LLMAuditor is an execution-based evaluation and monitoring framework for LLM, GenAI, and agentic AI applications, providing hallucination detection, cost tracking, and governance auditing.

Project description
LLMAuditor



Execution-Based GenAI Application Evaluation & Certification Framework.
LLMAuditor wraps around any LLM integration to provide per-execution auditing, hallucination detection, cost governance, certification scoring, and enterprise-grade report export — without locking you into any specific AI provider.
🏆 Proven in Production: Now deployed in real applications including multi-agent research systems, daily news apps, RAG pipelines, chatbot monitors, and terminal assistants
🚀 New Production Examples Available where LLMAuditor applied check link below & also report attached
- Multi-Agent Research Systems
- AI News App Production
- RAG Pipeline Auditing
- Chatbot Monitoring
- GenAI-Assistant-with-LLMAuditor-Integration
LLMAuditor Purpose
LLMAuditor is an execution-based evaluation framework for Generative AI applications.
Instead of static code review, LLMAuditor monitors real LLM executions and generates enterprise-grade evaluation reports including:
• Token usage and cost tracking
• Risk and confidence scoring
• Hallucination detection signals
• Governance controls (budget / guard / alert modes)
• Certification-style audit reports
The goal is to help organizations validate, evaluate, and certify GenAI applications before production deployment.
LLMAuditor Example Use Cases
• Enterprise GenAI audit and certification
• Monitoring RAG pipelines
• LLM governance compliance
• Production risk evaluation
• Cost and token monitoring for AI applications
🚀 Production-Ready Applications Using LLMAuditor
LLMAuditor isn't just a framework - it's proven in real production applications. We've built and deployed multiple GenAI applications that demonstrate LLMAuditor's capabilities in live environments:
📊 Real Applications Portfolio
| Application | Description | Certification Result | Repository |
|---|---|---|---|
| 🤖 Multi-Agent Research System | 3-agent coordination for market research with intentional error testing | Bronze (44.5%) → Platinum (93.1%) | View Project |
| 📰 AI-Powered Daily News App | News aggregation, AI summarization, and personalized briefings | Platinum Certification (92.3%) | View Project |
| 🔍 RAG Pipeline Auditor | HR knowledge base with document retrieval and quality monitoring | Platinum Certification (91.0%) | View Project |
| 💬 Chatbot Monitor | Interactive chatbot with governance controls and safety testing | Silver Certification (71.2%) | View Project |
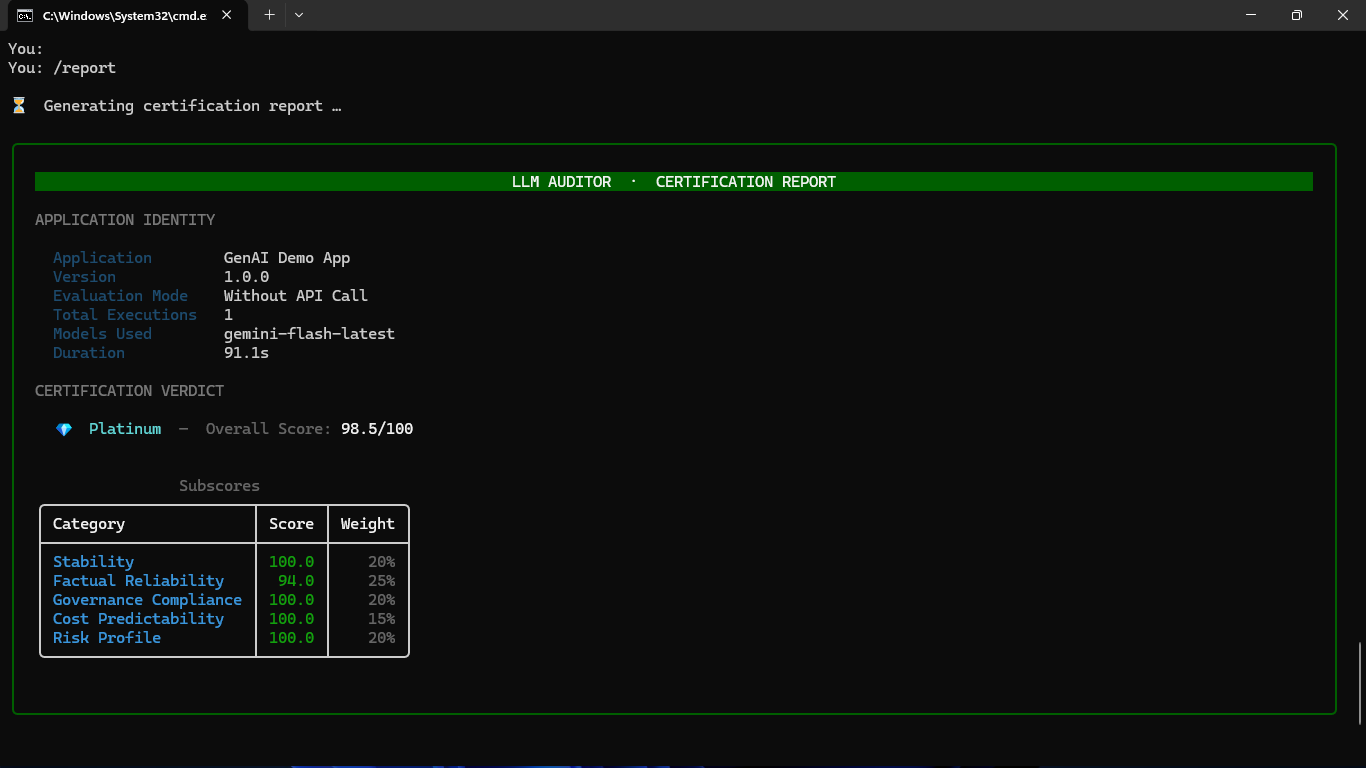
| 🤖 GenAI-Assistant-with-LLMAuditor-Integration | Simple conversational AI with FREE Google Gemini and real-time audit tracking | Platinum Certification (98.5%) | View Project |
🏆 Proven Capabilities - Real Certification Report
Our Multi-Agent Research System demonstrates LLMAuditor's enterprise-grade certification capabilities:
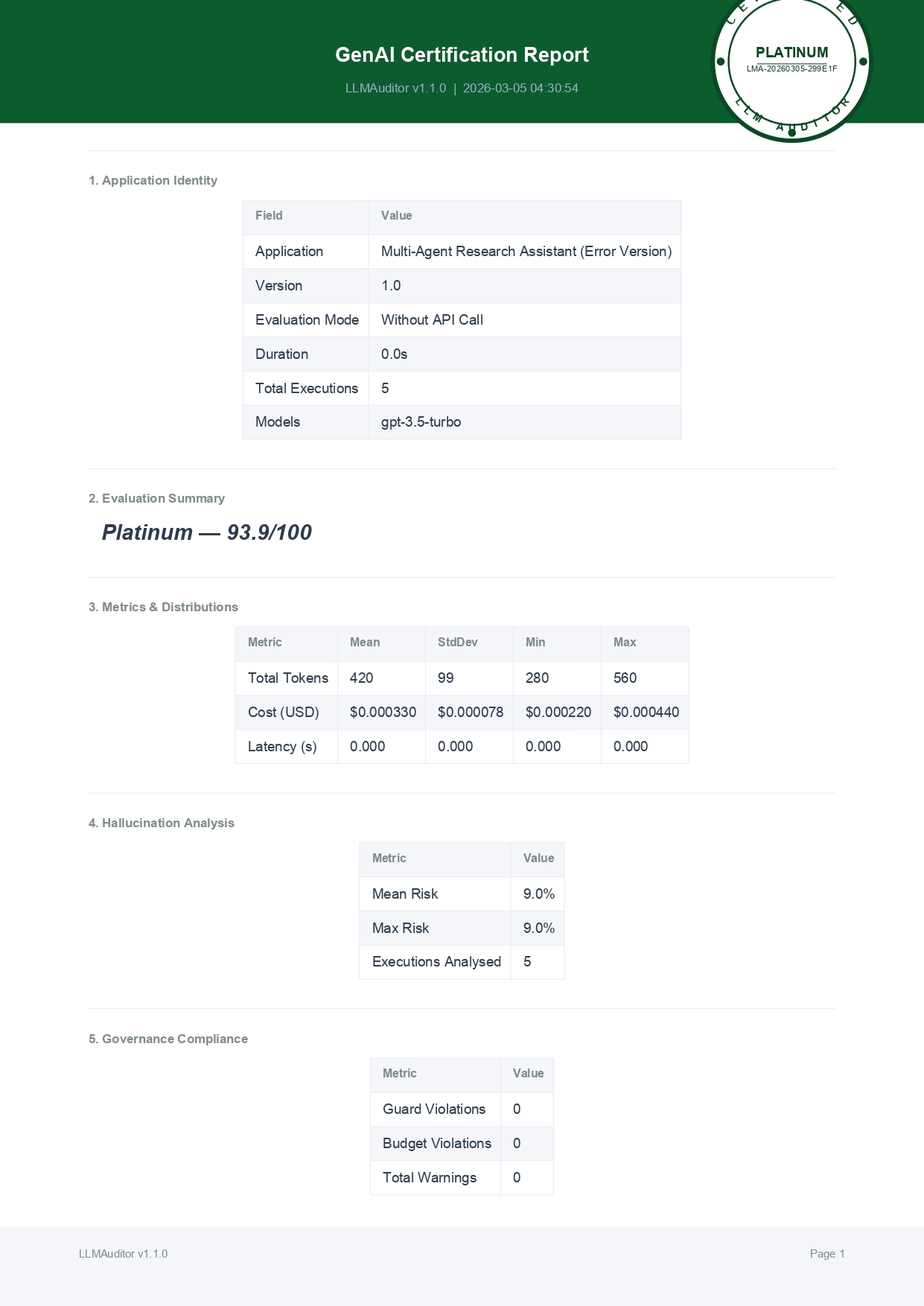
Certification report header with official stamp and executive summary

Digital signature page with certificate number and validation details
📈 Detection Performance Metrics
| Capability | Test Results | Success Rate |
|---|---|---|
| Hallucination Detection | 5/5 fake statistics caught | 100% |
| Source Verification | Fabricated sources flagged | 100% |
| Quality Differentiation | 49-point certification gap (44.5 → 93.1) | Excellent |
| Confidence Assessment | 79% improvement detection (52% → 93.1%) | Highly Accurate |
| Cost Monitoring | 62% efficiency difference detected | Precise |
| Multi-Agent Coordination | Real-time monitoring across 3 agents | Seamless |
💻 Ready-to-Deploy Examples
All applications are production-ready with:
- ✅ Real OpenAI API integration (not mocked)
- ✅ Authentic cost tracking (actual token usage)
- ✅ Live quality assessment (confidence scores)
- ✅ Generated certifications (PDF with license numbers)
- ✅ Interactive web interfaces (Streamlit dashboards)
- ✅ Comprehensive testing (unit tests and validation)
🔗 Explore the code: Each repository includes complete source code, setup instructions, and live demonstrations.
LLMAuditor Features
| Category | Capabilities |
|---|---|
| Execution Auditing | Per-call tracking of tokens, cost, latency, confidence, and risk level |
| Hallucination Detection | Hybrid engine — rule-based heuristics + optional AI judge |
| Certification Scoring | 5 subscores → weighted overall score → Platinum / Gold / Silver / Conditional / Fail |
| Governance | Budget enforcement, guard mode, alert mode, role-based access |
| Report Export | Markdown, HTML, and PDF with circular certification stamp, digital signature, and certificate number |
| Evaluation Sessions | Batch multiple executions into a scored, exportable certification report |
| Rich CLI Output | Color-coded panels with live token, cost, and risk display |
| Model-Agnostic | Works with OpenAI, Anthropic, Google, AWS Bedrock, or any custom wrapper |
LLMAuditor Installation
Install from PyPI:
pip install llmauditor
Then add a quick usage example:
from llmauditor import auditor
report = auditor.execute(
model="gpt-4o-mini",
input_tokens=120,
output_tokens=60,
raw_response="Market conditions remain stable.",
input_text="Give stock market outlook"
)
report.display()
Dependencies: rich>=13.0.0 (CLI display), reportlab>=4.0.0 (PDF export)
LLMAuditor Quick Start
1. Single Execution Audit
from llmauditor import auditor
report = auditor.execute(
model="gpt-4o",
input_tokens=520,
output_tokens=290,
raw_response="Merchant risk is assessed as LOW.",
input_text="Analyze merchant risk for account #4417",
)
report.display()
This produces a rich CLI panel showing execution ID, model, latency, token counts, estimated cost, confidence score, risk level, hallucination analysis, and improvement suggestions.
2. Monitor Decorator
from llmauditor import auditor
@auditor.monitor(model="gpt-4o")
def call_openai(prompt: str) -> dict:
# Your actual API call here
return {
"response": "Market outlook: bullish on tech sector.",
"input_tokens": 400,
"output_tokens": 150,
}
result = call_openai("Summarize today's market")
# Automatically tracked, displayed, and recorded in history
3. Passive Observation
report = auditor.observe(
model="claude-3.5-sonnet",
input_tokens=300,
output_tokens=120,
raw_response="The quarterly results show 12% growth.",
)
# Records without governance enforcement — useful for logging
4. Evaluation Session with Certification
from llmauditor import auditor
auditor.start_evaluation("My GenAI App", version="2.1.0")
# Run multiple executions...
auditor.execute(model="gpt-4o", input_tokens=500, output_tokens=200,
raw_response="Response 1...", input_text="Prompt 1")
auditor.execute(model="gpt-4o", input_tokens=600, output_tokens=250,
raw_response="Response 2...", input_text="Prompt 2")
auditor.end_evaluation()
# Generate certification report
eval_report = auditor.generate_evaluation_report()
eval_report.display()
eval_report.export("pdf", output_dir="./reports")
The exported PDF includes 11 sections with a circular certification stamp at the top and a digital signature with unique certificate number (LMA-YYYYMMDD-XXXXXX) at the bottom.
LLMAuditor Core API Reference
auditor.execute()
Record and audit a single LLM execution with full governance enforcement.
report = auditor.execute(
model="gpt-4o", # Model name (used for cost lookup)
input_tokens=500, # Tokens consumed by the prompt
output_tokens=200, # Tokens in the completion
raw_response="...", # The model's output text
input_text="...", # Original prompt (optional, for hallucination analysis)
)
Returns an ExecutionReport with: report.display(), report.export("md"|"html"|"pdf"), report.to_dict()
auditor.observe()
Passive recording — no governance enforcement, no blocking.
report = auditor.observe(
model="gpt-4o",
input_tokens=500,
output_tokens=200,
raw_response="...",
)
@auditor.monitor(model=)
Decorator that automatically audits any function returning {"response": str, "input_tokens": int, "output_tokens": int}.
@auditor.monitor(model="gpt-4o")
def my_function(prompt):
return {"response": "...", "input_tokens": 100, "output_tokens": 50}
LLMAuditor Governance
Budget Enforcement
auditor.set_budget(max_cost_usd=5.00)
# Check remaining budget
status = auditor.get_budget_status()
# → {"budget_limit": 5.0, "spent": 1.23, "remaining": 3.77, "utilization_pct": 24.6}
# Exceeding budget raises BudgetExceededError
Guard Mode
Blocks executions with confidence below the threshold.
auditor.guard_mode(confidence_threshold=70)
# Executions scoring below 70 confidence raise LowConfidenceError
Alert Mode
Prints real-time warnings for high-risk executions without blocking.
auditor.set_alert_mode(enabled=True)
Exception Handling
from llmauditor import auditor, BudgetExceededError, LowConfidenceError
try:
report = auditor.execute(model="gpt-4o", input_tokens=500,
output_tokens=200, raw_response="...")
except BudgetExceededError as e:
print(f"Budget exceeded: {e}")
except LowConfidenceError as e:
print(f"Blocked by guard mode: {e}")
LLMAuditor Hallucination Detection
LLMAuditor includes a hybrid hallucination detection engine:
- Rule-based heuristics — detects hedging language, self-contradiction, unsupported assertions, specificity without grounding, and temporal/numerical inconsistencies
- AI judge (optional) — configurable external LLM call for deeper analysis
Each execution report includes a HallucinationAnalysis with:
risk_level— None / Low / Medium / High / Criticalrisk_score— 0.0 to 1.0flags— list of detected patternsexplanation— human-readable summary
LLMAuditor Certification & Scoring
Evaluation sessions produce a CertificationScore with 5 subscores:
| Subscore | Measures |
|---|---|
| Stability | Latency/token variance, failure rate |
| Factual Reliability | Hallucination risk, confidence levels |
| Governance Compliance | Guard/budget/role violation rates |
| Cost Predictability | Cost variance, budget adherence |
| Risk Profile | Distribution of execution risk levels |
Certification Levels:
| Level | Score Range | Emoji |
|---|---|---|
| Platinum | ≥ 90 | 🏆 |
| Gold | ≥ 80 | 🥇 |
| Silver | ≥ 70 | 🥈 |
| Conditional Pass | ≥ 60 | ⚠️ |
| Fail | < 60 | ❌ |
Customizing Weights
auditor.set_certification_thresholds(weights={
"stability": 0.25,
"factual_reliability": 0.25,
"governance_compliance": 0.20,
"cost_predictability": 0.15,
"risk_profile": 0.15,
})
LLMAuditor Report Export
Per-Execution Reports
report = auditor.execute(model="gpt-4o", input_tokens=500,
output_tokens=200, raw_response="...")
report.export("md", output_dir="./reports") # Markdown
report.export("html", output_dir="./reports") # HTML
report.export("pdf", output_dir="./reports") # PDF
Evaluation Certification Reports
eval_report = auditor.generate_evaluation_report()
eval_report.export("pdf", output_dir="./reports")
Certification reports contain 11 sections:
- Certification Stamp — circular stamp with certification level
- Executive Summary — app name, version, execution count, overall score
- Certification Score — overall score with level and emoji
- Score Breakdown — 5 subscores with progress bars
- Execution Log — per-execution details table
- Token & Cost Analysis — aggregated token/cost statistics
- Hallucination Analysis — risk distribution and flagged patterns
- Governance Summary — budget utilization, guard/alert mode status
- Improvement Suggestions — actionable recommendations
- Methodology — scoring methodology and weight explanation
- Plain-Language Summary — business-readable certification narrative
Each report includes a digital signature with a unique certificate number (format: LMA-YYYYMMDD-XXXXXX).
LLMAuditor Supported Models & Pricing
| Provider | Model | Input (per 1K) | Output (per 1K) |
|---|---|---|---|
| OpenAI | gpt-4 | $0.0300 | $0.0600 |
| OpenAI | gpt-4-turbo | $0.0100 | $0.0300 |
| OpenAI | gpt-4o | $0.0050 | $0.0150 |
| OpenAI | gpt-4o-mini | $0.00015 | $0.0006 |
| OpenAI | gpt-3.5-turbo | $0.0005 | $0.0015 |
| Anthropic | claude-3-opus | $0.0150 | $0.0750 |
| Anthropic | claude-3-sonnet | $0.0030 | $0.0150 |
| Anthropic | claude-3-haiku | $0.00025 | $0.00125 |
| Anthropic | claude-3.5-sonnet | $0.0030 | $0.0150 |
| Anthropic | claude-3.5-haiku | $0.0008 | $0.0040 |
| gemini-pro | $0.00025 | $0.0005 | |
| gemini-1.5-flash | $0.000075 | $0.0003 | |
| gemini-1.5-pro | $0.00125 | $0.0050 | |
| gemini-2.0-flash | $0.00015 | $0.0006 | |
| gemini-2.0-flash-lite | $0.000075 | $0.0003 | |
| gemini-2.5-flash | $0.00015 | $0.0006 | |
| gemini-2.5-pro | $0.00125 | $0.0100 | |
| AWS | amazon.titan-text-express | $0.0002 | $0.0006 |
| AWS | amazon.titan-text-lite | $0.00015 | $0.0002 |
Custom Pricing
auditor.set_pricing_table({
"my-custom-model": {"input": 0.002, "output": 0.008},
})
Unlisted models default to $0.00 (never crash on unknown models).
LLMAuditor Project Structure
llm-control-engine/
├── llmauditor/
│ ├── __init__.py # Public API — singleton, exports, version
│ ├── auditor.py # LLMAuditor class — orchestration
│ ├── tracker.py # ExecutionTracker — time & token aggregation
│ ├── cost.py # Pricing registry + calculate_cost()
│ ├── report.py # ExecutionReport + rich CLI display
│ ├── exporter.py # Audit & certification export (MD/HTML/PDF)
│ ├── hallucination.py # Hybrid hallucination detection engine
│ ├── scoring.py # Certification scoring (5 subscores)
│ ├── evaluation.py # Evaluation sessions & metrics
│ └── suggestions.py # Improvement recommendations
├── validate_llmauditor.py # Validation script (49 checks)
├── pyproject.toml
├── LICENSE
└── README.md
LLMAuditor Design Principles
- Model-agnostic — works with any LLM provider or custom wrapper
- Metric-driven — all scoring and certification derived from actual execution data
- Separation of concerns — 10 focused modules, each with a single responsibility
- Non-invasive — integrates via
execute(),observe(), or@monitordecorator - Enterprise-ready — budget enforcement, guard mode, role control, audit export
- Never crash — unknown models, missing data, and edge cases handled gracefully
LLMAuditor — Complete Usage Guide
Version: 1.1.3
License: Apache-2.0
Python: ≥ 3.9
Install:pip install llmauditor
This document is a syntax and usage reference for llmauditor.
Copy any example below and adapt it to your project.
Table of Contents
- Installation
- Quick Start (3 Lines)
- Core Concepts
- Three Ways to Audit
- OpenAI Integration
- LangChain / LangGraph Integration
- Anthropic Claude Integration
- Google Gemini Integration
- Groq Integration
- AWS Bedrock Integration
- Local Models (Ollama / llama.cpp / vLLM)
- Agentic AI / Multi-Agent Patterns
- Budget & Governance
- Evaluation Sessions & Certification
- Exporting Reports (MD / HTML / PDF)
- Custom Pricing Tables
- Hallucination Detection
- FastAPI Integration
- Flask Integration
- Django Integration
- Streamlit Integration
- Error Handling & Safety
- Full API Reference
- Built-in Model Pricing
- Certification Levels
- FAQ
1. Installation
pip install llmauditor
Dependencies (installed automatically):
rich— CLI display panelsreportlab— PDF generation
No LLM SDK is required. llmauditor wraps around any LLM call you already have.
2. Quick Start (3 Lines)
from llmauditor import auditor
# Record any LLM execution
report = auditor.execute(
model="gpt-4o",
input_tokens=150,
output_tokens=80,
raw_response="The capital of France is Paris."
)
report.display() # Rich CLI panel
That's it. You get: cost, tokens, confidence score, risk level, hallucination analysis, and an executive summary.
3. Core Concepts
| Concept | Description |
|---|---|
| Execution Audit | Analyze a single LLM call (cost, tokens, latency, confidence, hallucination risk) |
| Evaluation Session | Group multiple executions, aggregate metrics, get certification score |
| Certification | Score 0–100 → Platinum / Gold / Silver / Conditional Pass / Fail |
| Governance | Budget limits, guard mode (block low-confidence), alert mode (warn instead of block) |
| Export | Generate professional reports in Markdown, HTML, or PDF |
Key principle: llmauditor never calls any LLM itself. You call your LLM, then tell llmauditor what happened. It audits the execution, not the model.
4. Three Ways to Audit
4.1 execute() — Manual Recording
Use when you already have token counts and the response text.
from llmauditor import auditor
report = auditor.execute(
model="gpt-4o",
input_tokens=200,
output_tokens=100,
raw_response="Paris is the capital of France.",
execution_time=1.2, # optional, seconds
input_text="What is the capital of France?" # optional, for hallucination analysis
)
# Access report data
print(report.estimated_cost) # e.g. 0.0025
print(report.total_tokens) # 300
print(report.to_dict()) # Full dict serialization
# Display rich CLI panel
report.display()
# Export to file
report.export("md", output_dir="./reports")
report.export("html", output_dir="./reports")
report.export("pdf", output_dir="./reports")
4.2 observe() — Observe & Display
Same as execute() but takes explicit input/output text and auto-displays the CLI panel.
from llmauditor import auditor
report = auditor.observe(
model="claude-3.5-sonnet",
input_text="Explain quantum computing in simple terms.",
output_text="Quantum computing uses qubits that can be 0 and 1 simultaneously...",
input_tokens=50,
output_tokens=200,
execution_time=2.1
)
# CLI panel is automatically displayed
4.3 monitor() — Decorator (Automatic)
Wrap any function that calls an LLM. The decorator measures time, extracts tokens, runs auditing, and displays the report — all automatically.
Return a dict with response, input_tokens, output_tokens:
from llmauditor import auditor
@auditor.monitor(model="gpt-4o")
def call_openai(prompt):
# ... your LLM call here ...
return {
"response": "The answer is 42.",
"input_tokens": 50,
"output_tokens": 20
}
result = call_openai("What is the meaning of life?")
# Audit panel is automatically displayed
# result is the original return value (the dict)
Return a plain string (tokens default to 0):
@auditor.monitor(model="gpt-4o-mini")
def simple_call(prompt):
return "Hello, world!"
simple_call("Say hello")
# Still audited — tokens show as 0, cost as $0
5. OpenAI Integration
Using the OpenAI SDK
import openai
from llmauditor import auditor
client = openai.OpenAI()
def ask_openai(prompt: str) -> str:
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}]
)
choice = response.choices[0].message.content
usage = response.usage
# Audit the execution
report = auditor.execute(
model="gpt-4o",
input_tokens=usage.prompt_tokens,
output_tokens=usage.completion_tokens,
raw_response=choice,
input_text=prompt
)
report.display()
return choice
answer = ask_openai("What are the benefits of TypeScript?")
Using the Decorator with OpenAI
import openai
from llmauditor import auditor
client = openai.OpenAI()
@auditor.monitor(model="gpt-4o")
def ask_openai(prompt: str):
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}]
)
usage = response.usage
return {
"response": response.choices[0].message.content,
"input_tokens": usage.prompt_tokens,
"output_tokens": usage.completion_tokens,
}
result = ask_openai("Explain REST APIs")
# Automatic audit panel displayed
OpenAI Streaming
import openai
from llmauditor import auditor
client = openai.OpenAI()
def ask_openai_stream(prompt: str) -> str:
chunks = []
stream = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}],
stream=True,
stream_options={"include_usage": True}
)
input_tokens = 0
output_tokens = 0
for chunk in stream:
if chunk.choices and chunk.choices[0].delta.content:
chunks.append(chunk.choices[0].delta.content)
if chunk.usage:
input_tokens = chunk.usage.prompt_tokens
output_tokens = chunk.usage.completion_tokens
full_response = "".join(chunks)
# Audit after streaming completes
report = auditor.execute(
model="gpt-4o",
input_tokens=input_tokens,
output_tokens=output_tokens,
raw_response=full_response,
input_text=prompt
)
report.display()
return full_response
6. LangChain / LangGraph Integration
LangChain with Manual Audit
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
from llmauditor import auditor
llm = ChatOpenAI(model="gpt-4o", temperature=0)
def ask_langchain(question: str) -> str:
response = llm.invoke([HumanMessage(content=question)])
# Extract token usage from LangChain response metadata
usage = response.usage_metadata # LangChain v0.2+
# Or: usage = response.response_metadata.get("token_usage", {})
report = auditor.execute(
model="gpt-4o",
input_tokens=usage.get("input_tokens", 0),
output_tokens=usage.get("output_tokens", 0),
raw_response=response.content,
input_text=question
)
report.display()
return response.content
answer = ask_langchain("What is LangChain?")
LangChain with Groq via LangChain
from langchain_groq import ChatGroq
from langchain_core.messages import HumanMessage
from llmauditor import auditor
llm = ChatGroq(model="llama-3.3-70b-versatile", temperature=0)
def ask_groq_langchain(question: str) -> str:
response = llm.invoke([HumanMessage(content=question)])
usage = response.usage_metadata
report = auditor.execute(
model="llama-3.3-70b-versatile",
input_tokens=usage.get("input_tokens", 0),
output_tokens=usage.get("output_tokens", 0),
raw_response=response.content,
input_text=question
)
report.display()
return response.content
LangChain RAG Chain
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from llmauditor import auditor
llm = ChatOpenAI(model="gpt-4o")
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.load_local("my_index", embeddings)
retriever = vectorstore.as_retriever()
prompt = ChatPromptTemplate.from_template(
"Answer based on context:\n{context}\n\nQuestion: {question}"
)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
)
def ask_rag(question: str) -> str:
response = chain.invoke(question)
usage = response.usage_metadata or {}
report = auditor.execute(
model="gpt-4o",
input_tokens=usage.get("input_tokens", 0),
output_tokens=usage.get("output_tokens", 0),
raw_response=response.content,
input_text=question
)
report.display()
return response.content
LangGraph Multi-Agent with Budget Tracking
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, END
from llmauditor import auditor
auditor.set_budget(0.50) # $0.50 budget for the whole agent pipeline
auditor.set_alert_mode(True) # Warn instead of crash on budget exceed
llm = ChatOpenAI(model="gpt-4o")
def researcher_node(state):
response = llm.invoke(state["messages"])
usage = response.usage_metadata or {}
auditor.execute(
model="gpt-4o",
input_tokens=usage.get("input_tokens", 0),
output_tokens=usage.get("output_tokens", 0),
raw_response=response.content,
input_text=str(state["messages"][-1])
)
return {"messages": state["messages"] + [response]}
def writer_node(state):
response = llm.invoke(state["messages"])
usage = response.usage_metadata or {}
auditor.execute(
model="gpt-4o",
input_tokens=usage.get("input_tokens", 0),
output_tokens=usage.get("output_tokens", 0),
raw_response=response.content,
input_text=str(state["messages"][-1])
)
return {"messages": state["messages"] + [response]}
# Check budget status after pipeline
status = auditor.get_budget_status()
print(f"Spent: ${status['cumulative_cost']:.4f} / ${status['budget_limit']}")
print(f"Remaining: ${status['remaining']:.4f}")
7. Anthropic Claude Integration
Using the Anthropic SDK
import anthropic
from llmauditor import auditor
client = anthropic.Anthropic()
def ask_claude(prompt: str) -> str:
response = client.messages.create(
model="claude-3.5-sonnet-20241022",
max_tokens=1024,
messages=[{"role": "user", "content": prompt}]
)
report = auditor.execute(
model="claude-3.5-sonnet",
input_tokens=response.usage.input_tokens,
output_tokens=response.usage.output_tokens,
raw_response=response.content[0].text,
input_text=prompt
)
report.display()
return response.content[0].text
answer = ask_claude("Explain the theory of relativity")
Claude with Tool Use (Function Calling)
import anthropic
from llmauditor import auditor
client = anthropic.Anthropic()
tools = [
{
"name": "get_weather",
"description": "Get the current weather",
"input_schema": {
"type": "object",
"properties": {"location": {"type": "string"}},
"required": ["location"]
}
}
]
def ask_claude_tools(prompt: str) -> str:
response = client.messages.create(
model="claude-3.5-sonnet-20241022",
max_tokens=1024,
tools=tools,
messages=[{"role": "user", "content": prompt}]
)
# Audit the tool-calling execution
output_text = ""
for block in response.content:
if hasattr(block, "text"):
output_text += block.text
elif block.type == "tool_use":
output_text += f"[Tool Call: {block.name}({block.input})]"
report = auditor.execute(
model="claude-3.5-sonnet",
input_tokens=response.usage.input_tokens,
output_tokens=response.usage.output_tokens,
raw_response=output_text,
input_text=prompt
)
report.display()
return output_text
8. Google Gemini Integration
Using google-generativeai
import google.generativeai as genai
from llmauditor import auditor
genai.configure(api_key="YOUR_API_KEY")
model = genai.GenerativeModel("gemini-2.0-flash")
def ask_gemini(prompt: str) -> str:
response = model.generate_content(prompt)
# Gemini provides usage metadata
usage = response.usage_metadata
report = auditor.execute(
model="gemini-2.0-flash",
input_tokens=usage.prompt_token_count,
output_tokens=usage.candidates_token_count,
raw_response=response.text,
input_text=prompt
)
report.display()
return response.text
answer = ask_gemini("What are the planets in our solar system?")
Gemini with Vertex AI
import vertexai
from vertexai.generative_models import GenerativeModel
from llmauditor import auditor
vertexai.init(project="my-project", location="us-central1")
model = GenerativeModel("gemini-2.5-pro")
def ask_vertex(prompt: str) -> str:
response = model.generate_content(prompt)
usage = response.usage_metadata
report = auditor.execute(
model="gemini-2.5-pro",
input_tokens=usage.prompt_token_count,
output_tokens=usage.candidates_token_count,
raw_response=response.text,
input_text=prompt
)
report.display()
return response.text
9. Groq Integration
from groq import Groq
from llmauditor import auditor
client = Groq()
def ask_groq(prompt: str) -> str:
response = client.chat.completions.create(
model="llama-3.3-70b-versatile",
messages=[{"role": "user", "content": prompt}]
)
choice = response.choices[0].message.content
usage = response.usage
# Register custom pricing for Groq models
auditor.set_pricing_table({
"llama-3.3-70b-versatile": {"input": 0.00059, "output": 0.00079}
})
report = auditor.execute(
model="llama-3.3-70b-versatile",
input_tokens=usage.prompt_tokens,
output_tokens=usage.completion_tokens,
raw_response=choice,
input_text=prompt
)
report.display()
return choice
answer = ask_groq("What is machine learning?")
10. AWS Bedrock Integration
import boto3
import json
from llmauditor import auditor
bedrock = boto3.client("bedrock-runtime", region_name="us-east-1")
def ask_bedrock(prompt: str) -> str:
response = bedrock.invoke_model(
modelId="amazon.titan-text-express-v1",
contentType="application/json",
body=json.dumps({
"inputText": prompt,
"textGenerationConfig": {"maxTokenCount": 512}
})
)
body = json.loads(response["body"].read())
output_text = body["results"][0]["outputText"]
report = auditor.execute(
model="amazon.titan-text-express",
input_tokens=body.get("inputTextTokenCount", len(prompt.split())),
output_tokens=body.get("results", [{}])[0].get("tokenCount", 0),
raw_response=output_text,
input_text=prompt
)
report.display()
return output_text
Bedrock with Claude
import boto3
import json
from llmauditor import auditor
bedrock = boto3.client("bedrock-runtime", region_name="us-east-1")
def ask_bedrock_claude(prompt: str) -> str:
response = bedrock.invoke_model(
modelId="anthropic.claude-3-5-sonnet-20241022-v2:0",
contentType="application/json",
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1024,
"messages": [{"role": "user", "content": prompt}]
})
)
body = json.loads(response["body"].read())
report = auditor.execute(
model="claude-3.5-sonnet",
input_tokens=body["usage"]["input_tokens"],
output_tokens=body["usage"]["output_tokens"],
raw_response=body["content"][0]["text"],
input_text=prompt
)
report.display()
return body["content"][0]["text"]
11. Local Models (Ollama / llama.cpp / vLLM)
Ollama
import requests
from llmauditor import auditor
def ask_ollama(prompt: str, model: str = "llama3.1") -> str:
response = requests.post(
"http://localhost:11434/api/generate",
json={"model": model, "prompt": prompt, "stream": False}
)
data = response.json()
report = auditor.execute(
model=model,
input_tokens=data.get("prompt_eval_count", 0),
output_tokens=data.get("eval_count", 0),
raw_response=data["response"],
execution_time=data.get("total_duration", 0) / 1e9, # nanoseconds to seconds
input_text=prompt
)
report.display()
return data["response"]
vLLM (OpenAI-compatible endpoint)
import openai
from llmauditor import auditor
# vLLM serves an OpenAI-compatible API
client = openai.OpenAI(base_url="http://localhost:8000/v1", api_key="dummy")
@auditor.monitor(model="meta-llama/Llama-3.1-8B-Instruct")
def ask_vllm(prompt: str):
response = client.chat.completions.create(
model="meta-llama/Llama-3.1-8B-Instruct",
messages=[{"role": "user", "content": prompt}]
)
usage = response.usage
return {
"response": response.choices[0].message.content,
"input_tokens": usage.prompt_tokens,
"output_tokens": usage.completion_tokens,
}
Custom Pricing for Local Models
Local models have no API cost, but you can still track them:
from llmauditor import auditor
# Free model — cost will be $0.00 (default for unpriced models)
report = auditor.execute(
model="my-local-finetuned-model",
input_tokens=500,
output_tokens=200,
raw_response="Local model response here..."
)
# Cost shows $0.000000 — all other metrics still work
# Or set custom pricing to track compute costs:
auditor.set_pricing_table({
"my-local-finetuned-model": {"input": 0.0001, "output": 0.0002}
})
12. Agentic AI / Multi-Agent Patterns
Single Agent with Multiple Steps
from llmauditor import auditor
auditor.set_budget(0.10)
# Step 1: Planning
plan_report = auditor.execute(
model="gpt-4o", input_tokens=500, output_tokens=300,
raw_response="Plan: 1) Research topic 2) Draft outline 3) Write content"
)
# Step 2: Research
research_report = auditor.execute(
model="gpt-4o", input_tokens=800, output_tokens=400,
raw_response="Research findings: The topic covers three main areas..."
)
# Step 3: Writing
write_report = auditor.execute(
model="gpt-4o", input_tokens=1200, output_tokens=600,
raw_response="Final article: Introduction to the topic..."
)
# Check total cost across all steps
status = auditor.get_budget_status()
print(f"Total cost: ${status['cumulative_cost']:.4f}")
print(f"Executions: {status['executions']}")
Multi-Agent System (Researcher + Writer + Reviewer)
from llmauditor import auditor
auditor.set_budget(1.00) # $1 total for the multi-agent pipeline
auditor.set_alert_mode(True)
# Agent 1: Researcher (using GPT-4o)
auditor.execute(
model="gpt-4o", input_tokens=200, output_tokens=500,
raw_response="Research: Found 5 key points about AI safety..."
)
# Agent 2: Writer (using Claude)
auditor.execute(
model="claude-3.5-sonnet", input_tokens=600, output_tokens=1000,
raw_response="Article draft: AI Safety in 2025..."
)
# Agent 3: Reviewer (using Gemini)
auditor.execute(
model="gemini-2.0-flash", input_tokens=1200, output_tokens=300,
raw_response="Review: The article covers key points well. Suggest adding..."
)
# Agent 4: Editor (using GPT-4o-mini for cost efficiency)
auditor.execute(
model="gpt-4o-mini", input_tokens=1500, output_tokens=1200,
raw_response="Final edited article: ..."
)
# View all execution history
for i, report in enumerate(auditor.history()):
print(f"Step {i+1}: {report.model_name} — ${report.estimated_cost:.6f}")
# Budget tracking
status = auditor.get_budget_status()
print(f"\nTotal: ${status['cumulative_cost']:.6f} / ${status['budget_limit']:.2f}")
CrewAI Integration
from crewai import Agent, Task, Crew
from llmauditor import auditor
# Wrap CrewAI's LLM calls with auditing
auditor.set_budget(2.00)
auditor.start_evaluation("CrewAI Pipeline", version="1.0.0")
# After each agent completes, audit its output
def audit_agent_output(agent_name: str, model: str, input_tok: int,
output_tok: int, response: str):
"""Call this after each CrewAI agent finishes."""
report = auditor.execute(
model=model,
input_tokens=input_tok,
output_tokens=output_tok,
raw_response=response
)
return report
# ... run your CrewAI pipeline ...
# After pipeline completes:
auditor.end_evaluation()
eval_report = auditor.generate_evaluation_report()
eval_report.display()
eval_report.export("pdf", output_dir="./reports")
AutoGen Integration
from llmauditor import auditor
auditor.start_evaluation("AutoGen Chat", version="2.0")
# After each AutoGen message exchange, record it:
def on_message(sender: str, model: str, message: str,
input_tokens: int, output_tokens: int):
"""Hook into AutoGen's message callback."""
auditor.execute(
model=model,
input_tokens=input_tokens,
output_tokens=output_tokens,
raw_response=message
)
# ... run AutoGen conversation ...
auditor.end_evaluation()
report = auditor.generate_evaluation_report()
report.display()
13. Budget & Governance
Set a Budget Limit
from llmauditor import auditor, BudgetExceededError
auditor.set_budget(0.50) # Maximum $0.50 total spend
try:
report = auditor.execute(model="gpt-4o", input_tokens=50000,
output_tokens=20000, raw_response="...")
except BudgetExceededError as e:
print(f"Budget exceeded: {e}")
Alert Mode (Warn Instead of Block)
from llmauditor import auditor
auditor.set_budget(0.10)
auditor.set_alert_mode(True) # Don't raise exceptions, just warn
report = auditor.execute(
model="gpt-4o",
input_tokens=50000,
output_tokens=20000,
raw_response="Expensive response..."
)
# Report includes warning: [BUDGET] Cumulative cost exceeds budget
print(report.warnings)
Guard Mode (Block Low-Confidence Responses)
from llmauditor import auditor, LowConfidenceError
auditor.guard_mode(confidence_threshold=80) # Block if confidence < 80%
try:
report = auditor.execute(
model="gpt-4o",
input_tokens=5,
output_tokens=2,
raw_response="ok" # Very short → low confidence
)
except LowConfidenceError as e:
print(f"Blocked: {e}")
Guard Mode + Alert Mode (Warn Instead of Block)
from llmauditor import auditor
auditor.guard_mode(confidence_threshold=80)
auditor.set_alert_mode(True)
report = auditor.execute(
model="gpt-4o",
input_tokens=5,
output_tokens=2,
raw_response="ok"
)
# Report has warning instead of exception
print(report.warnings) # ['[GUARD MODE] Confidence 45% below threshold 80%']
Budget Status
from llmauditor import auditor
auditor.set_budget(1.00)
# ... run several executions ...
status = auditor.get_budget_status()
print(status)
# {
# "budget_limit": 1.0,
# "cumulative_cost": 0.034500,
# "remaining": 0.965500,
# "executions": 3
# }
Role-Based Governance
from llmauditor import auditor
auditor.set_role("production-safety-auditor")
# Role label is attached to all subsequent reports
14. Evaluation Sessions & Certification
Basic Evaluation
from llmauditor import auditor
# 1. Start evaluation
auditor.start_evaluation("My AI Chatbot", version="2.1.0")
# 2. Run multiple executions (any models, any pattern)
auditor.execute(model="gpt-4o", input_tokens=100, output_tokens=80,
raw_response="Response 1...")
auditor.execute(model="gpt-4o", input_tokens=150, output_tokens=120,
raw_response="Response 2 with more detail...")
auditor.execute(model="gpt-4o", input_tokens=200, output_tokens=90,
raw_response="Response 3...")
auditor.execute(model="gpt-4o", input_tokens=180, output_tokens=110,
raw_response="Response 4...")
auditor.execute(model="gpt-4o", input_tokens=160, output_tokens=95,
raw_response="Response 5...")
# 3. End evaluation
auditor.end_evaluation()
# 4. Generate certification report
report = auditor.generate_evaluation_report()
report.display() # Rich CLI certification panel
# 5. Access score
print(f"Score: {report.score.overall:.1f}/100")
print(f"Level: {report.score.level}") # e.g. "Platinum"
print(f"Subscores: {report.score.subscores}")
# 6. Export
report.export("pdf", output_dir="./reports")
report.export("html", output_dir="./reports")
report.export("md", output_dir="./reports")
Multi-Model Evaluation
from llmauditor import auditor
auditor.start_evaluation("Multi-Model App", version="1.0.0")
# Mix of models in one evaluation
auditor.execute(model="gpt-4o", input_tokens=200, output_tokens=100,
raw_response="GPT-4o answer...")
auditor.execute(model="claude-3.5-sonnet", input_tokens=200, output_tokens=100,
raw_response="Claude answer...")
auditor.execute(model="gemini-2.0-flash", input_tokens=200, output_tokens=100,
raw_response="Gemini answer...")
auditor.execute(model="gpt-4o-mini", input_tokens=200, output_tokens=100,
raw_response="GPT-4o-mini answer...")
auditor.end_evaluation()
report = auditor.generate_evaluation_report()
report.display()
# Models used is tracked
print(report.metrics.models_used)
# ['claude-3.5-sonnet', 'gemini-2.0-flash', 'gpt-4o', 'gpt-4o-mini']
Custom Certification Thresholds
from llmauditor import auditor
# Adjust scoring weights (must sum to 1.0)
auditor.set_certification_thresholds(
weights={
"stability": 0.15,
"factual_reliability": 0.30, # Prioritize factual accuracy
"governance_compliance": 0.25,
"cost_predictability": 0.10,
"risk_profile": 0.20,
},
levels={
"Platinum": 95, # Stricter Platinum threshold
"Gold": 85,
"Silver": 75,
"Conditional Pass": 65,
}
)
Export All Formats at Once
from llmauditor import auditor
# After generating evaluation report:
report = auditor.generate_evaluation_report()
# Export all 3 formats in one call
paths = report.export_all(output_dir="./reports")
print(paths)
# {"md": "./reports/certification_....md",
# "html": "./reports/certification_....html",
# "pdf": "./reports/certification_....pdf"}
Or use the standalone function:
from llmauditor import export_certification_all
paths = export_certification_all(report, output_dir="./reports")
15. Exporting Reports (MD / HTML / PDF)
Per-Execution Report Export
from llmauditor import auditor
report = auditor.execute(
model="gpt-4o",
input_tokens=200,
output_tokens=100,
raw_response="The answer is..."
)
# Export single execution
md_path = report.export("md", output_dir="./reports")
html_path = report.export("html", output_dir="./reports")
pdf_path = report.export("pdf", output_dir="./reports")
print(f"Markdown: {md_path}")
print(f"HTML: {html_path}")
print(f"PDF: {pdf_path}")
Certification Report Export
from llmauditor import auditor
# ... run evaluation session ...
report = auditor.generate_evaluation_report()
# Single format
report.export("pdf", output_dir="./reports")
# All formats at once
paths = report.export_all(output_dir="./reports")
Report Sections Include:
- Application Identity
- Evaluation Summary
- Metrics & Distributions
- Hallucination Analysis
- Governance Compliance
- Stability Analysis
- Scoring Breakdown
- Certification Verdict
- Improvement Recommendations
- Integrity Hash (tamper-proof)
- Understanding the Numbers (plain-language explanations)
- Report Summary
16. Custom Pricing Tables
Add Custom Models
from llmauditor import auditor
# Prices are USD per 1,000 tokens
auditor.set_pricing_table({
"llama-3.3-70b-versatile": {"input": 0.00059, "output": 0.00079},
"mixtral-8x7b-32768": {"input": 0.00024, "output": 0.00024},
"deepseek-v3": {"input": 0.00014, "output": 0.00028},
"my-finetuned-model": {"input": 0.001, "output": 0.002},
})
# Now these models will have cost tracking
report = auditor.execute(
model="llama-3.3-70b-versatile",
input_tokens=1000,
output_tokens=500,
raw_response="Response from Groq..."
)
print(f"Cost: ${report.estimated_cost:.6f}")
Override Built-in Pricing
from llmauditor import auditor
# Override existing model pricing (e.g., after a price change)
auditor.set_pricing_table({
"gpt-4o": {"input": 0.0025, "output": 0.01} # Updated pricing
})
Built-in Models (No Configuration Needed)
These 19 models have built-in pricing:
| Provider | Models |
|---|---|
| OpenAI | gpt-4, gpt-4-turbo, gpt-4o, gpt-4o-mini, gpt-3.5-turbo |
| Anthropic | claude-3-opus, claude-3-sonnet, claude-3-haiku, claude-3.5-sonnet, claude-3.5-haiku |
| gemini-pro, gemini-1.5-flash, gemini-1.5-pro, gemini-2.0-flash, gemini-2.0-flash-lite, gemini-2.5-flash, gemini-2.5-pro | |
| AWS | amazon.titan-text-express, amazon.titan-text-lite |
17. Hallucination Detection
Automatic (Built-in Rule-Based)
Hallucination detection runs automatically on every execute() / observe() / monitor() call:
from llmauditor import auditor
report = auditor.execute(
model="gpt-4o",
input_tokens=100,
output_tokens=200,
raw_response="The population of Tokyo is exactly 14,215,316 as of January 2024.",
input_text="What is the population of Tokyo?"
)
# Access hallucination analysis
hal = report.hallucination
print(f"Risk Score: {hal.risk_score_pct}%") # e.g. 35%
print(f"Risk Level: {hal.risk_level}") # LOW / MEDIUM / HIGH
print(f"Factual Claims: {hal.factual_claims_count}")
print(f"Specific Numbers: {hal.specific_numbers_count}")
print(f"Hedging Ratio: {hal.hedging_ratio:.2f}")
print(f"Method: {hal.method}") # "rule-based"
Enhanced: AI Judge Model
Add a secondary AI model for factual consistency checking:
import openai
from llmauditor import auditor
client = openai.OpenAI()
def judge_fn(prompt: str) -> str:
"""The judge function evaluates factual consistency."""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
temperature=0
)
return response.choices[0].message.content
# Configure the AI judge
auditor.set_hallucination_model(judge_fn, model="gpt-4o-mini")
# Now hallucination detection uses rule-based + AI judge
report = auditor.execute(
model="gpt-4o",
input_tokens=100,
output_tokens=200,
raw_response="The Great Wall of China is 21,196 km long.",
input_text="How long is the Great Wall of China?"
)
hal = report.hallucination
print(f"Method: {hal.method}") # "hybrid"
print(f"AI Judge Score: {hal.ai_judge_score}") # 0.0–1.0
print(f"AI Reasoning: {hal.ai_judge_reasoning}")
18. FastAPI Integration
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from llmauditor import auditor
app = FastAPI()
auditor.set_budget(10.00)
auditor.set_alert_mode(True)
class QueryRequest(BaseModel):
question: str
class QueryResponse(BaseModel):
answer: str
audit: dict
@app.post("/ask", response_model=QueryResponse)
async def ask(request: QueryRequest):
# Your LLM call here
answer, input_tokens, output_tokens = your_llm_call(request.question)
# Audit the execution
report = auditor.execute(
model="gpt-4o",
input_tokens=input_tokens,
output_tokens=output_tokens,
raw_response=answer,
input_text=request.question
)
return QueryResponse(
answer=answer,
audit=report.to_dict()
)
# Audit endpoint — get budget status
@app.get("/audit/status")
async def audit_status():
return auditor.get_budget_status()
@app.post("/audit/evaluate")
async def run_evaluation():
"""Generate certification report from all recorded executions."""
auditor.start_evaluation("My FastAPI App", version="1.0.0")
auditor.end_evaluation()
report = auditor.generate_evaluation_report()
return report.to_dict()
@app.get("/audit/export")
async def export_report():
"""Export certification PDF."""
auditor.start_evaluation("My FastAPI App", version="1.0.0")
auditor.end_evaluation()
report = auditor.generate_evaluation_report()
paths = report.export_all(output_dir="./reports")
return paths
19. Flask Integration
from flask import Flask, request, jsonify
from llmauditor import auditor
app = Flask(__name__)
auditor.set_budget(5.00)
auditor.set_alert_mode(True)
@app.route("/ask", methods=["POST"])
def ask():
data = request.json
question = data["question"]
# Your LLM call
answer, in_tok, out_tok = your_llm_call(question)
# Audit
report = auditor.execute(
model="gpt-4o",
input_tokens=in_tok,
output_tokens=out_tok,
raw_response=answer,
input_text=question
)
return jsonify({
"answer": answer,
"cost": report.estimated_cost,
"confidence": report.to_dict()["quality"]["confidence_score"],
"hallucination_risk": report.hallucination.risk_level if report.hallucination else "N/A"
})
@app.route("/audit/budget", methods=["GET"])
def budget():
return jsonify(auditor.get_budget_status())
20. Django Integration
# views.py
import json
from django.http import JsonResponse
from django.views.decorators.http import require_POST
from llmauditor import auditor
auditor.set_budget(10.00)
auditor.set_alert_mode(True)
@require_POST
def ask_view(request):
data = json.loads(request.body)
question = data["question"]
# Your LLM call
answer, in_tok, out_tok = your_llm_call(question)
report = auditor.execute(
model="gpt-4o",
input_tokens=in_tok,
output_tokens=out_tok,
raw_response=answer,
input_text=question
)
return JsonResponse({
"answer": answer,
"audit": report.to_dict()
})
21. Streamlit Integration
import streamlit as st
from llmauditor import auditor
auditor.set_budget(1.00)
st.title("AI Chat with Auditing")
prompt = st.text_input("Ask a question:")
if prompt:
# Your LLM call
answer, in_tok, out_tok = your_llm_call(prompt)
report = auditor.execute(
model="gpt-4o",
input_tokens=in_tok,
output_tokens=out_tok,
raw_response=answer,
input_text=prompt
)
st.write(answer)
# Show audit metrics in sidebar
with st.sidebar:
st.metric("Cost", f"${report.estimated_cost:.6f}")
st.metric("Tokens", report.total_tokens)
if report.hallucination:
st.metric("Hallucination Risk", report.hallucination.risk_level)
status = auditor.get_budget_status()
st.progress(status["cumulative_cost"] / status["budget_limit"])
st.caption(f"${status['cumulative_cost']:.4f} / ${status['budget_limit']:.2f}")
22. Error Handling & Safety
llmauditor is designed to never crash your application. Every module has error isolation:
from llmauditor import auditor
# Even with bad data, auditor returns a valid report
report = auditor.execute(
model="gpt-4o",
input_tokens=100,
output_tokens=50,
raw_response="Some response"
)
# If anything breaks internally, report.warnings contains the error message
# Your app continues running normally
Governance Exceptions (Intentional)
These are the only exceptions llmauditor raises — and only when you configure them:
from llmauditor import auditor, BudgetExceededError, LowConfidenceError
# BudgetExceededError — raised when budget is exceeded (normal mode)
# LowConfidenceError — raised when guard mode blocks low confidence
# To prevent these, use alert mode:
auditor.set_alert_mode(True)
# Now both become warnings in report.warnings instead of exceptions
Monitor Decorator Safety
The @monitor decorator never breaks the decorated function:
@auditor.monitor(model="gpt-4o")
def my_function(prompt):
return call_my_llm(prompt)
# If auditor has an internal error:
# 1. The original function still runs normally
# 2. The return value is preserved
# 3. The audit panel is silently skipped
23. Full API Reference
LLMAuditor Class
| Method | Description |
|---|---|
execute(model, input_tokens, output_tokens, raw_response, execution_time=None, input_text="") |
Record a completed execution, return ExecutionReport |
observe(model, input_text, output_text, input_tokens, output_tokens, execution_time=0.0) |
Observe execution + auto-display panel |
monitor(model, **kwargs) |
Decorator for automatic auditing |
set_budget(max_cost_usd) |
Set cumulative cost limit (USD) |
get_budget_status() |
Return budget tracking dict |
guard_mode(confidence_threshold=80) |
Enable guard mode (block low confidence) |
set_alert_mode(enabled=True) |
Toggle alert mode (warn vs. block) |
set_role(role) |
Assign governance role label |
start_evaluation(app_name, version="1.0.0") |
Begin evaluation session |
end_evaluation() |
End evaluation session |
generate_evaluation_report() |
Generate EvaluationReport with certification |
set_certification_thresholds(weights=None, levels=None) |
Customize scoring parameters |
set_hallucination_model(llm_callable, model="gpt-4o") |
Configure AI judge for hallucination detection |
set_pricing_table(custom_pricing) |
Override/extend model pricing |
enable_ai_summary(enabled, llm_callable=None) |
Toggle AI executive summaries |
history() |
Return list of all ExecutionReport objects |
clear_history() |
Clear history and reset cost |
ExecutionReport Properties
| Property | Type | Description |
|---|---|---|
execution_id |
str |
Unique UUID |
model_name |
str |
Model identifier |
execution_time |
float |
Seconds elapsed |
input_tokens |
int |
Input token count |
output_tokens |
int |
Output token count |
total_tokens |
int |
Total tokens |
estimated_cost |
float |
Cost in USD |
raw_response |
str |
LLM response text |
hallucination |
`HallucinationAnalysis | None` |
warnings |
list[str] |
Governance warnings |
ai_summary |
`str | None` |
| Method | Description |
|---|---|
display() |
Render rich CLI panel |
export(fmt, output_dir=".") |
Export to md/html/pdf |
to_dict() |
Full dict serialization |
EvaluationReport Properties
| Property | Type | Description |
|---|---|---|
session |
EvaluationSession |
Session metadata |
metrics |
EvaluationMetrics |
Aggregated metrics |
score |
CertificationScore |
Scoring result |
suggestions |
list[Suggestion] |
Improvement recommendations |
execution_reports |
list[ExecutionReport] |
Individual reports |
| Method | Description |
|---|---|
display() |
Render rich CLI certification panel |
export(fmt, output_dir=".") |
Export certification report |
export_all(output_dir=".") |
Export in md + html + pdf at once |
to_dict() |
Full dict serialization |
HallucinationAnalysis Properties
| Property | Type | Description |
|---|---|---|
risk_score |
float |
0.0–1.0 risk score |
risk_score_pct |
int |
Risk as percentage (0–100) |
risk_level |
str |
LOW / MEDIUM / HIGH / CRITICAL |
factual_claims_count |
int |
Number of factual claims detected |
specific_numbers_count |
int |
Number of specific numbers found |
date_references_count |
int |
Date references found |
currency_references_count |
int |
Currency references found |
hedging_ratio |
float |
0.0–1.0 hedging language ratio |
absolute_claims_count |
int |
Absolute ("always", "never") claims |
ai_judge_score |
`float | None` |
method |
str |
"rule-based" or "hybrid" |
CertificationScore Properties
| Property | Type | Description |
|---|---|---|
overall |
float |
Overall score 0–100 |
level |
str |
Platinum / Gold / Silver / Conditional Pass / Fail |
level_emoji |
str |
Visual emoji indicator |
subscores |
dict[str, float] |
Per-category scores |
weights |
dict[str, float] |
Weights used |
breakdown |
dict |
Detailed per-metric breakdown |
Exceptions
| Exception | When Raised |
|---|---|
BudgetExceededError |
Cumulative cost exceeds set_budget() limit (normal mode only) |
LowConfidenceError |
Confidence below guard_mode() threshold (normal mode only) |
Module-Level Objects
from llmauditor import (
auditor, # Pre-configured singleton LLMAuditor instance
LLMAuditor, # Class for creating custom instances
BudgetExceededError, # Budget governance exception
LowConfidenceError, # Guard mode governance exception
HallucinationAnalysis, # Hallucination result type
EvaluationReport, # Evaluation report type
CertificationScore, # Scoring result type
export_certification_all, # Standalone export function
)
24. Built-in Model Pricing
All prices are USD per 1,000 tokens.
| Model | Input $/1K | Output $/1K |
|---|---|---|
| gpt-4 | 0.030 | 0.060 |
| gpt-4-turbo | 0.010 | 0.030 |
| gpt-4o | 0.005 | 0.015 |
| gpt-4o-mini | 0.00015 | 0.0006 |
| gpt-3.5-turbo | 0.0005 | 0.0015 |
| claude-3-opus | 0.015 | 0.075 |
| claude-3-sonnet | 0.003 | 0.015 |
| claude-3-haiku | 0.00025 | 0.00125 |
| claude-3.5-sonnet | 0.003 | 0.015 |
| claude-3.5-haiku | 0.0008 | 0.004 |
| gemini-pro | 0.00025 | 0.0005 |
| gemini-1.5-flash | 0.000075 | 0.0003 |
| gemini-1.5-pro | 0.00125 | 0.005 |
| gemini-2.0-flash | 0.00015 | 0.0006 |
| gemini-2.0-flash-lite | 0.000075 | 0.0003 |
| gemini-2.5-flash | 0.00015 | 0.0006 |
| gemini-2.5-pro | 0.00125 | 0.010 |
| amazon.titan-text-express | 0.0002 | 0.0006 |
| amazon.titan-text-lite | 0.00015 | 0.0002 |
Unpriced models (not in table) return $0.00 — they still get full auditing.
25. Certification Levels
| Level | Score | Emoji |
|---|---|---|
| Platinum | ≥ 90 | 💎 |
| Gold | ≥ 80 | 🥇 |
| Silver | ≥ 70 | 🥈 |
| Conditional Pass | ≥ 60 | ⚠️ |
| Fail | < 60 | ❌ |
Subscores (default weights):
| Category | Weight | What It Measures |
|---|---|---|
| Stability | 20% | Latency variance, token variance, failure rate |
| Factual Reliability | 25% | Hallucination risk, confidence levels |
| Governance Compliance | 20% | Guard/budget violations, warnings |
| Cost Predictability | 15% | Cost variance, budget adherence |
| Risk Profile | 20% | Distribution of execution risk levels |
26. FAQ
Q: Does llmauditor call any LLM API?
A: No. It only analyzes the data you provide (tokens, response text, model name). The optional AI judge feature is the only exception, and you provide the LLM callable yourself.
Q: Will it crash my app?
A: No. Every module has error isolation. Internal errors produce warnings, not crashes. The only intentional exceptions are BudgetExceededError and LowConfidenceError (which you explicitly enable).
Q: What if my model isn't in the pricing table?
A: Cost shows as $0.00. Everything else still works. Use set_pricing_table() to add your model's pricing.
Q: Can I use multiple auditor instances?
A: Yes. from llmauditor import auditor gives you a pre-made singleton. You can also create additional instances if needed:
from llmauditor import auditor
# Use the singleton for most cases
auditor.set_budget(10.00)
# For separate tracking, clear and reconfigure:
auditor.clear_history()
auditor.set_budget(1.00)
Q: Can I reset between evaluation sessions?
A: Yes:
auditor.clear_history() # Reset history and cumulative cost
auditor.start_evaluation("New Session", version="2.0.0")
Q: What Python versions are supported?
A: Python 3.9 and above (3.9, 3.10, 3.11, 3.12, 3.13).
Q: Is it thread-safe?
A: The auditor singleton has its own state. For multi-threaded apps, use separate auditor instances per thread or use locking.
Complete End-to-End Example
"""
Complete example: Audit an OpenAI app, certify it, export PDF.
"""
from llmauditor import auditor
# ── Configuration ──
auditor.set_budget(0.50)
auditor.set_alert_mode(True)
auditor.set_pricing_table({
"llama-3.3-70b-versatile": {"input": 0.00059, "output": 0.00079}
})
# ── Start evaluation ──
auditor.start_evaluation("My Production App", version="3.0.0")
# ── Simulate 5 executions across different models ──
auditor.execute(
model="gpt-4o", input_tokens=250, output_tokens=180,
raw_response="Detailed analysis of market trends shows growth in AI...",
input_text="Analyze current market trends in AI"
)
auditor.execute(
model="claude-3.5-sonnet", input_tokens=300, output_tokens=200,
raw_response="The key findings suggest three primary factors...",
input_text="Summarize key findings from the research"
)
auditor.execute(
model="gemini-2.0-flash", input_tokens=150, output_tokens=100,
raw_response="Based on the data, the recommendation is to proceed...",
input_text="What do you recommend based on this data?"
)
auditor.execute(
model="gpt-4o-mini", input_tokens=200, output_tokens=150,
raw_response="The comparison reveals that Option A is 23% more cost-effective...",
input_text="Compare Option A vs Option B"
)
auditor.execute(
model="llama-3.3-70b-versatile", input_tokens=180, output_tokens=120,
raw_response="In conclusion, the strategy should focus on...",
input_text="Draft a conclusion for the strategy document"
)
# ── End evaluation and certify ──
auditor.end_evaluation()
report = auditor.generate_evaluation_report()
# ── Display results ──
report.display()
print(f"\nCertification: {report.score.level} ({report.score.overall:.1f}/100)")
print(f"Models tested: {', '.join(report.metrics.models_used)}")
# ── Export all formats ──
paths = report.export_all(output_dir="./reports")
for fmt, path in paths.items():
print(f" {fmt.upper()}: {path}")
# ── Budget status ──
status = auditor.get_budget_status()
print(f"\nBudget: ${status['cumulative_cost']:.4f} / ${status['budget_limit']:.2f}")
LLMAuditor v1.1.3 — Apache-2.0 License — GitHub — Production Examples
Contributing
Contributions are welcome. See the Issues tab for open tasks.
🚀 New Production Examples Available:
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file llmauditor-1.1.9.tar.gz.
File metadata
- Download URL: llmauditor-1.1.9.tar.gz
- Upload date:
- Size: 106.2 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ba6252e18d3262ee627cb66f4e33581300f228ef8480a225fac7201b009994ac
|
|
| MD5 |
a2a47922b8f8e53a62d1bb156d5b2a6c
|
|
| BLAKE2b-256 |
47d53208c33b931ea17854900f3dd1f317ca4a2c1508a38f4a659b31f3da7644
|
File details
Details for the file llmauditor-1.1.9-py3-none-any.whl.
File metadata
- Download URL: llmauditor-1.1.9-py3-none-any.whl
- Upload date:
- Size: 76.1 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.11
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ea6e255f4d7cb44c37ad0af90ba56273be1b768edd0a7582211476801f79d76e
|
|
| MD5 |
4a74ec1d04d22a26ffb1c41f69809de7
|
|
| BLAKE2b-256 |
5e080c292b1dc556a1d5800c3da502aeb8be1edb249b6bd570529b199087da0d
|







