Uncertainty Estimation Toolkit for Transformer Language Models



Project description

LM-Polygraph: Uncertainty Estimation for LLMs






Installation | Basic usage | Overview | Benchmark | Demo application | Documentation
LM-Polygraph provides a battery of state-of-the-art uncertainty estimation (UE) methods for LLMs in text generation tasks. High uncertainty can indicate the presence of hallucinations and knowing a score that estimates uncertainty can help to make applications of LLMs safer.
LM-Polygraph is also one of the most widely used benchmarks for the consistent evaluation of uncertainty estimation and hallucination detection methods. It is adopted by hundreds of researchers and technology companies.
Installation
From GitHub
The latest stable version is available in the main branch, it is recommended to use a virtual environment:
python -m venv env # Substitute this with your virtual environment creation command
source env/bin/activate
pip install git+https://github.com/IINemo/lm-polygraph.git
You can also use tags:
pip install git+https://github.com/IINemo/lm-polygraph.git@v0.5.0
From PyPI
The latest tagged version is also available via PyPI:
pip install lm-polygraph
Optional dependencies
Some features require additional packages that are not installed by default:
- COMET metric (translation evaluation):
unbabel-cometpinsnumpy<2.0which may conflict with packages like vLLM. Install via extras:pip install lm-polygraph[comet]
If you need numpy 2.x (e.g., for vLLM), install without the extra and add comet manually:pip install lm-polygraph pip install unbabel-comet --no-deps
Basic usage
- Initialize the base model (encoder-decoder or decoder-only) and tokenizer from HuggingFace or a local file, and use them to initialize the WhiteboxModel for evaluation:
from transformers import AutoModelForCausalLM, AutoTokenizer
from lm_polygraph.utils.model import WhiteboxModel
model_path = "Qwen/Qwen2.5-0.5B-Instruct"
base_model = AutoModelForCausalLM.from_pretrained(model_path, device_map="cuda:0")
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = WhiteboxModel(base_model, tokenizer, model_path=model_path)
- Specify the UE method:
from lm_polygraph.estimators import *
ue_method = MeanTokenEntropy()
- Get predictions and their uncertainty scores:
from lm_polygraph.utils import estimate_uncertainty
input_text = "Who is George Bush?"
ue = estimate_uncertainty(model, ue_method, input_text=input_text)
print(ue)
# UncertaintyOutput(uncertainty=-6.504108926902215, input_text='Who is George Bush?', generation_text=' President of the United States', model_path='Qwen/Qwen2.5-0.5B-Instruct')
- More examples: basic_example.ipynb
- See also a low-level example for efficient integration into your code: low_level_example.ipynb
Using with LLMs deployed as a service
LM-Polygraph can work with any OpenAI-compatible API services:
from lm_polygraph import BlackboxModel
from lm_polygraph.estimators import Perplexity, MaximumSequenceProbability
model = BlackboxModel.from_openai(
openai_api_key='YOUR_API_KEY',
model_path='gpt-4o',
supports_logprobs=True # Enable for deployments
)
ue_method = Perplexity() # or MeanTokenEntropy(), EigValLaplacian(), etc.
estimate_uncertainty(model, ue_method, input_text='What has a head and a tail but no body?')
UE methods such as EigValLaplacian() support fully blackbox LLMs that do not provide logits.
More examples:
- basic_example.ipynb: simple examples of scoring individual queries
- low_level_example.ipynb: low-level integration into inference and claim-level UE
- low_level_vllm_example.ipynb: low-level example using vLLM for faster inference
- basic_visual_llm_example.ipynb: examples for visual LLMs
Overview of methods
| Uncertainty Estimation Method | Type | Category | Compute | Memory | Need Training Data? | Level |
|---|---|---|---|---|---|---|
| Maximum sequence probability | White-box | Information-based | Low | Low | No | sequence/claim |
| Perplexity (Fomicheva et al., 2020a) | White-box | Information-based | Low | Low | No | sequence/claim |
| Mean/max token entropy (Fomicheva et al., 2020a) | White-box | Information-based | Low | Low | No | sequence/claim |
| Monte Carlo sequence entropy (Kuhn et al., 2023) | White-box | Information-based | High | Low | No | sequence |
| Pointwise mutual information (PMI) (Takayama and Arase, 2019) | White-box | Information-based | Medium | Low | No | sequence/claim |
| Conditional PMI (van der Poel et al., 2022) | White-box | Information-based | Medium | Medium | No | sequence |
| Rényi divergence (Darrin et al., 2023) | White-box | Information-based | Low | Low | No | sequence |
| Fisher-Rao distance (Darrin et al., 2023) | White-box | Information-based | Low | Low | No | sequence |
| Attention Score (Sriramanan et al., 2024) | White-box | Information-based | Medium | Low | No | sequence/claim |
| Contextualized Sequence Likelihood (CSL) (Lin et al., 2024) | White-box | Information-based | Medium | Low | No | sequence |
| Recurrent Attention-based Uncertainty Quantification (RAUQ) (Vazhentsev et al., 2025) | White-box | Information-based | Low | Low | No | sequence |
| Focus (Zhang et al., 2023) | White-box | Information-based | Medium | Low | No | sequence/claim |
| BoostedProb (Dinh et al., 2025) | White-box | Information-based | Low | Low | No | sequence/claim |
| Semantic entropy (Kuhn et al., 2023) | White-box | Meaning diversity | High | Low | No | sequence |
| Claim-Conditioned Probability (Fadeeva et al., 2024) | White-box | Meaning diversity | Low | Low | No | sequence/claim |
| FrequencyScoring (Mohri et al., 2024) | White-box | Meaning diversity | High | Low | No | claim |
| TokenSAR (Duan et al., 2023) | White-box | Meaning diversity | High | Low | No | sequence/claim |
| SentenceSAR (Duan et al., 2023) | White-box | Meaning diversity | High | Low | No | sequence |
| SAR (Duan et al., 2023) | White-box | Meaning diversity | High | Low | No | sequence |
| SemanticDensity (Qiu et al., 2024) | White-box | Meaning diversity | High | Low | No | sequence |
| CoCoA (Vashurin et al., 2025) | White-box | Meaning diversity | High | Low | No | sequence |
| EigenScore (Chen et al., 2024) | White-box | Meaning diversity | High | Low | No | sequence |
| Sentence-level ensemble-based measures (Malinin and Gales, 2020) | White-box | Ensembling | High | High | Yes | sequence |
| Token-level ensemble-based measures (Malinin and Gales, 2020) | White-box | Ensembling | High | High | Yes | sequence |
| Mahalanobis distance (MD) (Lee et al., 2018) | White-box | Density-based | Low | Low | Yes | sequence |
| Robust density estimation (RDE) (Yoo et al., 2022) | White-box | Density-based | Low | Low | Yes | sequence |
| Relative Mahalanobis distance (RMD) (Ren et al., 2023) | White-box | Density-based | Low | Low | Yes | sequence |
| Hybrid Uncertainty Quantification (HUQ) (Vazhentsev et al., 2023a) | White-box | Density-based | Low | Low | Yes | sequence |
| p(True) (Kadavath et al., 2022) | White-box | Reflexive | Medium | Low | No | sequence/claim |
| Number of semantic sets (NumSets) (Lin et al., 2023) | Black-box | Meaning Diversity | High | Low | No | sequence |
| Sum of eigenvalues of the graph Laplacian (EigV) (Lin et al., 2023) | Black-box | Meaning Diversity | High | Low | No | sequence |
| Degree matrix (Deg) (Lin et al., 2023) | Black-box | Meaning Diversity | High | Low | No | sequence |
| Eccentricity (Ecc) (Lin et al., 2023) | Black-box | Meaning Diversity | High | Low | No | sequence |
| Lexical similarity (LexSim) (Fomicheva et al., 2020a) | Black-box | Meaning Diversity | High | Low | No | sequence |
| Kernel Language Entropy (Nikitin et al., 2024) | Black-box | Meaning Diversity | High | Low | No | sequence |
| LUQ (Zhang et al., 2024) | Black-box | Meaning diversity | High | Low | No | sequence |
| Verbalized Uncertainty 1S (Tian et al., 2023) | Black-box | Reflexive | Low | Low | No | sequence |
| Verbalized Uncertainty 2S (Tian et al., 2023) | Black-box | Reflexive | Medium | Low | No | sequence |
Benchmark
To evaluate the performance of uncertainty estimation methods consider a quick example:
CUDA_VISIBLE_DEVICES=0 polygraph_eval \
--config-dir=./examples/configs/ \
--config-name=polygraph_eval_coqa.yaml \
model.path=meta-llama/Llama-3.1-8B \
subsample_eval_dataset=100
To evaluate the performance of uncertainty estimation methods using vLLM for generation, consider the following example:
CUDA_VISIBLE_DEVICES=0 polygraph_eval \
--config-dir=./examples/configs/ \
--config-name=polygraph_eval_coqa.yaml \
model=vllm \
model.path=meta-llama/Llama-3.1-8B \
estimators=default_estimators_vllm \
stat_calculators=default_calculators_vllm \
subsample_eval_dataset=100
You can also use a pre-built docker container for benchmarking, example:
docker run --gpus '"device=0"' --rm \
-w /app \
inemo/lm_polygraph \
bash -c "polygraph_eval \
--config-dir=./examples/configs/ \
--config-name=polygraph_eval_coqa.yaml \
model.path=meta-llama/Llama-3.1-8B \
subsample_eval_dataset=100"
The benchmark datasets in the correct format could be found in the HF repo. The scripts for dataset preparation could be found in the dataset_builders directory.
Use visualization_tables.ipynb or result_tables.ipynb to generate the summarizing tables for an experiment.
A detailed description of the benchmark is in the documentation.
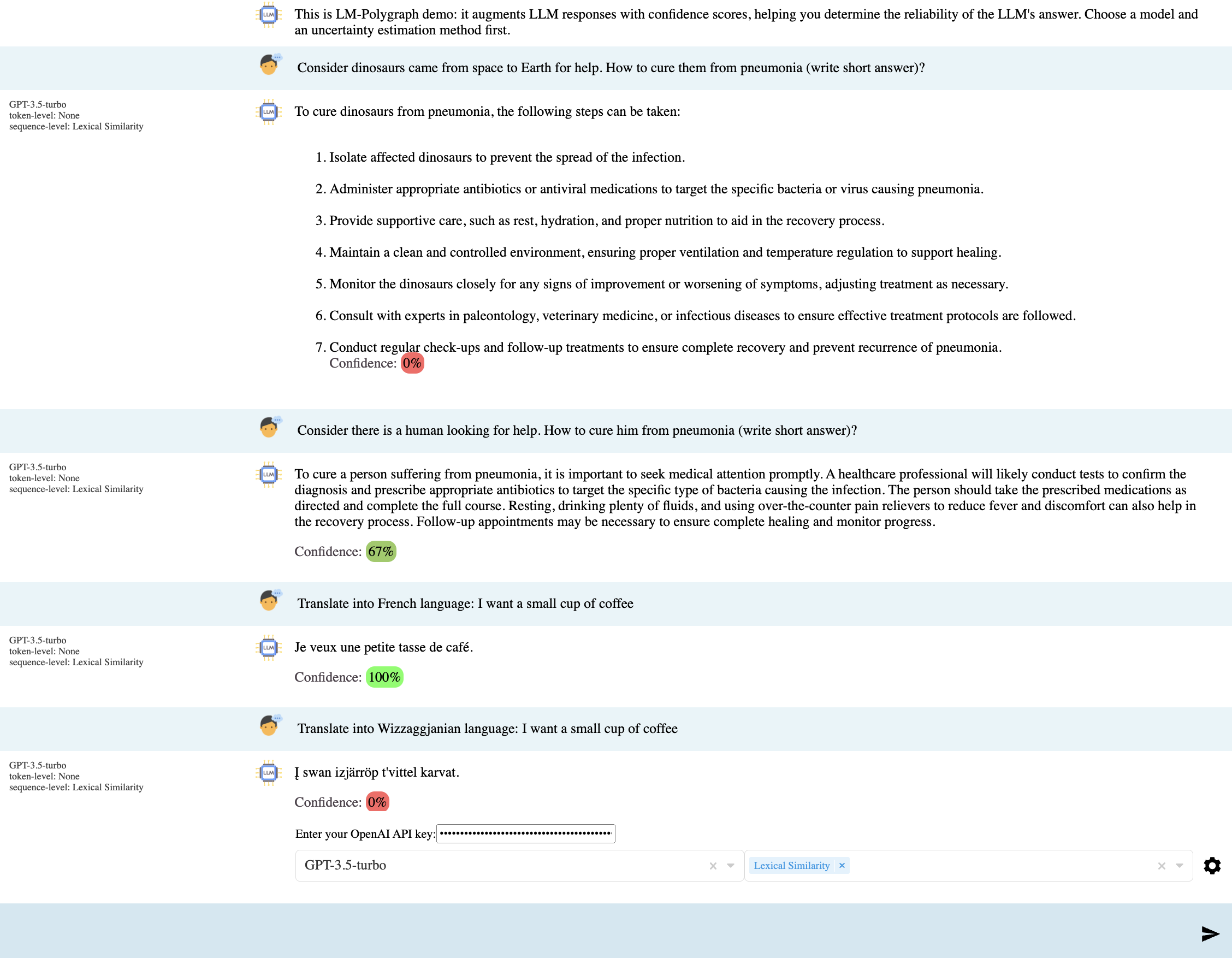
(Obsolete) Demo web application
Currently unsupported.
Cite
TACL-2025 paper:
@article{shelmanovvashurin2025,
author = {Vashurin, Roman and Fadeeva, Ekaterina and Vazhentsev, Artem and Rvanova, Lyudmila and Vasilev, Daniil and Tsvigun, Akim and Petrakov, Sergey and Xing, Rui and Sadallah, Abdelrahman and Grishchenkov, Kirill and Panchenko, Alexander and Baldwin, Timothy and Nakov, Preslav and Panov, Maxim and Shelmanov, Artem},
title = {Benchmarking Uncertainty Quantification Methods for Large Language Models with LM-Polygraph},
journal = {Transactions of the Association for Computational Linguistics},
volume = {13},
pages = {220-248},
year = {2025},
month = {03},
issn = {2307-387X},
doi = {10.1162/tacl_a_00737},
url = {https://doi.org/10.1162/tacl\_a\_00737},
eprint = {https://direct.mit.edu/tacl/article-pdf/doi/10.1162/tacl\_a\_00737/2511955/tacl\_a\_00737.pdf},
}
ACL-2025 Tutorial:
@inproceedings{shelmanov-etal-2025-uncertainty,
title = "Uncertainty Quantification for Large Language Models",
author = "Shelmanov, Artem and
Panov, Maxim and
Vashurin, Roman and
Vazhentsev, Artem and
Fadeeva, Ekaterina and
Baldwin, Timothy",
editor = "Arase, Yuki and
Jurgens, David and
Xia, Fei",
booktitle = "Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 5: Tutorial Abstracts)",
month = jul,
year = "2025",
address = "Vienna, Austria",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.acl-tutorials.3/",
doi = "10.18653/v1/2025.acl-tutorials.3",
pages = "3--4",
ISBN = "979-8-89176-255-8"
}
EMNLP-2023 paper:
@inproceedings{fadeeva-etal-2023-lm,
title = "{LM}-Polygraph: Uncertainty Estimation for Language Models",
author = "Fadeeva, Ekaterina and
Vashurin, Roman and
Tsvigun, Akim and
Vazhentsev, Artem and
Petrakov, Sergey and
Fedyanin, Kirill and
Vasilev, Daniil and
Goncharova, Elizaveta and
Panchenko, Alexander and
Panov, Maxim and
Baldwin, Timothy and
Shelmanov, Artem",
editor = "Feng, Yansong and
Lefever, Els",
booktitle = "Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.emnlp-demo.41",
doi = "10.18653/v1/2023.emnlp-demo.41",
pages = "446--461",
abstract = "Recent advancements in the capabilities of large language models (LLMs) have paved the way for a myriad of groundbreaking applications in various fields. However, a significant challenge arises as these models often {``}hallucinate{''}, i.e., fabricate facts without providing users an apparent means to discern the veracity of their statements. Uncertainty estimation (UE) methods are one path to safer, more responsible, and more effective use of LLMs. However, to date, research on UE methods for LLMs has been focused primarily on theoretical rather than engineering contributions. In this work, we tackle this issue by introducing LM-Polygraph, a framework with implementations of a battery of state-of-the-art UE methods for LLMs in text generation tasks, with unified program interfaces in Python. Additionally, it introduces an extendable benchmark for consistent evaluation of UE techniques by researchers, and a demo web application that enriches the standard chat dialog with confidence scores, empowering end-users to discern unreliable responses. LM-Polygraph is compatible with the most recent LLMs, including BLOOMz, LLaMA-2, ChatGPT, and GPT-4, and is designed to support future releases of similarly-styled LMs.",
}
Acknowledgements
The chat GUI implementation is based on the chatgpt-web-application project.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file lm_polygraph-0.7.0.tar.gz.
File metadata
- Download URL: lm_polygraph-0.7.0.tar.gz
- Upload date:
- Size: 181.8 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.25
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7f1ef49f75483199f76ae73e779b95d865ee4cd49adbb577555b76b728697027
|
|
| MD5 |
5478b9fc9e89d300a7d2fe8d4c2bc280
|
|
| BLAKE2b-256 |
b77bcd9829bd56e4897a37bff335c53dd673150c4677d0d216898e862f7679a6
|
File details
Details for the file lm_polygraph-0.7.0-py3-none-any.whl.
File metadata
- Download URL: lm_polygraph-0.7.0-py3-none-any.whl
- Upload date:
- Size: 267.9 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.9.25
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
081dc88132194c6949b3a3918e730af1652c23e60ca1c63bc42c7857139f6cff
|
|
| MD5 |
354aad465e0ec1bdfb07a68c06aedd6a
|
|
| BLAKE2b-256 |
be2c5738c1a8ee5e62a1bd72bab51778bdf57ecae754339de2b112ab8d8921e8
|







