A framework for selectively invoking LLMs and distilling repeated workloads into smaller models

Project description

LLMCostCut: The Intelligent Cost Cutter for Large Language Models
Optimized. Efficient. Powerful.





As LLM becomes more and more popular, the cost of using LLM is becoming a major concern. LLMCostCut is a discriminative workload for LLM to reduce the cost of using LLM while maintaining the accuracy.
Table of Contents
- 📋 Applications
- 🎯 Key Features
- 📦 Installation
- 🚀 Quick Start
- ⚙️ How It Works
- 📊 Experimental Results
- 📁 Project Structure
- 📚 API Reference
- 📖 Citation
- 🙏 Acknowledgements
📋 Applications
Reducing Cost of LLM Reasoning in Discriminative Workloads

🎯 Key Features
| 📈 Accuracy up to 95% | 💰 Around 10× Cost Reduction | ⚡ Nearly 1000× Speedup | 🛠️ Easy to Use |
|---|---|---|---|
| Maintain near-teacher quality while cutting LLM calls toward zero | Student handles most queries; teacher only when uncertain — inference bills drop dramatically | Local tiny student model (~100k-2M params) inference vs. LLM (~1T params) API calls — orders of magnitude faster in latency | Minimal code changes — Runnable in few lines of code |
📦 Installation
Install from source (recommended for development)
git clone https://github.com/zhaoliangvaio/llmcostcut.git
cd llmcostcut
pip install -e .
Install from PyPI
pip install llmcostcut
📋 Requirements
- Python >= 3.8
- PyTorch >= 1.9.0
- Transformers >= 4.20.0
Optional (for built-in OpenAI teacher and examples):
openai>=1.0.0python-dotenv>=1.0.0pydantic>=2.0.0
When using the built-in OpenAI teacher, set your API key:
export OPENAI_API_KEY="your-key-here"
Or put OPENAI_API_KEY=your-key-here in a .env file in the project root (loaded automatically if python-dotenv is installed).
🚀 Quick Start
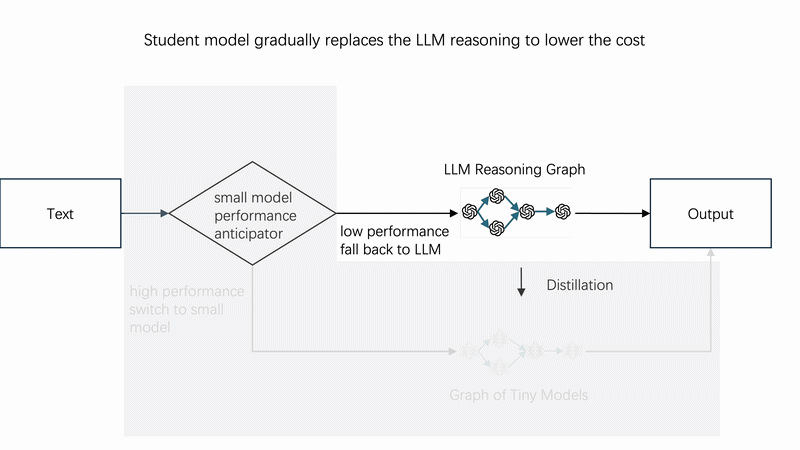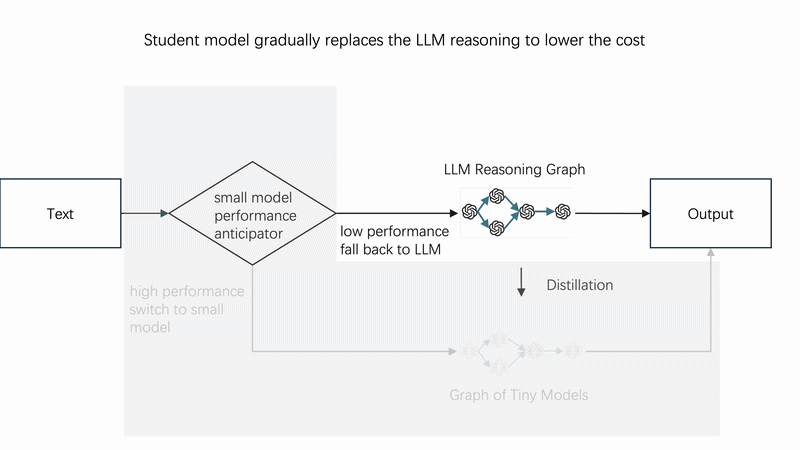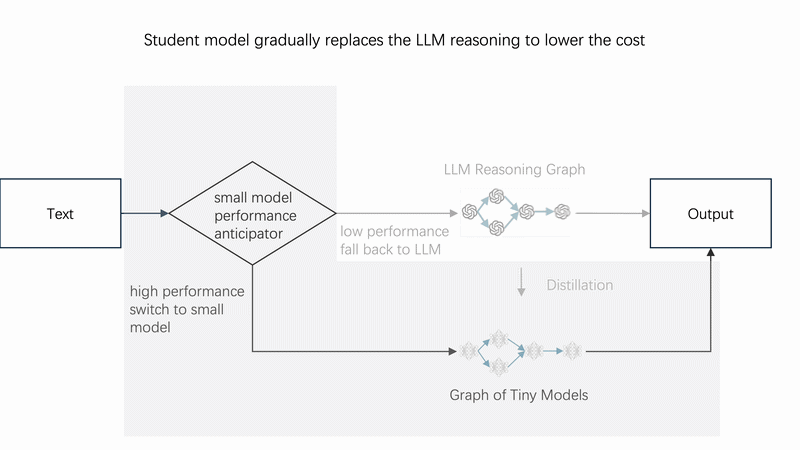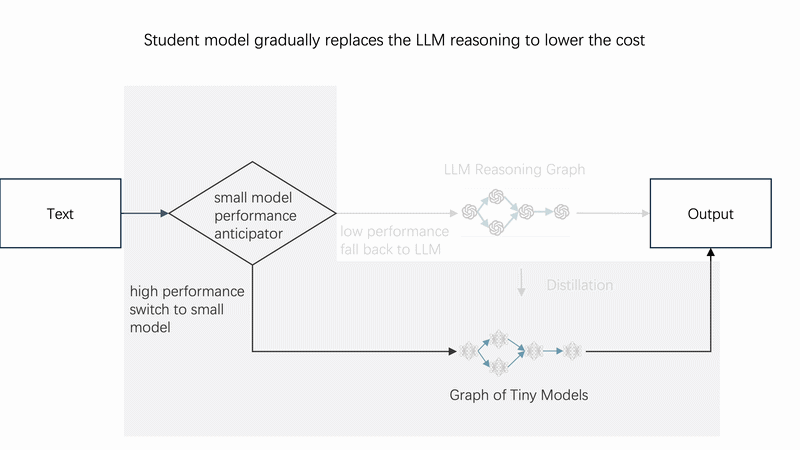
Instead of calling the LLM directly every time, use **monitor** as a smart router: it first tries the tiny student model; only when the student is uncertain (confidence below p_threshold) does it fall back to the teacher LLM. Over time, the student learns and LLM calls drop toward zero.
from datasets import load_dataset
from llmcostcut.monitor import monitor
from openai import OpenAI
def classify_with_llm(texts, task):
labels, client, results = task["topic_classification"], OpenAI(), []
for text in texts:
r = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role":"user","content":f"Classify into {labels}. Text: {text[:300]}. Output format should be one string of the label."}],
max_tokens=10,
)
results.append({"topic_classification": r.choices[0].message.content.strip()})
return results
TASK = {"topic_classification": ["World","Sports","Business","Sci/Tech"]}
for example in load_dataset("ag_news", split="train[:100]"):
output, used_llm_or_not = monitor(TASK, example["text"], llm_fn=classify_with_llm, mode="online")
monitor.close()
See examples/example.py for a full AG-News demo with GCP classifier and concept-level labels.
⚙️ How It Works
📊 Experimental Results
💰 Cost Reduction
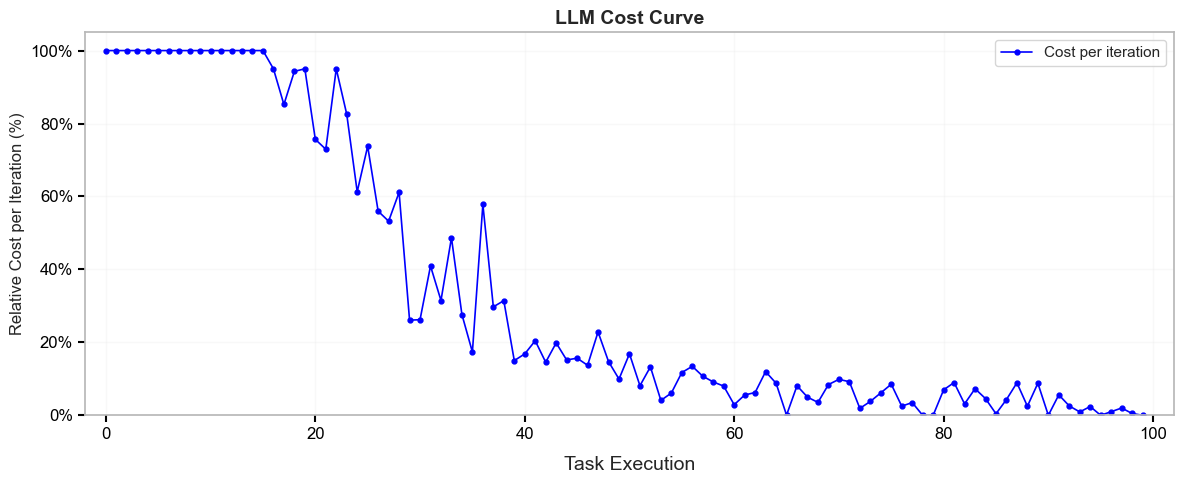
The inference cost decreases over time as the student model handles more queries and the fallback to the teacher LLM becomes less frequent.
📈 Accuracy
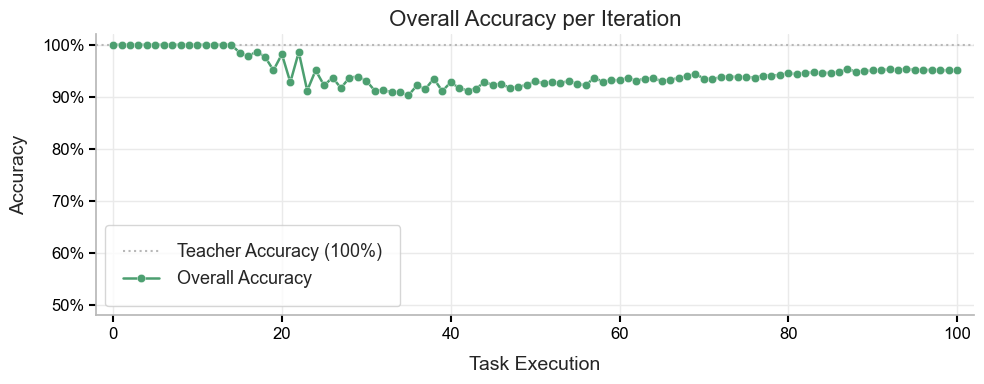
System accuracy stays close to the teacher baseline (100%) during training. Despite the drop in LLM fallback, accuracy stabilizes around 95% after the initial phase, showing that the distilled student preserves quality while cutting inference cost.
📊 Benchmarks Comparison in Accuracy
| Dataset | LLMCost with Multilayer Perceptron (MLP) as student model | LLMCost with Graph of Concepts (GCP) as student model |
|---|---|---|
| Supreme Court Judgment Prediction Dataset | 95.8 % | 97.6 % |
| MIMIC-CXR Dataset | 93.6 % | 96.5 % |
| American Express - Default Prediction Dataset | 95.7 % | 97.8 % |
Across Supreme Court Judgment Prediction Dataset, MIMIC-CXR Dataset, and American Express - Default Prediction Dataset, our student models approximately comparable to the teacher LLM baseline in relative accuracy: GCP (proposed in Distilling LLM Reasoning into Graph of Concept Predictors) reaches 97.6%, 96.5%, and 97.8% respectively, while MLP achieves 95.8%, 93.6%, and 95.7%. This demonstrates that the framework preserves prediction quality while enabling efficient inference.
📁 Project Structure
llmcostcut/
├── src/
│ └── llmcostcut/
│ __init__.py # Exports monitor
│ buffers.py # Replay buffer (RingBuffer, balanced sampling)
│ correctness.py # Correctness predictor
│ defaults.py # Encoder, tokenizer, optimizer defaults
│ models.py # Classifier heads (DeepMLP, GCP)
│ monitor.py # Core monitor() API and training orchestration
│ registry.py # Per-task registry
│ selector.py # Active-learning / offline sample selection
│ task.py # Task abstraction
│ trainer.py # Training and GCP submodule retraining
├── examples/
│ example.py # AG-News with GCP classifier (concept DAG + online/offline)
├── setup.py
├── pyproject.toml
├── requirements.txt
├── README.md
└── LICENSE
📚 API Reference
🔧 monitor(...) — main parameters
Required
**tasks**(dict[str, list[str]]): Task ID → list of allowed class labels.{"task1": ["class1", "class2"], "task2": ["A", "B", "C"]}
**text**(str | list[str] | tuple[str, ...]): Input text(s). Single string for one sample, list/tuple for batch.**mode**(str): Required."online"or"offline"."online": student is updated during inference."offline": student is frozen; samples are selected up-front viaoffline_select_methodandoffline_select_budget.
Optional parameters
| Parameter | Default | Description |
|---|---|---|
llm_fn |
built-in OpenAI | Teacher function. Custom signature: llm_fn(texts, tasks, **kwargs). |
p_threshold |
0.8 |
Min confidence to trust the student; below this, use LLM. |
classifier_type |
"deep_mlp" |
Student head: "deep_mlp" or "gcp". |
classifier_kwargs |
None |
Architecture-specific kwargs (see below). |
encoder |
distilbert-base-uncased |
Encoder model instance. |
device |
auto | Device (e.g. "cuda:0", "cpu"). |
llm_kwargs |
{} |
Passed to llm_fn. For default OpenAI teacher, can include concept_info for GCP concept labels. |
Offline-only parameters
| Parameter | Description |
|---|---|
offline_select_method |
Required when mode="offline". Strategy (e.g. "random", "uncertainty"). |
offline_select_budget |
Required when mode="offline". Max number of samples to send to the teacher. |
Return value
A 2-tuple (results, used_llm):
| Input | results |
used_llm |
|---|---|---|
Single str |
dict[str, str] |
bool |
| list/tuple str | list[dict[str, str]] |
list[bool] |
📖 Citation
If you use this framework in your research, please cite:
@article{yu2026distilling,
title = {Distilling {LLM} Reasoning into Graph of Concept Predictors},
author = {Ziyang Yu and Liang Zhao},
journal = {arXiv preprint arXiv:2602.03006},
year = {2026},
url = {https://arxiv.org/abs/2602.03006},
doi = {10.48550/arXiv.2602.03006},
}
🙏 Acknowledgements
This framework was developed by the team led by Prof. Liang Zhao at Emory University. We thank collaborators and students for feedback. The design draws on work in online learning, knowledge distillation, and adaptive inference.


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file llmcostcut-1.0.4.tar.gz.
File metadata
- Download URL: llmcostcut-1.0.4.tar.gz
- Upload date:
- Size: 47.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2b63360b45021e1a72459f05deca6420a189352bfb17760f0911a07b7ddc6f33
|
|
| MD5 |
93e56a20f386b0999e5e8a9e7da5b336
|
|
| BLAKE2b-256 |
2ca3294266dff9cdf3a094a2b36296b7b136416f1de43bbcfbbbeb5c0e3fd7c6
|
File details
Details for the file llmcostcut-1.0.4-py3-none-any.whl.
File metadata
- Download URL: llmcostcut-1.0.4-py3-none-any.whl
- Upload date:
- Size: 45.7 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.0
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ca71c42760bcad36a7541630489099d3a8db6f974baf32247b7920efcfd5c4b6
|
|
| MD5 |
a8a1669f3e8aeeb97b72081ea42ee7dd
|
|
| BLAKE2b-256 |
82527b503597a0cc927b4dd45d441d8af8eac9061f0958ca7a0479c77851849b
|







