama-model-saverand makes the--outputargument oftest-llama-archsfunctional (the models themselves are still broken though because they lack tokenizers). - The first issue fixed in this PR is that
llama-model-saveris simply unmaintained: a lot of new KV values were added since I implemented it and those were not being saved correctly. I simply went through the KV values again, added the missing ones and checked where the corresponding information can be extracted from. - The second issue fixed in this PR is that on master several archs have broken tensor names: typically what happens is that in
llama_model::load_tensorstensors are being created without a corresponding entry inllm_get_tensor_names. As a consequenceLLM_TN_IMPL::strthen doesn't use the provided arguments to format the tensor name with e.g. the layer index. So you end up with multiple, different tensors that have names likeblk.%d.attn_q. Since a GGUF context is populated by tensor name this leads to conflicts and the model cannot be saved correctly. To me it is now clear why we havellm_get_tensor_namesin the first place. I think it would make more sense to just check inLLM_TN_IMPL::str()whethersuffix,bid, and/orxidare set and to use them in those cases. Also add a warning in cases where the tensor name template and the provided arguments don't match. I would implement this refactor in this PR.
- This PR fixes
- b8525: model : allow causal_attn and pooling_type on all architectures (#20973)
- Change all architectures to read the
causal_attnandpooling_typehyperparameters. - Transformers has introduced a change that enables all decoder-only models to function as encoders too (see the previous PR #20746). Rather than adding support for each model individually, I thought it would be better to allow all models to be used as embedding models.
- Change all architectures to read the
- b8532: CUDA & CPU: support F32 kernel type for
CONV_TRANSPOSE_2D(#17094)- also updated test case in
test-backend-ops. - But since F32 kernel type is not supported on CPU, only
GGML_TYPE_F16is kept andGGML_TYPE_F32can be uncommented back in the future.
- also updated test case in
- b8545: hip: use fnuz fp8 for conversion on CDNA3 (#21040)
- HIP supports the fp8 types e4m3_fnuz and e4m3_ocp, the difference being that fnuz dosent support inf. GFX942 (uniquely) supports only e4m3_fnuz in hardware, due to what looks like an oversight in rocm, the combination of e4m3_ocp on devices with native fp8 support but no ocp support is not implemented.
- Use native fnuz here to avoid this.
- b8552: rpc : proper handling of data pointers to CPU buffers (#21030)
- The compute graph may contain tensors pointing to CPU buffers. In these cases the buffer address is serialized as 0 and sent over the wire. However, the data pointer is serialized as-is and this prevents proper validation on the server side. This patches fixes this by serializing the data pointer as 0 for non-RPC buffers and doing proper validation on the server side.
- closes: #21006
- I have read and agree with the contributing guidelines
🚀 Performance Improvements
- b8507: ggml-backend: re-enable graph reuse with pipeline parallelism (#20927)
- Fix #20835. This is a sufficient fix but might not be the most performant one. At least restores performance for multi-GPU setups.
🐛 Bug Fixes
- b8508: models : move the token embedding norms to the first layer (#20943)
- We were keeping the token embedding norms on the input layer buffers. This results in the operations being performed on the CPU:
-
</code></pre> </li> <li>make -j && GGML_SCHED_DEBUG=2 ./bin/llama-embedding -hf ggml-org/bge-m3-Q8_0-GGUF -p "Hello world" -lv 5</li> </ul> </li> <li><strong>b8513</strong>: [SYCL] fix wrong variable check by assert (<a href="https://github.com/ggml-org/llama.cpp/pull/20903">#20903</a>) <ul> <li>Fix the issue: <a href="https://github.com/ggml-org/llama.cpp/pull/19920#issuecomment-4107430630">https://github.com/ggml-org/llama.cpp/pull/19920#issuecomment-4107430630</a></li> <li>Correct the variable to be checked by assert.</li> </ul> </li> <li><strong>b8514</strong>: fix-pointer-dangling (<a href="https://github.com/ggml-org/llama.cpp/pull/20974">#20974</a>) <ul> <li> <!--In the JNI layer of the sample Android program, when calling processUserInput, the pointer of user_prompt is freed before being referenced, and if the memory is overwritten during this period, it will not be possible to correctly retrieve the input. </li> <li>--></li> </ul> </li> <li><strong>b8519</strong>: jinja: fix macro with kwargs (<a href="https://github.com/ggml-org/llama.cpp/pull/20960">#20960</a>) <ul> <li>Fix this case: <code>{% macro my_func(a, b=False) %}{% if b %}{{ a }}{% else %}nope{% endif %}{% endmacro %}{{ my_func(1, b=True) }}</code></li> <li>With the <code>master</code> branch version, it fails with this error:</li> <li> <pre><code>
- b8528: common : fix gguf selection in common_list_cached_models (#20996)
- Fix regression that makes
common_list_cached_models()showing all files - Related to #20994
- Fix regression that makes
- b8529: common : fix verbosity setup (#20989)
- The verbosity threshold was set at the end of
common_params_parse_ex(), after doing many things (like downloading files) so-vandLLAMA_LOG_VERBOSITYwere useless during this function.
- The verbosity threshold was set at the end of
- b8546: fix: mtmd "v.patch_embd" quant and unsupported im2col ops on Metal for deepseek-ocr (#21027)
- This PR fixes two issues affecting vision models:
-
- Quantization of
v.patch_embd
- Quantization of
-
- Unsupported
im2col(bf16) ops on Metal for DeepSeek-OCR
- Unsupported
- b8548: metal: Fix dimension constraint violation in matmul2d descriptor (#21048)
- Updates Metal tensor API test probes to fix the dimension constraint violation in the matmul2d descriptor (at least one value must be a multiple of 16).
- Some investigation detailed here https://github.com/ggml-org/llama.cpp/pull/16634#issuecomment-4138042074 indicated that the test probes for the metal tensor API fails to compile successfully on macOS 26.4, leading to the tensor support in the metal backend being disabled erroneously. This is due to a change in the Apple APIs between the time https://github.com/ggml-org/llama.cpp/pull/16634 was tested and merged by @ggerganov and today. They now require that at least one of the dimensions
MandNbe a multiple of 16. - Notably, the actual kernels used already respect this constraint (obviously, as they are compiling successfully today), and it is only these test probes which violate it.
- b8551: fix: session_tokens insert range in completion tool (no-op → correct) (#20917)
- The embd.begin(), embd.begin() range is empty and inserts nothing, so session_tokens never gets updated after
- decoding. Should be embd.begin(), embd.end(). Introduced in commit 2b6dfe8.
Additional Changes
10 minor improvements: 2 documentation, 6 examples, 2 maintenance.
Full Commit Range
- b8507 to b8555 (25 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8507...b8555
2026-03-24: Update to llama.cpp b8505
Summary
Updated llama.cpp from b8505 to b8505, incorporating 1 upstream commits.
Notable Changes
🐛 Bug Fixes
- b8505: common : fix get_gguf_split_info (#20946)
- Fix https://github.com/ggml-org/llama.cpp/actions/runs/23476321133/job/68309759940
prefixis referenced bym…, remembering that C++ is definitely not C 😅
Full Commit Range
- b8505 to b8505 (1 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8505...b8505
2026-03-18: Update to llama.cpp b8405
Summary
Updated llama.cpp from b8394 to b8405, incorporating 6 upstream commits with breaking changes and new features.
Notable Changes
⚠️ Breaking Changes
- b8399: vulkan: disable mmvq on Intel Windows driver (#20672)
- Fixes #17628
- @savvadesogle This disables MMVQ entirely on Intel Windows, that should remove the need to use the env var. Please try it.
- b8405: common : rework gpt-oss parser (#20393)
- Rework the gpt-oss parser.
- Tighten up the grammar, gpt-oss is very good at following its own Harmony spec.
- Allow any sequence of analysis/preamble.
🆕 New Features
- b8398: ggml blas: set mkl threads from thread context (#20602)
- Commit 1: Set number of threads for MKL
- Commit 2: Add way to run blas builds through local CI.
- b8400: hexagon: add neg, exp, sigmoid, softplus ops, cont, repeat ops (#20701)
- Add element-wise unary ops needed by Qwen 3.5's DeltaNet linear attention layers. These ops follow the existing unary-ops pattern with VTCM DMA double-buffering.
- neg: negate via scale by -1.0
- exp: uses existing hvx_exp_f32 HVX intrinsics
🐛 Bug Fixes
- b8394: vulkan: async and event fixes (#20518)
- I noticed incoherence with my multi-GPU setup as well when investigating issues like #20462. I found that they can be fixed by disabling
cpy_tensor_async, so the problem is with the async path. I narrowed it down to these problems: - events were set, but the wait command was never submitted to the queue, so the
event_waitfunction didn't do anything - events were resetting command buffers that had long since been reused, because they didn't track that. This was causing validation errors and perhaps driver issues/crashes
- I noticed incoherence with my multi-GPU setup as well when investigating issues like #20462. I found that they can be fixed by disabling
- b8401: Reset graph on control vector change (#20381)
- This PR makes an existing context pick up a change to its control vector configuration via
llama_context::set_adapter_cvec. - The issue in short:
- Initial call to
set_adapter_cvecworks, steering vector applies to generation.
- This PR makes an existing context pick up a change to its control vector configuration via
Full Commit Range
- b8394 to b8405 (6 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8394...b8405
2026-03-17: Update to llama.cpp b8392
Summary
Updated llama.cpp from b8338 to b8392, incorporating 32 upstream commits with breaking changes, new features, and performance improvements.
Notable Changes
⚠️ Breaking Changes
- b8358: ci : split build.yml + server.yml (#20546)
- cont #20540
- Split
build.yml+server.ymlinto parts and move some of the workflows in the new parts - Continue to run
build.yml+server.ymlon all PRs andmasterbranch
- b8363: ggml: avoid creating CUDA context during device init (#20595)
- Make sure to read the contributing guidelines before submitting a PR
- ggml_cuda_init() calls cudaSetDevice() on every GPU just to query free VRAM for logging. This triggers the creation of a CUDA primary context (120-550 MB depending on GPU), which is irreversible for the lifetime of the process. Every process that loads the backend pays this cost, even if it never uses the GPU (router mode).
- This PR removes cudaSetDevice + cudaMemGetInfo from device init. The log loses the free VRAM part but still shows total VRAM via cudaGetDeviceProperties (no context needed). Free VRAM is queried later by FIT through its own cudaSetDevice path, so the context creation is simply deferred to first real use.
🆕 New Features
- b8340: ggml : add native AVX512-FP16 support for F16 operations (#20529)
- The overall benchmark speed remains almost the same because the CPU is now calculating faster than the RAM can deliver the data. (See perf stat results below showing 2.7 billion fewer instructions).
- Also note that this path will be only enabled for native build or with custom flags.
- now:
- b8350: ci : move self-hosted workflows to separate files (#20540)
- ref https://github.com/ggml-org/llama.cpp/discussions/20446
- Extract self-hosted workflows in new .yml files
- Add
server-cudaworkflows (will run on the new DGX Spark runner via thellama-servertag)
- b8351: metal : add FA specialization for HSK = 320, HSV = 256 (#20549)
- Add Metal kernels
- Add
test-backend-opstests
- b8355: cuda : add RDNA4-specific MMVQ parameter table for bs=1 decode (#19478)
- Add a dedicated
MMVQ_PARAMETERS_RDNA4entry separate from RDNA2/RDNA3. RDNA4 (gfx1201) is wave32-only and has a different memory subsystem, so it benefits from a different MMVQ configuration than RDNA2/RDNA3. - For bs=1 decode on RDNA4, optimal config is
nwarps=8, rows_per_block=1: - 8 warps × 32 threads = 256 threads per block
- Add a dedicated
- b8372: model : wire up Nemotron-H tensors for NVFP4 support (#20561)
- prep #20539
- b8388: model: mistral small 4 support (#20649)
- Ref upstream PR: https://github.com/huggingface/transformers/pull/44760
- The model is the same as Mistral Large 3 (deepseek2 arch with llama4 scaling), but I'm moving it to a new arch
mistral4to be aligned with transformers code - Disclosure: this PR is made possible with the help from Mistral team. Kudos to @juliendenize for the coordination!
- b8392: kleidiai : fix MUL_MAT support for batched (3D) inputs (#20620)
- The supports_op() check incorrectly rejected MUL_MAT operations with 3D inputs (ne[2] > 1), but the actual compute_forward_qx() implementation handles batched inputs correctly via a loop over ne12.
- This caused models with Q4_0/Q8_0 weights to crash during graph scheduling when n_seq_max > 1, because weights were placed in KLEIDIAI buffers during loading (tested with 2D inputs) but the runtime used 3D inputs.
Also relax the buffer check to allow supports_op() to be called during weight loading when src[0]->buffer is NULL.
🚀 Performance Improvements
- b8348: ci: try to optimize some jobs (#20521)
- I tried to switch some jobs to arm or ubuntu-slim as per my comment in #20446 for builds where it really doesn't matter. Most jobs didn't fit in the 15 minute ubuntu-slim time limit and some like the sanitizer or android straight up failed on arm. If a job doesn't have ccache set up I also made it work on both x86 and arm so it would pick the first available machine.
- I'm not sure how much this really helps, but it does reduce the number of x86 machines that we're using at any given time.
- run in my fork with those jobs forced to run on arm: https://github.com/netrunnereve/llama.cpp/actions/runs/23031702820
- b8364: CUDA: limit number of FA stream-k CUDA blocks (#20586)
- On master the CUDA mma FA kernel can launch superfluous CUDA blocks that do not do any useful work but cause overhead. This can happen when running small models on GPUs with many streaming multiprocessors at low batch sizes. This PR fixes this by limiting the number of CUDA blocks to the number that can do useful work.
-
-
Performance changes
🐛 Bug Fixes
- b8347: hexagon: Q4_0 and MXFP4 repack fixes (#20527)
- Turns out our repack logic has bug where tensors with row sizes not multiple of 256 are getting corrupted.
- Basically, I made the wrong assumption that we can use
0:128,1:129,... INT4element packing for all blocks of 256 - This was causing the scales to partially override some of the tail quants (in Hexagon backend we repack the rows into all-quants followed by all-scales format).
- b8352: llama: Wire up Qwen3.5/Qwen3.5MoE tensors for NVFP4 support (#20506)
- PR https://github.com/ggml-org/llama.cpp/pull/20505 fixes the conversion errors for making Qwen3.5 NVFP4 GGUF files and properly reorders the Qwen3.5 linear attention layers, but without this update, those models will not load.
- This update wires up the Qwen3.5 tensors so they are properly loaded from Qwen3.5 NVFP4 gguf files and follows the same design intent using
build_lora_mm: - This links up the:
- b8353: Read the persisted llama_kv_cell_ext for n_pos_per_embd > 1 on state_read for all sequence ids (#20273)
- cont #20132
- Attempting to call llama_kv_cache::state_read fails when n_pos_per_embd is greater than 1, since llama_kv_cell_ext data is serialised in
state_savebut not read back instate_read, leading to deserialisation failure since the cell_ext data is being parsed as a seq_id. - I assume the attached fix is correct -- kv cache persistence to host memory is now working as expected.
- b8354: vulkan: use graphics queue on AMD (#20551)
- I'm not sure why, but the graphics queue is slightly faster in tg on AMD than the compute queue, and this also fixes the partial offload issue I fixed in #19976, so the second queue no longer has to be enabled by default. I got the idea from @zedbytes reporting that tg goes up when running with
RADV_DEBUG=nocompute. -
-
AMD RX 9070 XT
- I'm not sure why, but the graphics queue is slightly faster in tg on AMD than the compute queue, and this also fixes the partial offload issue I fixed in #19976, so the second queue no longer has to be enabled by default. I got the idea from @zedbytes reporting that tg goes up when running with
- b8356: Guard against sumq2 being 0 in IQ4_NL resulting in nan values (#20460)
- With
IQ4_NLon several recent models there have been issues where during quantization NaN blocks are being found which crashes the quant - It seems to be stemming from a scenario where
sumq2is 0 for a given block, likely from not having imatrix data for some obscure expert, or the weights themselves being 0 as we've seen with some recent Qwen models - This change guards against dividing by 0, instead setting
dto 0, which would then just set the block of weights to 0, which seems appropriate
- With
- b8360: fix: prevent nullptr dereference (#20552)
- When encountering an unsupported template (e.g. translategemma), the code currently dereferences a nullptr and causes the program to crash.
- With this fix, a proper exception will be thrown from
common_chat_templates_apply_jinjainstead.
- b8361: ggml/hip: fix APU compatibility - soft error handling for hipMemAdviseSetCoarseGrain (#20536)
- Description:
- On AMD APU/iGPU devices (unified memory architecture, e.g. AMD Strix Halo gfx1151),
hipMemAdviseSetCoarseGrainreturns hipErrorInvalidValuebecause this hint is not applicable to UMA systems. The current code wraps this call inCUDA_CHECK(), which treats
- b8366: sycl : fix for untransposed GDA recurrent state (#20583)
- cont #20443
- b8370: tests: Fix invalid iterator::end() dereference in common_regex (#20445)
- When compiling with VS2026 18.4 I noticed
test-regex-partialcrashes immediately with debug build. -
- I tracked this down to an iterator::end() dereference in the following test case which was occurring here.
- When compiling with VS2026 18.4 I noticed
- b8373: vulkan: fix flash attention dot product precision (#20589)
- The Q*K^T dot product was done in float16, but it should have been using ACC_TYPE. This fixes the GLM4 incoherence.
- Fixes #20555
- b8391: vulkan: allow graphics queue only through env var (#20599)
- Improve #20551 to fix the reported issues. Only use graphics queue on RADV on larger GPUs.
- Fixes #20597
Additional Changes
10 minor improvements: 3 documentation, 2 examples, 5 maintenance.
Full Commit Range
- b8338 to b8392 (32 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8338...b8392
2026-03-14: Update to llama.cpp b8329
Summary
Updated llama.cpp from b8287 to b8329, incorporating 29 upstream commits with new features.
Notable Changes
🆕 New Features
- b8291: metal : add env var to trigger graph capture (#20398)
- QoL for capturing execution of Metal graphs for profiling purposes.
- Usage:
-
</code></pre> </li> </ul> </li> <li><strong>b8295</strong>: llama : add support for Nemotron 3 Super (<a href="https://github.com/ggml-org/llama.cpp/pull/20411">#20411</a>) <ul> <li>This commit adds support for the Nemotron 3 Super model (120B.A12B) enabling this model to be converted to GGUF format and run in llama.cpp.</li> </ul> </li> <li><strong>b8299</strong>: llama : enable chunked fused GDN path (<a href="https://github.com/ggml-org/llama.cpp/pull/20340">#20340</a>) <ul> <li>cont #19504</li> <li>Backends can now implement the chunked version of the fused GDN operator.</li> <li>Implementations:</li> </ul> </li> <li><strong>b8299</strong>: metal : add GDN kernel (<a href="https://github.com/ggml-org/llama.cpp/pull/20361">#20361</a>) <ul> <li>target #20340</li> <li>cont #20244</li> <li>Add fused GDN recurrent kernel. Use both for BS == 1 and BS > 1.</li> </ul> </li> <li><strong>b8299</strong>: ggml: add GATED_DELTA_NET op (<a href="https://github.com/ggml-org/llama.cpp/pull/19504">#19504</a>) <ul> <li>Add CPU/CUDA impl for GATED_DELTA_NET used in qwen3next and a lot of upcoming recent attention models. This is a basic vector impl and not the chunking impl, although this should work for n_tokens > 1 as a reference implementation. I tested this vs <code>build_delta_net_autoregressive</code> and the results were good. I plan to add the chunked implementation for CPU and CUDA.</li> <li>master:</li> <li>| model | size | params | backend | threads | fa | test | t/s |</li> </ul> </li> <li><strong>b8299</strong>: CUDA: AR gated delta net improvements (<a href="https://github.com/ggml-org/llama.cpp/pull/20391">#20391</a>) <ul> <li>I profiled the AR gated delta net, and improved perf by:</li> <li> <ol> <li>Adding fastdiv/fastrem for s64 int (do we even need this arithmetic to happen in 64-bit?)</li> </ol> </li> <li> <ol start="2"> <li>Sharding a column across a full warp instead of using only a single thread. We don't fill SMs (at least on higher-tier GPUs) with existing launch-config (saw 16-32 CTAs with low thread-counts vs. 80+ SMs for e.g. 5080), so that was some free perf while reducing register-pressure in the case where S_v = 128 (saw some spill there)</li> </ol> </li> </ul> </li> <li><strong>b8304</strong>: tool parser: add GigaChatV3/3.1 models support in PEG format (<a href="https://github.com/ggml-org/llama.cpp/pull/19931">#19931</a>) <ul> <li>I have recreated the PR of <a href="https://github.com/ggml-org/llama.cpp/pull/17924">https://github.com/ggml-org/llama.cpp/pull/17924</a> for cleaner commits and no merge conflicts</li> </ul> </li> <li><strong>b8315</strong>: vulkan: fix SSM_CONV PP scaling with large ubatch sizes (<a href="https://github.com/ggml-org/llama.cpp/pull/20379">#20379</a>) <ul> <li>Fixes #18725</li> <li>The SSM_CONV shader dispatched one token per Y workgroup, each doing only <code>nc</code> (typically 4) multiply-adds. At ubatch=2048 this meant 2048 workgroups in Y with almost no work per launch — workgroup dispatch overhead dominated.</li> <li><strong>Changes:</strong></li> </ul> </li> <li><strong>b8317</strong>: llama : enable chunked fused GDN path (<a href="https://github.com/ggml-org/llama.cpp/pull/20340">#20340</a>) <ul> <li>cont #19504</li> <li>Backends can now implement the chunked version of the fused GDN operator.</li> <li>Implementations:</li> </ul> </li> <li><strong>b8329</strong>: ggml-cpu: add RVV vec dot kernels for quantization types (<a href="https://github.com/ggml-org/llama.cpp/pull/18859">#18859</a>) <ul> <li>This PR adds RVV vector dot kernels for a number of quantization types.</li> <li>Added the following RVV kernels:</li> <li>| Kernel | VLEN |</li> </ul> </li> </ul> <h4><a href="#user-content--bug-fixes-36" aria-hidden="true" class="anchor" id="user-content--bug-fixes-36"></a>🐛 Bug Fixes</h4> <ul> <li><strong>b8292</strong>: metal : fix q5_k mul_mv register spill (<a href="https://github.com/ggml-org/llama.cpp/pull/20399">#20399</a>) <ul> <li>cont #20398</li> <li>Noticed too high register pressure in the q5_k vec kernel:</li> <li> <pre><code class="language-bash">
- b8301: common : fix
--n-cpu-moe,--cpu-moefor models with fused gate + up (#20416)- Changed the regex that matches conditional experts from:
-
</code></pre> </li> <li>const char * const LLM_FFN_EXPS_REGEX = "\.ffn_(up|down|gate)_(ch|)exps";</li> </ul> </li> <li><strong>b8308</strong>: vulkan: Fix ErrorOutOfHostMemory on Intel GPU when loading large models with --no-mmap (<a href="https://github.com/ggml-org/llama.cpp/pull/20059">#20059</a>) <ul> <li>Fixes #19420.</li> <li>We were hitting an internal maximum number (16383) of command buffers for Intel's Windows GPU driver causing ErrorOutOfHostMemory when loading large models (1MB per transfer * 16383 == approx 16GB or more weight). This PR attempts to fix this by reusing command buffers that are done transferring data.</li> <li><code>llama-cli.exe -m Qwen3-Coder-30B-A3B-Instruct-Q4_K_M.gguf --no-mmap</code> show no crashing on both Intel iGPU and NVIDIA dGPU. Chat results are correct as well.</li> </ul> </li> <li><strong>b8309</strong>: vulkan: fix OOB check in flash_attn_mask_opt (<a href="https://github.com/ggml-org/llama.cpp/pull/20296">#20296</a>) <ul> <li>Fixes #19955.</li> <li>I saw a few percent slowdown with pp512 (which is too small to hit the aligned path on my system after this change) so I tweaked the use_mask_opt logic to hide it. I should look into spreading the work across more workgroups, but I don't have time for that today.</li> <li>@el95149 this is different enough from the test change that it's probably worth retesting.</li> </ul> </li> <li><strong>b8310</strong>: vulkan: fix l2_norm epsilon handling (<a href="https://github.com/ggml-org/llama.cpp/pull/20350">#20350</a>) <ul> <li>This is the only "real" bug I could find in test-llama-archs. I see some other failures but they may be driver/compiler bugs.</li> </ul> </li> <li><strong>b8318</strong>: grammar : Fix grammar root symbol check (<a href="https://github.com/ggml-org/llama.cpp/pull/19761">#19761</a>) <ul> <li>Constructing a GBNF grammar allows the programmer to select a <code>grammar_root</code>- the symbol to start the grammar from.</li> <li>The <code>llama_grammar_init_impl</code> function incldued a check to see whether the grammar contains a rule for a symbol named literally "root", instead of checking for a symbol with the named passed in as <code>grammar_root</code>. This causes valid grammars with non-"root" root symbols to fail, and invalid grammars with a rule named "root", but a different chosen <code>grammar_root</code> symbol to pass the check, and immediately fail hard (see failure case in Tests section).</li> <li>Check whether there is a rule for a symbol with the name passed in as <code>grammar_root</code>, not literally <code>"root"</code>.</li> </ul> </li> <li><strong>b8323</strong>: llama : disable graph reuse with pipeline parallelism (<a href="https://github.com/ggml-org/llama.cpp/pull/20463">#20463</a>) <ul> <li>The following repro demonstrates the issue:</li> <li> <pre><code class="language-bash">
- make -j && ./bin/llama-perplexity -hf ggml-org/Qwen3-0.6B-GGUF -f wiki.test.raw --chunks 16 -ngl 99 -ub 512 -b 2048
- b8325: metal : fix l2 norm scale (#20493)
- Bug revealed from recently added tests.
- b8328: ggml : fix typo gmml (#20512)
Additional Changes
10 minor improvements: 3 documentation, 5 examples, 2 maintenance.
Full Commit Range
- b8287 to b8329 (29 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8287...b8329
2026-03-08: Update to llama.cpp b8234
Summary
Updated llama.cpp from b8233 to b8234, incorporating 2 upstream commits with new features.
Notable Changes
🆕 New Features
- b8233: ggml: add GATED_DELTA_NET op (#19504)
- Add CPU/CUDA impl for GATED_DELTA_NET used in qwen3next and a lot of upcoming recent attention models. This is a basic vector impl and not the chunking impl, although this should work for n_tokens > 1 as a reference implementation. I tested this vs
build_delta_net_autoregressiveand the results were good. I plan to add the chunked implementation for CPU and CUDA. - master:
- | model | size | params | backend | threads | fa | test | t/s |
- Add CPU/CUDA impl for GATED_DELTA_NET used in qwen3next and a lot of upcoming recent attention models. This is a basic vector impl and not the chunking impl, although this should work for n_tokens > 1 as a reference implementation. I tested this vs
Additional Changes
1 minor improvements: 1 documentation.
- b8234: [SYCL] supprt Flash Attention for fp32/fp16/Q4/Q5/Q8 (#20190)
- Supprt Flash Attention for fp32/fp16/Q4/Q5/Q8.
- All supported Flash Attention UT cases are passed.
- Support to enable/disable Flash attention by environment variable: GGML_SYCL_ENABLE_FLASH_ATTN
Full Commit Range
- b8233 to b8234 (2 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8233...b8234
2026-03-07: Update to llama.cpp b8229
Summary
Updated llama.cpp from b8229 to b8229, incorporating 1 upstream commits.
Notable Changes
🐛 Bug Fixes
- b8229: [ggml-quants] Add memsets and other fixes for IQ quants (#19861)
- While trying to stop my Qwen3.5 quants from getting a ton of "Oops: found point X not on grid ...", I (and claude) came across a potential big issue
- Using gdb, it seems that
Lis often initialized to non-zero memory, and so when it's read, it has garbage data in it that's causing the quantizations to go awry when there's no candidates found during the search - With this change, with Qwen3.5, I no longer saw ANY "Oops: found point.." errors, and the PPL seems totally as expected
Full Commit Range
- b8229 to b8229 (1 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8229...b8229
2026-03-05: Update to llama.cpp b8204
Summary
Updated llama.cpp from b8185 to b8204, incorporating 16 upstream commits with breaking changes, new features, and performance improvements.
Notable Changes
⚠️ Breaking Changes
- b8189: Clean up per-thread parameter buffer pool and job submission logic (#19772)
- After splitting per-thread state and execution, this is the final cleanup diff.
- We allow the buffer pool to grow in case of multiple kernels in a command requiring more buffers, remove the inflight_threads logic, and replace it with num_kernels to decide when to submit a batch of commands.
- b8201: [WebGPU] Fix wait logic for inflight jobs (#20096)
- Fix WebGPU wait logic incorrectly removing futures. WaitAny returns when any future completes, but the previous implementation erased the entire submission entry (aka a vector of futures). Flatten the nested futures structure to a single vector and remove only the futures that are completed.
🆕 New Features
- b8188: ggml-webgpu: Support non-contiguous
src0and overlappingsrc0/src1in binary ops (#19850)- Hello. This PR improves the handling of binary operations in the WebGPU backend, adding support for patterns required by #16857 (MoE expert reduce).
- The changes are as follows:
- The index is now calculated based on stride to support cases where
src0is a non-contiguous tensor.
- b8190: ggml webgpu: fix workgroup dispatch limit for large batch sizes (#19965)
- WebGPU limits workgroup counts to 65535 per dimension. MUL_MAT operations with batch sizes exceeding this limit would fail or corrupt memory.
- This PR implements 2D workgroup dispatch to handle arbitrary batch sizes:
- Adds
compute_2d_workgroups()helper to split workgroups across X/Y dimensions when exceeding the 65535 limit
- b8191: opencl: add optimized q4_1 mm kernel for adreno (#19840)
- This PR adds optimized OpenCL kernels for Q4_1 GEMM and GEMV operations on Adreno GPUs.
- b8192: kleidiai : add sme fp16 compute path for q4_0 gemm on aarch64 (#20043)
- This patch introduce an SME2-based FP16 compute path for Q4_0 GEMM to improve performance on AARCH64.
- Benchmark result for Llama-3.2-1B-Instruct-Q4_0 — pp512 (t/s) (Mac M4 Pro, GGML_KLEIDIAI_SME=1)
- | Threads | w/o fp16q4 | w/ fp16q4 | Improvement |
- b8203: opencl: add
set, i32 forcpy(#20101)- Add
setand support i32 forcpy. Also some minor refactoring forcpyhost code.
- Add
🚀 Performance Improvements
- b8185: ggml-cpu: optimise s390x multiply extend instructions (#20032)
- This PR optimizes the multiply extend vector instructions for Q4_0, Q4_K, Q5_K, and Q6_K quantizations by using the fused multiply-add instruction instead of separating them into multiple instruction calls. We notice a performance improvement of about 28.77% and 16.35% for Prompt Processing and Token Generation respectively.
- Old Instruction Set
-
</code></pre> </li> </ul> </li> <li><strong>b8187</strong>: vulkan: tune MMVQ for Intel Windows (<a href="https://github.com/ggml-org/llama.cpp/pull/19988">#19988</a>) <ul> <li>Tune MMVQ use for Intel Windows according to <a href="https://github.com/ggml-org/llama.cpp/issues/17628#issuecomment-3897132360">https://github.com/ggml-org/llama.cpp/issues/17628#issuecomment-3897132360</a></li> <li>@savvadesogle Please try it and see if performance is good.</li> </ul> </li> <li><strong>b8197</strong>: ggml : use a simple std::thread in AMX without OpenMP (<a href="https://github.com/ggml-org/llama.cpp/pull/20074">#20074</a>) <ul> <li>Disabling OpenMP generally provides better inference performance (at least in my testing) but the loading becomes slightly slower.</li> <li>Benchmark results for <code>convert_B_packed_format()</code>:</li> <li>Before this commit:</li> </ul> </li> <li><strong>b8204</strong>: hexagon: Flash Attention optimizations (dma, mpyacc, multi-row) and MatMul updates (<a href="https://github.com/ggml-org/llama.cpp/pull/20118">#20118</a>) <ul> <li>Further updates on top of #19780 by @chraac</li> <li>Improved DMA pipelining in FA</li> <li>Reduced FA block size from 128 to 64 to improve DMA prefetch (128 is too big for most models)</li> </ul> </li> </ul> <h4><a href="#user-content--bug-fixes-38" aria-hidden="true" class="anchor" id="user-content--bug-fixes-38"></a>🐛 Bug Fixes</h4> <ul> <li><strong>b8196</strong>: impl : use 6 digits for tensor dims (<a href="https://github.com/ggml-org/llama.cpp/pull/20094">#20094</a>) <ul> <li>Many models have vocabulary sizes, and thus tensor shapes, with more than 5 digits (ex: Gemma 3's vocab size is 262,208).</li> <li>I already fixed this for <code>llama_format_tensor_shape</code> (tensor) but missed it for <code>llama_format_tensor_shape</code> (vector) until now. Oops.</li> <li><em>Make sure to read the <a href="https://github.com/ggml-org/llama.cpp/blob/master/CONTRIBUTING.md">contributing guidelines</a> before submitting a PR</em></li> </ul> </li> <li><strong>b8198</strong>: ggml: fix ggml_is_contiguous_n for ne == 1 (<a href="https://github.com/ggml-org/llama.cpp/pull/20092">#20092</a>) <ul> <li>While debugging a test failure for <a href="https://github.com/ggml-org/llama.cpp/pull/19802">https://github.com/ggml-org/llama.cpp/pull/19802</a> I found what I believe to be a bug in <code>ggml_is_contiguous_n</code>. A test case using the new fused experts from <a href="https://github.com/ggml-org/llama.cpp/pull/19139">https://github.com/ggml-org/llama.cpp/pull/19139</a> fails on an assert like <code>GGML_ASSERT(ggml_is_contiguous_1(a))</code>. This assertion failure happens specifically because the test case uses only a single expert vs. the real models using >1 experts. So the test case gets a tensor like this: <code>ne = {192, 1, 128, 1}, nb = {4, 1536, 1536, 196608}</code>. This should be contiguous in dimensions 1, 2, and 3 but it is not according to <code>ggml_is_contiguous_1</code>. The reason is that the code on master entirely skips dimensions that have a size of 1. But this then also skips the fix for <code>next_nb</code> if a dimension does not need to be contiguous. This PR adjusts the logic to skip only the check for whether or not the tensor is contiguous if a dimension is equal to 1.</li> </ul> </li> </ul> <h3><a href="#user-content-additional-changes-43" aria-hidden="true" class="anchor" id="user-content-additional-changes-43"></a>Additional Changes</h3> <p>3 minor improvements: 1 documentation, 2 examples.</p> <ul> <li><strong>b8200</strong>: ggml-webgpu: Add the support of <code>GGML_OP_CONCAT</code> (<a href="https://github.com/ggml-org/llama.cpp/pull/20068">#20068</a>) <ul> <li>Hello. This PR adds <code>GGML_OP_CONCAT</code> support to the WebGPU backend. This op is used by models such as DeepSeek-V2.</li> <li>This change supports two types <code>F32</code>, <code>I32</code> to match the types covered by <code>test_concat</code> in <code>test-backend-ops</code>.</li> </ul> </li> <li><strong>b8194</strong>: completion : Fix a typo in warning message (<a href="https://github.com/ggml-org/llama.cpp/pull/20082">#20082</a>) <ul> <li>resuse -> reuse</li> </ul> </li> <li><strong>b8195</strong>: Fix locale-dependent float printing in GGUF metadata (<a href="https://github.com/ggml-org/llama.cpp/pull/17331">#17331</a>) <ul> <li>I was running some llama.cpp examples on a system with a German locale (de_DE) and noticed something odd - when llama-cli printed out the model metadata, all the float values had commas as decimal separators (like "0,000000") instead of periods. But when I ran llama-perplexity on the same model, it used periods normally.</li> <li>After some digging, I found the issue was in the gguf_data_to_str() function in llama-impl.cpp. It was using std::to_string() to format floats, which respects the system's LC_NUMERIC locale setting. So depending on which tool you used and what locale it was running with, you'd get different formatting.</li> <li>I've changed it to use std::ostringstream with std::locale::classic() instead, which always formats floats with a period as the decimal separator, regardless of the system locale. This should make the output consistent across all tools and locales.</li> </ul> </li> </ul> <h3><a href="#user-content-full-commit-range-52" aria-hidden="true" class="anchor" id="user-content-full-commit-range-52"></a>Full Commit Range</h3> <ul> <li>b8185 to b8204 (16 commits)</li> <li>Upstream releases: <a href="https://github.com/ggml-org/llama.cpp/compare/b8185...b8204">https://github.com/ggml-org/llama.cpp/compare/b8185...b8204</a></li> </ul> <hr /> <h2><a href="#user-content-2026-03-02-update-to-llamacpp-b8185" aria-hidden="true" class="anchor" id="user-content-2026-03-02-update-to-llamacpp-b8185"></a>2026-03-02: Update to llama.cpp b8185</h2> <h3><a href="#user-content-summary-53" aria-hidden="true" class="anchor" id="user-content-summary-53"></a>Summary</h3> <p>Updated llama.cpp from b8182 to b8185, incorporating 4 upstream commits with performance improvements.</p> <h3><a href="#user-content-notable-changes-49" aria-hidden="true" class="anchor" id="user-content-notable-changes-49"></a>Notable Changes</h3> <h4><a href="#user-content--performance-improvements-26" aria-hidden="true" class="anchor" id="user-content--performance-improvements-26"></a>🚀 Performance Improvements</h4> <ul> <li><strong>b8184</strong>: vulkan: improve partial offloading performance on AMD (<a href="https://github.com/ggml-org/llama.cpp/pull/19976">#19976</a>) <ul> <li>I saw a big difference between Vulkan and ROCm performance in partial offloads. I narrowed it down to transfer speeds for weight transfer from CPU to GPU with offloaded ops. One possible explanation is that using the dedicated transfer queue on AMD may be faster than using a compute queue, so I implemented using a transfer queue for async transfers as well and synchronizing transfers using a timeline semaphore. This does improve performance.</li> <li>Then I checked and found that the dedicated transfer queue on AMD is not exposed by the Linux driver by default, so it's not actually being used. The difference comes from using a second queue (the graphics queue) for transfers, so I assume the issue was the compute queue being congested with other work.</li> <li>This helps on AMD RDNA4, but not on GCN and not on Nvidia. I couldn't test Intel because the Linux driver only exposes a single queue.</li> </ul> </li> <li><strong>b8185</strong>: ggml-cpu: optimise s390x multiply extend instructions (<a href="https://github.com/ggml-org/llama.cpp/pull/20032">#20032</a>) <ul> <li>This PR optimizes the multiply extend vector instructions for Q4_0, Q4_K, Q5_K, and Q6_K quantizations by using the fused multiply-add instruction instead of separating them into multiple instruction calls. We notice a performance improvement of about 28.77% and 16.35% for Prompt Processing and Token Generation respectively.</li> <li>Old Instruction Set</li> <li> <pre><code class="language-assembly">
🐛 Bug Fixes
- b8182: vendors: update miniaudio library to 0.11.24 (#19914)
- https://github.com/mackron/miniaudio/releases/tag/0.11.24.
- Fixed a possible glitch when processing the audio of a
ma_soundwhen doing resampling. - Fixed a possible crash in the node graph relating to scheduled starts and stops.
- b8183: cuda: fix grid.y overflow in non-contiguous dequantize/convert kernels (#19999)
- The
dequantize_blockandconvert_unarykernels passne01directly as the CUDA grid y-dimension, but grid.y is limited to 65535. Whenne01exceeds this, the kernel launch fails withcudaErrorInvalidConfiguration. - This happens when using
llama-serverwith flash attention, quantized KV cache, multiple parallel slots, and long context. With multiple slots the KV caches are non-contiguous, so the NC dequantization path is taken, andne01(the KV cache length) ends up as grid.y. - The grid.z dimension was already capped at 65535 with a grid-stride loop. This applies the same pattern to grid.y.
- The
Full Commit Range
- b8182 to b8185 (4 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8182...b8185
2026-03-01: Update to llama.cpp b8182
Summary
Updated llama.cpp from b8087 to b8182, incorporating 76 upstream commits with breaking changes, new features, and performance improvements.
Notable Changes
⚠️ Breaking Changes
- b8098: models : dedup qwen35 graphs (#19660)
- cont #19597
- Use the new
struct llm_build_delta_net_baseto deduplicate the delta net graphs from Qwen35 models. - TODO:
- b8101: llama : use output_resolve_row() in get_logits_ith/get_embeddings_ith (#19663)
- This commit updates get_logits_ith(), and get_embeddings_ith() to use output_resolve_row() to resolve the batch index to output row index.
- The motivation for this is to remove some code duplication between these functions.
- b8140: hexagon refactor all Ops to use local context struct (#19819)
- This PR completes the refactoring of all Hexagon Ops to use a local context structure. This allows each Op to precompute and cache more state. The refactoring also removes redundant function wrappers and unnecessary boilerplate.
- Most Ops now use DMA for fetching inputs and writing back outputs.
- The main loops of RoPE and Unary Ops have been completely rewritten for better DMA pipelining.
- b8146: ggml/gguf : prevent integer overflows (#19856)
- Strengthen integer overflow validation in ggml/gguf
- Impose max limits for string length and array elements of GGUF metadata
- Remove deprecated
ggml_type_sizef()
🆕 New Features
- b8091: ggml webgpu: shader library organization (#19530)
- We've been converting many of the existing WGSL shaders into a format that allows for efficient just-in-time compilation of variants used in specific model graphs, as well as sets them up for better performance tuning down the road. This PR makes a pretty large organizational change, moving the shader preprocessing, compilation, and caching into a new
ggml_webgpu_shader_libstructure. As part of this, the existing matrix multiplication shaders were also converted in to the JIT compilation format (using the wgsl preprocessor), along with get_rows and scale. - This new shader library class also opens up the opportunity for tons of interesting specialization in the WebGPU backend. For example, if you have a shader specialized for a particular GPU vendor/architecture in WGSL, it should be pretty easy to hook it into the logic for choosing the right shader/pipeline.
- It's always nice to have a PR that removes more lines of code than it adds too :)
- We've been converting many of the existing WGSL shaders into a format that allows for efficient just-in-time compilation of variants used in specific model graphs, as well as sets them up for better performance tuning down the road. This PR makes a pretty large organizational change, moving the shader preprocessing, compilation, and caching into a new
- b8091: Add oneliner for batch quantization (#17)
- b8100: full modern bert support (#18330)
- Made support for conversion from hf->gguf and execution on llama.cpp after my recent (granite-embd-support)[https://github.com/ggml-org/llama.cpp/pull/15641] which is a modern bert based model, this pr continues off of that and has some tweaks. I have ran cosine similarity tests with this script
-
- from sentence_transformers import SentenceTransformer
- b8102: model : Add tokenizer from LFM2.5-Audio-1.5B (#19687)
- LFM2.5-Audio-1.5B introduced a lightweight audio tokenizer.
- It is based on the LFM2 architecture and serves as an embedding model with different input
n_embdand outputn_embd_out. - To be used in https://github.com/ggml-org/llama.cpp/pull/18641.
- b8106: model: add JAIS-2 architecture support (#19488)
- Add support for the JAIS-2 family of Arabic-English bilingual models from Inception AI (https://huggingface.co/inceptionai/Jais-2-8B-Chat).
- Architecture characteristics:
- LayerNorm (not RMSNorm) with biases
- b8106: CUDA: fix padding of GQA to power of 2 in FA (#19115)
- Fixes https://github.com/ggml-org/llama.cpp/issues/19112 , the issue was introduced with https://github.com/ggml-org/llama.cpp/pull/19092 .
- The MMA CUDA FlashAttention kernel uses a stream-k decomposition to treat the four-dimensional input tensors as one continuous dimension to split across streaming multiprocessors. However, in conjunction with the GQA-specific optimizations in the MMA kernel this is only correct if the number of Q columns per CUDA block exactly divide
n_gqa. Otherwise the wrong Q and K/V heads will be associated and the result will be wrong (if there is only a single K/V head this doesn't matter so it was not detected in testing). - This PR extends the 4D space on master to a 5D space by splitting the "z" dimension with the number of Q heads into one dimension for the number of K/V heads and another dimension for the number of Q heads per K/V head. This then makes it possible to simply pad the Q columns per CUDA block to a power of 2.
- b8116: ggml-quants : weighted rounding algorithms with cumulative search (#12557)
- This adds proper
imatrixsupport toTQ1_0andTQ2_0, in addition to improving the rounding algorithm used forQ3_K,IQ4_NL,IQ4_XS(both with and withoutimatrix), as well as when usingimatrixwithQ4_0andQ5_0. - This is backward and forward compatible with other versions of
llama.cpp. - Since this doesn't change the format of the types, only how the values are rounded when quantized, even previous (or current) versions of
llama.cppcan use quants made with this PR.
- This adds proper
- b8117: ggml-cpu: add RVV vec dot kernels for quantization types (#18784)
- This PR adds RVV vector dot kernels for a number of quantization types.
- Added the following RVV kernels:
- | Kernel | VLEN |
- b8118: common : merge qwen3-coder and nemotron nano 3 parsers (#19765)
- Users are experiencing several issues with Qwen3-Coder-Next. Until #18675 is merged in, this PR serves as a stop-gap by replacing the existing Qwen3-Coder parsing with the Nemotron Nano 3 PEG parsing variant already present.
- This PR also adds parallel tool calling and fixes JSON schema support.
- fixes #19382
- b8123: Add a build target to generate ROCm artifacts using ROCm 7.2 (#19433)
- This builds the following targets:
- gfx1151
- gfx1150
- b8128: model: Add Kanana-2 model support (#19803)
- Make sure to read the contributing guidelines before submitting a PR
- This PR adds support for following Kanana-2 model family:
- kakaocorp/kanana-2-30b-a3b-instruct-2601
- b8131: jinja: correct stats for tojson and string filters (#19785)
- Target fix https://github.com/ggml-org/llama.cpp/pull/18675
- @pwilkin please give this a try (see the added test case for more info)
- b8142: vulkan: fix coopmat1 without bf16 support (#19793)
- This should fix the CI failure on lavapipe. lavapipe added coopmat1 support recently, but does not have bf16 support, so it falls back to the scalar path. This fallback didn't have quite the same tile size logic for subgroupsize=8 as when going through the scalar path directly.
- b8143: Vulkan Scalar Flash Attention Refactor (#19625)
- This started out as an attempt to go through the scalar FA version and add proper float16 support to improve AMD and Intel performance and went quite a bit further. @jeffbolznv Sorry about the amount of changes, let me know if there's something I can do to make the review easier. Please also let me know if you have architectural concerns. Flash Attention has so many dimensions and making it work well on so much hardware and models is pretty hard. I had to spend quite a lot of time figuring out and fixing regressions on specific configurations.
-
-
AI-generated summary of changes
- b8149: gguf : fix ftell/fseek for Windows (#19870)
- Regression introduced in #19856.
- This changes the
ftell/fseekcalls to use_ftelli64/_fseeki64on Windows, andftello/fseekofor POSIX systems. longon Windows is always 32-bit. Since that would cause an overflow on large files,ftell/fseekfails andnbytes_remain()returns0.
- b8155: common : add more aliases for sampler CLI params (#19797)
- Adds two CLI argument aliases for sampler parameters:
--top-n-sigma(for existing--top-nsigma)--temperature(for existing--temp)
- b8161: jinja : correct default size for string slices (#19913)
- Make sure to read the contributing guidelines before submitting a PR
- As of b8157, when trying to use string slices in a chat template, and the slice does not specify end index (e.g.
content[1 : ]), no output will be emitted since the default end index is calculated only for arrays, and remains 0 for strings. This PR adds handling for strings, and should be complete for currently supported data types. -
- b8164: llama: Add option to merge gate and exp weights (#19139)
- Continuing on #18740 and #18866, add option
--fuse_gate_up_expstoconvert_hf_to_gguf.py. - I've just added the gate_up tracking for deepseek2 (GLM 4.7 flash) and gpt-oss - although for gpt-oss we need even more changes (it goes through the
generate_extra_tensorsfor generating expert weights). This PR is not complete as we would need to add this check in all MoE models and their tensors, but putting it out there in any case. - on 5090:
- Continuing on #18740 and #18866, add option
- b8165: kv-cache : fix can_shift() check to take into account M-RoPE (#19928)
- fix #19915
- KV cache shift is not supported with M-RoPE (yet).
- b8169: ggml : fix AMX and add batched support (#19925)
- llama-perplexity -hf ggml-org/Qwen3-0.6B-GGUF:Q4_0 -f wikitext-2-raw/wiki.test.raw -c 2048 -b 2048 --chunks 2
- before this commit:
-
- b8175: ggml-cpu: add repack for mxfp4 (#19738)
- This is just a faithful copy of the
iq4_nlquant to mxfp4 with just the scale loading changed. Tested on AVX2 only, would appreciate tests on ARM and AVX512. Perplexity is already high for gpt-oss-20b but I see it is the same between master and this branch - | Model | Test | t/s master | t/s mxfp4-repack-cpu | Speedup |
- |:----------------------|:-------|-------------:|-----------------------:|----------:|
- This is just a faithful copy of the
- b8179: CUDA: add CDNA3 MFMA support for flash attention MMA kernel (#19806)
- Adds MI300X (gfx942) MFMA tensor core flash attention to
fattn-mma-f16.cuh. MI300X now routes toBEST_FATTN_KERNEL_MMA_F16instead of the tile-based fallback. - Uses
v_mfma_f32_16x16x16_f16(FP16 inputs, FP32 accumulate) with wavefront64 - Supports head sizes 64, 80, 96, 112, 128 via MMA; others fall back to VEC
- Adds MI300X (gfx942) MFMA tensor core flash attention to
- b8180: Add model metadata loading from huggingface for use with tests requiring real model data (#19796)
- This is based on the work from huggingface here:
- https://github.com/huggingface/huggingface.js/tree/main/packages/gguf
- Idea is to partially load GGUF models from huggingface, just enough to get the metadata
🚀 Performance Improvements
- b8087: opencl: refactor expm1 and softplus (#19404)
- This PR refactors the EXPM1 and Softplus OpenCL operators to improve code clarity and reduce duplication.
- b8099: powerpc: add FP16 MMA path for Q4/Q8 matmul (#19709)
- Avoid xvi8ger4pp signed→unsigned bias correction by dequantizing Q4/Q8 inputs to FP16 and using FP16×FP16→FP32 MMA. This removes post-processing overhead and improves performance.
- Performance Impact:
- 1.5 ~ 2x improvement in PP_Speed for Q4 and Q8 Models, measured with llama-bench and llama-batched-bench. Q8 Model: granite-4.0-h-micro-Q8_0.gguf (from huggingface) Q4 Model: Meta-Llama3-8b Q4 model (generated with llama-quantize from f32 model)
- b8121: Improve CUDA graph capture (#19754)
- Currently, CUDA graphs are eagerly enabled on the first call to ggml_backend_cuda_graph_compute. If the graph properties keep changing (4+ consecutive updates), the graph is permanently disabled. This is suboptimal because:
- The first call always incurs CUDA graph capture overhead even if the graph is unstable
- Once permanently disabled, CUDA graphs never re-enable even after the graph stabilizes (e.g., switching from prompt processing to decode)
🐛 Bug Fixes
- b8088: common : make small string helpers as inline functions (#19693)
- Also use string_view when it make sense and fix some corner cases.
- b8089: vulkan: split mul_mat into multiple dispatches to avoid overflow (#19509)
- The batch dimensions can be greater than the max workgroup count limit, in which case we need to split into multiple dispatches and pass the base index through a push constant.
- Fall back for the less common p021 and nc variants.
- Fixes #19471.
- b8095: ggml webgpu: Fix bug in dispatching large matrix-vector multiplication (#19535)
- Bug fix for calculating overflowing workgroup sizes for large matrix-vector multiplication batches. Should fix failures from new tests in https://github.com/ggml-org/llama.cpp/pull/19519.
- This approach isn't ideal because it may over-provision workgroups by quite a bit, a better strategy is the one proposed for Vulkan in https://github.com/ggml-org/llama.cpp/pull/19509, but this will work for now.
- b8105: CUDA: fix kernel selection logic for tile FA (#19686)
- Fixes https://github.com/ggml-org/llama.cpp/issues/19652 .
- The problem is that the kernel selection logic is slightly wrong so the host code runs into an abort.
- b8109: vulkan: fix MMQ shader push constants and multi-dispatch (#19732)
- We forgot to update the mul_mmq shader in #19509. This should fix #19710.
- b8112: common : fix gpt-oss Jinja error with content and thinking on tool-call messages (#19704)
- Erase the
contentfrom the adjusted message after copyingreasoning_contenttothinking. - Regression from #16937
- Fixes #19703.
- Erase the
- b8113: common : fix Step-3.5-Flash format detection and thinking support (#19635)
- Step-3.5-Flash (196B MoE) uses the same XML tool call output format as Qwen3-Coder and Nemotron 3 Nano (`<tool_call><function=...><parameter=...>`), but its template lacks the bare `` and plural `` markers in the tool enumeration section. The previous detection logic required all five XML markers, so Step-3.5-Flash fell through to Hermes 2 Pro, which doesn't call `func_args_not_string()`. Tool arguments stayed as JSON strings and templates using `arguments|items` crashed.
- Reported by multiple users in #19283:
- Leaked tool tokens with Codex (@tarruda)
- b8115: test: mul_mat tests with huge batch size (#19519)
- tests for #19471.
- vulkan fix is in #19509.
- b8119: hexagon : fix build release (#19444) (#19587)
- fixes: #19444
- cc: @max-krasnyansky
- b8130: common : fix improper trimming in XML parser on complete message (#19805)
- Fix courtesy of @julio75012. Although his use case has already been fixed, I'm submitting this PR to address other models that exhibit similar behavior.
- The issue is that the XML parser trims partially matched tags. The reason
>was trimmed from Seed-OSS is becausetool_sep = >, and the reason a trailing"is trimmed from MiniMax/Kimi-K2 is becausetool_sep = ">. This trimming should only happen when the message is still partial. Once the full message has been received, no trimming should occur. - Fixes #19795
- b8141: vulkan: fix data race in mul_mat_id shader (#19790)
- I've been working on automated data race detection (see https://github.com/KhronosGroup/Vulkan-ValidationLayers/pull/11717), and it found a data race in the mul_mat_id shaders. All invocations in a subgroup were storing the same value to shared memory, but this is still technically a data race. Just store on the first invocation.
- b8148: models : fix graph splits (#19866)
- fix #19860
- fix #19864
- Ensure the node order of Qwen 3.5 graphs is suitable for multi-GPU systems.
- b8156: vulkan: check for memory overlap before doing fusion (#19768)
- This fixes a class of potential fusion bugs where the destination could overwrite a source tensor while other elements of the same op still need those source values. Add some logic to compare the memory ranges and disable fusion if the bad case is detected. Some operations contribute to the destination in an elementwise fashion and can do a more relaxed check where exact overlap is allowed.
- In practice, I see this disabling TOPK_MOE fusion in some models (gpt-oss, qwen3) when there's more than one row, and this does appear to be a latent bug.
- b8157: [SYCL] Fix binbcast.cpp:200: GGML_ASSERT(s10 == 1) failed of Qwen3-Coder-Next-Q3_K_M.gguf (#19889)
- Fix issue: https://github.com/ggml-org/llama.cpp/issues/19779
- The PR (1725e316c models : optimize qwen3next graph) lead to the OP shape is changed and lead to assert.
- In binbcast ops:
- b8159: gguf : avoid too many file size calls (#19919)
- cont #19856
- fix #19912
- No need to do file calls on each read. Instead, determine the remaining bytes once at the start and after that update the value on each read.
- b8168: vulkan: fix fp16 Flash Attention on Windows AMD RDNA2 and below (#19921)
- For some reason a f16vec4 subgroupShuffleXor is broken on RDNA2 and lower. I found a workaround by shuffling vec4 instead. This also fixes fp16 Flash Attention on AMD GCN, so I removed the fp32 fallback.
- Fixes #19881 and also the issue reported here: https://github.com/ggml-org/llama.cpp/pull/19625#issuecomment-3940674420
- @masamaru-san @DeryabinIvan Please try this fix and let me know if it works for you.
- b8171: [SYCL] Replace the magic nunber 768 by max work group size to support iGPU (#19920)
- b8172: [CMake] Enable test-chat out of tree build (#19558)
- The test-chat binary relies on model files that it tries to find. However, when configuring the build directory to be parallel to the source tree those heuristics fail.
- This sets the working directory for the test executable to be the source-tree which resolves this issue.
- I validated locally with a build parallel to the source tree and nested inside the source tree.
- b8182: vendors: update miniaudio library to 0.11.24 (#19914)
- https://github.com/mackron/miniaudio/releases/tag/0.11.24.
- Fixed a possible glitch when processing the audio of a
ma_soundwhen doing resampling. - Fixed a possible crash in the node graph relating to scheduled starts and stops.
Additional Changes
27 minor improvements: 3 documentation, 19 examples, 5 maintenance.
Full Commit Range
- b8087 to b8182 (76 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8087...b8182
2026-02-18: Update to llama.cpp b8087
Summary
Updated llama.cpp from b8053 to b8087, incorporating 28 upstream commits with breaking changes, new features, and performance improvements.
Notable Changes
⚠️ Breaking Changes
- b8057: ggml-cpu: FA add GEMM microkernel (#19422)
- This PR contains the following improvements for the tiled FA kernel
- Add a simd gemm for float32 in the tiled FA kernel.
- Tune tile sizes for larger context
- b8075: Remove annoying warnings (unused functions) (#18639)
- When using common.h as a library, these function produce annoying warnings about not being used.
- Using "static" linking for these also doesn't make much sense because it potentially increases executable size with no gains.
🆕 New Features
- b8059: ggml : avoid UB in gemm ukernel + tests (#19642)
- cont #19422
- Reword the GEMM ukernel to not trip the compiler's aggressive loop optimization warnings. It's better to avoid the global pragma as it might be useful for other static analysis
- Add
test-backend-opswith BS=75 to exercise the new tiled SIMD implementation
- b8061: cmake : check if KleidiAI API has been fetched (#19640)
- This commit addresses a build issue with the KleidiAI backend when building multiple cpu backends. Commmit
- 3a00c98584e42a20675b6569d81beadb282b0952 ("cmake : fix KleidiAI install target failure with EXCLUDE_FROM_ALL") introduced a change where FetchContent_Populate is called instead of FetchContent_MakeAvailable, where the latter does handle this case (it is idempotent but FetchContent_Populate is not).
- I missed this during my review and I should not have commited without verifying the CI failure, sorry about that.
- b8068: ggml: aarch64: Implement SVE in Gemm q4_k 8x8 q8_k Kernel (#19132)
- This PR introduces support for SVE (Scalable Vector Extensions) kernels for the q4_K_q8_K gemm using i8mm and vector instructions. ARM Neon support for this kernel added in PR #16739
- Verifying Feature
----------------------------------------------------------------------------
- b8070: models : deduplicate delta-net graphs for Qwen family (#19597)
- cont #19375
- Add
llm_build_delta_net_basefor common delta net builds. Currently used only byqwen3next - Rename
llm_graph_context_mamba->llm_build_mamba_base
- b8071: Adjust workaround for ROCWMMA_FATTN/GFX9 to only newer ROCm veresions (#19591)
- Avoids issues with ROCm 6.4.4.
- Closes: https://github.com/ggml-org/llama.cpp/issues/19580
- Fixes: 6845f7f87 ("Add a workaround for compilation with ROCWMMA_FATTN and gfx9 (#19461)")
- b8073: Add support for Tiny Aya Models (#19611)
- This PR adds native support for the CohereLabs/tiny-aya family of models in llama.cpp. These models use a distinct BPE pre-tokenizer (tiny_aya) with a custom digit-grouping regex.
- Tagging @ngxson for visibility.
- b8076: feat: add proper batching to perplexity (#19661)
- This PR updates
llama-perplexityto allow for batching similarly to howllama-imatrixworks. The idea being that you can increase--batch-size/--ubatch-sizeto process multiple contexts chunks in a batch. This has limited application in VRAM-rich environments (eg, if you're running the entire model in VRAM) but it makes a huge difference when using models in a mixed CPU/GPU setup as it savesn_seqtrips from the CPU RAM to GPU VRAM per batch. - I've double-checked the before and after to make sure the resulting PPL and KLD look correct still.
-
- This PR updates
- b8077: convert_hf_to_gguf: add JoyAI-LLM-Flash tokenizer hash mapping to deepseek-v3 (#19651)
- adding hash for
jdopensource/JoyAI-LLM-Flashmapping to existingdeepseek-v3 DeepseekV3ForCausalLMarchitecture already supported- moved
GLM-4.7-Flashentry together with the otherglmentries
- adding hash for
🚀 Performance Improvements
- b8053: models : optimizing qwen3next graph (#19375)
- Rewording the ggml compute graph to avoid too many unnecessary copies.
- M2 Ultra:
- | Model | Test | t/s b7946 | t/s gg/qwen3-next-opt | Speedup |
- b8058: ggml-cpu: optimize ggml_vec_dot_bf16 for s390x (#19399)
- Similar to #18837, this pull request integrates the SIMD instruction set for BF16 on the s390x platform. We notice a 154.86% performance improvement for Prompt Processing. No performance difference was noticed for Token Generation.
- | model | size | params | backend | threads | mmap | test | t/s |
- | ------------------------------ | ---------: | ---------: | ---------- | ------: | ---: | --------------: | -------------------: |
- b8064: cuda: optimize iq2xxs/iq2xs/iq3xxs dequantization (#19624)
- While looking over quantizations I believe I found a few optimizations for iq2xxs/iq2xs/iq3xxs. With these changes, I get a 5-10% increase in flops in
test-backend-opsfor smalln, and a few extra flops otherwise: - load all 8 int8 for a grid position in one load
- calculate signs via popcnt instead of fetching from ksigns table
- While looking over quantizations I believe I found a few optimizations for iq2xxs/iq2xs/iq3xxs. With these changes, I get a 5-10% increase in flops in
- b8086: opencl: optimize mean and sum_row kernels (#19614)
- This PR optimizes the mean op and sum_rows op for the OpenCL backend.
- b8087: opencl: refactor expm1 and softplus (#19404)
- This PR refactors the EXPM1 and Softplus OpenCL operators to improve code clarity and reduce duplication.
🐛 Bug Fixes
- b8056: cmake: fix KleidiAI install target failure with EXCLUDE_FROM_ALL (#19581)
- Fix for the bug #19501 by adding
EXCLUDE_FROM_ALLto theFetchContent_Declarecall for KleidiAI. This properly excludes the KleidiAI library from both theallandinstalltargets, preventing CMake install failures when building withGGML_CPU_KLEIDIAI=ON. The KleidiAI source files are still compiled directly intolibggml-cpu.so, so functionality is preserved.
- Fix for the bug #19501 by adding
- b8060: context : fix output reorder with backend sampling (#19638)
- fix #19629
- Some of the sampling arrays could remain in invalid state after a sequence of enabling/disabling samplers.
- b8069: graph : fix KQ mask, lora, cvec reuse checks (#19644)
- cont #14482
- Graph reuse was never triggered for parallel decoding with non-unified KV cache due to incorrect check of the KQ mask shape.
- Also fix the checks for reusing lora and control vectors.
- b8071: Add a workaround for compilation with ROCWMMA_FATTN and gfx9 (#19461)
- There is an upstream problem [1] with AMD's LLVM 22 fork and rocWMMA 2.2.0 causing compilation issues on devices without native fp16 support (CDNA devices).
- The specialized types aren't resolved properly:
-
</code></pre> </li> </ul> </li> <li><strong>b8083</strong>: ggml: ggml-cpu: force-no-lto-for-cpu-feats (<a href="https://github.com/ggml-org/llama.cpp/pull/19609">#19609</a>) <ul> <li>When LTO enabled in build environments it forces all builds to have LTO in place. But feature detection logic is fragile, and causing Illegal instruction errors with lto. This disables LTO for the feature detection code to prevent cross-module optimization from inlining architecture-specific instructions into the score function. Without this, LTO can cause SIGILL when loading backends on older CPUs (e.g., loading power10 backend on power9 crashes before feature check runs).</li> <li>Please also see <a href="https://salsa.debian.org/deeplearning-team/ggml/-/merge_requests/6">https://salsa.debian.org/deeplearning-team/ggml/-/merge_requests/6</a> for more information about the issue we saw on ppc64el builds with LTO enabled in ubuntu.</li> <li><em>Make sure to read the <a href="https://github.com/ggml-org/llama.cpp/blob/master/CONTRIBUTING.md">contributing guidelines</a> before submitting a PR</em></li> </ul> </li> </ul> <h3><a href="#user-content-additional-changes-45" aria-hidden="true" class="anchor" id="user-content-additional-changes-45"></a>Additional Changes</h3> <p>8 minor improvements: 1 documentation, 3 examples, 4 maintenance.</p> <h3><a href="#user-content-full-commit-range-55" aria-hidden="true" class="anchor" id="user-content-full-commit-range-55"></a>Full Commit Range</h3> <ul> <li>b8053 to b8087 (28 commits)</li> <li>Upstream releases: <a href="https://github.com/ggml-org/llama.cpp/compare/b8053...b8087">https://github.com/ggml-org/llama.cpp/compare/b8053...b8087</a></li> </ul> <hr /> <h2><a href="#user-content-2026-02-14-update-to-llamacpp-b8040" aria-hidden="true" class="anchor" id="user-content-2026-02-14-update-to-llamacpp-b8040"></a>2026-02-14: Update to llama.cpp b8040</h2> <h3><a href="#user-content-summary-56" aria-hidden="true" class="anchor" id="user-content-summary-56"></a>Summary</h3> <p>Updated llama.cpp from b8027 to b8040, incorporating 11 upstream commits with breaking changes, new features, and performance improvements.</p> <h3><a href="#user-content-notable-changes-52" aria-hidden="true" class="anchor" id="user-content-notable-changes-52"></a>Notable Changes</h3> <h4><a href="#user-content-️-breaking-changes-25" aria-hidden="true" class="anchor" id="user-content-️-breaking-changes-25"></a>⚠️ Breaking Changes</h4> <ul> <li><strong>b8027</strong>: llama : remove deprecated codecvt (<a href="https://github.com/ggml-org/llama.cpp/pull/19565">#19565</a>) <ul> <li>Using the same conversion function ensures a consistent matching between the regex pattern and the text</li> </ul> </li> <li><strong>b8037</strong>: common : update download code (<a href="https://github.com/ggml-org/llama.cpp/pull/19573">#19573</a>) <ul> <li>This PR removes the legacy migration code for etag and forces a download if no etag file is found.</li> </ul> </li> </ul> <h4><a href="#user-content--new-features-46" aria-hidden="true" class="anchor" id="user-content--new-features-46"></a>🆕 New Features</h4> <ul> <li><strong>b8028</strong>: Kimi Linear fix conv state update (<a href="https://github.com/ggml-org/llama.cpp/pull/19531">#19531</a>) <ul> <li><em>Make sure to read the <a href="https://github.com/ggml-org/llama.cpp/blob/master/CONTRIBUTING.md">contributing guidelines</a> before submitting a PR</em></li> <li>The current implementation has incorrect conv state update such that it has state corruption when running parallel in llama-server. This is fixed in this PR.</li> <li> <pre><code>
- b8030: CUDA: Do not mutate cgraph for fused ADDs (#19566)
-
- We should try to minimize in-place changes to the incoming ggml_cgraph where possible (those should happen in a backends'
graph_optimizefunction)
- We should try to minimize in-place changes to the incoming ggml_cgraph where possible (those should happen in a backends'
-
- Modifying in-place leads to an additional, unnecessary graph capture step as we store the properties before modifying the graph in-place in the cuda-backend: We hit
ggml_cuda_graph_node_set_propertiesviaggml_cuda_graph_update_requiredbefore enteringggml_cuda_graph_evaluate_and_capture.
- Modifying in-place leads to an additional, unnecessary graph capture step as we store the properties before modifying the graph in-place in the cuda-backend: We hit
- Isolated from #19521
-
- b8036: model: support GLM MoE DSA arch (NOTE: indexer is not yet supported) (#19460)
- Ref upstream vllm PR: https://github.com/vllm-project/vllm/pull/34124
-
[!IMPORTANT]
-
This PR allows converting safetensors to GGUF while keeping the indexer tensors (for deepseek sparse attention), but they are left unused by the cpp code. The quality will be suboptimal
🚀 Performance Improvements
- b8038: vulkan: restore -inf check in FA shaders (#19582)
- For #19523.
- I verified the performance is restored with llama-batched-bench.
- b8040: hexagon: further optimizations and refactoring for flash attention (#19583)
- The PR includes some more refactoring and optimizations for flash attention op/kernel:
- Local fa_context that stores all precomputed values
- More HVX usage (hvx_vec_expf, ...)
🐛 Bug Fixes
- b8034: fix vulkan ggml_acc only works in 3d but not 4d (#19426)
- Make sure to read the contributing guidelines before submitting a PR
- Discovered ggml_acc for vulkan only works in 3d not 4d while working on
- https://github.com/ggml-org/llama.cpp/pull/18792
- b8035: ggml-cpu: arm64: Fix wrong memcpy length for q4_K block_interleave == 4 (#19575)
- https://github.com/ggml-org/llama.cpp/issues/19561 reports issues with the stack for Q4_K.
- I can't reproduce the issue locally, but the
make_block_q4_Kx8function would write past the buffer size 4 extra bytes, which could be the issue. - @taronaeo, since you found the problem, are you able to check if this patch fixes it?
Additional Changes
2 minor improvements: 1 examples, 1 maintenance.
- b8033: cli : support --verbose-prompt (#19576)
- Useful when debugging templates.
- b8032: CUDA: loop over ne2*ne3 in case it overflows (#19538)
Full Commit Range
- b8027 to b8040 (11 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b8027...b8040
2026-02-13: Update to llama.cpp b8018
Summary
Updated llama.cpp from b7958 to b8018, incorporating 44 upstream commits with breaking changes and new features.
Notable Changes
⚠️ Breaking Changes
- b8004: common : remove unused token util functions (#19506)
- This commit removes two unused functions
common_lcpandcommon_lcs. The last usage of these functions was removed in Commit 33eff4024084d1f0c8441b79f7208a52fad79858 ("server : vision support via libmtmd") and are no longer used anywhere in the codebase.
- This commit removes two unused functions
- b8007: common : replace deprecated codecvt using parse_utf8_codepoint (#19517)
🆕 New Features
- b7964: Support Step3.5-Flash (#19283)
- This PR adds support for the Step3.5-Flash model architecture.
- github:
- https://github.com/stepfun-ai/Step-3.5-Flash/tree/main
- b7966: metal : consolidate bin kernels (#19390)
- Refactor and consolidate the implementation of the binary Metal kernels.
- | Model | Test | t/s master | t/s gg/metal-bin-opt | Speedup |
- |:-------------------------|:-------|-------------:|-----------------------:|----------:|
- b7972: CUDA: Fix non-contig rope (#19338)
- This is a port of https://github.com/ggml-org/llama.cpp/pull/19299 to the CUDA backend, which should fix the broken logic revealed by tests added in https://github.com/ggml-org/llama.cpp/pull/19296
- Thanks @jeffbolznv for the work in #19299
- b7973: [Model] Qwen3.5 dense and MoE support (no vision) (#19435)
- I've gotten a bit tired of Llama.cpp missing all the zero-day releases, so this time I decided to make (or, more precisely, instructed Opus 4.6 to make, based on reference implementations and my guidelines for model adaptation) a conversion based on the Transformers PR ( https://github.com/huggingface/transformers/pull/43830/changes ). It's mostly based on Qwen3Next, but it's rebased on the common-delta-net PR ( #19125 ).
- Here are the mock models I generated to test it: https://huggingface.co/ilintar/qwen35_testing/tree/main
- Here are the conversion results from
causal-verify-logits:
- b7974: cmake: add variable to skip installing tests (#19370)
- When packaging downstream, there's usually little point in installing test. The default behaviour remains the same.
- b7976: [Model] Qwen3.5 dense and MoE support (no vision) (#19435)
- I've gotten a bit tired of Llama.cpp missing all the zero-day releases, so this time I decided to make (or, more precisely, instructed Opus 4.6 to make, based on reference implementations and my guidelines for model adaptation) a conversion based on the Transformers PR ( https://github.com/huggingface/transformers/pull/43830/changes ). It's mostly based on Qwen3Next, but it's rebased on the common-delta-net PR ( #19125 ).
- Here are the mock models I generated to test it: https://huggingface.co/ilintar/qwen35_testing/tree/main
- Here are the conversion results from
causal-verify-logits:
- b7976: revert : "[Model] Qwen3.5 dense and MoE support (no vision) (#19435)" (#19453)
- cont #19435
- Taking a step back to implement support for Qwen3.5 properly.
- b7981: chat: fix case where template accepts type content only (#19419)
- Fix chat template of PaddleOCR-VL, which requires content to be an array (see https://github.com/ggml-org/llama.cpp/pull/18825)
- This should be able to handle these case:
- Template supports ONLY string content
- b7982: cuda : extend GGML_OP_PAD to work with non-cont src0 (#19429)
- Extend CUDA support
- Remove redundant assert in CPU implementation
- Add permuted PAD tests
- b7983: CANN: Support MUL_MAT_ID in ACL graph (#19228)
- Implement ggml_cann_mul_mat_id_quant function to support quantized matrix
- multiplication for Mixture of Experts (MoE) architectures on CANN backend.
- Key features:
- b7988: ggml-cpu: arm64: q6_K repack gemm and gemv (and generic) implementations (dotprod) (#19360)
- https://github.com/ggml-org/llama.cpp/pull/19356 but Q6_K.
- PR contents:
- New generics for q6_K_8x4
- b7991: [WebGPU] Plug memory leaks and free resources on shutdown (#19315)
- This diff destroys
wgpu::Buffers and buffer pools on shutdown. It also fixes memory leaks on the heap, where we allocatebackend,backend_ctx,buffer_ctx, anddecisionson the heap but never delete them. These are either explicitly deleted or changed to be smart pointers. - We implement destructors for our buffer pool structs,
webgpu_contextstruct andwebgpu_global_contextstruct. Sincewebgpu_global_contextis a refcounted smart pointer, it will destruct automatically when all thread contexts have been destroyed. -
- This diff destroys
- b7992: CUDA: Update CCCL-tag for 3.2 to final release from RC (#19486)
- [CCCL 3.2 has been released](https://github.com/NVIDIA/cccl/releases/tag/v3.2.0
- ) since it was added to llama.cpp as part of the backend-sampling PR (#17004), and it makes sense to update from RC to final released version.
- b7994: metal : consolidate unary ops (#19490)
- cont #19390
- Common implementation of the unary kernels
- Extend support for non-cont src0
- b7995: ggml : extend bin bcast for permuted src1 (#19484)
- Remove CPU asserts preventing
src1from being permuted - Update CUDA kernels to support permuted
src1 - Add tests to exercise
src1permutation
- Remove CPU asserts preventing
- b7998: hexagon: Add ARGSORT, DIV, SQR, SQRT, SUM_ROWS, GEGLU (#19406)
- Catching up on the Op coverage for the Hexagon backend.
- This PR improves Op coverage for Gemma-3N, LFM2 and other models.
- All new Ops pass
test-backend-ops(mostly in f32).
- b8001: metal : extend l2_norm support for non-cont src0 (#19502)
- Support non-cont
src0 - Support
ne00non-multiple of 4
- Support non-cont
- b8005: ggml : unary ops support non-cont src0 + metal F16 unary ops (#19511)
- cont #19490
- b8006: opencl: add general Q6_K mm and Q4_K mv (#19347)
- Although still slow, this should make Q4_K_M a bit more usable. Q4_K mv is not flattened yet. More specialized Q6_K and Q4_K mm and mv using transposed layouts will be added in follow up PRs.
- b8008: hexagon: further optimization and tuning of matmul and dot kernels (#19407)
- This PR adds support for computing 2x2 (2 rows x 2 cols) dot products in parallel.
- Mostly helps with the Prompt processing that shows 10+ T/S gains for most models.
- Here are some numbers with Qwen3.
- b8012: metal : update sum_rows kernel to support float4 (#19524)

🐛 Bug Fixes
- b7958: MSVC regex fix (#19340)
- Fix MSVC regex error:
-
- Regex error: regex_error(error_stack): There was insufficient memory to determine whether the regular expression could match the specified character sequence.
- b7965: metal : fix event synchronization in cpy_tensor_async (#19402)
- cont #18966
- Was incorrectly recording the event in a separate command buffer. Fixes the synchronization issue reported in https://github.com/ggml-org/llama.cpp/pull/19378#issuecomment-3862086179
- b7987: ggml: use noexcept overload for is_regular_file in backend registration (#19452)
- using noexcept std::filesystem::directory_entry::is_regular_file overload prevents abnormal termination upon throwing an error (as caused by symlinks to non-existant folders on linux)
- fixes issue #18560
- Searched for existing PRs for this issue
- b7989: test: fix IMROPE perf test case (#19465)
- b7997: fix: correct typos 'occured' and 'occurences' (#19414)
- Fixes minor spelling typos in comments:
- occurred (1 instance in llama.h)
- occurrences (3 instances in ngram-map.h and ngram-map.cpp)
- b7999: common : improve download error reporting (#19491)
- While debugging the new
cpp-httplib, the current errors were unusable... - Here is a small patch to make life easier for the next person dealing with HTTP issues :)
- While debugging the new
- b8011: Add a workaround for compilation with ROCWMMA_FATTN and gfx9 (#19461)
- There is an upstream problem [1] with AMD's LLVM 22 fork and rocWMMA 2.2.0 causing compilation issues on devices without native fp16 support (CDNA devices).
- The specialized types aren't resolved properly:
-
</code></pre> </li> </ul> </li> <li><strong>b8018</strong>: vendor : update cpp-httplib (<a href="https://github.com/ggml-org/llama.cpp/pull/19537">#19537</a>) <ul> <li>The 0.32 version had important bug fixes, but it wasn’t working for us. We need the latest patches.</li> </ul> </li> </ul> <h3><a href="#user-content-additional-changes-47" aria-hidden="true" class="anchor" id="user-content-additional-changes-47"></a>Additional Changes</h3> <p>13 minor improvements: 3 documentation, 7 examples, 3 maintenance.</p> <h3><a href="#user-content-full-commit-range-57" aria-hidden="true" class="anchor" id="user-content-full-commit-range-57"></a>Full Commit Range</h3> <ul> <li>b7958 to b8018 (44 commits)</li> <li>Upstream releases: <a href="https://github.com/ggml-org/llama.cpp/compare/b7958...b8018">https://github.com/ggml-org/llama.cpp/compare/b7958...b8018</a></li> </ul> <hr /> <h2><a href="#user-content-2026-02-06-update-to-llamacpp-b7955" aria-hidden="true" class="anchor" id="user-content-2026-02-06-update-to-llamacpp-b7955"></a>2026-02-06: Update to llama.cpp b7955</h2> <h3><a href="#user-content-summary-58" aria-hidden="true" class="anchor" id="user-content-summary-58"></a>Summary</h3> <p>Updated llama.cpp from b7926 to b7955, incorporating 24 upstream commits with breaking changes, new features, and performance improvements.</p> <h3><a href="#user-content-notable-changes-54" aria-hidden="true" class="anchor" id="user-content-notable-changes-54"></a>Notable Changes</h3> <h4><a href="#user-content-️-breaking-changes-27" aria-hidden="true" class="anchor" id="user-content-️-breaking-changes-27"></a>⚠️ Breaking Changes</h4> <ul> <li><strong>b7931</strong>: ggml-virtgpu: make the code thread safe (<a href="https://github.com/ggml-org/llama.cpp/pull/19204">#19204</a>) <ul> <li>This PR improves the code of the ggml-virtgpu backend to make it thread safe, by using mutex for accessing the host<>guest shared memory buffers, and by pre-caching, during the initialization, the constant values queried from the backend.</li> <li>The unused <code>buffer_type_is_host</code> method is also deprecated.</li> </ul> </li> <li><strong>b7933</strong>: spec : fix the check-rate logic of ngram-simple (<a href="https://github.com/ggml-org/llama.cpp/pull/19261">#19261</a>) <ul> <li>fix #19231</li> <li>For the <code>spec-simple</code> method, we don't need to keep track of the last length to rate-limit the generations. We can simply use an incremental counter. This makes the speculator work with "Regenerate" of last message or branching the conversation from previous messages.</li> <li>Also, removed <code>struct common_ngram_simple_state</code> - seemed a bit redundant.</li> </ul> </li> </ul> <h4><a href="#user-content--new-features-48" aria-hidden="true" class="anchor" id="user-content--new-features-48"></a>🆕 New Features</h4> <ul> <li><strong>b7928</strong>: ci : add sanitizer runs for server (<a href="https://github.com/ggml-org/llama.cpp/pull/19291">#19291</a>) <ul> <li>Reenable the server sanitizer builds + runs. The thread sanitizer is quite slow, so remains disabled for now.</li> <li><a href="https://github.com/ggerganov/tmp2/actions/runs/21629674042">https://github.com/ggerganov/tmp2/actions/runs/21629674042</a></li> </ul> </li> <li><strong>b7929</strong>: metal : add solve_tri (<a href="https://github.com/ggml-org/llama.cpp/pull/19302">#19302</a>) <ul> <li>Add <code>GGML_OP_SOLVE_TRI</code> implementation for Metal.</li> <li>| Model | Test | t/s master | t/s gg/metal-solve-tri | Speedup |</li> <li>|:-----------------------|:-------|-------------:|-------------------------:|----------:|</li> </ul> </li> <li><strong>b7935</strong>: tests : add non-cont, inplace rope tests (<a href="https://github.com/ggml-org/llama.cpp/pull/19296">#19296</a>) <ul> <li>ref <a href="https://github.com/ggml-org/llama.cpp/pull/18986#issuecomment-3841942982">https://github.com/ggml-org/llama.cpp/pull/18986#issuecomment-3841942982</a></li> <li>ref <a href="https://github.com/ggml-org/llama.cpp/issues/19128#issuecomment-3807441909">https://github.com/ggml-org/llama.cpp/issues/19128#issuecomment-3807441909</a></li> <li>ref <a href="https://github.com/ggml-org/llama.cpp/issues/19292">https://github.com/ggml-org/llama.cpp/issues/19292</a></li> </ul> </li> <li><strong>b7941</strong>: vendor : add missing llama_add_compile_flags (<a href="https://github.com/ggml-org/llama.cpp/pull/19322">#19322</a>) <ul> <li><del>Hopefully fixes CI</del>Ensure <code>httplib</code> and <code>boringssl</code>/<code>libressl</code> are built with sanitizer options, see <a href="https://github.com/ggml-org/llama.cpp/pull/19291#discussion_r2761613566">https://github.com/ggml-org/llama.cpp/pull/19291#discussion_r2761613566</a></li> </ul> </li> <li><strong>b7946</strong>: metal : add diag (<a href="https://github.com/ggml-org/llama.cpp/pull/19330">#19330</a>) <ul> <li>Add implementation for GGML_OP_DIAG for the Metal backend</li> </ul> </li> </ul> <h4><a href="#user-content--performance-improvements-30" aria-hidden="true" class="anchor" id="user-content--performance-improvements-30"></a>🚀 Performance Improvements</h4> <ul> <li><strong>b7930</strong>: ggml-cpu: use LUT for converting e8->f32 scales on x86 (<a href="https://github.com/ggml-org/llama.cpp/pull/19288">#19288</a>) <ul> <li><code>perf</code> showed the e8m0->f32 function as a bottleneck. Use a LUT instead. Tested only on x86</li> <li>| Model | Test | t/s topk-cuda-refactor | t/s mxfp4-cpu-scale | Speedup |</li> <li>|:----------------------|:-------|-------------------------:|----------------------:|----------:|</li> </ul> </li> <li><strong>b7951</strong>: metal : adaptive CPU/GPU interleave based on number of nodes (<a href="https://github.com/ggml-org/llama.cpp/pull/19369">#19369</a>) <ul> <li>Put a bit more work on the main thread when encoding the graph. This helps to interleave better the CPU/GPU work, especially for larger graphs.</li> <li>| Model | Test | t/s master | t/s gg/metal-adaptive-cpu-interleave | Speedup |</li> <li>|:-------------------------|:-------|-------------:|---------------------------------------:|----------:|</li> </ul> </li> <li><strong>b7954</strong>: metal : skip loading all-zero mask (<a href="https://github.com/ggml-org/llama.cpp/pull/19337">#19337</a>) <ul> <li>Similar optimization as in #19281 to skip loading the all-zero mask blocks.</li> <li>| Model | Test | t/s master | t/s gg/metal-fa-mask-zero-opt | Speedup |</li> <li>|:----------------------|:--------|-------------:|--------------------------------:|----------:|</li> </ul> </li> </ul> <h4><a href="#user-content--bug-fixes-44" aria-hidden="true" class="anchor" id="user-content--bug-fixes-44"></a>🐛 Bug Fixes</h4> <ul> <li><strong>b7926</strong>: vulkan: disable coopmat1 flash attention on Nvidia Turing (<a href="https://github.com/ggml-org/llama.cpp/pull/19290">#19290</a>) <ul> <li>See <a href="https://github.com/ggml-org/llama.cpp/pull/19075#issuecomment-3820716090">https://github.com/ggml-org/llama.cpp/pull/19075#issuecomment-3820716090</a></li> </ul> </li> <li><strong>b7927</strong>: sampling : delegate input allocation to the scheduler (<a href="https://github.com/ggml-org/llama.cpp/pull/19266">#19266</a>) <ul> <li>fix #18622</li> <li>alt #18636</li> <li>Merge the sampler inputs into the main graph. This way the backend scheduler is responsible for allocating the memory which makes backend sampling compatible with pipeline parallelism</li> </ul> </li> <li><strong>b7936</strong>: model: (qwen3next) correct vectorized key_gdiff calculation (<a href="https://github.com/ggml-org/llama.cpp/pull/19324">#19324</a>) <ul> <li>Testing with the provided prompt from <a href="https://github.com/ggml-org/llama.cpp/issues/19305">https://github.com/ggml-org/llama.cpp/issues/19305</a></li> <li> <img width="837" height="437" alt="image" src="https://github.com/user-attachments/assets/54f19beb-a9d0-4f10-bc33-747057f36fe7" /> </li> </ul> </li> <li><strong>b7938</strong>: debug: make common_debug_print_tensor readable (<a href="https://github.com/ggml-org/llama.cpp/pull/19331">#19331</a>) <ul> <li>Now using 4-space indentation</li> <li>The log is output to stdout, so that I can do <code>llama-eval-callback ... > debug.log</code></li> <li> <pre><code>
- b7940: vendor: update cpp-httplib version (#19313)
- ref: #19017
- Sync the
cpp-httpliblibrary to fix #19017.
- b7942: Fix missing includes in metal build (#19348)
- Since commit https://github.com/ggml-org/llama.cpp/commit/6fdddb498780dbda2a14f8b49b92d25601e14764, I get errors when building on Mac.
- This PR adds the missing includes for
mutexandstringto fix the build. -
- b7943: vulkan: fix non-contig rope (#19299)
- For #19296.
- b7945: vulkan: fix GPU deduplication logic. (#19222)
- As reported in https://github.com/ggml-org/llama.cpp/issues/19221, the (same uuid, same driver) logic is problematic for windows+intel igpu.
- Let's just avoid filtering for MoltenVK which is apple-specific, and keep the logic the same as before 88d23ad5 - just dedup based on UUID.
- Verified that MacOS + 4xVega still reports 4 GPUs with this version.
- b7952: cuda : cuda graphs now compare all node params (#19383)
- ref https://github.com/ggml-org/llama.cpp/pull/19338#issuecomment-3852298933
- This should fix the CUDA graph usage logic when the ops have variable op params. This issue is most pronounced during
test-backend-ops.
Additional Changes
5 minor improvements: 1 examples, 4 maintenance.
- b7932: completion : simplify batch (embd) processing (#19286)
- This commit simplifies the processing of embd by removing the for loop that currently exists which uses params.n_batch as its increment. This commit also removes the clamping of n_eval as the size of embd is always at most the size of params.n_batch.
- The motivation is to clarify the code as it is currently a little confusing when looking at this for loop in isolation and thinking that it can process multiple batches.
- b7944: vulkan: Set k_load_shmem to false when K is too large (#19301)
- See https://github.com/ggml-org/llama.cpp/pull/19075/changes#r2726146004.
-
- Z:\github\jeffbolznv\llama.cpp\build\bin\RelWithDebInfo>llama-bench.exe -fa 1 -m c:\models\GLM-4.7-Flash-Q4_K_M.gguf -p 512 -n 128 -d 0,4096,16384
- b7947: vendor : update BoringSSL to 0.20260204.0 (#19333)
- b7950: vulkan: Preprocess FA mask to detect all-neg-inf and all-zero. (#19281)
- Write out a 2-bit code per block and avoid loading the mask when it matches these two common cases.
- Apply this optimization when the mask is relatively large (i.e. prompt processing).
-
- b7955: vulkan: make FA mask/softcap enables spec constants (#19309)
This is stacked on #19281.(merged)- This allows the compiler to do a bit better at overlapping loads and math (e.g. loading V can start while computing Q*K^t is still happening). Worth a couple percent for coopmat2, less for coopmat1/scalar.
-
Full Commit Range
- b7926 to b7955 (24 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b7926...b7955
2026-02-03: Update to llama.cpp b7921
Summary
Updated llama.cpp from b7907 to b7921, incorporating 11 upstream commits with new features.
Notable Changes
🆕 New Features
- b7907: ggml-backend: fix async set/get fallback sync (#19179)
- While working on an implementation for backend-agnostic tensor parallelism I found what I believe to be a bug in the ggml backend code. For a minimal implementation I did at first not implement
set_tensor_asyncandget_tensor_asyncassuming that I could just rely on the synchronous fallback and implement those later. However,set_tensor_asyncandget_tensor_asyncdo not callggml_backend_synchronizefor their fallback so I got incorrect results. This PR adds the corresponding calls.
- While working on an implementation for backend-agnostic tensor parallelism I found what I believe to be a bug in the ggml backend code. For a minimal implementation I did at first not implement
- b7909: metal : support virtual devices (#18919)
- Support virtual Metal devices. Allows simulating multi-GPU environments on Mac using the new
GGML_METAL_DEVICESenvironment variable. -
</code></pre> </li> <li>GGML_METAL_DEVICES=4 ./bin/llama-completion -m [model.gguf]</li> </ul> </li> <li><strong>b7919</strong>: support infill for Falcon-H1-Tiny-Coder (<a href="https://github.com/ggml-org/llama.cpp/pull/19249">#19249</a>) <ul> <li>Added FIM tokens used in Falcon-H1-Tiny-Coder (see <a href="https://tiiuae-tiny-h1-blogpost.hf.space/#fim-format">https://tiiuae-tiny-h1-blogpost.hf.space/#fim-format</a>, <a href="https://huggingface.co/tiiuae/Falcon-H1-Tiny-Coder-90M/blob/main/tokenizer_config.json#L1843">https://huggingface.co/tiiuae/Falcon-H1-Tiny-Coder-90M/blob/main/tokenizer_config.json#L1843</a>) to make the llama-server <code>POST /infill</code> handle work.</li> </ul> </li> <li><strong>b7921</strong>: ggml: added cleanups in ggml_quantize_free (<a href="https://github.com/ggml-org/llama.cpp/pull/19278">#19278</a>) <ul> <li>Add missing cleanup calls for IQ2_S, IQ1_M quantization types and IQ3XS with 512 blocks during quantization cleanup.</li> </ul> </li> </ul> <h4><a href="#user-content--bug-fixes-45" aria-hidden="true" class="anchor" id="user-content--bug-fixes-45"></a>🐛 Bug Fixes</h4> <ul> <li><strong>b7917</strong>: opencl: refactor some ops, concat, repeat, tanh and scale (<a href="https://github.com/ggml-org/llama.cpp/pull/19226">#19226</a>) <ul> <li>Gemma-3n-E2B and Gemma-3n-E4B have been producing weird (not really gibberish but apparently not correct) output. Ended up refactoring these ops and the issue is now fixed. In addition, this refactor also improves perf a bit.</li> <li>On X Elite,</li> <li><code>gemma-3n-E2B-it-Q8_0</code>,</li> </ul> </li> </ul> <h3><a href="#user-content-additional-changes-49" aria-hidden="true" class="anchor" id="user-content-additional-changes-49"></a>Additional Changes</h3> <p>6 minor improvements: 4 documentation, 1 examples, 1 maintenance.</p> <h3><a href="#user-content-full-commit-range-59" aria-hidden="true" class="anchor" id="user-content-full-commit-range-59"></a>Full Commit Range</h3> <ul> <li>b7907 to b7921 (11 commits)</li> <li>Upstream releases: <a href="https://github.com/ggml-org/llama.cpp/compare/b7907...b7921">https://github.com/ggml-org/llama.cpp/compare/b7907...b7921</a></li> </ul> <hr /> <h2><a href="#user-content-2026-02-02-update-to-llamacpp-b7907" aria-hidden="true" class="anchor" id="user-content-2026-02-02-update-to-llamacpp-b7907"></a>2026-02-02: Update to llama.cpp b7907</h2> <h3><a href="#user-content-summary-60" aria-hidden="true" class="anchor" id="user-content-summary-60"></a>Summary</h3> <p>Updated llama.cpp from b7885 to b7907, incorporating 14 upstream commits with breaking changes and new features.</p> <h3><a href="#user-content-notable-changes-56" aria-hidden="true" class="anchor" id="user-content-notable-changes-56"></a>Notable Changes</h3> <h4><a href="#user-content-️-breaking-changes-28" aria-hidden="true" class="anchor" id="user-content-️-breaking-changes-28"></a>⚠️ Breaking Changes</h4> <ul> <li><strong>b7903</strong>: Remove pipeline cache mutexes (<a href="https://github.com/ggml-org/llama.cpp/pull/19195">#19195</a>) <ul> <li>Now that <code>webgpu_context</code> is per-thread, we can remove mutexes from pipeline caches. We cannot remove mutexes from <code>webgpu_buf_pool</code> since they are allocated and freed in callback threads, and we cannot remove the mutex from the memset buffer pool since it is shared by all ggml buffers.</li> </ul> </li> </ul> <h4><a href="#user-content--new-features-50" aria-hidden="true" class="anchor" id="user-content--new-features-50"></a>🆕 New Features</h4> <ul> <li><strong>b7885</strong>: tests : add GQA=20 FA test (<a href="https://github.com/ggml-org/llama.cpp/pull/19095">#19095</a>) <ul> <li>Might be a good idea to have a test that exercises GQA=20 in order to catch any potential regressions.</li> </ul> </li> <li><strong>b7895</strong>: lookahead : add example for lookahead decoding (<a href="https://github.com/ggml-org/llama.cpp/pull/4207">#4207</a>) <ul> <li>ref #4157</li> <li>Think this should implement the approach from: <a href="https://lmsys.org/blog/2023-11-21-lookahead-decoding/">https://lmsys.org/blog/2023-11-21-lookahead-decoding/</a></li> <li>The approach requires large batches to be decoded, which in turn requires a lot of FLOPS even for single stream</li> </ul> </li> <li><strong>b7895</strong>: Prompt lookup decoding (<a href="https://github.com/ggml-org/llama.cpp/pull/4484">#4484</a>) <ul> <li>ref #4226</li> <li>This example implements the "Prompt Lookup Decoding" technique:</li> <li><a href="https://github.com/apoorvumang/prompt-lookup-decoding">https://github.com/apoorvumang/prompt-lookup-decoding</a></li> </ul> </li> <li><strong>b7898</strong>: ggml-hexagon: flash-attention and reduce-sum optimizations (<a href="https://github.com/ggml-org/llama.cpp/pull/19141">#19141</a>) <ul> <li>Further to the discussion in <a href="vscode-file://vscode-app/f:/Download/OneDrive/sync/tools/editor/VSCode/resources/app/out/vs/code/electron-browser/workbench/workbench.html">PR #19025</a>, this implements the dual row dot product for flash attention.</li> <li>Added <code>hvx_vec_reduce_sum_qf32x2</code>, a helper function for efficiently reducing and accumulating two HVX vectors of qf32 values, and refactored several places in the codebase to use this function for dual-accumulation scenarios. <a href="diffhunk://#diff-a61b8b4ec9b687ceb6adecb4f2de734f398493514475aa35a2ed1697d58e8a78R47-R57">[1]</a> <a href="diffhunk://#diff-9469cc7ef405748e1379a215fd377726746ae6087c02d975042955268ea40870L468-R469">[2]</a> <a href="diffhunk://#diff-9469cc7ef405748e1379a215fd377726746ae6087c02d975042955268ea40870L641-R639">[3]</a> <a href="diffhunk://#diff-9469cc7ef405748e1379a215fd377726746ae6087c02d975042955268ea40870L883-R878">[4]</a> <a href="diffhunk://#diff-9469cc7ef405748e1379a215fd377726746ae6087c02d975042955268ea40870L960-R952">[5]</a></li> <li>Introduced new "rx2" (dual accumulation) versions of dot product functions for both f32-f16 and f16-f16 cases (<code>hvx_dot_f32_f16_aa_rx2</code>, <code>hvx_dot_f16_f16_aa_rx2</code>), improving performance by processing two accumulations in parallel. <a href="diffhunk://#diff-703a5dfdf5d9711789e72c854d70db2559000749823e0cb8fa9defc4b276e7b8R76-R139">[1]</a> <a href="diffhunk://#diff-703a5dfdf5d9711789e72c854d70db2559000749823e0cb8fa9defc4b276e7b8R180-R233">[2]</a></li> </ul> </li> <li><strong>b7907</strong>: ggml-backend: fix async set/get fallback sync (<a href="https://github.com/ggml-org/llama.cpp/pull/19179">#19179</a>) <ul> <li>While working on an implementation for backend-agnostic tensor parallelism I found what I believe to be a bug in the ggml backend code. For a minimal implementation I did at first not implement <code>set_tensor_async</code> and <code>get_tensor_async</code> assuming that I could just rely on the synchronous fallback and implement those later. However, <code>set_tensor_async</code> and <code>get_tensor_async</code> do not call <code>ggml_backend_synchronize</code> for their fallback so I got incorrect results. This PR adds the corresponding calls.</li> </ul> </li> </ul> <h4><a href="#user-content--bug-fixes-46" aria-hidden="true" class="anchor" id="user-content--bug-fixes-46"></a>🐛 Bug Fixes</h4> <ul> <li><strong>b7895</strong>: llama : adjust default context size + print warnings (<a href="https://github.com/ggml-org/llama.cpp/pull/10136">#10136</a>) <ul> <li>fix #8817, <a href="https://github.com/ggerganov/llama.cpp/issues/9563#issuecomment-2452727620">https://github.com/ggerganov/llama.cpp/issues/9563#issuecomment-2452727620</a></li> <li>By default, the examples will use a context size of 4096, instead of the training context of the model. In a lot of cases, the default training context can be very big - 32k to 128k tokens, which causes enormous KV cache allocation and failures for regular hardware.</li> <li>Also, add warning logs when the specified context size per sequence does not match the training context.</li> </ul> </li> </ul> <h3><a href="#user-content-additional-changes-50" aria-hidden="true" class="anchor" id="user-content-additional-changes-50"></a>Additional Changes</h3> <p>7 minor improvements: 3 documentation, 4 examples.</p> <h3><a href="#user-content-full-commit-range-60" aria-hidden="true" class="anchor" id="user-content-full-commit-range-60"></a>Full Commit Range</h3> <ul> <li>b7885 to b7907 (14 commits)</li> <li>Upstream releases: <a href="https://github.com/ggml-org/llama.cpp/compare/b7885...b7907">https://github.com/ggml-org/llama.cpp/compare/b7885...b7907</a></li> </ul> <hr /> <h2><a href="#user-content-2026-01-30-update-to-llamacpp-b7885" aria-hidden="true" class="anchor" id="user-content-2026-01-30-update-to-llamacpp-b7885"></a>2026-01-30: Update to llama.cpp b7885</h2> <h3><a href="#user-content-summary-61" aria-hidden="true" class="anchor" id="user-content-summary-61"></a>Summary</h3> <p>Updated llama.cpp from b7871 to b7885, incorporating 9 upstream commits with breaking changes and new features.</p> <h3><a href="#user-content-notable-changes-57" aria-hidden="true" class="anchor" id="user-content-notable-changes-57"></a>Notable Changes</h3> <h4><a href="#user-content-️-breaking-changes-29" aria-hidden="true" class="anchor" id="user-content-️-breaking-changes-29"></a>⚠️ Breaking Changes</h4> <ul> <li><strong>b7872</strong>: jinja : do not pass empty tools and add some none filters (<a href="https://github.com/ggml-org/llama.cpp/pull/19176">#19176</a>) <ul> <li>Passing empty or null <code>tools</code> breaks many templates so avoid that.</li> <li>Added several filters to <code>none</code> that are accepted by <code>jinja2</code>, fixes some templates that will try to use them (like <code>Functionary</code>).</li> <li>Fixes #19155</li> </ul> </li> <li><strong>b7883</strong>: memory : remove unused tmp_buf (<a href="https://github.com/ggml-org/llama.cpp/pull/19199">#19199</a>) <ul> <li>This commit removes the unused tmp_buf variable from llama-kv-cache.cpp and llama-memory-recurrent.cpp.</li> <li>The tmp_buf variable was declared but never used but since it has a non-trivial constructor/desctuctor we don't get an unused variable warning about it.</li> </ul> </li> </ul> <h4><a href="#user-content--new-features-51" aria-hidden="true" class="anchor" id="user-content--new-features-51"></a>🆕 New Features</h4> <ul> <li><strong>b7871</strong>: HIP: add mmf for CDNA (<a href="https://github.com/ggml-org/llama.cpp/pull/18896">#18896</a>) <ul> <li>Add mmf for CDNA, CDNA3 is passed, it will be very helpful if anyone can test it on CDNA2 and CDNA1, thank you.</li> <li><input type="checkbox" checked="" disabled="" /> Refactor mmf to make rows_per_block as input parameter.</li> <li><input type="checkbox" checked="" disabled="" /> Pass MUL_MAT and MUL_MAT_ID.</li> </ul> </li> <li><strong>b7881</strong>: add tensor type checking as part of cuda graph properties (<a href="https://github.com/ggml-org/llama.cpp/pull/19186">#19186</a>) <ul> <li>Motivated by <a href="https://github.com/ggml-org/llama.cpp/pull/15805#issuecomment-3818986820">https://github.com/ggml-org/llama.cpp/pull/15805#issuecomment-3818986820</a></li> </ul> </li> <li><strong>b7885</strong>: tests : add GQA=20 FA test (<a href="https://github.com/ggml-org/llama.cpp/pull/19095">#19095</a>) <ul> <li>Might be a good idea to have a test that exercises GQA=20 in order to catch any potential regressions.</li> </ul> </li> </ul> <h4><a href="#user-content--bug-fixes-47" aria-hidden="true" class="anchor" id="user-content--bug-fixes-47"></a>🐛 Bug Fixes</h4> <ul> <li><strong>b7875</strong>: cuda : fix nkvo, offload and cuda graph node properties matching (<a href="https://github.com/ggml-org/llama.cpp/pull/19165">#19165</a>) <ul> <li>fix #19158</li> <li>fix #19169</li> <li>cont #19105</li> </ul> </li> </ul> <h3><a href="#user-content-additional-changes-51" aria-hidden="true" class="anchor" id="user-content-additional-changes-51"></a>Additional Changes</h3> <p>3 minor improvements: 3 documentation.</p> <ul> <li><strong>b7876</strong>: hexagon: enable offloading to Hexagon on Windows on Snapdragon (<a href="https://github.com/ggml-org/llama.cpp/pull/19150">#19150</a>) <ul> <li>GGML Hexagon backend updates to support Windows on Snapdragon.</li> <li>Features:</li> <li>Support for building and offloading to NPU on WoS.</li> </ul> </li> <li><strong>b7879</strong>: sycl: implement GGML_OP_TRI (<a href="https://github.com/ggml-org/llama.cpp/pull/19089">#19089</a>) <ul> <li>Implements GGML_OP_TRI for the SYCL backend (F32).</li> <li>The implementation matches CPU semantics for all ggml_tri_type values</li> <li>(lower/upper, with and without diagonal).</li> </ul> </li> <li><strong>b7880</strong>: sycl: implement GGML_UNARY_OP_SOFTPLUS (<a href="https://github.com/ggml-org/llama.cpp/pull/19114">#19114</a>) <ul> <li>Implements GGML_UNARY_OP_SOFTPLUS for the SYCL backend.</li> <li>Adds an element-wise softplus kernel integrated through the generic SYCL unary dispatch path.</li> <li>Numerical behavior matches the CPU backend implementation.</li> </ul> </li> </ul> <h3><a href="#user-content-full-commit-range-61" aria-hidden="true" class="anchor" id="user-content-full-commit-range-61"></a>Full Commit Range</h3> <ul> <li>b7871 to b7885 (9 commits)</li> <li>Upstream releases: <a href="https://github.com/ggml-org/llama.cpp/compare/b7871...b7885">https://github.com/ggml-org/llama.cpp/compare/b7871...b7885</a></li> </ul> <hr /> <h2><a href="#user-content-2026-01-29-update-to-llamacpp-b7871" aria-hidden="true" class="anchor" id="user-content-2026-01-29-update-to-llamacpp-b7871"></a>2026-01-29: Update to llama.cpp b7871</h2> <h3><a href="#user-content-summary-62" aria-hidden="true" class="anchor" id="user-content-summary-62"></a>Summary</h3> <p>Updated llama.cpp from b7847 to b7871, incorporating 22 upstream commits with breaking changes, new features, and performance improvements.</p> <h3><a href="#user-content-notable-changes-58" aria-hidden="true" class="anchor" id="user-content-notable-changes-58"></a>Notable Changes</h3> <h4><a href="#user-content-️-breaking-changes-30" aria-hidden="true" class="anchor" id="user-content-️-breaking-changes-30"></a>⚠️ Breaking Changes</h4> <ul> <li><strong>b7850</strong>: ggml-zendnn : update ZenDNN git tag to main branch (<a href="https://github.com/ggml-org/llama.cpp/pull/19133">#19133</a>) <ul> <li>This PR is related to ZenDNN removed their zendnnl branch and moved all the code to main</li> <li>Right now our code is still looking for the old zendnnl branch which no longer exists, so builds break.</li> <li>This fixes it by pointing to the new main branch instead</li> </ul> </li> <li><strong>b7852</strong>: sampling : remove sampling branching in output_reserve (<a href="https://github.com/ggml-org/llama.cpp/pull/18811">#18811</a>) <ul> <li>This commit updates output_reserve in llama-context.cpp to always allocate sampling buffers regardless of whether sampling is needed for the current batch.</li> <li>The motivation for this is to avoid reallocations and branching based on the sampling requirements of the batch.</li> </ul> </li> <li><strong>b7862</strong>: ggml-sycl: remove unused syclcompat header (<a href="https://github.com/ggml-org/llama.cpp/pull/19140">#19140</a>) <ul> <li>The <code>syclcompat/math.hpp</code> is not used anymore. The change that introduced it was successfully reverted (<a href="https://github.com/ggml-org/llama.cpp/pull/17826">https://github.com/ggml-org/llama.cpp/pull/17826</a>). This include path will become obsolete and dropped in oneAPI 2026.0 effectively breaking <code>ggml-sycl</code> builds.</li> <li><em>Make sure to read the <a href="https://github.com/ggml-org/llama.cpp/blob/master/CONTRIBUTING.md">contributing guidelines</a> before submitting a PR</em></li> </ul> </li> <li><strong>b7868</strong>: CUDA: refactor topk-moe to enable more models (GLM 4.7, Nemotron etc.) (<a href="https://github.com/ggml-org/llama.cpp/pull/19126">#19126</a>) <ul> <li>Refactor the topk-moe to enabling various combination of topk-moe. Hopefully this will cover most models. I removed some templates from the code and only kept the bias because it has a extra warp shuffle, the rest of the template code does not provide any significant speedup.</li> <li>3090</li> <li>| Model | Test | t/s master | t/s topk-cuda-refactor | Speedup |</li> </ul> </li> </ul> <h4><a href="#user-content--new-features-52" aria-hidden="true" class="anchor" id="user-content--new-features-52"></a>🆕 New Features</h4> <ul> <li><strong>b7849</strong>: jinja : implement mixed type object keys (<a href="https://github.com/ggml-org/llama.cpp/pull/18955">#18955</a>) <ul> <li>Allow all hashable types as object keys, taking care to replicate special python/jinja behavior between <code>int</code>/<code>float</code>/<code>bool</code>.</li> <li>Fixed array/object output with <code>string</code> filter.</li> <li>Fixed object <code>tojson</code> output (did not properly escape key string).</li> </ul> </li> <li><strong>b7860</strong>: CUDA: use mul_mat_q kernels by default (<a href="https://github.com/ggml-org/llama.cpp/pull/2683">#2683</a>) <ul> <li>There seem to have been no further reports of problems with the mul_mat_q kernels so I think it's fine to use them by default. This PR does just that and replaces the <code>-mmq</code>/<code>--mul-mat-q</code> CLI argument with <code>-nommq</code>/<code>--no-mul-mat-q</code>. Unless I'm mistaken the long-term plan is to also add equivalent CPU kernels for matrix matrix multiplications. Ideally I think the same CLI argument should then be used for switching the algorithm. So if you think that "mul_mat_q" is a bad name for matrix multiplications using quantized data now would be a good time to tell me.</li> </ul> </li> <li><strong>b7870</strong>: arg : add -kvu to llama-batched-bench (<a href="https://github.com/ggml-org/llama.cpp/pull/19172">#19172</a>)</li> <li><strong>b7871</strong>: HIP: add mmf for CDNA (<a href="https://github.com/ggml-org/llama.cpp/pull/18896">#18896</a>) <ul> <li>Add mmf for CDNA, CDNA3 is passed, it will be very helpful if anyone can test it on CDNA2 and CDNA1, thank you.</li> <li><input type="checkbox" checked="" disabled="" /> Refactor mmf to make rows_per_block as input parameter.</li> <li><input type="checkbox" checked="" disabled="" /> Pass MUL_MAT and MUL_MAT_ID.</li> </ul> </li> </ul> <h4><a href="#user-content--performance-improvements-31" aria-hidden="true" class="anchor" id="user-content--performance-improvements-31"></a>🚀 Performance Improvements</h4> <ul> <li><strong>b7847</strong>: CUDA: tune GLM 4.7 Flash FA kernel selection logic (<a href="https://github.com/ggml-org/llama.cpp/pull/19097">#19097</a>) <ul> <li>Follow-up to <a href="https://github.com/ggml-org/llama.cpp/pull/19092">https://github.com/ggml-org/llama.cpp/pull/19092</a> .</li> <li>Adjusts the kernel selection logic as a function of context depth to squeeze out a few more % on Ampere/Blackwell.</li> <li>| GPU | Model | Microbatch size | Test | t/s master | t/s 8a8b9a8bd | Speedup |</li> </ul> </li> <li><strong>b7858</strong>: ggml: new backend for Virglrenderer API Remoting acceleration (v2) (<a href="https://github.com/ggml-org/llama.cpp/pull/18718">#18718</a>) <ul> <li>This is a follow up of <a href="https://github.com/ggml-org/llama.cpp/pull/17072">https://github.com/ggml-org/llama.cpp/pull/17072</a></li> <li>The API Remoting backend/frontend allow escaping the VM isolation, with the help of the <code>virt-gpu</code> paravirtualization (and the <code>virglrenderer</code> library on the host side).</li> <li><code>ggml-remotingfrontend</code> is a GGML API implementation, which intercepts the GGML API calls and forwards them to the <code>virt-gpu</code> virtual device</li> </ul> </li> <li><strong>b7865</strong>: Vulkan Flash Attention Coopmat1 Refactor (<a href="https://github.com/ggml-org/llama.cpp/pull/19075">#19075</a>) <ul> <li>I finally had the time to go through Jeff's Flash Attention shaders in detail and used the chance to refactor the Coopmat1 for AMD. It started out as an attempt to use Coopmats for the Softmax * V matrix multiplication as well and then escalated into a refactor of the whole shader structure.</li> <li>It now uses coopmats for the Softmax result * V matrix multiplication, and I vectorized some variables, changed how shared memory is used, load K and V directly from global memory if possible, otherwise streamed through a shared memory cache.</li> <li>Tests are passing. Performance is up significantly on AMD RX 8060S (Strix Halo). Draft because there is a regression on Nvidia. Let me know if you see anything obvious @jeffbolznv. More tuning is likely required.</li> </ul> </li> </ul> <h4><a href="#user-content--bug-fixes-48" aria-hidden="true" class="anchor" id="user-content--bug-fixes-48"></a>🐛 Bug Fixes</h4> <ul> <li><strong>b7851</strong>: Split shared state (webgpu_context) into global state and per-thread state (<a href="https://github.com/ggml-org/llama.cpp/pull/18976">#18976</a>) <ul> <li>Right now, the WebGPU backend has a global <code>webgpu_context</code> struct with all the information required to instantiate and run a WebGPU graph.</li> <li>We want to split up the <code>webgpu_context</code> struct as follows:</li> <li>Move <code>get_tensor_sharing_buf</code> to global state, along with the <code>mutex</code></li> </ul> </li> <li><strong>b7853</strong>: llama : disable Direct IO by default (<a href="https://github.com/ggml-org/llama.cpp/pull/19109">#19109</a>) <ul> <li>ref <a href="https://github.com/ggml-org/llama.cpp/issues/19035#issuecomment-3798971944">https://github.com/ggml-org/llama.cpp/issues/19035#issuecomment-3798971944</a></li> <li>cont #18012</li> <li>Update <code>llama_model_params::use_direct_io == false</code> by default</li> </ul> </li> <li><strong>b7856</strong>: cuda : fix "V is K view" check for non-unified KV cache (<a href="https://github.com/ggml-org/llama.cpp/pull/19145">#19145</a>) <ul> <li>We weren't handling the case where both V and K are views of the same data with the same offset different from 0. This happens with split KV cache (e.g. <code>--parallel 4 --no-kv-unified</code>) and causes the flash attention to fall back to the CPU in such cases.</li> </ul> </li> <li><strong>b7860</strong>: vulkan: handle device dedup on MacOS + Vega II Duo cards (<a href="https://github.com/ggml-org/llama.cpp/pull/19058">#19058</a>) <ul> <li>Deduplication here relied on the fact that vulkan would return unique UUID for different physical GPUs. It is at the moment not always the case. On Mac Pro 2019 running Mac OS, with 2 Vega II Duo cards (so, 4 GPU total), MotlenVK would assign same UUID to pairs of GPUs, unless they are connected with Infinity Fabric.</li> <li>See more details here: KhronosGroup/MoltenVK#2683.</li> <li>The right way is to fix that in MoltenVK, but until it is fixed, llama.cpp would only recognize 2 of 4 GPUs in such configuration.</li> </ul> </li> <li><strong>b7861</strong>: jinja : undefined should be treated as sequence/iterable (return string/array) by filters/tests (<a href="https://github.com/ggml-org/llama.cpp/pull/19147">#19147</a>) <ul> <li>Fixes #19130</li> </ul> </li> <li><strong>b7869</strong>: ggml-zendnn : resolve ZenDNN backend cross-module symbol dependency (<a href="https://github.com/ggml-org/llama.cpp/pull/19159">#19159</a>) <ul> <li>This PR fixes the ZenDNN backend failing to load when <code>GGML_BACKEND_DL=ON</code></li> <li>The issue occurs because MODULE libs cannot access symbols from other MODULE libs, ZenDNN backend was attempting to call <code>ggml_get_type_traits_cpu()</code> from ggml-cpu, resulting in an undfined symbol error for <code>GGML_BACKEND_DL=ON</code></li> <li>This fix uses <code>ggml_get_type_traits()</code> from ggml-base instead, eliminating the dependency on ggml-cpu</li> </ul> </li> </ul> <h3><a href="#user-content-additional-changes-52" aria-hidden="true" class="anchor" id="user-content-additional-changes-52"></a>Additional Changes</h3> <p>5 minor improvements: 3 documentation, 2 maintenance.</p> <ul> <li><strong>b7864</strong>: Add self‑speculative decoding (no draft model required) (<a href="https://github.com/ggml-org/llama.cpp/pull/18471">#18471</a>) <ul> <li>This PR introduces self-speculative decoding: instead of using a dedicated draft model (which is good, if available, see #18039), the current token history is used to predict future tokens. This can provide a speedup in cases where the output contains repeated parts of the prompt. A typical example is making many small changes in a large source file.</li> <li><strong>Example 1</strong> (<code>gpt-oss-120b</code> in VRAM): Translation of a few comments in a Python script (chosen as a favorable case).</li> <li> <pre><code>
- Support virtual Metal devices. Allows simulating multi-GPU environments on Mac using the new
- b7864: Add self‑speculative decoding (no draft model required) (#18471)
- This PR introduces self-speculative decoding: instead of using a dedicated draft model (which is good, if available, see #18039), the current token history is used to predict future tokens. This can provide a speedup in cases where the output contains repeated parts of the prompt. A typical example is making many small changes in a large source file.
- Example 1 (
gpt-oss-120bin VRAM): Translation of a few comments in a Python script (chosen as a favorable case). -
- b7867: [SYCL] fix norm kernels: l2_norm, group_norm, rms_norm by remove assert (#19154)
- fix norm kernels: l2_norm, group_norm, rms_norm by remove assert.
- all ut cases of norm are 100% passed.
- no crash of UT cases.
- b7855: CUDA: tune GLM 4.7 Flash FA kernel selection logic (DGX Spark) (#19142)
- cont #19097
- This is similar to #19097, but for DGX Spark. I used only the
Q8_0model for the measurements. -
</code></pre> </li> </ul> </li> <li><strong>b7857</strong>: ggml-cpu: arm64: Q4_K repack (i8mm) scale unroll and vectorization (<a href="https://github.com/ggml-org/llama.cpp/pull/19108">#19108</a>) <ul> <li>While working on <a href="https://github.com/ggml-org/llama.cpp/pull/18860">https://github.com/ggml-org/llama.cpp/pull/18860</a> I found out a small perf optimization when loading the subblock scales.</li> <li>Behavior unchanged, it's a manual unroll + vectorization.</li> <li>Llama-bench:</li> </ul> </li> </ul> <h3><a href="#user-content-full-commit-range-62" aria-hidden="true" class="anchor" id="user-content-full-commit-range-62"></a>Full Commit Range</h3> <ul> <li>b7847 to b7871 (22 commits)</li> <li>Upstream releases: <a href="https://github.com/ggml-org/llama.cpp/compare/b7847...b7871">https://github.com/ggml-org/llama.cpp/compare/b7847...b7871</a></li> </ul> <hr /> <h2><a href="#user-content-2026-01-27-update-to-llamacpp-b7845" aria-hidden="true" class="anchor" id="user-content-2026-01-27-update-to-llamacpp-b7845"></a>2026-01-27: Update to llama.cpp b7845</h2> <h3><a href="#user-content-summary-63" aria-hidden="true" class="anchor" id="user-content-summary-63"></a>Summary</h3> <p>Updated llama.cpp from b7837 to b7845, incorporating 8 upstream commits with breaking changes, new features, and performance improvements.</p> <h3><a href="#user-content-notable-changes-59" aria-hidden="true" class="anchor" id="user-content-notable-changes-59"></a>Notable Changes</h3> <h4><a href="#user-content-️-breaking-changes-31" aria-hidden="true" class="anchor" id="user-content-️-breaking-changes-31"></a>⚠️ Breaking Changes</h4> <ul> <li><strong>b7839</strong>: graph : fix nkvo offload with FA (<a href="https://github.com/ggml-org/llama.cpp/pull/19105">#19105</a>) <ul> <li>fix #19096</li> <li>The <code>ggml_flash_attn_ext</code> was not being offloaded to the CPU when <code>-nkvo</code> is specified.</li> <li>Also remove obsolete <code>strcmp(name, "kqv_merged_cont")</code> check in the graph callback.</li> </ul> </li> </ul> <h4><a href="#user-content--new-features-53" aria-hidden="true" class="anchor" id="user-content--new-features-53"></a>🆕 New Features</h4> <ul> <li><strong>b7837</strong>: model : add correct type for GLM 4.7 Flash (<a href="https://github.com/ggml-org/llama.cpp/pull/19106">#19106</a>) <ul> <li>Fix the displayed model type in the logs:</li> <li> <pre><code class="language-bash">
- deepseek2 ?B Q8_0
- b7843: common : clarify HTTPS build options in error message (#19103)
- This commit updates the https error message to provide clearer instructions for users who encounter the "HTTPS is not supported" error.
- The motivation for this is that it might not be clear to users that only one of these options are needed to enable HTTPS support. The LLAMA_OPENSSL option is also added to the message to cover all possible build configurations.
- b7845: ggml-cpu: aarm64: q5_K repack gemm and gemv (and generic) implementations (i8mm) (#18860)
- This PR implements the REPACK version of q5_K, following most of the existing design used for q4_K, since Q5_K only differs from q4_K in having the
qhfield with the additional bit. - Most of the code is shared, but I didn't know how to abstract the common patterns without creating a convoluted mess of functions. Since only Q4_K and Q5_K share the same 6bit scales and mins decode, I opted to duplicate the code.
- I also moved around some declarations for Q2_K because the structure seemed weird (it's inverted with what I've seen in quants.c). The Q2_K function declarations were left where they were to avoid polluting the diff and messing the blame. If you want me to revert it, just say so.
- This PR implements the REPACK version of q5_K, following most of the existing design used for q4_K, since Q5_K only differs from q4_K in having the
- b7845: ggml-cpu: aarm64: q6_K repack gemm and gemv (and generic) implementations (i8mm) #18860 (#18888)
- Continuation of repack work for ARM, since
q4_K_Mandq5_K_Mquantizations spend ~%20 of compute time on q6_K layers. - Still pending rebasing on top of #18860 if that gets merged.
- Same testing practices from the other repack implementations.
- Continuation of repack work for ARM, since
🚀 Performance Improvements
- b7841: opencl: add flattened q6_K mv (#19054)
- This PR adds flattened q6_K mv and renames the existing q6_K mv kernel file to better reflect what the kernel does. There should be no performance improvement, but will enable further optimizations.
- b7842: ggml-cpu: Enable FP16 MMA kernels on PPC (#19060)
- This change introduces a unified FP16/BF16 MMA kernel selection via mma_instr,
- allowing FP16 models to leverage Power MMA instructions instead of falling back to scalar/vector paths.
- Performance impact (Power10, 10 threads, Mistral-7B FP16, llama-batched-bench):
Additional Changes
1 minor improvements: 1 documentation.
- b7844: [CUDA] Reduce CPU-side stalls due to the CUDA command buffer being full (#19042)
- With pipeline parallelism, during prompt processing, the CPU-side CUDA command buffer gets full, stalling the CPU. Due to this, enough work doesn't get submitted to the GPU, resulting in bubbles in the GPU timeline. This PR fixes this by setting the CUDA environment variable CUDA_SCALE_LAUNCH_QUEUES to 4x to increase the command buffer size.
- The NSight profile below shows the issue in more detail:
-
Full Commit Range
- b7837 to b7845 (8 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b7837...b7845
2026-01-26: Update to llama.cpp b7837
Summary
Updated llama.cpp from b7837 to b7837, incorporating 1 upstream commits with new features.
Notable Changes
🆕 New Features
- b7837: model : add correct type for GLM 4.7 Flash (#19106)
- Fix the displayed model type in the logs:
-
</code></pre> </li> <li>deepseek2 ?B Q8_0</li> </ul> </li> </ul> <h3><a href="#user-content-full-commit-range-64" aria-hidden="true" class="anchor" id="user-content-full-commit-range-64"></a>Full Commit Range</h3> <ul> <li>b7837 to b7837 (1 commits)</li> <li>Upstream releases: <a href="https://github.com/ggml-org/llama.cpp/compare/b7837...b7837">https://github.com/ggml-org/llama.cpp/compare/b7837...b7837</a></li> </ul> <hr /> <h2><a href="#user-content-2026-01-26-update-to-llamacpp-b7837-1" aria-hidden="true" class="anchor" id="user-content-2026-01-26-update-to-llamacpp-b7837-1"></a>2026-01-26: Update to llama.cpp b7837</h2> <h3><a href="#user-content-summary-65" aria-hidden="true" class="anchor" id="user-content-summary-65"></a>Summary</h3> <p>Updated llama.cpp from b7837 to b7837, incorporating 1 upstream commits with new features.</p> <h3><a href="#user-content-notable-changes-61" aria-hidden="true" class="anchor" id="user-content-notable-changes-61"></a>Notable Changes</h3> <h4><a href="#user-content--new-features-55" aria-hidden="true" class="anchor" id="user-content--new-features-55"></a>🆕 New Features</h4> <ul> <li><strong>b7837</strong>: model : add correct type for GLM 4.7 Flash (<a href="https://github.com/ggml-org/llama.cpp/pull/19106">#19106</a>) <ul> <li>Fix the displayed model type in the logs:</li> <li> <pre><code class="language-bash">
- deepseek2 ?B Q8_0
Full Commit Range
- b7837 to b7837 (1 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b7837...b7837
2026-01-26: Update to llama.cpp b7837
Summary
Updated llama.cpp from b7837 to b7837, incorporating 1 upstream commits with new features.
Notable Changes
🆕 New Features
- b7837: model : add correct type for GLM 4.7 Flash (#19106)
- Fix the displayed model type in the logs:
-
</code></pre> </li> <li>deepseek2 ?B Q8_0</li> </ul> </li> </ul> <h3><a href="#user-content-full-commit-range-66" aria-hidden="true" class="anchor" id="user-content-full-commit-range-66"></a>Full Commit Range</h3> <ul> <li>b7837 to b7837 (1 commits)</li> <li>Upstream releases: <a href="https://github.com/ggml-org/llama.cpp/compare/b7837...b7837">https://github.com/ggml-org/llama.cpp/compare/b7837...b7837</a></li> </ul> <hr /> <h2><a href="#user-content-2026-01-26-update-to-llamacpp-b7836" aria-hidden="true" class="anchor" id="user-content-2026-01-26-update-to-llamacpp-b7836"></a>2026-01-26: Update to llama.cpp b7836</h2> <h3><a href="#user-content-summary-67" aria-hidden="true" class="anchor" id="user-content-summary-67"></a>Summary</h3> <p>Updated llama.cpp from b7836 to b7836, incorporating 1 upstream commits with performance improvements.</p> <h3><a href="#user-content-notable-changes-63" aria-hidden="true" class="anchor" id="user-content-notable-changes-63"></a>Notable Changes</h3> <h4><a href="#user-content--performance-improvements-33" aria-hidden="true" class="anchor" id="user-content--performance-improvements-33"></a>🚀 Performance Improvements</h4> <ul> <li><strong>b7836</strong>: CUDA: faster FA for GQA > 1 but not power of 2 (<a href="https://github.com/ggml-org/llama.cpp/pull/19092">#19092</a>) <ul> <li>This PR generalizes the CUDA MMA FlashAttention kernel to enable the GQA optimizations for models where the ratio between the number of Q heads and the number of K/V heads is not a power of 2. This is done by simply padding the Q columns per CUDA block to the next higher power of 2. This wastes a bit of compute but particularly for small batch sizes the kernel is I/O-bound anyways.</li> <li>On Ampere or newer this improves performance of GLM 4.7 Flash as well as some random models like Granite 3.0 with a GQA ratio of 3. On Volta the new code path is slower than master so it's disabled. On RDNA4 it seems to be faster but as of right now the performance of the MMA kernel is bad on RDNA for head sizes > 128 so there is no benefit for GLM 4.7 Flash.</li> <li> <details> </li> </ul> </li> </ul> <h3><a href="#user-content-full-commit-range-67" aria-hidden="true" class="anchor" id="user-content-full-commit-range-67"></a>Full Commit Range</h3> <ul> <li>b7836 to b7836 (1 commits)</li> <li>Upstream releases: <a href="https://github.com/ggml-org/llama.cpp/compare/b7836...b7836">https://github.com/ggml-org/llama.cpp/compare/b7836...b7836</a></li> </ul> <hr /> <h2><a href="#user-content-2026-01-26-update-to-llamacpp-b7836-1" aria-hidden="true" class="anchor" id="user-content-2026-01-26-update-to-llamacpp-b7836-1"></a>2026-01-26: Update to llama.cpp b7836</h2> <h3><a href="#user-content-summary-68" aria-hidden="true" class="anchor" id="user-content-summary-68"></a>Summary</h3> <p>Updated llama.cpp from b7836 to b7836, incorporating 1 upstream commits with performance improvements.</p> <h3><a href="#user-content-notable-changes-64" aria-hidden="true" class="anchor" id="user-content-notable-changes-64"></a>Notable Changes</h3> <h4><a href="#user-content--performance-improvements-34" aria-hidden="true" class="anchor" id="user-content--performance-improvements-34"></a>🚀 Performance Improvements</h4> <ul> <li><strong>b7836</strong>: CUDA: faster FA for GQA > 1 but not power of 2 (<a href="https://github.com/ggml-org/llama.cpp/pull/19092">#19092</a>) <ul> <li>This PR generalizes the CUDA MMA FlashAttention kernel to enable the GQA optimizations for models where the ratio between the number of Q heads and the number of K/V heads is not a power of 2. This is done by simply padding the Q columns per CUDA block to the next higher power of 2. This wastes a bit of compute but particularly for small batch sizes the kernel is I/O-bound anyways.</li> <li>On Ampere or newer this improves performance of GLM 4.7 Flash as well as some random models like Granite 3.0 with a GQA ratio of 3. On Volta the new code path is slower than master so it's disabled. On RDNA4 it seems to be faster but as of right now the performance of the MMA kernel is bad on RDNA for head sizes > 128 so there is no benefit for GLM 4.7 Flash.</li> <li> <details> </li> </ul> </li> </ul> <h3><a href="#user-content-full-commit-range-68" aria-hidden="true" class="anchor" id="user-content-full-commit-range-68"></a>Full Commit Range</h3> <ul> <li>b7836 to b7836 (1 commits)</li> <li>Upstream releases: <a href="https://github.com/ggml-org/llama.cpp/compare/b7836...b7836">https://github.com/ggml-org/llama.cpp/compare/b7836...b7836</a></li> </ul> <hr /> <h2><a href="#user-content-2026-01-26-update-to-llamacpp-b7836-2" aria-hidden="true" class="anchor" id="user-content-2026-01-26-update-to-llamacpp-b7836-2"></a>2026-01-26: Update to llama.cpp b7836</h2> <h3><a href="#user-content-summary-69" aria-hidden="true" class="anchor" id="user-content-summary-69"></a>Summary</h3> <p>Updated llama.cpp from b7836 to b7836, incorporating 1 upstream commits with performance improvements.</p> <h3><a href="#user-content-notable-changes-65" aria-hidden="true" class="anchor" id="user-content-notable-changes-65"></a>Notable Changes</h3> <h4><a href="#user-content--performance-improvements-35" aria-hidden="true" class="anchor" id="user-content--performance-improvements-35"></a>🚀 Performance Improvements</h4> <ul> <li><strong>b7836</strong>: CUDA: faster FA for GQA > 1 but not power of 2 (<a href="https://github.com/ggml-org/llama.cpp/pull/19092">#19092</a>) <ul> <li>This PR generalizes the CUDA MMA FlashAttention kernel to enable the GQA optimizations for models where the ratio between the number of Q heads and the number of K/V heads is not a power of 2. This is done by simply padding the Q columns per CUDA block to the next higher power of 2. This wastes a bit of compute but particularly for small batch sizes the kernel is I/O-bound anyways.</li> <li>On Ampere or newer this improves performance of GLM 4.7 Flash as well as some random models like Granite 3.0 with a GQA ratio of 3. On Volta the new code path is slower than master so it's disabled. On RDNA4 it seems to be faster but as of right now the performance of the MMA kernel is bad on RDNA for head sizes > 128 so there is no benefit for GLM 4.7 Flash.</li> <li> <details> </li> </ul> </li> </ul> <h3><a href="#user-content-full-commit-range-69" aria-hidden="true" class="anchor" id="user-content-full-commit-range-69"></a>Full Commit Range</h3> <ul> <li>b7836 to b7836 (1 commits)</li> <li>Upstream releases: <a href="https://github.com/ggml-org/llama.cpp/compare/b7836...b7836">https://github.com/ggml-org/llama.cpp/compare/b7836...b7836</a></li> </ul> <hr /> <h2><a href="#user-content-2026-01-21-update-to-llamacpp-b7788" aria-hidden="true" class="anchor" id="user-content-2026-01-21-update-to-llamacpp-b7788"></a>2026-01-21: Update to llama.cpp b7788</h2> <h3><a href="#user-content-summary-70" aria-hidden="true" class="anchor" id="user-content-summary-70"></a>Summary</h3> <p>Updated llama.cpp from b7772 to b7788, incorporating 13 upstream commits with breaking changes, new features, and performance improvements.</p> <h3><a href="#user-content-notable-changes-66" aria-hidden="true" class="anchor" id="user-content-notable-changes-66"></a>Notable Changes</h3> <h4><a href="#user-content-️-breaking-changes-32" aria-hidden="true" class="anchor" id="user-content-️-breaking-changes-32"></a>⚠️ Breaking Changes</h4> <ul> <li><strong>b7782</strong>: ggml : cleanup path_str() (<a href="https://github.com/ggml-org/llama.cpp/pull/18928">#18928</a>) <ul> <li>Remove pragmas as <code>std::codecvt_utf8</code> is not used.</li> <li>Avoid implicit <code>strlen()</code>.</li> </ul> </li> </ul> <h4><a href="#user-content--new-features-57" aria-hidden="true" class="anchor" id="user-content--new-features-57"></a>🆕 New Features</h4> <ul> <li><strong>b7774</strong>: ggml : add ggml_build_forward_select (<a href="https://github.com/ggml-org/llama.cpp/pull/18550">#18550</a>) <ul> <li>target #18547</li> <li>alt #18549</li> <li>Add <code>GGML_TENSOR_FLAG_COMPUTE</code> flag indicating that a tensor in the graph must be computed</li> </ul> </li> <li><strong>b7777</strong>: jinja : fix undefined keys and attributes and int/float as bool (<a href="https://github.com/ggml-org/llama.cpp/pull/18924">#18924</a>) <ul> <li>Return <code>undefined</code> on undefined keys and attributes.</li> <li>Integers and floats can be represented as bools.</li> <li>Added <code>falsy</code> tests.</li> </ul> </li> </ul> <h4><a href="#user-content--performance-improvements-36" aria-hidden="true" class="anchor" id="user-content--performance-improvements-36"></a>🚀 Performance Improvements</h4> <ul> <li><strong>b7781</strong>: metal : enable FA for MLA heads (<a href="https://github.com/ggml-org/llama.cpp/pull/18950">#18950</a>) <ul> <li>ref #18936</li> <li>Re-enable FA for K head size of 576 (MQA mode of MLA) and adjust simdgroups and loop unrolling for performance.</li> </ul> </li> <li><strong>b7783</strong>: CUDA: Replace init_offsets kernel with iterators in cub-based argsort (<a href="https://github.com/ggml-org/llama.cpp/pull/18930">#18930</a>) <ul> <li>This is mostly a QOL improvement, saving us the cost of materializing the iterator.</li> <li>--- before</li> <li> <pre><code>
🐛 Bug Fixes
- b7772: DirectIO Model Loading: Extend and fix Fallback (#18887)
- Due to issues with the DirectIO model loading path on Android this PR adds
EINVALerrors to the fallback condition. Also there was a bug in the fallback tommapin caseopenwith the DirectIO flag fails.
- Due to issues with the DirectIO model loading path on Android this PR adds
- b7787: gguf: display strerrno when cant load a model (#18884)
- I've had issues loading models with llama-server:
- [44039] E gguf_init_from_file: failed to open GGUF file 'mistral-7b-v0.1.Q8_0.gguf'
- and I was sure it could access the file. Seems like --models-dir and --models-presets dont interact like I thought they would but I salvaged this snippet that helps troubleshooting
- b7788: Fix GLM 4.7 Lite MoE gating func (#18980)
- GLM 4.7 Lite uses SIGMOID, not SOFTMAX like Deepseek.
Additional Changes
5 minor improvements: 1 documentation, 4 examples.
- b7786: CUDA: Fix builds for older CCCL versions by ifdefing strided_iterator (#18964)
- Strided iterator was added in CCCL 3.1, which is packaged into [CTK
- 13.1](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#id5)
- Should fix #18960
- b7775: server: fix memory reservations in populate_token_probs (#18787)
- Fixes the two Vector::reserve calls in the populate_token_probs function.
- In case post_sampling is true the code now only reserves as much space in the Vector as is needed for the requested number of logprobs. This prevents reserving large amounts of memory that are not used.
- In case post_sampling is false the code now clamps the reserved size to the maximum number of tokens the model supports. This prevents reserving large amounts of unused memory when the client requests more token logprobs than the model supports and, in extreme cases, crashes from invalid memory allocations.
- b7779: server : refactor oai_parser_opt, move it to server_chat_params (#18937)
- In this PR:
- Rename
oaicompat_parser_options-->server_chat_params - Store
common_chat_templates_ptrinside it
- b7784: cli : fix reasoning responses in CLI (#18961)
- The chat format was not populate to task state in CLI, so reasoning content was not parsed correctly
- With this PR, GLM-4.7 now works correctly on CLI:
-
- b7785: common, server : use the same User-Agent by default (#18957)
- This commit also ensures that if a custom User-Agent is used, it will be the only one sent.
Full Commit Range
- b7772 to b7788 (13 commits)
- Upstream releases: https://github.com/ggml-org/llama.cpp/compare/b7772...b7788
2026-01-05: Update to llama.cpp b7631
- b7622 (b7622) – 2026-01-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b7622
- b7624 (b7624) – 2026-01-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b7624
- b7625 (b7625) – 2026-01-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b7625
- CUDA: disable cuda graph when using n-cpu-moe
- call ggml_cuda_set_device
- b7626 (b7626) – 2026-01-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b7626
- b7628 (b7628) – 2026-01-05 – https://github.com/ggml-org/llama.cpp/releases/tag/b7628
- b7630 (b7630) – 2026-01-05 – https://github.com/ggml-org/llama.cpp/releases/tag/b7630
- Implement ggml_cann_op_add_rms_norm_fused() using ACLNN AddRmsNorm
- Add ggml_cann_can_fuse() to check fusion eligibility
- Integrate fusion logic into computation graph evaluation
- Add test cases for ADD + RMS_NORM fusion
- Update documentation with new environment variable
- b7631 (b7631) – 2026-01-05 – https://github.com/ggml-org/llama.cpp/releases/tag/b7631
- refactor rope_freq_base/scale_swa conversion and init
- safe defaults for unknowns
- update relevant models
- grammar
- add get_rope_freq_scale to modern-bert
- const
- const
- log swa info
2026-01-03: Update to llama.cpp b7621
- b7489 (b7489) – 2025-12-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b7489
- b7490 (b7490) – 2025-12-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b7490
- b7491 (b7491) – 2025-12-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b7491
- tests: Avoid floating point precision false positives in SUM
- also apply to test_mean
- b7492 (b7492) – 2025-12-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b7492
- implement sleeping at queue level
- implement server-context suspend
- add test
- add docs
- optimization: add fast path
- make sure to free llama_init
- nits
- fix use-after-free
- allow /models to be accessed during sleeping, fix use-after-free
- don't allow accessing /models during sleep, it is not thread-safe
- fix data race on accessing props and model_meta
- small clean up
- trailing whitespace
- rm outdated comments
- b7493 (b7493) – 2025-12-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b7493
- b7495 (b7495) – 2025-12-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b7495
- Some improvement on mul_mat_iq2_xs
- Fix trailing whitespace
- b7496 (b7496) – 2025-12-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b7496
- b7497 (b7497) – 2025-12-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b7497
- b7498 (b7498) – 2025-12-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b7498
- b7499 (b7499) – 2025-12-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b7499
- b7501 (b7501) – 2025-12-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b7501
- b7502 (b7502) – 2025-12-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b7502
- b7503 (b7503) – 2025-12-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b7503
- b7506 (b7506) – 2025-12-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b7506
- Update release workflow to store XCFramework as Zip file
- Add comments to document Zip file requirement for XCFramework
- Apply suggestions from code review
- b7507 (b7507) – 2025-12-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b7507
- b7508 (b7508) – 2025-12-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b7508
- server: prevent data race from HTTP threads
- fix params
- fix default_generation_settings
- nits: make handle_completions_impl looks less strange
- stricter const
- fix GGML_ASSERT(idx < states.size())
- move index to be managed by server_response_reader
- http: make sure req & res lifecycle are tied together
- fix compile
- fix index handling buggy
- fix data race for lora endpoint
- nits: fix shadow variable
- nits: revert redundant changes
- nits: correct naming for json_webui_settings
- b7509 (b7509) – 2025-12-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b7509
- b7510 (b7510) – 2025-12-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b7510
- b7511 (b7511) – 2025-12-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b7511
- b7512 (b7512) – 2025-12-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b7512
- gen-docs: automatically update markdown file
- also strip whitespace
- do not add extra newline
- update TOC
- b7513 (b7513) – 2025-12-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b7513
- feat: working gelu with src0 put on vtcm
- feat: gelu ping-pong for both in and out
- fix: fixu compile error
- break: distinguish dma ddr->vtcm and vtcm->ddr operation
- fix: fix dma queue size
- break: update dma api to either pop src or dst ptr
- fix: fix activation vtcm allocation issue for src1 when swapperd
- refactor: ping-pong gelu logic to avoid unnecessary if else
- dma: improved queue interface and prefetch handling
- gelu: fix N+2 block prefetch
- b7515 (b7515) – 2025-12-23 – https://github.com/ggml-org/llama.cpp/releases/tag/b7515
- constants and tensor mappings for modern bert support, model not supported yet but working on getting conversion to work for encoder only
- conversion now working, hf -> gguf
- working on support, now working on building graph
- some cleanup
- cleanup
- continuing
- correct tensor shape for qkv
- fixed tensor mappings and working on buildin graph
- tensor debugging now works -> (llama-eval-callback), instead of simulated gate split with views, GEGLU is now used which does exactly this
- cleanup
- cleanup
- cleanup
- more cleanup
- ubatch issues, the assert for checking equal seqs in llama-graph.cpp when building attention keeps failing, setting ubatch size to 1 when running llama-embedding with --ubatch-size 1 makes it work, but needs to be looked into more
- added cls token per previous modern bert attempt, still working on checking out the rest
- fixed pre tokenizer and still working through previous pr
- working through previous attemp, implimented more accurate conversion per previous attempt, added local sliding window attention that alternates every third layer
- fixed pre tokenizer
- working on swa with local and global alternating attention
- some cleanup and now fails on build attn
- starting to work, and some cleanup, currently failing on last layer construction in graph build
- alternating rope implemented and modern bert graph build succeeds
- fixed asser for equal ubatch seq
- cleanup
- added mask check in vocab
- fixed alternating rope, the hparams.rope_freq_base_train and hparams.rope_freq_base_train_swa were the same and i set them to correct values
- reuse variable
- removed repeat
- standard swa method can be used instead of a new enum being LLAMA_SWA_TYPE_LOCAL
- correct swa layer indexing, is supposed to be 0, 3, 6 ... instead of 1, 4, 7 ...
- more modular hparam setting
- replaced attn out norm with ffn_norm and cosine similarity between hf embds and llama.cpp embds went way up, from 0.05 to 0.24, replaced the cacheless kv with swa todo per the previous conversion
- Update gguf-py/gguf/tensor_mapping.py
- Update convert_hf_to_gguf_update.py
- Update src/llama-model.cpp
- Update src/llama-vocab.cpp
- Update src/llama-model.cpp
- Update gguf-py/gguf/tensor_mapping.py
- Update convert_hf_to_gguf.py
- Update gguf-py/gguf/tensor_mapping.py
- Update gguf-py/gguf/tensor_mapping.py
- Update convert_hf_to_gguf.py
- Update gguf-py/gguf/tensor_mapping.py
- Update gguf-py/gguf/tensor_mapping.py
- Update gguf-py/gguf/tensor_mapping.py
- Update gguf-py/gguf/tensor_mapping.py
- Update gguf-py/gguf/tensor_mapping.py
- Update gguf-py/gguf/tensor_mapping.py
- Update src/llama-graph.cpp
- Update src/llama-arch.cpp
- b7516 (b7516) – 2025-12-23 – https://github.com/ggml-org/llama.cpp/releases/tag/b7516
- llama-model : fix Nemotron V2 crash by moving MoE parameters calculation
- remove whitespace
- b7519 (b7519) – 2025-12-23 – https://github.com/ggml-org/llama.cpp/releases/tag/b7519
- refactor: replace ggml_hexagon_mul_mat with template-based binary operation for improved flexibility
- refactor: replace ggml_hexagon_mul_mat_id with template-based binary operation for improved flexibility
- refactor: initialize buffer types and streamline dspqueue_buffers_init calls for clarity
- add comment
- refactor: remove redundant buffer checks in hexagon supported operations
- wip
- add missing include to fix weak symbol warning
- add ggml_hexagon_op_generic
- refactor: simplify tensor operation initialization and buffer management in hexagon implementation
- refactor: streamline hexagon operation initialization and buffer management
- refactor: update function signatures and streamline request handling in hexagon operations
- wip
- ggml-hexagon: clean up code formatting and improve unary operation handling
- wip
- rename
- fix: add support for permuted F16 tensors and enhance quantization checks in matrix operations
- refactor: replace ggml_hexagon_mul_mat with template-based binary operation for improved flexibility
- hexagon: fix merge conflicts
- hexagon: minor cleanup for buffer support checks
- hexagon: factor out op_desc and the overal op logging
- hexagon: further simplify and cleanup op dispatch logic
- snapdragon: update adb scripts to use llama-cli and llama-completion
- fix pipeline failure
- b7520 (b7520) – 2025-12-23 – https://github.com/ggml-org/llama.cpp/releases/tag/b7520
- b7522 (b7522) – 2025-12-23 – https://github.com/ggml-org/llama.cpp/releases/tag/b7522
- b7524 (b7524) – 2025-12-23 – https://github.com/ggml-org/llama.cpp/releases/tag/b7524
- b7525 (b7525) – 2025-12-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b7525
- b7526 (b7526) – 2025-12-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b7526
- b7527 (b7527) – 2025-12-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b7527
- b7529 (b7529) – 2025-12-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b7529
- b7530 (b7530) – 2025-12-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b7530
- b7531 (b7531) – 2025-12-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b7531
- model: llama-embed-nemotron
- minor: python lint
- changed arch-name
- templated llm_build_llama to be used for both llama and llama-embed arch
- b7538 (b7538) – 2025-12-25 – https://github.com/ggml-org/llama.cpp/releases/tag/b7538
- ggml-cuda: fix blackwell native builds
- replace for GGML_NATIVE=OFF too
- only replace for native
- remove 120f-virtual for default compilation
- b7539 (b7539) – 2025-12-25 – https://github.com/ggml-org/llama.cpp/releases/tag/b7539
- cuda: optimize cumsum cub path
- remove heavy perf test
- b7540 (b7540) – 2025-12-25 – https://github.com/ggml-org/llama.cpp/releases/tag/b7540
- ggml-cuda: fix regex for arch list
- make regex exact
- b7541 (b7541) – 2025-12-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b7541
- CANN: implement SSM_CONV operator
- CANN: remove custom error limit for SSM_CONV
- CANN: merge SSM_CONV tensor shape/strides into one line
- b7543 (b7543) – 2025-12-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b7543
- server : fix crash when seq_rm fails for hybrid/recurrent models
- server : add allow_processing param to clear_slot
- b7544 (b7544) – 2025-12-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b7544
- b7545 (b7545) – 2025-12-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b7545
- b7547 (b7547) – 2025-12-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b7547
- b7548 (b7548) – 2025-12-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b7548
- vulkan: Use BK=32 for coopmat2 mul_mat_id
- vulkan: optimize decodeFuncB in coopmat2 mul_mat_id shader
- b7549 (b7549) – 2025-12-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b7549
- b7550 (b7550) – 2025-12-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b7550
- b7551 (b7551) – 2025-12-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b7551
- b7552 (b7552) – 2025-12-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b7552
- b7553 (b7553) – 2025-12-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b7553
- llama: fix magic number of 999 for GPU layers
- use strings for -ngl, -ngld
- enacapsulate n_gpu_layers, split_mode
- b7554 (b7554) – 2025-12-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b7554
- b7555 (b7555) – 2025-12-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7555
- opencl: allow resizing transpose buffers instead of using fixed sizes
- opencl: remove commented code
- b7556 (b7556) – 2025-12-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7556
- b7557 (b7557) – 2025-12-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7557
- minor: Consolidated
#include <immintrin.h>underggml-cpu-impl.h - cmake: Added more x86-64 CPU backends when building with
GGML_CPU_ALL_VARIANTS=On ivybridgepiledrivercannonlakecascadelakecooperlakezen4
- minor: Consolidated
- b7558 (b7558) – 2025-12-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7558
- b7560 (b7560) – 2025-12-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7560
- b7561 (b7561) – 2025-12-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7561
- rpc: fix segfault on invalid endpoint format
- rpc: add error log for failed endpoint connection
- b7562 (b7562) – 2025-12-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7562
- b7563 (b7563) – 2025-12-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7563
- plamo3
- fix plamo3
- clean code
- clean up the code
- fix diff
- clean up the code
- clean up the code
- clean up the code
- clean up the code
- clean up the code
- clean up the code
- add chat_template if exist
- clean up the code
- fix cpu-backend
- chore: whitespace trim fix + typo fix
- Fix: address review feedback
- restore
FREQ_BASE_SWAconstant - Fix: address review feedback2
- Fix:typecheck
- Fix: address review feedback3
- final cleanup
- b7564 (b7564) – 2025-12-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7564
- b7566 (b7566) – 2025-12-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b7566
- ggml-cuda: fix race condition in cumsum
- remove unneccesary sync_threads
- b7567 (b7567) – 2025-12-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b7567
- b7568 (b7568) – 2025-12-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b7568
- common: fix return value check for setpriority
- tools: add logging for process priority setting
- b7569 (b7569) – 2025-12-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b7569
- b7571 (b7571) – 2025-12-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b7571
- b7572 (b7572) – 2025-12-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b7572
- Fix
msgtypo - Fix thread safety in destroy() to support generation abortion in lifecycle callbacks.
- UI polish: stack new message change from below; fix GGUF margin not in view port
- Bug fixes: rare racing condition when main thread updating view and and default thread updating messages at the same time; user input not disabled during generation.
- Bump dependencies' versions; Deprecated outdated dsl usage.
- Fix
- b7574 (b7574) – 2025-12-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b7574
- Prevent crash if TTFT >300sec, boosted to 90 days
- server : allow configurable HTTP timeouts for child models
- server : pass needed timeouts from params only
- b7579 (b7579) – 2025-12-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b7579
- CUDA: add log line when mxfp4 acceleration is used
- add in backend_get_features
- b7580 (b7580) – 2025-12-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b7580
- kleidiai: add and integrate SVE 256-bit vector-length kernel
- updated for review comments
- b7581 (b7581) – 2025-12-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b7581
- b7582 (b7582) – 2025-12-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b7582
- sampling: reuse token data buffer in llama_sampler_sample
- move cur buffer before timing section, after samplers
- minor : fix build
- b7583 (b7583) – 2025-12-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b7583
- lora: count lora nodes in graph_max_nodes
- 3 nodes per weight
- 4 nodes
- keep track n_lora_nodes from llama_model
- fix assert
- rm redundant header
- common: load adapters before context creation
- use 6 nodes
- b7585 (b7585) – 2025-12-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b7585
- common : default content to an empty string
- common : fix tests that break when content != null
- b7588 (b7588) – 2025-12-31 – https://github.com/ggml-org/llama.cpp/releases/tag/b7588
- cmake: work around broken IntelSYCLConfig.cmake in oneAPI 2025.x
- [AI] sycl: auto-detect and skip incompatible IntelSYCL package
- refactor: improve SYCL provider handling and error messages in CMake configuration
- refactor: enhance SYCL provider validation and error handling in CMake configuration
- ggml-sycl: wrap find_package(IntelSYCL) to prevent build crashes
- b7589 (b7589) – 2025-12-31 – https://github.com/ggml-org/llama.cpp/releases/tag/b7589
- b7590 (b7590) – 2025-12-31 – https://github.com/ggml-org/llama.cpp/releases/tag/b7590
- b7591 (b7591) – 2025-12-31 – https://github.com/ggml-org/llama.cpp/releases/tag/b7591
- b7592 (b7592) – 2025-12-31 – https://github.com/ggml-org/llama.cpp/releases/tag/b7592
- add count equal for metal
- remove trailing whitespace
- updated doc ops table
- changed shmem to i32
- added multi tg and templating
- removed BLAS support from Metal docs
- Apply suggestions from code review
- add memset to set dst to 0
- metal : cleanup
- b7593 (b7593) – 2025-12-31 – https://github.com/ggml-org/llama.cpp/releases/tag/b7593
- Inital commit, debugging q5_k_s quant
- Made hf_to_gguf extend whisper to reduce code duplication
- addressed convert_hf_to_gguf pull request issue
- b7595 (b7595) – 2025-12-31 – https://github.com/ggml-org/llama.cpp/releases/tag/b7595
- b7598 (b7598) – 2026-01-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b7598
- chat: make tool description and parameters optional per OpenAI spec
- refactor: use value() for cleaner optional field access
- b7599 (b7599) – 2026-01-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b7599
- b7600 (b7600) – 2026-01-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b7600
- vulkan: extend topk_moe to handle sigmoid w/exp_probs_b for nemotron
- change test_topk_moe to allow results in arbitrary order
- disable sigmoid fusion for moltenvk
- b7601 (b7601) – 2026-01-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b7601
- b7603 (b7603) – 2026-01-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b7603
- model: add Solar-Open model
- vocab: add solar-open to end eog blacklist
- model: add proper llm type
- chat: basic template for solar open
- typo: fix comment about vocab
- convert: sugested changes
- convert: suggested changes
- chat: change reasoning end tag for solar-open
- llama-chat: add solar-open template
- b7605 (b7605) – 2026-01-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b7605
- WIP: Initial commit for fixing JinaBert original FF type support
- convert: add jina-v2-de tokenizer variant for German_Semantic_V3
- convert: fix token collision in BERT phantom vocab conversion
- convert: add feed_forward_type metadata
- model: add feed_forward_type metadata for jina-bert-v2
- model: jina-bert-v2 support standard GELU FFN variant
- model: remove ffn_type, detect FFN variant from tensor dimensions
- Update src/llama-model.cpp
- Update src/llama-model.cpp
- Update src/models/bert.cpp
- Update src/models/bert.cpp
- revert collision fix to be handled in separate PR
- b7607 (b7607) – 2026-01-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b7607
- Support Youtu-VL Model
- merge code
- fix bug
- revert qwen2 code & support rsplit in minja.hpp
- update warm info
- fix annotation
- u
- revert minja.hpp
- fix
- Do not write routed_scaling_factor to gguf when routed_scaling_factor is None
- fix expert_weights_scale
- LGTM after whitespace fixes
- fix
- fix
- fix
- layers to layer_index
- enum fix
- b7608 (b7608) – 2026-01-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b7608
- remove modern-bert iswa template
- forgotten
- b7609 (b7609) – 2026-01-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b7609
- ggml-cuda: fixed assertion in ggml_cuda_cpy (#18140)
- ggml-cuda: changes in data types to int64_t
- ggml-cuda: added asserts for CUDA block numbers
- ggml-cuda: changed the condition for y and z dimension
- b7610 (b7610) – 2026-01-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b7610
- b7611 (b7611) – 2026-01-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b7611
- vocab : reduce debug logs about non-EOG control tokens
- cont : add comment
- b7612 (b7612) – 2026-01-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b7612
- b7613 (b7613) – 2026-01-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b7613
- b7614 (b7614) – 2026-01-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b7614
- Add Maincoder model support
- Removed SPM model vocabulary setting and MOE related GGUF parameters
- removed set_vocab
- added new line
- Fix formatting
- Add a new line for PEP8
- b7615 (b7615) – 2026-01-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b7615
- b7616 (b7616) – 2026-01-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b7616
- vulkan: Optimize GGML_OP_CUMSUM
- use 2 ELEM_PER_THREAD for AMD/Intel
- address feedback
- b7617 (b7617) – 2026-01-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b7617
- refactor: refactor silu
- refactor: optimize swiglu
- refactor: remove unncessary if in swiglu
- refactor: refactor swiglu_oai
- chore: fix formatting issue
- b7618 (b7618) – 2026-01-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b7618
- CUDA: Fixed obj byte size instead of obj count being passed to pool alloc (fattn-common, dst_tmp_meta)
- CUDA: Explicitly casted some of the int alloc counts before multiplication in argsort
- b7619 (b7619) – 2026-01-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b7619
- b7620 (b7620) – 2026-01-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b7620
- b7621 (b7621) – 2026-01-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b7621
2025-12-20: Update to llama.cpp b7488
- b7378 (b7378) – 2025-12-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7378
- b7379 (b7379) – 2025-12-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7379
- b7380 (b7380) – 2025-12-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7380
- b7381 (b7381) – 2025-12-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7381
- b7382 (b7382) – 2025-12-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7382
- b7383 (b7383) – 2025-12-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7383
- b7384 (b7384) – 2025-12-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7384
- b7385 (b7385) – 2025-12-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7385
- fix - w64devkit build
- fix - w64devkit build private scope
- b7386 (b7386) – 2025-12-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7386
- b7387 (b7387) – 2025-12-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7387
- b7388 (b7388) – 2025-12-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7388
- b7393 (b7393) – 2025-12-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b7393
- b7394 (b7394) – 2025-12-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b7394
- models : fix YaRN regression + consolidate logic
- cont : fix the fix
- cont : remove header
- cont : add header
- b7397 (b7397) – 2025-12-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b7397
- b7398 (b7398) – 2025-12-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b7398
- b7399 (b7399) – 2025-12-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b7399
- common : refactor common_sampler + grammar logic changes
- tests : increase max_tokens to get needed response
- batched : fix uninitialized samplers
- b7400 (b7400) – 2025-12-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b7400
- b7401 (b7401) – 2025-12-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b7401
- b7402 (b7402) – 2025-12-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b7402
- b7404 (b7404) – 2025-12-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b7404
- b7405 (b7405) – 2025-12-15 – https://github.com/ggml-org/llama.cpp/releases/tag/b7405
- [model] add glm-asr support
- fix format for ci
- fix convert format for ci
- update glm_asr convert script & use build_ffn for glm_asr clip & use build_stack for padding and review
- check root architecture for convert hf script
- fix conficlt with upstream
- fix convert script for glm asr & format clip-impl
- format
- restore hparams text
- improved conversion
- b7406 (b7406) – 2025-12-15 – https://github.com/ggml-org/llama.cpp/releases/tag/b7406
- support gpt-oss GPU by OP add-id, mul_mat for mxfp4, swiglu_oai, fix warning
- fix fault ut case, update ops.md
- rebase, fix format issue
- b7410 (b7410) – 2025-12-15 – https://github.com/ggml-org/llama.cpp/releases/tag/b7410
- mtmd: refactor audio preprocessing
- refactor
- wip
- wip (2)
- improve constructor
- fix use_natural_log
- fix padding for short input
- clean up
- remove need_chunking
- b7411 (b7411) – 2025-12-15 – https://github.com/ggml-org/llama.cpp/releases/tag/b7411
- metal: use shared buffers on eGPU
- metal: use shared buffers on eGPU
- metal: use shared buffers on eGPU
- b7413 (b7413) – 2025-12-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b7413
- kv-cache : fix state restore with fragmented cache (#17527)
- tests : update logic
- cleanup: tightened state_read_meta sig, added is_contiguous case
- fix: state_read_meta arg reorder loose ends
- b7414 (b7414) – 2025-12-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b7414
- vocab: add KORMo Tokenizer
- model: add KORMoForCausalLM
- vocab: change pretokenizer to qwen2
- lint: fix unintended line removal
- model: make qwen2 bias tensor optional
- model: use qwen2 architecture for KORMo
- b7415 (b7415) – 2025-12-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b7415
- feat: add run_mtmd script for hexagon
- fix: fix issue in fp16xfp32 mm
- fix: remove opt_experiment for fp16xfp32 mm
- fix: ggml-hexagon: matmul fp16xfp32 support non-contigious src0
- fix: fix syntax check for run-mtmd.sh for cli
- b7418 (b7418) – 2025-12-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b7418
- llama : add support for NVIDIA Nemotron Nano 3
- b7422 (b7422) – 2025-12-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b7422
- graph : reuse hybrid graphs
- graph : reuse recurrent graphs
- graph : fix reuse check for recurrent inputs
- memory : move the recurrent state into the memory context
- Revert "memory : move the recurrent state into the memory context"
- cont : fix build
- b7423 (b7423) – 2025-12-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b7423
- b7426 (b7426) – 2025-12-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b7426
- common : expose json-schema functionality to extract type info
- common : fix peg parser negation during needs_more_input
- common : add some defensive measures in constructed peg parser
- common : add nemotron nano 3 support
- common : add nemotron nano 3 tests
- remove debug line
- b7429 (b7429) – 2025-12-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b7429
- convert ok
- no deepstack
- less new tensors
- cgraph ok
- add mrope for text model
- faster patch merger
- add GGML_ROPE_TYPE_MRNORM
- add support for metal
- move glm4v do dedicated graph
- convert: add norm_embd
- clip: add debugging fn
- working correctly
- fix style
- use bicubic
- fix mrope metal
- improve cpu
- convert to neox ordering on conversion
- revert backend changes
- force stop if using old weight
- support moe variant
- fix conversion
- fix convert (2)
- Update tools/mtmd/clip-graph.h
- process mrope_section on TextModel base class
- resolve conflict merge
- b7432 (b7432) – 2025-12-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b7432
- It's Qwen3 Next, the lean mean token generation machine!
- Apply patches from thread
- Remove recurrent version, only keep chunked and autoregressive
- Remove unnecessary conts and asserts
- Remove more extra conts and asserts
- Cleanup masking
- b7433 (b7433) – 2025-12-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b7433
- arg: clarify auto kvu/np being set on server
- improve docs
- use invalid_argument
- b7434 (b7434) – 2025-12-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b7434
- arch: refactor LLM_TENSOR_NAMES
- update docs
- typo
- fix LLM_ARCH_NEMOTRON_H_MOE
- show more meaningful error message on missing tensor
- fix and tested LLM_ARCH_NEMOTRON_H_MOE
- b7436 (b7436) – 2025-12-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b7436
- server: fix crash when batch > ubatch with embeddings (#12836)
- Add parameter validation in main() after common_params_parse()
- When embeddings enabled and n_batch > n_ubatch:
- Log warnings explaining the issue
- Automatically set n_batch = n_ubatch
- Prevent server crash
- Build: Compiles successfully
- Validation triggers: Warns when -b > -ub with --embedding
- Auto-correction works: Adjusts n_batch = n_ubatch
- No false positives: Valid params don't trigger warnings
- Verified on macOS M3 Pro with embedding model
- Update tools/server/server.cpp
- b7437 (b7437) – 2025-12-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b7437
- b7438 (b7438) – 2025-12-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b7438
- b7439 (b7439) – 2025-12-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b7439
- b7440 (b7440) – 2025-12-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b7440
- b7441 (b7441) – 2025-12-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b7441
- b7442 (b7442) – 2025-12-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b7442
- b7444 (b7444) – 2025-12-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b7444
- b7445 (b7445) – 2025-12-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b7445
- b7446 (b7446) – 2025-12-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b7446
- UI: implement basic UI components
- util: implement performance monitor; wrap it with a viewmodel
- util: implement user preferences utility
- UI: implement core flow's screens
- UI: add a new MainActivity; update manifest
- [WIP] DI: implement simple local vm factory provider
- UI: disable triggering drawer via gesture; enable alert dialog on back navigation inside conversation and benchmark
- UI: allow drawer's gesture control only on Home and Settings screens; enable alert dialog on back navigation inside conversation and benchmark
- UI: split a nested parent settings screen into separate child settings screens
- UI: polish system prompt setup UI
- Deps: bump Kotlin plugin; introduce KSP; apply in :app subproject
- DB: setup Room database
- data: introduce repo for System Prompt; flow data from Room to VM
- bugfix: properly handle user's quitting conversation screen while tokens in generation
- UI: rename
ModeSelectiontoModelLoadingfor better clarity - UI: update app name to be more Arm
- UI: polish conversation screen
- data: code polish
- UI: code polish
- bugfix: handle user quitting on model loading
- UI: locks user in alert dialog when model is unloading
- vm: replace token metrics stubs with actual implementation
- UI: refactor top app bars
- nit: combine temperatureMetrics and useFahrenheit
- DI: introduce Hilt plugin + processor + lib dependencies
- DI: make app Hilt injectable
- DI: make viewmodels Hilt injectable
- DI: replace manual DI with Hilt DI
- UI: optimize AppContent's composing
- bugfix: wait for model to load before navigating to benchmark screen; use NavigationActions instead of raw navController
- UI: navigation with more natural animated transitions
- DI: Optimize AppModule
- Feature: Introduce ModelRepository and ModelsManagementViewModel; update AppModule
- UI: polish UI for ModelsManagementScreen; inject ModelsManagementVieModel
- DI: abstract the protocol of SystemPromptRepository; update AppModule
- data: [WIP] prepare for ModelRepository refactor & impl
- data: introduce Model entity and DAO; update DI module
- UI: replace Models Management screen's stubbing with instrumentation
- UI: polish sort order menu
- data: import local model with file picker
- bugfix: use List instead of Collection for ModelDao's deletion
- data: add a util file for extracting file name & size and model metadata
- UI: enrich ModelManagementState; extract filename to show correct importing UI
- UI: implement multiple models deletion; update Models Management screen
- UI: handle back navigation when user is in multi-selection mode
- util: extract file size formatting into ModelUtils
- UI: add a confirmation step when user picks a file; refactor model import overlay into AlertDialog
- UI: extract a shared ModelCard component
- UI: replace model selection screen's data stubbing; add empty view
- nit: tidy SystemPromptViewModel
- b7470 (b7470) – 2025-12-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b7470
- b7472 (b7472) – 2025-12-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b7472
- b7475 (b7475) – 2025-12-19 – https://github.com/ggml-org/llama.cpp/releases/tag/b7475
- ASR with LFM2-Audio-1.5B
- Set rope_theta
- Fix comment
- Remove rope_theta setting
- Address PR feedback
- rename functions to conformer
- remove some redundant ggml_cont
- fix missing tensor
- add prefix "a." for conv tensors
- remove redundant reshape
- clean up
- add test model
- b7476 (b7476) – 2025-12-19 – https://github.com/ggml-org/llama.cpp/releases/tag/b7476
- b7480 (b7480) – 2025-12-19 – https://github.com/ggml-org/llama.cpp/releases/tag/b7480
- presets: refactor, allow cascade presets from different sources
- update docs
- fix neg arg handling
- fix empty mmproj
- also filter out server-controlled args before to_ini()
- skip loading custom_models if not specified
- fix unset_reserved_args
- fix crash on windows
- b7481 (b7481) – 2025-12-19 – https://github.com/ggml-org/llama.cpp/releases/tag/b7481
- llama-server: friendlier error msg when ctx < input
- llama-server: use string_format inline
- fix test
- b7482 (b7482) – 2025-12-19 – https://github.com/ggml-org/llama.cpp/releases/tag/b7482
- b7483 (b7483) – 2025-12-19 – https://github.com/ggml-org/llama.cpp/releases/tag/b7483
- arg: fix order to use short form before long form
- arg: update doc
- arg: update test-arg-parser
- arg: address review feedback from ngxson
- arg: update doc
- b7484 (b7484) – 2025-12-19 – https://github.com/ggml-org/llama.cpp/releases/tag/b7484
- feat: implement real Q8_0
- feat: adding cmake option for configuring FP32 quantize group size
- typo: set() shall be used
- b7486 (b7486) – 2025-12-19 – https://github.com/ggml-org/llama.cpp/releases/tag/b7486
- remove non-windows zip artifacts
- add cuda dll links
- b7487 (b7487) – 2025-12-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b7487
- server: support autoload model, support preset-only options
- add docs
- load-on-startup
- fix
- Update common/arg.cpp
- b7488 (b7488) – 2025-12-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b7488
2025-12-13: Update to llama.cpp b7376
- b7285 (b7285) – 2025-12-05 – https://github.com/ggml-org/llama.cpp/releases/tag/b7285
- b7296 (b7296) – 2025-12-06 – https://github.com/ggml-org/llama.cpp/releases/tag/b7296
- metal : fix build
- tests : fix context destruction
- b7298 (b7298) – 2025-12-06 – https://github.com/ggml-org/llama.cpp/releases/tag/b7298
- b7300 (b7300) – 2025-12-06 – https://github.com/ggml-org/llama.cpp/releases/tag/b7300
- b7301 (b7301) – 2025-12-06 – https://github.com/ggml-org/llama.cpp/releases/tag/b7301
- llama : remove quantization sanity check
- llama : remove unused pruned_attention_w and is_clip_model vars
- b7302 (b7302) – 2025-12-06 – https://github.com/ggml-org/llama.cpp/releases/tag/b7302
- Improve error handling for search path existence checks
- Improve cache file existence check with error code
- Simplify existence check for search paths
- Fix logging path in error message for posix_stat
- Update ggml/src/ggml-backend-reg.cpp
- Adapt to the coding standard
- b7306 (b7306) – 2025-12-06 – https://github.com/ggml-org/llama.cpp/releases/tag/b7306
- b7307 (b7307) – 2025-12-06 – https://github.com/ggml-org/llama.cpp/releases/tag/b7307
- Feat: Added vulkan circular tiling support
- Feat: Added cpu circular
- Feat: Added cuda kernels
- Added tests
- Added tests
- Removed non-pad operations
- Removed unneded changes
- removed backend non pad tests
- Update test-backend-ops.cpp
- Fixed comment on pad test
- removed trailing whitespace
- Removed unneded test in test-backend-ops
- Removed removed test from calls
- Update ggml/src/ggml-vulkan/vulkan-shaders/pad.comp
- Fixed alignment
- Formatting
- Format pad
- Format
- Clang format
- format
- format
- don't change so much stuff
- clang format and update to bool
- fix duplicates
- don't need to fix the padding
- make circular bool
- duplicate again
- rename vulkan to wrap around
- Don't need indent
- moved to const expr
- removed unneded extra line break
- More readable method calls
- Minor wording changes
- Added final newline
- Update ggml/include/ggml.h
- Update ggml/include/ggml.h
- Added circular pad ext tests
- Gate non circular pad devices
- Cleaned gating of non-circular pad devices
- b7310 (b7310) – 2025-12-06 – https://github.com/ggml-org/llama.cpp/releases/tag/b7310
- vulkan: perf_logger improvements
- Move perf_logger from device to ctx.
- Add an env var to control the frequency we dump the stats. If you set a very
- Add a fusion info string to the tracking, only log one item per fused op.
- Fix MUL_MAT_ID flops calculation.
- fix vector sizes
- b7311 (b7311) – 2025-12-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b7311
- sycl: add missing BF16 conversion support for Intel oneAPI
- Fix Line 645: Trailing whitespace
- b7312 (b7312) – 2025-12-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b7312
- b7313 (b7313) – 2025-12-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b7313
- b7314 (b7314) – 2025-12-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b7314
- Optimize Vulkan shader for matrix-vector multiplication
- Revert changes on compute_outputs and main
- Fix trailing whitespace
- b7315 (b7315) – 2025-12-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b7315
- b7316 (b7316) – 2025-12-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b7316
- ggml-cpu: add ggml_thread_cpu_relax with Zihintpause support
- cmake: enable RISC-V zihintpause extension for Spacemit builds
- readme : add ZIHINTPAUSE support for RISC-V
- b7317 (b7317) – 2025-12-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b7317
- ggml-cuda: optimize solve_tri_f32_fast and fix stride handling
- Switch from using shared memory for the RHS/solution matrix to a register-based approach (x_low, x_high), reducing shared memory pressure and bank conflicts.
- Implement explicit
fmafinstructions for the reduction loop. - Update kernel arguments to pass strides in bytes rather than elements to align with standard ggml tensor arithmetic (casting to
char *before addition). - Remove unused
MAX_K_FASTdefinition. - Small cleanup
- Remove comments in solve_tri.cu
- Update ggml/src/ggml-cuda/solve_tri.cu
- Update ggml/src/ggml-cuda/solve_tri.cu
- Update ggml/src/ggml-cuda/solve_tri.cu
- Use const for variables in solve_tri.cu
- Replace fmaf with more readable code
- remove last fmaf
- b7318 (b7318) – 2025-12-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b7318
- b7324 (b7324) – 2025-12-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b7324
- support bfloat16 release package
- add fallback file
- b7325 (b7325) – 2025-12-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b7325
- server: delegate result_state creation to server_task
- remove unued states
- add more docs
- b7327 (b7327) – 2025-12-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b7327
- use fill instead of scale_bias in grouped expert selection
- do not explicitly use _inplace
- b7328 (b7328) – 2025-12-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b7328
- add support for rnj1
- refactor gemma3 to support rnj-1
- address review comments
- b7329 (b7329) – 2025-12-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b7329
- llama : add token support to llama-grammar
- fix inverse token comment
- refactor trigger_patterns to replay tokens instead of the entire string
- add token documentation
- fix test-llama-grammar
- improve test cases for tokens
- b7330 (b7330) – 2025-12-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b7330
- b7331 (b7331) – 2025-12-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b7331
- cann: add support for partial RoPE and Vision mode
- Support for partial RoPE (rope_dims < ne0):
- Split tensor into head (first rope_dims dimensions) and tail portions
- Apply rotation only to head portion using RotaryPositionEmbedding operator
- Copy unrotated tail portion directly from source to destination
- Handle both contiguous and non-contiguous tensor layouts
- Support for Vision mode (GGML_ROPE_TYPE_VISION):
- Set rope_dims = ne0 for Vision mode to rotate entire tensor
- Vision mode pairs dimension i with dimension i+n_dims (where n_dims = ne0/2)
- No tail handling needed since entire tensor is rotated
- Use has_tail flag to determine execution path: head/tail splitting when
- Support both F32 and F16 data types with intermediate F32 conversion
- Copy non-contiguous tensors to contiguous buffers before calling
- Improve cache invalidation logic to include rope_dims and indep_sects
- cann: fix review comment
- b7332 (b7332) – 2025-12-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b7332
- console: allow using arrow left/right to edit the line (with UTF-8 support)
- console: fix arrow keys on Windows using private-use Unicode
- console: add Home/End key support for Windows and Linux
- console: add basic Up/Down history navigation
- fix build
- console: allow using arrow left/right to edit the line (with UTF-8 support)
- console: fix arrow keys on Windows using private-use Unicode
- console: add Home/End key support for Windows and Linux
- console: add basic Up/Down history navigation
- console: remove unreachable wc == 0 check after VK switch
- console: add Ctrl+Left/Right word navigation
- Add KEY_CTRL_ARROW_LEFT and KEY_CTRL_ARROW_RIGHT codes
- Windows: detect CTRL modifier via dwControlKeyState
- Linux: parse ANSI sequences with modifier (1;5D/C)
- Implement move_word_left/right with space-skipping logic
- Refactor escape sequence parsing to accumulate params
- console: add Delete key support
- Windows: VK_DELETE detection
- Linux: ESC[3~ sequence parsing
- Forward character deletion with UTF-8 support
- console: implement bash-style history editing
- Edit any history line during UP/DOWN navigation, edits persist
- Pressing Enter appends edited version as new history entry
- Original line stay untouched in their positions
- clean up
- better history impl
- fix decode_utf8
- b7333 (b7333) – 2025-12-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b7333
- nit, DeepSeek V1 MoE is 16B
- base type on n_ff_exp instead
- b7334 (b7334) – 2025-12-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b7334
- This just sets the Mach-O current version to 0 to get it building
- b7335 (b7335) – 2025-12-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b7335
- b7336 (b7336) – 2025-12-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b7336
- b7337 (b7337) – 2025-12-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b7337
- fix: Provide macos-specific backtrace printing to avoid terminal death
- fix: Add GGML_BACKTRACE_LLDB env var to enable using lldb for backtrace
- b7339 (b7339) – 2025-12-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b7339
- Add DIAG for CUDA
- Refactor parameters
- b7340 (b7340) – 2025-12-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b7340
- feat: Add a batched version of ssm_conv
- feat: Optimized SSM_SCAN kernel for metal
- test: Add test-backend-ops perf tests for SSM_CONV
- test: Real representitive tests for SSM_CONV
- refactor: Use function constant for ssm_conv batch size
- test: backend op tests for ssm_scan from granite4 1b-h
- style: remove commented out templates
- feat: float4 version of ssm_conv_batched
- fix: Add missing ggml_metal_cv_free
- b7342 (b7342) – 2025-12-10 – https://github.com/ggml-org/llama.cpp/releases/tag/b7342
- b7343 (b7343) – 2025-12-10 – https://github.com/ggml-org/llama.cpp/releases/tag/b7343
- b7345 (b7345) – 2025-12-10 – https://github.com/ggml-org/llama.cpp/releases/tag/b7345
- b7347 (b7347) – 2025-12-10 – https://github.com/ggml-org/llama.cpp/releases/tag/b7347
- model : Qwen3-Next-80B-A3B has 48 layers
- model : Add 80B-A3B type name
- b7348 (b7348) – 2025-12-10 – https://github.com/ggml-org/llama.cpp/releases/tag/b7348
- wip
- wip
- fix logging, add display info
- handle commands
- add args
- wip
- move old cli to llama-completion
- rm deprecation notice
- move server to a shared library
- move ci to llama-completion
- add loading animation
- add --show-timings arg
- add /read command, improve LOG_ERR
- add args for speculative decoding, enable show timings by default
- add arg --image and --audio
- fix windows build
- support reasoning_content
- fix llama2c workflow
- color default is auto
- fix merge conflicts
- properly fix color problem
- better loading spinner
- make sure to clean color on force-exit
- also clear input files on "/clear"
- simplify common_log_flush
- add warning in mtmd-cli
- implement console writter
- fix data race
- add attribute
- fix llama-completion and mtmd-cli
- add some notes about console::log
- fix compilation
- b7349 (b7349) – 2025-12-10 – https://github.com/ggml-org/llama.cpp/releases/tag/b7349
- b7350 (b7350) – 2025-12-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b7350
- ggml : remove GGML_KQ_MASK_PAD constant
- cont : remove comment
- b7351 (b7351) – 2025-12-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b7351
- tests: update barrier test to check for race condition in active threads
- cpu: combine n_graph and n_threads into a single atomic update
- tests: add multi-graph test for test_barrier
- b7352 (b7352) – 2025-12-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b7352
- llama-server: recursive GGUF loading
- server : router config POC (INI-based per-model settings)
- server: address review feedback from @aldehir and @ngxson
- Simplify parser instantiation (remove arena indirection)
- Optimize grammar usage (ws instead of zero_or_more, remove optional wrapping)
- Fix last line without newline bug (+ operator instead of <<)
- Remove redundant end position check
- Remove auto-reload feature (will be separate PR per @ngxson)
- Keep config.ini auto-creation and template generation
- Preserve per-model customization logic
- server: adopt aldehir's line-oriented PEG parser
- Use p.chars(), p.negate(), p.any() instead of p.until()
- Support end-of-line comments (key=value # comment)
- Handle EOF without trailing newline correctly
- Strict identifier validation ([a-zA-Z_][a-zA-Z0-9_.-]*)
- Simplified visitor (no pending state, no trim needed)
- Grammar handles whitespace natively via eol rule
- Reject section names starting with LLAMA_ARG_*
- Accept only keys starting with LLAMA_ARG_*
- Require explicit section before key-value pairs
- server: fix CLI/env duplication in child processes
- add common/preset.cpp
- fix compile
- cont
- allow custom-path models
- add falsey check
- server: fix router model discovery and child process spawning
- Sanitize model names: replace / and \ with _ for display
- Recursive directory scan with relative path storage
- Convert relative paths to absolute when spawning children
- Filter router control args from child processes
- Refresh args after port assignment for correct port value
- Fallback preset lookup for compatibility
- Fix missing argv[0]: store server binary path before base_args parsing
- Revert "server: fix router model discovery and child process spawning"
- clarify about "no-" prefix
- correct render_args() to include binary path
- also remove arg LLAMA_ARG_MODELS_PRESET for child
- add co-author for ini parser code
- also set LLAMA_ARG_HOST
- add CHILD_ADDR
- Remove dead code
- b7353 (b7353) – 2025-12-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b7353
- cli: enable jinja by default
- Update common/arg.cpp
- b7354 (b7354) – 2025-12-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b7354
- clip: add support for fused qkv in build_vit
- use bulid_ffn whenever possible
- fix internvl
- mtmd-cli: move image to beginning
- test script: support custom args
- b7356 (b7356) – 2025-12-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b7356
- fix test failure
- fix: correct scaling calculations in rope_cache_init
- fix: optimize element copying in rope_hex_f32 using memcpy
- fix: optimize loop boundaries in rope_hex_f32 for better performance
- feat: add profiling macros for performance measurement in operations
- b7358 (b7358) – 2025-12-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b7358
- batch : fix sequence id ownage
- cont : reduce allocations
- b7360 (b7360) – 2025-12-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b7360
- Extended TRI
- Fix whitespace
- chore: update webui build output
- Just use cuBLAS for everything...
- Merge both versions
- Remove incorrect imports causing failures for CI
- Still failing... remove all direct cublas imports and rely on common imports from "common.cuh"
- Defines for hipBlas
- Aaaand MUSA defines...
- I hate this job...
- Stupid typo...
- Update ggml/src/ggml-cuda/solve_tri.cu
- b7362 (b7362) – 2025-12-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b7362
- enable mmf for RDNA3
- disable mmf for some shape
- move some mmvf to mmf
- more mmfv to mmf
- 3 is good in mmvf
- b7363 (b7363) – 2025-12-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b7363
- b7364 (b7364) – 2025-12-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b7364
- b7366 (b7366) – 2025-12-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7366
- arg: add -mm and -mmu as short form of --mmproj and --mmproj-url
- correct order
- update docs
- b7368 (b7368) – 2025-12-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b7368
- b7369 (b7369) – 2025-12-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b7369
- ggml-cpu:fix RISC-V Q4_0 repack select and RVV feature reporting
- using the name VLEN instead of CNT
- Update ggml/include/ggml-cpu.h
- b7370 (b7370) – 2025-12-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b7370
- b7371 (b7371) – 2025-12-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b7371
- models : fix the attn_factor for mistral3 graphs
- cont : rework attn_factor correction logic
- cont : make deepseek2 consistent
- cont : add TODO
- cont : special-case DSv2
- cont : revert Mistral 3 Large changes
- cont : fix DS2 to use the original attn_factor
- cont : minor comments
- b7372 (b7372) – 2025-12-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7372
- b7374 (b7374) – 2025-12-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7374
- b7375 (b7375) – 2025-12-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7375
- clip: move model cgraphs into their own files
- more explicit enums
- fix linux build
- fix naming
- missing headers
- nits: add comments for contributors
- b7376 (b7376) – 2025-12-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7376
- args: support negated args
- update docs
- fix typo
- add more neg options
- Apply suggestions from code review
- rm duplicated arg
- fix LLAMA_ARG_NO_HOST
- add test
2025-12-05: Update to llama.cpp b7278
- b7218 (b7218) – 2025-12-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b7218
- b7219 (b7219) – 2025-12-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b7219
- b7220 (b7220) – 2025-12-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b7220
- b7222 (b7222) – 2025-12-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b7222
- b7223 (b7223) – 2025-12-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b7223
- b7224 (b7224) – 2025-12-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b7224
- b7225 (b7225) – 2025-12-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b7225
- b7227 (b7227) – 2025-12-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b7227
- b7229 (b7229) – 2025-12-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b7229
- Revert "rm unused fn"
- server: explicitly set exec path when create new instance
- put back TODO
- only call get_server_exec_path() once
- add fallback logic
- b7230 (b7230) – 2025-12-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b7230
- b7231 (b7231) – 2025-12-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b7231
- server: remove default "gpt-3.5-turbo" model name
- do not reflect back model name from request
- fix test
- b7233 (b7233) – 2025-12-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b7233
- b7235 (b7235) – 2025-12-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b7235
- b7236 (b7236) – 2025-12-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b7236
- b7237 (b7237) – 2025-12-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b7237
- b7239 (b7239) – 2025-12-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b7239
- b7240 (b7240) – 2025-12-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b7240
- Compute row size for the temp buffer based on the output of the first pass.
- Update shader addressing math to use the output row size
- Pass the output row size as "ncols_output", what used to be "ncols_output" is now "k"
- b7243 (b7243) – 2025-12-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b7243
- server: add --media-path for local media files
- remove unused fn
- b7245 (b7245) – 2025-12-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b7245
- b7247 (b7247) – 2025-12-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b7247
- Faster tensors (#8)
- Use map for shader replacements instead of pair of strings
- Wasm (#9)
- webgpu : fix build on emscripten
- more debugging stuff
- test-backend-ops: force single thread on wasm
- fix single-thread case for init_tensor_uniform
- use jspi
- add pthread
- test: remember to set n_thread for cpu backend
- Add buffer label and enable dawn-specific toggles to turn off some checks
- Intermediate state
- Fast working f16/f32 vec4
- Working float fast mul mat
- Clean up naming of mul_mat to match logical model, start work on q mul_mat
- Setup for subgroup matrix mat mul
- Basic working subgroup matrix
- Working subgroup matrix tiling
- Handle weirder sg matrix sizes (but still % sg matrix size)
- Working start to gemv
- working f16 accumulation with shared memory staging
- Print out available subgroup matrix configurations
- Vectorize dst stores for sg matrix shader
- Gemv working scalar
- Minor set_rows optimization (#4)
- updated optimization, fixed errors
- non vectorized version now dispatches one thread per element
- Simplify
- Change logic for set_rows pipelines
- Comment on dawn toggles
- Working subgroup matrix code for (semi)generic sizes
- Remove some comments
- Cleanup code
- Update dawn version and move to portable subgroup size
- Try to fix new dawn release
- Update subgroup size comment
- Only check for subgroup matrix configs if they are supported
- Add toggles for subgroup matrix/f16 support on nvidia+vulkan
- Make row/col naming consistent
- Refactor shared memory loading
- Move sg matrix stores to correct file
- Working q4_0
- Formatting
- Work with emscripten builds
- Fix test-backend-ops emscripten for f16/quantized types
- Use emscripten memory64 to support get_memory
- Add build flags and try ci
- Remove extra whitespace
- Move wasm single-thread logic out of test-backend-ops for cpu backend
- Disable multiple threads for emscripten single-thread builds in ggml_graph_plan
- b7248 (b7248) – 2025-12-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b7248
- llama-server: fix duplicate HTTP headers in multiple models mode (#17693)
- llama-server: address review feedback from ngxson
- restrict scope of header after std::move
- simplify header check (remove unordered_set)
- b7250 (b7250) – 2025-12-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b7250
- Remove the build of openeuler-cann in release
- Remove the relevant release files
- b7251 (b7251) – 2025-12-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b7251
- b7252 (b7252) – 2025-12-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b7252
- b7253 (b7253) – 2025-12-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b7253
- b7255 (b7255) – 2025-12-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b7255
- b7256 (b7256) – 2025-12-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b7256
- CUDA: generalized (mma) FA, add Volta support
- use struct for MMA FA kernel config
- b7261 (b7261) – 2025-12-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b7261
- b7262 (b7262) – 2025-12-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b7262
- build: enable parallel builds in msbuild using MTT
- check LLAMA_STANDALONE
- b7263 (b7263) – 2025-12-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b7263
- b7264 (b7264) – 2025-12-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b7264
- b7265 (b7265) – 2025-12-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b7265
- b7266 (b7266) – 2025-12-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b7266
- b7268 (b7268) – 2025-12-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b7268
- b7270 (b7270) – 2025-12-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b7270
- b7271 (b7271) – 2025-12-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b7271
- b7273 (b7273) – 2025-12-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b7273
- server: move msg diffs tracking to HTTP thread
- wip
- tool call tests ok
- minor : style
- cont : fix
- move states to server_response_reader
- add safe-guard
- fix
- fix 2
- b7274 (b7274) – 2025-12-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b7274
- b7275 (b7275) – 2025-12-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b7275
- feat(wip): Port initial TRI impl from pervious work
- fix: Remove argument for constant val override
- feat: Move the ttype conditional to templating to avoid conditional in kernel
- fix: Type fixes
- feat: Add softplus for metal
- feat: Add EXPM1 for metal
- feat: Add FILL for metal
- refactor: Branchless version of tri using _ggml_vec_tri_cmp as a mask
- fix: Remove unused arguments
- refactor: Use select instead of branch for softplus non-vec
- b7276 (b7276) – 2025-12-05 – https://github.com/ggml-org/llama.cpp/releases/tag/b7276
- Add support for CUMSUM and TRI for CUDA.
- Minor optimizations.
- Correct warp_prefix_inclusive_sum in float2 variant to return float2
- Optimize TRI
- Whitespace
- Fix strides.
- Implement double loop
- Whitespace
- Fix HIP compilation bugs
- Optimizations + big case performance tests
- Implement using CUB with fallback to custom kernel
- Remove error message.
- Fixes from code review
- Comment out CPU-unsupported F16/BF16 cases to fix CI
- Fine, you win :P
- Fix last cast, use NO_DEVICE_CODE and GGML_UNUSED_VARS
- Vary warp-size based on physical warp size
- Add GGML_UNUSED_VARS in tri as well
- Use constexpr and call prefix_inclusive with warp_size template param
- Update ggml/src/ggml-cuda/cumsum.cu
- Apply suggestions from code review
- Change to tid % warp_size
- Fix strides; hardcode mask; add ggml_lane_mask_t
- Missing renames, remove unused get_warp_mask(), explicit calls to ggml_cuda_info()
- Too hasty...
- b7278 (b7278) – 2025-12-05 – https://github.com/ggml-org/llama.cpp/releases/tag/b7278
- transform release binary root dir in tar to llama-bXXXX
- bsdtar supports -s instead of --transform
2025-12-01: Update to llama.cpp b7213
- b7090 (b7090) – 2025-11-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b7090
- b7091 (b7091) – 2025-11-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b7091
- b7096 (b7096) – 2025-11-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b7096
- b7097 (b7097) – 2025-11-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b7097
- b7100 (b7100) – 2025-11-19 – https://github.com/ggml-org/llama.cpp/releases/tag/b7100
- b7101 (b7101) – 2025-11-19 – https://github.com/ggml-org/llama.cpp/releases/tag/b7101
- b7102 (b7102) – 2025-11-19 – https://github.com/ggml-org/llama.cpp/releases/tag/b7102
- b7103 (b7103) – 2025-11-19 – https://github.com/ggml-org/llama.cpp/releases/tag/b7103
- b7106 (b7106) – 2025-11-19 – https://github.com/ggml-org/llama.cpp/releases/tag/b7106
- b7107 (b7107) – 2025-11-19 – https://github.com/ggml-org/llama.cpp/releases/tag/b7107
- b7108 (b7108) – 2025-11-19 – https://github.com/ggml-org/llama.cpp/releases/tag/b7108
- b7109 (b7109) – 2025-11-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b7109
- b7110 (b7110) – 2025-11-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b7110
- b7111 (b7111) – 2025-11-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b7111
- b7112 (b7112) – 2025-11-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b7112
- b7113 (b7113) – 2025-11-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b7113
- b7117 (b7117) – 2025-11-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b7117
- b7118 (b7118) – 2025-11-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b7118
- b7120 (b7120) – 2025-11-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b7120
- b7122 (b7122) – 2025-11-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b7122
- b7123 (b7123) – 2025-11-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b7123
- b7124 (b7124) – 2025-11-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b7124
- b7126 (b7126) – 2025-11-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b7126
- b7127 (b7127) – 2025-11-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b7127
- b7128 (b7128) – 2025-11-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b7128
- b7129 (b7129) – 2025-11-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b7129
- b7130 (b7130) – 2025-11-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b7130
- b7132 (b7132) – 2025-11-23 – https://github.com/ggml-org/llama.cpp/releases/tag/b7132
- b7134 (b7134) – 2025-11-23 – https://github.com/ggml-org/llama.cpp/releases/tag/b7134
- b7136 (b7136) – 2025-11-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b7136
- b7137 (b7137) – 2025-11-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b7137
- b7138 (b7138) – 2025-11-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b7138
- b7139 (b7139) – 2025-11-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b7139
- b7140 (b7140) – 2025-11-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b7140
- b7141 (b7141) – 2025-11-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b7141
- b7142 (b7142) – 2025-11-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b7142
- b7144 (b7144) – 2025-11-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b7144
- b7146 (b7146) – 2025-11-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b7146
- b7148 (b7148) – 2025-11-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b7148
- b7149 (b7149) – 2025-11-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b7149
- b7150 (b7150) – 2025-11-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b7150
- b7151 (b7151) – 2025-11-25 – https://github.com/ggml-org/llama.cpp/releases/tag/b7151
- b7152 (b7152) – 2025-11-25 – https://github.com/ggml-org/llama.cpp/releases/tag/b7152
- b7154 (b7154) – 2025-11-25 – https://github.com/ggml-org/llama.cpp/releases/tag/b7154
- b7157 (b7157) – 2025-11-25 – https://github.com/ggml-org/llama.cpp/releases/tag/b7157
- b7158 (b7158) – 2025-11-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b7158
- b7159 (b7159) – 2025-11-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b7159
- b7160 (b7160) – 2025-11-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b7160
- b7161 (b7161) – 2025-11-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b7161
- b7162 (b7162) – 2025-11-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b7162
- b7163 (b7163) – 2025-11-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b7163
- b7164 (b7164) – 2025-11-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b7164
- b7165 (b7165) – 2025-11-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b7165
- b7166 (b7166) – 2025-11-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b7166
- b7167 (b7167) – 2025-11-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b7167
- b7168 (b7168) – 2025-11-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b7168
- b7169 (b7169) – 2025-11-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b7169
- b7170 (b7170) – 2025-11-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b7170
- b7171 (b7171) – 2025-11-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b7171
- b7172 (b7172) – 2025-11-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b7172
- b7175 (b7175) – 2025-11-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b7175
- b7176 (b7176) – 2025-11-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b7176
- b7177 (b7177) – 2025-11-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b7177
- b7178 (b7178) – 2025-11-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b7178
- b7179 (b7179) – 2025-11-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b7179
- b7180 (b7180) – 2025-11-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7180
- b7181 (b7181) – 2025-11-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7181
- b7182 (b7182) – 2025-11-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7182
- b7183 (b7183) – 2025-11-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7183
- b7184 (b7184) – 2025-11-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7184
- b7185 (b7185) – 2025-11-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7185
- b7186 (b7186) – 2025-11-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7186
- b7187 (b7187) – 2025-11-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7187
- b7188 (b7188) – 2025-11-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7188
- b7189 (b7189) – 2025-11-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7189
- b7190 (b7190) – 2025-11-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7190
- b7191 (b7191) – 2025-11-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7191
- b7192 (b7192) – 2025-11-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b7192
- b7194 (b7194) – 2025-11-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b7194
- b7195 (b7195) – 2025-11-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b7195
- b7196 (b7196) – 2025-11-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b7196
- b7197 (b7197) – 2025-11-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b7197
- b7198 (b7198) – 2025-11-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b7198
- b7199 (b7199) – 2025-11-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b7199
- b7200 (b7200) – 2025-11-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b7200
- b7201 (b7201) – 2025-11-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b7201
- b7202 (b7202) – 2025-11-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b7202
- b7203 (b7203) – 2025-11-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b7203
- b7204 (b7204) – 2025-11-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b7204
- b7205 (b7205) – 2025-11-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b7205
- b7206 (b7206) – 2025-11-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b7206
- b7207 (b7207) – 2025-11-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b7207
- b7208 (b7208) – 2025-11-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b7208
- b7209 (b7209) – 2025-11-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b7209
- b7210 (b7210) – 2025-11-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b7210
- b7211 (b7211) – 2025-11-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b7211
- b7213 (b7213) – 2025-12-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b7213
2025-11-14: Update to llama.cpp b7058
- b6959 (b6959) – 2025-11-05 – https://github.com/ggml-org/llama.cpp/releases/tag/b6959
- b6960 (b6960) – 2025-11-05 – https://github.com/ggml-org/llama.cpp/releases/tag/b6960
- b6961 (b6961) – 2025-11-05 – https://github.com/ggml-org/llama.cpp/releases/tag/b6961
- b6962 (b6962) – 2025-11-05 – https://github.com/ggml-org/llama.cpp/releases/tag/b6962
- b6963 (b6963) – 2025-11-06 – https://github.com/ggml-org/llama.cpp/releases/tag/b6963
- b6965 (b6965) – 2025-11-06 – https://github.com/ggml-org/llama.cpp/releases/tag/b6965
- b6966 (b6966) – 2025-11-06 – https://github.com/ggml-org/llama.cpp/releases/tag/b6966
- b6967 (b6967) – 2025-11-06 – https://github.com/ggml-org/llama.cpp/releases/tag/b6967
- b6968 (b6968) – 2025-11-06 – https://github.com/ggml-org/llama.cpp/releases/tag/b6968
- b6969 (b6969) – 2025-11-06 – https://github.com/ggml-org/llama.cpp/releases/tag/b6969
- b6970 (b6970) – 2025-11-06 – https://github.com/ggml-org/llama.cpp/releases/tag/b6970
- b6971 (b6971) – 2025-11-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b6971
- b6972 (b6972) – 2025-11-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b6972
- b6973 (b6973) – 2025-11-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b6973
- b6974 (b6974) – 2025-11-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b6974
- b6975 (b6975) – 2025-11-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b6975
- b6976 (b6976) – 2025-11-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b6976
- b6977 (b6977) – 2025-11-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b6977
- b6978 (b6978) – 2025-11-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b6978
- b6979 (b6979) – 2025-11-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b6979
- b6980 (b6980) – 2025-11-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b6980
- b6981 (b6981) – 2025-11-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b6981
- b6982 (b6982) – 2025-11-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b6982
- b6983 (b6983) – 2025-11-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b6983
- b6984 (b6984) – 2025-11-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b6984
- b6985 (b6985) – 2025-11-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b6985
- b6986 (b6986) – 2025-11-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b6986
- b6987 (b6987) – 2025-11-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b6987
- b6988 (b6988) – 2025-11-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b6988
- b6989 (b6989) – 2025-11-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b6989
- b6990 (b6990) – 2025-11-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b6990
- b6992 (b6992) – 2025-11-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b6992
- b6993 (b6993) – 2025-11-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b6993
- b6994 (b6994) – 2025-11-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b6994
- b6995 (b6995) – 2025-11-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b6995
- b6996 (b6996) – 2025-11-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b6996
- b6999 (b6999) – 2025-11-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b6999
- b7002 (b7002) – 2025-11-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b7002
- b7003 (b7003) – 2025-11-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b7003
- b7005 (b7005) – 2025-11-10 – https://github.com/ggml-org/llama.cpp/releases/tag/b7005
- b7007 (b7007) – 2025-11-10 – https://github.com/ggml-org/llama.cpp/releases/tag/b7007
- b7008 (b7008) – 2025-11-10 – https://github.com/ggml-org/llama.cpp/releases/tag/b7008
- b7009 (b7009) – 2025-11-10 – https://github.com/ggml-org/llama.cpp/releases/tag/b7009
- b7010 (b7010) – 2025-11-10 – https://github.com/ggml-org/llama.cpp/releases/tag/b7010
- b7011 (b7011) – 2025-11-10 – https://github.com/ggml-org/llama.cpp/releases/tag/b7011
- b7012 (b7012) – 2025-11-10 – https://github.com/ggml-org/llama.cpp/releases/tag/b7012
- b7013 (b7013) – 2025-11-10 – https://github.com/ggml-org/llama.cpp/releases/tag/b7013
- b7014 (b7014) – 2025-11-10 – https://github.com/ggml-org/llama.cpp/releases/tag/b7014
- b7015 (b7015) – 2025-11-10 – https://github.com/ggml-org/llama.cpp/releases/tag/b7015
- b7016 (b7016) – 2025-11-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b7016
- b7017 (b7017) – 2025-11-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b7017
- b7018 (b7018) – 2025-11-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b7018
- b7020 (b7020) – 2025-11-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b7020
- b7021 (b7021) – 2025-11-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b7021
- b7022 (b7022) – 2025-11-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b7022
- b7023 (b7023) – 2025-11-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b7023
- b7024 (b7024) – 2025-11-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b7024
- b7025 (b7025) – 2025-11-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b7025
- b7027 (b7027) – 2025-11-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b7027
- b7028 (b7028) – 2025-11-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b7028
- b7030 (b7030) – 2025-11-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b7030
- b7031 (b7031) – 2025-11-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b7031
- b7032 (b7032) – 2025-11-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b7032
- b7033 (b7033) – 2025-11-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b7033
- b7034 (b7034) – 2025-11-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b7034
- b7035 (b7035) – 2025-11-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b7035
- b7037 (b7037) – 2025-11-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b7037
- b7039 (b7039) – 2025-11-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b7039
- b7041 (b7041) – 2025-11-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7041
- b7042 (b7042) – 2025-11-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7042
- b7044 (b7044) – 2025-11-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7044
- b7045 (b7045) – 2025-11-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7045
- b7046 (b7046) – 2025-11-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7046
- b7047 (b7047) – 2025-11-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7047
- b7048 (b7048) – 2025-11-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7048
- b7049 (b7049) – 2025-11-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7049
- b7050 (b7050) – 2025-11-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7050
- b7051 (b7051) – 2025-11-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7051
- b7052 (b7052) – 2025-11-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7052
- b7053 (b7053) – 2025-11-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7053
- b7054 (b7054) – 2025-11-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b7054
- b7057 (b7057) – 2025-11-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b7057
- b7058 (b7058) – 2025-11-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b7058
2025-11-05: Update to llama.cpp b6957
- b6919 (b6919) – 2025-11-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b6919
- b6920 (b6920) – 2025-11-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b6920
- b6922 (b6922) – 2025-11-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b6922
- b6923 (b6923) – 2025-11-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b6923
- b6924 (b6924) – 2025-11-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b6924
- b6927 (b6927) – 2025-11-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b6927
- b6929 (b6929) – 2025-11-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b6929
- b6931 (b6931) – 2025-11-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b6931
- b6932 (b6932) – 2025-11-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b6932
- b6933 (b6933) – 2025-11-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b6933
- b6934 (b6934) – 2025-11-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b6934
- b6935 (b6935) – 2025-11-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b6935
- b6936 (b6936) – 2025-11-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b6936
- b6937 (b6937) – 2025-11-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b6937
- b6940 (b6940) – 2025-11-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b6940
- b6941 (b6941) – 2025-11-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b6941
- b6942 (b6942) – 2025-11-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b6942
- b6943 (b6943) – 2025-11-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b6943
- b6945 (b6945) – 2025-11-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b6945
- b6947 (b6947) – 2025-11-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b6947
- b6948 (b6948) – 2025-11-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b6948
- b6949 (b6949) – 2025-11-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b6949
- b6953 (b6953) – 2025-11-05 – https://github.com/ggml-org/llama.cpp/releases/tag/b6953
- b6954 (b6954) – 2025-11-05 – https://github.com/ggml-org/llama.cpp/releases/tag/b6954
- b6955 (b6955) – 2025-11-05 – https://github.com/ggml-org/llama.cpp/releases/tag/b6955
- b6957 (b6957) – 2025-11-05 – https://github.com/ggml-org/llama.cpp/releases/tag/b6957
2025-11-01: Update to llama.cpp b6916
- b6904 (b6904) – 2025-10-31 – https://github.com/ggml-org/llama.cpp/releases/tag/b6904
- b6905 (b6905) – 2025-10-31 – https://github.com/ggml-org/llama.cpp/releases/tag/b6905
- b6906 (b6906) – 2025-10-31 – https://github.com/ggml-org/llama.cpp/releases/tag/b6906
- b6907 (b6907) – 2025-10-31 – https://github.com/ggml-org/llama.cpp/releases/tag/b6907
- b6908 (b6908) – 2025-11-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b6908
- b6909 (b6909) – 2025-11-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b6909
- b6910 (b6910) – 2025-11-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b6910
- b6912 (b6912) – 2025-11-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b6912
- b6915 (b6915) – 2025-11-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b6915
- b6916 (b6916) – 2025-11-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b6916
2025-10-31: Update to llama.cpp b6900
- b6793 (b6793) – 2025-10-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b6793
- b6794 (b6794) – 2025-10-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b6794
- b6795 (b6795) – 2025-10-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b6795
- b6799 (b6799) – 2025-10-19 – https://github.com/ggml-org/llama.cpp/releases/tag/b6799
- b6800 (b6800) – 2025-10-19 – https://github.com/ggml-org/llama.cpp/releases/tag/b6800
- b6801 (b6801) – 2025-10-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b6801
- b6802 (b6802) – 2025-10-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b6802
- b6804 (b6804) – 2025-10-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b6804
- b6808 (b6808) – 2025-10-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b6808
- b6810 (b6810) – 2025-10-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b6810
- b6811 (b6811) – 2025-10-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b6811
- b6812 (b6812) – 2025-10-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b6812
- b6813 (b6813) – 2025-10-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b6813
- b6814 (b6814) – 2025-10-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b6814
- b6815 (b6815) – 2025-10-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b6815
- b6816 (b6816) – 2025-10-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b6816
- b6817 (b6817) – 2025-10-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b6817
- b6818 (b6818) – 2025-10-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b6818
- b6821 (b6821) – 2025-10-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b6821
- b6822 (b6822) – 2025-10-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b6822
- b6823 (b6823) – 2025-10-23 – https://github.com/ggml-org/llama.cpp/releases/tag/b6823
- b6824 (b6824) – 2025-10-23 – https://github.com/ggml-org/llama.cpp/releases/tag/b6824
- b6825 (b6825) – 2025-10-23 – https://github.com/ggml-org/llama.cpp/releases/tag/b6825
- b6826 (b6826) – 2025-10-23 – https://github.com/ggml-org/llama.cpp/releases/tag/b6826
- b6827 (b6827) – 2025-10-23 – https://github.com/ggml-org/llama.cpp/releases/tag/b6827
- b6829 (b6829) – 2025-10-23 – https://github.com/ggml-org/llama.cpp/releases/tag/b6829
- b6833 (b6833) – 2025-10-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b6833
- b6834 (b6834) – 2025-10-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b6834
- b6836 (b6836) – 2025-10-25 – https://github.com/ggml-org/llama.cpp/releases/tag/b6836
- b6837 (b6837) – 2025-10-25 – https://github.com/ggml-org/llama.cpp/releases/tag/b6837
- b6838 (b6838) – 2025-10-25 – https://github.com/ggml-org/llama.cpp/releases/tag/b6838
- b6840 (b6840) – 2025-10-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b6840
- b6841 (b6841) – 2025-10-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b6841
- b6843 (b6843) – 2025-10-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b6843
- b6844 (b6844) – 2025-10-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b6844
- b6845 (b6845) – 2025-10-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b6845
- b6846 (b6846) – 2025-10-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b6846
- b6847 (b6847) – 2025-10-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b6847
- b6848 (b6848) – 2025-10-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b6848
- b6849 (b6849) – 2025-10-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b6849
- b6850 (b6850) – 2025-10-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b6850
- b6851 (b6851) – 2025-10-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b6851
- b6852 (b6852) – 2025-10-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b6852
- b6853 (b6853) – 2025-10-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b6853
- b6854 (b6854) – 2025-10-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b6854
- b6855 (b6855) – 2025-10-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b6855
- b6856 (b6856) – 2025-10-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b6856
- b6857 (b6857) – 2025-10-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b6857
- b6858 (b6858) – 2025-10-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b6858
- b6859 (b6859) – 2025-10-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b6859
- b6860 (b6860) – 2025-10-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b6860
- b6861 (b6861) – 2025-10-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b6861
- b6862 (b6862) – 2025-10-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b6862
- b6863 (b6863) – 2025-10-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b6863
- b6864 (b6864) – 2025-10-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b6864
- b6865 (b6865) – 2025-10-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b6865
- b6866 (b6866) – 2025-10-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b6866
- b6868 (b6868) – 2025-10-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b6868
- b6869 (b6869) – 2025-10-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b6869
- b6870 (b6870) – 2025-10-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b6870
- b6871 (b6871) – 2025-10-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b6871
- b6872 (b6872) – 2025-10-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b6872
- b6873 (b6873) – 2025-10-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b6873
- b6874 (b6874) – 2025-10-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b6874
- b6875 (b6875) – 2025-10-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b6875
- b6876 (b6876) – 2025-10-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b6876
- b6877 (b6877) – 2025-10-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b6877
- b6878 (b6878) – 2025-10-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b6878
- b6879 (b6879) – 2025-10-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b6879
- b6880 (b6880) – 2025-10-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b6880
- b6881 (b6881) – 2025-10-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6881
- b6882 (b6882) – 2025-10-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6882
- b6883 (b6883) – 2025-10-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6883
- b6884 (b6884) – 2025-10-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6884
- b6885 (b6885) – 2025-10-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6885
- b6886 (b6886) – 2025-10-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6886
- b6887 (b6887) – 2025-10-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6887
- b6888 (b6888) – 2025-10-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6888
- b6889 (b6889) – 2025-10-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6889
- b6890 (b6890) – 2025-10-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6890
- b6891 (b6891) – 2025-10-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6891
- b6895 (b6895) – 2025-10-31 – https://github.com/ggml-org/llama.cpp/releases/tag/b6895
- b6896 (b6896) – 2025-10-31 – https://github.com/ggml-org/llama.cpp/releases/tag/b6896
- b6897 (b6897) – 2025-10-31 – https://github.com/ggml-org/llama.cpp/releases/tag/b6897
- b6898 (b6898) – 2025-10-31 – https://github.com/ggml-org/llama.cpp/releases/tag/b6898
- b6900 (b6900) – 2025-10-31 – https://github.com/ggml-org/llama.cpp/releases/tag/b6900
2025-10-18: Update to llama.cpp b6792
- b6670 (b6670) – 2025-10-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b6670
- b6671 (b6671) – 2025-10-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b6671
- b6672 (b6672) – 2025-10-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b6672
- b6673 (b6673) – 2025-10-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b6673
- b6676 (b6676) – 2025-10-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b6676
- b6678 (b6678) – 2025-10-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b6678
- b6679 (b6679) – 2025-10-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b6679
- b6680 (b6680) – 2025-10-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b6680
- b6682 (b6682) – 2025-10-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b6682
- b6683 (b6683) – 2025-10-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b6683
- b6684 (b6684) – 2025-10-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b6684
- b6685 (b6685) – 2025-10-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b6685
- b6686 (b6686) – 2025-10-03 – https://github.com/ggml-org/llama.cpp/releases/tag/b6686
- b6687 (b6687) – 2025-10-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b6687
- b6688 (b6688) – 2025-10-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b6688
- b6689 (b6689) – 2025-10-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b6689
- b6690 (b6690) – 2025-10-04 – https://github.com/ggml-org/llama.cpp/releases/tag/b6690
- b6691 (b6691) – 2025-10-05 – https://github.com/ggml-org/llama.cpp/releases/tag/b6691
- b6692 (b6692) – 2025-10-05 – https://github.com/ggml-org/llama.cpp/releases/tag/b6692
- b6695 (b6695) – 2025-10-06 – https://github.com/ggml-org/llama.cpp/releases/tag/b6695
- b6697 (b6697) – 2025-10-06 – https://github.com/ggml-org/llama.cpp/releases/tag/b6697
- b6699 (b6699) – 2025-10-06 – https://github.com/ggml-org/llama.cpp/releases/tag/b6699
- b6700 (b6700) – 2025-10-06 – https://github.com/ggml-org/llama.cpp/releases/tag/b6700
- b6701 (b6701) – 2025-10-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b6701
- b6702 (b6702) – 2025-10-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b6702
- b6703 (b6703) – 2025-10-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b6703
- b6704 (b6704) – 2025-10-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b6704
- b6706 (b6706) – 2025-10-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b6706
- b6708 (b6708) – 2025-10-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b6708
- b6709 (b6709) – 2025-10-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b6709
- b6710 (b6710) – 2025-10-07 – https://github.com/ggml-org/llama.cpp/releases/tag/b6710
- b6711 (b6711) – 2025-10-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b6711
- b6713 (b6713) – 2025-10-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b6713
- b6714 (b6714) – 2025-10-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b6714
- b6715 (b6715) – 2025-10-08 – https://github.com/ggml-org/llama.cpp/releases/tag/b6715
- b6717 (b6717) – 2025-10-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b6717
- b6718 (b6718) – 2025-10-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b6718
- b6719 (b6719) – 2025-10-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b6719
- b6721 (b6721) – 2025-10-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b6721
- b6724 (b6724) – 2025-10-09 – https://github.com/ggml-org/llama.cpp/releases/tag/b6724
- b6726 (b6726) – 2025-10-10 – https://github.com/ggml-org/llama.cpp/releases/tag/b6726
- b6727 (b6727) – 2025-10-10 – https://github.com/ggml-org/llama.cpp/releases/tag/b6727
- b6728 (b6728) – 2025-10-10 – https://github.com/ggml-org/llama.cpp/releases/tag/b6728
- b6729 (b6729) – 2025-10-10 – https://github.com/ggml-org/llama.cpp/releases/tag/b6729
- b6730 (b6730) – 2025-10-10 – https://github.com/ggml-org/llama.cpp/releases/tag/b6730
- b6732 (b6732) – 2025-10-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b6732
- b6733 (b6733) – 2025-10-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b6733
- b6735 (b6735) – 2025-10-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b6735
- b6736 (b6736) – 2025-10-11 – https://github.com/ggml-org/llama.cpp/releases/tag/b6736
- b6737 (b6737) – 2025-10-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b6737
- b6738 (b6738) – 2025-10-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b6738
- b6739 (b6739) – 2025-10-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b6739
- b6741 (b6741) – 2025-10-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b6741
- b6743 (b6743) – 2025-10-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b6743
- b6745 (b6745) – 2025-10-12 – https://github.com/ggml-org/llama.cpp/releases/tag/b6745
- b6746 (b6746) – 2025-10-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b6746
- b6747 (b6747) – 2025-10-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b6747
- b6748 (b6748) – 2025-10-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b6748
- b6750 (b6750) – 2025-10-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b6750
- b6751 (b6751) – 2025-10-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b6751
- b6752 (b6752) – 2025-10-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b6752
- b6753 (b6753) – 2025-10-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b6753
- b6754 (b6754) – 2025-10-13 – https://github.com/ggml-org/llama.cpp/releases/tag/b6754
- b6756 (b6756) – 2025-10-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b6756
- b6757 (b6757) – 2025-10-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b6757
- b6758 (b6758) – 2025-10-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b6758
- b6759 (b6759) – 2025-10-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b6759
- b6760 (b6760) – 2025-10-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b6760
- b6761 (b6761) – 2025-10-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b6761
- b6762 (b6762) – 2025-10-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b6762
- b6763 (b6763) – 2025-10-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b6763
- b6764 (b6764) – 2025-10-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b6764
- b6765 (b6765) – 2025-10-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b6765
- b6766 (b6766) – 2025-10-15 – https://github.com/ggml-org/llama.cpp/releases/tag/b6766
- b6767 (b6767) – 2025-10-15 – https://github.com/ggml-org/llama.cpp/releases/tag/b6767
- b6768 (b6768) – 2025-10-15 – https://github.com/ggml-org/llama.cpp/releases/tag/b6768
- b6769 (b6769) – 2025-10-15 – https://github.com/ggml-org/llama.cpp/releases/tag/b6769
- b6770 (b6770) – 2025-10-15 – https://github.com/ggml-org/llama.cpp/releases/tag/b6770
- b6773 (b6773) – 2025-10-15 – https://github.com/ggml-org/llama.cpp/releases/tag/b6773
- b6774 (b6774) – 2025-10-15 – https://github.com/ggml-org/llama.cpp/releases/tag/b6774
- b6776 (b6776) – 2025-10-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b6776
- b6777 (b6777) – 2025-10-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b6777
- b6778 (b6778) – 2025-10-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b6778
- b6779 (b6779) – 2025-10-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b6779
- b6780 (b6780) – 2025-10-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b6780
- b6782 (b6782) – 2025-10-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b6782
- b6783 (b6783) – 2025-10-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b6783
- b6784 (b6784) – 2025-10-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b6784
- b6785 (b6785) – 2025-10-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b6785
- b6786 (b6786) – 2025-10-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b6786
- b6788 (b6788) – 2025-10-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b6788
- b6789 (b6789) – 2025-10-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b6789
- b6790 (b6790) – 2025-10-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b6790
- b6791 (b6791) – 2025-10-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b6791
- b6792 (b6792) – 2025-10-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b6792
2025-10-02: Update to llama.cpp b6666
- b6499 (b6499) – 2025-09-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b6499
- b6500 (b6500) – 2025-09-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b6500
- b6501 (b6501) – 2025-09-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b6501
- b6502 (b6502) – 2025-09-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b6502
- b6503 (b6503) – 2025-09-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b6503
- b6504 (b6504) – 2025-09-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b6504
- b6505 (b6505) – 2025-09-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b6505
- b6506 (b6506) – 2025-09-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b6506
- b6507 (b6507) – 2025-09-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b6507
- b6508 (b6508) – 2025-09-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b6508
- b6509 (b6509) – 2025-09-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b6509
- b6510 (b6510) – 2025-09-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b6510
- b6511 (b6511) – 2025-09-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b6511
- b6512 (b6512) – 2025-09-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b6512
- b6513 (b6513) – 2025-09-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b6513
- b6514 (b6514) – 2025-09-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b6514
- b6515 (b6515) – 2025-09-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b6515
- b6516 (b6516) – 2025-09-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b6516
- b6517 (b6517) – 2025-09-18 – https://github.com/ggml-org/llama.cpp/releases/tag/b6517
- b6518 (b6518) – 2025-09-19 – https://github.com/ggml-org/llama.cpp/releases/tag/b6518
- b6519 (b6519) – 2025-09-19 – https://github.com/ggml-org/llama.cpp/releases/tag/b6519
- b6521 (b6521) – 2025-09-19 – https://github.com/ggml-org/llama.cpp/releases/tag/b6521
- b6522 (b6522) – 2025-09-19 – https://github.com/ggml-org/llama.cpp/releases/tag/b6522
- b6523 (b6523) – 2025-09-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b6523
- b6524 (b6524) – 2025-09-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b6524
- b6527 (b6527) – 2025-09-20 – https://github.com/ggml-org/llama.cpp/releases/tag/b6527
- b6528 (b6528) – 2025-09-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b6528
- b6529 (b6529) – 2025-09-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b6529
- b6532 (b6532) – 2025-09-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b6532
- b6533 (b6533) – 2025-09-21 – https://github.com/ggml-org/llama.cpp/releases/tag/b6533
- b6534 (b6534) – 2025-09-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b6534
- b6535 (b6535) – 2025-09-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b6535
- b6536 (b6536) – 2025-09-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b6536
- b6541 (b6541) – 2025-09-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b6541
- b6543 (b6543) – 2025-09-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b6543
- b6544 (b6544) – 2025-09-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b6544
- b6545 (b6545) – 2025-09-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b6545
- b6548 (b6548) – 2025-09-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b6548
- b6549 (b6549) – 2025-09-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b6549
- b6550 (b6550) – 2025-09-22 – https://github.com/ggml-org/llama.cpp/releases/tag/b6550
- b6556 (b6556) – 2025-09-23 – https://github.com/ggml-org/llama.cpp/releases/tag/b6556
- b6557 (b6557) – 2025-09-23 – https://github.com/ggml-org/llama.cpp/releases/tag/b6557
- b6558 (b6558) – 2025-09-23 – https://github.com/ggml-org/llama.cpp/releases/tag/b6558
- b6565 (b6565) – 2025-09-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b6565
- b6567 (b6567) – 2025-09-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b6567
- b6568 (b6568) – 2025-09-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b6568
- b6569 (b6569) – 2025-09-24 – https://github.com/ggml-org/llama.cpp/releases/tag/b6569
- b6572 (b6572) – 2025-09-25 – https://github.com/ggml-org/llama.cpp/releases/tag/b6572
- b6574 (b6574) – 2025-09-25 – https://github.com/ggml-org/llama.cpp/releases/tag/b6574
- b6575 (b6575) – 2025-09-25 – https://github.com/ggml-org/llama.cpp/releases/tag/b6575
- b6576 (b6576) – 2025-09-25 – https://github.com/ggml-org/llama.cpp/releases/tag/b6576
- b6578 (b6578) – 2025-09-25 – https://github.com/ggml-org/llama.cpp/releases/tag/b6578
- b6580 (b6580) – 2025-09-25 – https://github.com/ggml-org/llama.cpp/releases/tag/b6580
- b6582 (b6582) – 2025-09-25 – https://github.com/ggml-org/llama.cpp/releases/tag/b6582
- b6583 (b6583) – 2025-09-25 – https://github.com/ggml-org/llama.cpp/releases/tag/b6583
- b6585 (b6585) – 2025-09-25 – https://github.com/ggml-org/llama.cpp/releases/tag/b6585
- b6586 (b6586) – 2025-09-25 – https://github.com/ggml-org/llama.cpp/releases/tag/b6586
- b6587 (b6587) – 2025-09-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b6587
- b6591 (b6591) – 2025-09-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b6591
- b6593 (b6593) – 2025-09-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b6593
- b6594 (b6594) – 2025-09-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b6594
- b6595 (b6595) – 2025-09-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b6595
- b6598 (b6598) – 2025-09-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b6598
- b6601 (b6601) – 2025-09-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b6601
- b6602 (b6602) – 2025-09-26 – https://github.com/ggml-org/llama.cpp/releases/tag/b6602
- b6603 (b6603) – 2025-09-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b6603
- b6604 (b6604) – 2025-09-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b6604
- b6605 (b6605) – 2025-09-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b6605
- b6606 (b6606) – 2025-09-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b6606
- b6607 (b6607) – 2025-09-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b6607
- b6608 (b6608) – 2025-09-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b6608
- b6610 (b6610) – 2025-09-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b6610
- b6611 (b6611) – 2025-09-27 – https://github.com/ggml-org/llama.cpp/releases/tag/b6611
- b6612 (b6612) – 2025-09-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b6612
- b6613 (b6613) – 2025-09-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b6613
- b6615 (b6615) – 2025-09-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b6615
- b6619 (b6619) – 2025-09-28 – https://github.com/ggml-org/llama.cpp/releases/tag/b6619
- b6621 (b6621) – 2025-09-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b6621
- b6622 (b6622) – 2025-09-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b6622
- b6623 (b6623) – 2025-09-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b6623
- b6624 (b6624) – 2025-09-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b6624
- b6627 (b6627) – 2025-09-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b6627
- b6628 (b6628) – 2025-09-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b6628
- b6634 (b6634) – 2025-09-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b6634
- b6635 (b6635) – 2025-09-29 – https://github.com/ggml-org/llama.cpp/releases/tag/b6635
- b6638 (b6638) – 2025-09-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6638
- b6640 (b6640) – 2025-09-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6640
- b6641 (b6641) – 2025-09-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6641
- b6642 (b6642) – 2025-09-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6642
- b6643 (b6643) – 2025-09-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6643
- b6644 (b6644) – 2025-09-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6644
- b6646 (b6646) – 2025-09-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6646
- b6647 (b6647) – 2025-09-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6647
- b6648 (b6648) – 2025-09-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6648
- b6650 (b6650) – 2025-09-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6650
- b6651 (b6651) – 2025-09-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6651
- b6653 (b6653) – 2025-09-30 – https://github.com/ggml-org/llama.cpp/releases/tag/b6653
- b6660 (b6660) – 2025-10-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b6660
- b6661 (b6661) – 2025-10-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b6661
- b6662 (b6662) – 2025-10-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b6662
- b6663 (b6663) – 2025-10-01 – https://github.com/ggml-org/llama.cpp/releases/tag/b6663
- b6666 (b6666) – 2025-10-02 – https://github.com/ggml-org/llama.cpp/releases/tag/b6666
This file lists notable changes synchronized from upstream llama.cpp releases. Each entry corresponds to the vendor submodule update in this package.
2025-09-17: Update to llama.cpp b6497
- b6469 (b6469) – 2025-09-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b6469
- b6470 (b6470) – 2025-09-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b6470
- b6471 (b6471) – 2025-09-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b6471
- b6473 (b6473) – 2025-09-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b6473
- b6474 (b6474) – 2025-09-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b6474
- b6475 (b6475) – 2025-09-14 – https://github.com/ggml-org/llama.cpp/releases/tag/b6475
- b6476 (b6476) – 2025-09-15 – https://github.com/ggml-org/llama.cpp/releases/tag/b6476
- b6477 (b6477) – 2025-09-15 – https://github.com/ggml-org/llama.cpp/releases/tag/b6477
- b6478 (b6478) – 2025-09-15 – https://github.com/ggml-org/llama.cpp/releases/tag/b6478
- b6479 (b6479) – 2025-09-15 – https://github.com/ggml-org/llama.cpp/releases/tag/b6479
- b6480 (b6480) – 2025-09-15 – https://github.com/ggml-org/llama.cpp/releases/tag/b6480
- b6482 (b6482) – 2025-09-15 – https://github.com/ggml-org/llama.cpp/releases/tag/b6482
- b6483 (b6483) – 2025-09-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b6483
- b6484 (b6484) – 2025-09-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b6484
- b6488 (b6488) – 2025-09-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b6488
- b6490 (b6490) – 2025-09-16 – https://github.com/ggml-org/llama.cpp/releases/tag/b6490
- b6491 (b6491) – 2025-09-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b6491
- b6492 (b6492) – 2025-09-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b6492
- b6493 (b6493) – 2025-09-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b6493
- b6494 (b6494) – 2025-09-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b6494
- b6496 (b6496) – 2025-09-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b6496
- b6497 (b6497) – 2025-09-17 – https://github.com/ggml-org/llama.cpp/releases/tag/b6497
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file llama_cpp_pydist-0.85.0.tar.gz.
File metadata
- Download URL: llama_cpp_pydist-0.85.0.tar.gz
- Upload date:
- Size: 31.8 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2f05c7d08a3ed75901fbafe6a3dc4fff837fe2e97ca89dc40ad5cd49e82a2de9
|
|
| MD5 |
9e7ac75f35de0f8eaccf2bbe6963e6a2
|
|
| BLAKE2b-256 |
aa9fa391192742fc949378649418846a8f69d0d9034fadc98ba7b5220b770d67
|
File details
Details for the file llama_cpp_pydist-0.85.0-py3-none-any.whl.
File metadata
- Download URL: llama_cpp_pydist-0.85.0-py3-none-any.whl
- Upload date:
- Size: 33.1 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.3
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
644b95a61f0dce6ebc63715e2de61c60811dc36dd33b7016743cc4f15f01a421
|
|
| MD5 |
df79e7392f4449233f11ecd35b9fbea9
|
|
| BLAKE2b-256 |
a20bea793ee219249dbdee5099dff78c7d12bc874b4a979da7f9807072065905
|







